
A Novel Method of Small Object Detection in UAV Remote Sensing Images Based on Feature Alignment of Candidate Regions


Abstract
:1. Introduction
- APA-FPN establishes the corresponding relationship between feature mappings, thus solving the misalignment between features and enriching the semantic representation of shallow features of small objects.
- PHDA captures local areas containing small object features through parallel channel domain attention and spatial domain attention. These areas are assigned with a larger weight to eliminate the interference of background noise.
- The rotation branch introduces the rotating bounding box to solve the missing detection of small objects with dense distribution and arbitrary direction and the mismatch between the object and the candidate region features.
- The loss function is improved to enhance the robustness of the model. The experimental results show that the proposed method is more accurate and faster than the state-of-the-art remote sensing object detection methods.
2. Related Works
2.1. Conventional Object Detection
2.2. Remote Sensing Object Detection
2.3. Conventional Small Object Detection
2.4. Remote Sensing Small Object Detection
3. Overview of the Proposed Method
3.1. AFA-FPN (Attention-Based Feature Alignment FPN Module)
3.2. PHDA (Polarization Hybrid Domain Attention Module)
3.3. Rotation Branch
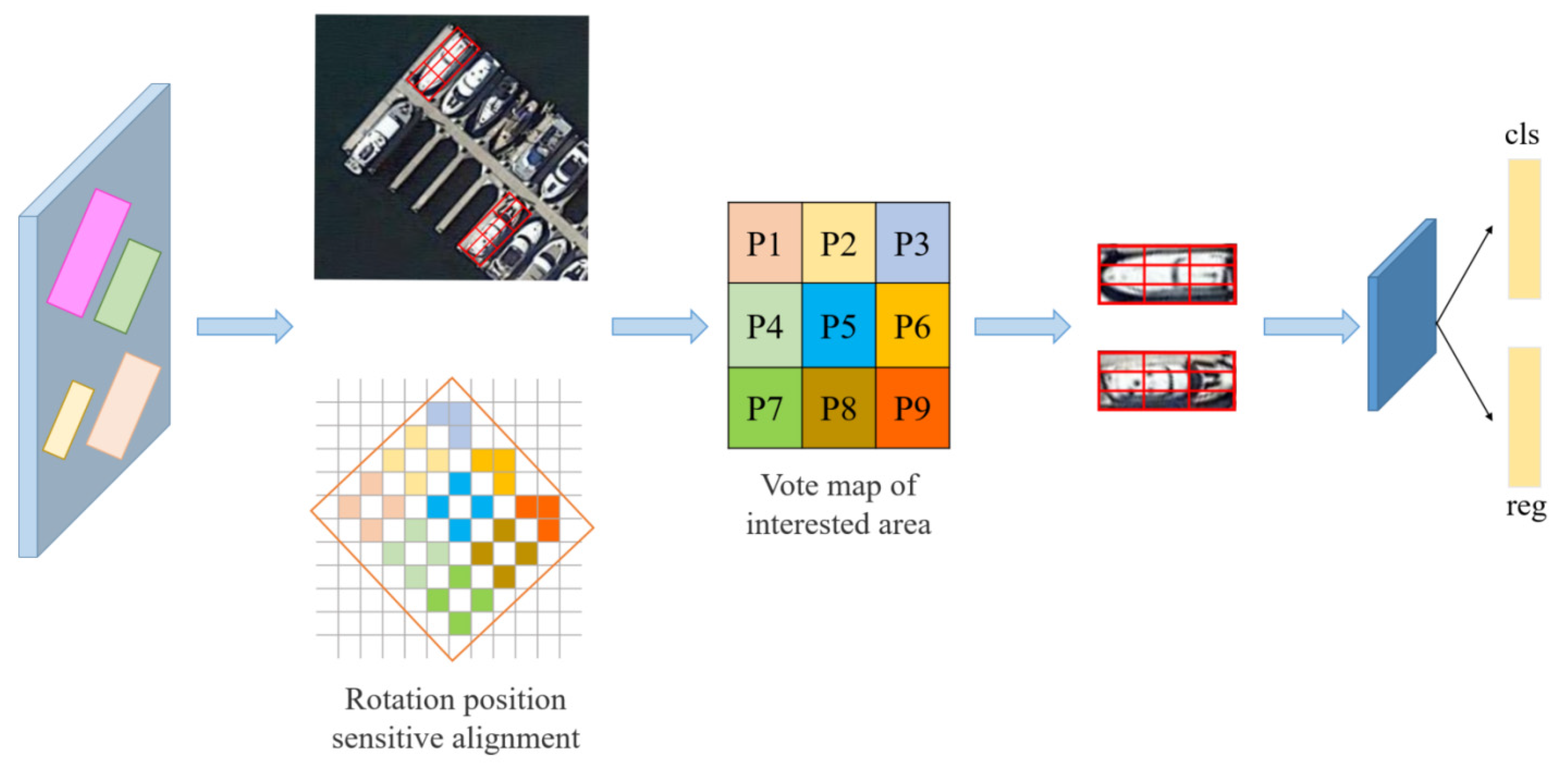
3.3.1. RRoI Alignment
3.3.2. RRoI Rotation Position-Sensitive Pooling
3.4. Loss Function
3.4.1. Classification Loss Function
3.4.2. Regression Loss Function
4. Experimental Analysis
4.1. Dataset
4.2. Experimental Setting
4.3. Ablation Experiment
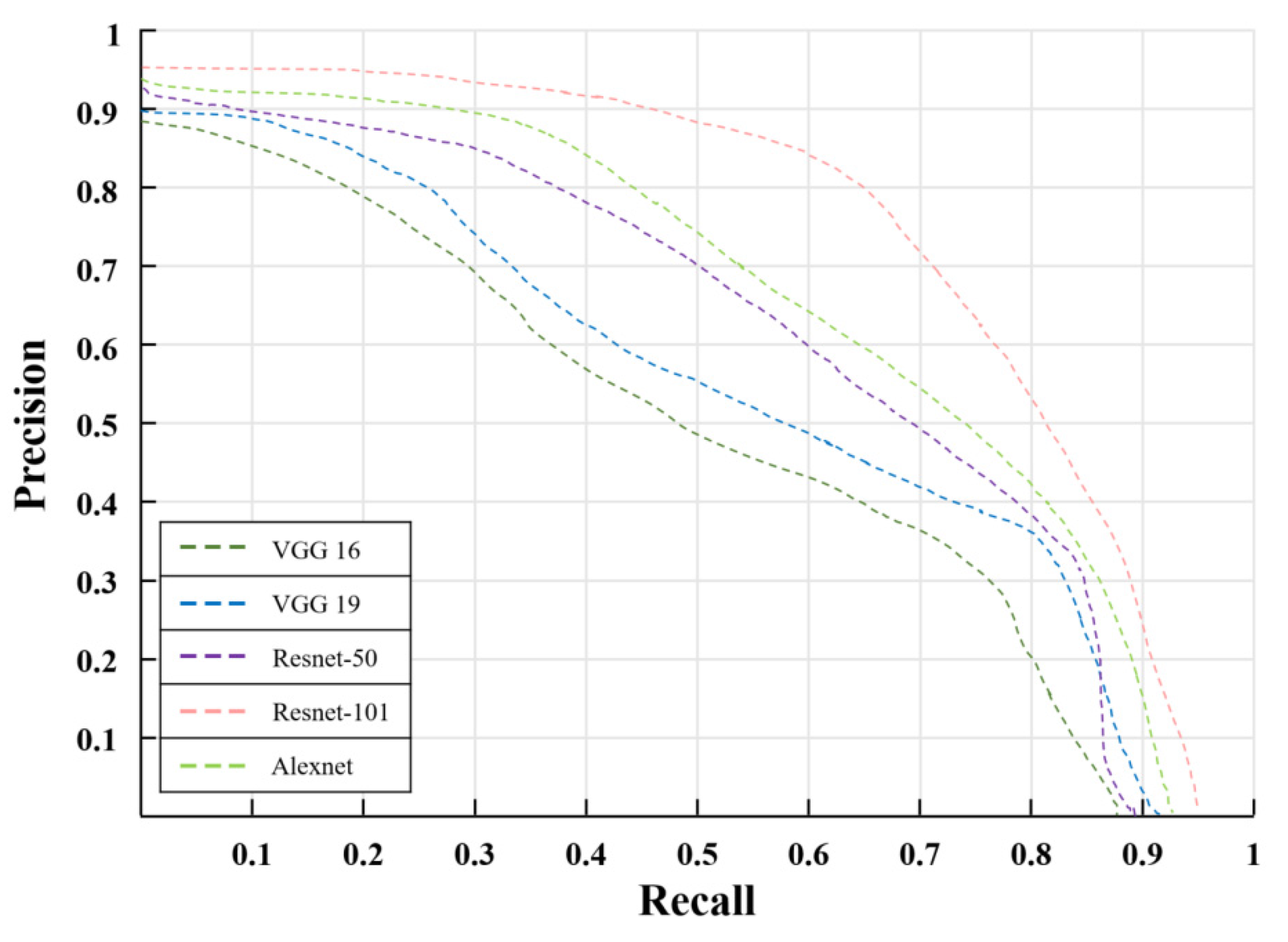
4.4. Experimental Results and Analysis
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Wang, C.; Liu, Y.; Fu, K. PBNet: Part-based convolutional neural network for complex composite object detection in remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 173, 50–65. [Google Scholar] [CrossRef]
- Wang, Y.; Bashir, S.M.A.; Khan, M.; Ullah, Q.; Wang, R.; Song, Y.; Guo, Z.; Niu, Y. Remote sensing image super-resolution and object detection: Benchmark and state of the art. Expert Syst. Appl. 2022, 197, 116793. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. Computer Science. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In IEEE Transactions on Pattern Analysis & Machine Intelligence; IEEE: Piscataway Township, NJ, USA, 2018; pp. 2999–3007. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway Township, NJ, USA, 2015; pp. 640–651. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2021. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. Piou loss: Towards accurate oriented object detection in complex environments. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align deep features for oriented object detection. In IEEE Transactions on Geoscience and Remote Sensing; IEEE: Piscataway Township, NJ, USA, 2021; Volume 60. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Nguyen, N.D.; Do, T.; Ngo, T.D.; Le, D.D. An evaluation of deep learning methods for small object detection. J. Electr. Comput. Eng. 2020, 2020, 3189691. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale deconvolutional single shot detector for small objects. arXiv 2018, arXiv:1805.07009. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Shen, T. Small object detection with multiple receptive fields. IOP Conf. Ser. Earth Environ. Sci. 2020, 440, 032093. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhao, C.; Guo, H.; Wang, J.; Zhao, X.; Lu, H. Attention CoupleNet: Fully convolutional attention coupling network for object detection. IEEE Trans. Image Process. 2018, 28, 113–126. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Li, H.; Wu, Q.; Chen, X.; Ngan, K.N. Simultaneously detecting and counting dense vehicles from drone images. IEEE Trans. Ind. Electron. 2019, 66, 9651–9662. [Google Scholar] [CrossRef]
- Xi, Y.; Zheng, J.; He, X.; Jia, W.; Li, H.; Xie, Y.; Feng, M.; Li, X. Beyond context: Exploring semantic similarity for small object detection in crowded scenes. Pattern Recognit. Lett. 2020, 137, 53–60. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. SCRDet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway Township, NJ, USA, 2022. [Google Scholar]
- Li, C.; Cong, R.; Guo, C.; Li, H.; Zhang, C.; Zheng, F.; Zhao, Y. A Parallel Down-Up Fusion Network for Salient Object Detection in Optical Remote Sensing Images. Neurocomputing 2020, 415, 411–420. [Google Scholar] [CrossRef]
- Hou, L.; Lu, K.; Xue, J.; Hao, L. Cascade detector with feature fusion for arbitrary-oriented objects in remote sensing images. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020. [Google Scholar]
- Qu, J.; Su, C.; Zhang, Z.; Razi, A. Dilated convolution and feature fusion SSD network for small object detection in remote sensing images. IEEE Access 2020, 8, 82832–82843. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense attention fluid network for salient object detection in optical remote sensing images. IEEE Trans. Image Process. 2020, 30, 1305–1317. [Google Scholar] [CrossRef]
- Lu, X.; Ji, J.; Xing, Z.; Miao, Q. Attention and feature fusion SSD for remote sensing object detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. Proc. AAAI Conf. Artif. Intell. 2019, 33, 9259–9266. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, S.; Zhang, L.; Lu, H.; He, Y. Center-boundary dual attention for oriented object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603914. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine feature pyramid network and multi-layer attention network for arbitrary-oriented object detection of remote sensing images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Dong, Y.; Chen, F.; Han, S.; Liu, H. Ship object detection of remote sensing image based on visual attention. Remote Sens. 2021, 13, 3192. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A critical feature capturing network for arbitrary-oriented object detection in remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5605814. [Google Scholar] [CrossRef]
- Yu, Y.; Guan, H.; Li, D.; Gu, T.; Tang, E.; Li, A. Orientation guided anchoring for geospatial object detection from remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 160, 67–82. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 74057415. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. arXiv 2017, arXiv:1711.10398. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe Nevada, CA, USA, 3–6 December 2012. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Brief Methodology | Highlights | Limitations |
|---|---|---|---|
| CSL | Boundary problem transformation, Circular Smooth Label | The regression problem of angle is transformed into a classification problem, and the range of prediction results is limited to eliminate large boundary loss. | Too many angle categories will cause the head part of RetinaNet to be too thick, resulting in low calculation efficiency. |
| Pixel by pixel feature interpolation, Rotation RetinaNet | The feature refinement module realizes feature reconstruction and alignment through pixel-by-pixel feature interpolation. An approximate SkewIoU loss is proposed to achieve more accurate rotation estimation. | The continuity of local pixel information is interrupted, and the adaptability to unknown deformation is poor. | |
| MDSSD | Feature fusion, multi-scale convolution | The high-level feature map with rich semantic features is enlarged by deconvlution, and then fused with the low-level feature map to achieve more refined feature extraction. | Without designing the rotating frame, it is impossible to accurately predict the rotating object. |
| Anchor refinement network, Active rotating filter | FAM generates high-quality anchors through an anchor thinning network, and adaptively aligns convolution features. ODM uses an active rotation filter to encode the direction information, and generates the characteristics of direction sensitivity and direction invariance. | Insensitive to small-scale remote sensing objects, and the detection effect is not good. | |
| PIoU | PIoU loss | PIoU loss is calculated by pixel-by-pixel judgment and is continuously differentiable, which effectively improves the detection effect of inclined targets. | Insensitive to small-scale remote sensing objects. |
| SCRDet++ | Instance-Level Feature Denoising, Rotation Loss Smoothing | In feature map, a novel instance-level denoising module is designed to suppress noise and highlight prospects, and an improved Smooth L1 loss is designed to solve the boundary problem of rotating bounding box regression. | Without feature alignment, the ability of feature expression is poor. |
| Oriented R-CNN | Oriented RPN, Oriented RCNN head | Orientation RPN generates high-quality orientation proposals at almost no cost. Directional R-CNN header refines and identifies the region of interest. | The detection effect of small and chaotic objects is not good. |
| Baseline | FPN | AFA-FPN | PHDA | Rotation Branch | GIoU | CIoU | |||
|---|---|---|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 48.75 | 64.28 | 53.27 | ||||
| ✓ | ✓ | ✓ | 53.60 | 67.59 | 54.03 | ||||
| ✓ | ✓ | ✓ | 56.21 | 66.37 | 54.82 | ||||
| ✓ | ✓ | ✓ | 52.74 | 65.98 | 53.94 | ||||
| ✓ | ✓ | ✓ | ✓ | 68.92 | 73.57 | 56.05 | |||
| ✓ | ✓ | ✓ | ✓ | 64.31 | 72.11 | 55.71 | |||
| ✓ | ✓ | ✓ | ✓ | ✓ | 74.48 | 77.14 | 58.45 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | 78.21 | 82.04 | 59.70 |
| Method | PL | BD | ST | SH | TC | BR | GTF | HA |
| CSL | 67.38 | 69.80 | 66.15 | 71.65 | 83.61 | 65.75 | 77.15 | 76.53 |
| 68.59 | 69.37 | 71.36 | 68.24 | 86.24 | 64.38 | 82.43 | 70.52 | |
| MDSSD | 62.11 | 71.25 | 71.54 | 70.35 | 85.34 | 66.54 | 79.01 | 72.77 |
| 75.96 | 76.89 | 75.38 | 76.77 | 88.48 | 74.68 | 84.28 | 79.85 | |
| PIoU | 78.43 | 79.54 | 78.09 | 78.05 | 89.71 | 78.02 | 84.21 | 80.64 |
| SCRDet++ | 76.78 | 77.42 | 76.08 | 76.91 | 90.46 | 77.25 | 87.92 | 83.60 |
| Oriented R-CNN | 80.93 | 80.42 | 81.23 | 78.94 | 89.60 | 78.17 | 85.14 | 80.53 |
| Ours | 82.42 | 79.46 | 82.21 | 79.02 | 89.94 | 77.63 | 85.47 | 81.75 |
| Method | BC | SV | LV | SBF | RA | SP | HC | mAP |
| CSL | 68.52 | 61.06 | 58.08 | 79.22 | 74.75 | 78.98 | 76.21 | 71.66 |
| 67.44 | 63.21 | 61.19 | 84.68 | 76.88 | 76.54 | 72.64 | 72.25 | |
| MDSSD | 75.07 | 69.52 | 71.44 | 78.55 | 89.42 | 83.59 | 79.05 | 75.04 |
| 77.26 | 66.24 | 71.07 | 78.22 | 81.79 | 86.87 | 77.96 | 79.04 | |
| PIoU | 78.11 | 67.83 | 70.22 | 80.06 | 82.56 | 87.98 | 82.58 | 78.57 |
| SCRDet++ | 70.84 | 64.32 | 71.03 | 82.60 | 86.71 | 88.19 | 84.01 | 79.61 |
| Oriented R-CNN | 78.58 | 68.55 | 70.08 | 81.35 | 84.56 | 88.02 | 84.37 | 80.24 |
| Ours | 79.27 | 74.11 | 75.16 | 83.49 | 88.31 | 87.58 | 84.81 | 82.04 |
| Method | FPS | ||||||
|---|---|---|---|---|---|---|---|
| CSL | 61.02 | 71.02 | 80.23 | 70.22 | 58.11 | 46.97 | 22.0 |
| 63.21 | 72.38 | 81.54 | 71.35 | 58.64 | 47.82 | 17.3 | |
| MDSSD | 68.85 | 75.61 | 77.69 | 71.98 | 59.07 | 48.33 | 33.4 |
| 71.58 | 76.71 | 78.09 | 75.84 | 60.49 | 49.01 | 22.3 | |
| PIoU | 74.02 | 78.04 | 80.14 | 76.35 | 61.50 | 51.20 | 20.7 |
| SCRDet++ | 70.99 | 79.09 | 81.30 | 75.08 | 62.44 | 49.03 | 21.2 |
| Oriented R-CNN | 75.54 | 81.99 | 80.24 | 78.45 | 64.94 | 51.96 | 18.6 |
| Yolo v4 | 39.54 | 48.09 | 58.22 | 56.47 | 41.98 | 33.84 | 106 |
| Yolo v7 | 48.31 | 57.87 | 69.61 | 61.29 | 55.31 | 39.05 | 114 |
| Ours | 78.21 | 84.77 | 80.43 | 82.04 | 69.70 | 53.41 | 24.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Shao, F.; He, X.; Lu, G. A Novel Method of Small Object Detection in UAV Remote Sensing Images Based on Feature Alignment of Candidate Regions. Drones 2022, 6, 292. https://doi.org/10.3390/drones6100292
Wang J, Shao F, He X, Lu G. A Novel Method of Small Object Detection in UAV Remote Sensing Images Based on Feature Alignment of Candidate Regions. Drones. 2022; 6(10):292. https://doi.org/10.3390/drones6100292
Chicago/Turabian StyleWang, Jinkang, Faming Shao, Xiaohui He, and Guanlin Lu. 2022. "A Novel Method of Small Object Detection in UAV Remote Sensing Images Based on Feature Alignment of Candidate Regions" Drones 6, no. 10: 292. https://doi.org/10.3390/drones6100292
APA StyleWang, J., Shao, F., He, X., & Lu, G. (2022). A Novel Method of Small Object Detection in UAV Remote Sensing Images Based on Feature Alignment of Candidate Regions. Drones, 6(10), 292. https://doi.org/10.3390/drones6100292