



Fair-CMNB: Advancing Fairness-Aware Stream Learning with Naïve Bayes and Multi-Objective Optimization



Abstract
:1. Introduction
- We challenge the deep learning dogma by presenting a novel adaptation of Naïve Bayes (Fair-CMNB: Fairness- and Class Imbalance-aware Mixed Naive Bayes) to address fairness concerns in streaming environments where computational efficiency, model interpretability, and active learning are important.
- We mitigate discrimination as well as reverse discrimination (discrimination towards the privileged group) over the stream while simultaneously improving the predictive performance through multi-objective optimization.
- Fair-CMNB is also capable of dynamically handling concept drifts and class imbalances.
- Fair-CMNB is agnostic to the employed fairness notion (including the causal fairness notion FACE [11]).
2. Related Work
2.1. Fairness-Aware Static Learning
2.1.1. Pre-Processing Techniques
2.1.2. In-Processing Techniques
2.1.3. Post-Processing Techniques
2.2. Stream Classification
2.3. Fairness-Aware Stream Learning
2.4. Class Imbalance-Aware Stream Learning
3. Preliminaries
3.1. Prequential Evaluation
3.2. Multi-Objective Optimization (MOO)
3.3. Fairness Notions
3.4. Potential Outcomes
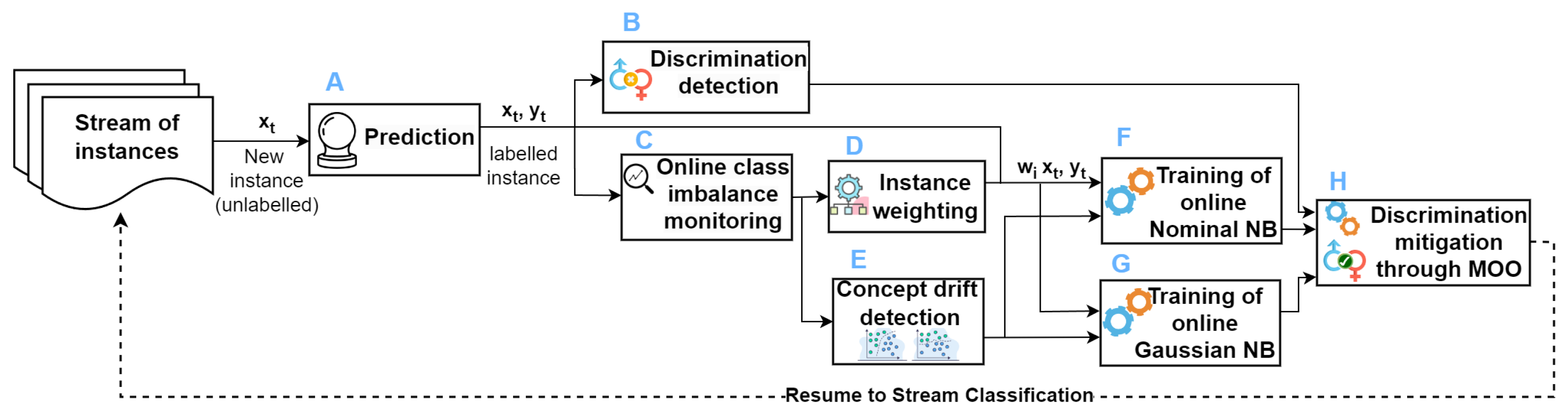
4. Proposed Model
4.1. Mixed Naïve Bayes
4.1.1. Online Nominal Naïve Bayes
4.1.2. Online Gaussian Naïve Bayes
4.2. Module for Monitoring and Handling Class Imbalance
| Algorithm 1 Computing instance weights | |
| Require: true class labels y, positive class weight , negative class weight , | |
| 1: | Initialize: current instance’s weight ; |
| 2: | if and then |
| 3: | |
| 4: | if and then |
| 5: | |
4.3. Module for Handling Concept Recurrence
4.4. Online Discrimination Detection and Mitigation
| Algorithm 2 Online discrimination mitigation procedure. | |
| Require: Summaries of the number of samples belonging to the positive class with protected value N(); the number of samples belonging to the positive class with non-protected value N(); the number of samples belonging to the negative class with protected value N(); the number of samples belonging to the negative class with non-protected value N(); discrimination score disc. | |
| Ensure: The overall number of samples does not change. | |
| 1: | if then |
| 2: | |
| 3: | |
| 4: | |
| 5: | |
| 6: | if then |
| 7: | |
| 8: | |
| 9: | |
| 10: | |
Adaptive Hyperparameter Tuning through MOO
| Algorithm 3 Multi-objective optimization procedure to actively tune . | |
| Require: Summaries of all the samples of a window | |
| Ensure: Optimized to ensure Pareto optimal trade-off between balanced accuracy and discrimination score. | |
| 1: | |
| 2: | while or trade-off improving do |
| 3: | ▹ Combine parent and child populations of |
| 4: | |
| 5: | ▹ sorted non dominated fronts of |
| 6: | |
| 7: | repeat |
| 8: | |
| 9: | |
| 10: | |
| 11: | until |
| 12: | ▹ sort in descending order according to dominance |
| 13: | |
| 14: | ▹ make new/ child population using selection, crossover, and mutation |
| 15: | |
| 16: | |
5. Complexity Analysis
5.1. Online Naïve Bayes Classifier
- Model Update: For d features and c classes, the update complexity is .
- Prediction: The prediction complexity per data point is .
5.2. NSGA-II for Hyperparameter Tuning
- Population Initialization: Time complexity for initial population setup with p individuals is .
- Fitness Evaluation: For p individuals, with E as the evaluation time, the complexity is .
- Non-dominated Sorting and Selection: The sorting process complexity is .
- Genetic Operators: The complexity of crossover and mutation operations is .
5.3. Page-Hinkley for Concept Drift Detection
- Drift Detection: The complexity for each incoming data point is .
5.4. Overall Computational Complexity
- Online Naïve Bayes: Update and Prediction complexity is .
- NSGA-II Operations: Dominated by the fitness evaluation, it is , primarily .
- Page-Hinkley Drift Detection: Overall complexity is .
6. Evaluation Setup
6.1. Benchmark Baselines
- CSMOTE [40]: This baseline is not fairness-aware, but it is designed to handle class imbalance in a non-stationary environment by re-sampling the minority class in a defined window of instances.
- OSBoost [28]: This is a classification model for data streams. It is not capable of handling either class imbalance or discrimination.
- Massaging (MS) [34]: This is a fairness-aware learning method. It is a chunk-based technique which handles discrimination in the current chunk by swapping labels. But it does not account for cumulative effects of discrimination; it is designed to handle discrimination only on a short-term basis, i.e., for the current chunk. We use the default chunk size for training this baseline, i.e., 1000, as proposed by [34]. This method cannot handle class imbalance.
- Fairness-Aware Hoeffding Tree (FAHT) [35]: This method is an adaptation of Hoeffding tree that is designed to deal with discrimination. It incorporates the fairness gain along with the information gain into the partitioning criteria of the decision tree. This model is not able to deal with class imbalance and concept drifts.
- FABBOO [1]: This is an online boosting approach that handles class imbalance by monitoring class ratios in an online fashion. It employs boundary adjustment methods to handle discrimination.
- MNB (Mixed Naïve Bayes): This is a combination of online nominal Naïve Bayes and online Gaussian Naïve Bayes. It considers no notion of fairness and class imbalance while performing classification tasks.
- Fair-CMNB (Discrimination- and Class Imbalance-Aware Mixed Naïve Bayes): This is a variant of MNB which mitigates discrimination (utilizing MOO) as well as handles class imbalance and concept drifts in the evolving stream.
6.2. Benchmark Datasets
6.3. Evaluation Metrics
7. Results and Discussion
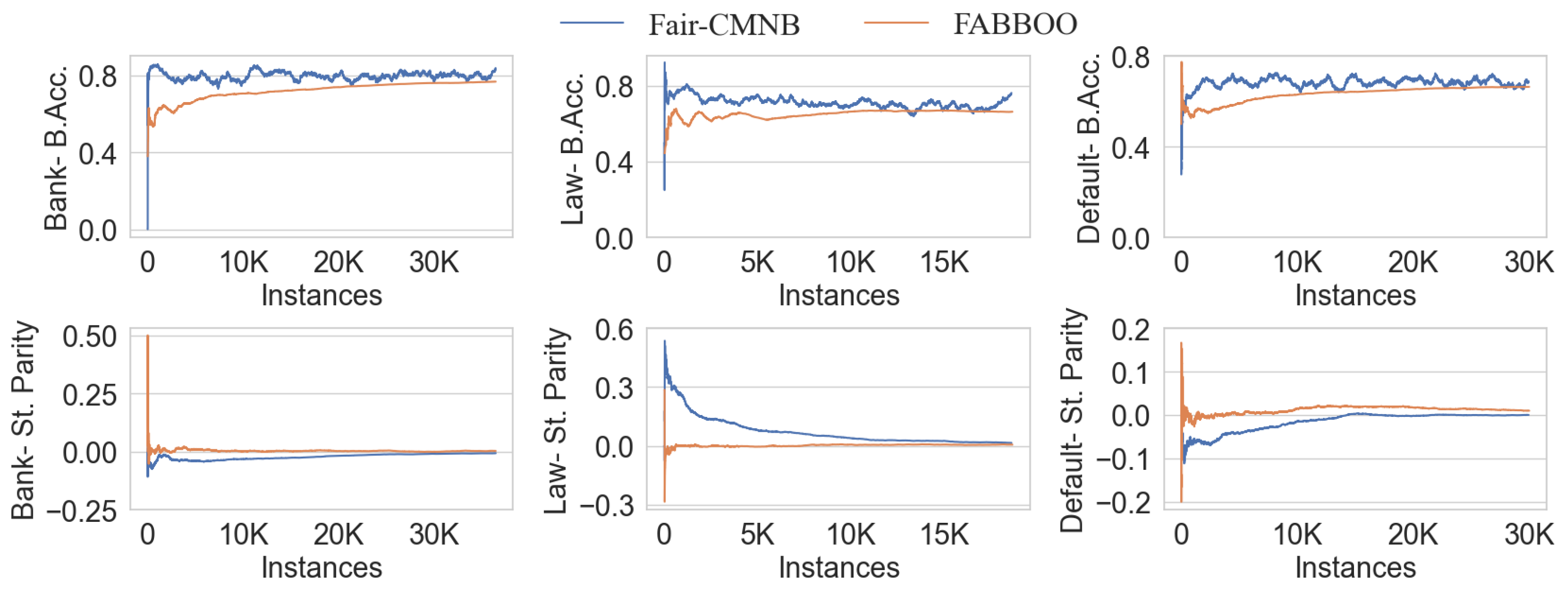
7.1. Comparison with Baselines
7.2. Scalability
7.3. Agnosticism to Fairness Notions
7.4. Impact Assessment of Naïve Bayes Modules
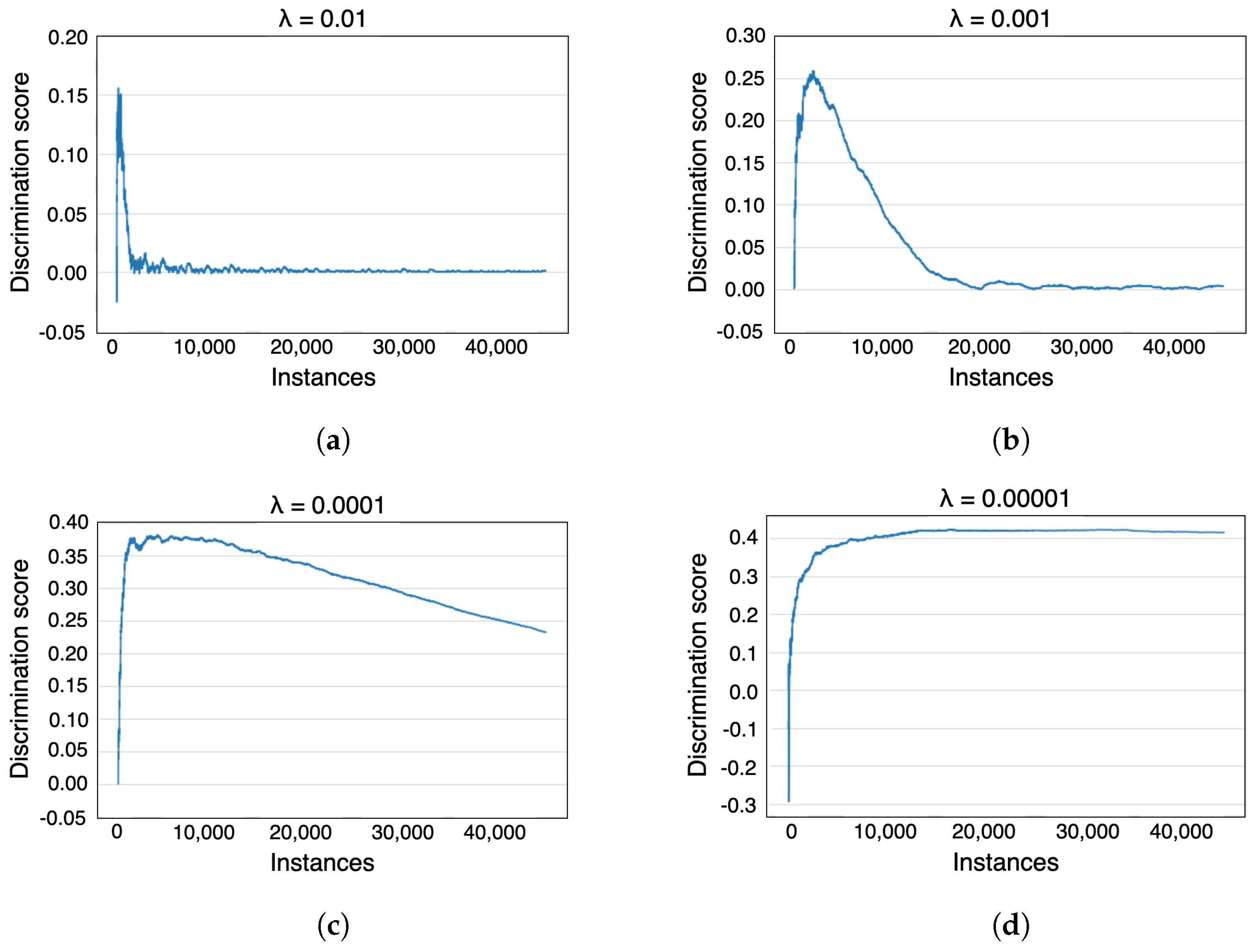
7.5. Hyperparameter Sensitivity
7.6. Deep Learning vs. Naïve Bayes
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Iosifidis, V.; Ntoutsi, E. FABBOO-Online Fairness-Aware Learning Under Class Imbalance. In Proceedings of the International Conference on Discovery Science, Thessaloniki, Greece, 19–21 October 2020; Springer: Cham, Switzerland, 2020; pp. 159–174. [Google Scholar]
- Iosifidis, V.; Ntoutsi, E. Dealing with Bias via Data Augmentation in Supervised Learning Scenarios; Bates, J., Clough, P.D., Jäschke, R., Eds.; BibSonomy: Kassel, Germany, 2018; pp. 24–29. [Google Scholar]
- Aghaei, S.; Azizi, M.J.; Vayanos, P. Learning optimal and fair decision trees for non-discriminative decision-making. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1418–1426. [Google Scholar]
- Kamiran, F.; Calders, T. Classifying without discriminating. In Proceedings of the Computer, Control and Communication, 2009, IC4 2009, 2nd International Conference, Karachi, Pakistan, 17–18 February 2009; pp. 1–6. [Google Scholar]
- Kamiran, F.; Calders, T.; Pechenizkiy, M. Discrimination aware decision tree learning. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, NSW, Australia, 13–17 December 2010; pp. 869–874. [Google Scholar]
- Zafar, M.B.; Valera, I.; Gomez-Rodriguez, M.; Gummadi, K.P. Fairness constraints: A flexible approach for fair classification. J. Mach. Learn. Res. 2019, 20, 2737–2778. [Google Scholar]
- Liu, A.; Song, Y.; Zhang, G.; Lu, J. Regional concept drift detection and density synchronized drift adaptation. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Lelie, F.; Crul, M.; Schneider, J. The European Second Generation Compared: Does the Integration Context Matter; Amsterdam University Press: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Wang, X.; Zhao, Y.; Pourpanah, F. Recent advances in deep learning. Int. J. Mach. Learn. Cybern. 2020, 11, 747–750. [Google Scholar] [CrossRef]
- Xhemali, D.; Hinde, C.J.; Stone, R. Naïve bayes vs. decision trees vs. neural networks in the classification of training web pages. IJCSI Int. J. Comput. Sci. Issues 2009, 4, 16–23. [Google Scholar]
- Khademi, A.; Lee, S.; Foley, D.; Honavar, V. Fairness in algorithmic decision making: An excursion through the lens of causality. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2907–2914. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Calders, T.; Kamiran, F.; Pechenizkiy, M. Building classifiers with independency constraints. In Proceedings of the IEEE International Conference on Data Mining Workshops, Miami, FL, USA, 6 December 2009; pp. 13–18. [Google Scholar]
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2012, 33, 1–33. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, Y.; Wu, X. Achieving Non-Discrimination in Prediction. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3097–3103. [Google Scholar]
- Petrović, A.; Nikolić, M.; Radovanović, S.; Delibašić, B.; Jovanović, M. FAIR: Fair adversarial instance re-weighting. Neurocomputing 2022, 476, 14–37. [Google Scholar] [CrossRef]
- Shekhar, S.; Fields, G.; Ghavamzadeh, M.; Javidi, T. Adaptive sampling for minimax fair classification. Adv. Neural Inf. Process. Syst. 2021, 34, 24535–24544. [Google Scholar]
- Padala, M.; Gujar, S. FNNC: Achieving fairness through neural networks. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Iosifidis, V.; Ntoutsi, E. Adafair: Cumulative fairness adaptive boosting. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 781–790. [Google Scholar]
- Blanzeisky, W.; Cunningham, P. Using Pareto simulated annealing to address algorithmic bias in machine learning. Knowl. Eng. Rev. 2022, 37, e5. [Google Scholar] [CrossRef]
- Calders, T.; Verwer, S. Three naive bayes approaches for discrimination-free classification. Data Min. Knowl. Discov. 2010, 21, 277–292. [Google Scholar] [CrossRef]
- Hajian, S.; Domingo-Ferrer, J.; Monreale, A.; Pedreschi, D.; Giannotti, F. Discrimination-and privacy-aware patterns. Data Min. Knowl. Discov. 2015, 29, 1733–1782. [Google Scholar] [CrossRef]
- Fish, B.; Kun, J.; Lelkes, Á.D. A confidence-based approach for balancing fairness and accuracy. In Proceedings of the SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; pp. 144–152. [Google Scholar]
- Nguyen, D.; Gupta, S.; Rana, S.; Shilton, A.; Venkatesh, S. Fairness improvement for black-box classifiers with Gaussian process. Inf. Sci. 2021, 576, 542–556. [Google Scholar] [CrossRef]
- Chiappa, S. Path-specific counterfactual fairness. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7801–7808. [Google Scholar]
- Masud, M.M.; Woolam, C.; Gao, J.; Khan, L.; Han, J.; Hamlen, K.W.; Oza, N.C. Facing the reality of data stream classification: Coping with scarcity of labeled data. Knowl. Inf. Syst. 2012, 33, 213–244. [Google Scholar] [CrossRef]
- Bifet, A.; Pfahringer, B.; Read, J.; Holmes, G. Efficient data stream classification via probabilistic adaptive windows. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 801–806. [Google Scholar]
- Chen, S.T.; Lin, H.T.; Lu, C.J. An online boosting algorithm with theoretical justifications. arXiv 2012, arXiv:1206.6422. [Google Scholar]
- Yu, H.; Zhang, Q.; Liu, T.; Lu, J.; Wen, Y.; Zhang, G. Meta-ADD: A meta-learning based pre-trained model for concept drift active detection. Inf. Sci. 2022, 608, 996–1009. [Google Scholar] [CrossRef]
- Nguyen, T.T.T.; Nguyen, T.T.; Sharma, R.; Liew, A.W.C. A lossless online Bayesian classifier. Inf. Sci. 2019, 489, 1–17. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, Z.; Li, C. Online semi-supervised support vector machine. Inf. Sci. 2018, 439–440, 125–141. [Google Scholar] [CrossRef]
- Abbasi, A.; Javed, A.R.; Chakraborty, C.; Nebhen, J.; Zehra, W.; Jalil, Z. ElStream: An Ensemble Learning Approach for Concept Drift Detection in Dynamic Social Big Data Stream Learning. IEEE Access 2021, 9, 66408–66419. [Google Scholar] [CrossRef]
- Paulraj, D.; Prem M, V. A Novel Ensemble Classifier Framework to Preprocess, Learn and Predict Imbalanced Heterogeneous Drifted Data Stream. In Proceedings of the 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Erode, India, 5–7 April 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Iosifidis, V.; Tran, T.N.H.; Ntoutsi, E. Fairness-enhancing interventions in stream classification. In Proceedings of the International Conference on Database and Expert Systems Applications, Linz, Austria, 26–29 August 2019; Springer: Cham, Switzerland, 2019; pp. 261–276. [Google Scholar]
- Zhang, W.; Ntoutsi, E. FAHT: An Adaptive Fairness-aware Decision Tree Classifier. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1480–1486. [Google Scholar]
- Badar, M.; Nejdl, W.; Fisichella, M. FAC-fed: Federated adaptation for fairness and concept drift aware stream classification. Mach. Learn. 2023, 112, 2761–2786. [Google Scholar] [CrossRef]
- Pham, D.; Tran, B.; Nguyen, S.; Alahakoon, D. Fairness Aware Swarm-based Machine Learning for Data Streams. In Proceedings of the AI 2022: Advances in Artificial Intelligence, Perth, WA, Australia, 5–8 December 2022; pp. 205–219. [Google Scholar]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Wang, B.; Pineau, J. Online bagging and boosting for imbalanced data streams. IEEE Trans. Knowl. Data Eng. 2016, 28, 3353–3366. [Google Scholar] [CrossRef]
- Bernardo, A.; Gomes, H.M.; Montiel, J.; Pfahringer, B.; Bifet, A.; Della Valle, E. C-SMOTE: Continuous Synthetic Minority Oversampling for Evolving Data Streams. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 483–492. [Google Scholar]
- Younis, R.; Fisichella, M. FLY-SMOTE: Re-balancing the non-IID iot edge devices data in federated learning system. IEEE Access 2022, 10, 65092–65102. [Google Scholar] [CrossRef]
- Gama, J. Knowledge Discovery from Data Streams; Chapman and Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Gama, J.; Sebastiao, R.; Rodrigues, P.P. On evaluating stream learning algorithms. Mach. Learn. 2013, 90, 317–346. [Google Scholar] [CrossRef]
- Verma, S.; Rubin, J. Fairness definitions explained. In Proceedings of the 2018 IEEE/ACM International Workshop on Software Fairness (Fairware), Gothenburg, Sweden, 29 May 2018; pp. 1–7. [Google Scholar]
- Makhlouf, K.; Zhioua, S.; Palamidessi, C. Survey on causal-based machine learning fairness notions. arXiv 2020, arXiv:2010.09553. [Google Scholar]
- Stuart, E.A. Matching methods for causal inference: A review and a look forward. Stat. Sci. Rev. J. Inst. Math. Stat. 2010, 25, 1. [Google Scholar] [CrossRef]
- Welford, B. Note on a method for calculating corrected sums of squares and products. Technometrics 1962, 4, 419–420. [Google Scholar] [CrossRef]
- Wang, S.; Minku, L.L.; Yao, X. A learning framework for online class imbalance learning. In Proceedings of the 2013 IEEE Symposium on Computational Intelligence and Ensemble Learning (CIEL), Singapore, 16–19 April 2013; pp. 36–45. [Google Scholar]
- Serakiotou, N. Change detection. 1987. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Bache, K.; Lichman, M. UCI Machine Learning Repository; University of California: Irvine, CA, USA, 2013. [Google Scholar]
- Larson, J.; Mattu, S.; Kirchner, L.; Angwin, J. How we analyzed the COMPAS recidivism algorithm. ProPublica 2016, 9, 3. [Google Scholar]
- Wightman, L.F. LSAC National Longitudinal Bar Passage Study; LSAC Research Report Series; ERIC. 1998. Available online: https://racism.org/images/pdf/LawSchool/Admission/NLBPS.pdf (accessed on 9 August 2023).
- Chapman, D.; Panchadsaram, R.; Farmer, J.P.; Introducing alpha.data.gov. Office of Science and Technology Policy. 2013. Available online: https://obamawhitehouse.archives.gov/blog/2013/01/28/introducing-alphadatagov (accessed on 9 August 2023).
- Cortez, V. Preventing Discriminatory Outcomes in Credit Models. 2019. Available online: https://github.com/valeria-io/bias-in-credit-models (accessed on 9 August 2023).
- Sahoo, D.; Pham, Q.; Lu, J.; Hoi, S.C.H. Online Deep Learning: Learning Deep Neural Networks on the Fly. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2660–2666. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | #Inst. | #Att. | Sens. Att. | Class Imb. | Positive Class | Type |
|---|---|---|---|---|---|---|
| Adult Census [51] | 45,175 | 14 | Gender | 1:3.0 | >50 K | Static |
| Compas [52] | 5278 | 9 | Race | 1:1.1 | recidivism | Static |
| KDD [51] | 299,285 | 41 | Gender | 1:15.1 | >50 K | Static |
| Default [51] | 30,000 | 24 | Gender | 1:3.52 | default payment | Static |
| Law School [53] | 18,692 | 12 | Gender | 1:3.5 | pass bar | Static |
| NYPD [54] | 311,367 | 16 | Gender | 1:3.7 | felony | Stream |
| Loan [55] | 21,443 | 38 | Gender | 1:1.26 | paid | Stream |
| Bank Marketing [51] | 41,188 | 21 | Marital Status | 1:7.87 | subscription | Stream |
| Dataset | Model | Recall (%) | B.Acc. (%) | Gmean (%) | St. Parity (%) |
|---|---|---|---|---|---|
| NYPD | CSMOTE | 98.01 | 58.19 | 42.43 | 4.82 |
| OSBoost | 98.87 | 52.20 | 23.38 | −0.60 | |
| MS | 19.17 | 58.94 | 43.50 | 6.39 | |
| FAHT | 0.45 | 49.01 | 6.62 | 0.06 | |
| FABBOO | 48.73 | 64.15 | 71.44 | 0.03 | |
| Fair-CMNB | 86.78 | 81.25 | 81.06 | 0.019 | |
| Bank Marketing | CSMOTE | 85.91 | 83.21 | 83.16 | 7.34 |
| OSBoost | 37.65 | 68.55 | 61.19 | 2.93 | |
| MS | 35.29 | 66.43 | 58.67 | 6.68 | |
| FAHT | 38.15 | 67.95 | 61.06 | 2.07 | |
| FABBOO | 57.03 | 76.16 | 73.71 | 1.02 | |
| Fair-CMNB | 82.91 | 82.06 | 82.05 | −0.033 | |
| Loan | CSMOTE | 75.57 | 71.64 | 71.53 | 2.88 |
| OSBoost | 78.61 | 69.61 | 69.02 | 4.72 | |
| MS | 69.00 | 68.53 | 68.52 | 50.83 | |
| FAHT | 69.41 | 68.01 | 67.99 | 0.12 | |
| FABBOO | 75.60 | 69.67 | 69.41 | 0.75 | |
| Fair-CMNB | 86.25 | 80.37 | 79.87 | 0.065 |
| Dataset | Model | Recall (%) | B.Acc. (%) | Gmean (%) | St. Parity (%) |
|---|---|---|---|---|---|
| Adult Census | CSMOTE | 81.92 | 79.73 | 79.69 | 29.88 |
| OSBoost | 56.06 | 73.85 | 71.67 | 19.19 | |
| MS | 51.98 | 74.32 | 70.88 | 23.54 | |
| FAHT | 51.36 | 75.23 | 71.34 | 16.18 | |
| FABBOO | 66.26 | 75.90 | 75.28 | 0.25 | |
| Fair-CMNB | 84.56 | 81.24 | 81.17 | 0.0227 | |
| KDD | CSMOTE | 65.17 | 76.77 | 75.88 | 9.36 |
| OSBoost | 33.61 | 66.35 | 57.71 | 5.15 | |
| MS | 27.88 | 63.44 | 52.53 | 15.80 | |
| FAHT | 29.65 | 63.92 | 53.95 | 2.44 | |
| FABBOO | 78.39 | 81.97 | 81.89 | 0.17 | |
| Fair-CMNB | 88.01 | 84.11 | 82.13 | 0.026 | |
| Compas | CSMOTE | 66.12 | 67.05 | 67.04 | 20.19 |
| OSBoost | 61.09 | 67.11 | 66.83 | 25.99 | |
| MS | 60.26 | 65.38 | 65.17 | 45.02 | |
| FAHT | 62.25 | 65.21 | 66.69 | 21.43 | |
| FABBOO | 65.06 | 65.15 | 65.14 | 1.03 | |
| Fair-CMNB | 70.40 | 71.71 | 71.69 | 0.776 | |
| Default | CSMOTE | 81.69 | 60.80 | 57.09 | 3.21 |
| OSBoost | 32.88 | 64.09 | 55.97 | 1.97 | |
| MS | 32.27 | 63.97 | 55.56 | 10.28 | |
| FAHT | 31.92 | 64.93 | 55.91 | 1.62 | |
| FABBOO | 43.19 | 66.14 | 62.03 | 0.79 | |
| Fair-CMNB | 62.23 | 69.63 | 69.23 | 0.012 | |
| Law School | CSMOTE | 76.01 | 75.27 | 74.53 | 1.43 |
| OSBoost | 18.96 | 59.12 | 43.38 | 1.29 | |
| MS | 19.07 | 58.87 | 43.38 | 3.23 | |
| FAHT | 14.49 | 55.61 | 37.43 | 0.76 | |
| FABBOO | 40.48 | 69.21 | 62.97 | 0.27 | |
| Fair-CMNB | 74.25 | 81.27 | 80.97 | 0.012 |
| Dataset | Recall (%) | B.Acc. (%) | Gmean (%) | FACE (%) |
|---|---|---|---|---|
| Adult Census | 85.55 | 80.56 | 80.41 | 0.488 |
| KDD | 86.96 | 82.61 | 82.50 | −0.104 |
| Compas | 77.94 | 70.53 | 70.13 | 0.346 |
| Default | 63.39 | 69.23 | 68.98 | −0.131 |
| Law School | 71.84 | 77.77 | 77.54 | −0.028 |
| NYPD | 76.85 | 78.34 | 78.33 | 0.066 |
| Bank Marketing | 79.95 | 80.63 | 80.61 | 0.929 |
| Loan | 93.95 | 87.59 | 87.35 | 0.812 |
| Dataset | Model | Recall (%) | B.Acc. (%) | Gmean (%) | St. Parity (%) |
|---|---|---|---|---|---|
| Adult Census | MNB | 78.15 | 79.79 | 79.77 | 29.17 |
| Fair-CMNB | 84.56 | 81.24 | 81.17 | 0.0227 | |
| KDD | MNB | 78.03 | 82.17 | 82.06 | 14.35 |
| Fair-CMNB | 88.01 | 84.11 | 82.13 | 0.026 | |
| Compas | MNB | 67.85 | 68.96 | 68.95 | 27.28 |
| Fair-CMNB | 70.40 | 71.71 | 71.69 | 0.776 | |
| Default | MNB | 52.04 | 68.46 | 66.46 | 2.65 |
| Fair-CMNB | 62.23 | 69.63 | 69.23 | 0.012 | |
| Law School | MNB | 86.51 | 76.13 | 75.41 | 49.64 |
| Fair-CMNB | 74.25 | 81.27 | 80.97 | 0.012 | |
| NYPD | MNB | 71.76 | 76.43 | 76.28 | 19.85 |
| Fair-CMNB | 86.78 | 81.25 | 81.06 | 0.019 | |
| Bank Marketing | MNB | 71.31 | 79.51 | 79.08 | 2.71 |
| Fair-CMNB | 82.91 | 82.06 | 82.05 | −0.033 | |
| Loan | MNB | 82.00 | 77.35 | 77.2 | 14.73 |
| Fair-CMNB | 89.25 | 80.37 | 79.87 | 0.065 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Badar, M.; Fisichella, M. Fair-CMNB: Advancing Fairness-Aware Stream Learning with Naïve Bayes and Multi-Objective Optimization. Big Data Cogn. Comput. 2024, 8, 16. https://doi.org/10.3390/bdcc8020016
Badar M, Fisichella M. Fair-CMNB: Advancing Fairness-Aware Stream Learning with Naïve Bayes and Multi-Objective Optimization. Big Data and Cognitive Computing. 2024; 8(2):16. https://doi.org/10.3390/bdcc8020016
Chicago/Turabian StyleBadar, Maryam, and Marco Fisichella. 2024. "Fair-CMNB: Advancing Fairness-Aware Stream Learning with Naïve Bayes and Multi-Objective Optimization" Big Data and Cognitive Computing 8, no. 2: 16. https://doi.org/10.3390/bdcc8020016
APA StyleBadar, M., & Fisichella, M. (2024). Fair-CMNB: Advancing Fairness-Aware Stream Learning with Naïve Bayes and Multi-Objective Optimization. Big Data and Cognitive Computing, 8(2), 16. https://doi.org/10.3390/bdcc8020016