Comparative Analysis of Classification Algorithms Using CNN Transferable Features: A Case Study Using Burn Datasets from Black Africans


Abstract
:1. Introduction
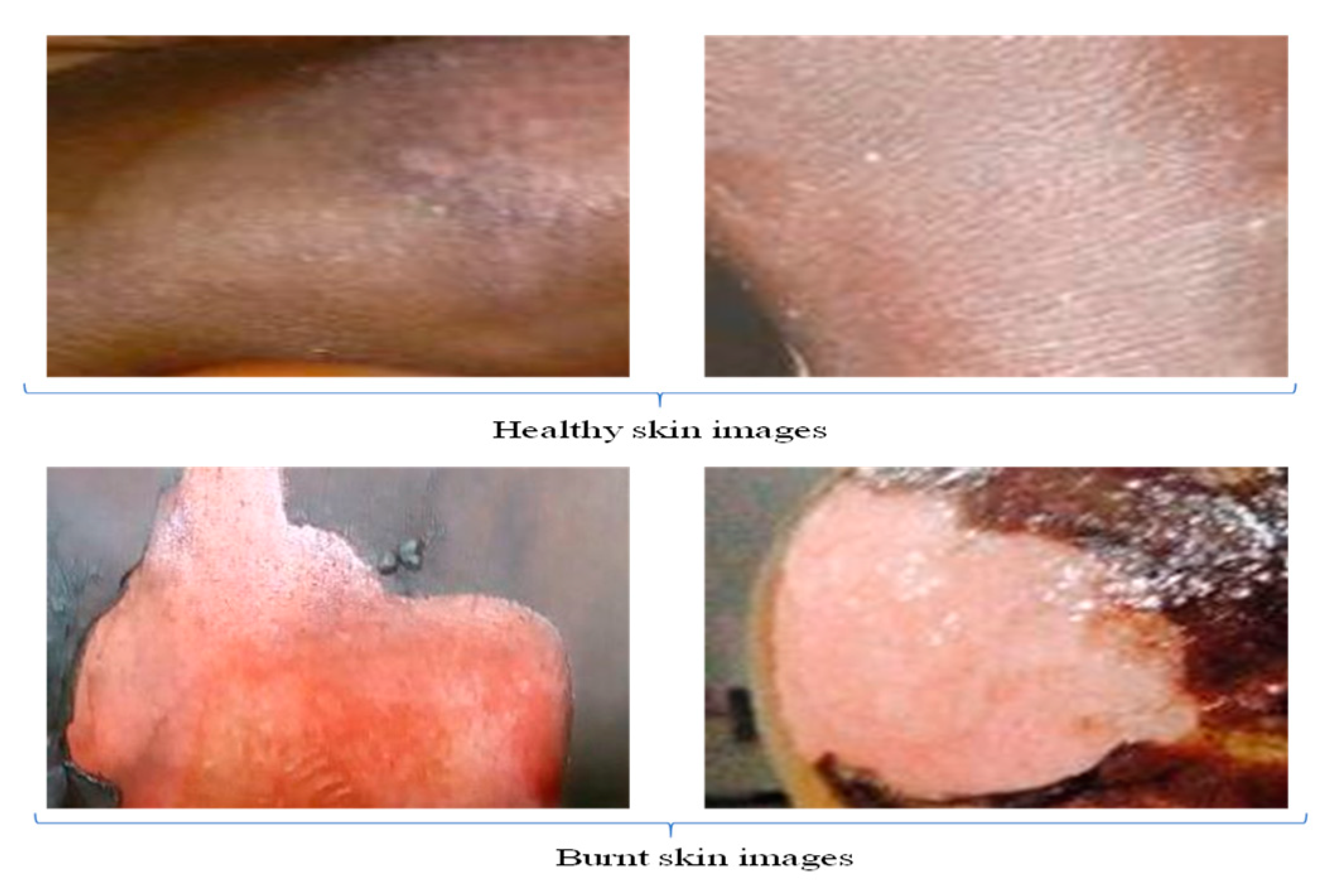
2. Materials and Methodology
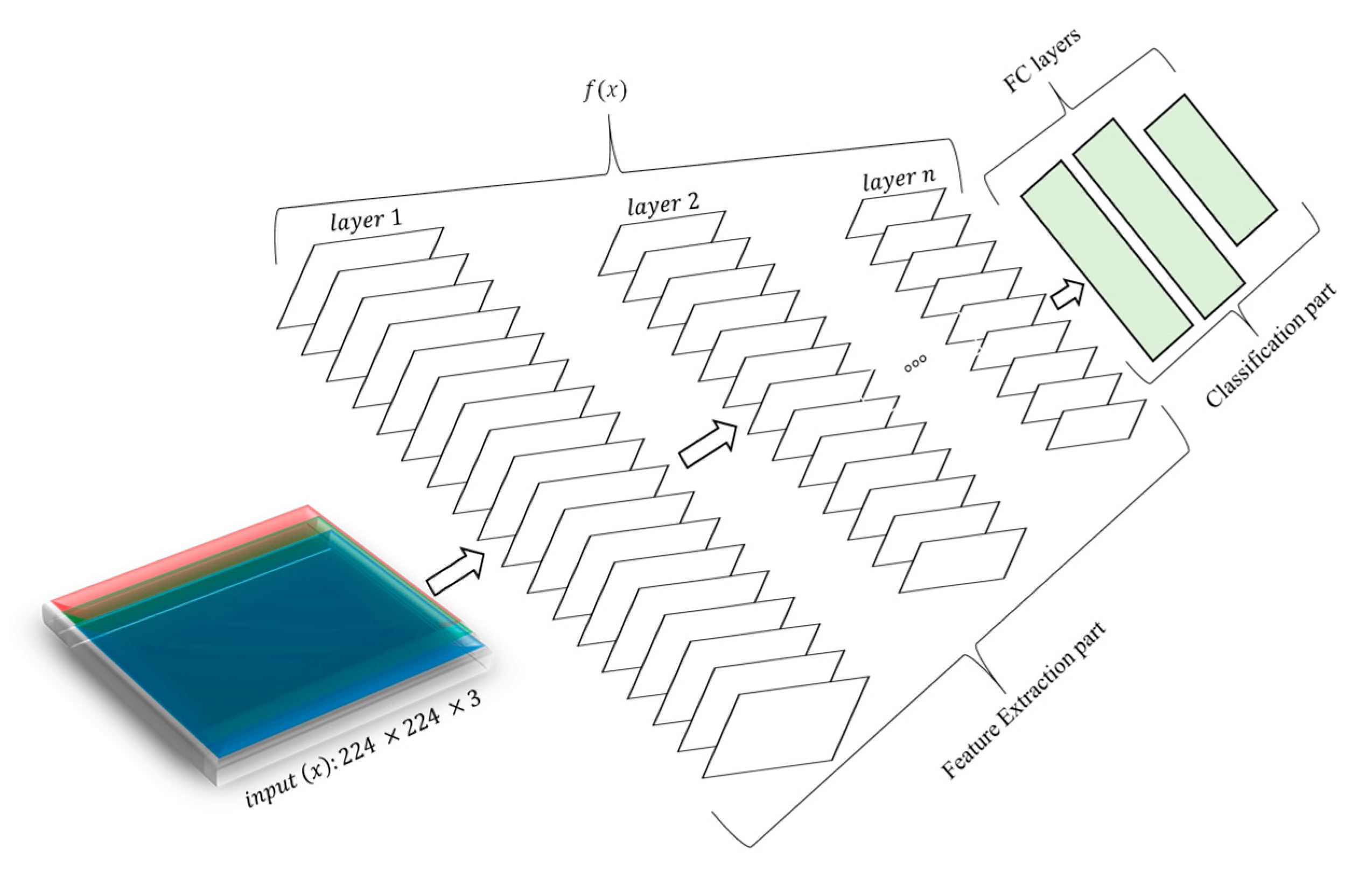
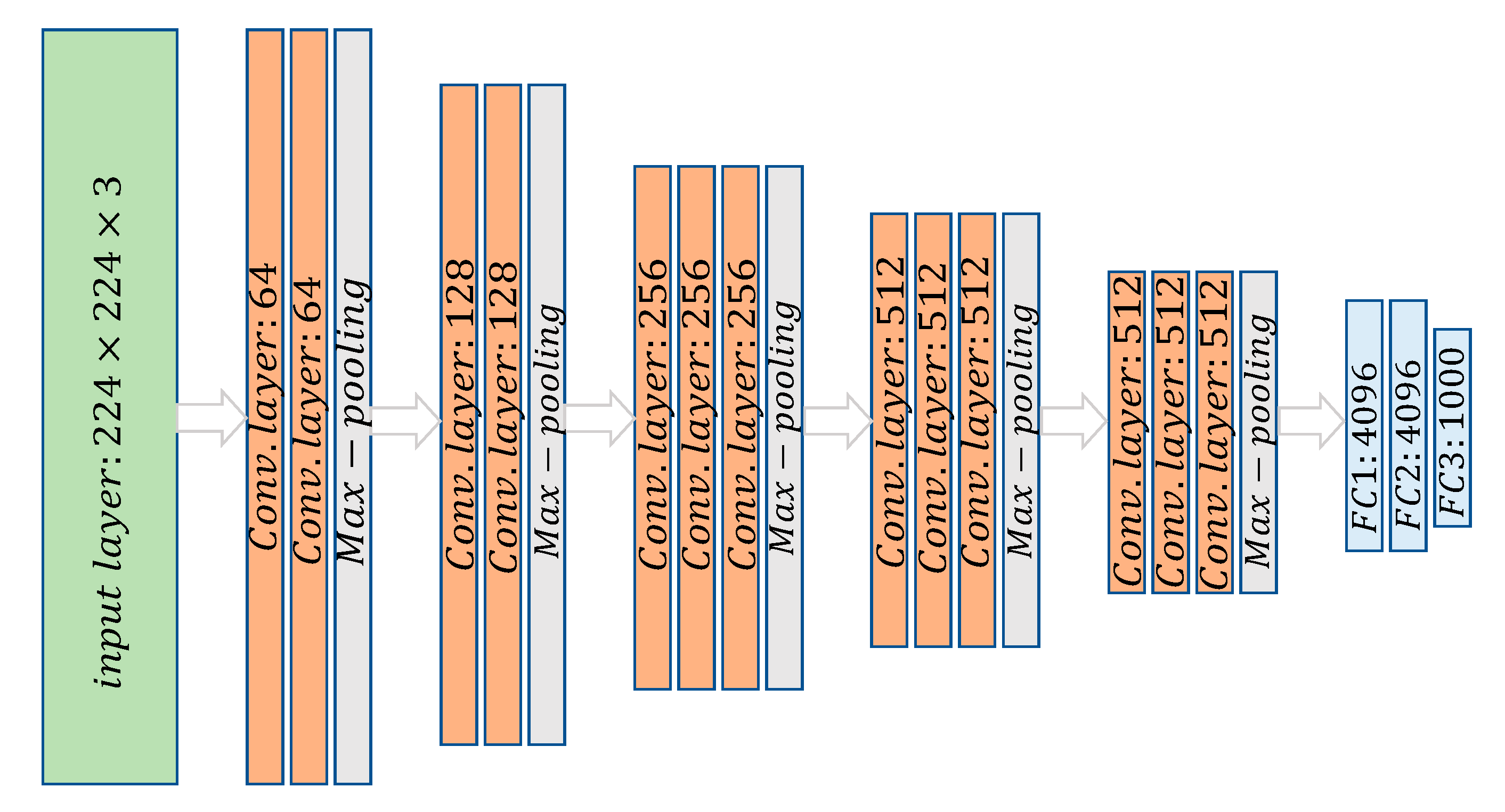
2.1. Extraction of Image Features
2.2. Classification of Features
- DT is a classical classification supervised learning algorithm applied in different application domains such as medical diagnosis [18], signal processing [19], and intrusion detection [20]. It is a hierarchical classifier that builds a multi-label discrimination between classes to determine by determining their specific patterns, and it is very flexible in terms of handling both binary and multi-class classification problems [21].
- SVM is a supervised learning algorithm mostly used for binary classification [22]. It works by finding an optimal separating hyperplane (a decision boundary) that separate the two classes.
- Logistic regression (LR) is also used for binary classification problems [23]; it determines a relationship between categorical independent variables and dependent variables by evaluating probabilities using a logistic function. LR is computationally efficient and takes less time to train compared to SVM.
- The naïve Bayes (NB) classifier finds the probability of each class using a Bayesian formula [24,25]. It makes an assumption that all features of the samples in a particular class are independent of each other, and then discriminates the features by evaluating the posterior probability for each class, before allocating the feature to the class generating the maximum posterior probability.
- K-nearest neighbour (KNN) is a nonparametric classification algorithm that discriminates instances into their distinct classes according to the degree of likeness [24]. The input datasets are separated into K groups with during training where each instance is composed of features belonging to its group.
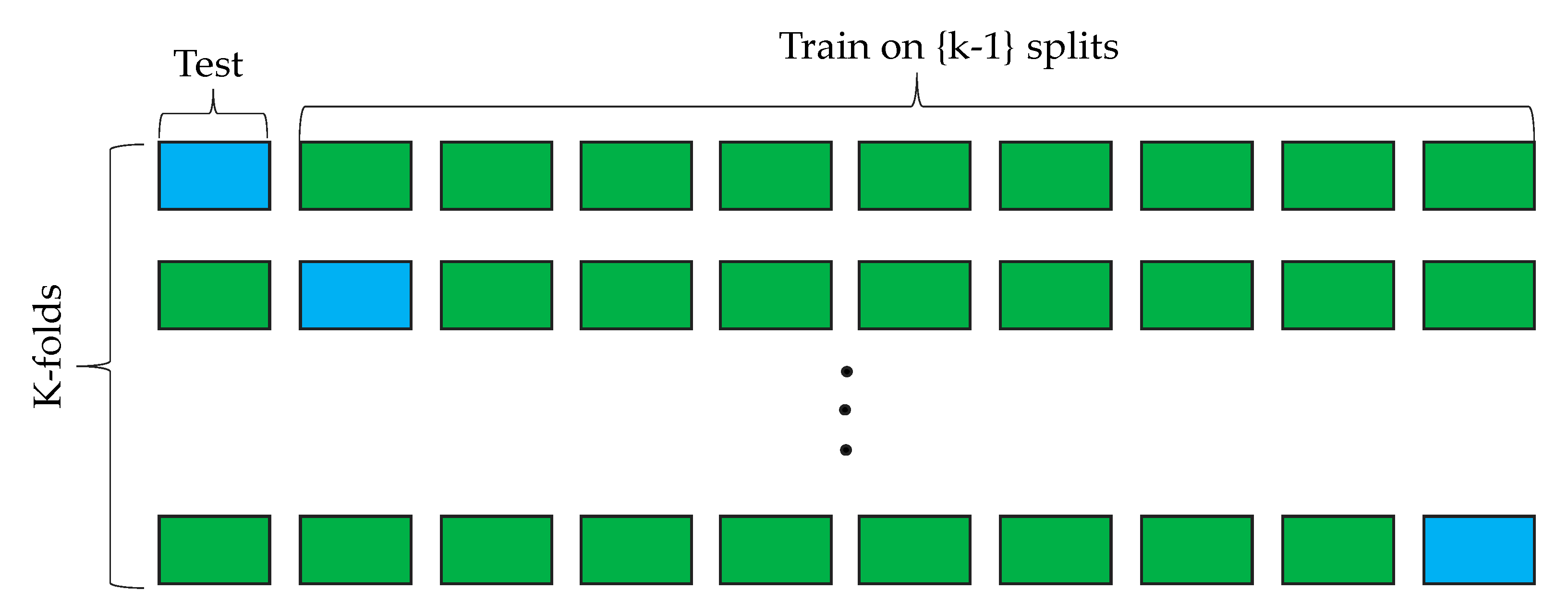
2.3. Training Process
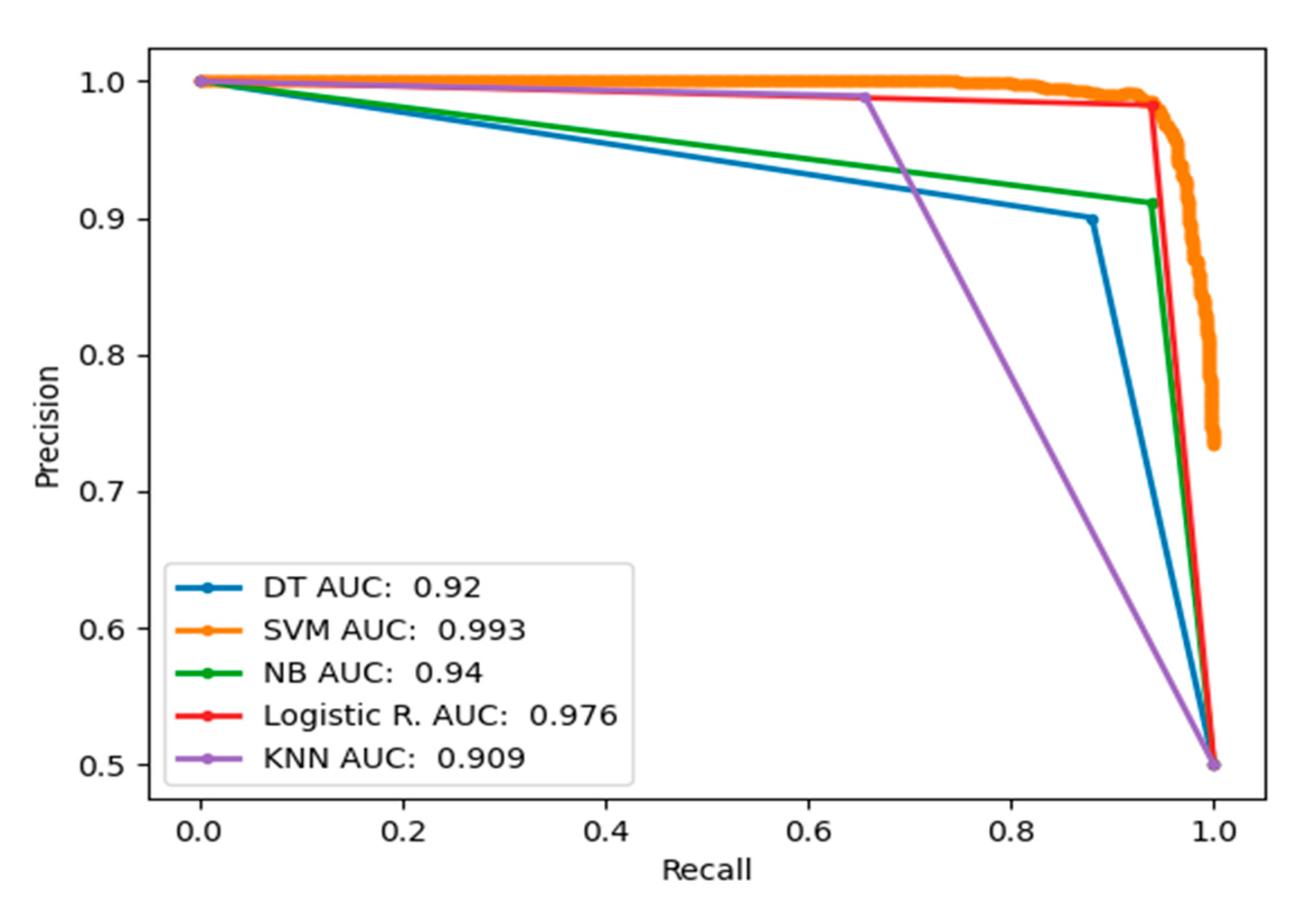
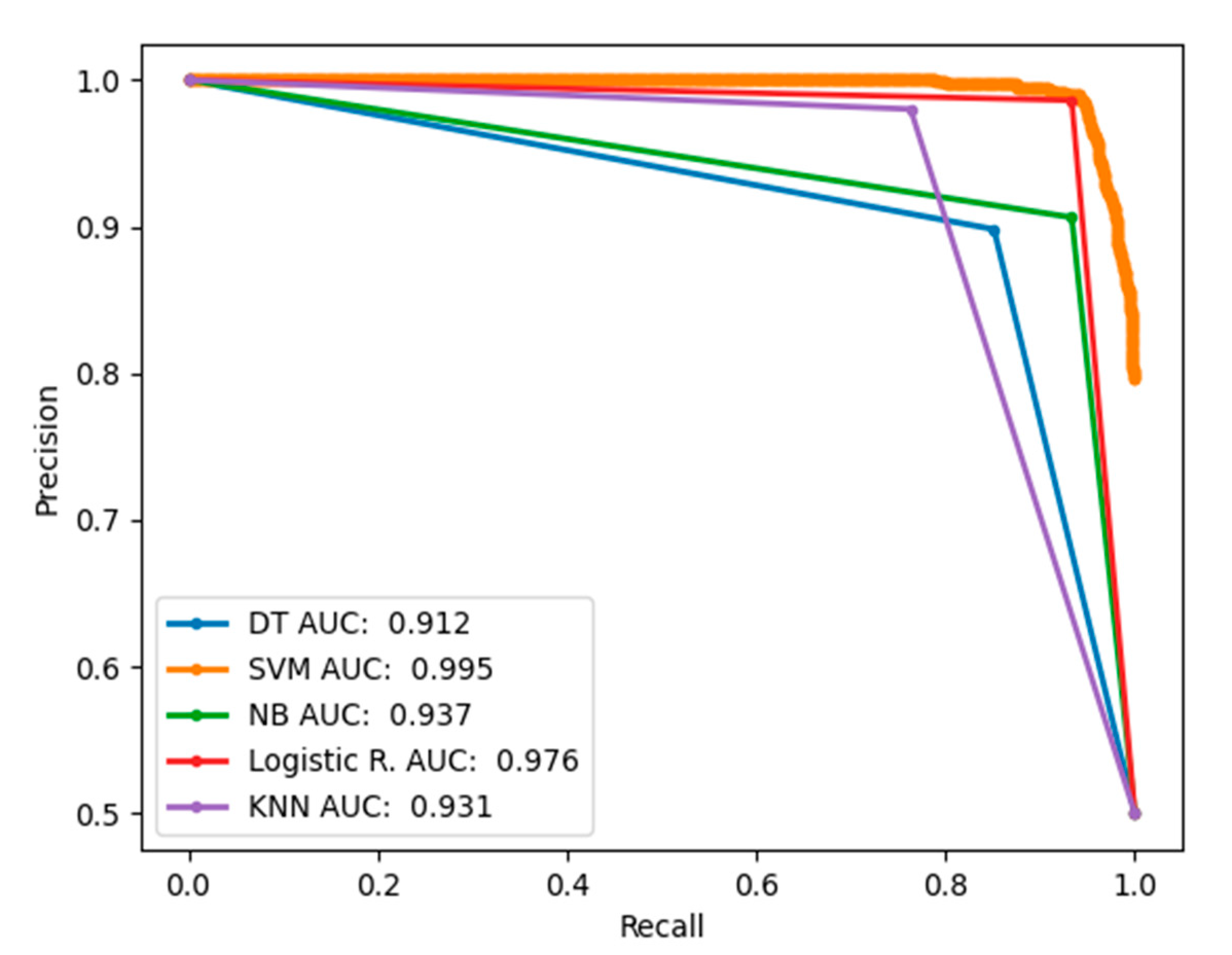
3. Results and Discussion
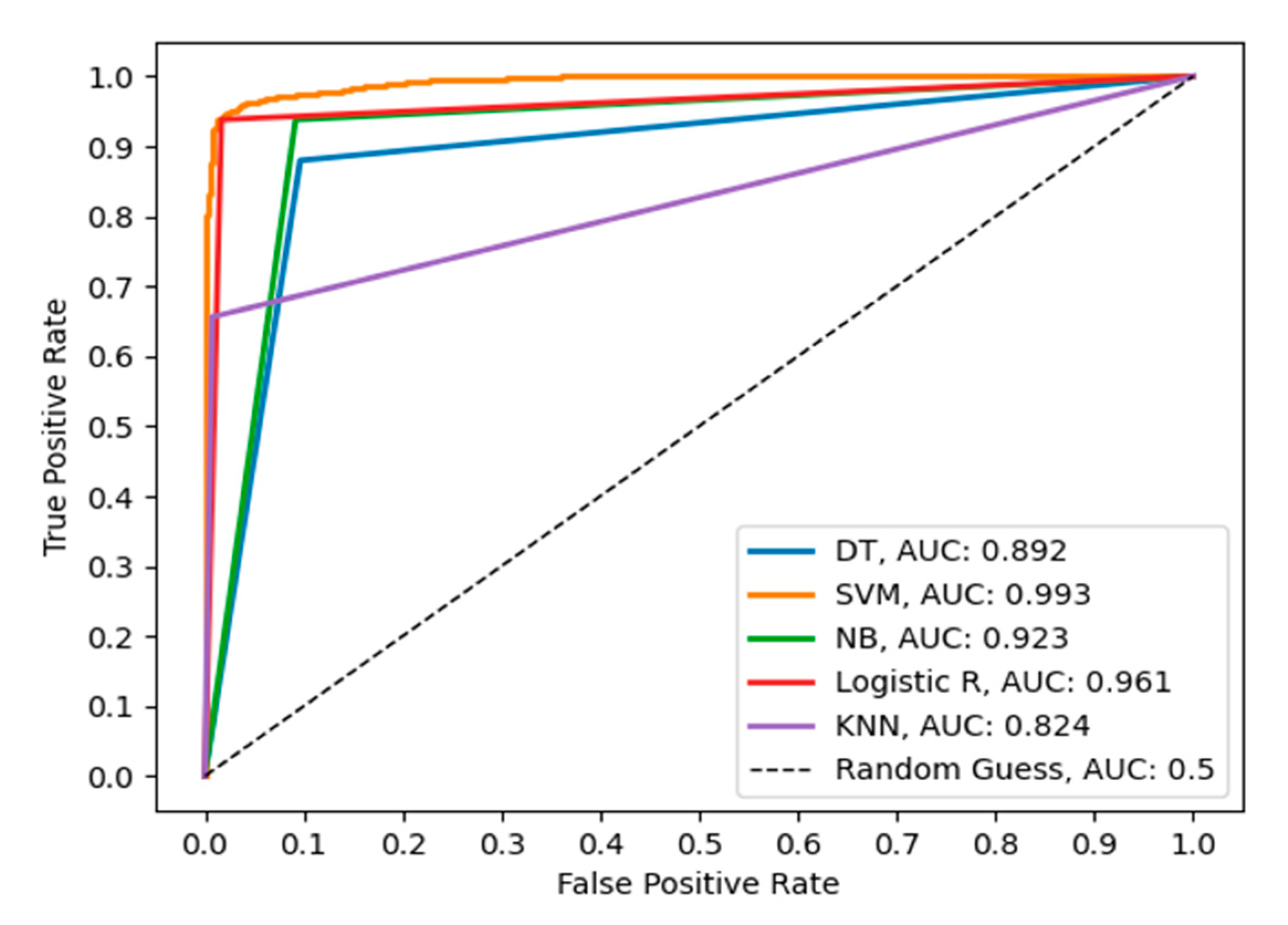
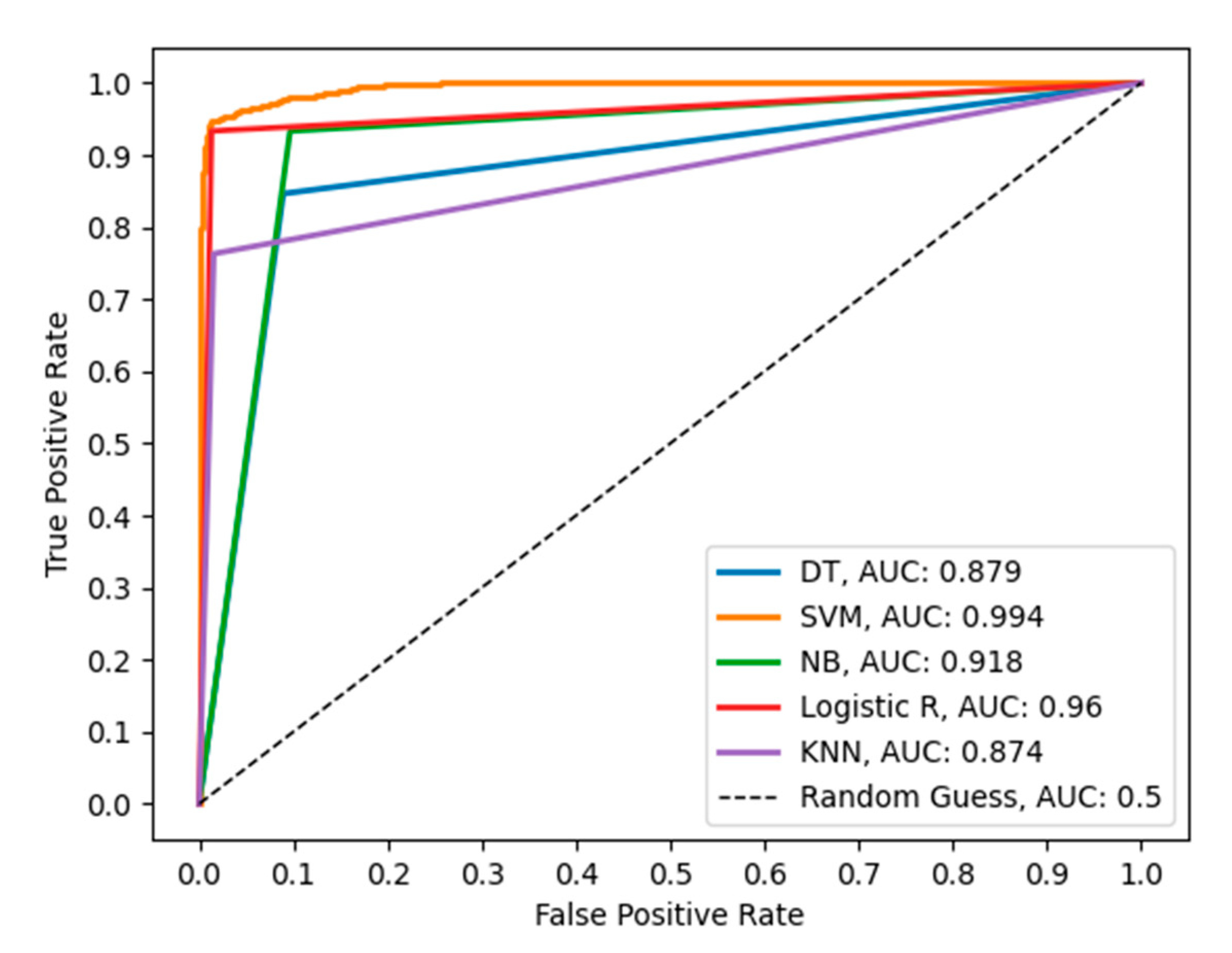
Performance Evaluation
4. Conclusions
Funding
Conflicts of Interest
References
- Grosu-Bularda, A.; Andrei, M.-C.; Mladin, A.D.; Ionescu, S.M.; Dringa, M.-M.; Lunca, D.C.; Lascar, I.; Teodoreanu, R.N. Periorbital lesions in severely burned patients. Rom. J. Ophthalmol. 2019, 63, 38–55. [Google Scholar] [CrossRef]
- Peck, M.D.; Toppi, J.T. Epidemiology and Prevention of Burns throughout the World. In Handbook of Burns; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1, pp. 17–57. [Google Scholar]
- He, S.; Alonge, O.; Agrawal, P.; Sharmin, S.; Islam, I.; Mashreky, S.R.; El Arifeen, S. Epidemiology of Burns in Rural Bangladesh: An Update. Int. J. Environ. Res. Public Heal. 2017, 14, 381. [Google Scholar] [CrossRef] [PubMed]
- Abubakar, A.; Ugail, H.; Bukar, A.M.; Aminu, A.A.; Musa, A. Transfer Learning Based Histopathologic Image Classification for Burns Recognition. In Proceedings of the 2019 15th International Conference on Electronics, Computer and Computation (ICECCO), Abuja, Nigeria, 10–12 December 2019; Aminu, A.A., Musa, A., Eds.; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Abubakar, A.; Ajuji, M.; Yahya, I.U. Comparison of Deep Transfer Learning Techniques in Human Skin Burns Discrimination. Appl. Syst. Innov. 2020, 3, 20. [Google Scholar] [CrossRef] [Green Version]
- Jaspers, M.; Van Haasterecht, L.; Van Zuijlen, P.P.; Mokkink, L.B. A systematic review on the quality of measurement techniques for the assessment of burn wound depth or healing potential. Burns 2019, 45, 261–281. [Google Scholar] [CrossRef] [PubMed]
- Mirdell, R.; Farnebo, S.; Sjöberg, F.; Tesselaar, E. Using blood flow pulsatility to improve the accuracy of laser speckle contrast imaging in the assessment of burns. Burns 2020, 46, 1398–1406. [Google Scholar] [CrossRef] [PubMed]
- Abubakar, A.; Ugail, H. Discrimination of Human Skin Burns Using Machine Learning; Springer: Cham, Switzerland, 2019; pp. 641–647. [Google Scholar]
- Abubakar, A.; Ugail, H.; Bukar, A.M. Assessment of Human Skin Burns: A Deep Transfer Learning Approach. J. Med. Biol. Eng. 2020, 40, 321–333. [Google Scholar] [CrossRef]
- Hoeksema, H.; Baker, R.; A Holland, A.J.; Perry, T.; Jeffery, S.; Verbelen, J.; Monstrey, S. A new, fast LDI for assessment of burns: A multi-centre clinical evaluation. Burns 2014, 40, 1274–1282. [Google Scholar] [CrossRef] [PubMed]
- Elmahmudi, A.; Ugail, H. Experiments on Deep Face Recognition Using Partial Faces. In Proceedings of the 2018 International Conference on Cyberworlds (CW), Singapore, 3–5 October 2018; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 357–362. [Google Scholar]
- Deepak, S.; Ameer, P. Brain tumor classification using deep CNN features via transfer learning. Comput. Biol. Med. 2019, 111, 103345. [Google Scholar] [CrossRef] [PubMed]
- Karthik, R.; Hariharan, M.; Anand, S.; Mathikshara, P.; Johnson, A.; Menaka, R. Attention embedded residual CNN for disease detection in tomato leaves. Appl. Soft Comput. 2020, 86, 105933. [Google Scholar]
- Abubakar, A.; Ugail, H.; Bukar, A.M. Noninvasive assessment and classification of human skin burns using images of Caucasian and African patients. J. Electron. Imaging 2019, 29, 041002. [Google Scholar] [CrossRef]
- Jilani, S.K.; Ugail, H.; Bukar, A.M.; Logan, A. On the Ethnic Classification of Pakistani Face using Deep Learning. In Proceedings of the 2019 International Conference on Cyberworlds (CW), Kyoto, Japan, 2–4 October 2019; pp. 191–198. [Google Scholar]
- Bukar, A.M. Automatic Age Progression and Estimation from Faces. Ph.D. Thesis, University of Bradford, Bradford, UK, 2019. [Google Scholar]
- Bukar, A.M.; Ugail, H. Automatic age estimation from facial profile view. IET Comput. Vis. 2017, 11, 650–655. [Google Scholar] [CrossRef] [Green Version]
- Mohsen, A.A.; Alsurori, M.; AlDobai, B.; Mohsen, G.A. New Approach to Medical Diagnosis Using Artificial Neural Network and Decision Tree Algorithm: Application to Dental Diseases. Int. J. Inf. Eng. Electron. Bus. 2019, 11, 52–60. [Google Scholar] [CrossRef]
- Jahmunah, V.; Oh, S.L.; Rajinikanth, V.; Ciaccio, E.J.; Cheong, K.H.; Arunkumar, N.; Acharya, U.R. Automated detection of schizophrenia using nonlinear signal processing methods. Artif. Intell. Med. 2019, 100, 101698. [Google Scholar] [CrossRef] [PubMed]
- Ahmim, A.; Maglaras, L.; Ferrag, M.A.; Derdour, M.; Janicke, H. A Novel Hierarchical Intrusion Detection System Based on Decision Tree and Rules-Based Models. In Proceedings of the 2019 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Santorini Island, Greece, 29–31 May 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; pp. 228–233. [Google Scholar]
- Wang, F.; Wang, Q.; Nie, F.; Li, Z.; Yu, W.; Ren, F. A linear multivariate binary decision tree classifier based on K-means splitting. Pattern Recognit. 2020, 107, 107521. [Google Scholar] [CrossRef]
- Qian, Y.; Zhou, W.; Yan, J.; Li, W.; Han, L. Comparing machine learning classifiers for object-based land cover classification using very high resolution imagery. Remote. Sens. 2015, 7, 153–168. [Google Scholar] [CrossRef]
- Khairunnahar, L.; Hasib, M.A.; Bin Rezanur, R.H.; Islam, M.R.; Hosain, K. Classification of malignant and benign tissue with logistic regression. Inform. Med. Unlocked 2019, 16, 100189. [Google Scholar] [CrossRef]
- Farhi, L.; Zia, R.; Ali, Z.A. 5 Performance Analysis of Machine Learning Classifiers for Brain Tumor MR Images. Sir Syed Res. J. Eng. Technol. 2018, 1, 6. [Google Scholar] [CrossRef]
- Al Zorgani, M.; Ugail, H. Comparative Study of Image Classification Using Machine Learning Algorithms. Technical Report. 2018. Available online: https://www.semanticscholar.org/paper/EasyChair-Preprint-No-332-Comparative-Study-of-Zorgani-Ugail/6abe570933f798215534fb0ff168f42c118e5401?p2df (accessed on 14 October 2020).
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | DT | SVM | NB | LR | KNN |
|---|---|---|---|---|---|
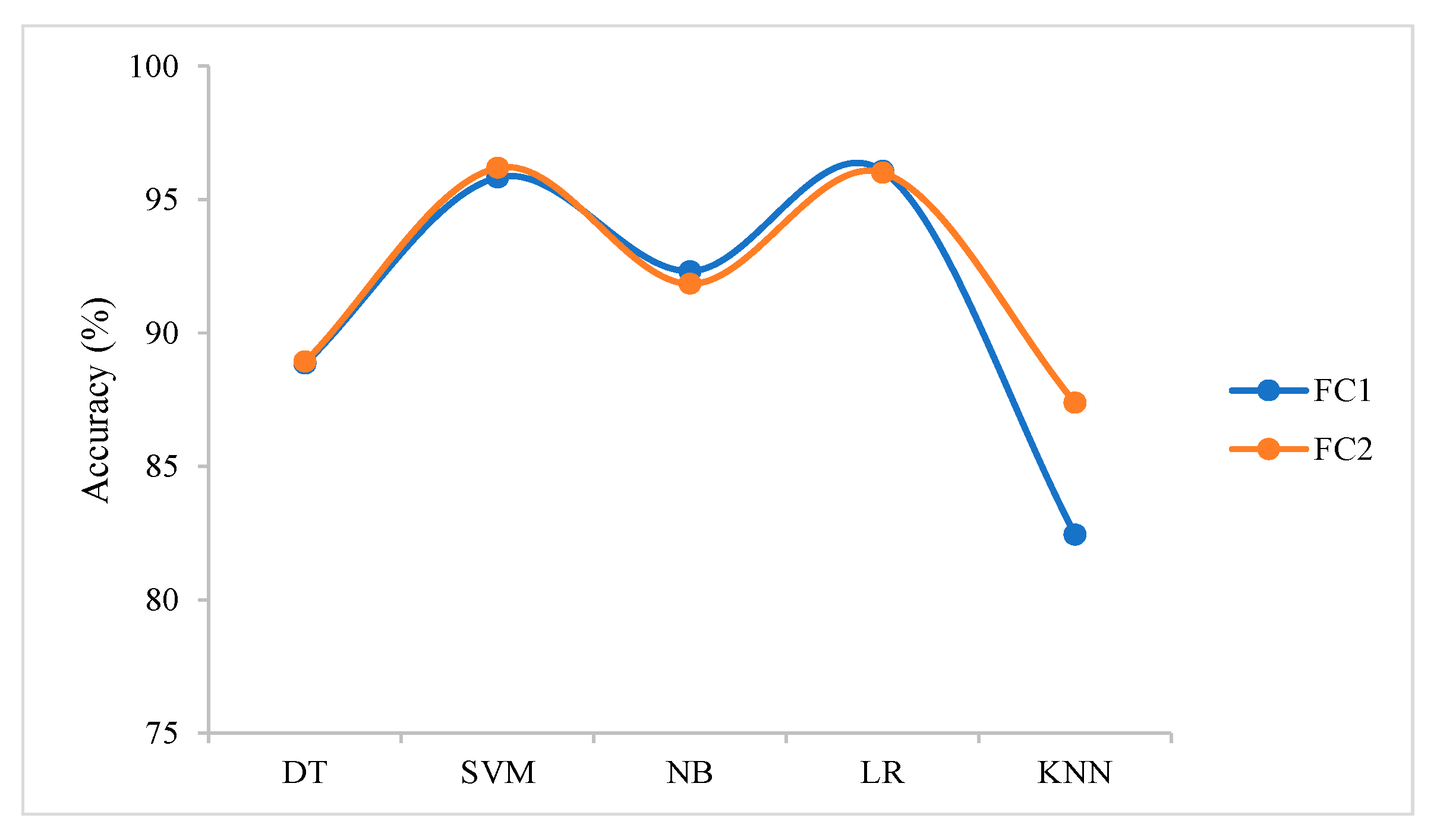
| FC1 | 88.86% | 95.83% | 92.32% | 96.07% | 82.44% |
| FC2 | 88.93% | 96.19% | 91.85% | 96.01% | 87.38% |
| Layer | DT | SVM | NB | LR | KNN |
|---|---|---|---|---|---|
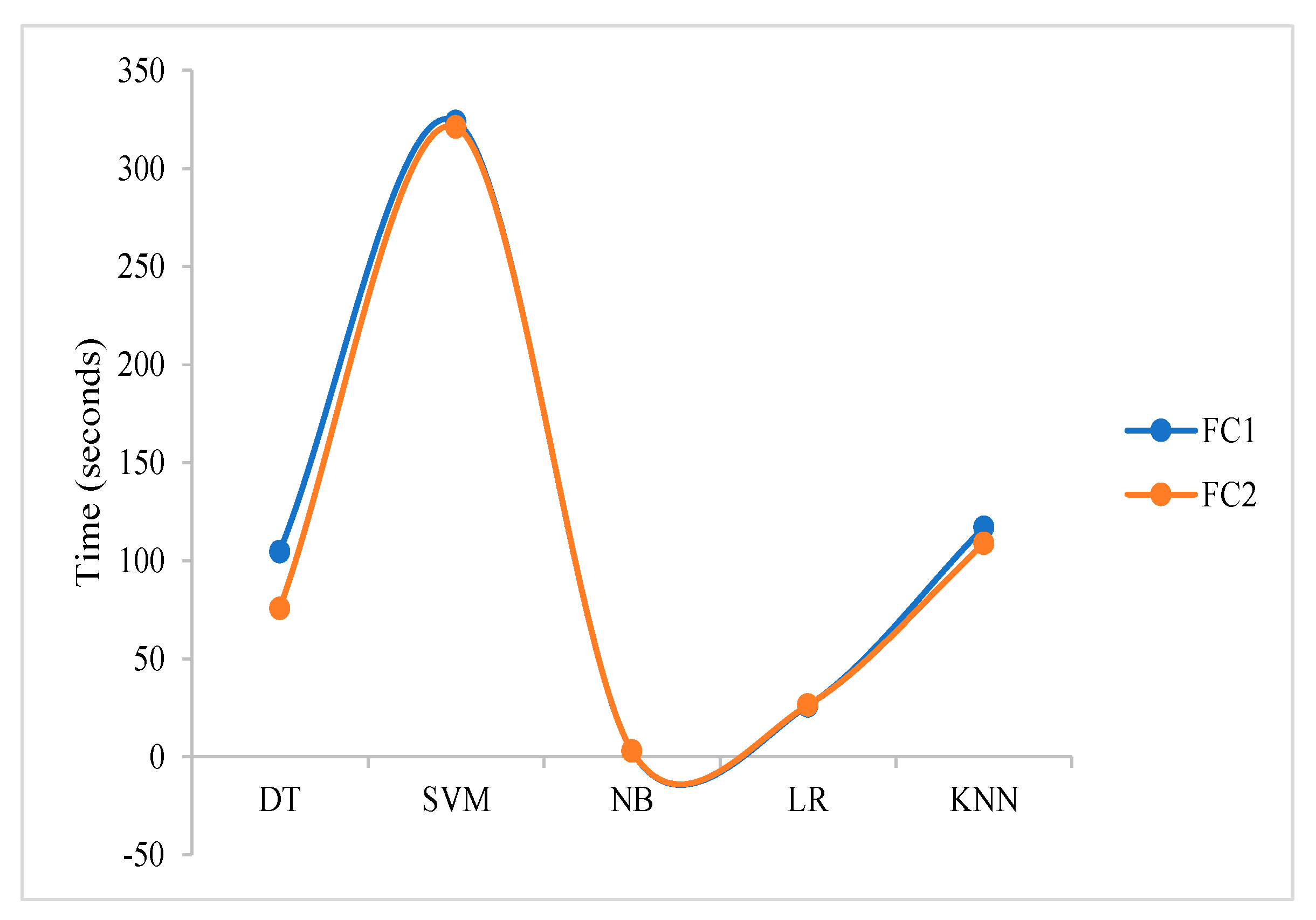
| FC1 | 104.75 | 323.99 | 2.91 | 26.10 | 117.09 |
| FC2 | 75.78 | 321.11 | 3.06 | 26.47 | 108.92 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | TN | FP |
| Positive | FN | TP |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 761 | 79 |
| Positive | 97 | 743 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 829 | 11 |
| Positive | 59 | 781 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 763 | 77 |
| Positive | 52 | 788 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 826 | 14 |
| Positive | 52 | 788 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 834 | 6 |
| Positive | 289 | 551 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 755 | 85 |
| Positive | 128 | 712 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 832 | 8 |
| Positive | 56 | 784 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 759 | 81 |
| Positive | 56 | 784 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 829 | 11 |
| Positive | 56 | 784 |
| True Class | Predicted Class | |
|---|---|---|
| Negative | Positive | |
| Negative | 827 | 13 |
| Positive | 199 | 641 |
| Layer | DT | SVM | NB | LR | KNN |
|---|---|---|---|---|---|
| FC1 | 90.39% | 98.61% | 91.10% | 98.25% | 98.92% |
| FC2 | 89.34% | 98.99% | 90.64% | 98.62% | 98.01% |
| Layer | DT | SVM | NB | LR | KNN |
|---|---|---|---|---|---|
| FC1 | 88.45% | 92.98% | 93.81% | 93.81% | 65.60% |
| FC2 | 84.76% | 93.33% | 93.33% | 93.33% | 76.31% |
| Layer | DT | SVM | NB | LR | KNN |
|---|---|---|---|---|---|
| FC1 | 89.41% | 95.71% | 92.43% | 95.98% | 78.88% |
| FC2 | 86.99% | 96.08% | 91.96% | 95.90% | 85.81% |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abubakar, A. Comparative Analysis of Classification Algorithms Using CNN Transferable Features: A Case Study Using Burn Datasets from Black Africans. Appl. Syst. Innov. 2020, 3, 43. https://doi.org/10.3390/asi3040043
Abubakar A. Comparative Analysis of Classification Algorithms Using CNN Transferable Features: A Case Study Using Burn Datasets from Black Africans. Applied System Innovation. 2020; 3(4):43. https://doi.org/10.3390/asi3040043
Chicago/Turabian StyleAbubakar, Aliyu. 2020. "Comparative Analysis of Classification Algorithms Using CNN Transferable Features: A Case Study Using Burn Datasets from Black Africans" Applied System Innovation 3, no. 4: 43. https://doi.org/10.3390/asi3040043
APA StyleAbubakar, A. (2020). Comparative Analysis of Classification Algorithms Using CNN Transferable Features: A Case Study Using Burn Datasets from Black Africans. Applied System Innovation, 3(4), 43. https://doi.org/10.3390/asi3040043