
Twi Machine Translation



Abstract
:1. Introduction
- We are the first to introduce non-commercial machine translation systems for Twi–French and French–Twi.
- We created a parallel Twi–French corpus by extending an existing Twi–English corpus.
- For our language pairs, we investigated direct machine translation and cascading systems that use English as a pivot language.
- We compared our systems with the commercial system of Google Translate and managed to slightly outperform Google Translate with our best French–Twi system.
- To contribute to the improvement of low-resource languages, we share our code and our corpus with the research community (https://github.com/gyasifred/TW-FR-MT).
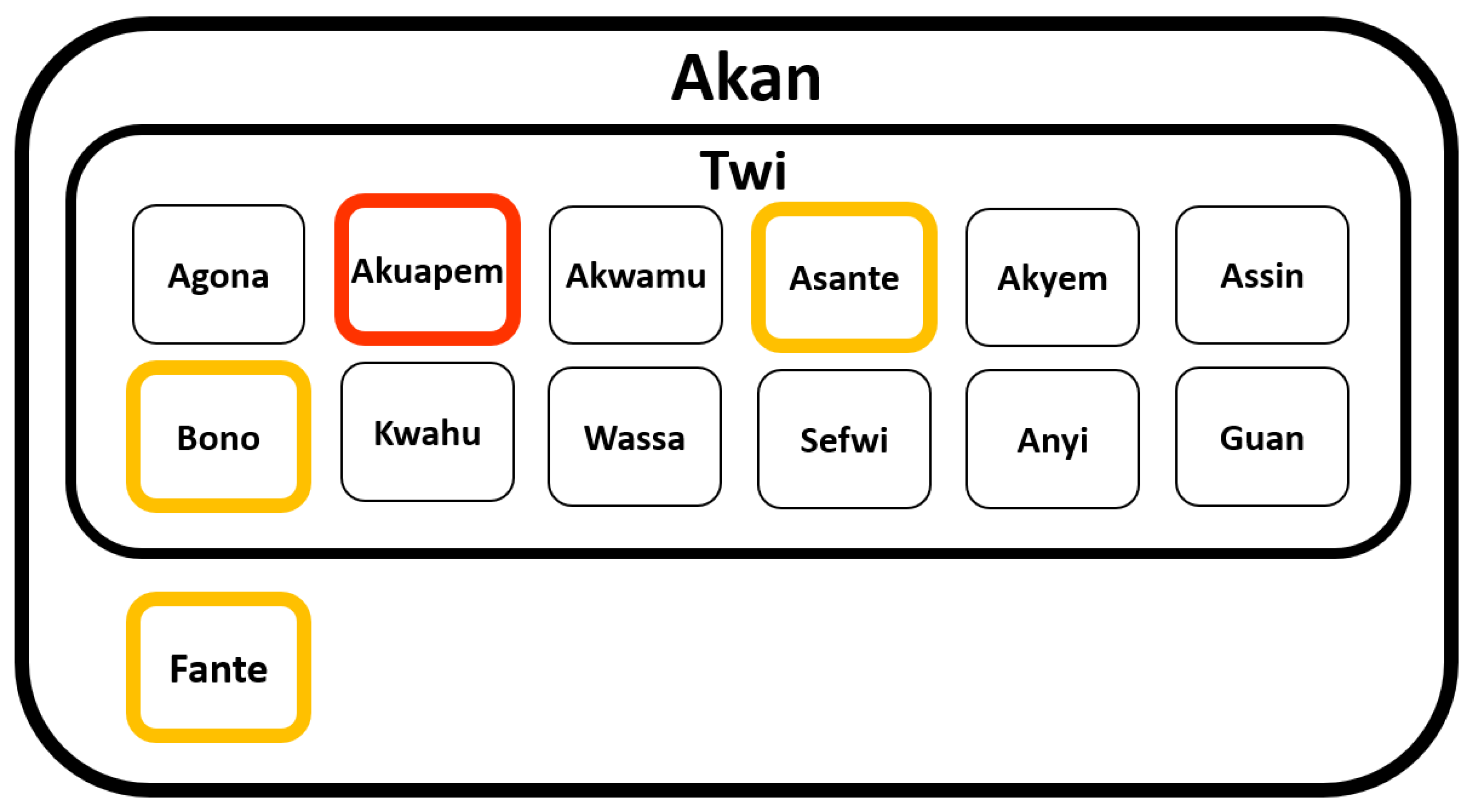
2. The Language Twi
3. Related Work
3.1. Parallel Corpora for Twi
3.2. Twi Machine Translation Systems
4. Our Parallel Twi–French–English Corpus
5. Twi Machine Translation
5.1. Evaluation Metrics
5.1.1. BLEU
5.1.2. AzunreBLEU
5.1.3. SacreBLEU
5.2. Systems’ Setup
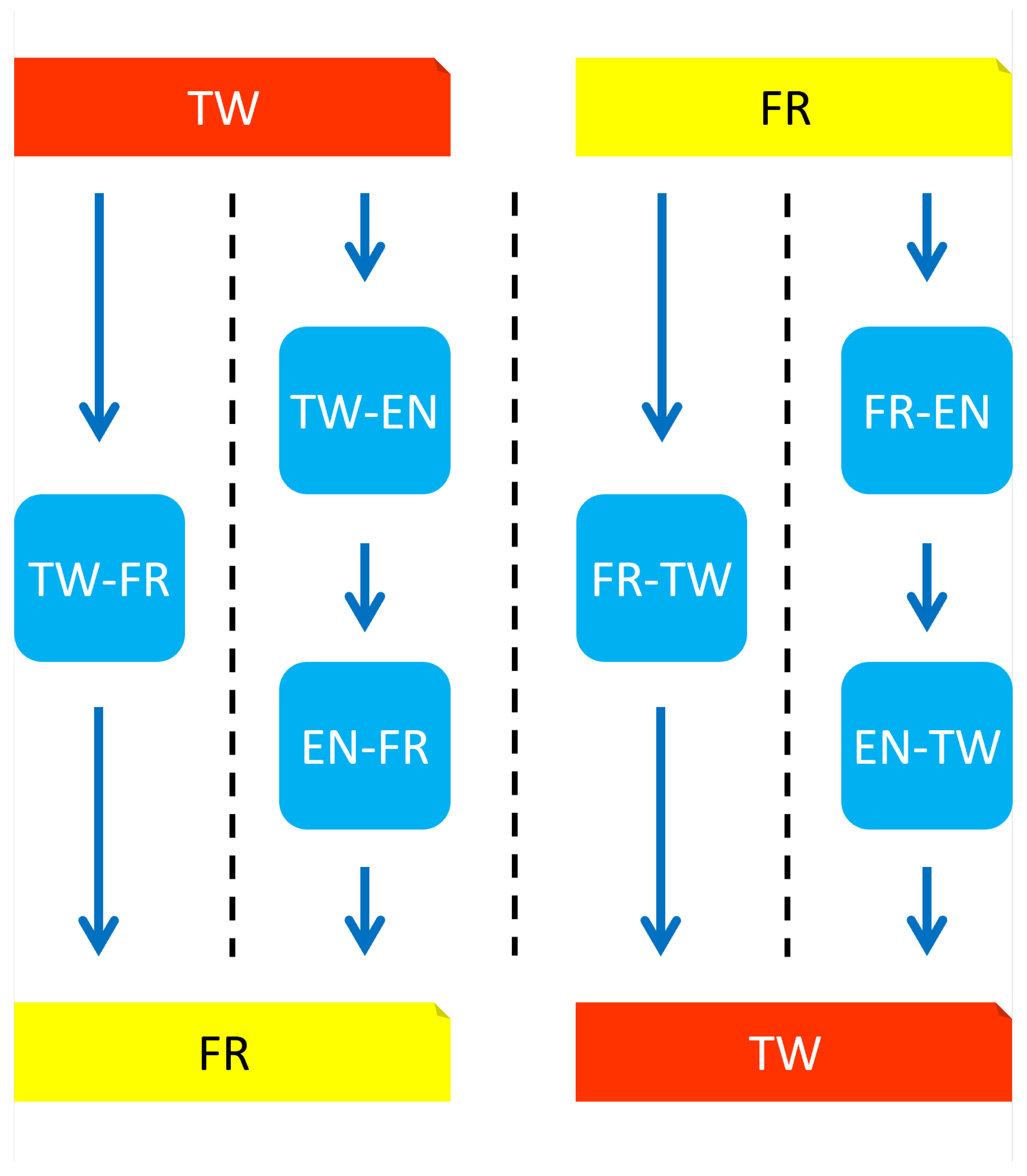
- In the direct machine translation systems, the texts in the source language is directly translated to the target language using a <source language>–<target language> model.
- In the cascading systems, the source language text is first translated to EN and then translated into the target language using a <source language>–EN model and an EN–<target language> model.

5.3. Results
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Steigerwald, E.; Ramírez-Castañeda, V.; Brandt, D.Y.C.; Báldi, A.; Shapiro, J.T.; Bowker, L.; Tarvin, R.D. Overcoming Language Barriers in Academia: Machine Translation Tools and a Vision for a Multilingual Future. BioScience 2022, 72, 988–998. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Garg, A.; Agarwal, M. Machine Translation: A Literature Review. arXiv 2019, arXiv:1901.01122. [Google Scholar]
- What Is Machine Translation? Available online: https://aws.amazon.com/what-is/machine-translation (accessed on 16 April 2023).
- Sabtan, Y.; Hussein, M.; Ethelb, H.; Omar, A. An Evaluation of the Accuracy of the Machine Translation Systems of Social Media Language. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 406–415. [Google Scholar] [CrossRef]
- Urlaub, P.; Dessein, E. Machine Translation and Foreign Language Education. Front. Artif. Intell. 2022, 5, 936111. [Google Scholar] [CrossRef] [PubMed]
- Schlippe, T.; Sawatzki, J. Cross-Lingual Automatic Short Answer Grading. In Proceedings of the 2nd International Conference on Artificial Intelligence in Education Technology (AIET), Wuhan, China, 18–20 June 2021. [Google Scholar]
- Schlippe, T.; Sawatzki, J. AI-Based Multilingual Interactive Exam Preparation. In Proceedings of the Learning Ideas Conference 2021 (14th annual conference), ALICE - Special Conference Track on Adaptive Learning via Interactive, Collaborative and Emotional Approaches, New York, NY, USA, 14–18 June 2021. [Google Scholar]
- Schlippe, T.; Eichinger, K. Multilingual Text Simplification and its Performance on Social Sciences Coursebooks. In Proceedings of the 4th International Conference on Artificial Intelligence in Education Technology (AIET), Berlin, Germany, 30 June–2 July 2023. [Google Scholar]
- Brynjolfsson, E.; Hui, X.; Liu, M. Does Machine Translation Affect International Trade? Evidence from a Large Digital Platform. Manag. Sci. 2019, 65, 5449–5460. [Google Scholar] [CrossRef]
- Emezue, C.C.; Dossou, B.F.P. MMTAfrica: Multilingual Machine Translation for African Languages. In Proceedings of the Sixth Conference on Machine Translation, Online, 10–11 November 2021; pp. 398–411. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the NIPS’14 27th International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; Volume 2, pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Kalchbrenner, N.; Espeholt, L.; Simonyan, K.; van den Oord, A.; Graves, A.; Kavukcuoglu, K. Neural Machine Translation in Linear Time. arXiv 2016, arXiv:1610.10099. [Google Scholar]
- Yang, J.; Yin, Y.; Ma, S.; Zhang, D.; Li, Z.; Wei, F. High-resource Language-specific Training for Multilingual Neural Machine Translation. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, (IJCAI-22), Vienna, Austria, 23–29 July 2022; pp. 4461–4467. [Google Scholar] [CrossRef]
- Haddow, B.; Bawden, R.; Miceli Barone, A.V.; Helcl, J.; Birch, A. Survey of Low-Resource Machine Translation. Comput. Linguist. 2022, 48, 673–732. [Google Scholar] [CrossRef]
- Ranathunga, S.; Lee, E.S.A.; Skenduli, M.P.; Shekhar, R.; Alam, M.; Kaur, R. Neural Machine Translation for Low-Resource Languages: A Survey. ACM Comput. Surv. 2021, 55, 1–37. [Google Scholar] [CrossRef]
- Meuret, D.; Duru-Bellat, M. English and French Modes of Regulation of the Education System: A Comparison. Comp. Educ. 2003, 39, 463–477. [Google Scholar] [CrossRef]
- Cashman, K. Masakhane: Using AI to Bring African Languages Into the Global Conversation. 2023. Available online: https://en.reset.org/masakhane-using-ai-bring-african-languages-global-conversation-02042020 (accessed on 16 April 2023).
- Azunre, P.; Osei, S.; Salomey, A.A.; Adu-Gyamfi, L.A.; Moore, S.; Adabankah, B.; Opoku, B.; Asare-Nyarko, C.; Nyarko, S.; Amoaba, C.; et al. English-Twi Parallel Corpus for Machine Translation. arXiv 2021, arXiv:2103.15625. [Google Scholar]
- Ghana. 2023. Available online: https://thecommonwealth.org/our-member-countries/ghana (accessed on 16 April 2023).
- Fournier-Passard, Y. Ghana Relies on French Language to Influence West Africa. 2019. Available online: http://www.echosdughana.com/2019/07/08/ghana-relies-on-french-language-to-influence-west-africa (accessed on 16 April 2023).
- The French Language in Figures. 2022. Available online: https://www.diplomatie.gouv.fr/en/french-foreign-policy/francophony-and-the-french-language/the-french-language-in-figures (accessed on 16 April 2023).
- Qui Parle Français Dans Le Monde. 2023. Available online: http://observatoire.francophonie.org/qui-parle-francais-dans-le-monde (accessed on 16 April 2023).
- Parliament Support Choice of French as 2nd Language. 2019. Available online: https://www.parliament.gh/news?CO=40 (accessed on 16 April 2023).
- Khaya Translator App—Android. 2021. Available online: https://ghananlp.org/project/khaya-android (accessed on 16 April 2023).
- Caswell, I. Google Translate Learns 24 New Languages. 2022. Available online: https://blog.google/products/translate/24-new-languages (accessed on 16 April 2023).
- Tiedemann, J.; Thottingal, S. OPUS-MT—Building Open Translation Services for the World. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; pp. 479–480. [Google Scholar]
- Chachu, S. Implications of Language Barriers for Access to Healthcare: The Case of Francophone Migrants in Ghana. Legon J. Humanit. 2022, 32, e122. [Google Scholar] [CrossRef]
- Akan (Twi) at Rutgers. 2022. Available online: https://www.amesall.rutgers.edu/languages/128-akan-twi (accessed on 16 April 2023).
- Akan Twi. 2023. Available online: https://celt.indiana.edu/portal/Akan%20Twi/index.html (accessed on 16 April 2023).
- Osam, E.K. An Introduction to the Verbal and Multi-Verbal System of Akan. In Proceedings of the Workshop on Multi-verb Constructions, Trondheim, Norway, 2003. [Google Scholar]
- Kouadio, N.J. A Unified Orthography for the Akan Languages of Ghana and Ivory Coast: General Unified Spelling Rules; Monograph Series; Centre for Advanced Studies of African Society, CASAS: Cape Town, South Africa, 2003; Volume 20. [Google Scholar]
- Schachter, P.; Fromkin, V. A Phonology of Akan: Akuapem, Asante, Fante; Working Papers in Phonetics; University of California: Los Angeles, CA, USA, 1979. [Google Scholar]
- The African Linguists Network Blog. Language Guide. Available online: https://alnresources.wordpress.com/african-culture-and-language (accessed on 16 April 2023).
- Alabi, J.O.; Amponsah-Kaakyire, K.; Adelani, D.I.; España-Bonet, C. Massive vs. Curated Embeddings for Low-Resourced Languages: The Case of Yorùbá and Twi. In Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), Marseilles, France, 13–15 May 2020. [Google Scholar]
- Agić, Ž.; Vulić, I. JW300: A Wide-Coverage Parallel Corpus for Low-Resource Languages. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3204–3210. [Google Scholar] [CrossRef]
- Afram, G.K.; Weyori, B.A.; Adekoya, F.A. TWIENG: A Multi-Domain Twi-English Parallel Corpus for Machine Translation of Twi, a Low-Resource African Language. Preprints 2022. [Google Scholar] [CrossRef]
- Beermann, D.; Hellan, L. Enhancing Grammar and Valence Resources for Akan and Ga. In West African Languages. Linguistic Theory and Communication; WUW: Warszawa, Poland, 2020; pp. 166–188. [Google Scholar] [CrossRef]
- Beermann, D.; Hellan, L.; Mihaylov, P.; Struck, A. Developing a Twi (Asante) Dictionary from Akan Interlinear Glossed Texts. In Proceedings of the 1st Joint Workshop on Spoken Language Technologies for Under-resourced languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL), Marseille, France, 13–15 May 2020; pp. 294–297. [Google Scholar]
- Strassel, S.; Tracey, J. LORELEI Language Packs: Data, Tools, and Resources for Technology Development in Low Resource Languages. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 3273–3280. [Google Scholar]
- Christianson, C.; Duncan, J.; Onyshkevych, B. Overview of the DARPA LORELEI Program. Mach. Transl. 2018, 32, 3–9. [Google Scholar] [CrossRef]
- Tracey, J.; Strassel, S.; Graff, D.; Wright, J.; Chen, S.; Ryant, N.; Kulick, S.; Griffitt, K.; Delgado, D.; Arrigo, M. LORELEI Akan Representative Language Pack; Web Download; Linguistic Data Consortium: Philadelphia, PA, USA, 15 January 2021. [Google Scholar] [CrossRef]
- Adjeisah, M.; Liua, G.; Nortey, R.N.; Song, J. English↔Twi Parallel-Aligned Bible corpus for Encoder-Decoder based machine translation. Acad. J. Sci. Res. 2020, 8, 371–382. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Hoang, H.; Koehn, P. Design of the Moses Decoder for Statistical Machine Translation. In Proceedings of the Software Engineering, Testing, and Quality Assurance for Natural Language Processing, Columbus, OH, USA, 20 June 2008; pp. 58–65. [Google Scholar]
- Junczys-Dowmunt, M.; Grundkiewicz, R.; Dwojak, T.; Hoang, H.; Heafield, K.; Neckermann, T.; Seide, F.; Germann, U.; Aji, A.F.; Bogoychev, N.; et al. Marian: Fast Neural Machine Translation in C++. In Proceedings of the ACL 2018, System Demonstrations, Melbourne, Australia, 15–20 July 2018; pp. 116–121. [Google Scholar] [CrossRef]
- Spark NLP. 2023. Available online: https://nlp.johnsnowlabs.com (accessed on 16 April 2023).
- Post, M. A Call for Clarity in Reporting BLEU Scores. arXiv 2018, arXiv:1804.08771. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL 2002), Philadelphia, PA, USA, 6–12 July 2002. [Google Scholar]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL 2002), Philadelphia, PA, USA, 6–12 July 2002; pp. 63–70. [Google Scholar] [CrossRef]
- Lin, Z.; Jin, X.; Xu, X.; Wang, Y.; Tan, S.; Cheng, X. Make It Possible: Multilingual Sentiment Analysis Without Much Prior Knowledge. In Proceedings of the IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014; Volume 2, pp. 79–86. [Google Scholar] [CrossRef]
- Balahur, A.; Turchi, M. Comparative Experiments using Supervised Learning and Machine Translation for Multilingual Sentiment Analysis. Comput. Speech Lang. 2014, 28, 56–75. [Google Scholar] [CrossRef]
- Vilares, D.; Alonso Pardo, M.; Gómez-Rodríguez, C. Supervised Sentiment Analysis in Multilingual Environments. Inf. Process. Manag. 2017, 53, 595–607. [Google Scholar] [CrossRef]
- Can, E.F.; Ezen-Can, A.; Can, F. Multilingual Sentiment Analysis: An RNN-Based Framework for Limited Data. In Proceedings of the ACM SIGIR 2018 Workshop on Learning from Limited or Noisy Data, Ann Arbor, MI, USA, 8–12 July 2018. [Google Scholar]
- Rakhmanov, O.; Schlippe, T. Sentiment Analysis for Hausa: Classifying Students’ Comments. In Proceedings of the 1st Annual Meeting of the ELRA/ISCA Special Interest Group on Under-Resourced Languages (SIGUL 2022), Marseille, France, 24–25 June 2022. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP): System Demonstrations, Brussels, Belgium, 7–11 December 2018; pp. 66–71. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization; In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #Sentences | #Word Tokens | #Unique Words | |
|---|---|---|---|
| Twi | 10,708 | 70,400 | 7,966 |
| French | 10,708 | 70,257 | 10,160 |
| English | 10,708 | 67,677 | 8,239 |
| #Sentences | % | |
|---|---|---|
| Train | 8,566 | 80 |
| Validation | 1,071 | 10 |
| Test | 1,071 | 10 |
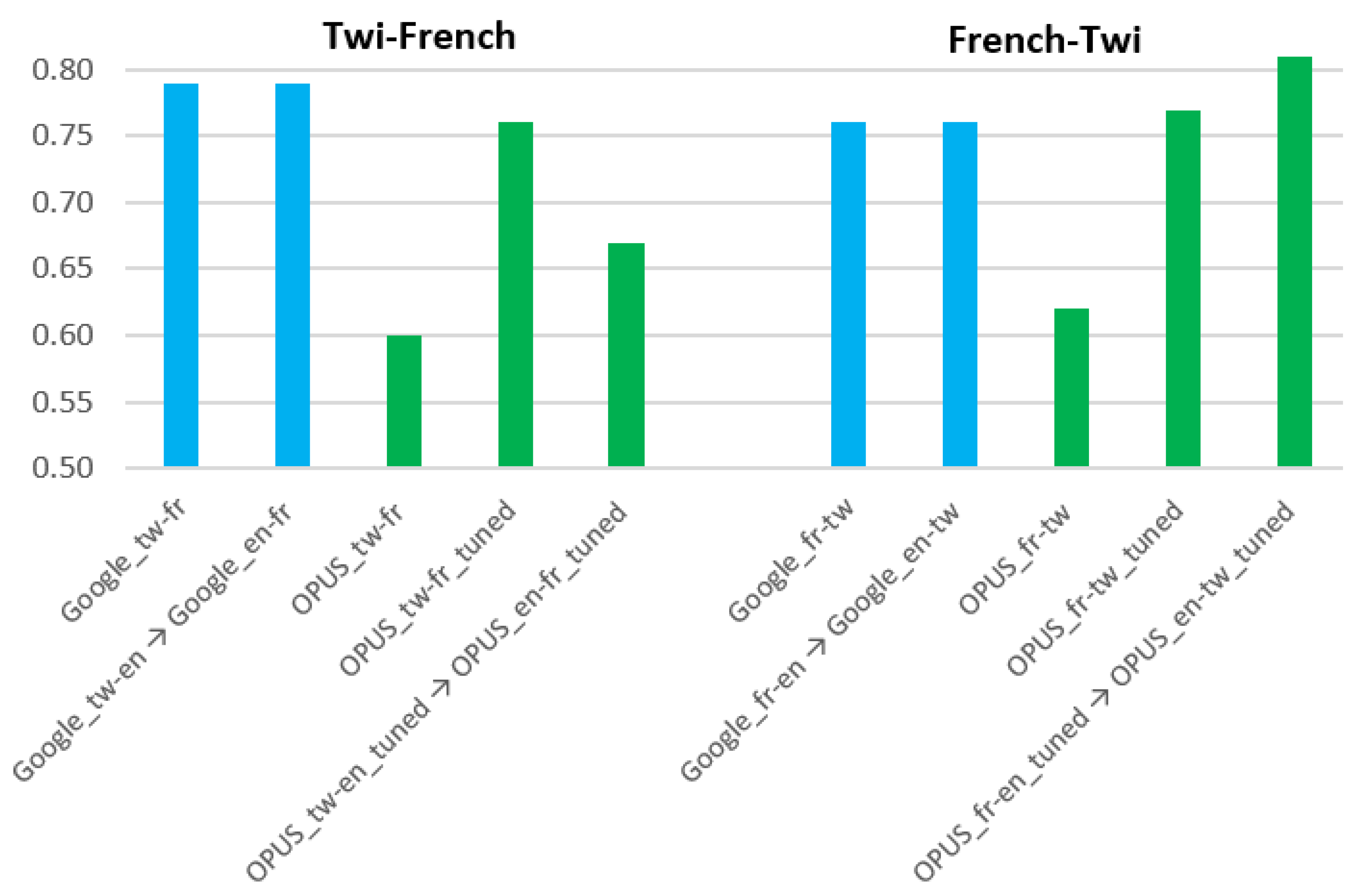
| Model | Fine-Tuning | BLEU | AzunreBLEU | SacreBLEU |
|---|---|---|---|---|
| Google_tw-fr | — | 0.41 | 0.79 | 0.44 |
| Google_tw-en→Google_en-fr | — | 0.41 | 0.79 | 0.44 |
| OPUS_tw-fr | — | 0.22 | 0.60 | 0.21 |
| OPUS_tw-fr_tuned | our corpus | 0.36 | 0.76 | 0.37 |
| OPUS_tw-en_tuned → OPUS_en-fr_tuned | our corpus | 0.30 | 0.67 | 0.31 |
| Google_fr-tw | — | 0.37 | 0.76 | 0.34 |
| Google_fr-en→Google_en-tw | — | 0.37 | 0.76 | 0.34 |
| OPUS_fr-tw | — | 0.21 | 0.62 | 0.14 |
| OPUS_fr-tw_tuned | our corpus | 0.40 | 0.77 | 0.39 |
| OPUS_fr-en_tuned → OPUS_en-tw_tuned | our corpus | 0.44 | 0.81 | 0.42 |
| BLEU | AzunreBLEU | SacreBLEU | |
|---|---|---|---|
| to Google_tw_fr | −12.2% | −3.8% | −15.9% |
| to OPUS_tw_fr | 63.6% | 26.7% | 76.2% |
| to Google_fr_tw | 18.9% | 6.6% | 23.5% |
| to OPUS_tw_fr | 125.0% | 30.6% | 200.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gyasi, F.; Schlippe, T. Twi Machine Translation. Big Data Cogn. Comput. 2023, 7, 114. https://doi.org/10.3390/bdcc7020114
Gyasi F, Schlippe T. Twi Machine Translation. Big Data and Cognitive Computing. 2023; 7(2):114. https://doi.org/10.3390/bdcc7020114
Chicago/Turabian StyleGyasi, Frederick, and Tim Schlippe. 2023. "Twi Machine Translation" Big Data and Cognitive Computing 7, no. 2: 114. https://doi.org/10.3390/bdcc7020114
APA StyleGyasi, F., & Schlippe, T. (2023). Twi Machine Translation. Big Data and Cognitive Computing, 7(2), 114. https://doi.org/10.3390/bdcc7020114