
Enhancing UAV Aerial Docking: A Hybrid Approach Combining Offline and Online Reinforcement Learning



Abstract
:1. Introduction
- We developed an expert strategy scheme that combines hybrid force/position control to solve the docking problem during the interaction process of two quadrotors.
- For aerial docking tasks, we designed effective rewards for RL to support strategy training.
- We efficiently combined offline learning and online learning strategies in RL, effectively increasing the success rate of the entire training task to 95%.
2. Problem Definition
2.1. Quadrotor Dynamics
2.2. Thrust-Omega Controller
2.3. Reinforcement Learning
3. Method
3.1. Rule-Based Expert Policy
3.2. Offline-to-Online Reinforcement Learning
3.3. Reward Function
4. Simulation and Result
4.1. Online RL Simulation
4.2. Offline RL Simulation
4.3. Offline-to-Online RL Simulation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Karakostas, I.; Mademlis, I.; Nikolaidis, N.; Pitas, I. Shot type constraints in UAV cinematography for autonomous target tracking. Inf. Sci. 2020, 506, 273–294. [Google Scholar] [CrossRef]
- Shi, C.; Lai, G.; Yu, Y.; Bellone, M.; Lippiello, V. Real-Time Multi-Modal Active Vision for Object Detection on UAVs Equipped with Limited Field of View LiDAR and Camera. IEEE Robot. Autom. Lett. 2023, 8, 6571–6578. [Google Scholar] [CrossRef]
- Sharma, A.; Vanjani, P.; Paliwal, N.; Basnayaka, C.M.W.; Jayakody, D.N.K.; Wang, H.C.; Muthuchidambaranathan, P. Communication and networking technologies for UAVs: A survey. J. Netw. Comput. Appl. 2020, 168, 102739. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, K.; Du, J.; Xu, B.; Xiang, C. Design and Trajectory Linearization Geometric Control of Multiple Aerial Vehicles Assembly. J. Mech. Eng. 2022, 58, 16–26. [Google Scholar] [CrossRef]
- Nguyen, H.N.; Park, S.; Park, J.; Lee, D. A novel robotic platform for aerial manipulation using quadrotors as rotating thrust generators. IEEE Trans. Robot. 2018, 34, 353–369. [Google Scholar] [CrossRef]
- Yu, Y.; Shi, C.; Shan, D.; Lippiello, V.; Yang, Y. A hierarchical control scheme for multiple aerial vehicle transportation systems with uncertainties and state/input constraints. Appl. Math. Model. 2022, 109, 651–678. [Google Scholar] [CrossRef]
- Sanalitro, D.; Savino, H.J.; Tognon, M.; Cortés, J.; Franchi, A. Full-Pose Manipulation Control of a Cable-Suspended Load with Multiple UAVs Under Uncertainties. IEEE Robot. Autom. Lett. 2020, 5, 2185–2191. [Google Scholar] [CrossRef]
- Park, S.; Lee, Y.; Heo, J.; Lee, D. Pose and Posture Estimation of Aerial Skeleton Systems for Outdoor Flying. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 704–710. [Google Scholar] [CrossRef]
- Park, S.; Lee, J.; Ahn, J.; Kim, M.; Her, J.; Yang, G.H.; Lee, D. ODAR: Aerial Manipulation Platform Enabling Omnidirectional Wrench Generation. IEEE/ASME Trans. Mechatron. 2018, 23, 1907–1918. [Google Scholar] [CrossRef]
- Sugihara, J.; Nishio, T.; Nagato, K.; Nakao, M.; Zhao, M. Design, Control, and Motion Strategy of TRADY: Tilted-Rotor-Equipped Aerial Robot with Autonomous In-flight Assembly and Disassembly Ability. arXiv 2023, arXiv:2303.07106. [Google Scholar]
- Zhang, M.; Li, M.; Wang, K.; Yang, T.; Feng, Y.; Yu, Y. Zero-Shot Sim-To-Real Transfer of Robust and Generic Quadrotor Controller by Deep Reinforcement Learning. In Proceedings of the International Conference on Cognitive Systems and Signal Processing, LuoYang, China, 10–12 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 27–43. [Google Scholar]
- Feng, Y.; Shi, C.; Du, J.; Yu, Y.; Sun, F.; Song, Y. Variable admittance interaction control of UAVs via deep reinforcement learning. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1291–1297. [Google Scholar]
- Song, Y.; Romero, A.; Müller, M.; Koltun, V.; Scaramuzza, D. Reaching the limit in autonomous racing: Optimal control versus reinforcement learning. Sci. Robot. 2023, 8, eadg1462. [Google Scholar] [CrossRef]
- Kaufmann, E.; Bauersfeld, L.; Loquercio, A.; Müller, M.; Koltun, V.; Scaramuzza, D. Champion-level drone racing using deep reinforcement learning. Nature 2023, 620, 982–987. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Chikhaoui, K.; Ghazzai, H.; Massoud, Y. PPO-based reinforcement learning for UAV navigation in urban environments. In Proceedings of the 2022 IEEE 65th International Midwest Symposium on Circuits and Systems (MWSCAS), Fukuoka, Japan, 7–10 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Guan, Y.; Zou, S.; Peng, H.; Ni, W.; Sun, Y.; Gao, H. Cooperative UAV trajectory design for disaster area emergency communications: A multi-agent PPO method. IEEE Internet Things J. 2023, 11, 8848–8859. [Google Scholar] [CrossRef]
- Molchanov, A.; Chen, T.; Hönig, W.; Preiss, J.A.; Ayanian, N.; Sukhatme, G.S. Sim-to-(multi)-real: Transfer of low-level robust control policies to multiple quadrotors. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macao, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 59–66. [Google Scholar]
- Vithayathil Varghese, N.; Mahmoud, Q.H. A survey of multi-task deep reinforcement learning. Electronics 2020, 9, 1363. [Google Scholar] [CrossRef]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning, New York, NY, USA, 4 July 2004; p. 1. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the AAAI, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 1433–1438. [Google Scholar]
- Arora, S.; Banerjee, B.; Doshi, P. Maximum Entropy Multi-Task Inverse RL. arXiv 2020, arXiv:2004.12873. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Advances in Neural Information Processing Systems 29, Proceedings of the 30th Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; NeurIPS: La Jolla, CA, USA, 2016. [Google Scholar]
- Peng, X.B.; Ma, Z.; Abbeel, P.; Levine, S.; Kanazawa, A. Amp: Adversarial motion priors for stylized physics-based character control. ACM Trans. Graph. (ToG) 2021, 40, 1–20. [Google Scholar] [CrossRef]
- Vollenweider, E.; Bjelonic, M.; Klemm, V.; Rudin, N.; Lee, J.; Hutter, M. Advanced skills through multiple adversarial motion priors in reinforcement learning. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 5120–5126. [Google Scholar]
- Wu, J.; Xin, G.; Qi, C.; Xue, Y. Learning robust and agile legged locomotion using adversarial motion priors. IEEE Robot. Autom. Lett. 2023, 8, 4975–4982. [Google Scholar] [CrossRef]
- Pomerleau, D.A. Efficient training of artificial neural networks for autonomous navigation. Neural Comput. 1991, 3, 88–97. [Google Scholar] [CrossRef] [PubMed]
- Torabi, F.; Warnell, G.; Stone, P. Behavioral cloning from observation. arXiv 2018, arXiv:1805.01954. [Google Scholar]
- Kumar, A.; Hong, J.; Singh, A.; Levine, S. Should i run offline reinforcement learning or behavioral cloning? In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Yang, J.; Zhou, K.; Li, Y.; Liu, Z. Generalized out-of-distribution detection: A survey. arXiv 2021, arXiv:2110.11334. [Google Scholar]
- Levine, S.; Kumar, A.; Tucker, G.; Fu, J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv 2020, arXiv:2005.01643. [Google Scholar]
- Kumar, A.; Zhou, A.; Tucker, G.; Levine, S. Conservative q-learning for offline reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 1179–1191. [Google Scholar]
- Fujimoto, S.; Gu, S.S. A minimalist approach to offline reinforcement learning. Adv. Neural Inf. Process. Syst. 2021, 34, 20132–20145. [Google Scholar]
- Agarwal, R.; Schuurmans, D.; Norouzi, M. An optimistic perspective on offline reinforcement learning. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; pp. 104–114. [Google Scholar]
- Kostrikov, I.; Nair, A.; Levine, S. Offline reinforcement learning with implicit q-learning. arXiv 2021, arXiv:2110.06169. [Google Scholar]
- Fujimoto, S.; Meger, D.; Precup, D. Off-policy deep reinforcement learning without exploration. In Proceedings of the International conference on machine learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 2052–2062. [Google Scholar]
- Ghasemipour, S.K.S.; Schuurmans, D.; Gu, S.S. Emaq: Expected-max q-learning operator for simple yet effective offline and online rl. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; pp. 3682–3691. [Google Scholar]
- Jaques, N.; Ghandeharioun, A.; Shen, J.H.; Ferguson, C.; Lapedriza, A.; Jones, N.; Gu, S.; Picard, R. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog. arXiv 2019, arXiv:1907.00456. [Google Scholar]
- Kumar, A.; Fu, J.; Soh, M.; Tucker, G.; Levine, S. Stabilizing off-policy q-learning via bootstrapping error reduction. In Advances in Neural Information Processing Systems 32, Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019; NeurIPS: La Jolla, CA, USA, 2019. [Google Scholar]
- Wu, Y.; Tucker, G.; Nachum, O. Behavior regularized offline reinforcement learning. arXiv 2019, arXiv:1911.11361. [Google Scholar]
- Siegel, N.Y.; Springenberg, J.T.; Berkenkamp, F.; Abdolmaleki, A.; Neunert, M.; Lampe, T.; Hafner, R.; Heess, N.; Riedmiller, M. Keep doing what worked: Behavioral modelling priors for offline reinforcement learning. arXiv 2020, arXiv:2002.08396. [Google Scholar]
- Guo, Y.; Feng, S.; Le Roux, N.; Chi, E.; Lee, H.; Chen, M. Batch reinforcement learning through continuation method. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 April 2020. [Google Scholar]
- Hwangbo, J.; Lee, J.; Hutter, M. Per-contact iteration method for solving contact dynamics. IEEE Robot. Autom. Lett. 2018, 3, 895–902. [Google Scholar] [CrossRef]
- Quan, Q. Introduction to Multicopter Design and Control; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Fahad Mon, B.; Wasfi, A.; Hayajneh, M.; Slim, A.; Abu Ali, N. Reinforcement Learning in Education: A Literature Review. Informatics 2023, 10, 74. [Google Scholar] [CrossRef]
- Sivamayil, K.; Rajasekar, E.; Aljafari, B.; Nikolovski, S.; Vairavasundaram, S.; Vairavasundaram, I. A Systematic Study on Reinforcement Learning Based Applications. Energies 2023, 16, 1512. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Pinosky, A.; Abraham, I.; Broad, A.; Argall, B.; Murphey, T.D. Hybrid control for combining model-based and model-free reinforcement learning. Int. J. Robot. Res. 2023, 42, 337–355. [Google Scholar] [CrossRef]
- Byeon, H. Advances in Value-based, Policy-based, and Deep Learning-based Reinforcement Learning. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 348–354. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep Reinforcement Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 5064–5078. [Google Scholar] [CrossRef]
- Yi, W.; Qu, R.; Jiao, L. Automated algorithm design using proximal policy optimisation with identified features. Expert Syst. Appl. 2023, 216, 119461. [Google Scholar] [CrossRef]
- Nguyen, H.N.; Lee, D. Hybrid force/motion control and internal dynamics of quadrotors for tool operation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 3458–3464. [Google Scholar]
- Nguyen, H.N.; Ha, C.; Lee, D. Mechanics, control and internal dynamics of quadrotor tool operation. Automatica 2015, 61, 289–301. [Google Scholar] [CrossRef]
- Tao, Y.; Yu, Y.; Feng, Y. AqauML: Distributed Deep Learning Framework Based on Tensorflow2. 2023. Available online: https://github.com/BIT-aerial-robotics/AquaML/tree/2.2.0 (accessed on 2 May 2023).
- Huang, S.; Dossa, R.F.J.; Raffin, A.; Kanervisto, A.; Wang, W. The 37 implementation details of proximal policy optimization. In Proceedings of the The ICLR Blog Track, Online, 25–29 April 2022. [Google Scholar]










{kind=link}
{kind=link}
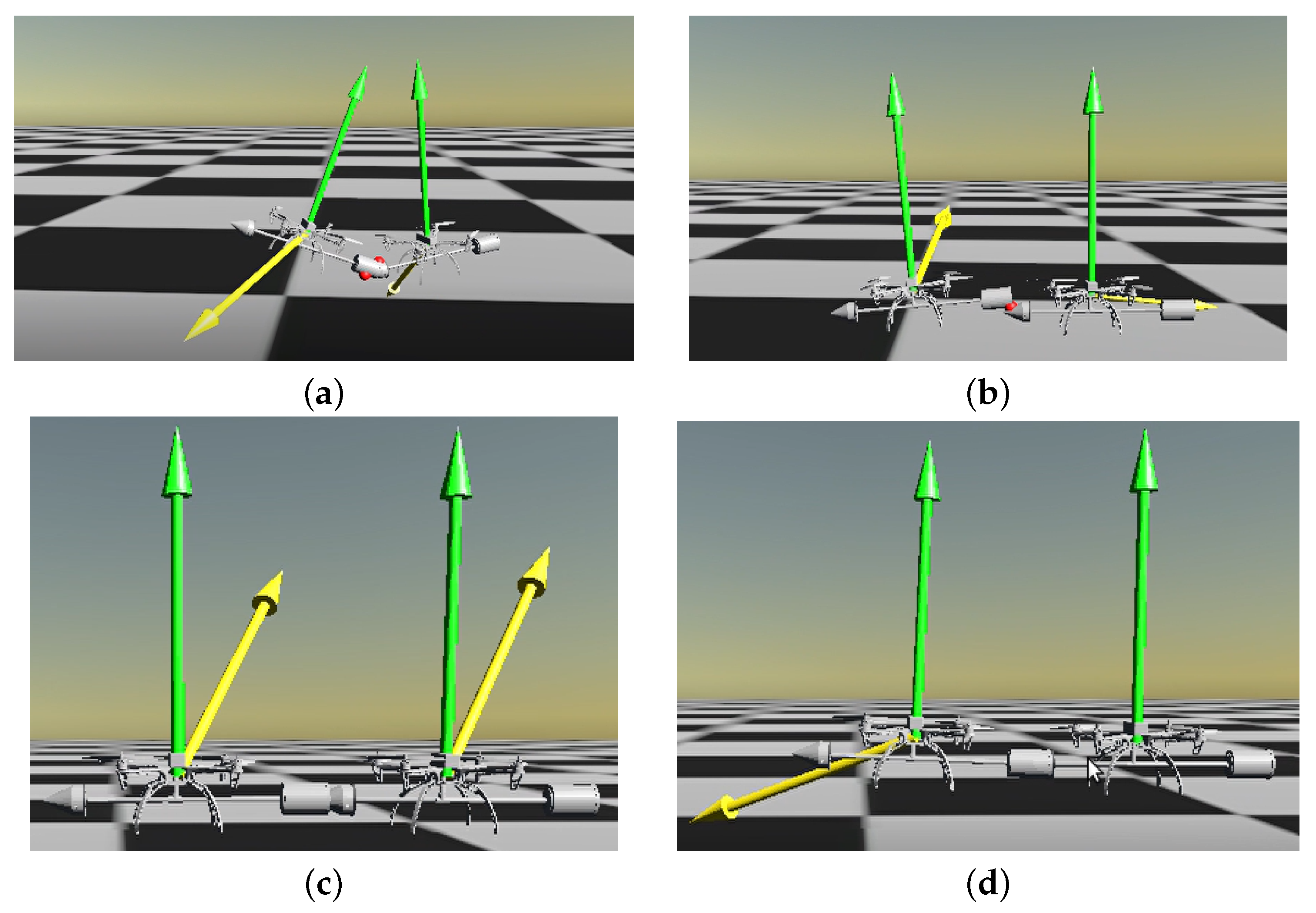{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
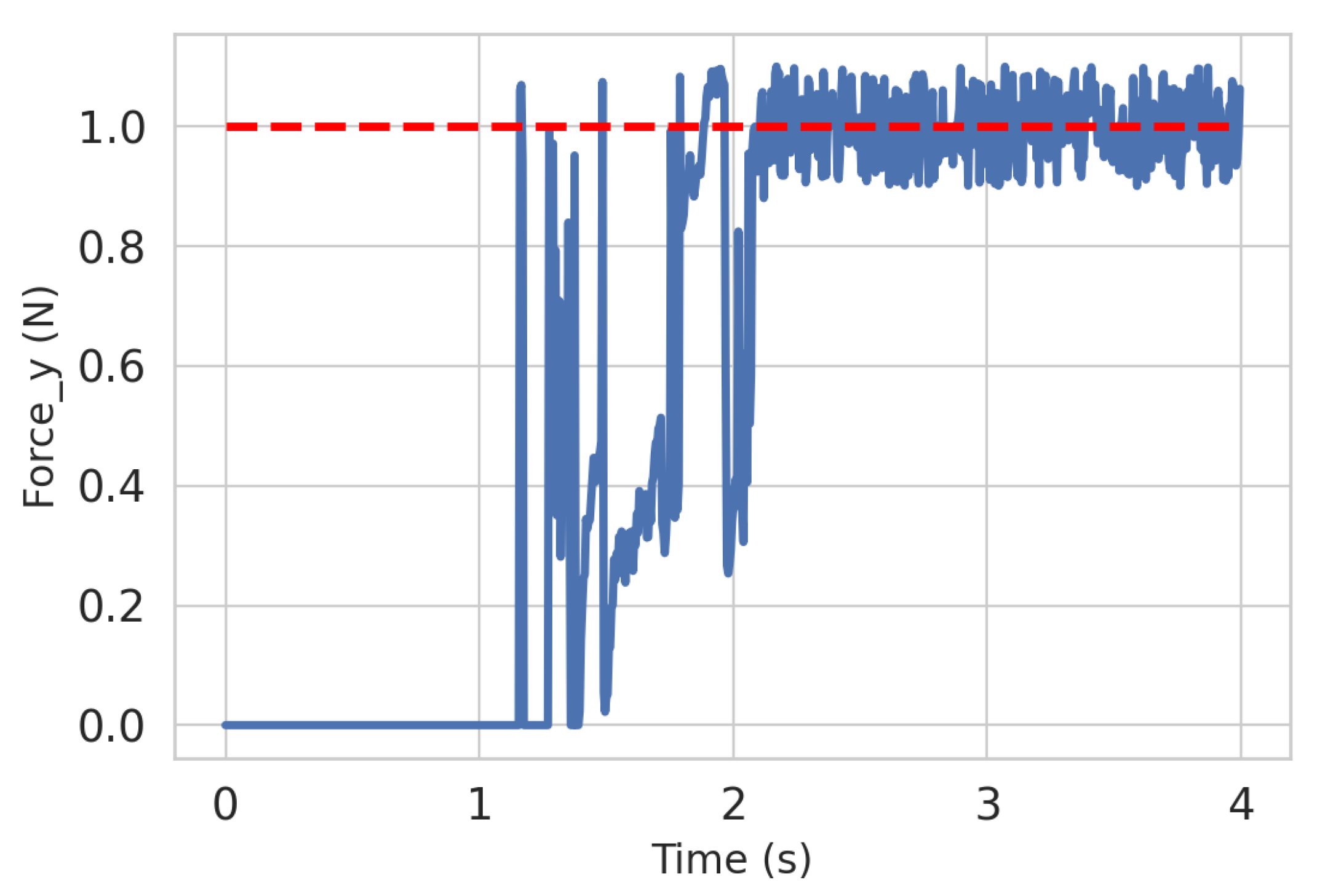{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| 0.1 | |
| 1.02 | |
| 1.0 | |
| 0.3 | |
| 2.0 | |
| 0.0 | |
| 0.02 |
| Parameter | Value |
|---|---|
| Batch size | 4096 |
| Target update rate | 0.005 |
| Policy noise | 0.2 |
| Policy noise clipping | (−0.5, 0.5) |
| Policy update frequency | 2 |
| Actor learning rate | 3 × 10−4 |
| 2.5 |
| Parameter | Value |
|---|---|
| 0.99 | |
| clip ratio | 0.05 |
| target KL | 0.05 |
| log std init value | −1.2 |
| 1.0 | |
| entropy coef | 0.005 |
| learning rate | 2 × 10−6 |
| Algorithm Type | Algorithm | Success Rate | Steps |
|---|---|---|---|
| Online | PPO | × | × |
| Online | AMP CL | × | × |
| Online | PPO CL | × | × |
| Offline | IQL | 60% | 990 |
| Offline | TD3BC | 65% | 980 |
| Offline-to-Online | TD3BC+PPO | 95% | 890 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Y.; Yang, T.; Yu, Y. Enhancing UAV Aerial Docking: A Hybrid Approach Combining Offline and Online Reinforcement Learning. Drones 2024, 8, 168. https://doi.org/10.3390/drones8050168
Feng Y, Yang T, Yu Y. Enhancing UAV Aerial Docking: A Hybrid Approach Combining Offline and Online Reinforcement Learning. Drones. 2024; 8(5):168. https://doi.org/10.3390/drones8050168
Chicago/Turabian StyleFeng, Yuting, Tao Yang, and Yushu Yu. 2024. "Enhancing UAV Aerial Docking: A Hybrid Approach Combining Offline and Online Reinforcement Learning" Drones 8, no. 5: 168. https://doi.org/10.3390/drones8050168
APA StyleFeng, Y., Yang, T., & Yu, Y. (2024). Enhancing UAV Aerial Docking: A Hybrid Approach Combining Offline and Online Reinforcement Learning. Drones, 8(5), 168. https://doi.org/10.3390/drones8050168