

Implicit Neural Mapping for a Data Closed-Loop Unmanned Aerial Vehicle Pose-Estimation Algorithm in a Vision-Only Landing System


Abstract
:1. Introduction
- (1)
- A novel pose-estimation framework in a vision-only landing system is proposed, which introduces implicit mapping and ground-truth annotation modules to improve the pose-estimation accuracy and data-annotation efficiency.
- (2)
- We build a runway-detection pipeline. The multi-stage detection framework proposed in this paper makes full use of the features of different stages, which can guarantee semantic features and positioning ability and therefore greatly improves the runway line detection accuracy.
- (3)
- We present a NeRF-based mapping module in a visual landing system, whose high fidelity provides the possibility of reusing ground truth annotation, while its differentiability provides the basis for accurate pose estimation. Our NeRF-based mapping allows for the coding of different temporal styles, which is not possible with other mapping methods.
2. Related Work
2.1. Runway Detection
2.2. Neural Radiance Field
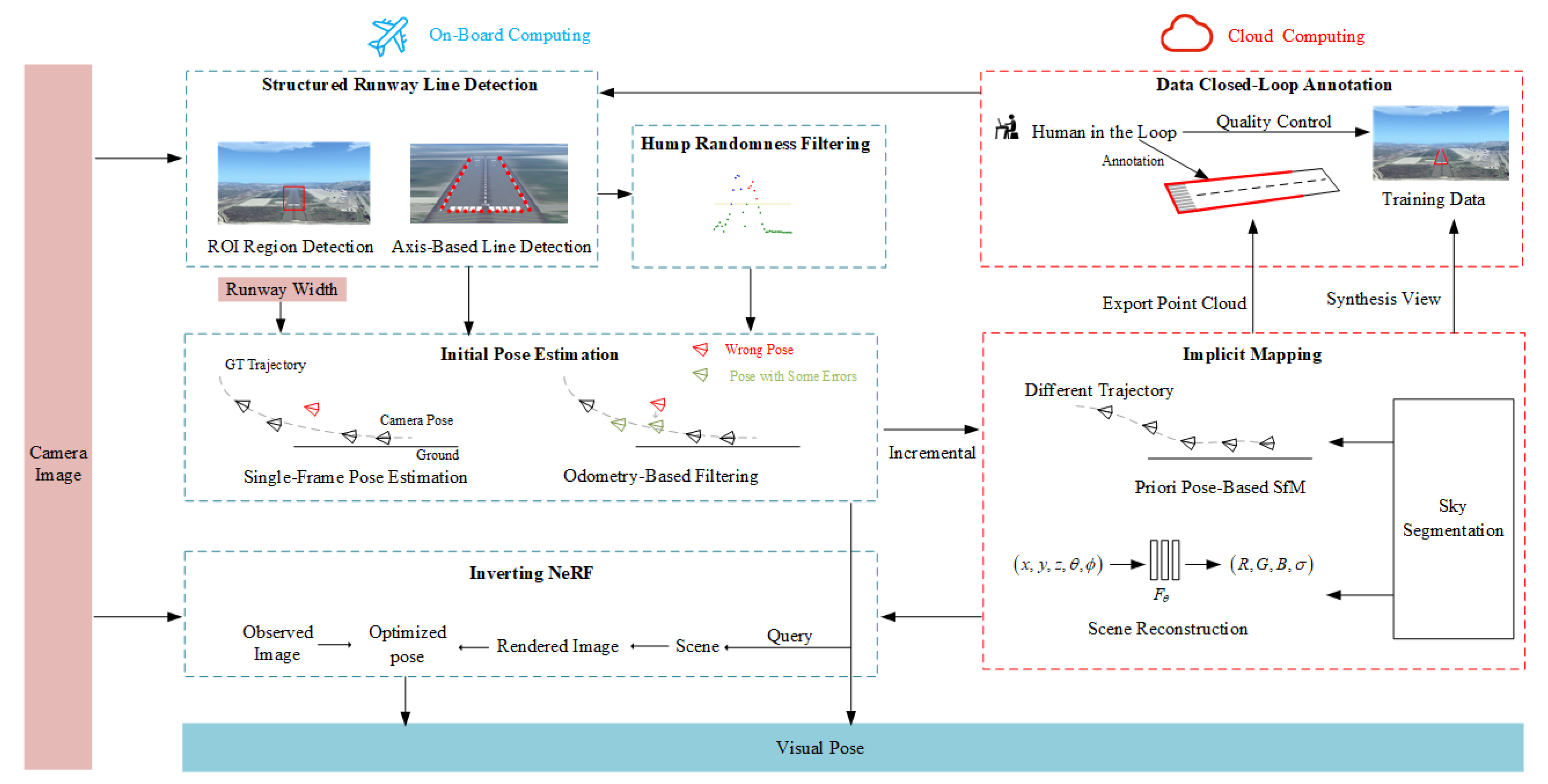
3. Method
3.1. Multi-Stage Flexible Runway Detection
3.1.1. Structured Runway-Line Detection
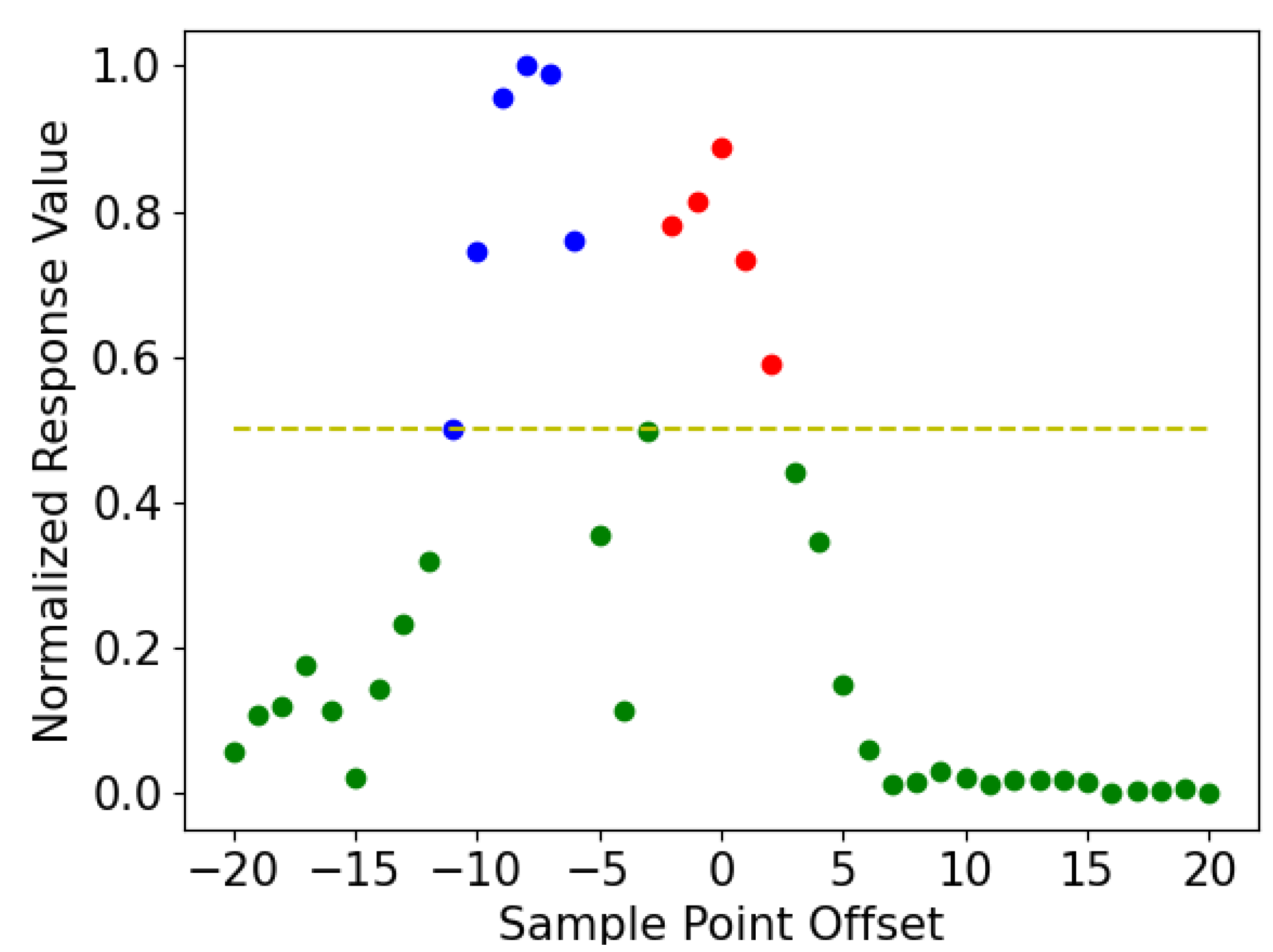
3.1.2. Hump Randomness Filtering
| Algorithm 1 Hump Randomness Filter |
|
3.2. Implicit Reconstruction-Based Pose Estimation
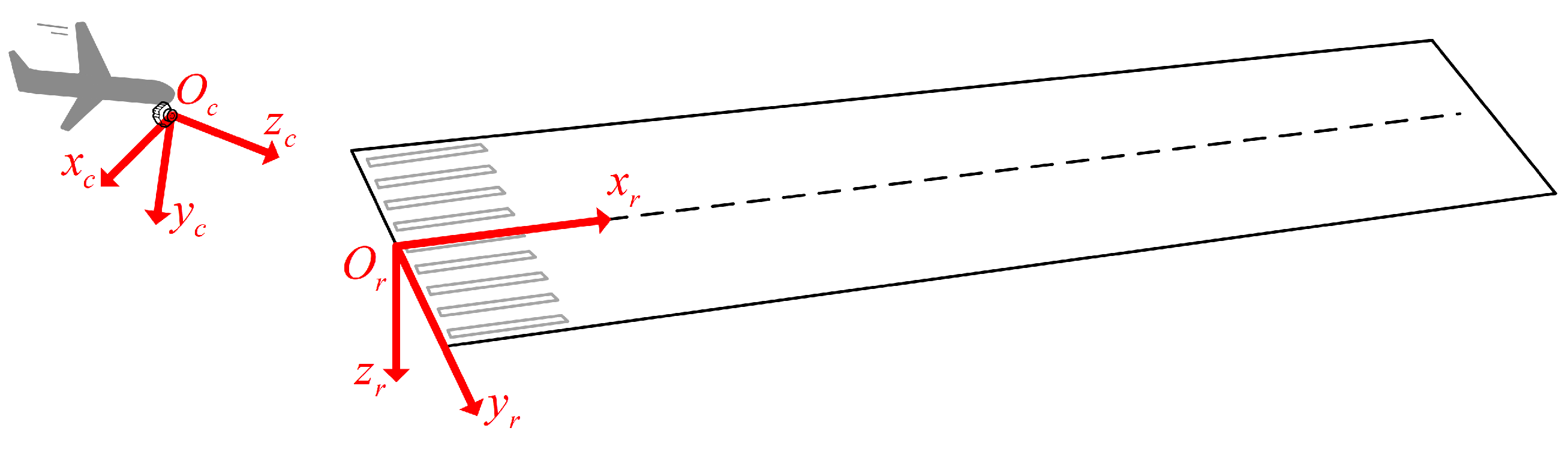
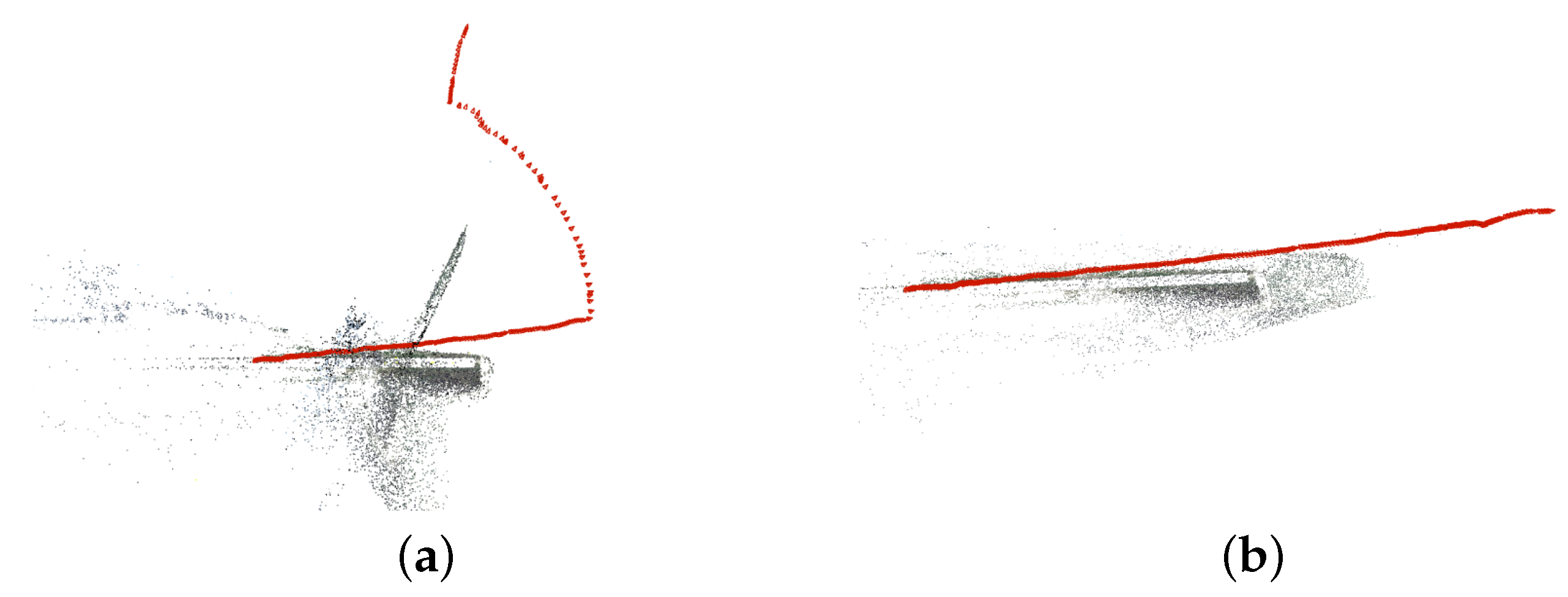
3.2.1. Initial Pose Estimation
3.2.2. Implicit Mapping
3.2.3. Inverting NeRF
3.3. Data Closed-Loop Strategy
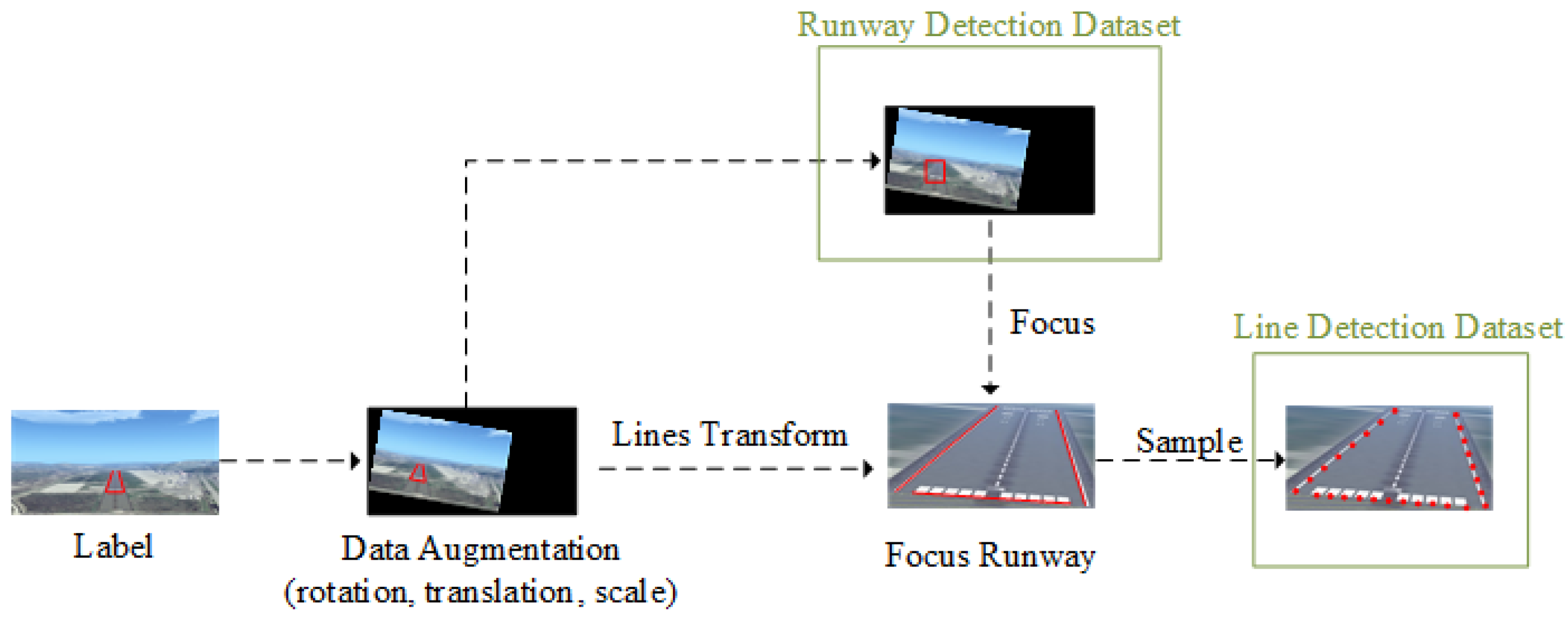
3.3.1. Dataset
3.3.2. Data Closed-Loop Ground-Truth Annotation
4. Experiments
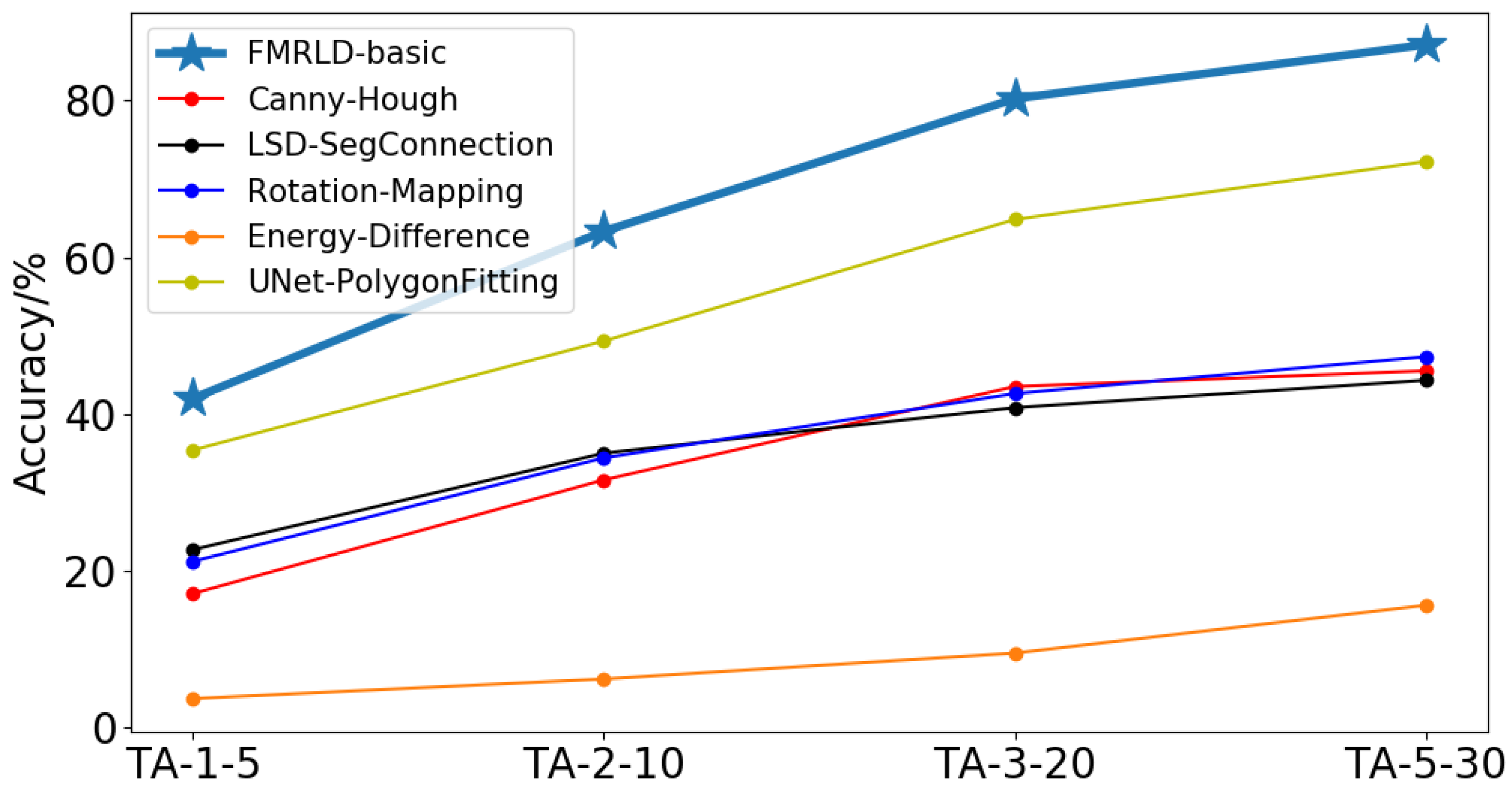
4.1. Runway Line Detection Experiments
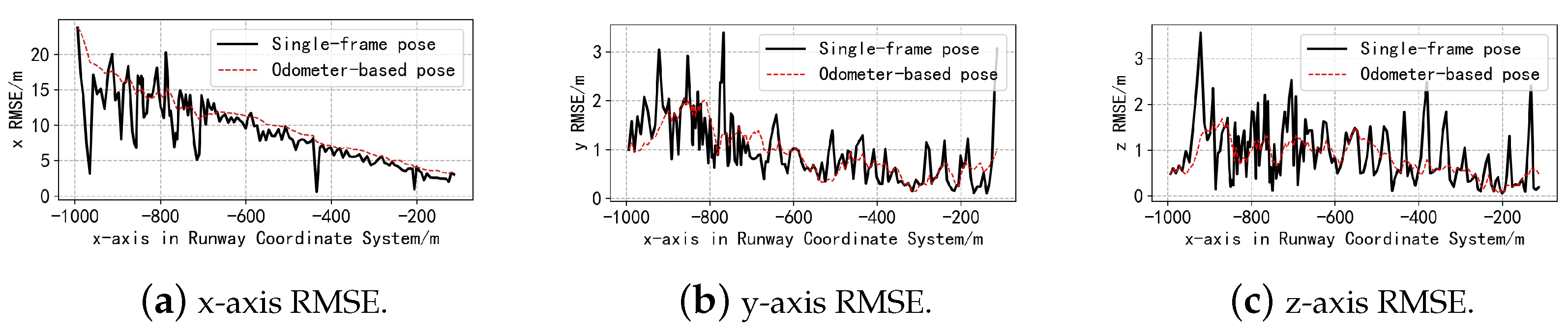
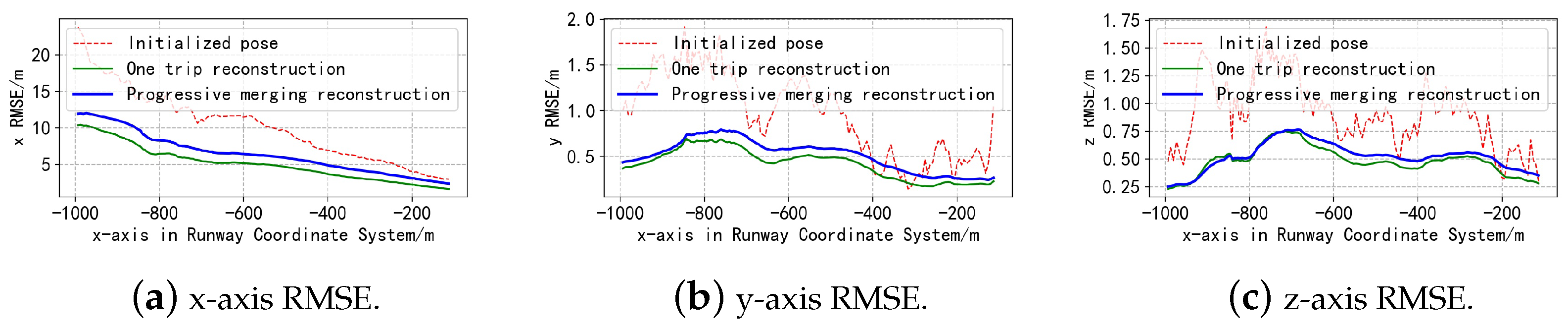
4.2. Pose-Estimation Experiments
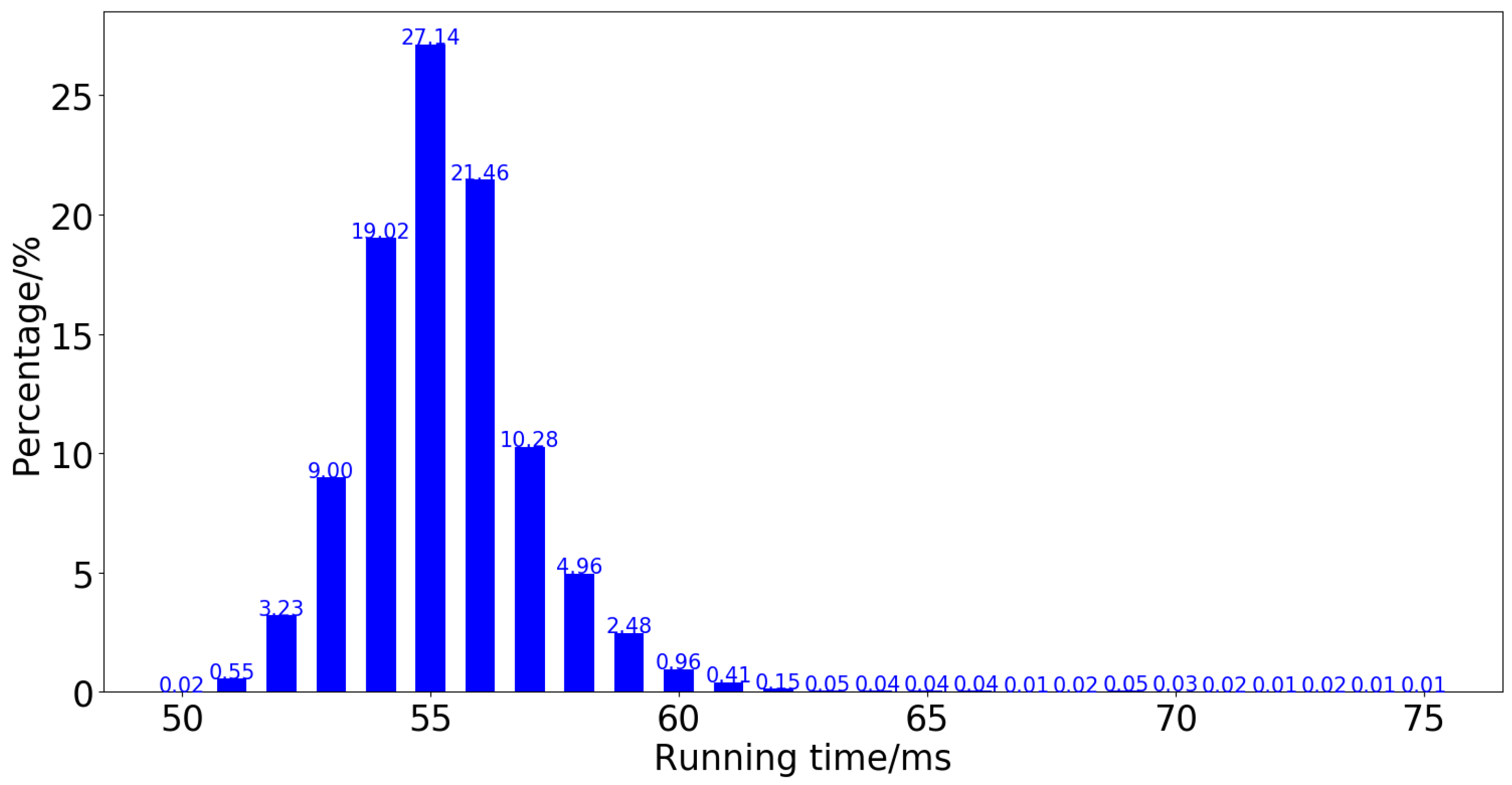
4.3. Lightweight Neural Network Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kong, W.; Zhou, D.; Zhang, D.; Zhang, J. Vision-based autonomous landing system for unmanned aerial vehicle: A survey. In Proceedings of the 2014 International Conference on Multisensor Fusion and Information Integration for Intelligent Systems (MFI), Beijing, China, 28–29 September 2014; pp. 1–8. [Google Scholar]
- Kügler, M.E.; Mumm, N.C.; Holzapfel, F.; Schwithal, A.; Angermann, M. Vision-augmented automatic landing of a general aviation fly-by-wire demonstrator. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019; p. 1641. [Google Scholar]
- Tang, C.; Wang, Y.; Zhang, L.; Zhang, Y.; Song, H. Multisource fusion UAV cluster cooperative positioning using information geometry. Remote Sens. 2022, 14, 5491. [Google Scholar] [CrossRef]
- Yen-Chen, L.; Florence, P.; Barron, J.T.; Rodriguez, A.; Isola, P.; Lin, T.Y. inerf: Inverting neural radiance fields for pose estimation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1323–1330. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 2022, 41, 1–15. [Google Scholar] [CrossRef]
- Tang, Y.L.; Kasturi, R. Runway detection in an image sequence. In Image and Video Processing III; SPIE: Bellingham, WA, USA, 1995; Volume 2421, pp. 181–190. [Google Scholar]
- Angermann, M.; Wolkow, S.; Schwithal, A.; Tonhäuser, C.; Hecker, P. High precision approaches enabled by an optical-based navigation system. In Proceedings of the ION 2015 Pacific PNT Meeting, Honolulu, HA, USA, 20–23 April 2015; pp. 694–701. [Google Scholar]
- Wang, J.; Cheng, Y.; Xie, J.; Niu, W. A real-time sensor guided runway detection method for forward-looking aerial images. In Proceedings of the 2015 11th International Conference on Computational Intelligence and Security (CIS), Shenzhen, China, 19–20 December 2015; pp. 150–153. [Google Scholar]
- Guan, Z.; Li, J.; Yang, H. Runway extraction method based on rotating projection for UAV. In Proceedings of the 6th International Asia Conference on Industrial Engineering and Management Innovation: Innovation and Practice of Industrial Engineering and Management (Volume 2); Springer: Berlin/Heidelberg, Germany, 2016; pp. 311–324. [Google Scholar]
- Akbar, J.; Shahzad, M.; Malik, M.I.; Ul-Hasan, A.; Shafait, F. Runway detection and localization in aerial images using deep learning. In Proceedings of the 2019 Digital Image Computing: Techniques and Applications (DICTA), Perth, WA, Australia, 2–4 December 2019; pp. 1–8. [Google Scholar]
- Lin, C.E.; Chou, W.Y.; Chen, T. Visual-Assisted UAV Auto-Landing System; DEStech Transactions on Engineering and Technology Research: Lancaster, PA, USA, 2018. [Google Scholar]
- Hiba, A.; Zsedrovits, T.; Heri, O.; Zarandy, A. Runway detection for UAV landing system. In Proceedings of the CNNA 2018, the 16th International Workshop on Cellular Nanoscale Networks and Their Applications, Budapest, Hungary, 28–30 August 2018; pp. 1–4. [Google Scholar]
- Wang, Y.; Jiang, H.; Liu, C.; Pei, X.; Qiu, H. An airport runway detection algorithm based on Semantic segmentation. Navig. Position. Timing CSTPCD 2021, 8, 97–106. [Google Scholar]
- Fridovich-Keil, S.; Yu, A.; Tancik, M.; Chen, Q.; Recht, B.; Kanazawa, A. Plenoxels: Radiance fields without neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5501–5510. [Google Scholar]
- Wang, P.; Liu, Y.; Chen, Z.; Liu, L.; Liu, Z.; Komura, T.; Theobalt, C.; Wang, W. F2-NeRF: Fast Neural Radiance Field Training with Free Camera Trajectories. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4150–4159. [Google Scholar]
- Niemeyer, M.; Barron, J.T.; Mildenhall, B.; Sajjadi, M.S.; Geiger, A.; Radwan, N. Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5480–5490. [Google Scholar]
- Deng, K.; Liu, A.; Zhu, J.Y.; Ramanan, D. Depth-supervised nerf: Fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12882–12891. [Google Scholar]
- Rematas, K.; Liu, A.; Srinivasan, P.P.; Barron, J.T.; Tagliasacchi, A.; Funkhouser, T.; Ferrari, V. Urban radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12932–12942. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5855–5864. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference (Proceedings, Part XXIV 16), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 276–291. [Google Scholar]
- Sobel, I.; Feldman, G. A 3 × 3 isotropic gradient operator for image processing. In A Talk at the Stanford Artificial Project; 1968; pp. 271–272. Available online: https://www.researchgate.net/publication/285159837_A_33_isotropic_gradient_operator_for_image_processing (accessed on 15 July 2023).
- Canny, J. A computational approach to edge detection. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 1986; pp. 679–698. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++ the advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Philadelphia, PA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Liu, C.; Liu, L.; Hu, G.; Xu, X. A P3P problem solving algorithm for landing vision navigation. Navig. Position. Timing 2018, 5, 58–61. [Google Scholar]
- Tang, C.; Wang, C.; Zhang, L.; Zhang, Y.; Song, H. Multivehicle 3D cooperative positioning algorithm based on information geometric probability fusion of GNSS/wireless station navigation. Remote Sens. 2022, 14, 6094. [Google Scholar] [CrossRef]
- Zhou, L.; Zhong, Q.; Zhang, Y.; Lei, Z.; Zhang, X. Vision-based landing method using structured line features of runway surface for fixed-wing unmanned aerial vehicles. J. Natl. Univ. Def. Technol. 2016, 9, 38. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Max, N. Optical models for direct volume rendering. IEEE Trans. Vis. Comput. Graph. 1995, 1, 99–108. [Google Scholar] [CrossRef] [Green Version]
- Barron, J.T.; Mildenhall, B.; Verbin, D.; Srinivasan, P.P.; Hedman, P. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5470–5479. [Google Scholar]
- Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 7210–7219. [Google Scholar]
- Lindén, J.; Forsberg, H.; Haddad, J.; Tagebrand, E.; Cedernaes, E.; Ek, E.G.; Daneshtalab, M. Curating Datasets for Visual Runway Detection. In Proceedings of the 2021 IEEE/AIAA 40th Digital Avionics Systems Conference (DASC), San Antonio, TX, USA, 3–7 October 2021; pp. 1–9. [Google Scholar]
- Kalra, A.; Stoppi, G.; Brown, B.; Agarwal, R.; Kadambi, A. Towards rotation invariance in object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3530–3540. [Google Scholar]
- Dong, Y.; Yuan, B.; Wang, H.; Shi, Z. A runway recognition algorithm based on heuristic line extraction. In Proceedings of the 2011 International Conference on Image Analysis and Signal Processing, Wuhan, China, 21–23 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 292–296. [Google Scholar]
- Abu-Jbara, K.; Alheadary, W.; Sundaramorthi, G.; Claudel, C. A robust vision-based runway detection and tracking algorithm for automatic UAV landing. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1148–1157. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Proceedings of the 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—Proceedings of the MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | TA-1-5 | TA-2-10 | TA-3-20 | TA-5-30 | FPS |
|---|---|---|---|---|---|
| FMRLD-basic | 42.0 | 63.3 | 80.2 | 87.1 | 40.7 |
| +correlation constraint | 42.4 (+0.4) | 64.3 (+1.0) | 81.6 (+1.4) | 88.4 (+1.3) | 40.7 |
| +rotational data augmentation | 45.5 (+3.1) | 68.1 (+3.8) | 84.9 (+3.3) | 90.9 (+2.5) | 40.7 |
| +hump filter (rough) | 51.0 (+5.5) | 70.8 (+2.7) | 85.3 (+0.4) | 91.5 (+0.6) | 24.2 |
| +hump filter (fine) | 52.3 (+1.3) | 70.5 (−0.3) | 86.1 (+0.8) | 92.0 (+0.5) | 10.6 |
| Method | x | y | z | |||
|---|---|---|---|---|---|---|
| FMRLD | 10.72 m | 1.01 m | 0.81 m | 0.525° | 0.338° | 0.615° |
| UNet-PolygonFitting | 36.42 m | 8.34 m | 2.39 m | 2.412° | 3.183° | 4.264° |
| Method | x | y | z | |||
|---|---|---|---|---|---|---|
| Initialized pose | 10.75 m | 1.04 m | 0.96 m | 0.542° | 0.339° | 0.617° |
| One trip pose (offline) | 5.35 m | 0.48 m | 0.50 m | 0.347° | 0.284° | 0.482° |
| Progressive implicit pose (offline) | 6.94 m | 0.56 m | 0.54 m | 0.425° | 0.310° | 0.535° |
| Method | x | y | z | |||
|---|---|---|---|---|---|---|
| Initialized pose | 10.96 m | 1.08 m | 1.04 m | 0.548° | 0.346° | 0.621° |
| One-trip pose (online) | 9.32 m | 1.01 m | 0.63 m | 0.492° | 0.334° | 0.587° |
| Progressive implicit pose (online) | 7.08 m | 0.63 m | 0.55 m | 0.437° | 0.315° | 0.538° |
| Method | TA-1-5 | TA-2-10 | TA-3-20 | TA-5-30 | x | y | z |
|---|---|---|---|---|---|---|---|
| FMRLD-Light | 43.5 | 65.2 | 82.8 | 90.3 | 13.17 m | 1.44 m | 1.32 m |
| FMRLD | 52.3 | 70.5 | 86.1 | 92.0 | 7.08 m | 0.63 m | 0.55 m |
| UNet-PolygonFitting | 35.7 | 47.1 | 60.5 | 71.2 | 36.42 m | 8.34 m | 2.39 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Li, C.; Xu, X.; Yang, N.; Qin, B. Implicit Neural Mapping for a Data Closed-Loop Unmanned Aerial Vehicle Pose-Estimation Algorithm in a Vision-Only Landing System. Drones 2023, 7, 529. https://doi.org/10.3390/drones7080529
Liu X, Li C, Xu X, Yang N, Qin B. Implicit Neural Mapping for a Data Closed-Loop Unmanned Aerial Vehicle Pose-Estimation Algorithm in a Vision-Only Landing System. Drones. 2023; 7(8):529. https://doi.org/10.3390/drones7080529
Chicago/Turabian StyleLiu, Xiaoxiong, Changze Li, Xinlong Xu, Nan Yang, and Bin Qin. 2023. "Implicit Neural Mapping for a Data Closed-Loop Unmanned Aerial Vehicle Pose-Estimation Algorithm in a Vision-Only Landing System" Drones 7, no. 8: 529. https://doi.org/10.3390/drones7080529
APA StyleLiu, X., Li, C., Xu, X., Yang, N., & Qin, B. (2023). Implicit Neural Mapping for a Data Closed-Loop Unmanned Aerial Vehicle Pose-Estimation Algorithm in a Vision-Only Landing System. Drones, 7(8), 529. https://doi.org/10.3390/drones7080529