
Improved YOLOv7 Target Detection Algorithm Based on UAV Aerial Photography

Abstract
:1. Introduction
2. Related Work
2.1. Targeted Detection
2.2. Unmanned Aerial Vehicle Target Detection
3. Principles and Improvements
3.1. YOLOv7
3.2. Improvement
3.2.1. Dynamic Snake Convolution
3.2.2. Improvement of SPPCSPC
3.2.3. Improvement of IOU LoSS
4. Analysis of Experimental Results
4.1. Datasets
4.2. Experimental Steps
4.3. Evaluation Indicators
4.4. Ablation Experiments
- The first set of experiments for the baseline model, i.e., the YOLOv7 algorithmic model, is used as a reference, which has a mAP value of 50.47% on the Visdrone2019 dataset;
- The second group is to replace the ELAN of the benchmark model with the improved ELAN_DSC; the number of parameters increases by 16.32M, but the mAP is improved by 3.4%, the accuracy is improved by 2.6%, and the recall is improved by 3.5% compared with the benchmark model, and the main reasons for the model’s enhancement include the following: The target as a fine structure accounts for a very small percentage of the overall image, with a limited pixel composition, and it is easily affected by the complex background. The main reasons for the model improvement are: the target is a small proportion of the overall image, the pixel composition is limited, and it is easily interfered with by the complex background, which makes it difficult for the model to accurately identify the subtle changes of the target, but the addition of the dynamic serpentine convolution to ELAN can effectively focus on the slender and curved target, thus improving the detection performance. Since dynamic serpentine convolution has better segmentation performance and increased complexity compared to normal convolution, the number of parameters in the improved module rises compared to the original model;
- The third group is replaced by the improved SPPF module, which improves 1.3% over the baseline model, improves 1.1% accuracy, improves 1.2% recall, and reduces the parameters. mAP, P, and R improvements and parameter reductions are analyzed as follows: the improved SPPF module performs Maxpool operations on convolutional kernels of different sizes to differentiate between different targets, increase the receptive field, and extract more important feature information; therefore, mAP, P, and R are improved; the improved module performs serial operations on convolutional kernels of different sizes and therefore reduces the model complexity, so the number of parameters decreases. The improved SPPF module uses different sizes of convolutional kernels for the Maxpool operation to distinguish different targets, increase the receptive field, and extract more important feature information, so the mAP, P, and R are improved; the improved module operates the different sizes of convolutional kernels in a serial manner, so the complexity of the model is reduced, and the number of parameters decreases;
- The fourth group replaces the loss function with EIOU, the mAP improves by 0.43%, the accuracy improves by 0.5%, the recall improves by 0.6%, and the number of parameters is unchanged because of the unaltered network model and, therefore, unchanged compared to the baseline model. Analysis of the reasons for improving the detection performance: the loss function directly minimizes the difference in the height and width between the target box and the anchor box, which results in faster convergence and a better localization effect;
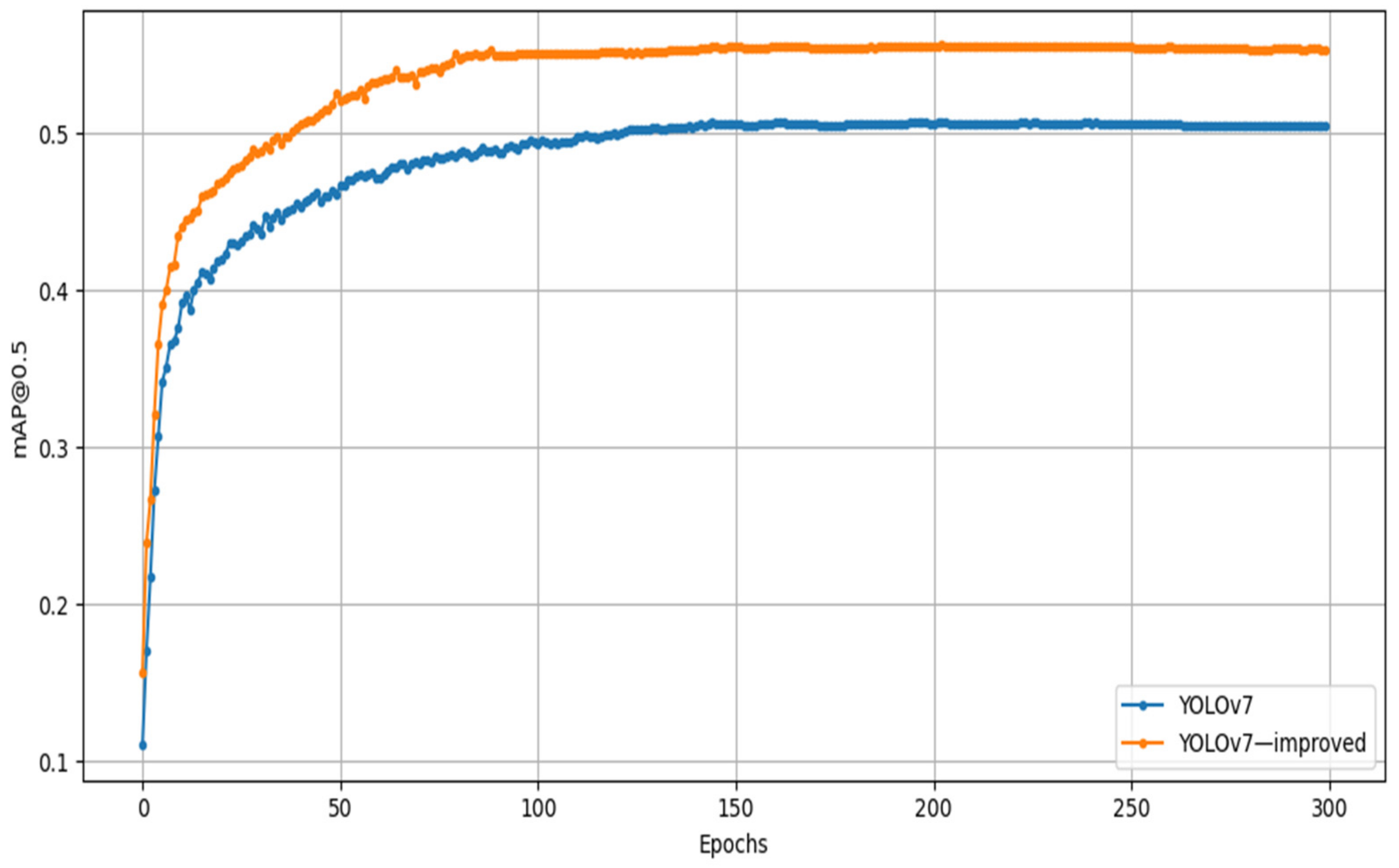
- From the second to the seventh set of ablation experiments, the introduction of DSCNet provided the key improvement, with a 3.4% improvement in mAP in Figure 7.
4.5. Comparative Experiments
4.6. Analysis of Detection Effects
5. Conclusions
6. Future Work
- (1)
- Application migration and algorithm generalization: Exploring the migration of the improved algorithms developed in this study, such as dynamic serpentine convolution (DSC), improved spatial pyramid pooling structure (SPPFCSPC), and EIoU loss functions, to other models, for instance, YOLOv8, or SSD. Investigate how these improvements can be adapted to the characteristics of different algorithmic frameworks and how the parameters can be adjusted during the migration process to maintain or improve the accuracy and efficiency of target detection;
- (2)
- Cross-domain application exploration: In addition to UAV image processing, explore the potential of the improved algorithms to be applied in other domains, such as satellite image analysis and traffic monitoring. In particular, study the performance of the algorithms in processing image data of different resolutions and scales and how to adapt the algorithms to the specific needs of these new fields;
- (3)
- Real-time processing and edge computing: considering that UAV and satellite image analysis often requires real-time processing, future research could focus on optimizing the lightweighting and acceleration of models to adapt to edge computing platforms. Investigate how to deploy deep learning models to devices with limited hardware resources while maintaining efficient computational performance and accurate detection results;
- (4)
- Multimodal data fusion: In UAV and satellite image analysis, multiple types of data (e.g., optical images, infrared images, radar data, etc.) are often involved. Future research can explore how to effectively fuse these different modalities of data.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. Uav-yolo: Small object detection on unmanned aerial vehicle perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Saetchnikov, I.; Skakun, V.; Tcherniavskaia, E. Efficient objects tracking from an unmanned aerial vehicle. In Proceedings of the 2021 IEEE 8th International Workshop on Metrology for AeroSpace (MetroAeroSpace), Naples, Italy, 23–25 June 2021; pp. 221–225. [Google Scholar]
- Li, Z.; Liu, X.; Zhao, Y.; Liu, B.; Huang, Z.; Hong, R. A lightweight multi-scale aggregated model for detecting aerial images captured by UAVs. J. Vis. Commun. Image Represent. 2021, 77, 103058. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Diko, A.; Fagioli, A.; Foresti, G.L.; Mecca, A.; Pannone, D.; Piciarelli, C. MS-Faster R-CNN: Multi-stream backbone for improved Faster R-CNN object detection and aerial tracking from UAV images. Remote Sens. 2021, 13, 1670. [Google Scholar] [CrossRef]
- Azimi, S.M.; Kraus, M.; Bahmanyar, R.; Reinartz, P. Multiple pedestrians and vehicles tracking in aerial imagery: A comprehensive study. arXiv 2020, arXiv:2010.09689. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 8311–8320. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6070–6079. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. Yolov6 v3. 0: A full-scale reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, T.; He, W.; Zhang, Z. Yolov7-uav: An unmanned aerial vehicle image object detection algorithm based on improved yolov7. Electronics 2023, 12, 3141. [Google Scholar] [CrossRef]
- Zhang, L.; Xiong, N.; Pan, X.; Yue, X.; Wu, P.; Guo, C. Improved object detection method utilizing yolov7-tiny for unmanned aerial vehicle photographic imagery. Algorithms 2023, 16, 520. [Google Scholar] [CrossRef]
- Li, X.; Wei, Y.; Li, J.; Duan, W.; Zhang, X.; Huang, Y. Improved YOLOv7 Algorithm for Small Object Detection in Unmanned Aerial Vehicle Image Scenarios. Appl. Sci. 2024, 14, 1664. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Name | Type |
|---|---|---|
| CPU | Intel(R) Core(TM) i9-113500F | |
| Hardware | GPU | NVIDIA GeForce GTX3090 |
| Memory | 40GB | |
| CUDA | 11.6 | |
| Software | Python | 3.8.6 |
| Pytorch | 1.11.0 | |
| Learning Rate | 0.01 | |
| Image Size | 640 × 640 | |
| Hyperparameters | Workers | 8 |
| Batch Size | 16 | |
| Maximum Training Epochs | 300 |
| Method | P% | R% | Parameters/M | mAP% |
|---|---|---|---|---|
| YOLOv7 | 59.7 | 50.6 | 35.51 | 50.47 |
| YOLOv7_dscnet | 62.3 | 53.1 | 51.83 | 53.07 |
| YOLOv7_SPPF | 60.8 | 51.8 | 30.01 | 51.37 |
| YOLOv7_EIOU | 60.3 | 51.2 | 35.51 | 50.90 |
| YOLOv7_dscnet_SPPF | 62.8 | 53.5 | 46.82 | 53.45 |
| YOLOv7_dscnet_EIOU | 62.5 | 53.4 | 51.83 | 53.28 |
| YOLOv7_SPPF_EIOU | 61.3 | 52.3 | 30.01 | 52.01 |
| Ours | 64.1 | 54.9 | 46.82 | 54.7 |
| Method | AP% | mAP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pedestrian | Person | Bicycle | Car | Van | Truck | Tricycle | A-T | Bus | Motor | ||
| Faster RCNN | 21.4 | 15.6 | 6.7 | 51.7 | 29.5 | 19.0 | 13.1 | 7.7 | 31.4 | 20.7 | 21.7 |
| YOLOv4 | 25.0 | 13.1 | 8.6 | 64.3 | 22.4 | 22.7 | 11.4 | 8.1 | 44.3 | 22.1 | 43.1 |
| CDNet | 35.6 | 19.2 | 13.8 | 55.8 | 42.1 | 38.2 | 33.0 | 25.4 | 49.5 | 29.3 | 34.2 |
| DMNet | 28.5 | 20.4 | 15.9 | 56.8 | 37.9 | 30.1 | 22.6 | 14.0 | 47.1 | 29.2 | 30.3 |
| RetinaNet | 13.0 | 7.9 | 1.4 | 45.5 | 19.9 | 11.5 | 6.3 | 4.2 | 17.8 | 11.8 | 13.9 |
| Cascade R-CNN | 22.2 | 14.8 | 7.6 | 54.6 | 31.5 | 21.6 | 14.8 | 8.6 | 34.9 | 21.4 | 23.2 |
| CenterNet | 22.6 | 20.6 | 14.6 | 59.7 | 24.0 | 21.3 | 20.1 | 17.4 | 37.9 | 23.7 | 26.2 |
| YOLOv3-LITE | 34.5 | 23.4 | 7.9 | 70.8 | 31.3 | 21.9 | 15.3 | 6.2 | 40.9 | 32.7 | 28.5 |
| MSC-CenterNet | 33.7 | 15.2 | 12.1 | 55.2 | 40.5 | 34.1 | 29.2 | 21.6 | 42.2 | 27.5 | 31.1 |
| DBAI-Det | 36.7 | 12.8 | 14.7 | 47.4 | 38.0 | 41.4 | 23.4 | 16.9 | 31.9 | 16.6 | 28.0 |
| YOLOv5s | 35.8 | 30.5 | 10.1 | 65 | 31.5 | 29.5 | 20.6 | 11.1 | 41.0 | 35.4 | 31.1 |
| YOLOv7 | 53.3 | 46.5 | 26.1 | 77.3 | 53.4 | 46.5 | 39.8 | 19.9 | 59.7 | 55.8 | 50.47 |
| Ours | 57.6 | 51.1 | 29.3 | 82.4 | 58.6 | 51.7 | 44.4 | 24.6 | 64.7 | 60.4 | 54.7 |
| Method | mAP% | Parameters/M |
|---|---|---|
| YOLOv7-UAV | 52.21 | 3.07 |
| PDWT-YOLO | 41.2 | 24.2 |
| Improved YOLOv7 | 45.30 | 26.77 |
| Ours | 54.7 | 16.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Z.; Pei, X.; Qiao, Z.; Wu, G.; Bai, Y. Improved YOLOv7 Target Detection Algorithm Based on UAV Aerial Photography. Drones 2024, 8, 104. https://doi.org/10.3390/drones8030104
Bai Z, Pei X, Qiao Z, Wu G, Bai Y. Improved YOLOv7 Target Detection Algorithm Based on UAV Aerial Photography. Drones. 2024; 8(3):104. https://doi.org/10.3390/drones8030104
Chicago/Turabian StyleBai, Zhen, Xinbiao Pei, Zheng Qiao, Guangxin Wu, and Yue Bai. 2024. "Improved YOLOv7 Target Detection Algorithm Based on UAV Aerial Photography" Drones 8, no. 3: 104. https://doi.org/10.3390/drones8030104
APA StyleBai, Z., Pei, X., Qiao, Z., Wu, G., & Bai, Y. (2024). Improved YOLOv7 Target Detection Algorithm Based on UAV Aerial Photography. Drones, 8(3), 104. https://doi.org/10.3390/drones8030104