


Advanced Mathematical Approaches in Psycholinguistic Data Analysis: A Methodological Insight



Abstract
:1. Introduction and Motivation
- Complexity and non-linearity: Utilizing fractile regression allows us to address the significant asymmetries (skewness) present in the distributions of our data and to embrace their inherent non-linear characteristics [2,6]. This alignment with the complexities is in tune with the FF philosophy of interpreting non-linear patterns [8,9].
- Data distribution insights: The concept of fractile defines specific points on a probability density curve, which in turn divides the curve based on established proportions. A case in point is the median or the 50th percentile, serving as a fractile and splitting data into two balanced portions. This intricate view of data distribution is consistent with the FF emphasis on detailed and recurrent patterns.
- Bootstrapping and permutation tests: Through bootstrapping, we create multiple samples from our original dataset, bolstering the reliability of our findings. Concurrently, permutation tests provide an avenue to assess our data devoid of rigid assumptions, directly tackling their complexities. This painstaking and iterative examination echoes FF methods and prioritizes a holistic understanding of the data.
- Real-world application: Our methodology extends beyond the realm of theory. It offers tangible insights for linguistic research, showcasing the pivotal role of fractile regression and resampling methods in decoding real-world linguistic patterns. Such an application accentuates the relevance of these methods in revealing nuanced patterns, aligning with the FF principles [2,6,8,9].
2. Methodologies
2.1. Fractile Regression
- (i)
- It describes the complete conditional distribution of a dependent (response) variable given the covariates.
- (ii)
- It offers robust estimated coefficients that are non-sensitive to outliers on the dependent variable.
- (iii)
- It generates more efficient estimators than those from ordinary least squares when the error term is non-normally distributed.
- (iv)
- It facilitates the interpretation of different solutions at different fractiles as variations in the response of the dependent variable to changes in the covariates at various points in its conditional distribution.
- (v)
- It allows easy representation of regression coefficient estimation via linear mathematical programming.
- (I)
- Definition based on the conditional fractile function:
- (II)
- Definition based on the fractile regression model [29]:
- (III)
- Definition based on a check function [14]:
- (IV)
- Definition based on the asymmetric Laplace density function [30]:
2.2. Permutation Tests
2.3. Bootstrap Method
| Algorithm 1 Bootstrap procedure |
Input: Original dataset Input: Statistic of interest Input: Number of bootstrap samples B (commonly ) for to B do Draw a sample of size n from X with replacement Compute the statistic for the bootstrap sample Add to the bootstrap distribution end for Output: Bootstrap distribution of T, used for estimating standard errors, constructing confidence intervals, or performing hypothesis tests Output: Statistical inference using the bootstrap distribution of T |
3. Case Study
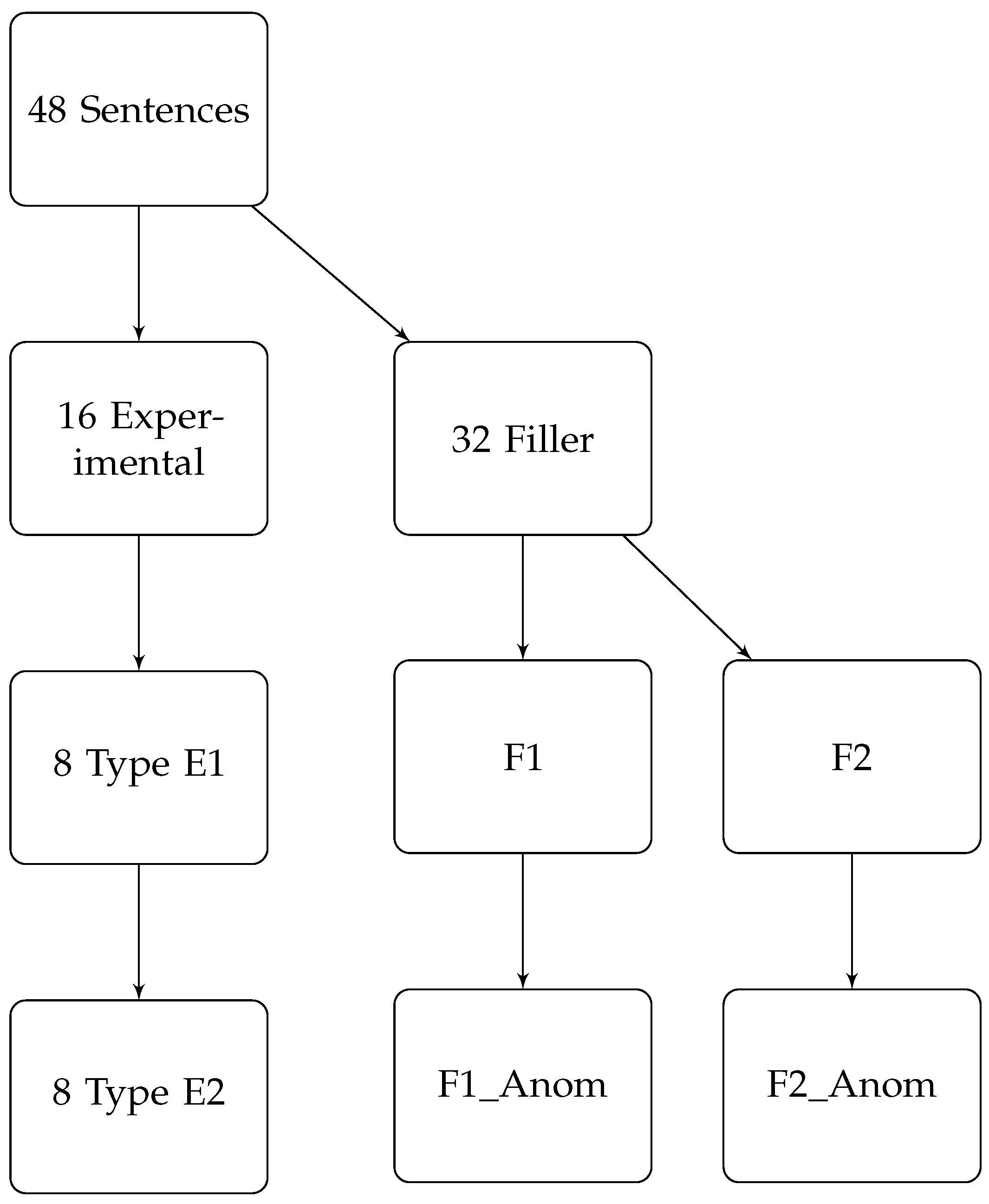
3.1. Experimental Design
- Participant ratings on the Likert scale.
- Any alterations to the initial responses.
- Frequency of response alterations.
- Time taken to read the sentence or other stimuli (as an image, for example).
- Time spent marking responses.
- Time to submit responses before moving to the next sentence.
3.2. Statistical Model and Considerations
3.3. Results and Discussion
- (i)
- Bootstrap confidence intervals for the mean and median of time to respond (TTR) for each list (List), each condition (Condition), and each plausibility rate (Plaus).
- (ii)
- A test between TTR and time to submit (TTS), based on interaction with List.
- (iii)
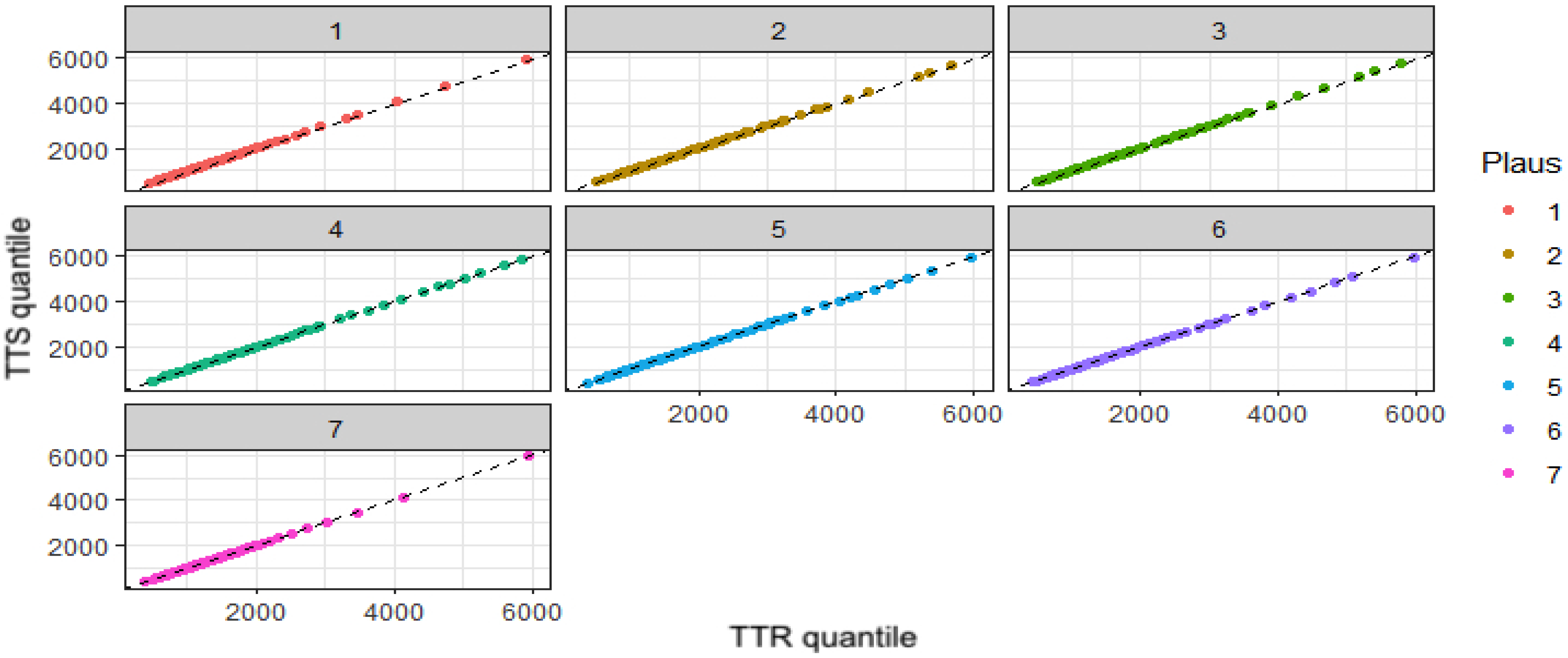
- Fractile plots to compare distributions of TTR and TTS in each level of Plaus.
- (iv)
- Fractile regression for the median TTR, including interaction between List and Plaus.
- (v)
- Fractile regression for the median TTR, including interaction between List and Plaus, with subject as a random effect.
- Mean_L and Median_L denote the lower bounds of the confidence intervals for the mean and median, respectively.
- Mean_H and Median_H correspond to the upper bounds.
- A notable effect of TTR on TTS, suggesting that as TTR values change, so do TTS values.
- Variances in the plausibility rating, termed ’Plaus’, significantly influence TTS.
- An intriguing interaction between TTR and Plaus concerning TTS, suggesting that the impact of TTR on TTS is influenced by Plaus levels and vice versa.
4. Conclusions
4.1. Contributions of the Study
- [Innovative statistical methods] Our study introduces and utilizes advanced statistical methods, including permutation tests, bootstrap confidence intervals, and fractile regression (with and without random effects). These methods offer a nuanced approach to data analysis, especially when confronted with skewed distributions, and they provide a robust understanding of interactions between variables in psycholinguistic experiments.
- [Blending traditional and advanced mathematical tools] Our research integrates traditional statistical techniques with advanced mathematical tools stemming from fractal and fractional mathematics. Applying these concepts leads to increased precision and reveals intricate patterns in the data previously overlooked.
- [Comprehensive understanding of language processing]: Our findings delve deeper into the intricacies of language processing, emphasizing the importance of individual variations. These variations, when viewed in light of behaviors associated with decision-making during language tasks, reveal intricate patterns. Such patterns can differentiate between response patterns that originate from specific linguistic processes and those influenced by broader psychological mechanisms.
- [Future software development] Recognizing the potential of our methodological advances, we are in the process of developing a user-friendly software tailored for linguists and other professionals. Our software will incorporate the advanced statistical techniques presented in this study, enabling more sophisticated and precise analyses of psycholinguistic data. The development aims to democratize access to our methods, making them more accessible to a wider audience.
- [Potential for broader application] Our research, while focused on psycholinguistic data, offers a versatile methodological approach that could be applied to other domains where data complexity poses challenges. Introducing these techniques in different fields could lead to more comprehensive and nuanced analyses of complex datasets.
4.2. Theoretical and Practical Reflexes and Implications
4.3. Limitations, Challenges, and Difficulties
4.4. Future Developments and Implications
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Altman, G.T.M. The language machine: Psycholinguistics in review. Br. J. Psychol. 2001, 92, 129–170. [Google Scholar] [CrossRef]
- Li, S.; Chen, J.; Li, B. Estimation and testing of random effects semiparametric regression model with separable space-time filters. Fractal Fract. 2022, 6, 735. [Google Scholar] [CrossRef]
- Christianson, K.; Dempsey, J.; Tsiola, A.; Goldshtein, M. What if they’re just not that into you (or your experiment)? On motivation and psycholinguistics. In The Psychology of Learning and Motivation; Academic Press: Cambridge, MA, USA, 2022; Volume 76, pp. 51–88. [Google Scholar]
- Qian, Z.; Garnsey, S.; Christianson, K. A comparison of online and offline measures of good-enough processing in garden-path sentences. Lang. Cogn. Neurosci. 2018, 33, 227–254. [Google Scholar] [CrossRef]
- Ferreira, F.; Yang, Z. The problem of comprehension in Psycholinguistics. Discourse Process. 2019, 56, 485–495. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, H.; Li, S.; Dong, R. A novel grey seasonal model for natural gas production forecasting. Fractal Fract. 2023, 7, 422. [Google Scholar] [CrossRef]
- van Doorn, J.; Aust, F.; Haaf, J.M.; Stefan, A.M.; Wagenmakers, E.J. Bayes factors for mixed models. Comput. Brain Behav. 2023, 6, 13–26. [Google Scholar] [CrossRef]
- Korkmaz, M.Ç.; Leiva, V.; Martin-Barreiro, C. The continuous Bernoulli distribution: Mathematical characterization, fractile regression, computational simulations, and applications. Fractal Fract. 2023, 7, 386. [Google Scholar] [CrossRef]
- Leiva, V.; Mazucheli, J.; Alves, B. A novel regression model for fractiles: Formulation, computational aspects, and applications to medical data. Fractal Fract. 2023, 7, 169. [Google Scholar] [CrossRef]
- Vasishth, S.; Yadav, H.; Schad, D.J.; Nicenboim, B. Sample size determination for Bayesian hierarchical models commonly used in psycholinguistics. Comput. Brain Behav. 2023, 6, 102–126. [Google Scholar] [CrossRef]
- Kim, I.; Balakrishnan, S.; Wasserman, L. Minimax optimality of permutation tests. Ann. Stat. 2022, 50, 225–251. [Google Scholar] [CrossRef]
- Zhao, W.; Liu, D.; Wang, H. Sieve bootstrap test for multiple change points in the mean of long memory sequence. AIMS Math. 2022, 7, 10245–10255. [Google Scholar] [CrossRef]
- Zhao, Q.; Zhang, C.; Wu, J.; Wang, X. Robust and efficient estimation for nonlinear model based on composite quantile regression with missing covariates. AIMS Math. 2022, 7, 8127–8146. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Hao, L.; Naiman, D.Q. Quantile Regression; Sage Publications: Thousand Oaks, CA, USA, 2007. [Google Scholar]
- Davino, C.; Furno, M.; Vistocco, D. Quantile Regression: Theory and Applications; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Koenker, R.; Chernozhukov, V.; He, X.; Peng, L. Handbook of Quantile Regression; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Sánchez, L.; Leiva, V.; Saulo, H.; Marchant, C.; Sarabia, J.M. A new quantile regression model and its diagnostic analytics for a Weibull distributed response with applications. Mathematics 2021, 9, 2768. [Google Scholar] [CrossRef]
- Davison, A.C. Statistical Models; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models; Chapman and Hall: London, UK, 1983. [Google Scholar]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression and its diagnostics with application to economic data. Appl. Stoch. Model. Bus. Ind. 2021, 37, 53–73. [Google Scholar] [CrossRef]
- Saulo, H.; Dasilva, A.; Leiva, V.; Sánchez, L.; de la Fuente-Mella, H. Log-symmetric quantile regression models. Stat. Neerl. 2022, 76, 124–163. [Google Scholar] [CrossRef]
- Cook, R.D.; Weisberg, S. Residuals and Influence in Regression; Chapman and Hall: London, UK, 1982. [Google Scholar]
- Dunn, P.; Smyth, G. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
- Saulo, H.; Leão, J.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders autoregressive conditional duration models applied to high-frequency financial data. Stat. Pap. 2019, 60, 1605–1629. [Google Scholar] [CrossRef]
- Saulo, H.; Vila, R.; Bittencourt, V.L.; Leao, J.; Leiva, V.; Christakos, G. On a new extreme value distribution: Characterization, parametric quantile regression, and application to extreme air pollution events. Stoch. Environ. Res. Risk Assess. 2023, 37, 1119–1136. [Google Scholar] [CrossRef]
- Abdulla, F.; El-Raouf, M.A.; Rahman, A.; Aldallal, R.; Mohamed, M.S.; Hossain, M.M. Prevalence and determinants of wasting among under-5 Egyptian children: Application of quantile regression. Food Sci. Nutr. 2023, 11, 1073–1083. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Xia, M. Quantile regression applications in climate change. In Encyclopedia of Data Science and Machine Learning; IGI Global: Hershey, PA, USA, 2023; pp. 2450–2462. [Google Scholar]
- Bailar, B.A. Salary survey of U.S. colleges and universities offering degrees in statistics. Amstat News 1991, 182, 3. [Google Scholar]
- Yu, K.; Moyeed, R.A. Bayesian quantile regression. Stat. Probab. Lett. 2001, 54, 437–447. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Moir, R. A Monte Carlo analysis of the fisher randomization technique: Reviving randomization for experimental economists. Exp. Econ. 1998, 1, 87–100. [Google Scholar] [CrossRef]
- Sherstyuk, K. Collusion without conspiracy: An experimental study of one-sided auctions. Exp. Econ. 1999, 2, 59–75. [Google Scholar] [CrossRef]
- Abbink, K. Staff rotation as an anti-corruption policy: An experimental study. Eur. J. Political Econ. 2004, 20, 887–906. [Google Scholar] [CrossRef]
- Orzen, H. Counterintuitive number effects in experimental oligopolies. Exp. Econ. 2008, 11, 390–401. [Google Scholar] [CrossRef]
- Anderson, L.R.; DiTraglia, F.J.; Gerlach, J.R. Measuring altruism in a public goods experiment: A comparison of U.S. and Czech subjects. Exp. Econ. 2011, 14, 426–437. [Google Scholar] [CrossRef]
- Sieberg, K.; Clark, D.; Holt, C.A.; Nordstrom, T.; Reed, W. An experimental analysis of asymmetric power in conflict bargaining. Games Econ. Behav. 2013, 4, 375–397. [Google Scholar] [CrossRef]
- Nosenzo, D.; Quercia, S.; Sefton, M. Cooperation in small groups: The effect of group size. Exp. Econ. 2015, 18, 4–14. [Google Scholar] [CrossRef]
- Rosokha, Y.; Younge, K. Motivating innovation: The effect of loss aversion on the willingness to persist. Rev. Econ. Stat. 2020, 102, 569–582. [Google Scholar] [CrossRef]
- Erkal, N.; Gangadharan, L.; Koh, B.H. Replication: Belief elicitation with quadratic and binarized scoring rules. J. Econ. Psychol. 2020, 81, 102315. [Google Scholar] [CrossRef]
- Kujansuua, E.; Schram, A. Shocking gift exchange. J. Econ. Behav. Organ. 2021, 188, 783–810. [Google Scholar] [CrossRef]
- Stephenson, D.G.; Brown, A.L. Playing the field in all-pay auctions. Exp. Econ. 2021, 24, 489–514. [Google Scholar] [CrossRef]
- Schram, A.; Zheng, J.D.; Zhuravleva, T. Corruption: A cross-country comparison of contagion and conformism. J. Econ. Behav. Organ. 2022, 193, 497–518. [Google Scholar] [CrossRef]
- Holt, C.A.; Sullivan, S.P. Permutation tests for experimental data. Exp. Econ. 2023. [Google Scholar] [CrossRef] [PubMed]
- Efron, B. More efficient bootstrap computations. J. Am. Stat. Assoc. 1990, 85, 79–89. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Van Der Vaart, A.W.; Wellner, J.A. Weak Convergence and Empirical Processes; Springer: New York, NY, USA, 1996. [Google Scholar]
- Hall, P. Methodology and Theory for the Bootstrap. In Handbook of Econometrics; Springer: Berlin/Heidelberg, Germany, 1994; Volume 4, pp. 2341–2381. [Google Scholar]
- Booth, J.G.; Hall, P. Monte Carlo approximation and the Iterated Bootstrap. Biometrika 1994, 81, 331–340. [Google Scholar] [CrossRef]
- Ma, Y.; Leng, C.; Wang, H. Optimal subsampling bootstrap for massive data. J. Bus. Econ. Stat. 2023. [Google Scholar] [CrossRef]
- Huang, A.A.; Huang, S.Y. Increasing transparency in machine learning through bootstrap simulation and shapely additive explanations. PLoS ONE 2023, 18, e0281922. [Google Scholar] [CrossRef]
- Michelucci, U.; Venturini, F. Estimating neural network’s performance with bootstrap: A tutorial. Mach. Learn. Knowl. Extr. 2021, 3, 357–373. [Google Scholar] [CrossRef]
- Kouritzin, M.A.; Styles, S.; Vritsiou, B.H. A bootstrap algorithm for fast supervised learning. arXiv 2023, arXiv:2305.03099. [Google Scholar]
- Wang, D.; Sun, R.; Green, L. Prediction intervals of loan rate for mortgage data based on bootstrapping technique: A comparative study. Math. Found. Comput. 2023, 6, 280–289. [Google Scholar] [CrossRef]
- Lourenço-Gomes, M.C. Assessing Participants’ Actions and Time in Performing Acceptability Judgment Tasks through a Dedicated Web-Based Application; Institute of Arts and Humanities/Center for Humanistic Studies, University of Minho: Braga, Portugal, 2018. [Google Scholar]
- Lourenço-Gomes, M.C.; Castro, C.; Amorim, A.; Bezerra, G. Tracking participants’ behaviour when performing linguistic tasks. In Proceedings of the 13th International Conference of Experimental Linguistics, Paris, France, 17–19 October 2022; pp. 113–116. [Google Scholar]



{kind=link}
{kind=link}
| List | Mean | Mean_L | Mean_H | SD |
|---|---|---|---|---|
| L1_75 | 1383.14 | 1346.25 | 1422.52 | 792.37 |
| L2_50 | 1598.69 | 1551.43 | 1645.61 | 927.27 |
| L3_25 | 1486.08 | 1441.98 | 1530.81 | 909.35 |
| L4_zero | 1398.59 | 1360.87 | 1437.72 | 873.09 |
| List | Median | Median_L | Median_H |
|---|---|---|---|
| L1_75 | 1175.85 | 1151.00 | 1204.63 |
| L2_50 | 1351.85 | 1308.44 | 1397.82 |
| L3_25 | 1227.50 | 1189.50 | 1261.21 |
| L4_zero | 1144.00 | 1115.00 | 1171.60 |
| Condition | Mean | Mean_L | Mean_H | SD |
|---|---|---|---|---|
| F1_Anom | 1330.41 | 1277.14 | 1385.07 | 747.47 |
| F2_Anom | 1569.76 | 1497.16 | 1642.31 | 912.62 |
| E1 | 1532.53 | 1482.33 | 1583.64 | 906.10 |
| E2 | 1476.83 | 1426.65 | 1527.69 | 874.30 |
| F1 | 1463.03 | 1417.42 | 1505.14 | 905.98 |
| F2 | 1415.80 | 1371.79 | 1459.10 | 875.93 |
| Condition | Median | Median_L | Median_H |
|---|---|---|---|
| F1_Anom | 1148.60 | 1118.00 | 1188.90 |
| F2_Anom | 1296.75 | 1244.10 | 1349.30 |
| E1 | 1532.53 | 1217.58 | 1313.32 |
| E2 | 1476.83 | 1178.29 | 1262.92 |
| F1 | 1463.03 | 1164.50 | 1250.50 |
| F2 | 1415.80 | 1145.10 | 1202.75 |
| Plaus_Rate | Mean | Mean_L | Mean_H | SD |
|---|---|---|---|---|
| 1 1 | 1380.46 | 1344.20 | 1423.82 | 787.18 |
| 2 2 | 1805.98 | 1708.42 | 1909.95 | 1021.01 |
| 5 3 | 1735.59 | 1622.37 | 1851.05 | 1088.45 |
| 7 4 | 1842.68 | 1718.02 | 1968.54 | 1133.61 |
| 6 5 | 1850.34 | 1750.32 | 1950.06 | 1131.18 |
| 4 6 | 1602.79 | 1536.41 | 1669.83 | 987.20 |
| 3 7 | 1278.97 | 1253.89 | 1306.40 | 683.59 |
| Plaus_Rate | Median | Median_L | Median_H |
|---|---|---|---|
| 1 1 | 1184.10 | 1155.70 | 1209.35 |
| 2 2 | 1417.00 | 1357.00 | 1539.40 |
| 5 3 | 1432.40 | 1327.07 | 1579.05 |
| 7 4 | 1515.80 | 1442.50 | 1617.00 |
| 6 5 | 1455.00 | 1372.40 | 1552.50 |
| 4 6 | 1277.00 | 1208.20 | 1335.10 |
| 3 7 | 1115.00 | 1096.30 | 1136.60 |
| p-Value () | ||
|---|---|---|
| Fixed (No Random) Effect | Random Effect | |
| L3: Plaus7 | 0.028 () | |
| L4: Plaus7 | 0.002 () | 0.082 () |
| Plaus2 | 0.009 () | |
| Plaus3 | 0.015 () | |
| Plaus4 | 0.075 () | |
| Plaus5 | 0.001 () | |
| Plaus6 | 0.001 () | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castro, C.; Leiva, V.; Lourenço-Gomes, M.d.C.; Amorim, A.P. Advanced Mathematical Approaches in Psycholinguistic Data Analysis: A Methodological Insight. Fractal Fract. 2023, 7, 670. https://doi.org/10.3390/fractalfract7090670
Castro C, Leiva V, Lourenço-Gomes MdC, Amorim AP. Advanced Mathematical Approaches in Psycholinguistic Data Analysis: A Methodological Insight. Fractal and Fractional. 2023; 7(9):670. https://doi.org/10.3390/fractalfract7090670
Chicago/Turabian StyleCastro, Cecilia, Víctor Leiva, Maria do Carmo Lourenço-Gomes, and Ana Paula Amorim. 2023. "Advanced Mathematical Approaches in Psycholinguistic Data Analysis: A Methodological Insight" Fractal and Fractional 7, no. 9: 670. https://doi.org/10.3390/fractalfract7090670
APA StyleCastro, C., Leiva, V., Lourenço-Gomes, M. d. C., & Amorim, A. P. (2023). Advanced Mathematical Approaches in Psycholinguistic Data Analysis: A Methodological Insight. Fractal and Fractional, 7(9), 670. https://doi.org/10.3390/fractalfract7090670