1. Introduction
The lottery ticket hypothesis has shifted the field of pruning networks and allows us to create a standard for discovering smaller networks within larger neural network. It states that given a dense neural network that is randomly initialized, there exists a subnetwork that can match the performance of the original using at most the same number of training iterations. The weights that allow us to find such a subnetwork are ideally lottery ticket weights, which are the key weights to fit the dataset properly. The hypothesis tells us a smaller subnetwork should be possible, but often it requires us to train the original network in order to select potential lottery weights. To validate subnetworks, the subnetwork must be reinitialized to the original weights (prior to training) and retrained, thus making a redundant use of training. Moreover, the dataset itself is not optimized in any way during this process. Should a subnetwork require the entire dataset?
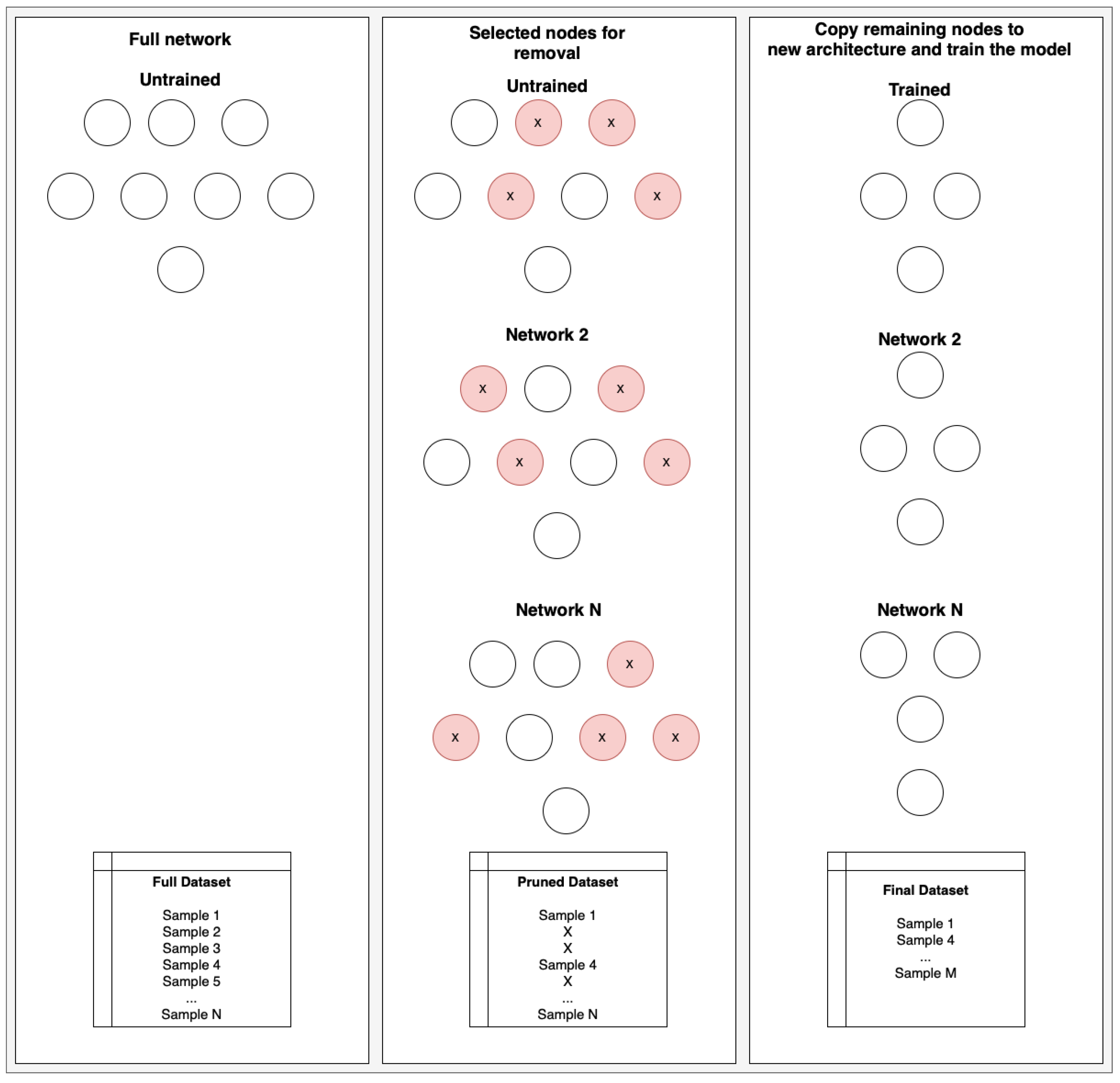
In this paper we aim to reverse how we discovery lottery tickets. We first propose an approach to search for lottery tickets without training the original model. This removes the redundancy of first training the original network, then retraining the subnetwork. Second, we propose an expansion to the lottery ticket hypothesis by applying it to the training set of the model. Given a training dataset for a network, we claim there exists a subset of samples to train the same network (or subnetwork) with equivalent performance to that achieved from the original dataset. This would allow researchers to explore the idea of applying approaches learned from lottery ticket algorithms to dataset reduction for higher quality datasets.
We apply some of these ideas to tabular neural networks on a large variety of datasets. The tabular neural network was shown to be a leading model for tabular datasets in our recent paper [
1]. It has been shown to be leading in many other tabular problems [
2,
3,
4,
5]. In particular a highway study mentions “Fast.ai neural network model for tabular data: Fast.ai model has demonstrated the state-of-art performance in the tabular data modeling in this study.” [
5]. And is often used to achieve state-of-the-art performance, “the FastAI tabular model was selected because it has thus far obtained the best classification result on the [Anatomical Therapeutic Chemical (ATC)] benchmark” [
3]. The network design allows for categorical embedding and continuous features to be processed through a series of linear layers and optional batch normalization.
The contributions of our paper is as follows: (1) the lottery ticket search no longer limited by the size of the original model; (2) we remove the need to train the large original network (which is usually trained and tested multiple times); (3) we show that large parts of the training dataset, up to 95% reduction, is not required to find lottery tickets; (4) we show these improvements are not tradeoffs, but allow the algorithm to perform equivalently or better than prior methods at searching for lottery tickets; (5) we present an extention of the lottery ticket hypothesis to include the ability to also prune the dataset using a similar approach.
Our paper is organized as follows. First, we present previous works on the lottery ticket hypotheses, dataset reduction, tabular models, and the use of the genetic algorithm for pruning techniques. Second, we describe the datasets we use and the approach we take to prune our models using a genetic algorithm and reduce training samples. Third, we present our experiments and results of our pruning strategy. Finally, the paper is concluded including future work.
2. Previous Works
The lottery ticket hypothesis [
6] has been tested on a variety of network architectures. All use a similar goal to prune a network by a large margin, usually over 80%, and have a model perform similarly or even better than the original network. For example, there have been many attempts at pruning convolutional neural networks (CNNs) which include the original paper on lottery tickets itself [
6] (80–90% prune rate), a generalized approach [
7] to prune across many vision datasets (such as MNIST, SVHN, CIFAR-10/100, ImageNet, and Places365), and an object detection variant [
8] pruned up to 80%.
There have been many tests of the lottery ticket hypotheses applied to large pre-trained networks. In this case we have large pre-trained models which no longer have the original weights, so the test of the lottery ticket hypotheses is be performed on downstream tasks [
9]. In this case they did not structurally prune the model but applied masks leading to a 40–90% sparsity depending on the downstream task. Other papers, such as [
10], have proposed to structurally prune transformers using question-answering tasks and achieving double inference speeds with a minor loss of accuracy. S. Prasanna, A. Rogers, and A. Rumshisky [
11] made an interesting study on good and bad subnetworks found based on the down-steam task.
We use a mix of regression and classification tasks for evaluation. Many works focus on these types of problems, for example some different areas of focus are sentiment analysis [
12], malware detection [
13], ensemble of models focusing on a task [
14], and camera messaging systems [
15,
16]. Our work aims at tackling regression and classification problems in a generic set of tasks within a tabular context. Generally tabular data is processed by models like random forest (RF), k-nearest neighbors (KNN), gradient boosting (GB), etc. There are high performance deep neural networks that have been shown to perform well on tabular data such as timeseries TabBERT [
17], and TabTransformer [
18], both based on the natural language processing transformer model using attention [
19]. We chose the FastAI network for its ability to perform given its small size in line with our goal to propose a method to produce small networks in a stable manner without training the original model, adaptable to many different datasets.
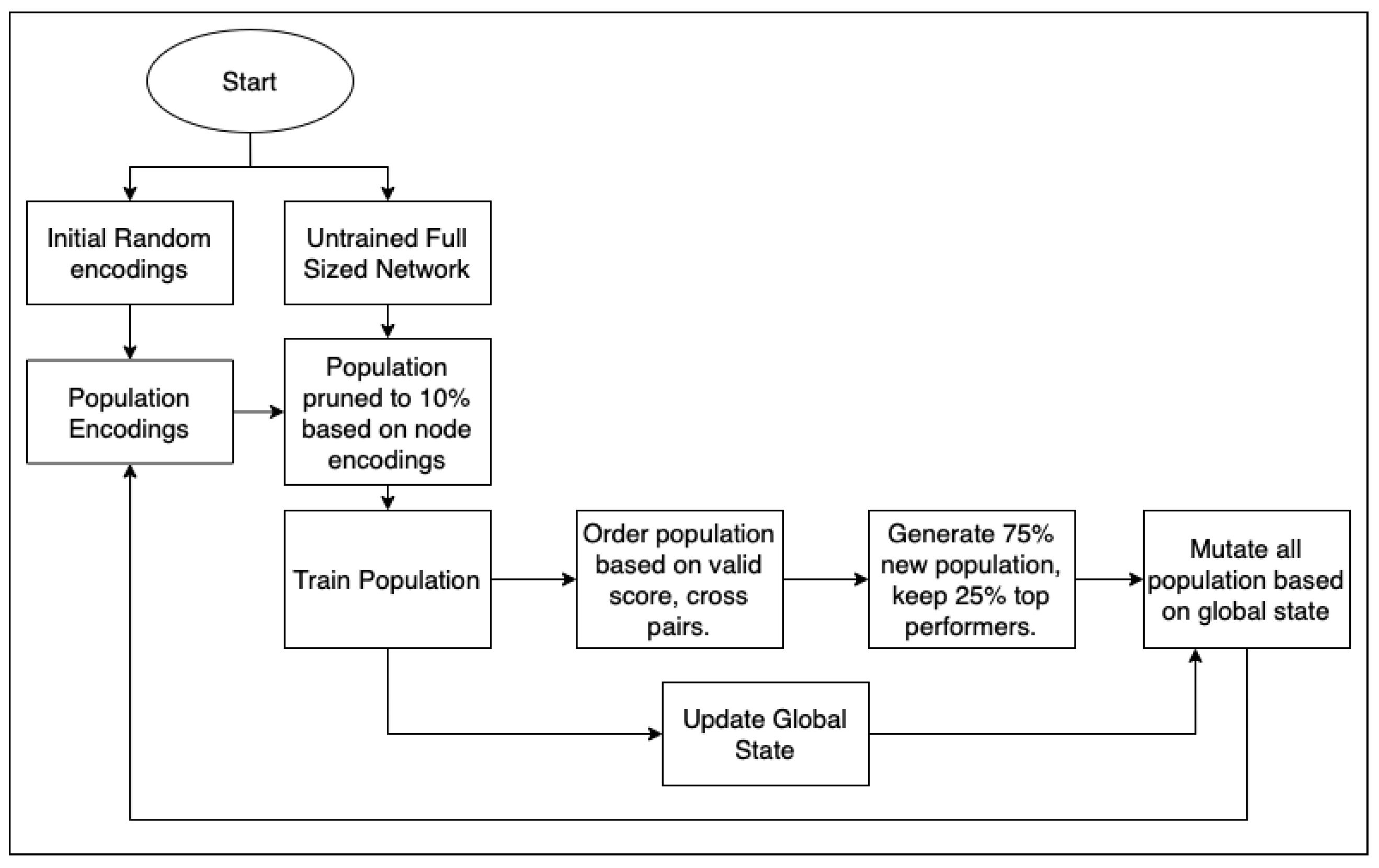
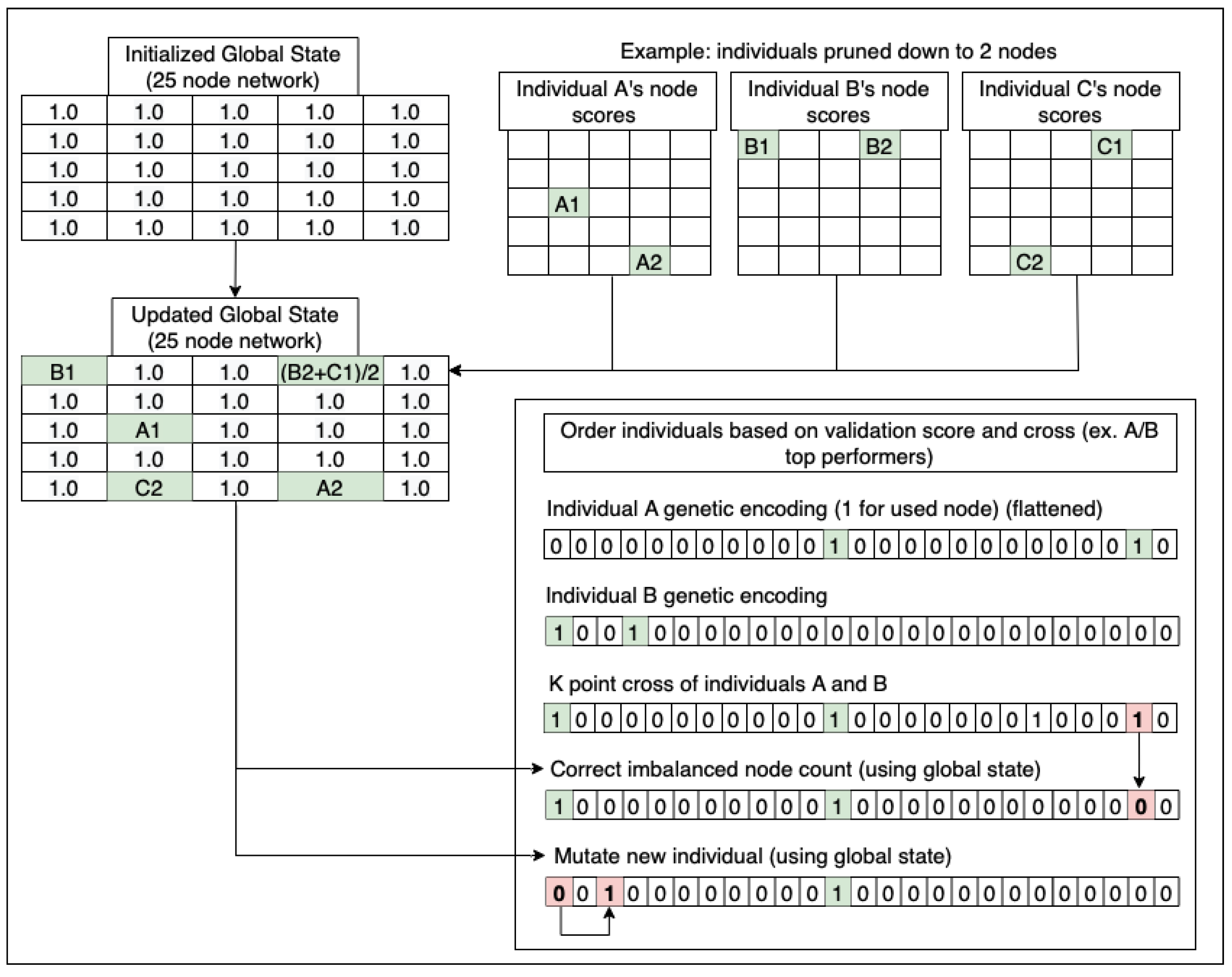
Our approach uses a genetic algorithm in order to produce small networks by pruning them through generations of subnetwork tests by fixing the size and optimizing for best accuracy, and in particular our approach aims to avoid training the original network altogether. Genetic algorithms have been used for pruning in other works. For example Z. Wang et al. [
20] use a genetic algorithm to prune channels of a CNN by optimizing for size and minimizing accuracy loss at the same time. The authors directly mention “after pruning, the structure of the new network and the parameters of the reserved channels must be retrained” [
20]. D. Mantzaris et al. [
21] use a genetic algorithm as a feature selection approach which in turn reduces input nodes but is not directly testing the idea of lottery ticket pruning which would fix weights and search for subnetworks. C. Yang et al. [
22] also prune a CNN with a two step process. “First, we prune the network by taking the advantages of swarm intelligence. Next, we retrain the elite network and reinitialize the population by the trained elite.” [
22]. Note that they must “retrain the elite genome so that the remained weights can compensate for the loss of accuracy” [
22]. P.J. Hancock [
23] from 1992 even tested the idea of pruning a network using a genetic algorithm. The method first trains the original network, then uses the genetic algorithm to prune it, “then prunes connections prior to retraining of the remainder” [
23]. We aim to eliminate the training process of the original network which also eliminates the redundancy of retraining the subnetwork. Thus instead of the typical approach, 1. train original network, 2. select sub networks, 3. retrain subnetworks independently, we instead skip step 1 and simply train instead of “retrain” the subnetwork.
There are a few other things we wanted to highlight. First the original lottery paper [
6] mentions that normal pruning often leads to less accurate models, but applications of pruning in search of lottery tickets tends to resolve this issue. Second, in the generalized work on pruning CNNs [
7] they mention larger datasets tend to produce better lottery tickets. Finally, in our previous work [
1] we found that larger networks tend to hold more lottery tickets which made it easier to find a set of tickets when pruning. This leads us to the idea that the approach or concept of lottery tickets can be applied to datasets, like finding lottery samples. For instance, in comparison to the first point, removal of training data generally leads to less accurate models which is well known so ideally finding lottery samples could relieve this issue. In the second point larger dataset tends to produce better lottery tickets which can suggest that there was a higher chance the dataset contains key lottery samples to find better lottery tickets, much like how a larger network may contain more lottery tickets just by chance. The idea here is that samples are tied to lottery tickets, thus the set of samples that belong to a subnetwork of lottery tickets would be lottery samples. Thus we propose the idea that a subset of samples, or lottery samples, can be found and used to find lottery tickets and train a subnetwork with similar accuracy to the original larger network on the full dataset.
Much like pruning prior to the lottery ticket hypotheses, the concept of training reduction has been tested in many papers. For example, S. Ougiaroglou et al. [
24] used dataset reduction in order reduce the amount of space and inference complexity KNN requires from holding the dataset for nearest neighbor comparisons. In this case it is a model specific example of how a few key samples can result in a similar model. However, KNN and similar distance based algorithms can be very inefficient and does not indicate if this reduced training dataset can be useful to other models. F.U. Nuha et al. [
25] applies dataset reduction to generative adversarial networks (GANs) to show that a dataset with 50k samples is ideal and can outperform a larger noisy dataset. J. Chandrasekaran et al. [
26] uses random sampling to reduce the dataset with the goal of tuning the hyperparameters of a model faster. They show that the reduction of the dataset down to 800 samples has the same coverage as the original allowing them to use the reduced dataset for model testing.
What we propose is that dataset reduction can benefit from reshaping the problem as lottery samples through a combination of sample selection and lottery ticket pruning. The pruning process would allow the network to properly fit a given dataset reduction without overfitting and allow for faster training times without complex selection algorithms. For example, we show a random subsampling is enough for us to achieve equivalent models when we use it in conjunction with lottery ticket pruning (as the tickets found fit the subset of data), allowing us to potentially reduce training datasets down to 5% their original size, some at just 13 samples. This would also open dataset reduction to techniques found by lottery ticket pruning that can be applied to sample selection problems (such as the genetic algorithm we propose for lottery ticket selection) to stabilize the reduction and improve coverage.
4. Experimentations, Results, and Discussion
In our previous paper we had already performed parameter searches regarding model training such as number of neurons, layers, learning rate, etc. We built on these parameters and continued to test our approach for the lottery pruning parameters specifically. Many of the parameters were tested in a grid-style approach. For example, the retained population parameter was searched in a range of 0–25 which was limited to 25 since we wanted a diverse population. The number of generations were set higher than the optimal value since we can fully exaust the performance of the genetic algorithm without loss of accuracy due to the retained population. From there we analysed the generational validation performance to determine the best stopping point in individual datasets and across all datasets. The number of subnetworks were limited by our hardware which was a 2-CPU machine, mainly to show that we can achieve great performance on low hardware requirements. Our previous paper, previous works, and in our own tests have found 80–95% prune rates to work well, so we have tested in this range. We performed a grid search on the dataset reduction testing 0%, 25%, 50%, 75%, 90%, and 95% dataset reduction. Finally we test a wide variety of pruning metrics which measure the quality of the nodes pruned.
After parameter searches for the genetic algorithm, we found 25% retained population at each generation to be ideal. We chose a fixed 40 generations for all tests, but early stopping can be applied if validation performance slows or does not improve. We used 30 subnetworks per generation for large datasets, and 60 for small datasets. Population size was chosen to optimize search times on two CPUs, although with more hardware performance a higher search area can be used with more networks. We found across all datasets about 90% node reduction was optimal, so we fixed this prune rate for all our tests. We used dataset reduction as a variable search between 25–95%. The node selection measure was tested using many different norms, weight metrics, and training metrics as described in our methodology.
Our approach for lottery ticket pruning and sample selection is tested across many trials. We present results categorized by the prune method, each tested across many same reductions. The first method uses the best performing norm in our tests, L0, to measure the quality of nodes and is used across all datasets. The next test shows that a combination of norms and metrics (L0, L1, Linf, and random noise) can improve the results of our lottery ticket search further. Finally, we show that focusing on selecting the proper norm and metrics for individual datasets can lead to even greater performance. We also push the approach to its limit and describe some results of lottery ticket pruning with extreme dataset reduction.
For the first test,
Table 2 highlights our best scores using the norm L0 as a single measure across all datasets. In general, it was shown to find better performing networks on 5 of 8 datasets up to 30%+ improvement. We note a loss of accuracy by 1.2% in Chocolate, 3.1% in Poker and 6.1% in Wine. In particular, it is not a surprise that the Wine dataset has poor performance since it has been shown to be resistant to lottery ticket strategies in our tests from our previous paper [
1] We could not find a weight reduction of any size to improve its performance.
For the second test,
Table 3 highlights our best scores using multiple norms and measures across all datasets. We simply tried random combinations of the individual measures used in an attempt to find a better pruned subnetwork. In this case we found the combination of L0, L1, Linf, and some random noise allowed the genetic algorithm to find roughly equivalent subnetworks in all but the Wine dataset, however the Wine dataset compared to L0 selection was improved marginally as well. If we think logically about the score combination used, the L1 norm is the sum of all weights, L0 is the number of non-zero weights, and Linf is the largest element. Thus, the score of their combination is looking for nodes with dense information in an attempt to reduce empty space with zero-weight counting and small-weight sums. This is likely why L0 outperformed as an individual score as it simply looks for the densest nodes of the network, but adding weight sums with L1 can help differentiate ties when density is maxed out.
The previous two tables presented results where the same measures were used on all datasets, however optimizing each dataset individually can improve results further. For the third test,
Table 4 presents the best measure found for each dataset individually. The Wine dataset had a loss of accuracy of 1.6% which is only marginally worse than original. We therefore argue in every dataset we found a nearly equivalent subnetwork using a subset of the training data.
We include a graph of the validation improvement over the 40 generations for the GA algorithms of
Table 4 in
Figure 4. The improvement is in percentage (shown as a log chart for visibility) compared to the first generation, so all datasets start at 0% improvement and we show how the algorithm progresses over each generation. The chart shows in some cases, such as Poker, Wine and Alcohol, the full 40 generations continue to improve validation scores. For the other datasets, we find that the improvement flattens early on suggesting an early stop can be implemented for some datasets. In many datasets we could stop at generation 15, and in some even at 7 generations. Across all datasets, after 25 generations there is little performance gain, but still improvements. This would mean an early stop mechanism could be implemented to stop the search process early on and improve search times by an additional 35–80%.
We wanted to highlight some extreme cases of sample reduction on a few tests. For our large datasets, the Susy dataset had a reduction of training data by 90% (from 4M training samples to 400k) while improving F1 by 0.35%. For our smaller datasets, the Chocolate dataset was able to be reduced by 95% (from 1149 training samples to just 57 samples) while improving RMSE by 4.94%. The Alcohol dataset was reduced to 190 samples and still outperformed original by 6.71%. The Titanic dataset used 347 samples to outperform original by 5.59%. If the goal were simply to reduce training data and maintain at most equivalent performance, many of these datasets could be reduced even further with a small drop in accuracy. For example, Susy with a 95% reduction can still achieve a loss of accuracy of only 0.10% (using the same measure), while samples are reduced to 200k. In an extreme case, Alcohol had a loss of only 1.76% at 95% reduction, which corresponds to only 13 training samples. We include some network training and inference time results in
Table 5. Note that inference time can be subject to CPU processing noise due to the small nature of the datasets, so we included in bold the result from the larger datasets which show improved inference.
In addition to our comparison to original (which has no dataset reduction and no weight reduction), the results in each table are compared to the original network trained with dataset reduction (equivalently reduced train dataset to the respective GA result), and random pruning (equivalent 90% prune rate) tested both with and without dataset reduction. For original trained on dataset reduction, we found it mostly made performance significantly worse, and in some cases untrainable if the reduction was too high. This is expected since generally reducing training data for neural networks tends to lead to worse performance and a reduced ability to generalize. We also found that random pruning (on the full dataset) is not enough to find lottery ticket weights and that our GA algorithm generally improves over random pruning. And finally, combining the two using random pruning and dataset reduction made performance even worse, likely compounding the overall negative effects of both. Thus, our results suggest that in order to use dataset reduction, or in other words apply the idea of lottery samples, the network must also be pruned to its lottery weights, meaning the two approaches to find lottery samples and lottery weights must work together to find an optimized subnetwork. We believe this needs to be the case because the lottery ticket weights allow the network to learn on the reduced dataset with increased generalizability allowing us to avoid overfitting the networks. The lottery weights are directly tied to the lottery samples which would imply a different selection of training samples would be tied to a different subset of optimal lottery weights.
Finally, we compare with the current leading approach on tabular datasets [
1] for tabular datasets in
Table 6. The first two columns are from the previous work using the best of iterative pruning or oneshot pruning algorithm. The algorithms prune starting from a model as large as [1600, 800] neurons in size (size of each linear tabular layer). The standard iterative approach (approach 1) prunes by 50% at each step until it reaches a final size of [1, 1] and use the best performing size reduction. The adaptive iterative approach (approach 2) first looks for an optimal original network size (which can vary weights), then prunes iteratively on this better network. The oneshot approach will prune directly to a size of [1, 1] which has only succeeded in the case of Alcohol. The second column is our GA working with a fixed prune rate of 90%. In this case we start with a model of size [200, 100] and prune down to 30 neurons total. The comparison shown is the improvement over the original starting network of the respective model that was pruned, so this score is based on the starting network used.
We do not compare best accuracy in this case because this depends on the original model (which can change with varying sizes, better initialization of lottery weights, and/or training strategy) and the goal of the paper is to create an algorithm to improve the search method to find lottery tickets. In some datasets for the previous approach, the best model could only be found with hundreds of neurons while we can still achieve similar improvements on small networks. We show that our approach generally finds lottery tickets and improves over the original starting network in most datasets, and show the benefit of a fixed prune rate to achieve a fixed final size of the network. We also want to highlight that our GA approach never trains the original network while still being able to compete with and outperform the current leading approach that requires training and retraining of the subnetwork several times over on an iterative scheme. In addition, we only use a fraction of the training dataset in the GA approach.
5. Conclusions and Future Work
In conclusion, we designed a genetic algorithm capable of searching for lottery tickets using a fraction of the training dataset without ever training the original network. The algorithm can target a fixed prune rate and search for lottery tickets by training networks a fraction of the size of the original network. We were able to find networks 90% smaller than original while improving up to 30% in accuracy in some cases. We demonstrated that the search algorithm does not require all data and in some cases we were able to search for lottery tickets with as little as 5% of the training data. For example, the Alcohol dataset can achieve nearly equivalent performance to original with a 95% training reduction (using a total of 13 training samples). We also showed this can be applied to a dataset of 4M samples, reducing it to just 200k samples and having equivalent performance (−0.10%). We compared with our previous work [
1] and found in general we were able to find a higher quality of lottery weights with the ability to fix the prune rate. All results presented were compared to random pruning and dataset reduction to show the improvement of each component of our algorithm. We found our approach improves over random pruning and showed adding dataset reduction to random pruning in addition to just training the original network has worse effects on training overall (sometimes untrainable). This leads to our conclusion that we can find lottery samples in the dataset if we apply it in conjunction to associated lottery tickets in order to train a smaller network with a fraction of the data.
Current limitations of our approach are the selection of lottery samples. Currently we simply randomly reduce the training data by a fraction (keeping the same reduced dataset across all tests) which is not an optimized search process. This means we are searching for lottery tickets to match the already reduced dataset, thus optimizing through lottery tickets rather than improving the training dataset directly. To improve this work, we can apply lottery ticket search algorithms (such as our GA approach) to the sample reduction process in order to select lottery samples while applying lottery pruning techniques (on the weights) to fit the dataset properly. This would also allow for the variable dataset size reduction to become fixed like we have shown with our GA prune rate. Other limitations include the ability to search efficiently since we are limited by the number of smaller models we can search, however this is also a limitation of prior approaches which also need to test larger models. While the approach is not limited by parameters of the original model, in order to search the whole space the approach requires many smaller models to cover all parameters, however the goal is to find an equivalent model rather than search the whole space.
Future work will focus on improving the search mechanism for both lottery ticket search and sample selection. We will also focus on applying this approach to much larger models in the language model space which will allow us to test the approach on relatively extremely large models for lottery ticket search while using very large dataset for sample selection.
In summary, we proposed an extension to the lottery ticket hypothesis to include lottery samples and applied it to our proposed genetic algorithm for improved lottery ticket search. The reduction of samples improves search time with the potential to also allow for a larger population and improve lottery ticket search quality in turn, or simply find a smaller network faster. In our previous work [
1] we asked if it were possible to prune a network without ever training it to begin with, and with our proposed work we demonstrated that we do not need to train the original network, nor use the whole training dataset, in order to produce a quality pruned network with similar accuracy.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



