The experiment was conducted in two parts. In the first part, we evaluated the performance of our proposed MDJL pedestrian detection method. In the second part, we adjusted the pedestrian tracking parameters on the basis of our MDJL for comparison with other advanced tracking algorithms.
The computer hardware specifications used in the experiment included an Intel Core i7-930 CPU with 24 GB RAM and an Nvidia GTX 1080Ti GPU with 11 GB RAM. The operating system was Ubuntu 14.04 LTS, and CUDA 8.0, CUDNN 5.1, and MATLAB R2014b were the primary software programs.
4.1. Ablation Study
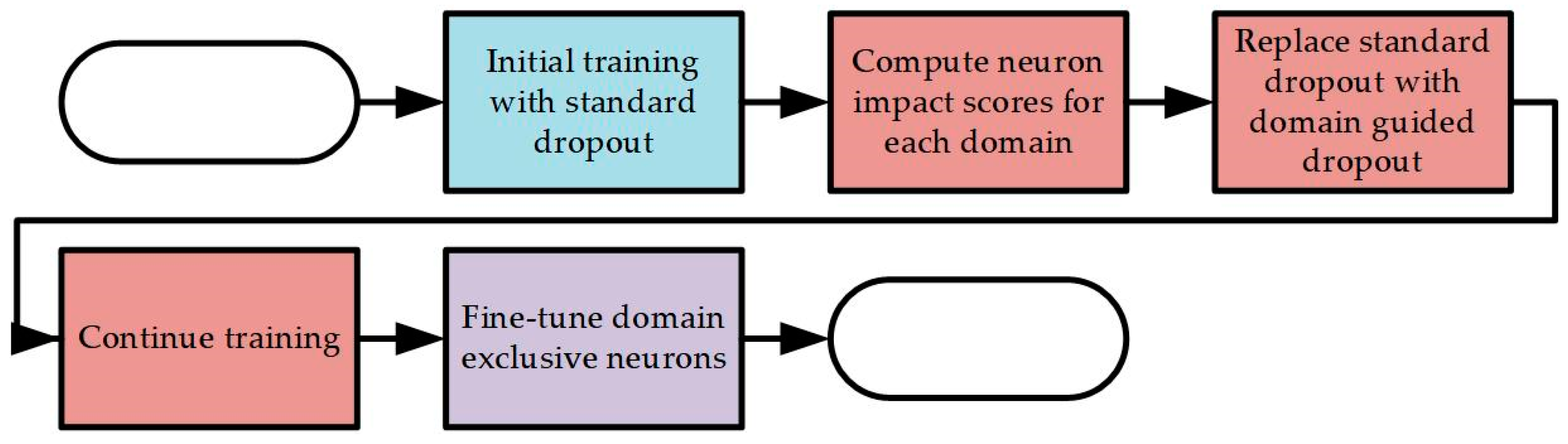
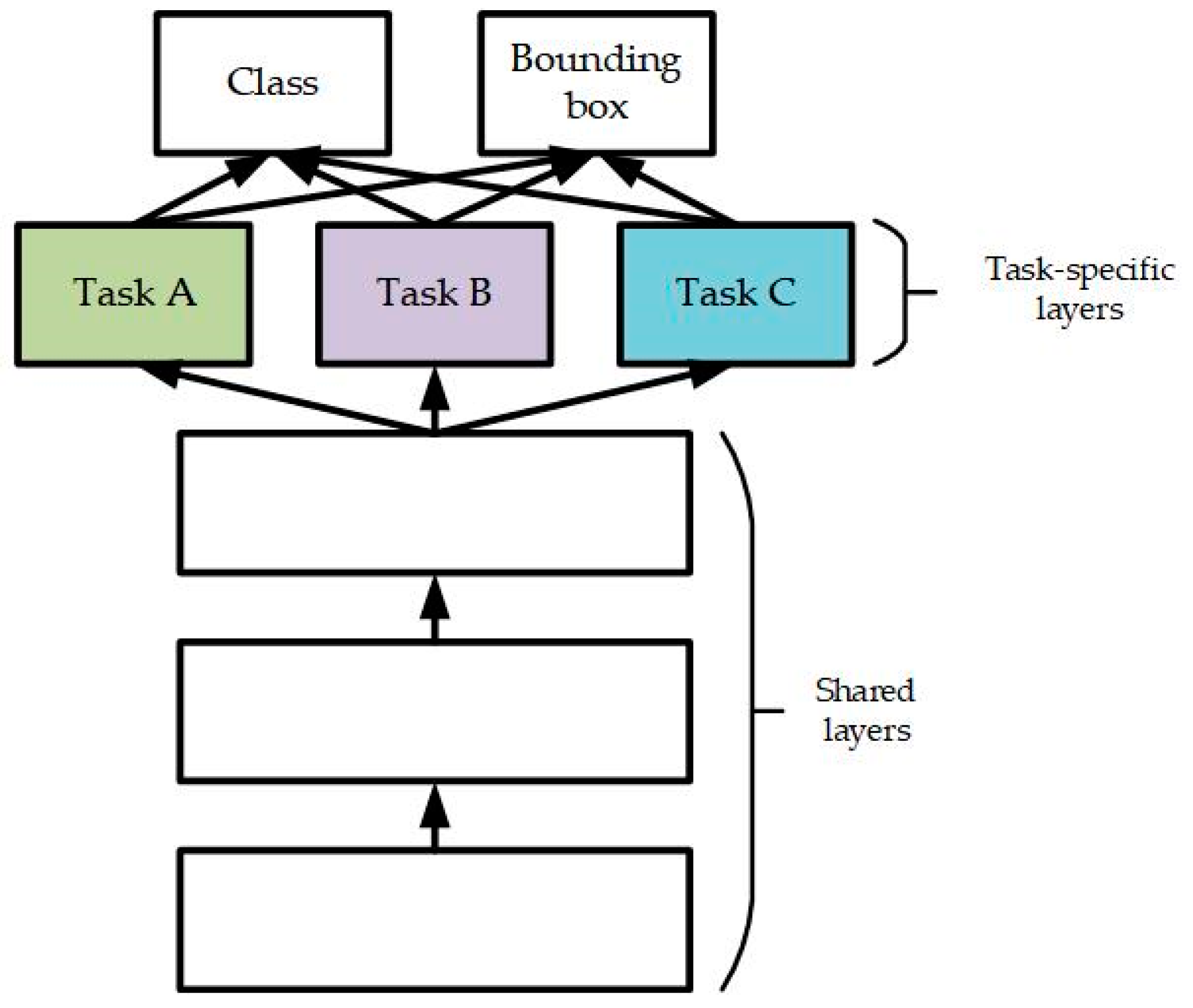
MDJL is a network training method designed for a multidomain dataset. Our objective is to use this method to address the reduction in network accuracy that occurs when using a multidomain dataset for training. In this experiment, we discuss the aforementioned issues and evaluate the effectiveness of our method.
In the following experiments, we used the Caltech dataset (referred to as c), PETS09 (referred to as p), and DroneFJU (referred to as d) for different sizes and different shooting methods, to combine them into several multidomain datasets and use these datasets to train the baseline network (MS-CNN) and our proposed method (MDJL). The method of evaluating the network uses an appropriate setting of the Caltech pedestrian detection benchmark to assess the network’s average miss rate and the receiver-operating characteristic (ROC) curve in the test set of the aforementioned three datasets.
Table 1 summarizes the number of training, validation, and testing samples for each dataset. The number of training samples of PETS09 is approximately one-third of that of the Caltech dataset, whereas the number of training samples of DroneFJU is approximately one-half of that of the Caltech dataset. This difference may affect the final network performance. Therefore, in this experiment, it was necessary to increase the number of training samples of the smaller datasets to the same or more than that of the Caltech dataset. We used two data augmentation methods to create two additional PETS09 training images and a DroneFJU training image. The first method flips the original image left and right, and the second method adds Gaussian noise to the original image. The Gaussian noise parameters had an average of 0 and a standard deviation of 0.01. Using these two data augmentation methods, we increased the number of training samples of PETS09 to 36,504, whereas that of DroneFJU increased to 35,632 via the addition of Gaussian noise. Finally, to balance the number of samples in each dataset, we used the number of training samples of the Caltech dataset as the standard and randomly extracted the same number of samples from the expanded dataset to obtain the final dataset.
Eight types of multidomain datasets were used, and the abbreviations used for the new dataset combine the names of each. Therefore, for example, for Caltech + PETS09, the multidomain dataset is called cp, and for Caltech + PETS09 + DroneFJU, the dataset is called cpd. If the multidomain dataset used data augmentation to balance the number of samples, the symbol * was used next to the abbreviation. For example, Caltech + PETS09 with data augmentation is denoted as cp*, and Caltech + PETS09 with data augmentation + DroneFJU with data augmentation is denoted as cp*d*.
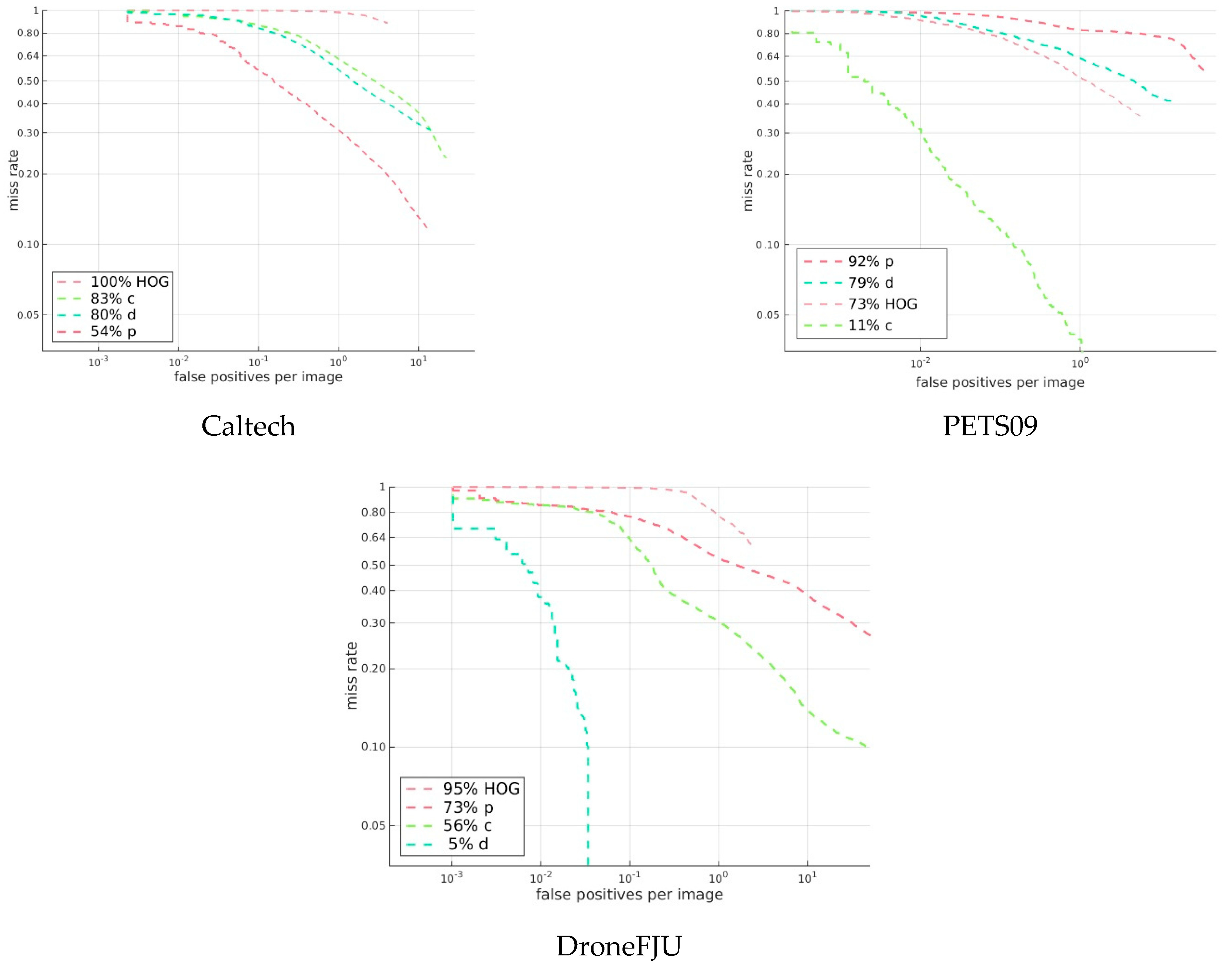
First, let us examine the evaluation results for different datasets when we use a single dataset, the so-called single-domain dataset, to train the model. We used the Caltech dataset, PETS09, and DroneFJU to train the MS-CNN model and to evaluate the three trained models, c, p, and d, on the test set of each dataset. The results are shown in
Figure 13.
Figure 13 shows that all the single-domain dataset models yield better evaluation results only for the dataset of the same domain and perform poorly on other domains. These results show that a model trained using a single dataset can be applied only to the same domain and cannot be generalized to other domains.
Table 2 lists the test results of the models trained using different multidomain datasets with appropriate settings of the test set of the Caltech dataset. We also include the evaluation results for the same setting when MS-CNN uses only the Caltech dataset as the baseline for comparison. The corresponding data are not shown for MDJL because they form a network designed for a multidomain dataset. Therefore, we did not consider the performance when using a single dataset for training. To perform a fair comparison, we selected only the multidomain dataset containing the Caltech dataset.
The MS-CNN section is summarized in
Table 2. When training was performed with the cp, cd, and cpd datasets without data augmentation, it was determined that simply adding a domain (such as cp and cd) to the dataset increased the average miss rate by approximately 0.2%, whereas adding cpd to the three domains increased it by approximately 0.5%. If we examine cp*, cd*, and cp*d* that use data augmentation, it is determined that the average miss rate further increased by approximately 1%. Thus, the overall average miss rate increased by 0.5%, with a standard deviation of 0.006. This indicates that the greater the number of domains involved in training the network with a multidomain dataset, the more significant the impact on the network performance. Moreover, using data augmentation to balance the number of samples increased the influence of the initially small dataset on the network training and also affected the accuracy of the network.
The experimental results of MDJL show that regardless of the number of domains contained in the multidomain dataset, the average miss rate increased by only approximately 0.2%. Furthermore, even if data augmentation was used, the average miss rate increased by only approximately 0.3%. Thus, the overall average increase in the average miss rate was 0.1%, and the standard deviation was 0.002. This indicates that MDJL is more stable when using multidomain dataset training and is not highly susceptible to the number of domains or the number of data. In addition, regardless of the multidomain dataset used for training, the average miss rate of MDJL was lower than that of MS-CNN. This implies that MDJL can improve the overall accuracy when training with a multidomain dataset.
In the following table, we compare the performance of the models trained using each multidomain dataset on the test set. Therefore, we indicate the dataset name used in the training after the method name to facilitate comparison. For example, the MDJL model trained with the cpd dataset is called MDJL-cpd.
We used the MS-CNN and MDJL models, which were trained on the eight multidomain datasets, to evaluate the test sets of the Caltech, PETS09, and DroneFJU datasets, and we recorded the average miss rates in
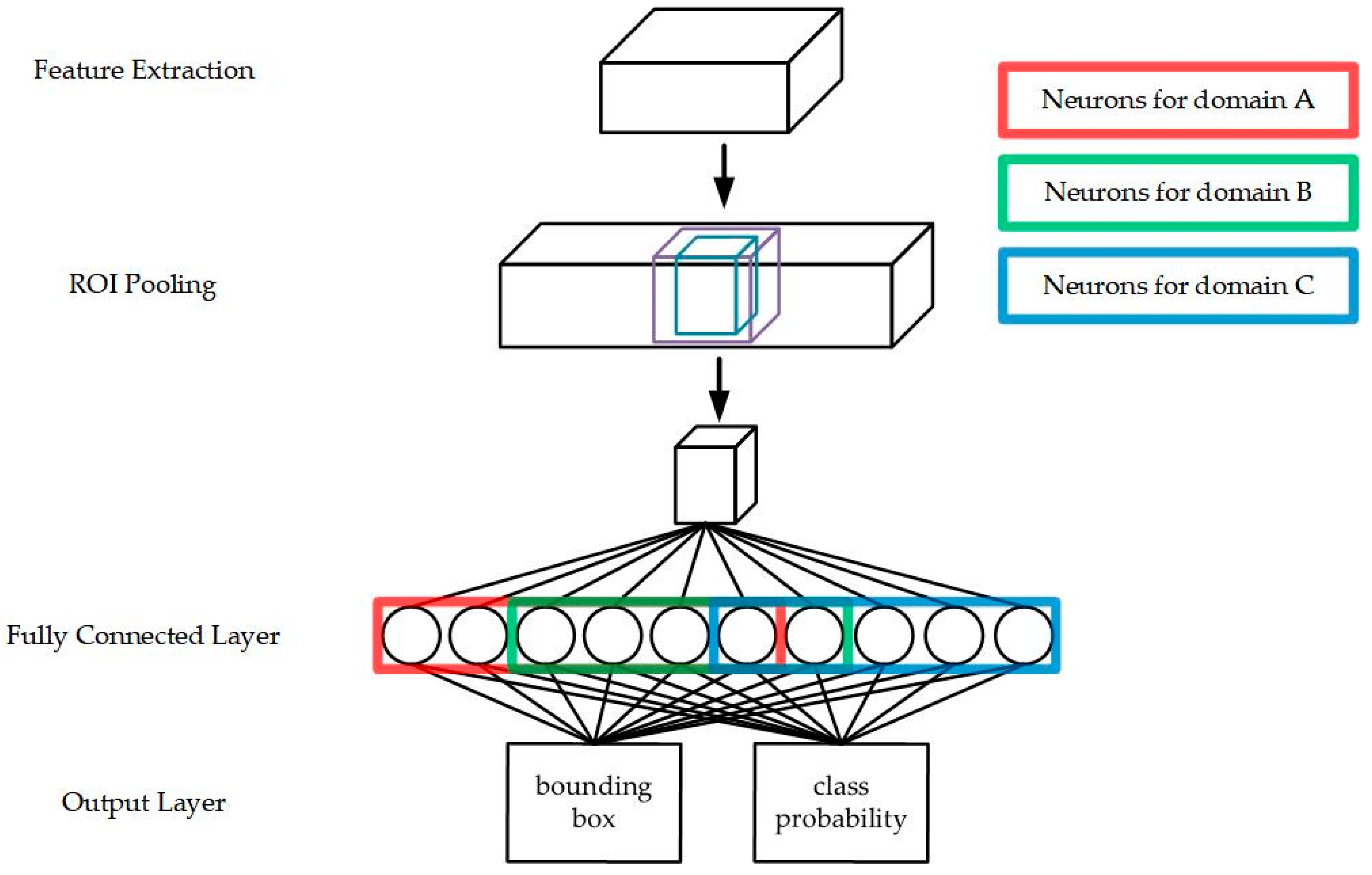
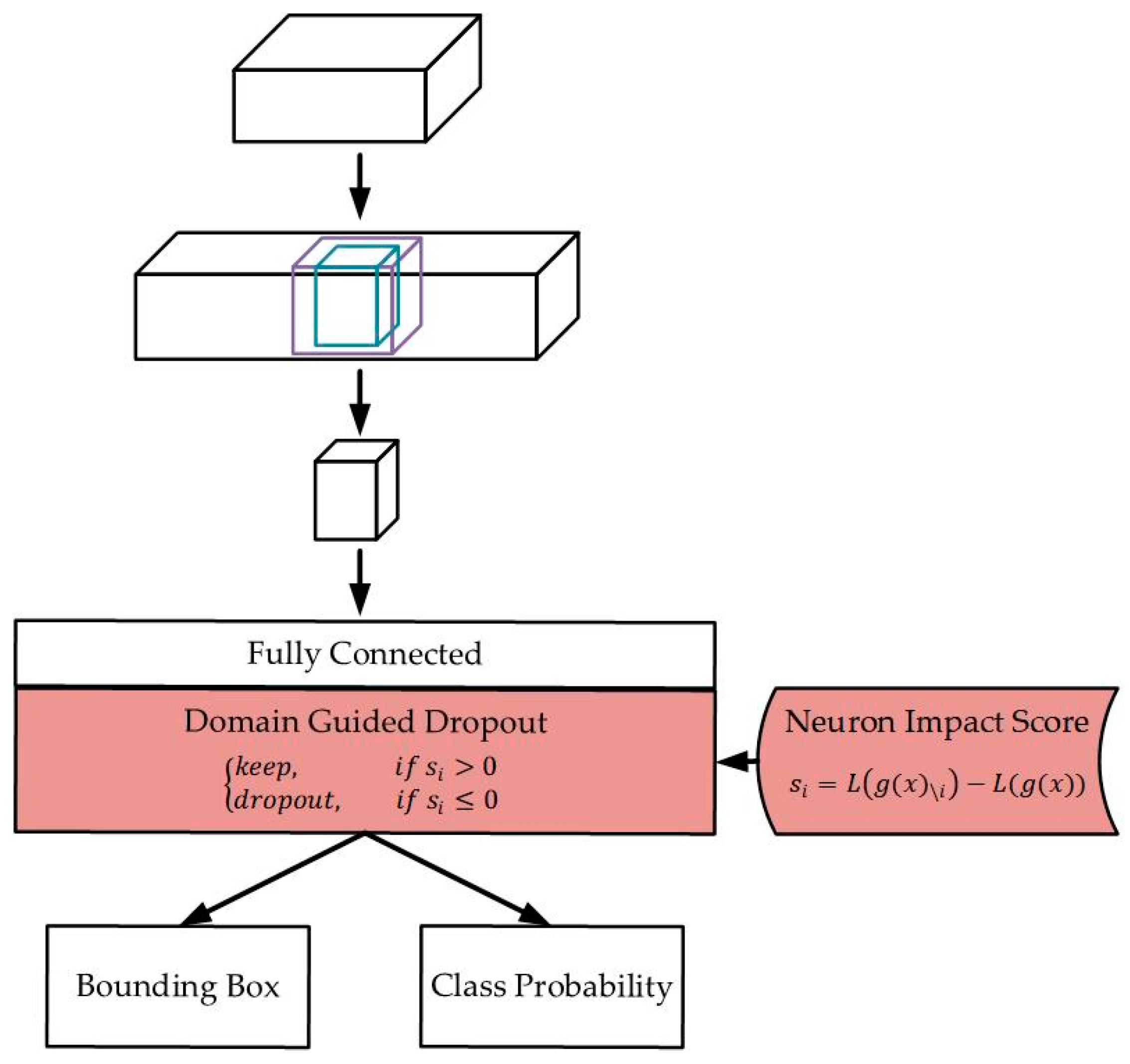
Table 3. Two aspects were analyzed in this table. First, the performance of the MS-CNN and MDJL models that were trained using the same multidomain dataset for each evaluation dataset is identified by using a thick box. We investigated the network trained using the three datasets of cpd, cd, and pd, and it was determined that the average miss rate evaluated for PEST09 and DroneFJU using MDJL was higher than that of MS-CNN. None of these datasets used data augmentation to balance the sample size difference between the domains. Therefore, we speculate that even if our method can effectively divide the network into several small networks for fine-tuning on the basis of the response to each domain, as shown in
Figure 14, shared and generalized neurons will still exist across the domains. These neurons are more susceptible to larger datasets (Caltech) during training and are dominated by these datasets, thus affecting the network performance on smaller datasets (PETS09 and DroneFJU). However, suppose we use the same domain combination of cp*d*, cd*, and p*d* for data augmentation. In this case, this problem is not encountered, which establishes that our assertion is reasonable. To optimize and balance the network’s performance on each dataset, the number of samples of each domain in the multidomain dataset must also be balanced. Therefore, when discussing other phenomena, we will use the data augmentation model.
Second, the three blocks in
Table 3 that are identified by using a gray color represent the network trained by each multidomain dataset. The performance on the test set of the dataset is interesting in each case. The results indicate that the model was trained using two datasets, cp* and cd*. It is foreseeable that the evaluation results of these models on the datasets, which have never been observed, are not satisfactory. However, the data show that MDJL-cp* exhibits an improvement of 2.7% in the average miss rate compared with MS-CNN-cp* and that MDJL-cd* is 1.7% better than MS-CNN-cd*. This improvement is not insignificant, so we believe that the model trained by MDJL has better generalizability.
However, if we examine the MS-CNN-p*d*and MDJL-p*d*models trained using the p*d* dataset, this phenomenon is not observed, and the evaluation performance of the two networks is similar. This result is not surprising given that the ability to generalize originates from similar situations that are learned or seen, from which knowledge is extended. The two datasets, PETS09 and DroneFJU, differ from the Caltech dataset used for the evaluation of the shooting angle and the shooting methods, which results in different image characteristics in the dataset. Therefore, neither MS-CNN nor MDJL can be used in PETS09, and DroneFJU learned how to correctly evaluate the Caltech dataset to obtain the presented results.
According to the results of this experiment, it is evident that the proposed method can effectively improve the impact of training networks using a multidomain dataset. Furthermore, using data augmentation to balance the number of samples in each domain in a multidomain dataset can increase the effectiveness of MDJL. Finally, MDJL appears to have better generalizability than MS-CNN does.
4.2. Analysis of Multidomain Joint Learning Method
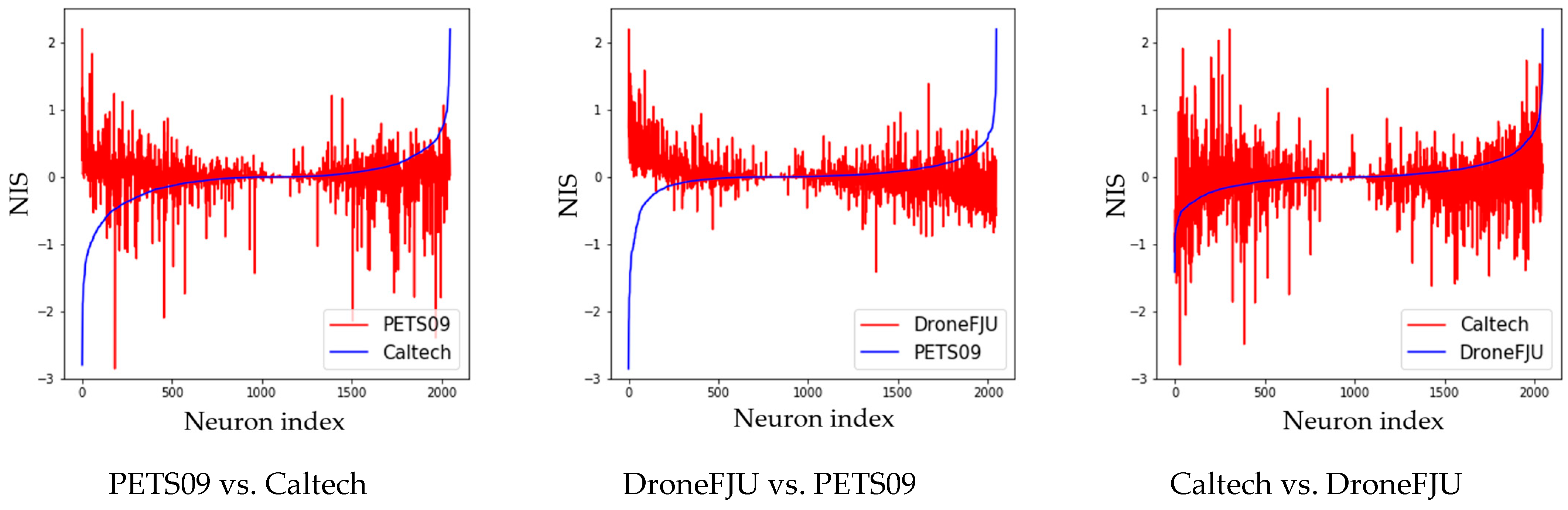
In this experiment, the NIS calculated using MDJL is represented as a chart to analyze the relationship between the subnetworks after segmentation. First, we investigated whether there was a relationship between the response degree (NIS) of each neuron to different domains in the network. Three sets of comparisons were conducted, each of which selected two domains, A and B. We then sorted the NIS of domain A from small to large, arranged domain B in the same order, and represented the results as a line chart. As shown in
Figure 15, domain A is the blue curve, and domain B is the red curve. The three results in the figure show that the NIS among the various domains does not exhibit a correlation, which means that the neurons in the network that strongly respond to each domain are not the same.
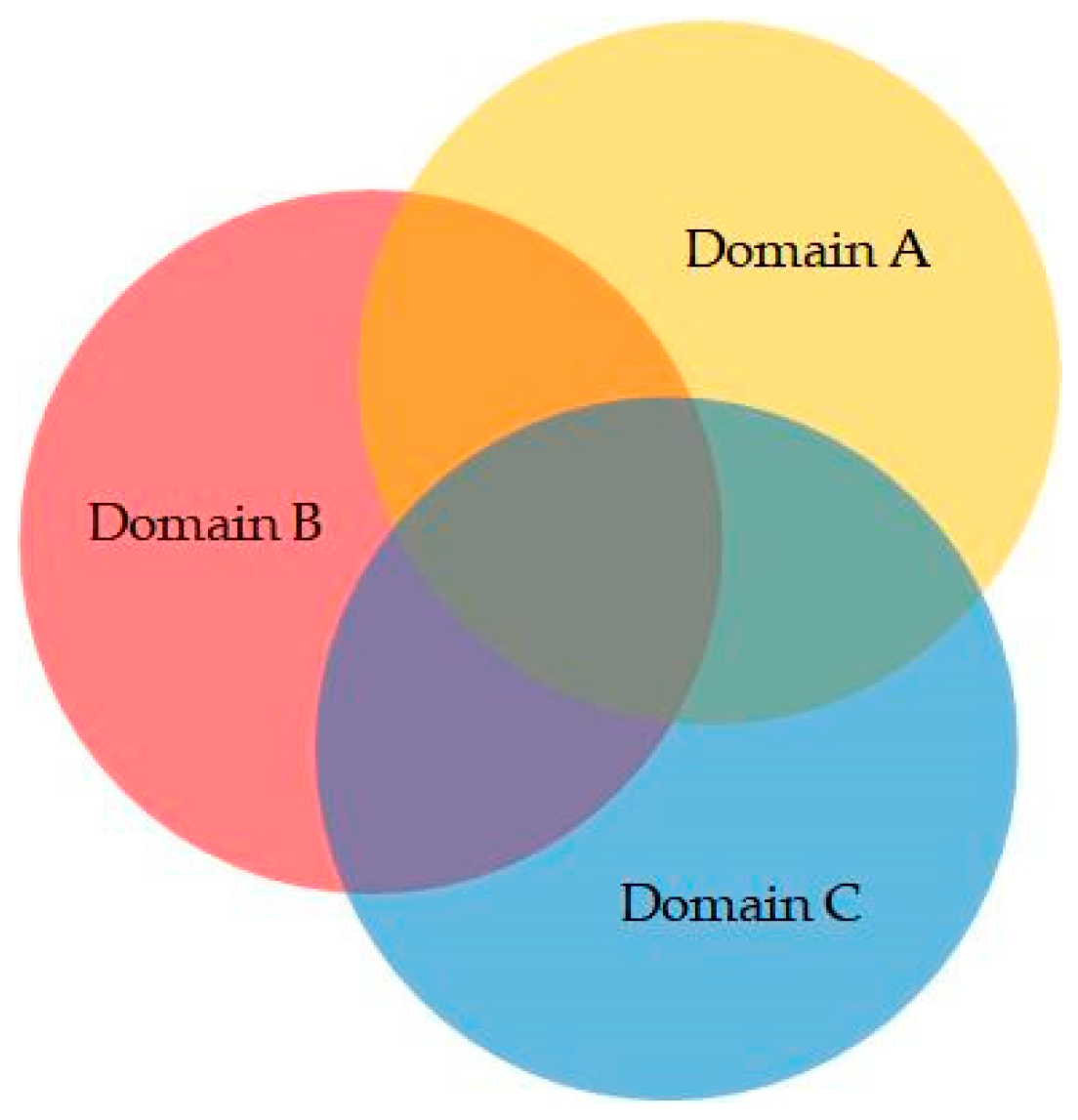
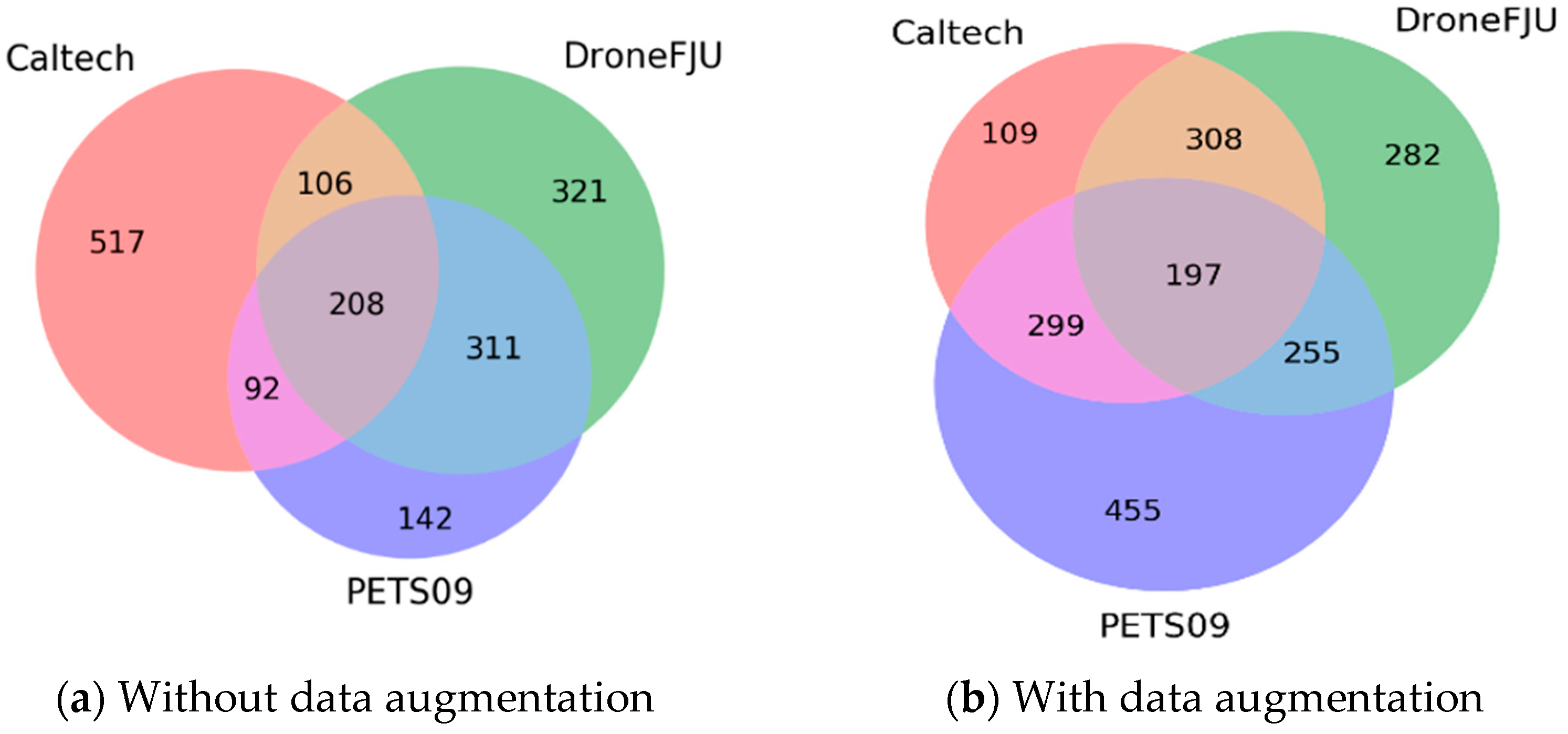
Next, we analyze the degree of overlap in the subnetworks divided according to the deterministic rule (NIS > 0), according to the NIS of each domain, and the results are represented as a Venn diagram.
Figure 14 shows the distribution of neurons according to the models trained using the datasets with and without data augmentation.
First, in
Figure 14a, a dataset without data augmentation is used to train the model, and the distribution of neurons is allocated to more or fewer neurons according to the training sample size of each domain.
Thus, a large domain (e.g., Caltech) is assigned to more neurons, and small domains (e.g., PETS09) are assigned to fewer neurons. This phenomenon is consistent with the observations summarized in
Table 3. Therefore, large domains dominate the network. In
Figure 14b, the neurons are distributed according to the complexity of the domain because of data augmentation. PETS09 was used because the pedestrians in the video were sometimes dense and sometimes loose. The shooting angle is a downward projection; it can easily cause pedestrian deformation, and the situation is complex. Therefore, when the network allocates neurons, it provides more neurons to the PETS09 domain. In contrast, although the scene at Caltech is relatively open because the camera’s shooting angle is forward facing and the situation when pedestrians appear is relatively simple, the network allocates fewer neurons to this domain.
In addition, from
Figure 15, it is evident that although there is no correlation between the NIS of each domain, there are still neurons in
Figure 14 included in the multidomain subnets. We believe that these neurons are responsible for common information processing across domains. Moreover, the nonoverlapping parts are responsible for the unique information processing of the domain, thereby achieving the concept of divide and conquer. From the aforementioned two results, it is evident that MDJL can effectively divide the network into several subnetworks according to the degree of the neuron response to different domains. It includes dedicated neurons for each domain and neurons shared among the domains.
4.3. Domain-Oriented Fine-Tuning Experiments and Analysis
In this experiment, we used the previously trained model MDJL-cp*d* to perform further fine-tuning and obtain the model’s evaluation results for each dataset, as summarized in
Table 4. The gray background is the performance evaluated by the model trained using the single-domain dataset in the corresponding dataset. Therefore, for the evaluation, only Caltech assessed MS-CNN-c, PETS09 only assessed MS-CNN-p, and MS-CNN-d only used DroneFJU. We named this model MDJL-ft-cp*d*.
According to
Table 4, it is evident that the average miss rate of the model after fine-tuning for the evaluation using the Caltech dataset is 10.7807%, which is better than that of MS-CNN’s 11.0483%. This is a slight improvement on PETS09 and DroneFJU. These results show that domain-oriented fine-tuning can effectively strengthen the domain-exclusive neurons and improve the network model. Therefore, we discuss in the next section how to adjust the parameters of domain-oriented fine-tuning.
There are three adjustable parameters for domain-oriented fine-tuning. The first is the T parameter in Equation (3), which we call the sigmoid scaler. The second is the R parameter in Equation (8), which we refer to as the reserve constant. The third is the number of iterations during fine-tuning training. We separately explore how the adjustment of these three parameters affects the performance of the network. The parameters that did not change in the following experiments were preset values: T = 1.0, R = 0, and iteration number = 20,000.
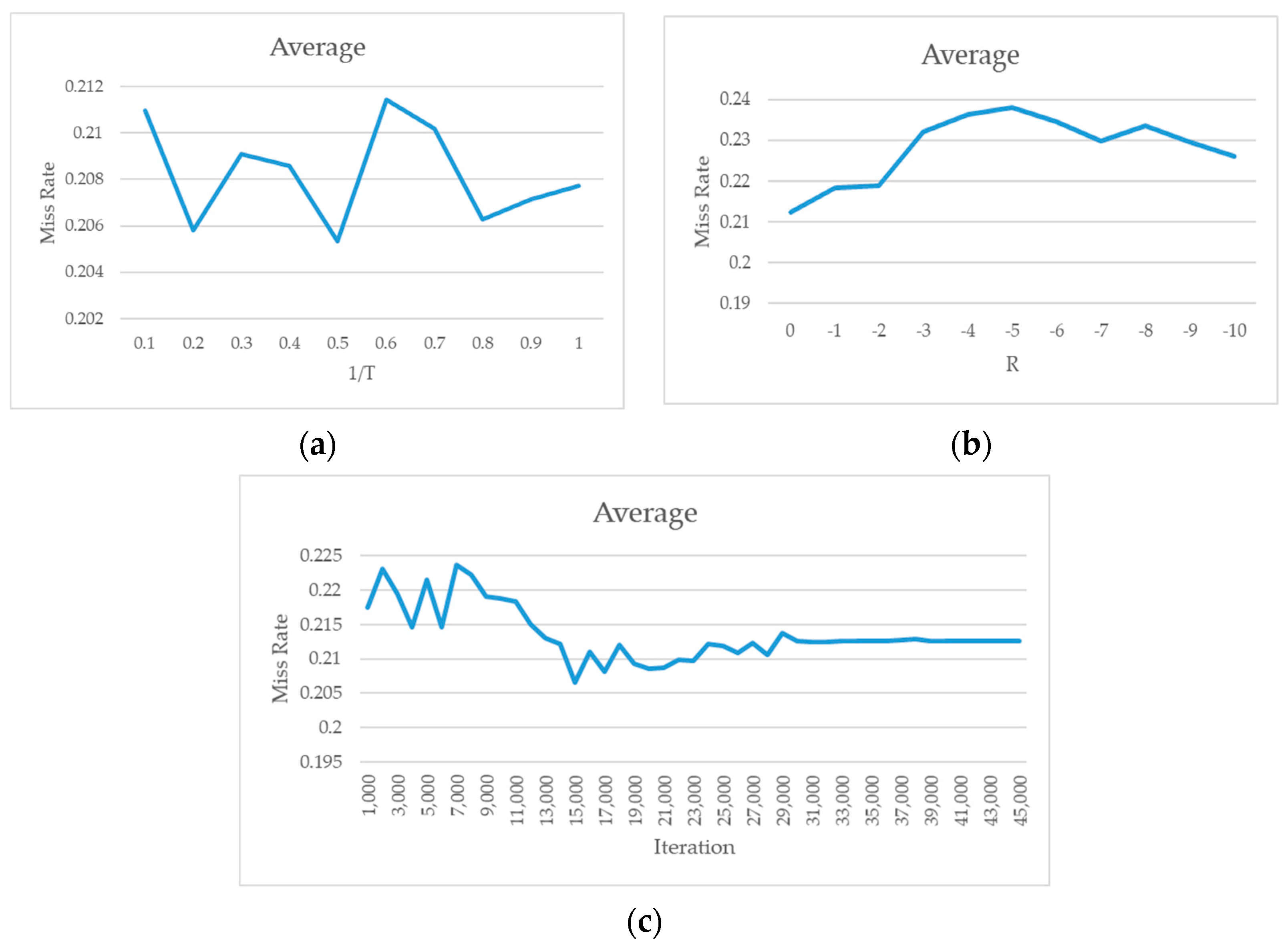
First, we discuss the T parameter in Equation (3), which is responsible primarily for adjusting the influence of the eNIS on the reserve rate of domain-exclusive neurons during fine-tuning. When , stochastic DGD is converted to deterministic DGD because it can convert the result of Equation (3) to only 1 (eNIS ≥ 0) or 0 (eNIS < 0). In contrast, if , regardless of the value of eNIS, the result of Equation (3) is always 0.5, causing stochastic DGD to degenerate back to regular dropout. For convenience, we used the value as the adjustment target in the following experiments.
We adjusted
from 0.1 to 1.0 and trained 10 models using 0.1 as the interval in the experiment. Each trained model was evaluated using the Caltech test set, PETS09, and the DroneFJU datasets, and the average of the results was calculated. The experimental results are shown in
Figure 16a.
Figure 16a indicates that there is no consistent trend in the performance of different
parameters for each dataset. However, if we observe the overall average performance in
Figure 16a, we find that the relationship between the parameter T and the miss rate is slightly low, in the range of 0.2–0.5. Thus, the lowest point was at
= 0.5. According to
Section 4.2, the maximum NIS value is approximately 2. Therefore, by applying Equation (3), the highest reserve rate of domain-exclusive neurons in fine-tuning is 73.11%.
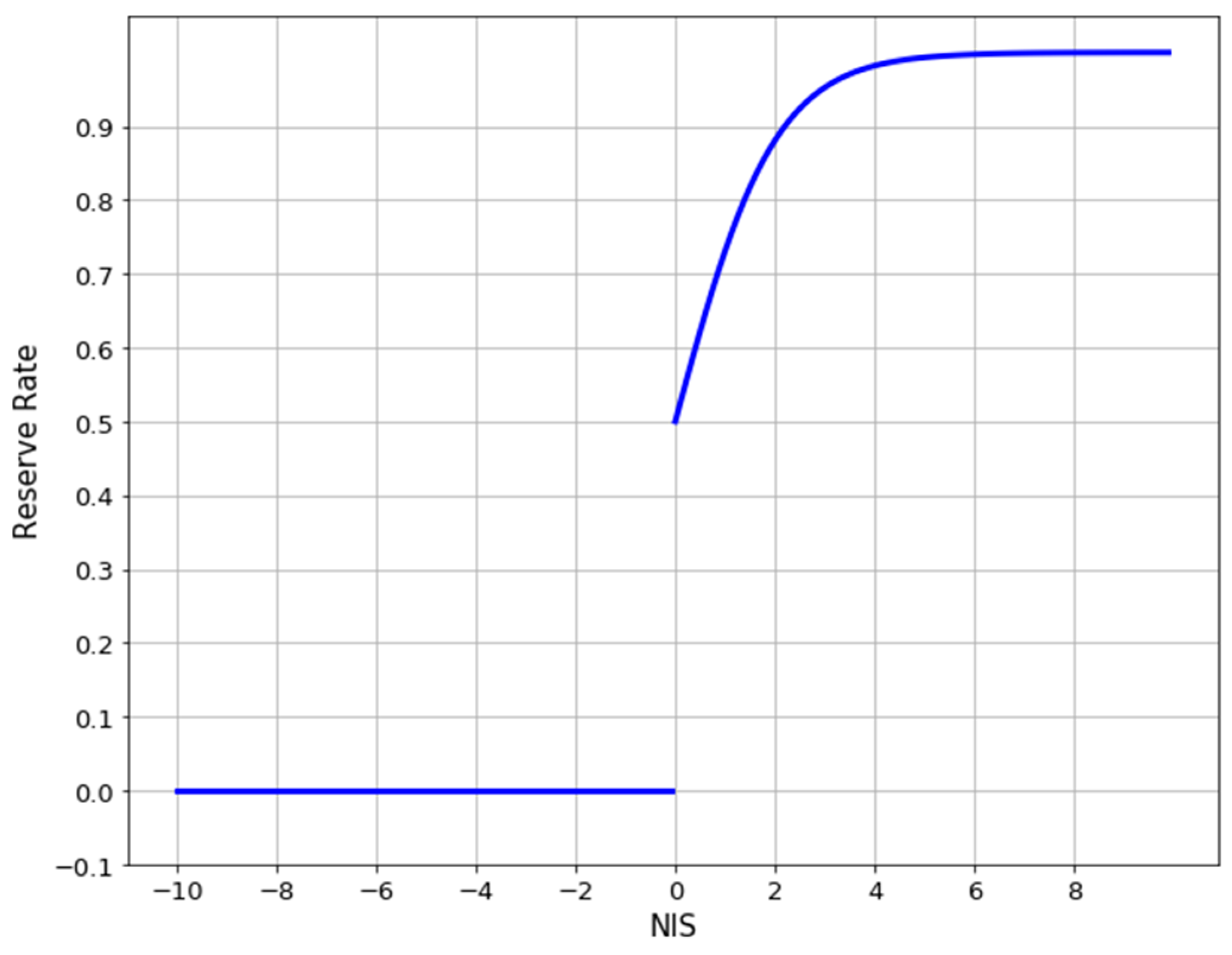
The second parameter to be discussed is the R parameter in Equation (8), namely the reserve constant. This parameter is responsible for adjusting the reserve rate of neurons that do not belong to domain-exclusive neurons in domain-oriented fine-tuning and is a number less than 0. We adjusted the parameter R from 0 to −10, with −1 as the interval, and changed it 11 times. Each trained model was evaluated by using the Caltech test set, PETS09, and the DroneFJU datasets, and the average was calculated. The experimental results are shown in
Figure 16b.
In
Figure 16b, we found that the average miss rate obtained using the evaluation had the lowest point: 0. When
, the reserve rate of the non-domain-exclusive neurons was 50%. Thus, this value was too close to the reserve rate of the domain-exclusive neurons obtained in the T-parameter experiment (73.11%). It performed best on the PETS09 dataset and poorly on the other datasets. Therefore, it seems that
is the optimum value, with a reserve rate of 26.89%. This shows that the R parameters should not be too small and that non-domain-exclusive neurons should still have some fine-tuning space.
According to the aforementioned two experiments, the selection of the T and R parameters should be dominated by T and supplemented by R. The choice of T should refer to the maximum value of the NIS of each domain, such that the reserve rate is maintained at approximately 75%, which is in this experiment. However, the choice of R should set the reserve rate of non-domain-exclusive neurons at approximately 25%, which is in this experiment.
Finally, we discuss the iteration times of fine-tune training. Although fine-tuning has been widely used in many studies, there is no practical method for estimating the number of iterations that should be introduced in the fine-tuning stage. Therefore, in this experiment, we observed the performance of the model that was trained via domain-oriented fine-tuning for different iterations of each dataset on the basis of the investigation. In this experiment, 1000 iterations were used as units to increase the number of iterations to 45,000. A total of 45 models were trained. The base learning rate was 0.00002; for every 10,000 iterations, the learning rate was reduced by a factor of 0.1. Each trained model was evaluated using the Caltech test set, PETS09, and the DroneFJU datasets, and the average was calculated. The experimental results are shown in
Figure 16c.
According to the experimental results shown in
Figure 16c, we found that the miss rate of the model was minimal when the number of iterations was 15,000. If the training was continued, the miss rate started to increase. The miss rate remained constant after approximately 30,000 iterations. This phenomenon may be because of the reduction of the learning to
, which may be too low, rendering the network unable to effectively continue learning. The optimal fine-tuned iteration time was set as 15,000.
On the basis of the aforementioned three experiments, we selected the best parameters to train the new model and evaluated its performance on the test set for the three pedestrian detection datasets. The chosen parameters were
and
, and the iteration number was 15,000. R was −2 because a value of 0.5 was chosen for
to maintain a reserve rate of 26.89%;
must be satisfied. Using the above formula, we obtain a new
. The model was named for the best fine-tuning parameter as MDJL-ft-bv-cp*d*, and the results are listed in
Table 5. Thus, the evaluation results in the gray background are the same as those in
Table 4. The evaluation results were obtained by training the model using the single-domain dataset in the corresponding dataset.
Table 5 summarizes that the model trained with the best parameters improved by approximately 1% in each domain, which demonstrates the importance of choosing the correct parameters for fine-tuning.
4.4. Comparison with State-of-the-Art Methods
The experiment was conducted in two parts. The first part compares the performances of the models trained using single-domain and multidomain datasets to highlight the associated advantages. The second part compares the proposed method with several state-of-the-art methods.
Table 6 indicates that in the past, when training a machine-learning method or deep learning network, we often chose a training dataset that was commonly used in the research community, such as the Caltech or INRIA datasets, to train the model. Given that the video data contained in these datasets generally have the same characteristics, such as the shooting environment, shooting angle, and equipment used, this type of dataset is called a single-domain dataset.
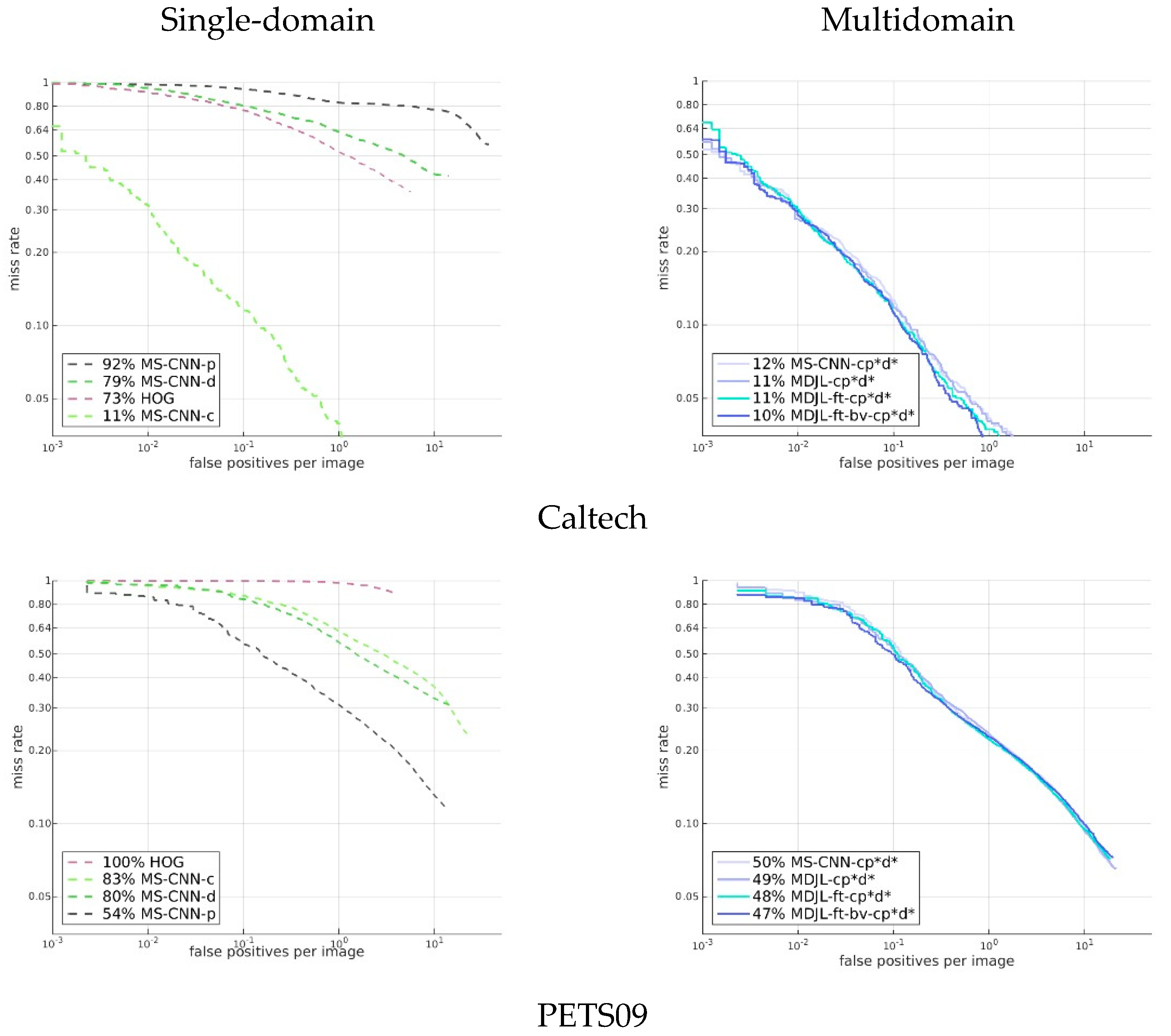
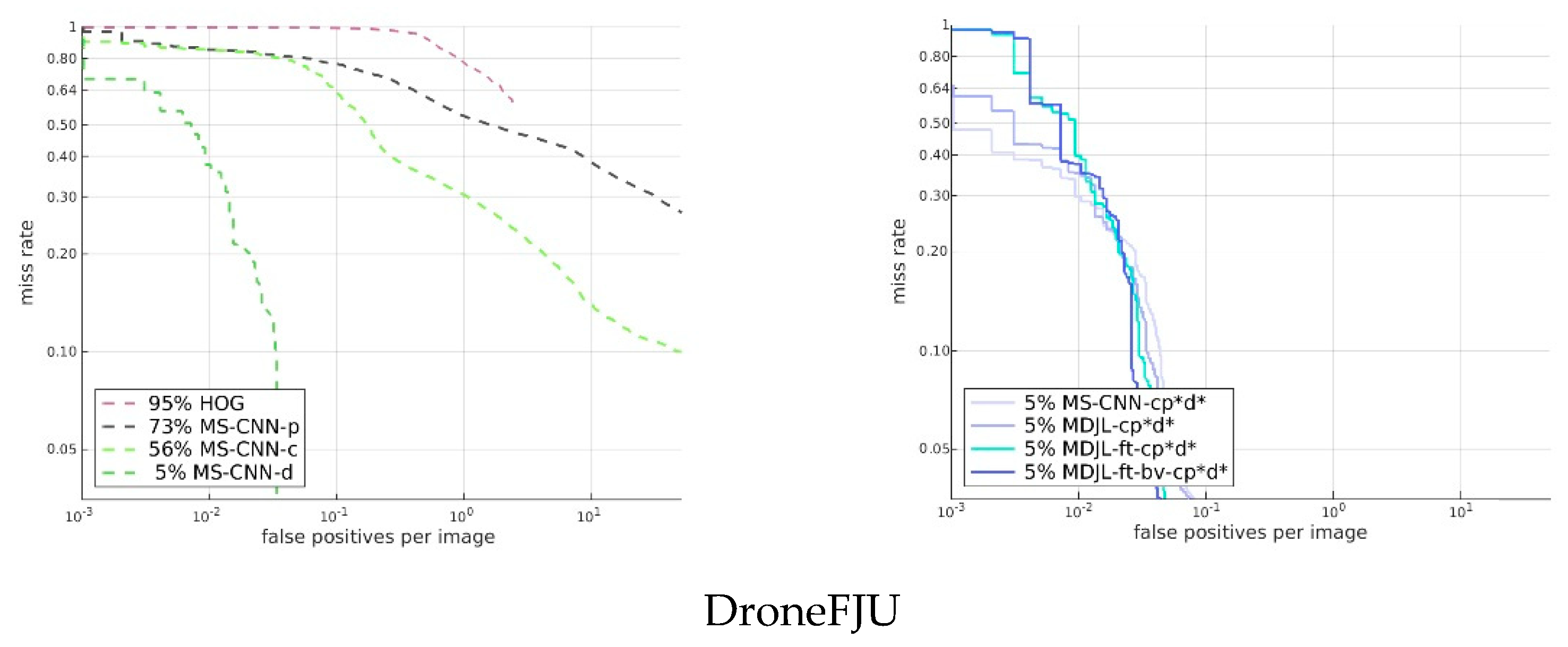
Figure 17 shows the results for the cross-domain evaluation between several pedestrian detection models that were trained using a single-domain dataset and pedestrian detection models trained using a multidomain dataset. The dotted lines in the figure represent the results for a part of the single-domain dataset. We used HOG trained using the INRIA dataset as the traditional baseline method. In addition, we used the Caltech dataset, PETS09, and the DroneFJU datasets trained using MS-CNN as the baseline of the deep learning network. The solid lines in the figure represent the results for a part of the multidomain dataset. The MS-CNN and MDJL models were used, which were trained on the cp*d* dataset. For the evaluation, we used the Caltech, PETS09, and DroneFJU test sets.
The results show that HOG was not observed in any dataset used in the evaluation in the training stage, so the effects on each dataset are not ideal. If we observe other models, we find that for the model trained using the single-domain dataset (dashed line), only the model trained with the training set of the same dataset performed better, and the rest were not ideal. For example, the average miss rate of MS-CNN for the Caltech dataset was 11%, but the average miss rates of MS-CNN-d and MS-CNN-p were as high as 79% and 92%, respectively. This result shows that it is difficult to achieve cross-domain generalization using single-domain dataset training. Therefore, we believe it is essential to use multidomain dataset training.
Figure 17 shows that the model (solid line) trained with the multidomain dataset has comparable performance to the model (dotted line) trained using the corresponding single-domain dataset, regardless of the dataset. For example, in the evaluation results for the DroneFJU, the average miss rates of the three models, MS-CNN-cp*d*, MDJL-cp*d*, and MS-CNN-d, were similar. If we examine the evaluation results of PETS09, the average miss rates of MS-CNN-cp*d* and MDJL-cp*d* using the multidomain dataset are 4% and 5% lower than that of MS-CNN-p, respectively. These results show not only that using multidomain dataset training allows the model to have cross-domain generalization capabilities but also that domains can occasionally have complementary effects.
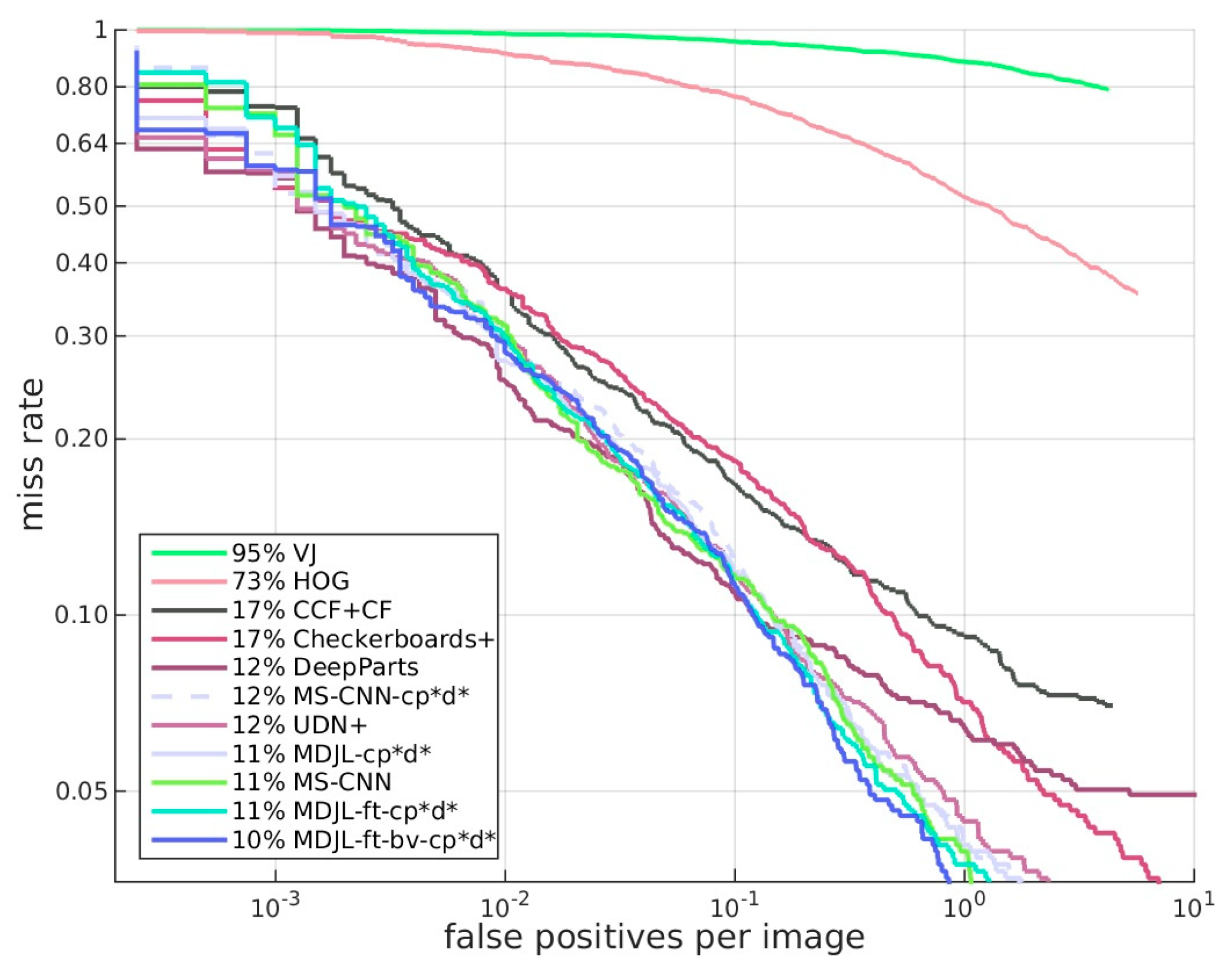
Next, we compared the proposed method with current state-of-the-art approaches. Results were obtained for MS-CNN, MS-CNN-cp*d*, and MDJL-cp*d*. The data for the other algorithms were obtained by using the data on the Caltech pedestrian detection benchmark website. The classification methods used for each method and the dataset used for training are listed in
Table 6.
Receiver-operating characteristic (ROC) analysis is a valuable tool for evaluating the performance of diagnostic tests and the accuracy of a statistical model’s outcomes. We compared MDJL with state-of-the-art methods and drew the ROC curve shown in
Figure 18. From
Figure 18 and
Table 6, it is evident that although MDJL used a multidomain dataset to train the network, it can still maintain the performance of the state-of-the-art pedestrian detection benchmark and can beat MS-CNN after fine-tuning.
4.5. Pedestrian Tracking
In this experiment, we considered pedestrians as the primary tracking objects. In the experiment, we used the four videos from the MOT Challenge 2015 as the training and test data. The training part of the MDP tracker used S2L1 in PETS09 and TUD-Stadtmitte [
38] (
Table 7), whereas the experimental evaluation used S2L2 in PETS09 and TUD-Crossing as test videos.
In this experiment, two videos were selected in PETS09, namely S2L1 and S2L2, for training and testing, respectively. Both videos were acquired in an open outdoor environment, and the shooting angle was from the perspective of a fixed surveillance camera with a downward projection. In the PETS09 video set, several crowded groups of pedestrians walk freely, and there are numerous occlusions between the pedestrians, which leads to difficulty in detection or tracking.
Figure 19a is a screenshot of a region of the pedestrian scene in the video set.
The TUD-Stadtmitte and TUD-Crossing are outdoor street scenes, as shown in
Figure 19b. The difference compared with PETS09 is that the shooting angle is fixed, and image acquisition is performed from a forward projection. Many pedestrians are observed walking along the street in the video. However, because of the forward projection, the occlusion between pedestrians is more significant compared with the surveillance view with a downward projection, which makes it more difficult to track the trajectory and associate the bounding box.
In the performance evaluation, multiple evaluation criteria [
39] were used for the MOT benchmark [
40], including multiobject tracking accuracy (MOTA), multiobject tracking precision (MOTP), ID switch, false positive (FP), false negative (FN), mostly tracked (MT), and mostly lost (ML).
FP denotes the total number of marking errors in the bounding box, and FN is the total number of unmarked ground truths. The ID switch is an important criterion for evaluating multiobject tracking, because the primary goal of this process is to obtain the object ID and monitor the trajectory. The definition of MOTA is given in Equation (11). MOTA is used primarily to evaluate the tracking accuracy of the object’s trajectory. The referenced error-rate scores include the FN, FP, and ID switches, which are useful indicators. Compared with MOTA, MOTP does not consider the erroneous result of the ID switch but evaluates the tracker’s accuracy in estimating the position and size of the object. The MOTP is calculated using Equation (12). First, the total error between the actual and estimated positions of all targets in the frames was counted and averaged.
is the number of objects in the ground truth of the
t-th frame, and
is the overlapping rate of the bounding box of the
i-th target in the
t frames. Next, MT and ML were used to evaluate the integrity of the trajectory; however, the ID switch was not considered. If the trajectory time of an object was successfully tracked for more than 80%, then the trajectory was classified as MT; if it was only successfully tracked for less than 20%, then the trajectory was classified as ML.
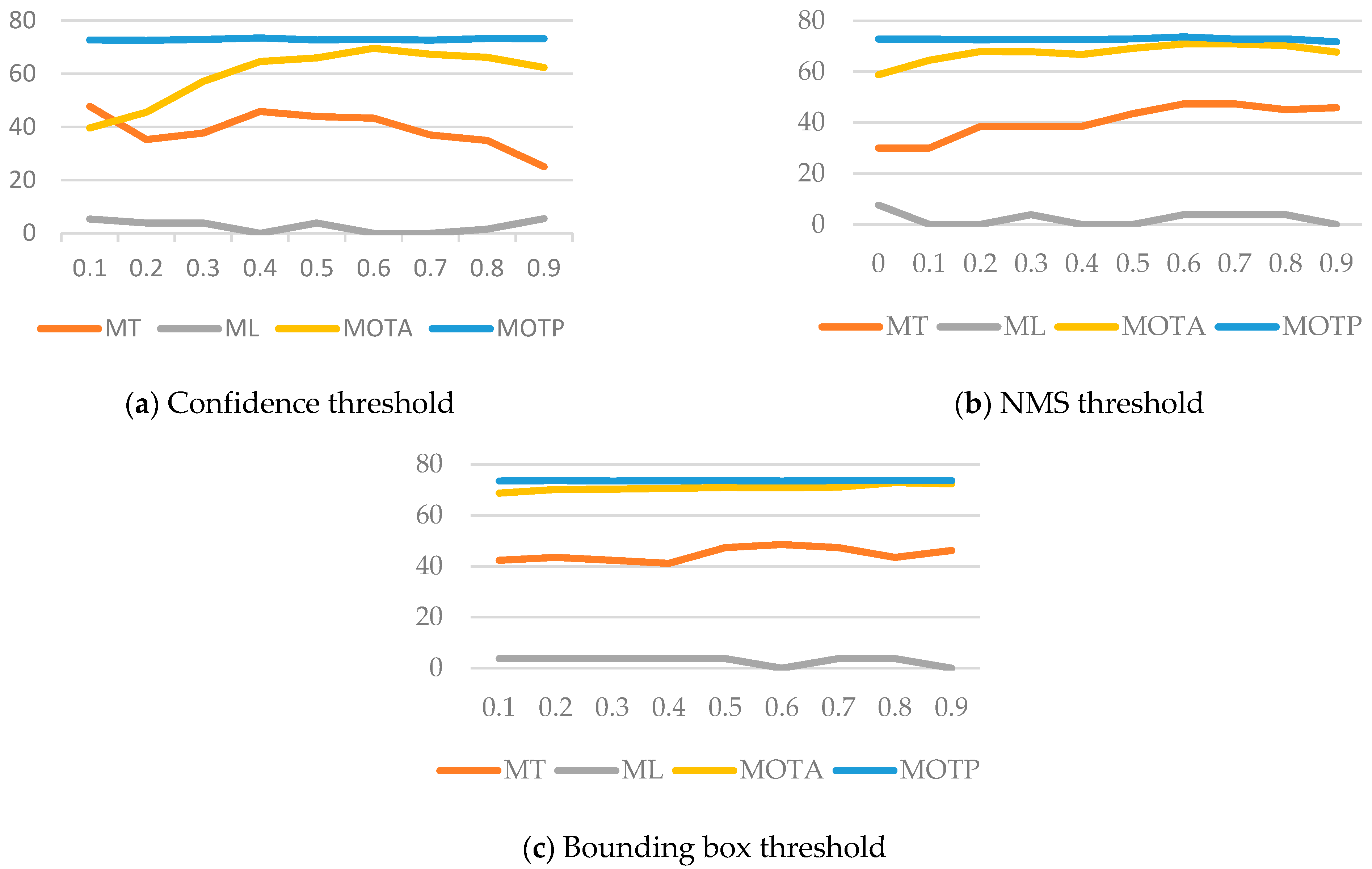
In this experiment, we determined the system’s best parameters by observing the influence of each parameter on the final tracking result. We adjusted the parameters to filter the pedestrian detection results: confidence threshold, nonmaximum suppression (NMS) threshold, and the bounding box threshold (parameter for pedestrian tracking). We used PEST09-S2L2 and TUD-Crossing as test videos and averaged the results.
The first parameter of pedestrian detection is the confidence threshold, which is used primarily to filter the bounding box obtained via pedestrian detection. This parameter affects the number of FP and FN. When the threshold is high, the detection results have a low FP, but it is relatively easy to obtain a higher FN. The effect of this threshold adjustment on the tracking results is shown in
Figure 20a. The results show that this parameter has little impact on MOTP. However, when the threshold is too high or too small, MOTA and MT begin to decline, whereas ML increases. It is speculated that when FN is higher than a threshold value, the tracker is unable to associate with the target, and the trajectory is broken. Thus, the MT decreases, and the ML increases. The level of MOTA depends on the number of FN and FP. It was determined that the optimal parameter was 0.6, which resulted in the highest MOTA.
The second parameter for pedestrian detection was the NMS threshold. This parameter affects the accuracy and the quantity of the bounding box positions. The effect of this threshold adjustment on the tracking results is shown in
Figure 20b. The results show that when the threshold is high, MOTP decreases slightly, and MT increases simultaneously. It is speculated that when the threshold is high, some bounding boxes have too many redundant detection results because of the inability to merge, which increases the number of FPs and decreases the value of MOTP. Conversely, when the threshold is lower, most bounding boxes obtain the best detection position. However, if multiple objects are too close, the bounding boxes of various objects may merge, thereby increasing the number of FN. Therefore, the MOTP will be higher, but the MT will be lower. Therefore, the optimum parameter was determined to be 0.6, which maintained the highest MOTA and MOTP.
Finally, we adjusted the pedestrian tracking parameter bounding box threshold. When the overlap rate between the pedestrian position predicted by the tracker and the bounding box was higher than this threshold, the algorithm associated the bounding box with the tracker and then continuously performed tracking. This parameter directly affects the tracking accuracy. The effect of this threshold adjustment on the tracking results is shown in
Figure 20c. The results show that MT increases to a specific level when the threshold increases and then subsequently decreases. It is speculated that the tracker is more prone to associate errors when the threshold is low. Therefore, both MT and MOTA were relatively low. The tracker can associate the correct bounding box more accurately when the threshold increases. However, when the threshold is high, the tracker has a low error tolerance because of the threshold; therefore, both MT and MOTA decrease. Thus, the optimal parameter was chosen to be 0.8, which maintained the highest MOTA.
After adjusting the optimal parameters, the system was referred to as MDP_MDJL. Next, we compared our system with the current state-of-the-art methods in several experiments. The test videos used were PETS09-S2L2 and TUD-Crossing. Our method was compared with the six most advanced tracking techniques using the MOT benchmark, including two offline tracking methods, TSML_CDE [
41] and DMT [
42], and four online tracking methods, CDA_DDAL [
43], AMIR [
44], APRCNN [
45], and MDP [
33].
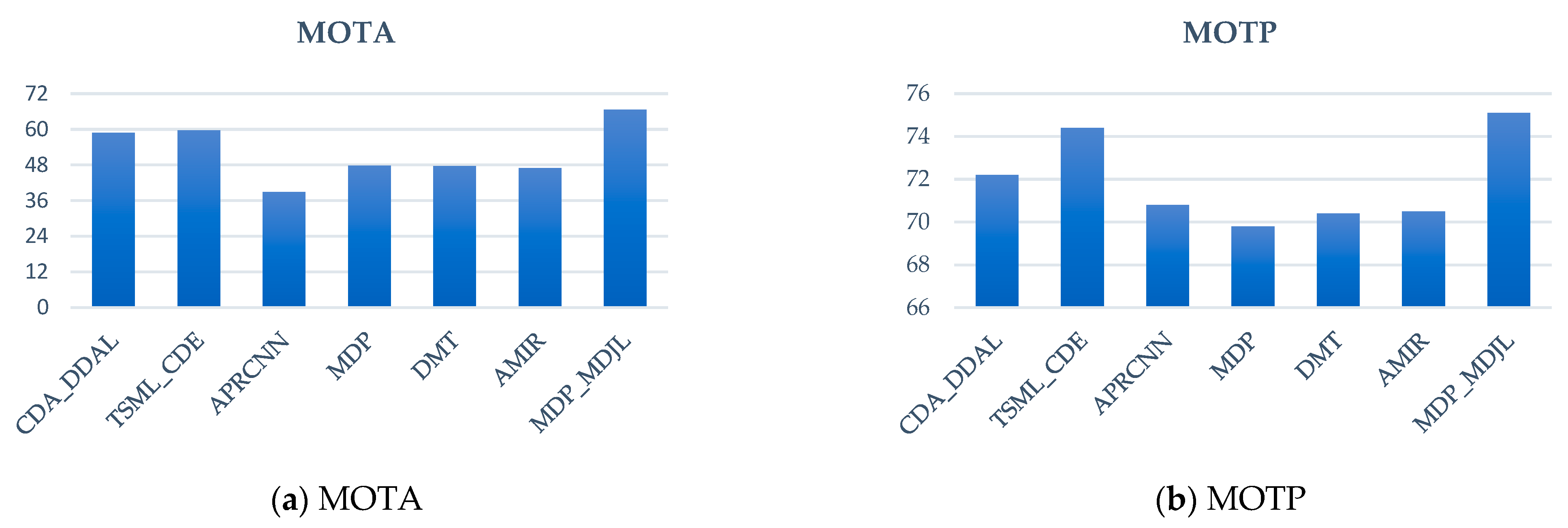
The results for PETS09-S2L2 are shown in
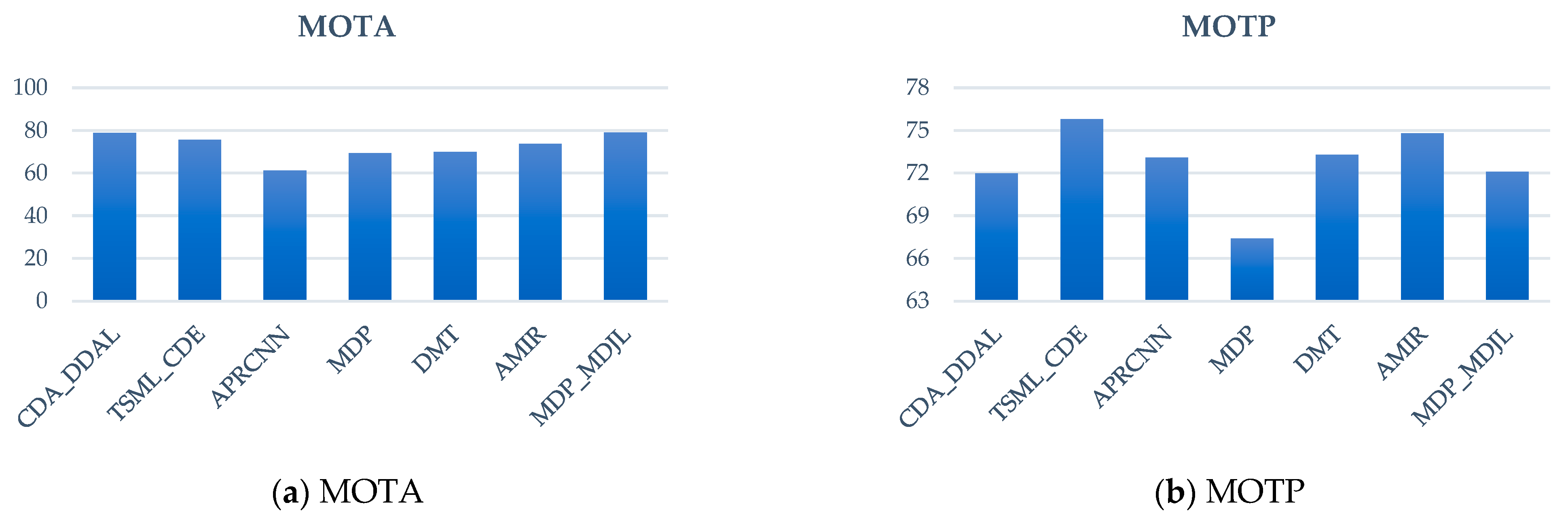
Figure 21, which indicates that the proposed approach has the best MOTA and MOTP compared with the other methods. Compared with MDP, MOTA and MOTP increased by 18.8% and 5.3%, respectively. The result for the TUD-Crossing is shown in
Figure 22; our approach has the best MOTA compared with the other methods. Compared with MDP, MOTA and MOTP increased by 9.7% and 4.7%, respectively.
Overall, the proposed method performed best on the MOTA indicator in the two experimental video scenarios. This was primarily because of the high accuracy of MDJL in the case of multiple domains. In addition, optimizing the parameters allowed the detector to obtain the most accurate position, thus yielding the best performance.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}