

Empowering Propaganda Detection in Resource-Restraint Languages: A Transformer-Based Framework for Classifying Hindi News Articles


Abstract
:1. Introduction
1.1. Background
1.2. Motivation
- Limited analysis of techniques effective in striving against propaganda;
- Constrained research on identifying propaganda in Hindi news articles.
1.3. Contributions
- Experiments with three deep learning models using Word2vec embeddings trained on our corpus;
- Experimentation with four variations of bidirectional encoder representation from transformer embeddings;
- Analysis of all models by evaluating them on test data;
- Fine-tuned multi-lingual BERT model for propaganda classification.
2. Related Work
2.1. Deep Learning Models
2.2. Transformer-Based Models
2.3. Propaganda Classification in Low-Resource Languages
2.4. Propaganda-Related Datasets
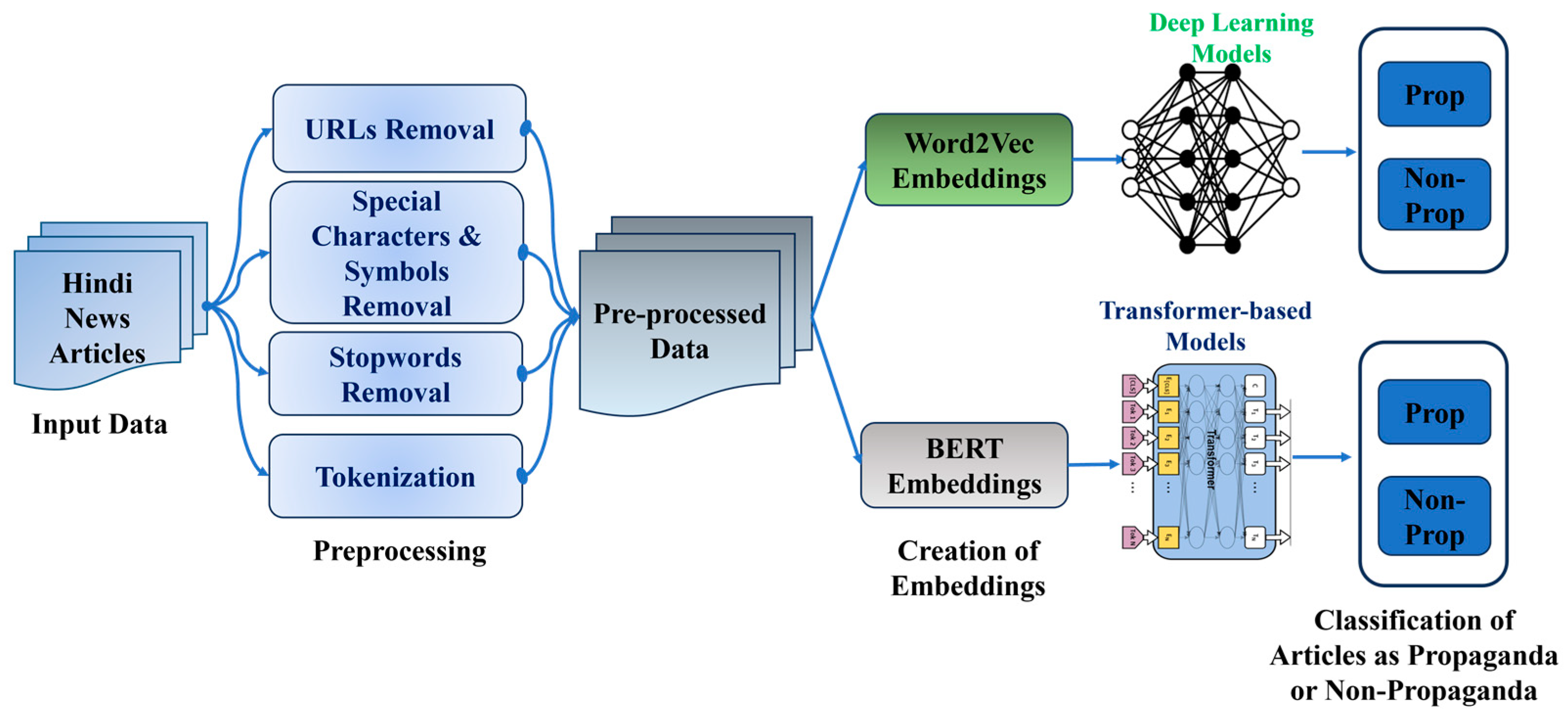
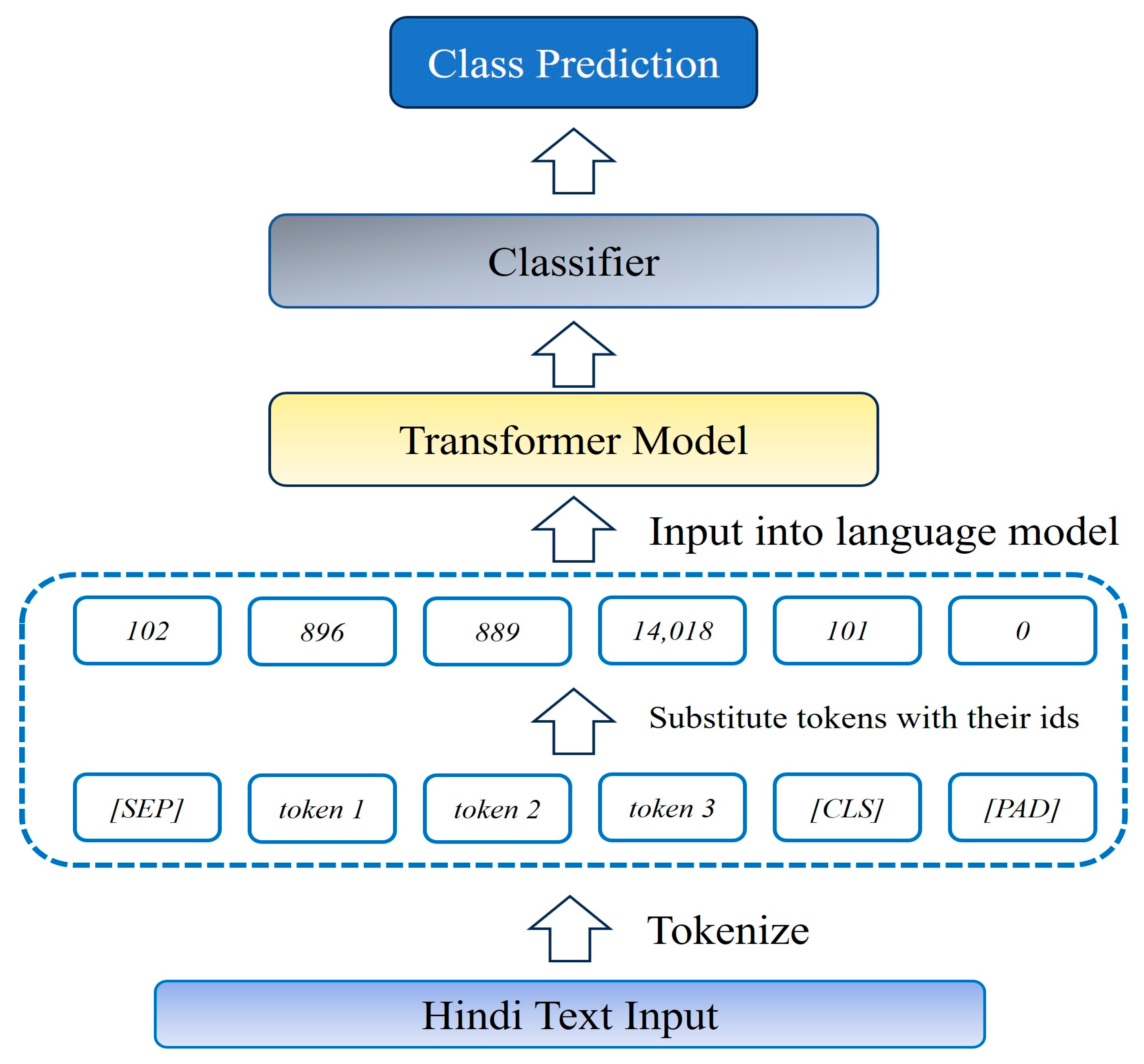
3. Materials and Methods
3.1. Problem Statement
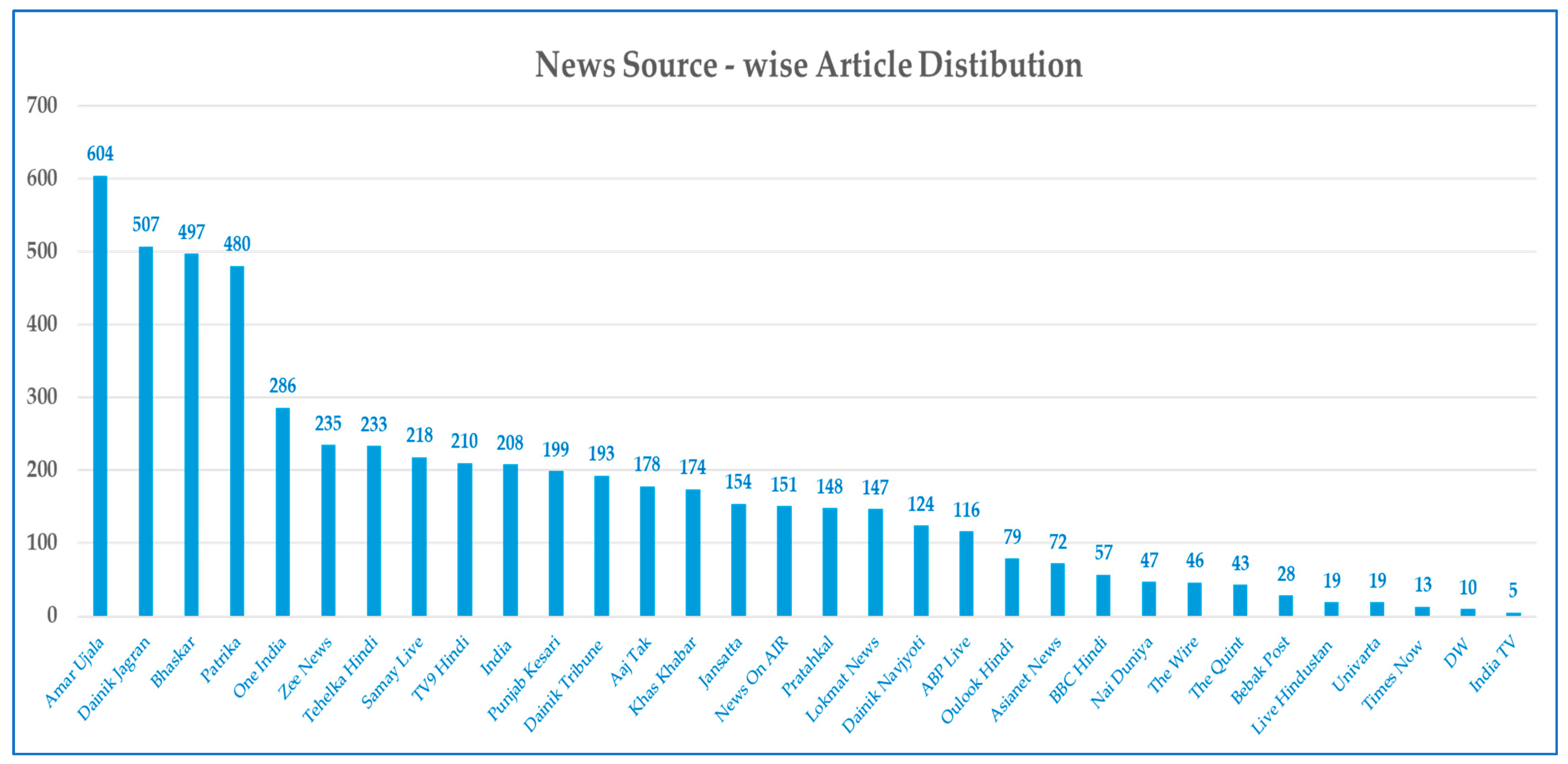
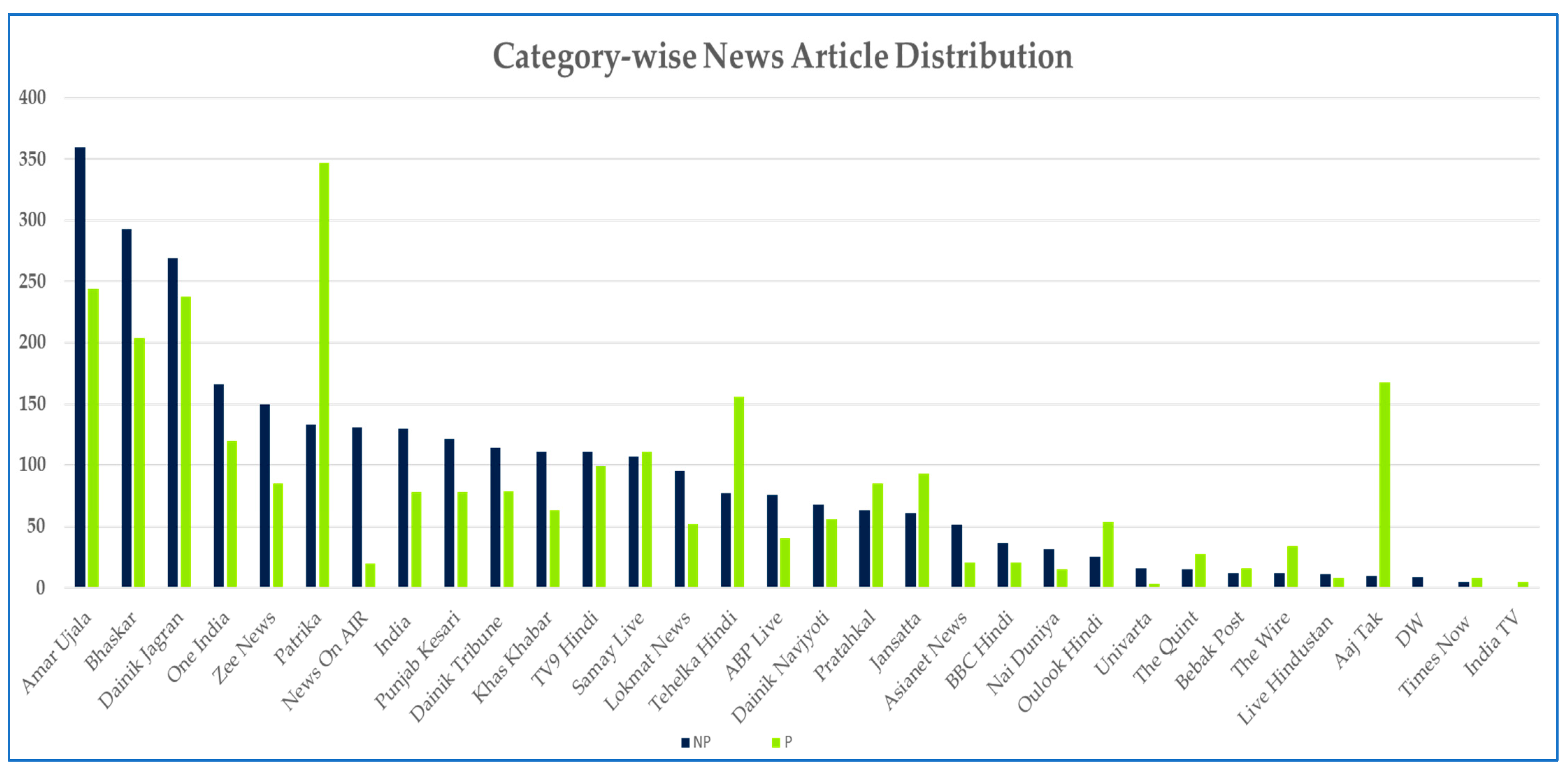
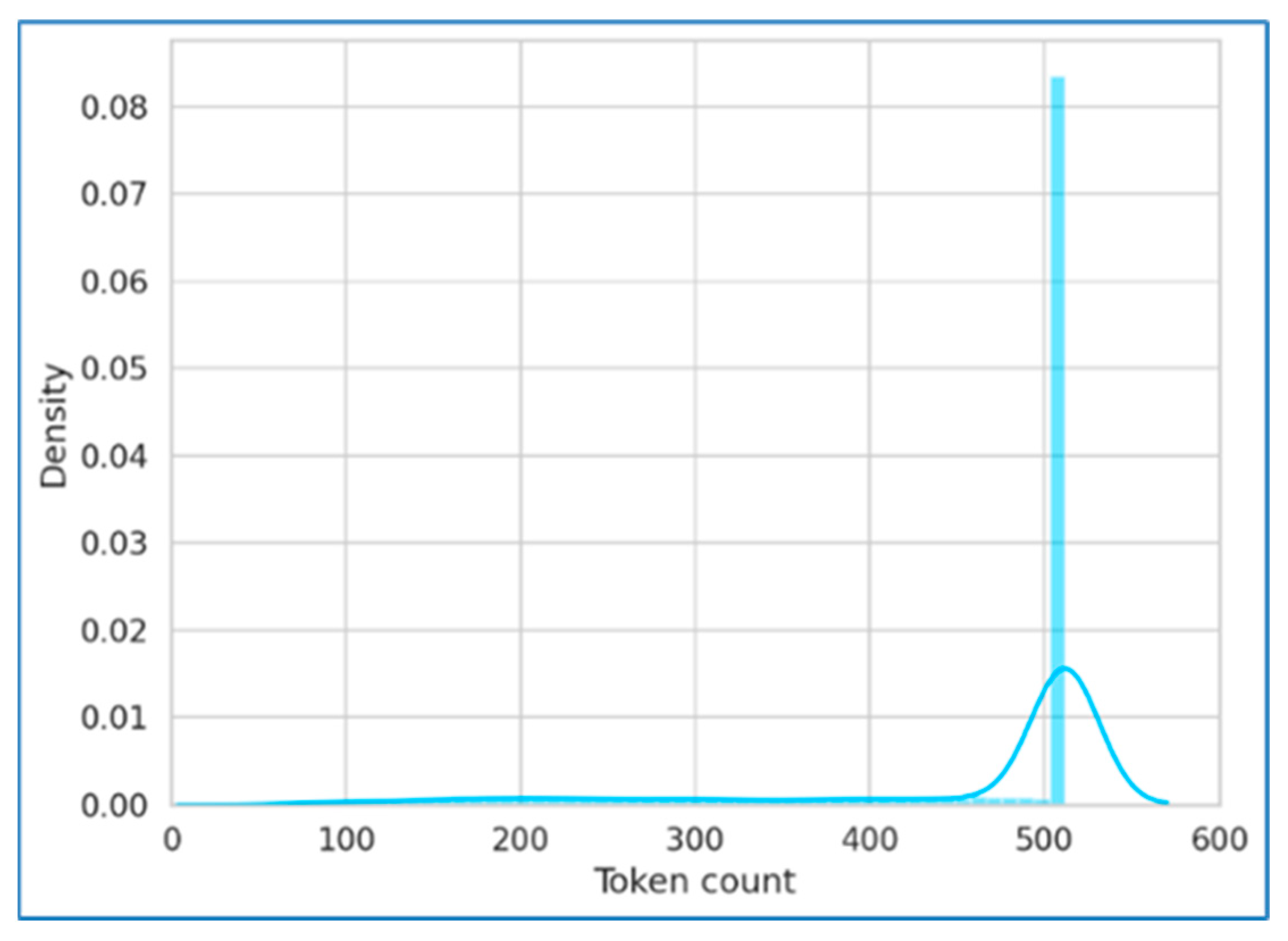
3.2. Dataset
3.3. Data Preprocessing
- URL and mentions removal: Some news articles contain URLs and tweet mentions. These were identified using regular expressions and replaced by a space. The URLs were removed using regular expression patterns like “http://” or “https://”. A simple regular expression pattern “@\w+” was used to find the mentions. This expression identifies tweet mentions by finding the strings starting with “@” followed by one or more characters.
- Stop word and non-Hindi word removal: Stop words are frequently occurring words in the text that do not hold any meaning. Some examples of Hindi stop words are “और” (and), “की” (of), “है” (is), and so on. A predefined list of Hindi stop words was used to remove the stop words from the text. Removing these words helps in reducing the noise and focusing on the content-carrying words. To remove non-Hindi words, a language detection library, langdetect, was used and the words belonging to English were removed. Additionally, all punctuation marks were removed.
- Tokenization: Tokenization was performed using the indicnlp tokenizer, which is a specialized tokenizer for Indian languages. It is tailored to handle the linguistic characteristics and requirements of languages spoken in India, which may differ from tokenizers used for languages with different linguistic structures. The “indicnlp tokenizer” tokenizes text based on punctuation boundaries. This means it breaks text into tokens wherever it finds punctuation marks like periods, commas, question marks, exclamation marks, and so on. Punctuation marks act as usual boundaries between words or subword units in Hindi. Tokenization based on punctuation boundaries is a direct approach and works well for Hindi.
3.4. Hindi Word Embedding Creation
3.5. Deep Learning Models
- Convolutional neural networks (CNNs) perform well at identifying local characteristics in text, which is useful for tasks like classifying propaganda. CNNs also have the capability to detect patterns in limited text segments and can offer computational advantages for smaller datasets and less intricate natural language processing (NLP) assignments.
- Long short-term memory (LSTM) networks are specifically built to effectively process sequential data, enabling them to capture and represent long-range dependencies within textual information. These models have the capability to handle the input sequences of varying lengths, a characteristic frequently seen in news articles. Long short-term memory (LSTM) models have demonstrated a notable ability to properly preserve context and conversation history, which is required for the propaganda classification task.
- Bidirectional long short-term memory (Bi-LSTM) models are capable of capturing contextual information from both preceding and succeeding tokens within a sequence. This characteristic is of utmost significance, as it enables a comprehensive analysis of the complete context surrounding a given word or phrase. The inclusion of contextual information can be advantageous in the task of classifying propaganda. Bi-LSTM models also have the capability to construct sentence embeddings by effectively encoding information from both forward and backward directions.
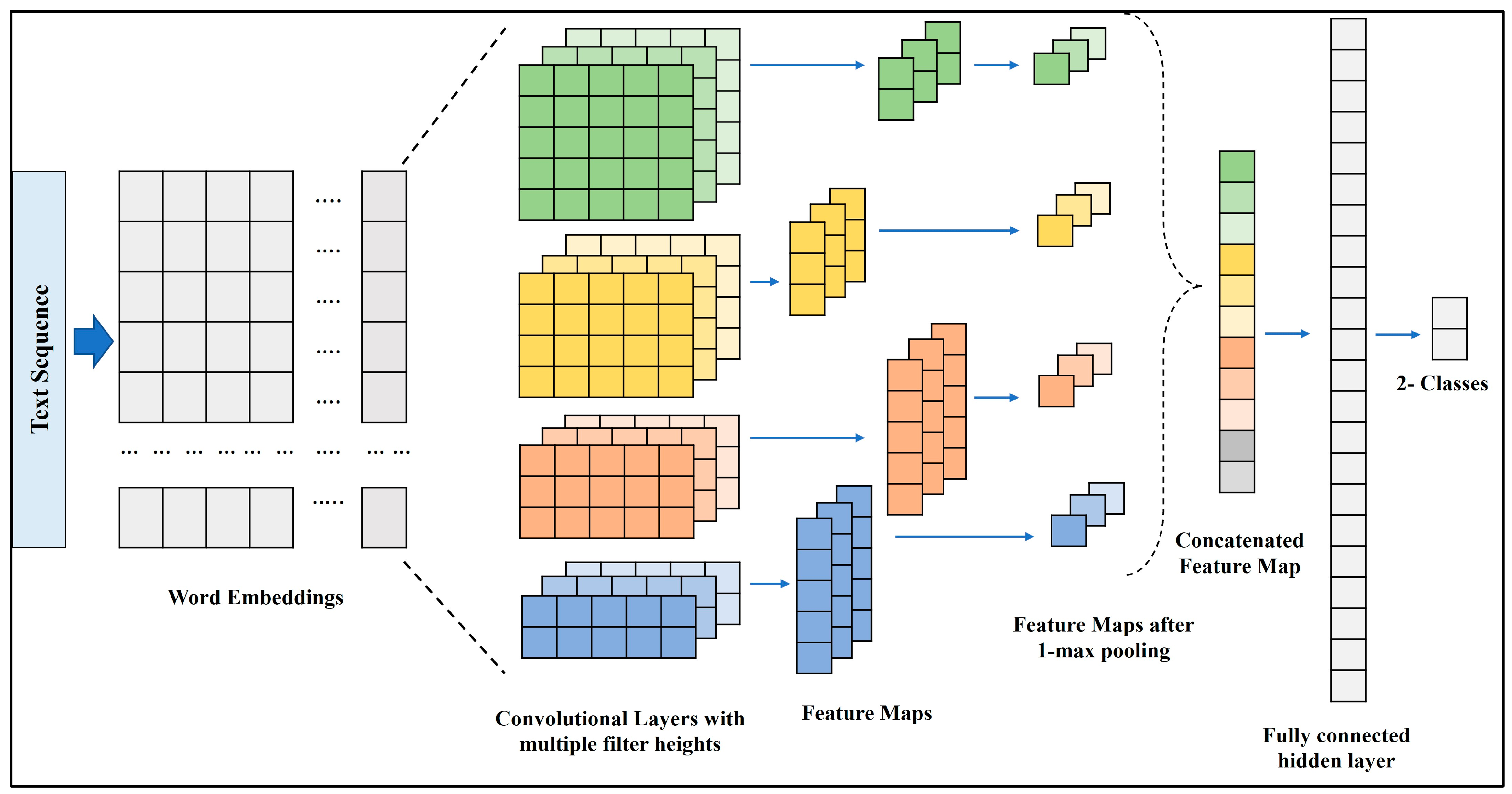
3.5.1. Convolutional Neural Network (CNN)
3.5.2. Long Short-Term Memory (LSTM)
3.5.3. Bidirectional Long Short-Term Memory (BILSTM)
3.6. Transformer-Based Models
3.6.1. Multi-Lingual Bert (Bert-Base-Multi-Lingual-Cased)
3.6.2. Distil-Multi-lingual Bert (Distilbert-Base-Multi-Lingual-Cased)
3.6.3. Hindi Bert and Hindi-Tpu-Electra
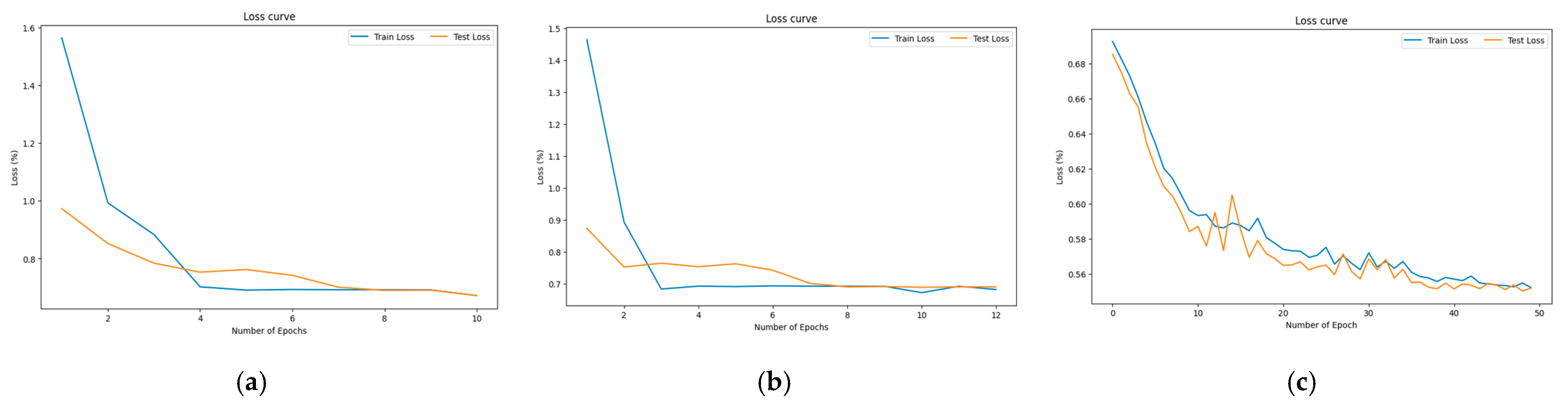
4. Experimental Settings
5. Results and Analysis
5.1. Evaluation Metrics
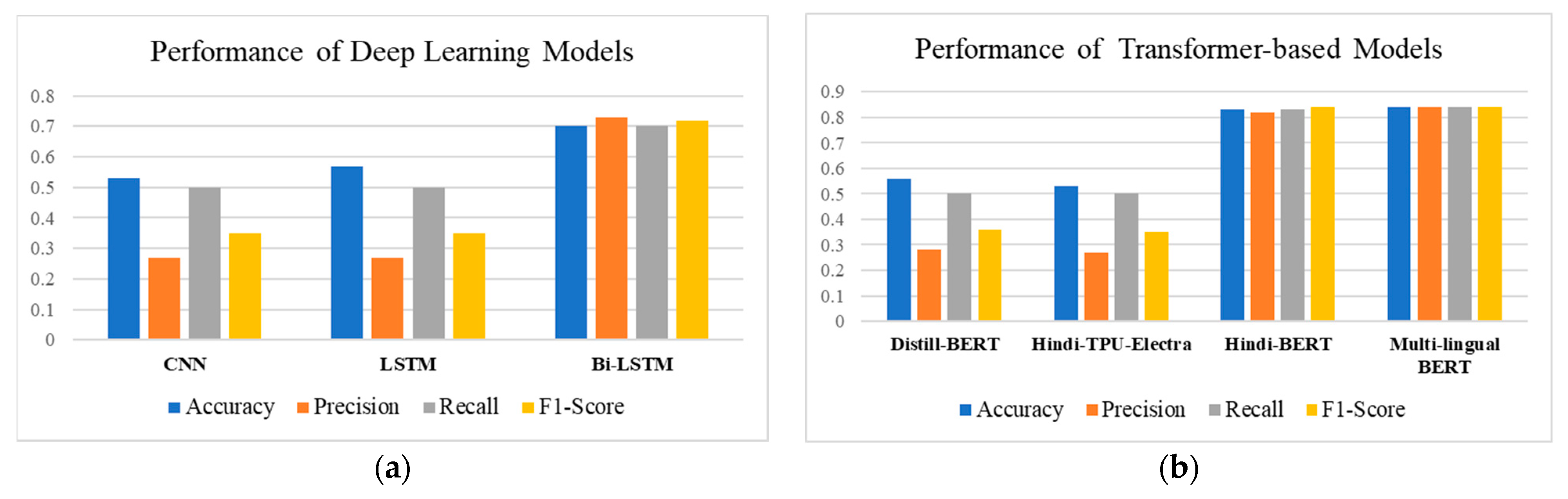
5.2. Model Performance
6. Conclusions
Limitations and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chaudhari, D.D.; Pawar, A.V. Propaganda analysis in social media: A bibliometric review. Inf. Discov. Deliv. 2021, 49, 57–70. [Google Scholar] [CrossRef]
- Kellner, A.; Rangosch, L.; Wressnegger, C.; Rieck, K. Political Elections Under (Social) Fire? Analysis and Detection of Propaganda on Twitter; Technische Universität Braunschweig: Braunschweig, Germany, 2019; pp. 1–20. Available online: http://arxiv.org/abs/1912.04143 (accessed on 22 June 2020).
- Gavrilenko, O.; Oliinyk, Y.; Khanko, H. Analysis of Propaganda Elements Detecting Algorithms in Text Data; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 938. [Google Scholar]
- Heidarysafa, M.; Kowsari, K.; Odukoya, T.; Potter, P.; Barnes, L.E.; Brown, D.E. Women in ISIS Propaganda: A Natural Language Processing Analysis of Topics and Emotions in a Comparison with Mainstream Religious Group. 2019. Available online: http://arxiv.org/abs/1912.03804 (accessed on 21 June 2020).
- Johnston, A.H.; Weiss, G.M. Identifying sunni extremist propaganda with deep learning. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence, Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Nizzoli, L.; Avvenuti, M.; Cresci, S.; Tesconi, M. Extremist propaganda tweet classification with deep learning in realistic scenarios. In Proceedings of the WebSci 2019—Proceedings of the 11th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 203–204. [Google Scholar] [CrossRef]
- Relations, E. An Analysis of Online Terrorist Recruiting and Propaganda Strategies; E International Relations: Bristol, UK, 2017; pp. 1–11. [Google Scholar]
- Ellul, J. Propaganda: The Formation Of Men’s Attitudes By Jacques Ellul. In United States: Vintage Books; Vintage: Tokyo, Japan, 1965. [Google Scholar]
- Stukal, D.; Sanovich, S.; Tucker, J.A.; Bonneau, R. For Whom the Bot Tolls: A Neural Networks Approach to Measuring Political Orientation of Twitter Bots in Russia. SAGE Open 2019, 9, 2158244019827715. [Google Scholar] [CrossRef]
- Beǧenilmiş, E.; Uskudarli, S. Supervised Learning Methods in Classifying Organized Behavior in Tweet Collections. Int. J. Artif. Intell. Tools 2019, 28, 1960001. [Google Scholar] [CrossRef]
- Ahmed, W.; Seguí, F.L.; Vidal-Alaball, J.; Katz, M.S. COVID-19 and the ‘Film Your Hospital’ conspiracy theory: Social network analysis of Twitter data. J. Med. Internet Res. 2020, 22, e22374. [Google Scholar] [CrossRef] [PubMed]
- Baisa, V.; Herman, O.; Horák, A. Benchmark dataset for propaganda detection in Czech newspaper texts. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; pp. 77–83. [Google Scholar] [CrossRef]
- Kausar, S.; Tahir, B.; Mehmood, M.A. Prosoul: A framework to identify propaganda from online urdu content. IEEE Access 2020, 8, 186039–186054. [Google Scholar] [CrossRef]
- Chaudhari, D.; Pawar, A.V.; Cedeño, A.B. H-Prop and H-Prop-News: Computational Propaganda Datasets in Hindi. Data 2022, 7, 29. [Google Scholar] [CrossRef]
- Barrón-Cedeño, A.; Jaradat, I.; Da San Martino, G.; Nakov, P. Proppy: Organizing the news based on their propagandistic content. Inf. Process. Manag. 2019, 56, 1849–1864. [Google Scholar] [CrossRef]
- da San Martino, G.; Yu, S.; Barrón-Cedeño, A.; Petrov, R.; Nakov, P. Fine-grained analysis of propaganda in news articles. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5636–5646. [Google Scholar]
- Vorakitphan, V.; Cabrio, E.; Villata, S. PROTECT—A Pipeline for Propaganda Detection and Classification To cite this version: HAL Id: Hal-03417019 A Pipeline for Propaganda Detection and Classification. In Proceedings of the CLiC-it 2021-Italian Conference on Computational Linguistics, Milan, Italy, 26–28 January 2022. [Google Scholar]
- HRashkin; Choi, E.; Jang, J.Y.; Volkova, S.; Choi, Y. Truth of varying shades: Analyzing language in fake news and political fact-checking. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2931–2937. [Google Scholar] [CrossRef]
- Salman, M.U.; Hanif, A.; Shehata, S.; Nakov, P. Detecting Propaganda Techniques in Code-Switched Social Media Text. 2023. Available online: http://arxiv.org/abs/2305.14534 (accessed on 27 September 2023).
- Solopova, V.; Popescu, O.-I.; Benzmüller, C.; Landgraf, T. Automated Multilingual Detection of Pro-Kremlin Propaganda in Newspapers and Telegram Posts. Datenbank-Spektrum 2023, 23, 5–14. [Google Scholar] [CrossRef]
- Maarouf, A.; Bär, D.; Geissler, D.; Feuerriegel, S. HQP: A Human-Annotated Dataset for Detecting Online Propaganda. No. Mcml. 2023. Available online: https://arxiv.org/abs/2304.14931v1 (accessed on 27 September 2023).
- Ahmad, P.N.; Khan, K. Propaganda Detection And Challenges Managing Smart Cities Information On Social Media. EAI Endorsed Trans. Smart Cities 2023, 7, e2. [Google Scholar] [CrossRef]
- Al-Omari, H.; Abdullah, M.; AlTiti, O.; Shaikh, S. JUSTDeep at NLP4IF 2019 Task 1: Propaganda Detection using Ensemble Deep Learning Models. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda, Hong Kong, China, 3 November 2019; pp. 113–118. [Google Scholar] [CrossRef]
- Gupta, P.; Saxena, K.; Yaseen, U.; Runkler, T.; Schütze, H. Neural Architectures for Fine-Grained Propaganda Detection in News. arXiv 2019, arXiv:1909.06162. [Google Scholar] [CrossRef]
- Hashemi, M.; Hall, M. Detecting and classifying online dark visual propaganda. Image Vis. Comput. 2019, 89, 95–105. [Google Scholar] [CrossRef]
- Cruz, A.F.; Rocha, G.; Cardoso, H.L. On Sentence Representations for Propaganda Detection: From Handcrafted Features to Word Embeddings. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda, Hong Kong, China, 3 November 2019; pp. 107–112. [Google Scholar] [CrossRef]
- Mapes, N.; White, A.; Medury, R.; Dua, S. Divisive Language and Propaganda Detection using Multi-head Attention Transformers with Deep Learning BERT-based Language Models for Binary Classification. In Proceedings of the Second Workshop on Natural Language Processing for Internet Freedom: Censorship, Disinformation, and Propaganda, Hong Kong, China, 3 November 2019; pp. 103–106. [Google Scholar] [CrossRef]
- Alhindi, T.; Pfeiffer, J.; Muresan, S. Fine-Tuned Neural Models for Propaganda Detection at the Sentence and Fragment levels. arXiv 2019, arXiv:1910.09702. [Google Scholar] [CrossRef]
- Madabushi, H.T.; Kochkina, E.; Castelle, M. Cost-Sensitive BERT for Generalisable Sentence Classification on Imbalanced Data. arXiv 2020, arXiv:2003.11563. [Google Scholar] [CrossRef]
- Firoj, P.N.A.; Mubarak, H.; Wajdi, Z.; Martino, G.D.S. Overview of the WANLP 2022 Shared Task on Propaganda Detection in Arabic. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (Wanlp), Abu Dhabi, United Arab Emirates, 7–11 December 2022; Available online: https://aclanthology.org/2022.wanlp-1.11 (accessed on 27 September 2023).
- Samir, A. NGU_CNLP at WANLP 2022 Shared Task: Propaganda Detection in Arabic. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 545–550. [Google Scholar]
- Mittal, S.; Nakov, P. IITD at WANLP 2022 Shared Task: Multilingual Multi-Granularity Network for Propaganda Detection. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (Wanlp), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 529–533. Available online: https://aclanthology.org/2022.wanlp-1.63 (accessed on 27 September 2023).
- Laskar, S.R.; Singh, R.; Khilji, A.F.U.R.; Manna, R.; Pakray, P.; Bandyopadhyay, S. CNLP-NITS-PP at WANLP 2022 Shared Task: Propaganda Detection in Arabic using Data Augmentation and AraBERT Pre-trained Model. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (Wanlp), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 541–544. Available online: https://aclanthology.org/2022.wanlp-1.65 (accessed on 27 September 2023).
- Refaee, E.A.; Ahmed, B.; Saad, M. AraBEM at WANLP 2022 Shared Task: Propaganda Detection in Arabic Tweets. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (Wanlp), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 524–528. Available online: https://aclanthology.org/2022.wanlp-1.62 (accessed on 27 September 2023).
- Attieh, J.; Hassan, F. Pythoneers at WANLP 2022 Shared Task: Monolingual AraBERT for Arabic Propaganda Detection and Span Extraction. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (Wanlp), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 534–540. Available online: https://aclanthology.org/2022.wanlp-1.64 (accessed on 27 September 2023).
- Singh, G. AraProp at WANLP 2022 Shared Task: Leveraging Pre-Trained Language Models for Arabic Propaganda Detection. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (Wanlp), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 496–500. Available online: https://aclanthology.org/2022.wanlp-1.56 (accessed on 26 September 2023).
- Taboubi, B.; Brahem, B.; Haddad, H. iCompass at WANLP 2022 Shared Task: ARBERT and MARBERT for Multilabel Propaganda Classification of Arabic Tweets. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (Wanlp), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 511–514. Available online: https://aclanthology.org/2022.wanlp-1.59 (accessed on 26 September 2023).
- van Wissen, L.; Boot, P. An Electronic Translation of the LIWC Dictionary into Dutch. In Proceedings of the eLex 2017: Lexicography from Scratch, Leiden, The Netherlands, 19–21 September 2017; pp. 703–715. Available online: https://pure.knaw.nl/portal/en/publications/an-electronic-translation-of-the-liwc-dictionary-into-dutch(de9c8272-0df1-4c92-bcb3-d789ad793603)/export.html (accessed on 22 June 2020).
- Cruz, J.C.B.; Cheng, C. Establishing Baselines for Text Classification in Low-Resource Languages. 2020. Available online: http://arxiv.org/abs/2005.02068 (accessed on 22 June 2020).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Smetanin, S.; Komarov, M. Sentiment analysis of product reviews in Russian using convolutional neural networks. In Proceedings of the Proceedings—21st IEEE Conference on Business Informatics, CBI 2019, Moscow, Russia, 15–17 July 2019; Volume 1, pp. 482–486. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MI, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. Available online: http://arxiv.org/abs/1910.01108 (accessed on 22 June 2020).
- Manning, C.D. Electra: P Re—Training T Ext E Ncoders As D Iscriminators R Ather T Han G Enerators(ICLR2020). arXiv 2020, arXiv:2003.10555. Available online: https://github.com/google-research/ (accessed on 22 June 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Models Used | Dataset | Techniques/Word Embeddings | Evaluation Parameters |
|---|---|---|---|---|
| [3] | CNN, LSTM, H-LSTM | Internet Research Agency (IRA) corpus | word2vec, GloVe | CNN + word2vec: Accuracy—0.877, F-measure—0.83 |
| [6] | CNN, RCNN | ISIS propaganda tweets | character-based CNN, RCNN with pre-trained FastText word embeddings | RCNN: F1 score −0.9 |
| [19] | Ensemble of BiLSTM, XGBoost, and BERT | Proppy corpus | Glove embedding | BERT-cased + BERT-uncased + BiLSTM + XGBoost: F1—0.67, Precision—0.62, Recall—0.73 |
| [20] | CNN, LSTM-CRF, and BERT | Proppy corpus | Linguistic, layout, and topical features | CNN, LSTM-CRF, BERT Ensemble: F1—0.62, Precision—0.57 Recall-0.6819 |
| [21] | CNN—AlexNet | Violent extremist organizations (VEOs) propaganda images collected from Twitter | Five convolutional layers and three fully connected layers | CNN AlexNet: Accuracy—97.02% F1—97.89% |
| [22] | BiLSTM, attention-based bidirectional LSTM | Proppy corpus | Dense word representations using ELMO models | ABL-Balanced-Ens: F1—59.5, Precision—50.9 Recall—71.6 |
| [23] | BERT-based attention transformer model | Proppy corpus | Attention heads and transformer blocks with a softmax layer | BERT: Precision—60.1, Recall—66.5 and F1—63.2 |
| [24] | BERT variations | Proppy corpus | BERT with logits | Precision—0.57, Recall—0.79, F1 score—0.66 |
| [25] | BERT | Propaganda techniques corpus | Cost-sensitive BERT | Precision—0.56, Recall—0.70, F1 score—0.62 |
| Source | Dataset Name | Language | Data Type | Source of Data | Classes/Labels |
|---|---|---|---|---|---|
| [18] | TSHP-17 | English | News article | English gigaword corpus and other News websites | Trusted, satire, hoax, propaganda |
| [15] | QProp Corpus | English | News article | News sources published by MBFC (media bias/fact check) | Propagandist, non-propagandist |
| [16] | Proppy | English | News article | 13 propaganda news outlets and 36 non-propaganda news outlets | 18 propaganda technique labels |
| [12] | The propaganda benchmark dataset currently | Czech | News article | 4 Czech digital news servers | 15 propaganda technique labels |
| [13] | ProSOUL | Urdu | News article | Qprop [15] translated in Urdu | Propaganda, non-propaganda |
| [13] | Humkinar-Web | Urdu | Urdu content contents from a variety of domains including news, sports, health, religion, entertainment, and books, etc. | Urdu content on the WWW | Propaganda, non-propaganda |
| [13] | Humkinar-News | Urdu | News article | News webpages from 35 manually selected propaganda-free websites | Propaganda, non-propaganda |
| [27] | Arabic Propaganda Dataset (WANLP Shared Task) | Arabic | Tweets | Tweets from top news sources in Arabic countries | 20 propaganda techniques |
| [14] | H-Prop | Hindi | News article | QProp corpus [15] translated in Hindi | Propaganda, non-propaganda |
| [14] | H-Prop-News | Hindi | News article | 32 prominent Hindi News websites | Propaganda, non-propaganda |
| Data Partition | Propaganda Articles | Non-Propaganda Articles |
|---|---|---|
| Development | 275 | 275 |
| Training | 1850 | 2000 |
| Testing | 505 | 595 |
| Total | 2630 | 2870 |
| Environment | Configuration Details | |
|---|---|---|
| Hardware | GPU | Nvidia DGX-Server with 4 Nvidia Tesla V-100 GPUs |
| CPU | Intel(R) Core(TM) i7-8565U CPU @ 1.80 GHz 1.99 GHz | |
| Memory | 20 GB | |
| Software | Operating System | Windows 10 |
| Programming Environment | Anaconda, Google Colab | |
| Libraries | TensorFlow, Keras, PyTorch, Scikit-Learn, nltk, GenSim |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| CNN | 0.53 | 0.27 | 0.50 | 0.35 |
| LSTM | 0.57 | 0.27 | 0.50 | 0.35 |
| Bi-LSTM | 0.70 | 0.73 | 0.70 | 0.72 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Multi-lingual BERT | 0.84 | 0.84 | 0.84 | 0.84 |
| Distill-BERT | 0.56 | 0.28 | 0.50 | 0.36 |
| Hindi-BERT | 0.83 | 0.82 | 0.83 | 0.84 |
| Hindi-TPU-Electra | 0.53 | 0.27 | 0.5 | 0.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaudhari, D.; Pawar, A.V. Empowering Propaganda Detection in Resource-Restraint Languages: A Transformer-Based Framework for Classifying Hindi News Articles. Big Data Cogn. Comput. 2023, 7, 175. https://doi.org/10.3390/bdcc7040175
Chaudhari D, Pawar AV. Empowering Propaganda Detection in Resource-Restraint Languages: A Transformer-Based Framework for Classifying Hindi News Articles. Big Data and Cognitive Computing. 2023; 7(4):175. https://doi.org/10.3390/bdcc7040175
Chicago/Turabian StyleChaudhari, Deptii, and Ambika Vishal Pawar. 2023. "Empowering Propaganda Detection in Resource-Restraint Languages: A Transformer-Based Framework for Classifying Hindi News Articles" Big Data and Cognitive Computing 7, no. 4: 175. https://doi.org/10.3390/bdcc7040175
APA StyleChaudhari, D., & Pawar, A. V. (2023). Empowering Propaganda Detection in Resource-Restraint Languages: A Transformer-Based Framework for Classifying Hindi News Articles. Big Data and Cognitive Computing, 7(4), 175. https://doi.org/10.3390/bdcc7040175