
Early Drought Detection in Maize Using UAV Images and YOLOv8+


Abstract
:1. Background
2. Introduction
2.1. Research Work by Relevant Scholars
2.2. Contribution of This Article
3. Experimental Data
3.1. Data Collection
3.2. Data Categories and Datasets
3.3. A800 Computing Server
4. YOLOv8 Network Model
4.1. YOLOv8 Model
4.2. Anchor Module without Anchor Boxes
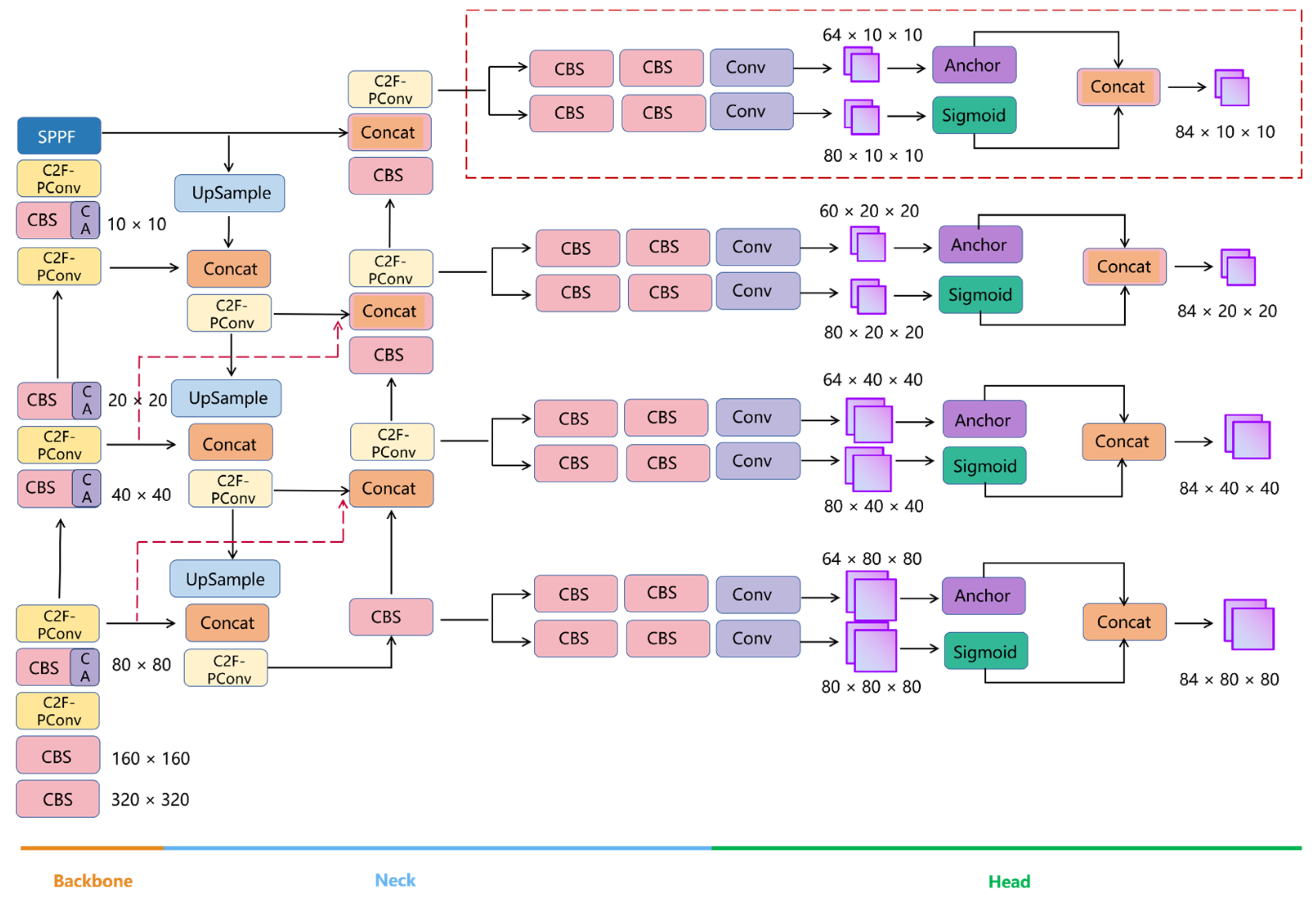
5. Yolov8+ Network Model
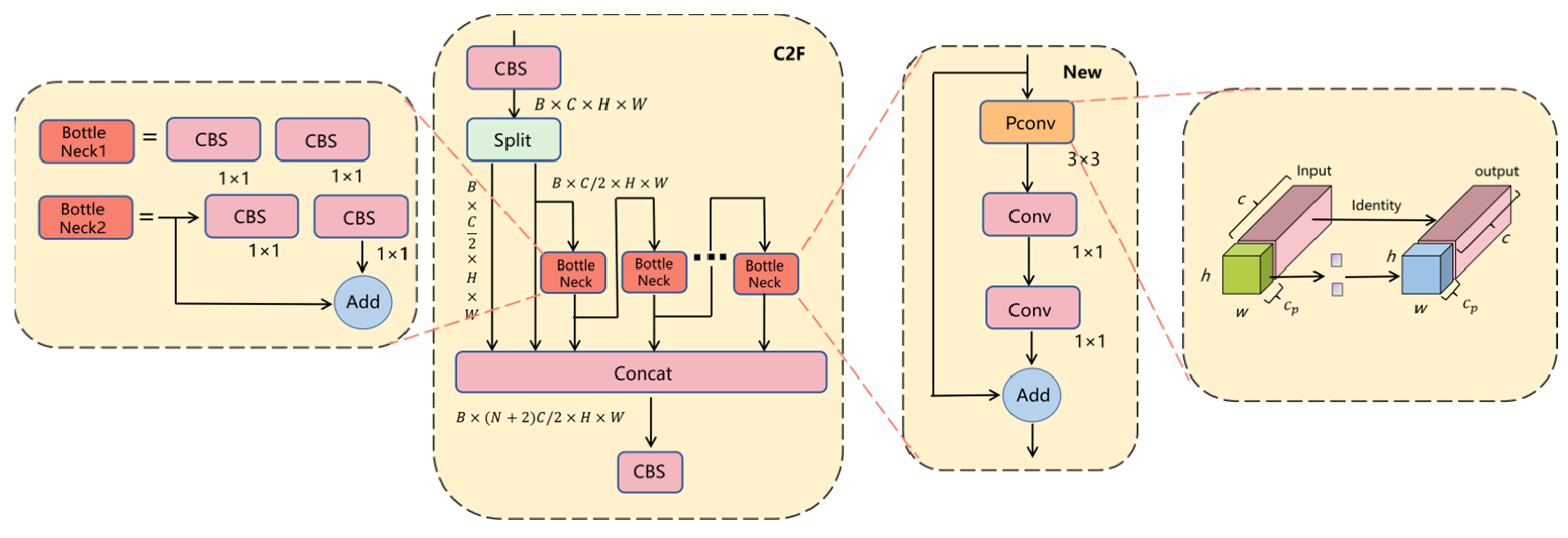
5.1. Lightweight C2F-Pconv Module
5.2. BiFPN Model Structure
5.3. Addition of Detection Boxes for Small Targets
5.4. Fusion Loss Function
6. Experimental Methods and Results
6.1. Network Training
6.2. Evaluation Metrics
6.3. Ablation Experiment
6.4. Comparison with Other Mainstream Methods
6.5. Specific Detection Performance Chart
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, E.; Liu, X.; Zhang, J.; Wang, Y.; Wang, C.; Wang, R.; Li, D. Assessing spatiotemporal variation of drought and its impact on maize yield in Northeast China. J. Hydrol. 2017, 553, 231–247. [Google Scholar] [CrossRef]
- Herrero-Huerta, M.; Gonzalez-Aguilera, D.; Yang, Y. Structural Component Phenotypic Traits from Individual Maize Skeletonization by UAS-Based Structure-from-Motion Photogrammetry. Drones 2023, 7, 108. [Google Scholar] [CrossRef]
- Liu, Y.; Subhash, C.; Yan, J.; Song, C.; Zhao, J.; Li, J. Maize leaf temperature responses to drought: Thermal imaging and quantitative trait loci (QTL) mapping. Environ. Exp. Bot. 2011, 71, 158–165. [Google Scholar] [CrossRef]
- Mertens, S.; Verbraeken, L.; Sprenger, H.; Demuynck, K.; Maleux, K.; Cannoot, B.; De Block, J.; Maere, S.; Nelissen1, H.; Bonaventure, G.; et al. Proximal hyperspectral imaging detects diurnal and drought-induced changes in maize physiology. Front. Plant Sci. 2021, 12, 640914. [Google Scholar] [CrossRef] [PubMed]
- Brewer, K.; Clulow, A.; Sibanda, M.; Gokool, S.; Odindi, J.; Mutanga, O.; Naiken, V.; Chimonyo, V.G.P.; Mabhaudhi, T. Estimation of maize foliar temperature and stomatal conductance as indicators of water stress based on optical and thermal imagery acquired using an unmanned aerial vehicle (UAV) platform. Drones 2022, 6, 169. [Google Scholar] [CrossRef]
- Pradawet, C.; Khongdee, N.; Pansak, W.; Spreer, W.; Hilger, T.; Cadisch, G. Thermal imaging for assessment of maize water stress and yield prediction under drought conditions. J. Agron. Crop Sci. 2023, 209, 56–70. [Google Scholar] [CrossRef]
- Praprotnik, E.; Vončina, A.; Žigon, P.; Knapič, M.; Susič, N.; Širca, S.; Vodnik, D.; Lenarčič, D.; Lapajne, J.; Žibrat, U.; et al. Early Detection of Wireworm (Coleoptera: Elateridae) Infestation and Drought Stress in Maize Using Hyperspectral Imaging. Agronomy 2023, 13, 178. [Google Scholar] [CrossRef]
- Jiang, B.; Wang, P.; Zhuang, S.; Li, M.; Li, Z.; Gong, Z. Detection of maize drought based on texture and morphological features. Comput. Electron. Agric. 2018, 151, 50–60. [Google Scholar] [CrossRef]
- Zhuang, S.; Wang, P.; Jiang, B.; Li, M.; Gong, Z. Early detection of water stress in maize based on digital images. Comput. Electron. Agric. 2017, 140, 461–468. [Google Scholar] [CrossRef]
- An, J.; Li, W.; Li, M.; Cui, S.; Yue, H. Identification and classification of maize drought stress using deep convolutional neural network. Symmetry 2019, 11, 256. [Google Scholar] [CrossRef]
- Goyal, P.; Sharda, R.; Saini, M.; Siag, M. A deep learning approach for early detection of drought stress in maize using proximal scale digital images. Neural Comput. Appl. 2024, 36, 1899–1913. [Google Scholar] [CrossRef]
- Fu, X.; Wei, G.; Yuan, X.; Liang, Y.; Bo, Y. Efficient YOLOv7-Drone: An Enhanced Object Detection Approach for Drone Aerial Imagery. Drones 2023, 7, 616. [Google Scholar] [CrossRef]
- Pu, H.; Chen, X.; Yang, Y.; Tang, R.; Luo, J.; Wang, Y.; Mu, J. Tassel-YOLO: A new high-precision and real-time method for maize tassel detection and counting based on UAV aerial images. Drones 2023, 7, 492. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, H.; Liu, Y.; Zhang, H.; Zheng, D. Tree-Level Chinese Fir Detection Using UAV RGB Imagery and YOLO-DCAM. Remote Sens. 2024, 16, 335. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, K.; Hu, X.; Lu, Y. Crop type recognition of VGI road-side images via hierarchy structure based on semantic segmentation model Deeplabv3+. Displays 2024, 81, 102574. [Google Scholar] [CrossRef]
- Zhao, H.; Wan, F.; Lei, G.; Xiong, Y.; Xu, L.; Xu, C.; Zhou, W. LSD-YOLOv5: A Steel Strip Surface Defect Detection Algorithm Based on Lightweight Network and Enhanced Feature Fusion Mode. Sensors 2023, 23, 6558. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Zhuo, Q.; Fu, J.; Liu, A. Research on evaluation method of underwater image quality and performance of underwater structure defect detection model. Eng. Struct. 2024, 306, 117797. [Google Scholar] [CrossRef]
- Tahir, N.U.A.; Long, Z.; Zhang, Z.; Asim, M.; ELAffendi, M. PVswin-YOLOv8s: UAV-Based Pedestrian and Vehicle Detection for Traffic Management in Smart Cities Using Improved YOLOv8. Drones 2024, 8, 84. [Google Scholar] [CrossRef]
- Wang, X.; Han, J.; Xiang, H.; Wang, B.; Wang, G.; Shi, H.; Chen, L.; Wang, Q. A Lightweight Traffic Lights Detection and Recognition Method for Mobile Platform. Drones 2023, 7, 293. [Google Scholar] [CrossRef]
- Singhania, D.; Rahaman, R.; Yao, A. C2F-TCN: A framework for semi-and fully-supervised temporal action segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11484–11501. [Google Scholar] [CrossRef]
- Jeng, K.-Y.; Liu, Y.-C.; Liu, Z.Y.; Wang, J.-W.; Chang, Y.-L.; Su, H.-T.; Hsu, W. Gdn: A coarse-to-fine (c2f) representation for end-to-end 6-dof grasp detection. In Proceedings of the 4th Conference on Robot Learning (PMLR), Cambridge MA, USA, 16–18 November 2021. [Google Scholar]
- Yu, X.; Xu, L.; Li, J.; Ji, X. MagConv: Mask-guided convolution for image inpainting. IEEE Trans. Image Process. 2023, 32, 4716–4727. [Google Scholar] [CrossRef] [PubMed]
- Zeng, W.; Li, H.; Hu, G.; Liang, D. Lightweight dense-scale network (LDSNet) for corn leaf disease identification. Comput. Electron. Agric. 2022, 197, 106943. [Google Scholar] [CrossRef]
- Wang, W.; Han, B.; Guo, Y.; Luo, X.; Yuan, M. Fault-tolerant platoon control of autonomous vehicles based on event-triggered control strategy. IEEE Access 2020, 8, 25122–25134. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhao, L.; Zhu, M. MS-YOLOv7: YOLOv7 based on multi-scale for object detection on UAV aerial photography. Drones 2023, 7, 188. [Google Scholar] [CrossRef]
- Raturi, A.; Jennifer, J.; Thompson, V.A.; Chase, C.A.; Davis, B.W.; Myers, R.; Poncet, A.; Ramos-Giraldo, P.; Reberg-Horton, C.; Rejesus, R.; et al. Cultivating trust in technology-mediated sustainable agricultural research. Agron. J. 2022, 114, 2669–2680. [Google Scholar] [CrossRef]
- Seth, A.; James, A.; Kuantama, E.; Mukhopadhyay, S.; Han, R. Drone High-Rise Aerial Delivery with Vertical Grid Screening. Drones 2023, 7, 300. [Google Scholar] [CrossRef]
- Chen, J.; Mai, H.S.; Luo, L.; Chen, X.; Wu, K. Effective feature fusion network in BIFPN for small object detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Angelis, G.-F.; Chorozoglou, D.; Papadopoulos, S.; Drosou, A.; Giakoumis, D.; Tzovaras, D. AI-enabled Underground Water Pipe non-destructive Inspection. Multimed. Tools Appl. 2023, 83, 18309–18332. [Google Scholar] [CrossRef]
- Saeed, Z.; Yousaf, M.H.; Ahmed, R.; Velastin, S.A.; Viriri, S. On-board small-scale object detection for unmanned aerial vehicles (UAVs). Drones 2023, 7, 310. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Talaat, F.M.; Hanaa, Z. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Chang, Y.; Li, D.; Gao, Y.; Su, Y.; Jia, X. An improved YOLO model for UAV fuzzy small target image detection. Appl. Sci. 2023, 13, 5409. [Google Scholar] [CrossRef]
- Wang, J.; Gauri, J. Cooperative SGD: A unified framework for the design and analysis of local-update SGD algorithms. J. Mach. Learn. Res. 2021, 22, 1–50. [Google Scholar]
- Boukabou, I.; Kaabouch, N. Electric and magnetic fields analysis of the safety distance for UAV inspection around extra-high voltage transmission lines. Drones 2024, 8, 47. [Google Scholar] [CrossRef]
- Shi, Y.; Li, X.; Wang, G.; Jin, X. Research on the Recognition and Classification of Recyclable Garbage in a Complex Environment Based on Improved YOLOv8s. In Proceedings of the 2023 5th International Conference on Control and Robotics (ICCR), Tokyo, Japan, 23–25 November 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Liu, Y.; Huang, X.; Liu, D. Weather-Domain Transfer-Based Attention YOLO for Multi-Domain Insulator Defect Detection and Classification in UAV Images. Entropy 2024, 26, 136. [Google Scholar] [CrossRef]
- Wei, B.; Barczyk, M. Experimental Evaluation of Computer Vision and Machine Learning-Based UAV Detection and Ranging. Drones 2021, 5, 37. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | C2F-Pconv | CA Model | BiFPN Fusion | Loss Function | Params/MB | mAP@50/% | mAP@50:95/% | Detection Time/ms |
|---|---|---|---|---|---|---|---|---|
| Yolov8 | — | — | — | — | 20.13 | 85.26 | 67.84 | 34.63 |
| (A) | √ | — | — | — | 18.62 | 85.02 | 67.36 | 30.28 |
| (B) | — | √ | — | — | 19.21 | 86.46 | 68.69 | 31.18 |
| (C) | — | — | √ | — | 18.93 | 87.91 | 68.53 | 30.53 |
| (D) | — | — | — | √ | 19.30 | 86.7 | 66.92 | 27.53 |
| (E) | √ | √ | — | — | 18.38 | 86.86 | 68.20 | 27.82 |
| (F) | √ | — | √ | — | 18.53 | 87.21 | 68.51 | 26.94 |
| (G) | √ | — | — | √ | 17.26 | 87.13 | 68.26 | 26.17 |
| (H) | — | √ | √ | — | 17.83 | 87.59 | 69.13 | 26.45 |
| (I) | — | √ | — | √ | 16.58 | 87.27 | 68.90 | 26.15 |
| (J) | — | — | √ | √ | 16.64 | 87.53 | 68.43 | 25.93 |
| (K) | √ | √ | √ | — | 15.83 | 88.21 | 69.32 | 25.76 |
| (L) | √ | — | √ | √ | 15.47 | 88.62 | 69.64 | 25.49 |
| (M) | — | √ | √ | √ | 14.42 | 88.79 | 70.84 | 25.08 |
| (N) | √ | √ | √ | √ | 13.76 | 89.16 | 71.14 | 24.63 |
| Drought | Semi-Drought | Optimal | |
|---|---|---|---|
| The first line | 4 | 50 | 45 |
| The second line | 4 | 37 | 77 |
| The third line | 4 | 51 | 58 |
| The fourth line | 0 | 19 | 88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, S.; Nie, Z.; Li, G.; Zhu, W. Early Drought Detection in Maize Using UAV Images and YOLOv8+. Drones 2024, 8, 170. https://doi.org/10.3390/drones8050170
Niu S, Nie Z, Li G, Zhu W. Early Drought Detection in Maize Using UAV Images and YOLOv8+. Drones. 2024; 8(5):170. https://doi.org/10.3390/drones8050170
Chicago/Turabian StyleNiu, Shanwei, Zhigang Nie, Guang Li, and Wenyu Zhu. 2024. "Early Drought Detection in Maize Using UAV Images and YOLOv8+" Drones 8, no. 5: 170. https://doi.org/10.3390/drones8050170
APA StyleNiu, S., Nie, Z., Li, G., & Zhu, W. (2024). Early Drought Detection in Maize Using UAV Images and YOLOv8+. Drones, 8(5), 170. https://doi.org/10.3390/drones8050170