
Bioinspired Environment Exploration Algorithm in Swarm Based on Lévy Flight and Improved Artificial Potential Field

 ,
, 

Abstract
:1. Introduction
- (1)
- The proposed LF-APF algorithm applies the LF search mechanism at the swarm level. Combining the advantages of LF and APF can enable agents to efficiently explore the environment through simple and natural random walking like natural creatures.
- (2)
- The improved APF method makes agents follow the virtual leader, maintain a certain distance from each other, and move in an orderly manner in the specified task area, autonomously changing their formations to traverse complex obstacles without colliding with them.
- (3)
- Experimental validations on E-puck2 robots are conducted. In particular, the performance of the agent’s swarm movement and the fulfilment of environmental exploration tasks are evaluated in comparative studies.
2. Problem Definition
3. Roaming Strategy: Lévy Flight
4. Flocking Based on Improved Artificial Potential Field Method
4.1. Method of Following the Virtual Leader
4.2. Repulsion
4.3. Avoid Obstacles and Avoid Moving out of Boundaries
4.4. Final Equation of Desired Speed
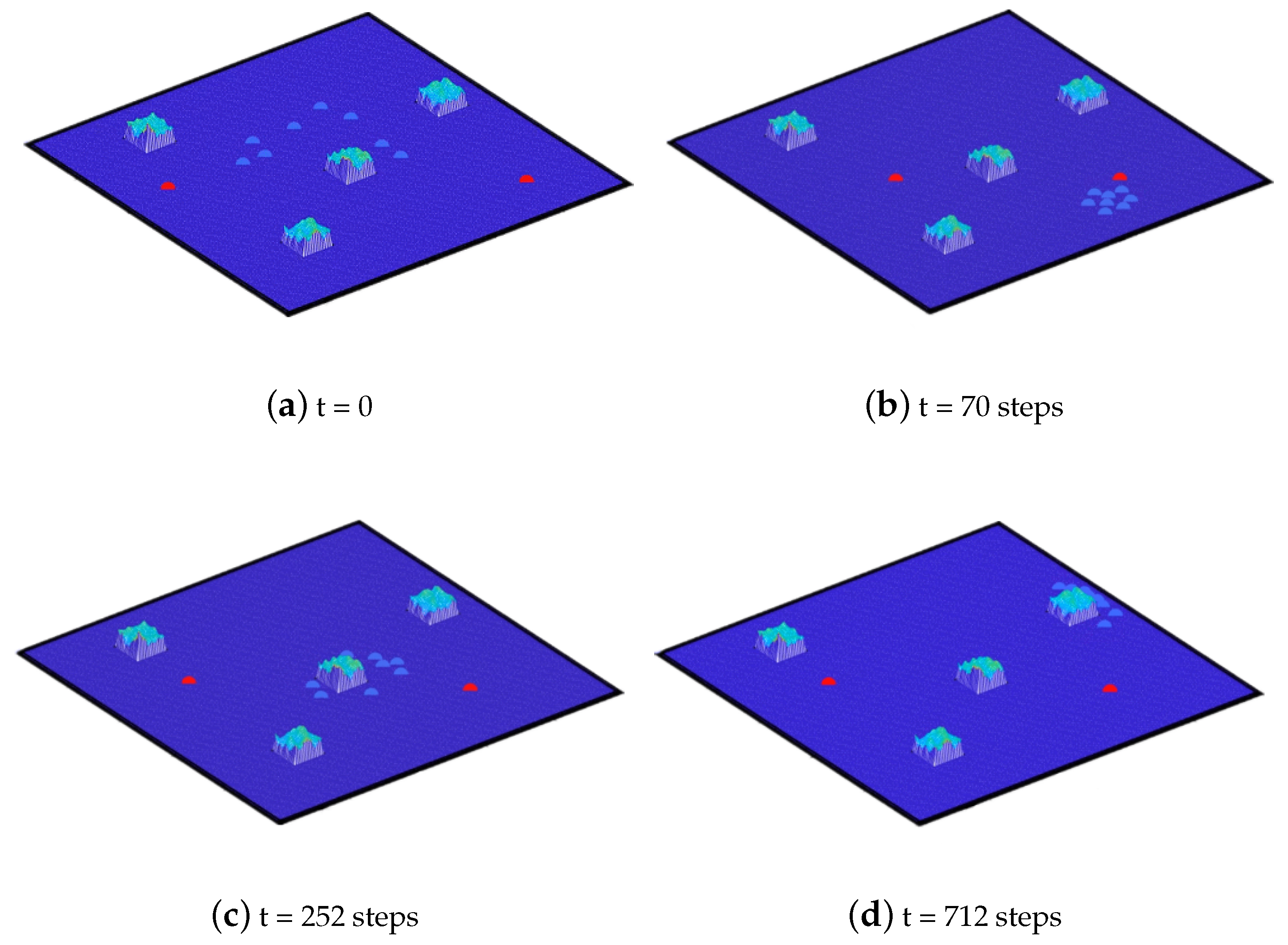
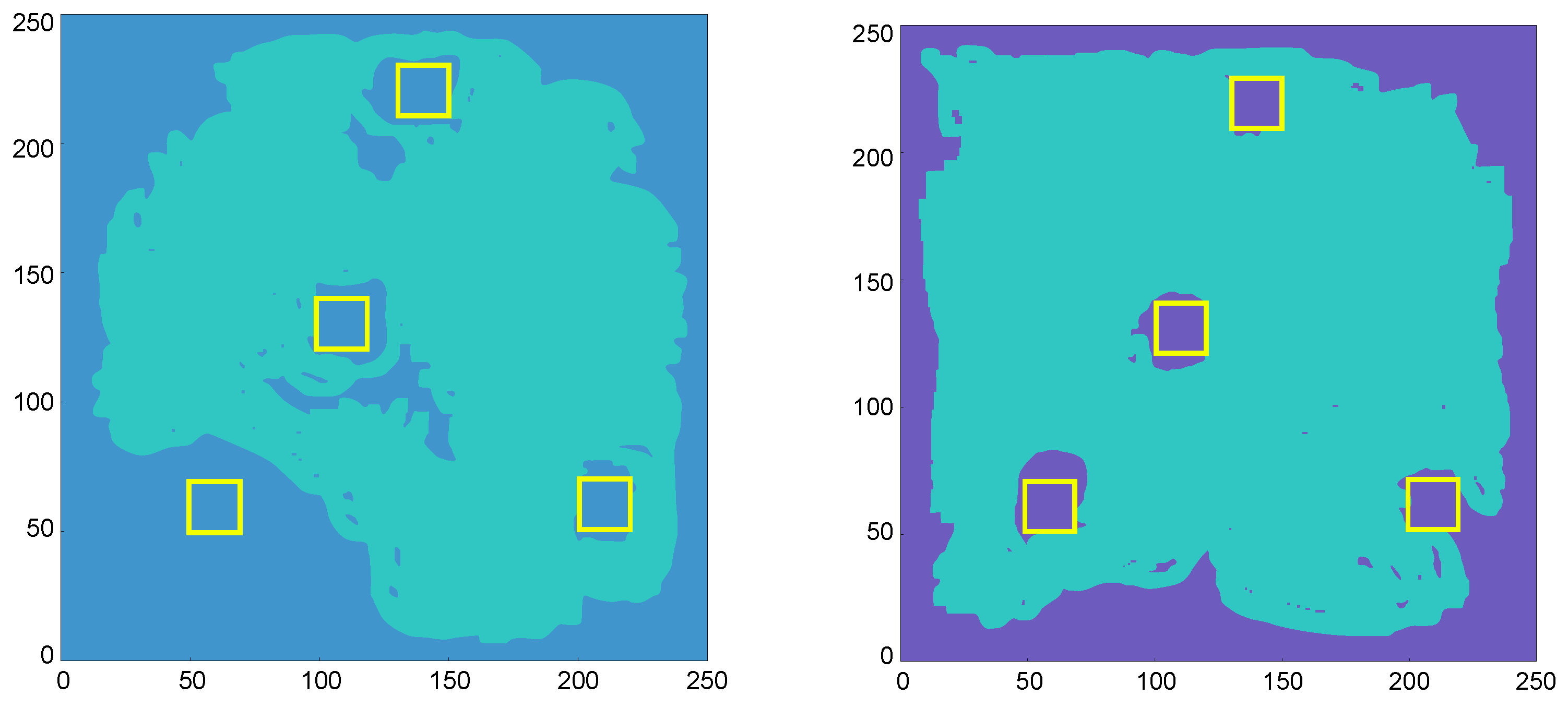
5. Simulation Experiments and Analysis
5.1. Simulation Experiments
- (1)
- The agents do not collide with each other, keep a proper distance from each other, flexibly change their formation, and shuttle in the task area, similar to a natural population.
- (2)
- The agents can flexibly avoid isolating islands in the ocean. On some special occasions, the agents swim past obstacles in groups or pass through a limited space in a line.
- (3)
- When the agents move near obstacles, their speed decreases smoothly, which complies more with their dynamic constraints.
- (4)
- The agents can follow the virtual leader to achieve efficient traversal of the task area.
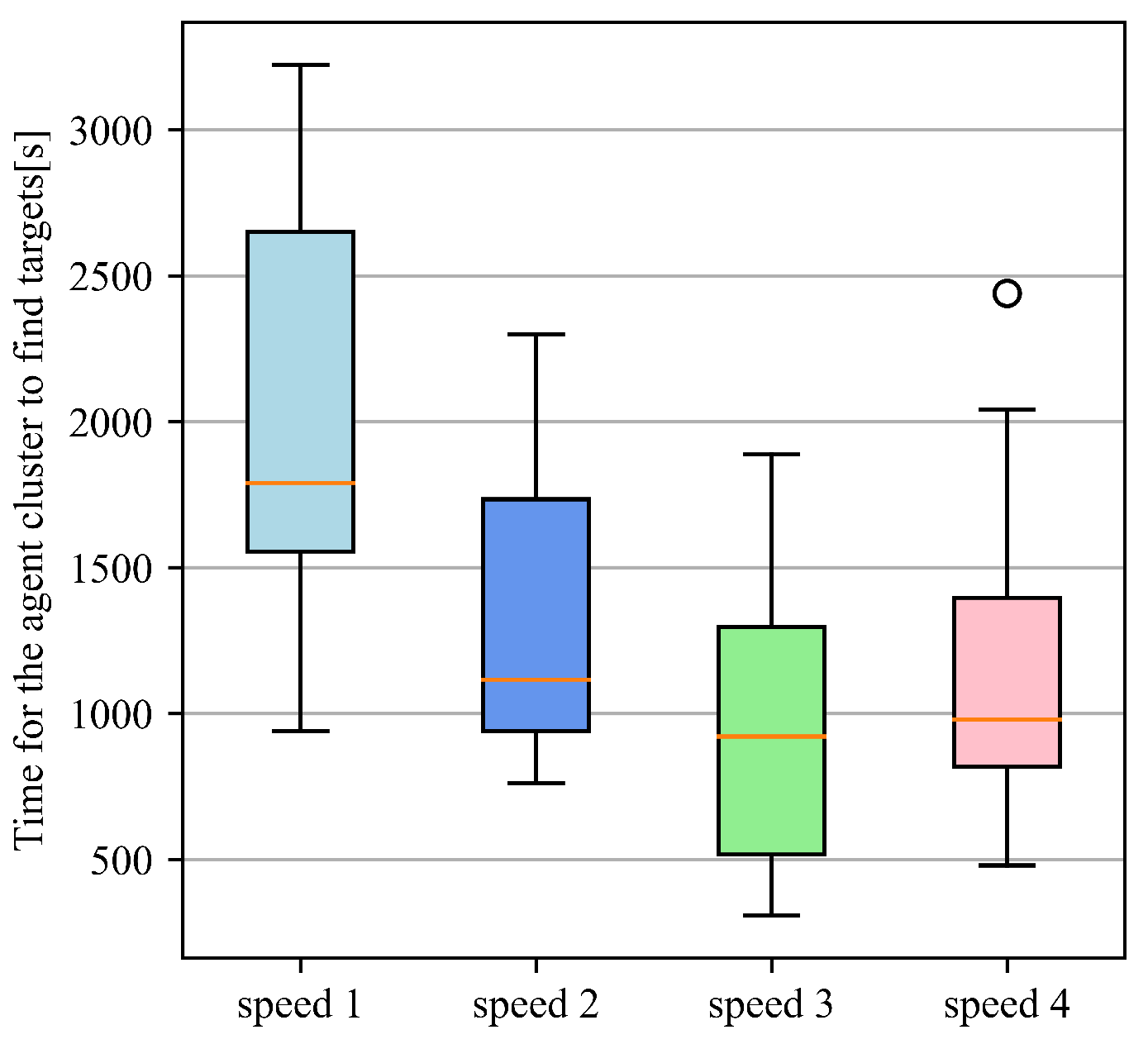
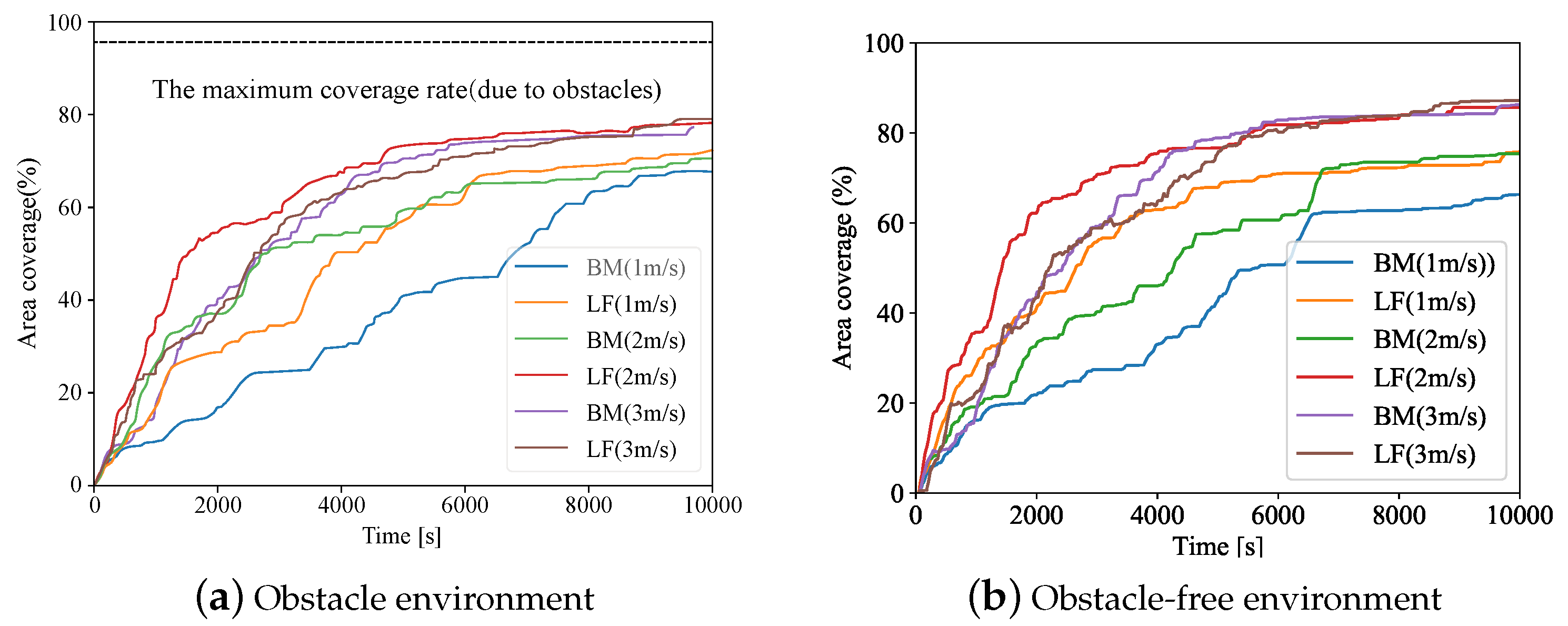
5.2. Indicator Statistics
- (1)
- Time for the swarm to find target;
- (2)
- The coverage area of the swarm in a period of time;
- (3)
- The change of agents’ area coverage ratio over time;
- (4)
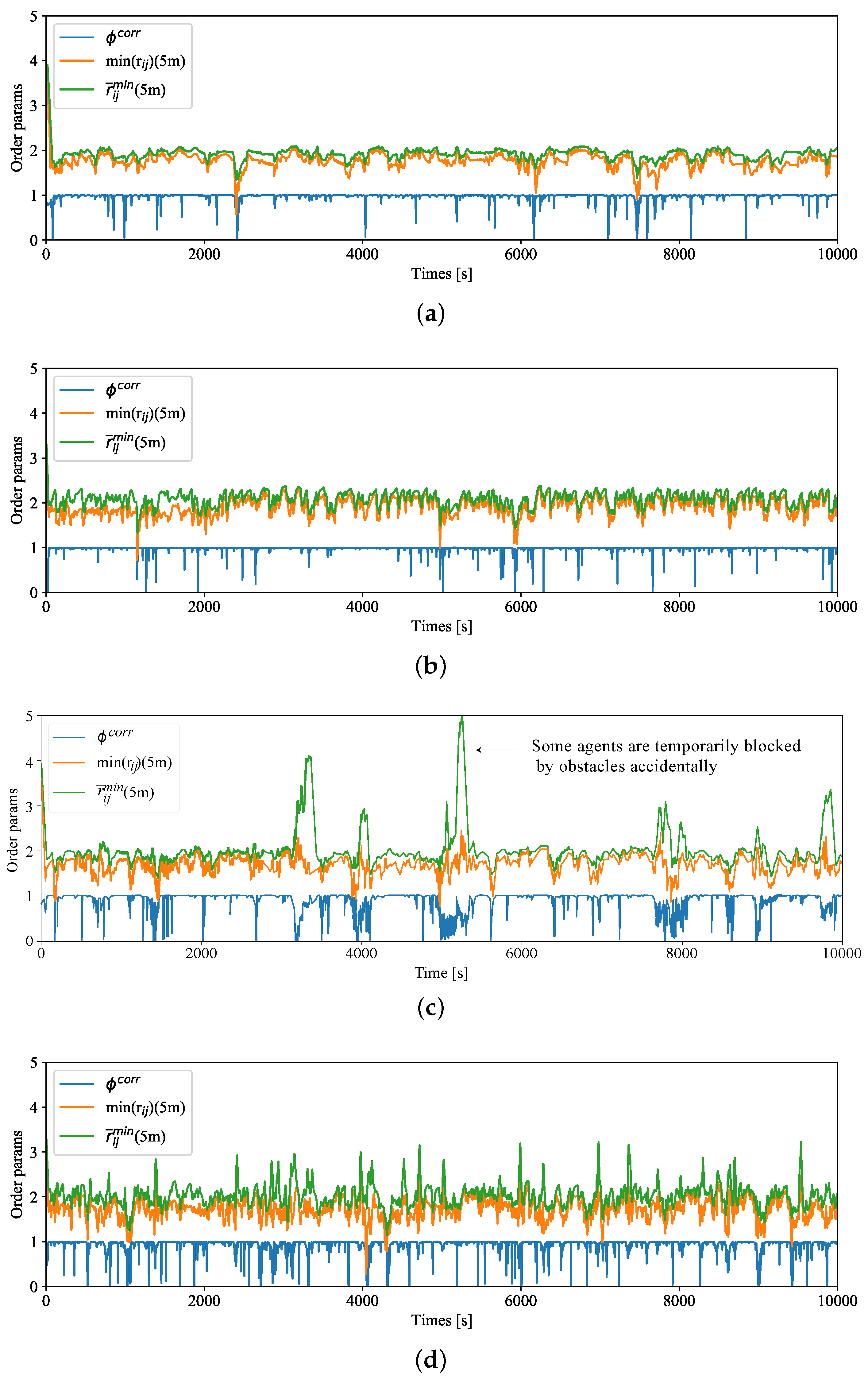
- The correlation of agents’ speed, the average and minimum inter-agent distances while agents are flocking.
6. Real-World Experiments
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| LF | Lévy flight |
| BM | Brownian motion |
| APF | Artificial potential field |
Appendix A
References
- Chen, J.Y. UAV-guided navigation for ground robot tele-operation in a military reconnaissance environment. Ergonomics 2010, 53, 940–950. [Google Scholar] [CrossRef] [PubMed]
- Waharte, S.; Trigoni, N.; Julier, S. Coordinated search with a swarm of UAVs. In Proceedings of the 2009 6th IEEE Annual Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks Workshops, Rome, Italy, 22–26 July 2009; pp. 1–3. [Google Scholar]
- Pitonakova, L.; Crowder, R.; Bullock, S. Information flow principles for plasticity in foraging robot swarms. Swarm Intell. 2016, 10, 33–63. [Google Scholar] [CrossRef] [Green Version]
- Kei Cheang, U.; Lee, K.; Julius, A.A.; Kim, M.J. Multiple-robot drug delivery strategy through coordinated teams of microswimmers. Appl. Phys. Lett. 2014, 105, 083705. [Google Scholar] [CrossRef] [Green Version]
- Wei, C.; Xu, J.; Wang, C.; Wiggers, P.; Hindriks, K. An approach to navigation for the humanoid robot nao in domestic environments. Appl. Phys. Lett. 2013, 298–310. [Google Scholar]
- McGuire, K.N.; De Wagter, C.; Tuyls, K.; Kappen, H.J.; de Croon, G.C. Minimal navigation solution for a swarm of tiny flying robots to explore an unknown environment. Sci. Robot. 2019, 4, eaaw9710. [Google Scholar] [CrossRef]
- Herianto; Sakakibara, T.; Koiwa, T.; Kurabayashi, D. Realization of a pheromone potential field for autonomous navigation by radio frequency identification. Adv. Robot. 2008, 22, 1461–1478. [Google Scholar] [CrossRef]
- Tang, Q.; Xu, Z.; Yu, F.; Zhang, Z.; Zhang, J. Dynamic target searching and tracking with swarm robots based on stigmergy mechanism. Robot. Auton. Syst. 2019, 120, 103251. [Google Scholar] [CrossRef]
- Wei, C.; Hindriks, K.V.; Jonker, C.M. Dynamic task allocation for multi-robot search and retrieval tasks. Appl. Intell. 2016, 45, 383–401. [Google Scholar] [CrossRef]
- Alitappeh, R.J.; Jeddisaravi, K. Multi-robot exploration in task allocation problem. Appl. Intell. 2022, 52, 2189–2211. [Google Scholar] [CrossRef]
- Reid, C.R.; Sumpter, D.J.; Beekman, M. Optimisation in a natural system: Argentine ants solve the Towers of Hanoi. Appl. Intell. 2011, 214, 50–58. [Google Scholar] [CrossRef] [Green Version]
- Menzel, R.; Fuchs, J.; Kirbach, A.; Lehmann, K.; Greggers, U. Navigation and Communication in Honey Bees. In Honeybee Neurobiology and Behavior: A Tribute to Randolf Menzel; Springer: Dordrecht, The Netherlands, 2012. [Google Scholar]
- Wei, C.; Hindriks, K.V.; Jonker, C.M. Altruistic coordination for multi-robot cooperative pathfinding. Appl. Intell. 2016, 44, 269–281. [Google Scholar] [CrossRef]
- Wu, M.; Zhu, X.; Ma, L.; Wang, J.; Bao, W.; Li, W.; Fan, Z. Torch: Strategy evolution in swarm robots using heterogeneous–homogeneous coevolution method. J. Ind. Inf. Integr. 2022, 25, 100239. [Google Scholar] [CrossRef]
- Ajanic, E.; Feroskhan, M.; Mintchev, S.; Noca, F.; Floreano, D. Bioinspired wing and tail morphing extends drone flight capabilities. Sci. Robot. 2020, 5, eabc2897. [Google Scholar] [CrossRef] [PubMed]
- Ramezani, A.; Chung, S.J.; Hutchinson, S. A biomimetic robotic platform to study flight specializations of bats. Sci. Robot. 2017, 2, eaal2505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roderick, W.R.T.; Cutkosky, M.R.; Lentink, D. Bird-inspired dynamic grasping and perching in arboreal environments. Sci. Robot. 2021, 6, eabj7562. [Google Scholar] [CrossRef]
- Viswanathan, G.M.; Afanasyev, V.; Buldyrev, S.V.; Havlin, S.; Da Luz, M.G.E.; Raposo, E.P.; Stanley, H.E. Lévy flights in random searches. Phys. A Stat. Mech. Appl. 2000, 282, 1–12. [Google Scholar] [CrossRef]
- Wei, J.; Chen, Y.; Yu, Y.; Chen, Y. Optimal randomness in swarm-based search. Mathematics 2019, 7, 828. [Google Scholar] [CrossRef] [Green Version]
- Martinez, F.; Jacinto, E.; Acero, D. Brownian motion as exploration strategy for autonomous swarm robots. J. Anim. Ecol. 2012, 2375–2380. [Google Scholar]
- Sims, D.W.; Humphries, N.E.; Bradford, R.W.; Bruce, B.D. Lévy flight and Brownian search patterns of a free-ranging predator reflect different prey field characteristics. J. Anim. Ecol. 2012, 81, 432–442. [Google Scholar] [CrossRef]
- Sims, D.W.; Southall, E.J.; Humphries, N.E.; Hays, G.C.; Bradshaw, C.J.; Pitchford, J.W.; James, A.; Ahmed, M.Z.; Brierley, A.S.; Hindell, M.A.; et al. Scaling laws of marine predator search behaviour. Nature 2008, 451, 1098–1102. [Google Scholar] [CrossRef]
- Reynolds, A.M.; Swain, J.L.; Smith, A.D.; Martin, A.P.; Osborne, J.L. Honeybees use a Lévy flight search strategy and odour-mediated anemotaxis to relocate food sources. Behav. Ecol. Sociobiol. 2009, 64, 115–123. [Google Scholar] [CrossRef]
- Zhou, J.; Yao, X. Multi-objective hybrid artificial bee colony algorithm enhanced with Lévy flight and self-adaption for cloud manufacturing service composition. Appl. Intell. 2017, 47, 721–742. [Google Scholar] [CrossRef]
- Pang, B.; Song, Y.; Zhang, C.; Yang, R. Effect of random walk methods on searching efficiency in swarm robots for area exploration. Appl. Intell. 2021, 51, 5189–5199. [Google Scholar] [CrossRef]
- Fioriti, V.; Fratichini, F.; Chiesa, S.; Moriconi, C. Levy foraging in a dynamic environment–extending the levy search. Int. J. Adv. Robot. Syst. 2015, 12, 98. [Google Scholar] [CrossRef] [Green Version]
- Jeddisaravi, K.; Alitappeh, R.J.; Pimenta, L.C.A.; Guimarães, F.G. Multi-objective approach for robot motion planning in search tasks. Appl. Intell. 2016, 45, 305–321. [Google Scholar] [CrossRef]
- Blum, C.; Merkle, D. Swarm Intelligence: Introduction and Applications. In Applied Intelligence; Springer Science & Business Media: New York, NY, USA, 2008; pp. 19–20. [Google Scholar]
- Chen, Y.B.; Luo, G.C.; Mei, Y.S.; Yu, J.Q.; Su, X.L. UAV path planning using artificial potential field method updated by optimal control theory. Int. J. Syst. Sci. 2016, 47, 1407–1420. [Google Scholar] [CrossRef]
- Sudhakara, P.; Ganapathy, V.; Priyadharshini, B.; Sundaran, K. Obstacle avoidance and navigation planning of a wheeled mobile robot using amended artificial potential field method. Procedia Comput. Sci. 2018, 133, 998–1004. [Google Scholar] [CrossRef]
- Singh, Y.; Sharma, S.; Sutton, R.; Hatton, D.C. Towards use of Dijkstra Algorithm for Optimal Navigation of an Unmanned Surface Vehicle in a Real-Time Marine Environment with results from Artificial Potential Field. TransNav Int. J. Mar. Navig. Saf. Sea Transp. 2018, 12, 125–131. [Google Scholar] [CrossRef]
- Vásárhelyi, G.; Virágh, C.; Somorjai, G.; Nepusz, T.; Eiben, A.E.; Vicsek, T. Optimized flocking of autonomous drones in confined environments. Sci. Robot. 2018, 3, eaat3536. [Google Scholar] [CrossRef] [Green Version]
- Mantegna, R.N. Fast, accurate algorithm for numerical simulation of Levy stable stochastic processes. Phys. Rev. E 2000, 282, 1–12. [Google Scholar] [CrossRef]
- Pal, A.; Tiwari, R.; Shukla, A. Communication constraints multi-agent territory exploration task. Appl. Intell. 2013, 38, 357–383. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiments | 1st | 2nd | 3rd | 4th | 5th | 6th |
|---|---|---|---|---|---|---|
| The time of finding one target | 174 s | 62 s | 235 s | 419 s | 311 s | 283 s |
| The time of finding all targets | 432 s | 211 s | 619 s | 847 s | 346 s | 438 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Wang, D.; Gu, M.; Huang, H.; Wang, Z.; Yuan, Y.; Zhu, X.; Wei, W.; Fan, Z. Bioinspired Environment Exploration Algorithm in Swarm Based on Lévy Flight and Improved Artificial Potential Field. Drones 2022, 6, 122. https://doi.org/10.3390/drones6050122
Wang C, Wang D, Gu M, Huang H, Wang Z, Yuan Y, Zhu X, Wei W, Fan Z. Bioinspired Environment Exploration Algorithm in Swarm Based on Lévy Flight and Improved Artificial Potential Field. Drones. 2022; 6(5):122. https://doi.org/10.3390/drones6050122
Chicago/Turabian StyleWang, Chen, Dongliang Wang, Minqiang Gu, Huaxing Huang, Zhaojun Wang, Yutong Yuan, Xiaomin Zhu, Wu Wei, and Zhun Fan. 2022. "Bioinspired Environment Exploration Algorithm in Swarm Based on Lévy Flight and Improved Artificial Potential Field" Drones 6, no. 5: 122. https://doi.org/10.3390/drones6050122
APA StyleWang, C., Wang, D., Gu, M., Huang, H., Wang, Z., Yuan, Y., Zhu, X., Wei, W., & Fan, Z. (2022). Bioinspired Environment Exploration Algorithm in Swarm Based on Lévy Flight and Improved Artificial Potential Field. Drones, 6(5), 122. https://doi.org/10.3390/drones6050122