
A Survey of Offline- and Online-Learning-Based Algorithms for Multirotor Uavs



Abstract
:1. Introduction
- Navigation task: This refers to the (autonomous or semi-autonomous) function that the multirotor needs to accomplish, given a specific controller design and/or configuration.
- Learning: This refers to ‘what’ the agent learns in order to complete the navigation task.
- Learning algorithm: This refers to the specific algorithm that needs to be followed for the agent to learn. Inherent in this attribute is ‘what’ is being learned by the agent, and ‘how’.
- Real-time applicability: This refers to ‘how fast’ learning is achieved and ‘how computationally expensive’ the learning algorithm is, which basically dictates whether learning is applicable in hard real time or in almost hard real time. Stated differently, the answer to ‘how fast’ determines the implementability of the learning algorithm. The calculation of the algorithm’s computational complexity may also provide additional information on ‘how fast’ the agent learns.
- Pros and Cons: This refers to the advantages and limitations of the underlying learning approach, which, in unison with all other attributes, determines the overall applicability and implementability of the learning approach on multirotor UAVs.
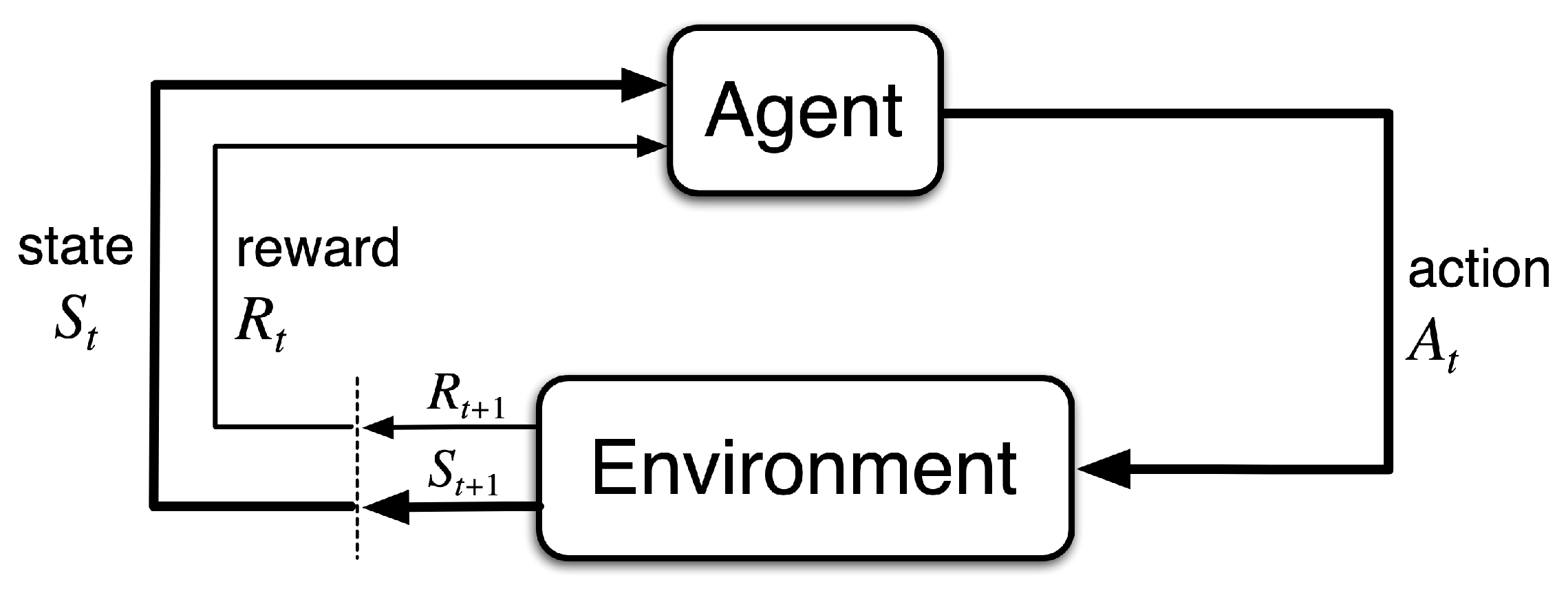
2. Background Information
Definitions
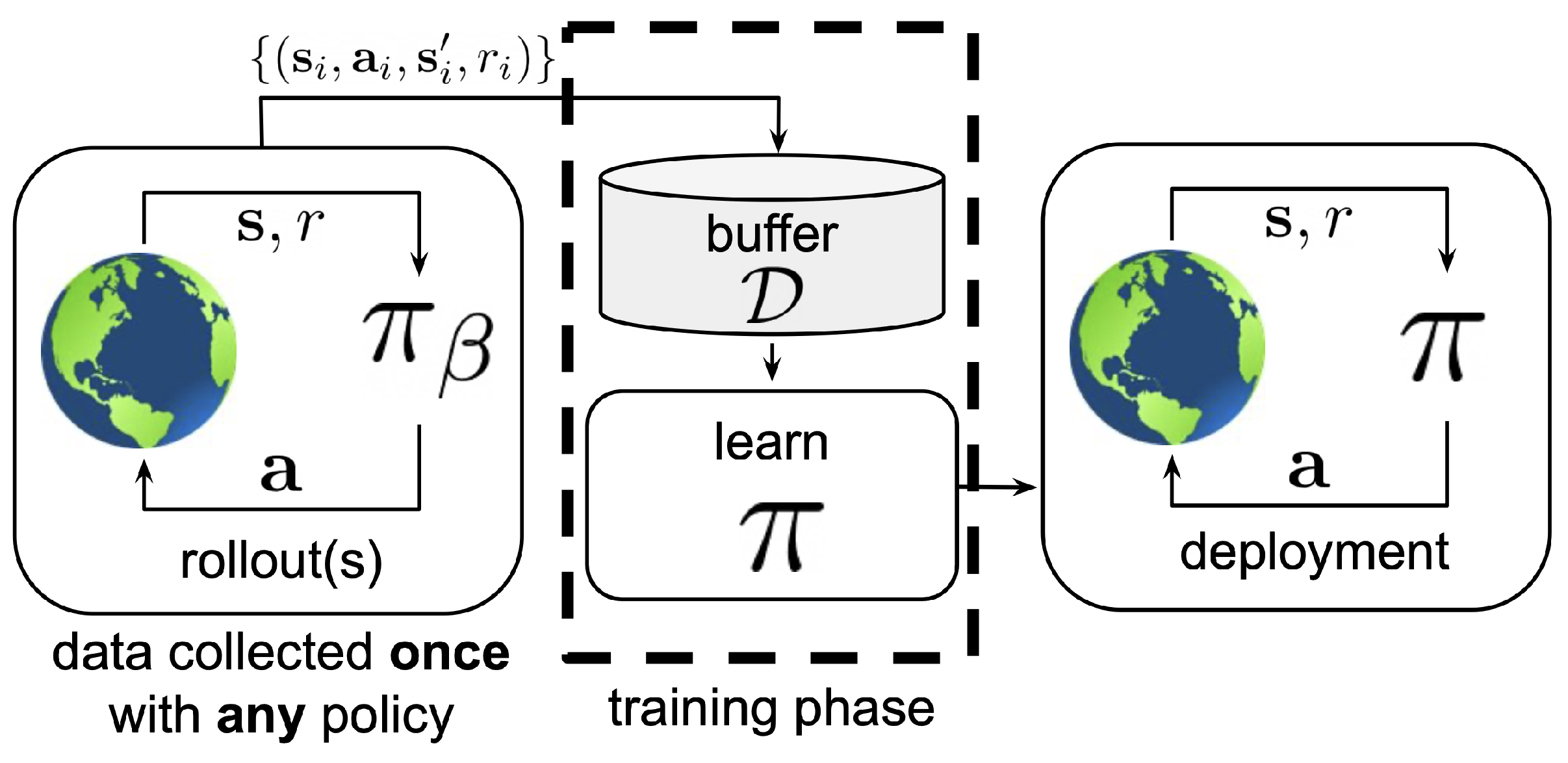
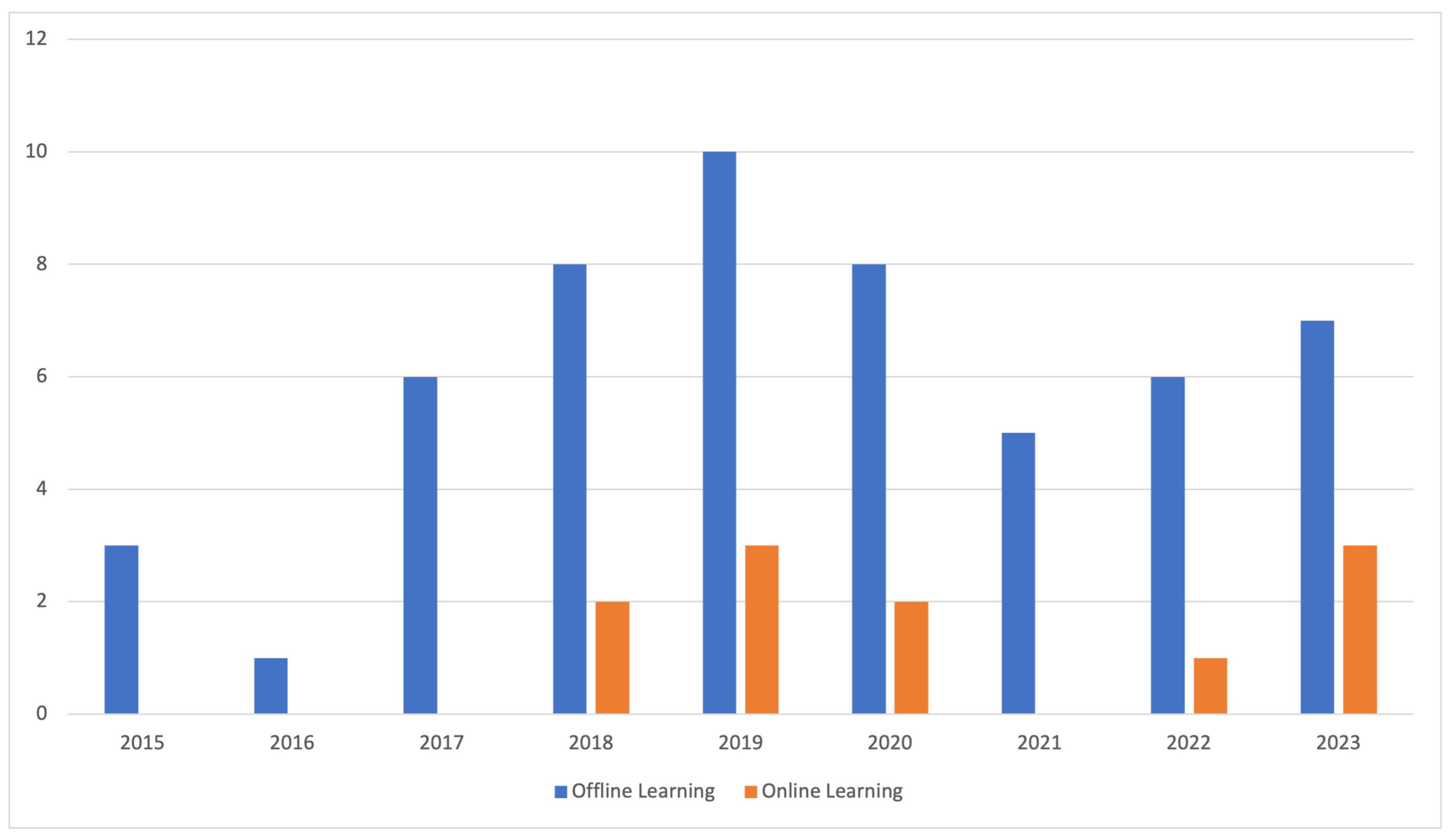
3. Offline Learning
3.1. Machine Learning
- –
- TL if ;
- –
- GS if ;
- –
- TR if .
3.2. Deep Learning
3.3. Reinforcement Learning
3.3.1. Value-Function-Based Algorithms
3.3.2. Policy-Search-Based Algorithms
3.3.3. Actor–Critic Algorithms
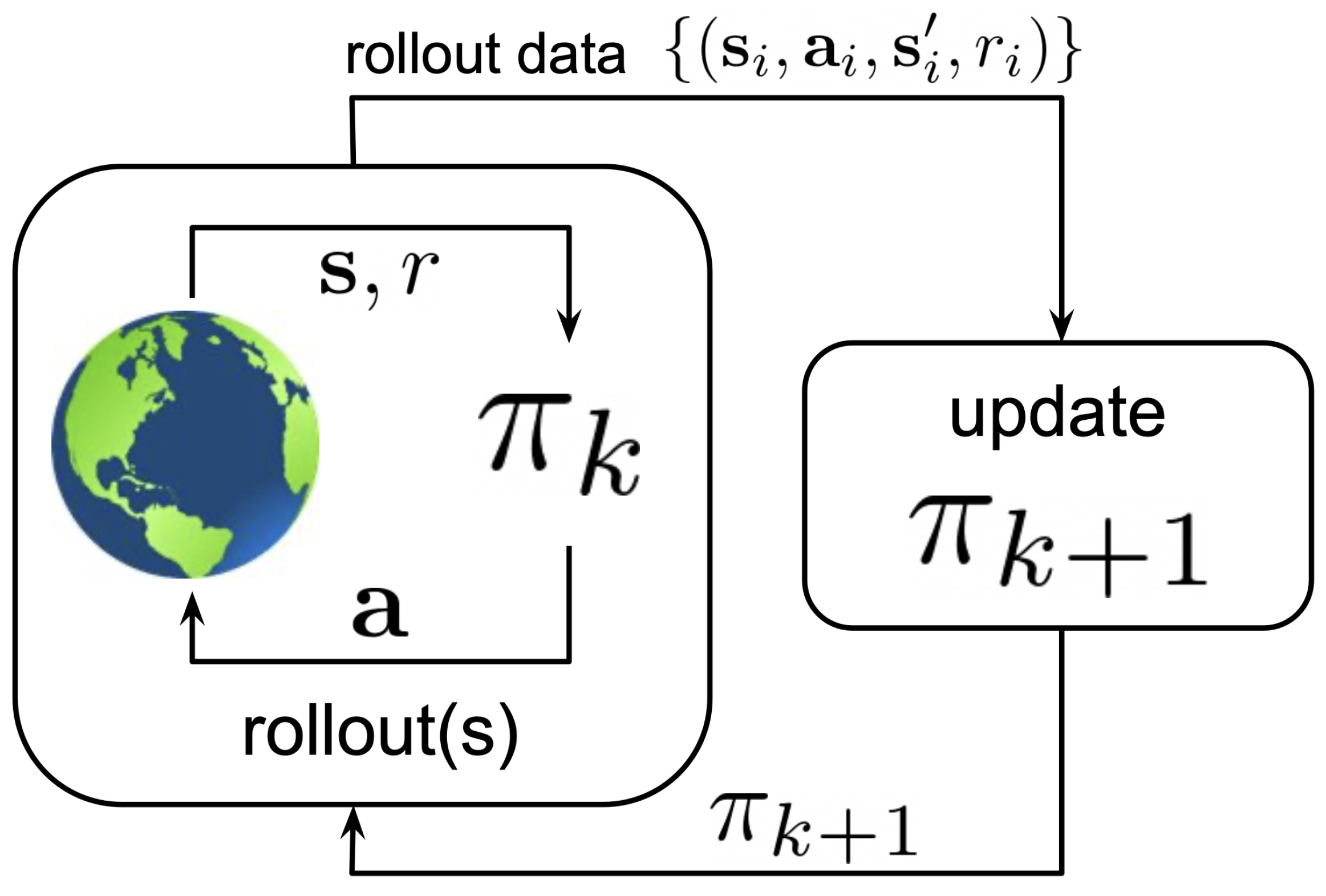
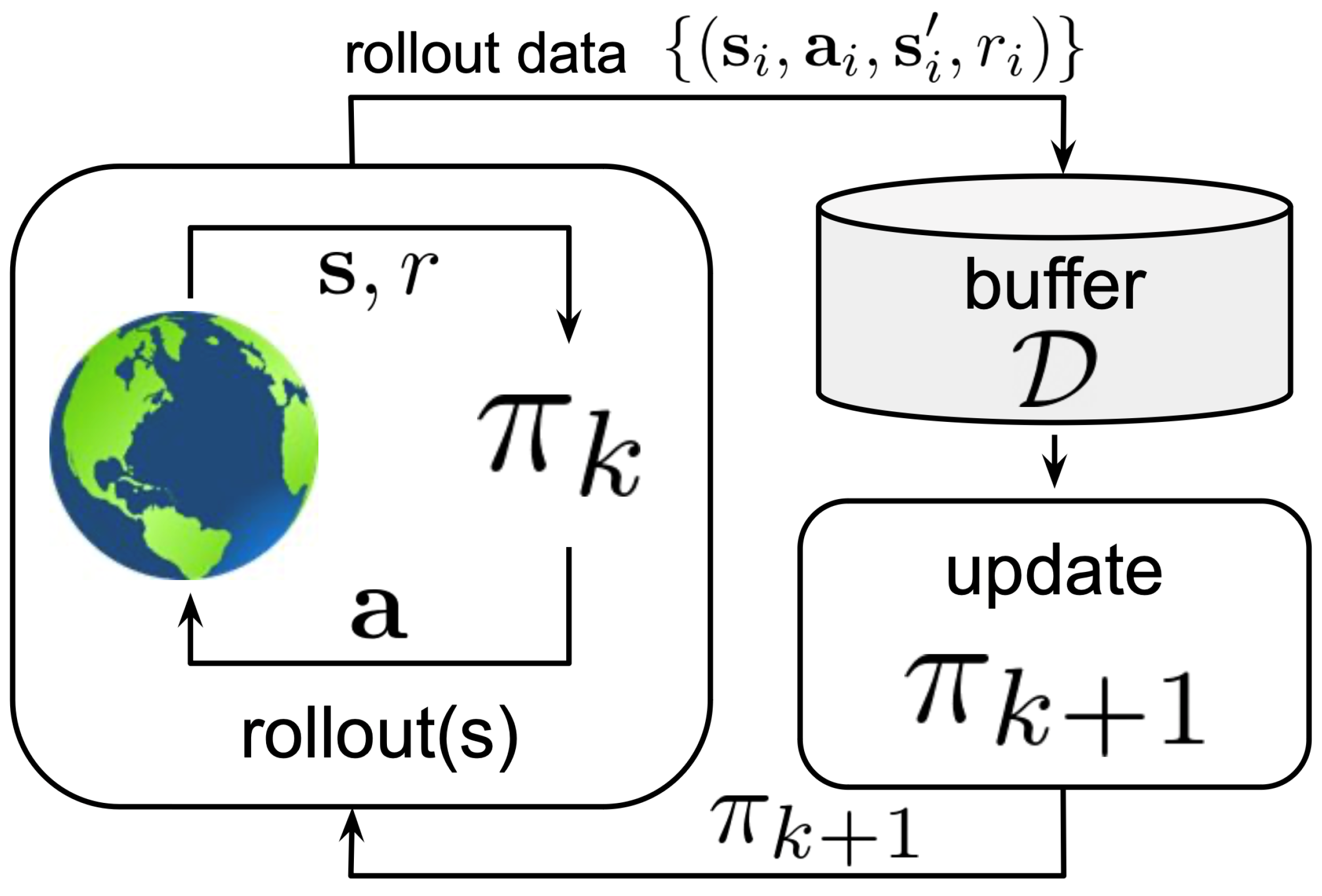
4. Online Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Paper | Task | Algorithm | Model-Free or Model-Based | Advantages | Compared with | Offline Part | Sim/Exp |
|---|---|---|---|---|---|---|---|---|
| 2018 | Yang et al. [86] | Navigation and synchronization | [86] | Model-free | Solves inhomogeneous algebraic Riccati equations online | Adaptive control approach in [87] | No | Sim |
| 2018 | Wang et al. [96] | Environment exploration | Data-driven approach based on Gaussian process | Model-free | Reduces possible crashes in the online learning phase | - | No | Sim |
| 2019 | Sarabakha and Kayacan [90] | Trajectory tracking | Back-propagation | Model-free | - | Offline-trained network, PID controller | Yes | Sim |
| 2019 | He et al. [97] | Agile mobility in a dynamic environment | StateRate | Model-free | Finely adjusts the prediction framework, and onboard sensor data are effectively used | Previous OPT, signal-to-noise rate (SNR), SampleRate, CHARM | Yes | Sim |
| 2019 | Wang et al. [98] | Robust control | DPG-IC | Model-free | Elimination of the steady error | PID controller, DDPG | Yes | Sim |
| 2020 | Shin et al. [89] | Speed optimization | SSD MobileNet | Model-free | Quicker object detection time | - | No | Sim |
| 2020 | Shiri et al. [95] | Path Planning | oHJB | Model-free | The algorithm keeps working even if UAV loses the connection with BS | aHJB, mHJB | No | Sim |
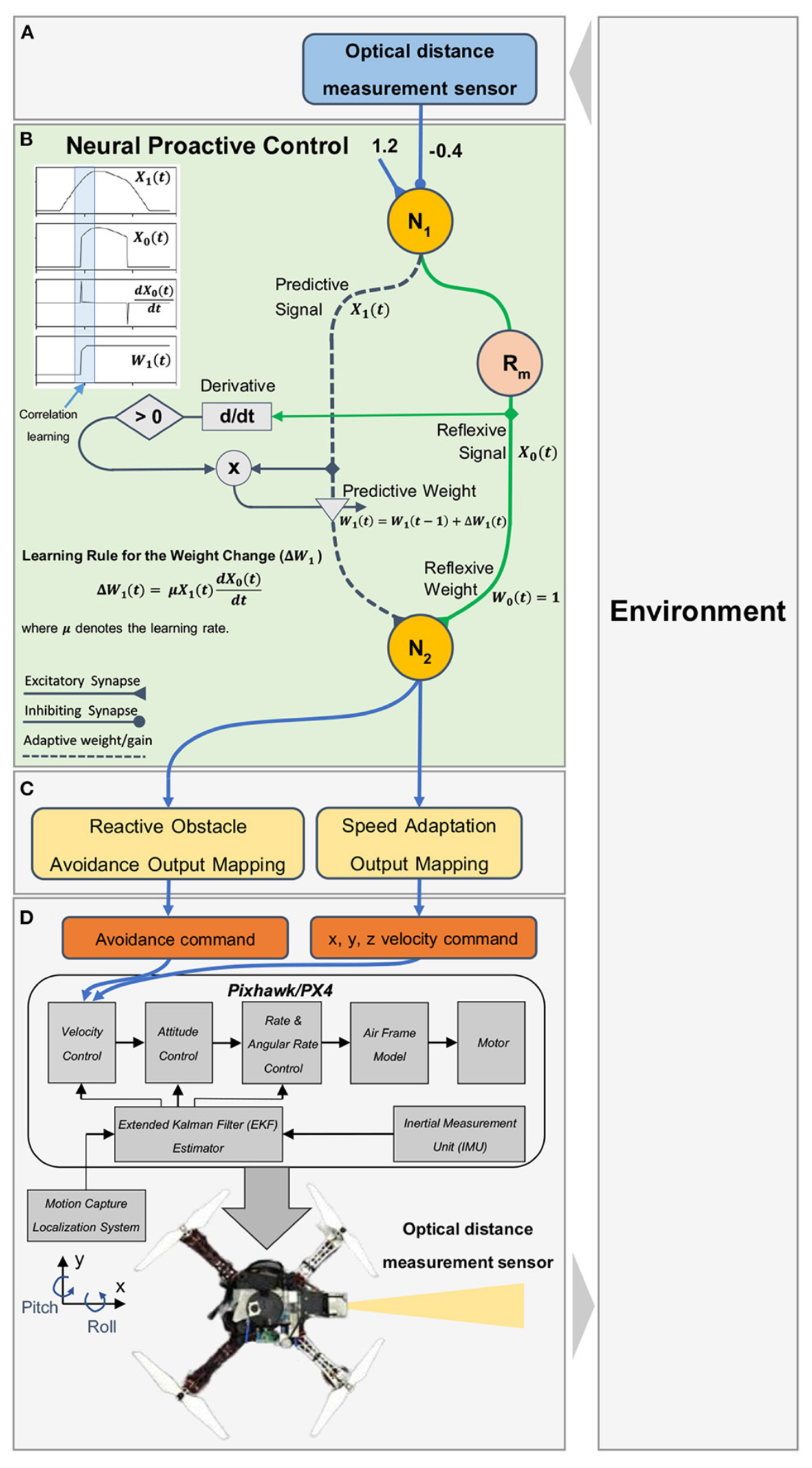
| 2022 | Jaiton et al. [88] | Speed optimization | Neural proactive control | Model-free | Computationally inexpensive | MPC | No | Exp |
| 2023 | O’Connell et al. [99] | Stabilization | DAIML | Model-free | Can control a wide range of quadrotors and not require pre-training for each UAV | Mellinger and Kumar [92], adaptive controller, incremental nonlinear dynamic inversion controller | Yes | Exp |
| 2023 | Jia et al. [93] | Trajectory tracking | RFPID | Model-based | Strong learning ability | PID, Fuzzy-PID | No | Sim |
| 2023 | Zhang et al. [94] | Stabilization | RBiLC | Model-free | Significant improvement in stabilization in roll and pitch, but does not show the same performance in yaw | PID | No | Exp |
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAV | Unmanned aerial vehicle |
| RL | Reinforcement learning |
| DRL | Deep reinforcement learning |
| SARSA | State–Action–Reward–State–Action |
| DDPG | Deep deterministic policy gradient |
| ANN | Artificial neural network |
| ML | Machine learning |
| DL | Deep learning |
| MDP | Markov decision process |
| AI | Artificial Intelligence |
| DNN | Deep neural network |
| NN | Neural network |
| TLD | Tracking–Learning–Detection |
| GCS | Ground control station |
| CNN | Convolutional neural network |
| VIO | Visual-inertial odometry |
| RMLP | Recurrent multilayer perceptron |
| LSTM | Long Short-Term Memory |
| PID | Proportional–Integral–Derivative |
| LQR | Linear–Quadratic Regulator |
| RGB | Red–blue–green |
| MAE | Mean Absolute Error |
| SSD | Single-Shot Detection |
| LOS | Line-Of-Sight |
| MAV | Micro aerial vehicle |
| DSO | Direct sparse odometry |
| LSTMCNN | LSTM Layers interleaved with convolutional 1D layers |
| CLSTM | Convolutional 1D Layers cascaded with LSTM layers |
| DP | Dynamic programming |
| MC | Monte Carlo |
| TD | Temporal Difference |
| DQN | Deep Q-Network |
| AR | Augmented reality |
| GAT | Graph attention network |
| FANAT | Flying ad hoc network |
| GAT-FANET | GAT-based FANET |
| DRGN | Deep Recurrent Graph Network |
| SDRGN | Soft deep recurrent graph network |
| GRU | Gated recurrent unit |
| MAAC | Multi-actor attention critic |
| DGN | Graph Convolutional Reinforcement Learning |
| AMLQ | Adaptive multi-level quantization |
| RRT | Rapidly exploring random tree |
| RSS | Received signal strength |
| HMM | Hidden Markov model |
| DTW | Dynamic time warping |
| DDQN | Double DQN |
| LSPI | Least-Square Policy Iteration |
| ADP | Approximate dynamic programming |
| SOL | Structured online learning-based algorithm |
| PWM | Pulse-width modulation |
| IBVS | Image-based Visual Servoing |
| PBVS | Position-based Visual Servoing |
| PPO | Proximal Policy Optimization |
| PPO-IC | Proximal Policy Optimization-Integral Compensator |
| TD3 | Twin-Delay Deep Deterministic Gradient |
| SAC | Soft Action–Critic |
| PLATO | Policy Learning using Adaptive Trajectory Optimization |
| MPC | Model predictive control |
| UKF | Unscented Kalman Filter |
| PF | Particle Filter |
| TRPO | Trust Region Policy Optimization |
| PILCO | Probabilistic inference for learning control |
| NLGL | Nonlinear Guidance Law |
| POMDP | Partially observable Markov decision process |
| RDPG | Recurrent deterministic policy gradient algorithm |
| DeFRA | DRL-based flight resource allocation framework |
| DQN-FRA | DQNs-based Flight Resource Allocation Policy |
| CAWS | Channel-Aware Waypoint Selection |
| PTRS | Planned Trajectory Random Scheduling |
| DDPG-MC | DDPG-based Movement Control |
| PR | Policy relief |
| SW | Significance weighting |
| TRPO-gae | Trust Region Policy Optimization with a generalized advantage estimator |
| UGV | Unmanned Ground Vehicle |
| meta-TD3 | Meta twin delay deep deterministic policy gradient |
| CdRL | Consciousness-driven reinforcement learning |
| MAPPO | Multi-agent PPO |
| HAPPO | Heterogeneous-agent PPO |
| MADDPG | Multi-agent DDPG |
| ARE | Algebraic Riccati equation |
| FLS | Fuzzy logic system |
| DAIML | Domain adversarially invariant meta-learning |
| RBF | Radial basis function |
| FPID | Fuzzy-PID |
| RBiLC | Real-time brain-inspired learning control |
| HJB | Hamilton–Jacobian–Belmann equation |
| BS | Base station |
| DPG-IC | Deterministic Policy Gradient-Integral Compensator |
References
- Martinez, C.; Sampedro, C.; Chauhan, A.; Campoy, P. Towards autonomous detection and tracking of electric towers for aerial power line inspection. In Proceedings of the 2014 International Conference on Unmanned Aircraft Systems (ICUAS), Orlando, FL, USA, 27–30 May 2014; pp. 284–295. [Google Scholar]
- Ren, H.; Zhao, Y.; Xiao, W.; Hu, Z. A review of UAV monitoring in mining areas: Current status and future perspectives. Int. J. Coal Sci. Technol. 2019, 6, 320–333. [Google Scholar] [CrossRef]
- Olivares-Mendez, M.A.; Fu, C.; Ludivig, P.; Bissyandé, T.F.; Kannan, S.; Zurad, M.; Annaiyan, A.; Voos, H.; Campoy, P. Towards an autonomous vision-based unmanned aerial system against wildlife poachers. Sensors 2015, 15, 31362–31391. [Google Scholar] [CrossRef] [PubMed]
- Bassoli, R.; Sacchi, C.; Granelli, F.; Ashkenazi, I. A virtualized border control system based on UAVs: Design and energy efficiency considerations. In Proceedings of the 2019 IEEE Aerospace Conference, Big Sky, MT, USA, 2–9 March 2019; pp. 1–11. [Google Scholar]
- Carrio, A.; Pestana, J.; Sanchez-Lopez, J.L.; Suarez-Fernandez, R.; Campoy, P.; Tendero, R.; García-De-Viedma, M.; González-Rodrigo, B.; Bonatti, J.; Rejas-Ayuga, J.G.; et al. UBRISTES: UAV-based building rehabilitation with visible and thermal infrared remote sensing. In Proceedings of the Robot 2015: Second Iberian Robotics Conference: Advances in Robotics, Lisbon, Portugal, 19–21 November 2015; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1, pp. 245–256. [Google Scholar]
- Li, L.; Fan, Y.; Huang, X.; Tian, L. Real-time UAV weed scout for selective weed control by adaptive robust control and machine learning algorithm. In Proceedings of the 2016 ASABE Annual International Meeting. American Society of Agricultural and Biological Engineers, Orlando, FL, USA, 17 July–20 July 2016; p. 1. [Google Scholar]
- Carrio, A.; Sampedro, C.; Rodriguez-Ramos, A.; Campoy, P. A review of deep learning methods and applications for unmanned aerial vehicles. J. Sens. 2017, 2017, 3296874. [Google Scholar] [CrossRef]
- Polydoros, A.S.; Nalpantidis, L. Survey of model-based reinforcement learning: Applications on robotics. J. Intell. Robot. Syst. 2017, 86, 153–173. [Google Scholar] [CrossRef]
- Choi, S.Y.; Cha, D. Unmanned aerial vehicles using machine learning for autonomous flight; state-of-the-art. Adv. Robot. 2019, 33, 265–277. [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone deep reinforcement learning: A review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annu. Rev. Control. Robot. Auton. Syst. 2022, 5, 411–444. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Levine, S.; Kumar, A.; Tucker, G.; Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv 2020, arXiv:2005.01643. [Google Scholar]
- Bartak, R.; Vykovskỳ, A. Any object tracking and following by a flying drone. In Proceedings of the 2015 Fourteenth Mexican International Conference on Artificial Intelligence (MICAI), Cuernavaca, Mexico, 25–21 October 2015; pp. 35–41. [Google Scholar]
- Edhah, S.; Mohamed, S.; Rehan, A.; AlDhaheri, M.; AlKhaja, A.; Zweiri, Y. Deep Learning Based Neural Network Controller for Quad Copter: Application to Hovering Mode. In Proceedings of the 2019 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 19–21 November 2019; pp. 1–5. [Google Scholar]
- Xu, Y.; Liu, Z.; Wang, X. Monocular vision based autonomous landing of quadrotor through deep reinforcement learning. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 10014–10019. [Google Scholar]
- Rodriguez-Ramos, A.; Sampedro, C.; Bavle, H.; De La Puente, P.; Campoy, P. A deep reinforcement learning strategy for UAV autonomous landing on a moving platform. J. Intell. Robot. Syst. 2019, 93, 351–366. [Google Scholar] [CrossRef]
- Yoo, J.; Jang, D.; Kim, H.J.; Johansson, K.H. Hybrid reinforcement learning control for a micro quadrotor flight. IEEE Control Syst. Lett. 2020, 5, 505–510. [Google Scholar] [CrossRef]
- Hoi, S.C.; Sahoo, D.; Lu, J.; Zhao, P. Online learning: A comprehensive survey. Neurocomputing 2021, 459, 249–289. [Google Scholar] [CrossRef]
- Giusti, A.; Guzzi, J.; Cireşan, D.C.; He, F.L.; Rodríguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Di Caro, G.; et al. A machine learning approach to visual perception of forest trails for mobile robots. IEEE Robot. Autom. Lett. 2015, 1, 661–667. [Google Scholar] [CrossRef]
- Kaufmann, E.; Loquercio, A.; Ranftl, R.; Dosovitskiy, A.; Koltun, V.; Scaramuzza, D. Deep drone racing: Learning agile flight in dynamic environments. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 133–145. [Google Scholar]
- Janousek, J.; Marcon, P.; Klouda, J.; Pokorny, J.; Raichl, P.; Siruckova, A. Deep Neural Network for Precision Landing and Variable Flight Planning of Autonomous UAV. In Proceedings of the 2021 Photonics & Electromagnetics Research Symposium (PIERS), Hangzhou, China, 21–25 November 2021; pp. 2243–2247. [Google Scholar]
- Vladov, S.; Shmelov, Y.; Yakovliev, R.; Khebda, A.; Brusakova, O. Modified Neural Network Method for Stabilizing Multi-Rotor Unmanned Aerial Vehicles. In Proceedings of the 7th International Conference on Computational Linguistics and Intelligent Systems, Kharkiv, Ukraine, 20–21 April 2023. [Google Scholar]
- Kim, D.K.; Chen, T. Deep neural network for real-time autonomous indoor navigation. arXiv 2015, arXiv:1511.04668. [Google Scholar]
- Li, Q.; Qian, J.; Zhu, Z.; Bao, X.; Helwa, M.K.; Schoellig, A.P. Deep neural networks for improved, impromptu trajectory tracking of quadrotors. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5183–5189. [Google Scholar]
- Smolyanskiy, N.; Kamenev, A.; Smith, J.; Birchfield, S. Toward low-flying autonomous MAV trail navigation using deep neural networks for environmental awareness. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4241–4247. [Google Scholar]
- Jung, S.; Hwang, S.; Shin, H.; Shim, D.H. Perception, guidance, and navigation for indoor autonomous drone racing using deep learning. IEEE Robot. Autom. Lett. 2018, 3, 2539–2544. [Google Scholar] [CrossRef]
- Loquercio, A.; Maqueda, A.I.; Del-Blanco, C.R.; Scaramuzza, D. Dronet: Learning to fly by driving. IEEE Robot. Autom. Lett. 2018, 3, 1088–1095. [Google Scholar] [CrossRef]
- Mantegazza, D.; Guzzi, J.; Gambardella, L.M.; Giusti, A. Vision-based control of a quadrotor in user proximity: Mediated vs end-to-end learning approaches. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6489–6495. [Google Scholar]
- Cardenas, J.A.; Carrero, U.E.; Camacho, E.C.; Calderon, J.M. Intelligent Position Controller for Unmanned Aerial Vehicles (UAV) Based on Supervised Deep Learning. Machines 2023, 11, 606. [Google Scholar] [CrossRef]
- Imanberdiyev, N.; Fu, C.; Kayacan, E.; Chen, I.M. Autonomous navigation of UAV by using real-time model-based reinforcement learning. In Proceedings of the 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), Phuket, Thailand, 13–15 November 2016; pp. 1–6. [Google Scholar]
- Polvara, R.; Patacchiola, M.; Sharma, S.; Wan, J.; Manning, A.; Sutton, R.; Cangelosi, A. Autonomous quadrotor landing using deep reinforcement learning. arXiv 2017, arXiv:1709.03339. [Google Scholar]
- Choi, S.; Kim, S.; Jin Kim, H. Inverse reinforcement learning control for trajectory tracking of a multirotor UAV. Int. J. Control. Autom. Syst. 2017, 15, 1826–1834. [Google Scholar] [CrossRef]
- Kahn, G.; Zhang, T.; Levine, S.; Abbeel, P. Plato: Policy learning using adaptive trajectory optimization. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3342–3349. [Google Scholar]
- Hwangbo, J.; Sa, I.; Siegwart, R.; Hutter, M. Control of a quadrotor with reinforcement learning. IEEE Robot. Autom. Lett. 2017, 2, 2096–2103. [Google Scholar] [CrossRef]
- Lee, S.; Shim, T.; Kim, S.; Park, J.; Hong, K.; Bang, H. Vision-based autonomous landing of a multi-copter unmanned aerial vehicle using reinforcement learning. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 108–114. [Google Scholar]
- Vankadari, M.B.; Das, K.; Shinde, C.; Kumar, S. A reinforcement learning approach for autonomous control and landing of a quadrotor. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018; pp. 676–683. [Google Scholar]
- Kersandt, K.; Muñoz, G.; Barrado, C. Self-training by reinforcement learning for full-autonomous drones of the future. In Proceedings of the 2018 IEEE/AIAA 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018; pp. 1–10. [Google Scholar]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Van Nguyen, L. Reinforcement learning for autonomous uav navigation using function approximation. In Proceedings of the 2018 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Philadelphia, PA, USA, 6–8 August 2018; pp. 1–6. [Google Scholar]
- Liu, H.; Zhao, W.; Lewis, F.L.; Jiang, Z.P.; Modares, H. Attitude synchronization for multiple quadrotors using reinforcement learning. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 2480–2483. [Google Scholar]
- Lambert, N.O.; Drew, D.S.; Yaconelli, J.; Levine, S.; Calandra, R.; Pister, K.S. Low-level control of a quadrotor with deep model-based reinforcement learning. IEEE Robot. Autom. Lett. 2019, 4, 4224–4230. [Google Scholar] [CrossRef]
- Manukyan, A.; Olivares-Mendez, M.A.; Geist, M.; Voos, H. Deep Reinforcement Learning-based Continuous Control for Multicopter Systems. In Proceedings of the 2019 6th International Conference on Control, Decision and Information Technologies (CoDIT), Paris, France, 23–26 April 2019; pp. 1876–1881. [Google Scholar]
- Srivastava, R.; Lima, R.; Das, K.; Maity, A. Least square policy iteration for ibvs based dynamic target tracking. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 1089–1098. [Google Scholar]
- Wu, C.; Ju, B.; Wu, Y.; Lin, X.; Xiong, N.; Xu, G.; Li, H.; Liang, X. UAV autonomous target search based on deep reinforcement learning in complex disaster scene. IEEE Access 2019, 7, 117227–117245. [Google Scholar] [CrossRef]
- Wang, C.; Wang, J.; Shen, Y.; Zhang, X. Autonomous navigation of UAVs in large-scale complex environments: A deep reinforcement learning approach. IEEE Trans. Veh. Technol. 2019, 68, 2124–2136. [Google Scholar] [CrossRef]
- Zeng, Y.; Xu, X. Path design for cellular-connected UAV with reinforcement learning. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Rubí, B.; Morcego, B.; Pérez, R. A Deep Reinforcement Learning Approach for Path Following on a Quadrotor. In Proceedings of the 2020 European Control Conference (ECC), Saint Petersburg, Russia, 12–15 May 2020; pp. 1092–1098. [Google Scholar]
- Pi, C.H.; Hu, K.C.; Cheng, S.; Wu, I.C. Low-level autonomous control and tracking of quadrotor using reinforcement learning. Control Eng. Pract. 2020, 95, 104222. [Google Scholar] [CrossRef]
- Zhao, W.; Liu, H.; Lewis, F.L. Robust formation control for cooperative underactuated quadrotors via reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4577–4587. [Google Scholar] [CrossRef] [PubMed]
- Guerra, A.; Guidi, F.; Dardari, D.; Djurić, P.M. Reinforcement learning for UAV autonomous navigation, mapping and target detection. In Proceedings of the 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, OR, USA, 20–23 April 2020; pp. 1004–1013. [Google Scholar]
- Li, B.; Gan, Z.; Chen, D.; Sergey Aleksandrovich, D. UAV maneuvering target tracking in uncertain environments based on deep reinforcement learning and meta-learning. Remote Sens. 2020, 12, 3789. [Google Scholar] [CrossRef]
- Kulkarni, S.; Chaphekar, V.; Chowdhury, M.M.U.; Erden, F.; Guvenc, I. UAV aided search and rescue operation using reinforcement learning. In Proceedings of the 2020 SoutheastCon, Raleigh, NC, USA, 28–29 March 2020; Volume 2, pp. 1–8. [Google Scholar]
- Hu, H.; Wang, Q.l. Proximal policy optimization with an integral compensator for quadrotor control. Front. Inf. Technol. Electron. Eng. 2020, 21, 777–795. [Google Scholar] [CrossRef]
- Kooi, J.E.; Babuška, R. Inclined Quadrotor Landing using Deep Reinforcement Learning. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 2361–2368. [Google Scholar]
- Rubí, B.; Morcego, B.; Pérez, R. Deep reinforcement learning for quadrotor path following with adaptive velocity. Auton. Robot. 2021, 45, 119–134. [Google Scholar] [CrossRef]
- Bhan, L.; Quinones-Grueiro, M.; Biswas, G. Fault Tolerant Control combining Reinforcement Learning and Model-based Control. In Proceedings of the 2021 5th International Conference on Control and Fault-Tolerant Systems (SysTol), Saint-Raphael, France, 29 September–1 October2021; pp. 31–36. [Google Scholar]
- Li, X.; Zhang, J.; Han, J. Trajectory planning of load transportation with multi-quadrotors based on reinforcement learning algorithm. Aerosp. Sci. Technol. 2021, 116, 106887. [Google Scholar] [CrossRef]
- Jiang, Z.; Song, G. A Deep Reinforcement Learning Strategy for UAV Autonomous Landing on a Platform. arXiv 2022, arXiv:2209.02954. [Google Scholar]
- Abo Mosali, N.; Shamsudin, S.S.; Mostafa, S.A.; Alfandi, O.; Omar, R.; Al-Fadhali, N.; Mohammed, M.A.; Malik, R.; Jaber, M.M.; Saif, A. An Adaptive Multi-Level Quantization-Based Reinforcement Learning Model for Enhancing UAV Landing on Moving Targets. Sustainability 2022, 14, 8825. [Google Scholar] [CrossRef]
- Panetsos, F.; Karras, G.C.; Kyriakopoulos, K.J. A deep reinforcement learning motion control strategy of a multi-rotor uav for payload transportation with minimum swing. In Proceedings of the 2022 30th Mediterranean Conference on Control and Automation (MED), Vouliagmeni, Greece, 28 June–1 July 2022; pp. 368–374. [Google Scholar]
- Ye, Z.; Wang, K.; Chen, Y.; Jiang, X.; Song, G. Multi-UAV Navigation for Partially Observable Communication Coverage by Graph Reinforcement Learning. IEEE Trans. Mob. Comput. 2022, 22, 4056–4069. [Google Scholar] [CrossRef]
- Wang, X.; Ye, X. Consciousness-driven reinforcement learning: An online learning control framework. Int. J. Intell. Syst. 2022, 37, 770–798. [Google Scholar] [CrossRef]
- Farsi, M.; Liu, J. Structured online learning for low-level control of quadrotors. In Proceedings of the 2022 American Control Conference (ACC), Atlanta, GA, USA, 8–10 June 2022; pp. 1242–1247. [Google Scholar]
- Xia, K.; Huang, Y.; Zou, Y.; Zuo, Z. Reinforcement Learning Control for Moving Target Landing of VTOL UAVs with Motion Constraints. IEEE Trans. Ind. Electron. 2023. [Google Scholar] [CrossRef]
- Ma, B.; Liu, Z.; Dang, Q.; Zhao, W.; Wang, J.; Cheng, Y.; Yuan, Z. Deep Reinforcement Learning of UAV Tracking Control Under Wind Disturbances Environments. IEEE Trans. Instrum. Meas. 2023, 72, 2510913. [Google Scholar] [CrossRef]
- Castro, G.G.d.; Berger, G.S.; Cantieri, A.; Teixeira, M.; Lima, J.; Pereira, A.I.; Pinto, M.F. Adaptive Path Planning for Fusing Rapidly Exploring Random Trees and Deep Reinforcement Learning in an Agriculture Dynamic Environment UAVs. Agriculture 2023, 13, 354. [Google Scholar] [CrossRef]
- Mitakidis, A.; Aspragkathos, S.N.; Panetsos, F.; Karras, G.C.; Kyriakopoulos, K.J. A Deep Reinforcement Learning Visual Servoing Control Strategy for Target Tracking Using a Multirotor UAV. In Proceedings of the 2023 9th International Conference on Automation, Robotics and Applications (ICARA), Abu Dhabi, United Arab Emirates, 10–12 February 2023; pp. 219–224. [Google Scholar]
- Shurrab, M.; Mizouni, R.; Singh, S.; Otrok, H. Reinforcement learning framework for UAV-based target localization applications. Internet Things 2023, 23, 100867. [Google Scholar] [CrossRef]
- Santana, P.; Correia, L.; Mendonça, R.; Alves, N.; Barata, J. Tracking natural trails with swarm-based visual saliency. J. Field Robot. 2013, 30, 64–86. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Caffe|Model Zoo. Available online: http://caffe.berkeleyvision.org/model_zoo.html (accessed on 11 October 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Li, K.; Ni, W.; Dressler, F. LSTM-characterized Deep Reinforcement Learning for Continuous Flight Control and Resource Allocation in UAV-assisted Sensor Network. IEEE Internet Things J. 2021, 9, 4179–4189. [Google Scholar] [CrossRef]
- Bilgin, E. Mastering Reinforcement Learning with Python: Build Next-Generation, Self-Learning Models Using Reinforcement Learning Techniques and Best Practices; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Lapan, M. Deep Reinforcement Learning Hands-On: Apply Modern RL Methods to Practical Problems of Chatbots, Robotics, Discrete Optimization, Web Automation, and More; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Lapan, M. Deep Reinforcement Learning Hands-On: Apply Modern RL Methods, with Deep Q-Networks, Value Iteration, Policy Gradients, TRPO, AlphaGo Zero and More; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Polvara, R.; Patacchiola, M.; Hanheide, M.; Neumann, G. Sim-to-Real quadrotor landing via sequential deep Q-Networks and domain randomization. Robotics 2020, 9, 8. [Google Scholar] [CrossRef]
- Farsi, M.; Liu, J. Structured online learning-based control of continuous-time nonlinear systems. IFAC-PapersOnLine 2020, 53, 8142–8149. [Google Scholar] [CrossRef]
- Kanellakis, C.; Nikolakopoulos, G. Survey on computer vision for UAVs: Current developments and trends. J. Intell. Robot. Syst. 2017, 87, 141–168. [Google Scholar] [CrossRef]
- Stevens, B.L.; Lewis, F.L.; Johnson, E.N. Aircraft Control and Simulation: Dynamics, Controls Design, and Autonomous Systems; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Xu, B.; Gao, F.; Yu, C.; Zhang, R.; Wu, Y.; Wang, Y. Omnidrones: An efficient and flexible platform for reinforcement learning in drone control. IEEE Robot. Autom. Lett. 2024, 9, 2838–2844. [Google Scholar] [CrossRef]
- Srinivasan, D. Innovations in Multi-Agent Systems and Application—1; Springer: Berlin/Heidelberg, Germany, 2010; Volume 310. [Google Scholar]
- Van Otterlo, M.; Wiering, M. Reinforcement learning and markov decision processes. In Reinforcement Learning: State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–42. [Google Scholar]
- Yang, Y.; Modares, H.; Wunsch, D.C.; Yin, Y. Leader–follower output synchronization of linear heterogeneous systems with active leader using reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2139–2153. [Google Scholar] [CrossRef]
- Das, A.; Lewis, F.L. Distributed adaptive control for synchronization of unknown nonlinear networked systems. Automatica 2010, 46, 2014–2021. [Google Scholar] [CrossRef]
- Jaiton, V.; Rothomphiwat, K.; Ebeid, E.; Manoonpong, P. Neural Control and Online Learning for Speed Adaptation of Unmanned Aerial Vehicles. Front. Neural Circuits 2022, 16, 839361. [Google Scholar] [CrossRef]
- Shin, S.; Kang, Y.; Kim, Y.G. Evolution algorithm and online learning for racing drone. In Proceedings of the NeurIPS 2019 Competition and Demonstration Track, Vancouver, BC, Canada, 10–12 December 2020; pp. 100–109. [Google Scholar]
- Sarabakha, A.; Kayacan, E. Online deep learning for improved trajectory tracking of unmanned aerial vehicles using expert knowledge. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7727–7733. [Google Scholar]
- O’Connell, M.; Shi, G.; Shi, X.; Azizzadenesheli, K.; Anandkumar, A.; Yue, Y.; Chung, S.J. Neural-fly enables rapid learning for agile flight in strong winds. Sci. Robot. 2022, 7, eabm6597. [Google Scholar] [CrossRef] [PubMed]
- Mellinger, D.; Kumar, V. Minimum snap trajectory generation and control for quadrotors. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2520–2525. [Google Scholar]
- Jia, K.; Lin, S.; Du, Y.; Zou, C.; Lu, M. Research on route tracking controller of Quadrotor UAV based on fuzzy logic and RBF neural network. IEEE Access 2023, 11, 111433–111447. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Y.; Chen, W.; Yang, H. Realtime Brain-Inspired Adaptive Learning Control for Nonlinear Systems with Configuration Uncertainties. IEEE Trans. Autom. Sci. Eng. 2023. [Google Scholar] [CrossRef]
- Shiri, H.; Park, J.; Bennis, M. Remote UAV online path planning via neural network-based opportunistic control. IEEE Wirel. Commun. Lett. 2020, 9, 861–865. [Google Scholar] [CrossRef]
- Wang, L.; Theodorou, E.A.; Egerstedt, M. Safe learning of quadrotor dynamics using barrier certificates. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2460–2465. [Google Scholar]
- He, S.; Wang, W.; Yang, H.; Cao, Y.; Jiang, T.; Zhang, Q. State-aware rate adaptation for UAVs by incorporating on-board sensors. IEEE Trans. Veh. Technol. 2019, 69, 488–496. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, J.; He, H.; Sun, C. Deterministic policy gradient with integral compensator for robust quadrotor control. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 50, 3713–3725. [Google Scholar] [CrossRef]
- O’Connell, M.; Shi, G.; Shi, X.; Azizzadenesheli, K.; Anandkumar, A.; Yue, Y.; Chung, S.J. Pretraining Neural-Networks with Neural-Fly for Rapid Online Learning. In Proceedings of the ICRA2023 Workshop on Pretraining for Robotics (PT4R), London, UK, 29 May 2023. [Google Scholar]






| Year | Authors | Learning Model | Application Task | What Is Being Learned |
|---|---|---|---|---|
| 2015 | Bartak et al. [14] | ML | Object tracking | How to detect an object |
| 2015 | Giusti et al. [20] | ML | Navigation | Image classification to determine the direction |
| 2018 | Kaufmann et al. [21] | ML | Waypoints and the desired velocity | How to detect an object |
| 2021 | Janousek et al. [22] | ML | Landing and flight planning | How to recognize an object |
| 2023 | Vladov et al. [23] | ML | Stabilization | How to adjust controller parameters |
| 2015 | Kim et al. [24] | DL | Navigation | Image classification to assist in flights |
| 2017 | Li et al. [25] | DL | Trajectory tracking | Control signals |
| 2017 | Smolyanskiy et al. [26] | DL | Navigation | The view orientation and lateral offset |
| 2018 | Jung et al. [27] | DL | Navigation | How to detect the center of a gate |
| 2018 | Loquercio et al. [28] | DL | Navigation | How to adjust the yaw angle and the probability of collision |
| 2019 | Edhah et al. [15] | DL | Hovering | How to determine propeller speed |
| 2019 | Mantegazza et al. [29] | DL | Ground target tracking | Image classification for control |
| 2023 | Cardenas et al. [30] | DL | Position control | How to determine the rotor speeds |
| 2016 | Imanberdiyev et al. [31] | RL | Navigation | How to select the moving direction |
| 2017 | Polvara et al. [32] | RL | Landing | How to detect a landmark and control vertical descent |
| 2017 | Choi et al. [33] | RL | Trajectory tracking | The control input |
| 2017 | Kahn et al. [34] | RL | Avoiding failure | The policy |
| 2017 | Hwangbo et al. [35] | RL | Stabilization | How to determine the rotor thrusts |
| 2018 | Xu et al. [16] | RL | Landing | How to determine the velocities of the UAV |
| 2018 | Lee et al. [36] | RL | Landing | How to determine the roll and pitch angles |
| 2018 | Vankadari et al. [37] | RL | Landing | How to determine the velocities of the UAV on the x- and y-axes |
| 2018 | Kersandt et al. [38] | RL | Navigation | How to select three actions: move forward, turn right, and turn left |
| 2018 | Pham et al. [39] | RL | Navigation | How to select the moving direction |
| 2019 | Rodriguez et al. [17] | RL | Landing | How to determine the velocities of the UAV on the x- and y-axes |
| 2019 | Liu et al. [40] | RL | Formation control | The optimal control law |
| 2019 | Lambert et al. [41] | RL | Hovering | The mean and variance of the changes in states |
| 2019 | Manukyan et al. [42] | RL | Hovering | How to determine the rotor speeds |
| 2019 | Srivastava et al. [43] | RL | Target tracking | How to determine the velocities of the UAV on the x-, y-, and z-axes |
| 2019 | Wu et al. [44] | RL | Trajectory planning | How to select the moving direction |
| 2019 | Wang et al. [45] | RL | Navigation | How to determine the steering angle |
| 2019 | Zeng and Xu [46] | RL | Path Planning | How to select the flight direction |
| 2020 | Yoo et al. [18] | RL | Trajectory tracking | How to adjust PD and LQR controller gains |
| 2020 | Rubi et al. [47] | RL | Trajectory tracking | How to determine the yaw angle |
| 2020 | Pi et al. [48] | RL | Trajectory tracking | How to determine the rotor thrusts |
| 2020 | Zhao et al. [49] | RL | Formation control | How to solve the Bellman equation |
| 2020 | Guerra et al. [50] | RL | Trajectory optimization | The control signal |
| 2020 | Li et al. [51] | RL | Target tracking | How to determine the angular velocity of the yaw angle and linear acceleration |
| 2020 | Kulkarni et al. [52] | RL | Navigation | How to select the moving direction |
| 2020 | Hu and Wang [53] | RL | Speed optimization | How to determine the rotor speeds |
| 2021 | Kooi et al. [54] | RL | Landing | How to determine the total thrust and the roll and pitch angles |
| 2021 | Rubi et al. [55] | RL | Trajectory tracking | How to determine the yaw angle |
| 2021 | Bhan et al. [56] | RL | Avoiding failure | How to adjust the gains of the PD position controller |
| 2021 | Li et al. [57] | RL | Trajectory planning | How to obtain the parameter vector of the approximate value function |
| 2022 | Jiang et al. [58] | RL | Landing | How to determine the velocity of the UAV on the x- and y-axes |
| 2022 | Abo et al. [59] | RL | Landing | How to determine the roll, pitch, and yaw angles and the velocity of the UAV on the z-axis |
| 2022 | Panetsos et al. [60] | RL | Payload transportation | How to obtain the reference Euler angles and velocity on the z-axis |
| 2022 | Ye et al. [61] | RL | Navigation | How to select the moving direction and determine the velocity |
| 2022 | Wang and Ye [62] | RL | Trajectory tracking | How to determine the pitch and roll torques |
| 2022 | Farsi and Liu [63] | RL | Hovering | How to determine the rotor speeds |
| 2023 | Xia et al. [64] | RL | Landing | How to obtain the force and torque command |
| 2023 | Ma et al. [65] | RL | Trajectory tracking | How to determine the rotor speeds |
| 2023 | Castro et al. [66] | RL | Path Planning | How to find optimized routes for navigation |
| 2023 | Mitakidis et al. [67] | RL | Target tracking | How to obtain the roll, pitch, and yaw actions |
| 2023 | Shurrab et al. [68] | RL | Target localization | How to determine the linear velocity and yaw angle |
| Methods | Algorithms | Papers |
|---|---|---|
| Value-function-based | Q-learning | Guerra et al. [50], Pham et al. [39], Kulkarni et al. [52], Abo et al. [59], Zeng and Xu [46] |
| DQN | Xu et al. [16], Polvara et al. [32], Castro et al. [66], Shurrab et al. [68], Wu et al. [44], Kersandt et al. [38] | |
| LSPI | Vankadari et al. [37], Lee et al. [36], Srivastava et al. [43] | |
| IRL | Choi et al. [33] | |
| Others | Imanberdiyev et al. [31], Ye et al. [61], Farsi and Liu [63], Li et al. [57], Xia et al. [64] | |
| Policy-search-based | PPO | Kooi and Babuška [54], Bhan et al [56] |
| TRPO | Manukyan et al. [42] | |
| PILCO | Yoo et al. [18] | |
| PLATO | Kahn et al. [34] | |
| Others | Hu and Wang [53], Lambert et al. [41] | |
| Actor–critic | DDPG | Jiang and Song [58], Rodriguez et al. [17], Rubi et al. [47], Rubi et al. [55], Ma et al. [65], Mitakidis et al. [67] |
| TD3 | Jiang and Song [58], Kooi and Babuška [54], Li et al. [51], Panetsos et al. [60] | |
| SAC | Jiang and Song [58], Kooi and Babuška [54], | |
| Fast-RDPG | Wang et al. [45] | |
| DeFRA | Li et al. [75] | |
| CdRL | Wang and Ye [62] | |
| Others | Pi et al. [48], Hwangbo et al. [35] |
| Value-Function-Based | Policy-Search-Based |
|---|---|
| Indirect policy optimization | Direct policy optimization |
| Generally off-policy | On-policy |
| Simpler algorithm | Complex algorithm |
| Computationally expensive | Computationally inexpensive |
| More iterations to converge | Fewer iterations to converge |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sönmez, S.; Rutherford, M.J.; Valavanis, K.P. A Survey of Offline- and Online-Learning-Based Algorithms for Multirotor Uavs. Drones 2024, 8, 116. https://doi.org/10.3390/drones8040116
Sönmez S, Rutherford MJ, Valavanis KP. A Survey of Offline- and Online-Learning-Based Algorithms for Multirotor Uavs. Drones. 2024; 8(4):116. https://doi.org/10.3390/drones8040116
Chicago/Turabian StyleSönmez, Serhat, Matthew J. Rutherford, and Kimon P. Valavanis. 2024. "A Survey of Offline- and Online-Learning-Based Algorithms for Multirotor Uavs" Drones 8, no. 4: 116. https://doi.org/10.3390/drones8040116
APA StyleSönmez, S., Rutherford, M. J., & Valavanis, K. P. (2024). A Survey of Offline- and Online-Learning-Based Algorithms for Multirotor Uavs. Drones, 8(4), 116. https://doi.org/10.3390/drones8040116