When Diversity Met Accuracy: A Story of Recommender Systems †


{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Algorithms
2.2. Evaluation Protocol
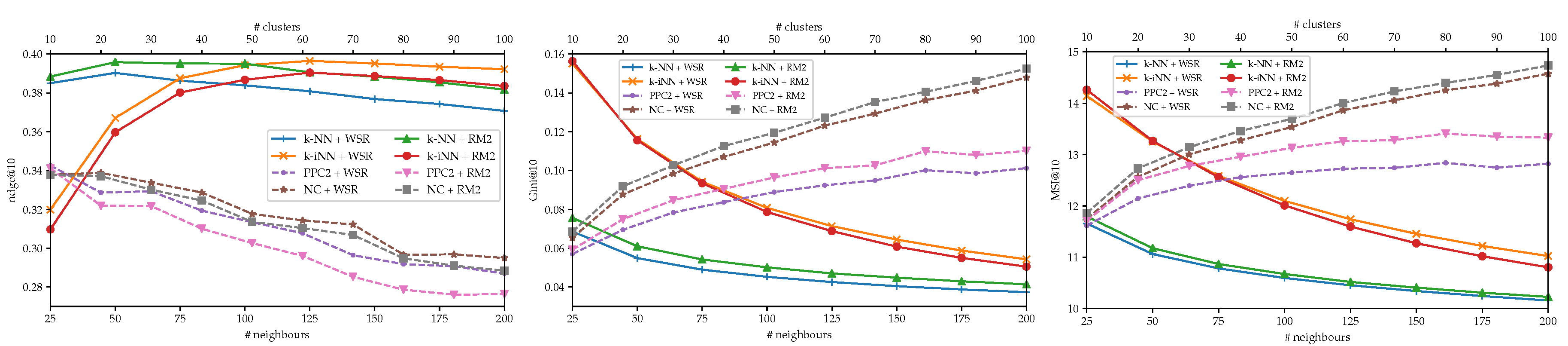
3. Results
4. Discussion
Funding
Conflicts of Interest
References
- Cremonesi, P.; Koren, Y.; Turrin, R. Performance of Recommender Algorithms on Top-N Recommendation Tasks. In Proceedings of the 4th ACM Conference on Recommender Systems (RecSys’10), Barcelona, Spain, 26–30 September 2010; ACM: New York, NY, USA, 2010; pp. 39–46. [Google Scholar] [CrossRef]
- McLaughlin, M.R.; Herlocker, J.L. A collaborative filtering algorithm and evaluation metric that accurately model the user experience. In Proceedings of the 27th Annual International Conference on Research and Development in Information Retrieval (SIGIR’04), Sheffield, UK, 25–29 July 2004; ACM Press: New York, NY, USA, 2004; p. 329. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- McNee, S.M.; Riedl, J.; Konstan, J.A. Being Accurate is Not Enough: How Accuracy Metrics have hurt Recommender Systems. In Proceedings of the CHI’06 Extended Abstracts on Human Factors in Computing Systems (CHI EA’06), Montréal, QC, Canada, 22–27 April 2006; ACM Press: New York, NY, USA, 2006; p. 1097. [Google Scholar] [CrossRef]
- Ge, M.; Delgado-Battenfeld, C.; Jannach, D. Beyond Accuracy: Evaluating Recommender Systems by Coverage and Serendipity. In Proceedings of the Fourth ACM Conference on Recommender Systems (RecSys’10), Barcelona, Spain, 26–30 September 2010; pp. 257–260. [Google Scholar] [CrossRef]
- Fleder, D.; Hosanagar, K. Blockbuster Culture’s Next Rise or Fall: The Impact of Recommender Systems on Sales Diversity. Manag. Sci. 2009, 55, 697–712. [Google Scholar] [CrossRef]
- Valcarce, D.; Parapar, J.; Barreiro, Á. Item-based relevance modelling of recommendations for getting rid of long tail products. Knowl.-Based Syst. 2016, 103, 41–51. [Google Scholar] [CrossRef]
- Valcarce, D.; Parapar, J.; Barreiro, A. Efficient Pseudo-Relevance Feedback Methods for Collaborative Filtering Recommendation. In Proceedings of the European Conference on Information Retrieval (ECIR’16), Padua, Italy, 20–23 March 2016; pp. 602–613. [Google Scholar] [CrossRef]
- Lavrenko, V.; Croft, W.B. Relevance based language models. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’01), New Orleans, LA, USA, 9–12 September 2001; ACM Press: New York, NY, USA, 2001; pp. 120–127. [Google Scholar] [CrossRef]
- Parapar, J.; Bellogín, A.; Castells, P.; Barreiro, A. Relevance-based language modelling for recommender systems. Inf. Process. Manag. 2013, 49, 966–980. [Google Scholar] [CrossRef]
- Ning, X.; Desrosiers, C.; Karypis, G. A Comprehensive Survey of Neighborhood-Based Recommendation Methods. In Recommender Systems Handbook, 2nd ed.; Ricci, F., Rokach, L., Shapira, B., Eds.; Springer: Boston, MA, USA, 2015; pp. 37–76. [Google Scholar] [CrossRef]
- Vargas, S.; Castells, P. Improving Sales Diversity by Recommending Users to Items. In Proceedings of the 8th ACM Conference on Recommender Systems (RecSys’14), Foster City, CA, USA, 6–10 October 2014; ACM: New York, NY, USA, 2014; pp. 145–152. [Google Scholar] [CrossRef]
- Zhang, Z.Y.; Li, T.; Ding, C.; Tang, J. An NMF-framework for Unifying Posterior Probabilistic Clustering and Probabilistic Latent Semantic Indexing. Commun. Stat.-Theory Methods 2014, 43, 4011–4024. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. 2000, 22, 888–905. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Li, Y.; He, D.; Chen, W.; Liu, T.Y. A Theoretical Analysis of NDCG Ranking Measures. In Proceedings of the 26th Annual Conference on Learning Theory (COLT’13), Princeton, NJ, USA, 12–14 June 2013; pp. 1–30. [Google Scholar]
- Zhou, T.; Kuscsik, Z.; Liu, J.G.; Medo, M.; Wakeling, J.R.; Zhang, Y.C. Solving the apparent diversity-accuracy dilemma of recommender systems. Proc. Natl. Acad. Sci. USA 2010, 107, 4511–4515. [Google Scholar] [CrossRef] [PubMed]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Landin, A.; Suárez-García, E.; Valcarce, D. When Diversity Met Accuracy: A Story of Recommender Systems. Proceedings 2018, 2, 1178. https://doi.org/10.3390/proceedings2181178
Landin A, Suárez-García E, Valcarce D. When Diversity Met Accuracy: A Story of Recommender Systems. Proceedings. 2018; 2(18):1178. https://doi.org/10.3390/proceedings2181178
Chicago/Turabian StyleLandin, Alfonso, Eva Suárez-García, and Daniel Valcarce. 2018. "When Diversity Met Accuracy: A Story of Recommender Systems" Proceedings 2, no. 18: 1178. https://doi.org/10.3390/proceedings2181178
APA StyleLandin, A., Suárez-García, E., & Valcarce, D. (2018). When Diversity Met Accuracy: A Story of Recommender Systems. Proceedings, 2(18), 1178. https://doi.org/10.3390/proceedings2181178