1. Introduction
Compared to conventional manufacturing, which often involves machining or other techniques to extract surplus material, additive manufacturing (AM) creates components layer by layer [
1]. AM uses CAD/CAM software for model generation, then the model is inputted into a 3D printer for slicing and G&M code generation, after which the 3D printer forms a 3D component. There are several types of AM processes that include fused deposition modeling (FDM), stereolithography (SLA), digital light processing (DLP), selective laser sintering (SLS), etc. [
2]. The application range of AM is wide; it is used in the field of manufacturing, healthcare, aerospace engineering, fabrication, fashion, etc. [
3,
4] Because of the low cost of materials and the state of material available, Fused Deposition Modelling (FDM) is the most popular AM method. Despite the diversity of components AM can produce, AM is still susceptible to various defects due to the material properties and structural diversity of printed components. FDM 3D printers are subjected to multiple defects. During printing, due to material property or process failure, the component gets printed with several defects, such as warping, blistering, porosity, cracking, and residual stress.
The research provides an experimental comparative analysis of real-time defect detection. The objectives of this research are:
To provide a real-time fault detection system for FDM 3D printers.
To provide a comparative study of model algorithms for fault detection on their computational accuracy results.
To provide a density-wise classification of printed components.
To provide ensemble learning results of model algorithm combinations.
The paper overview includes the system methodology in which the experimental approach, algorithms, and pre-trained model used are explained. Further, it includes the experimental setup used, including the data collection technique and the result obtained by experimental analysis and comparative results of model algorithms.
Different defects that occur in printed components and their causes and effects are shown in
Table 1. Out of all the defects in 3D printed components, most are because of the material property or printing technique used. Warping gets introduced during the printing of a long component. The material extrusion layer-by-layer technique used in FDM components often requires post-processing since the printed component has a poor surface finish. Sometimes formation of small voids can lead to crack generation and, later on, failure of a component. Various defects that occur, such as clogging of the nozzle, improper bed leveling, misalignment of the printing platform, lack or loss of adhesion of the print platform etc., can be solved by manual adjustment. These errors are mainly due to carelessness of the operator and are not part of the research.
2. Literature Review
Given that 3D printing is still a relatively new technology in the manufacturing sector, there is limited literature addressing quality issues with 3D printing. H. Gunaydin et al. have stated the different errors that occurs, such as clogging of the nozzle, adhesion problem, vibration or shocks, misalignment of the print platform, etc., which causes loss of material, time, and money [
8]. D. Geng and J. Zhao stated the severity of warpage problems, which are caused due to improper cooling [
5]. Apart from machine errors, printing components are subjected to errors due to structural and material shortcomings such as porosity, cracking, residual stresses, etc. [
7]. L. Yuan emphasizes the solidification defects in printed components that affect the overall strength of the printed part [
6].
During the manufacturing process, the ongoing process or system component often interacts with the environment, humans, and various parameters that affect the physical element. An important factor for monitoring a system is the availability of built-in sensors, but current FDM printers lack these built-in sensors. Therefore, it is a very difficult task for sensing the real-time system state, which is vital for fault detection. Many studies are performed for anomaly detection using a sensor-based approach such as Kousiatza and Karalekas, who used temperature sensors and thermocouples to generate temperature profiles for fault detection [
11]. Li et al. provided a sensor-based model for surface anomaly detection [
12]. Many works are done using a sensor-based model for fault detection. However, almost all FDM machines currently have few sensing capabilities that are either inaccessible to users or are not equipped with feedback measurement systems for process correction [
13]. For diagnosing a single defect, sensor-based monitoring systems need several sensors. In contrast, only a few sensors can precisely track and recognize product quality during the actual process. Finding the sensor’s perfect position is difficult since data gathering accuracy depends on the sensors’ position.
The majority of the defects are detectable by the naked eye. Still, it is difficult to consistently monitor the process by sight, making it difficult to detect errors on time. Some errors go unnoticed in the sensor-based approach as it does not consider the errors that occur in layers while printing. This study focuses on anomaly detection using a camera using the layer-wise approach. Computational Image Analysis is an interdisciplinary area that allows computers to interpret images and video frames at a higher level. Computer vision (CV) is typically a difficult task since it focuses on various issues such as image segmentation, object tracking in a video stream, feature extraction, and motion tracking [
14]. Many printers now include a monitoring camera that can be streamed to a website or a smartphone app; this makes it much easier to keep a closer eye on the printer and ensure that nothing is wrong. However, human interaction is still required, and the additive manufacturing process is not as automated as possible. To avoid human interaction or minimize it as much as possible, machine learning (ML) can play an important role since ML provides various algorithms for classification, segmentation, error detection, etc. [
15]. Many works are done in the area of anomaly detection using ML. Machine learning [
16] can play a critical role in developing multi-level predictive models for the AM process. Many machine learning models have been investigated for specific processes and applications to find faults in the AM process [
17,
18]. N. Silaparasetty stated the overview of ML, deep learning, and big data [
19]. A. Dey explained all the techniques of ML and different algorithms with structure, ML provides wide range of algorithm that can be used for fault detection [
20]. Zhang et al. implemented ML model and computational data to control powder quality in metal AM processes obtained from the Discrete Element Method [
21]. Stoyanov et al. used an ML model to improve the electronics component generated by 3D inkjet printing [
22]. Many works use ML architectures combined with acoustics or visual monitoring for automatic defect detection during the printing process. Konstantinos Paraskevoudis et al. used a computer vision approach for stringing type error but did not consider layer-wise fault detection [
9].
Literature findings are shown in
Table 2 in the form of the 3D printer technique, the approach used for study, selection of the model, and accuracy obtained by selected model.
Table 2 shows the literature findings in a simplified format; it shows which AM technique is considered for the experimental purpose, such as FDM, SLS, etc.
Table 2 visualizes the approach used in research; it may be sensor-based, computer vision-based (with the help of a camera), or any other monitoring or fault detection method. The table also incorporates which technique is used for fault detection, whether it is ML, deep learning, convolutional neural network (CNN), artificial neural network (ANN), or a combination of these techniques along with their accuracy obtained.
Many studies include monitoring based on sensors, which involves finding the perfect location for the sensor since sensor location is an important factor that affects the model’s overall efficiency. Very few studies used a layer-wise image capturing approach for fault detection. This study provides a method to identify defects by capturing the layer-wise photo of the printing process with the help of ML and computer vision. This paper suggests a computer vision system based on machine learning for monitoring the quality characteristics of additive manufacturing processes. The material may overfill or underfill due to the residual pressure of the melted filament inside the extrusion chamber, resulting in visible surface defects or unseen internal defects, leading to degradation of the product’s quality. System failures can be predicted and flagged by the monitoring system in the earliest stage of the proposed monitoring system. For the implementation of the monitoring system, we first trained the model in offline mode by gathering an image dataset, and then tested the predictive model for online AM process monitoring. This capability will transform the 3D printer into a self-inspecting machine capable of inspecting parts as they are being constructed, adding another layer of quality control to the process.
3. Methodology
All the work is performed on the FDM-based 3D printer Dreamer; no hardware changes are done except camera mounting for image capturing. Red-Green-Blue (RGB) images are automatically captured with the raspberry-pi camera. All the programming, training, and testing are done in Matlab.
3.1. System Methodology
A layer-wise approach is used most of the time, as the defects involved in printed components go unnoticed in the sensor-wise approach for fault detection. Current FDM printers lack inbuilt sensors, which is why this study focuses on layer-wise monitoring of printing components for fault detection. Layer-wise monitoring involves capturing layer-wise images of printed components for training, processing, and classification.
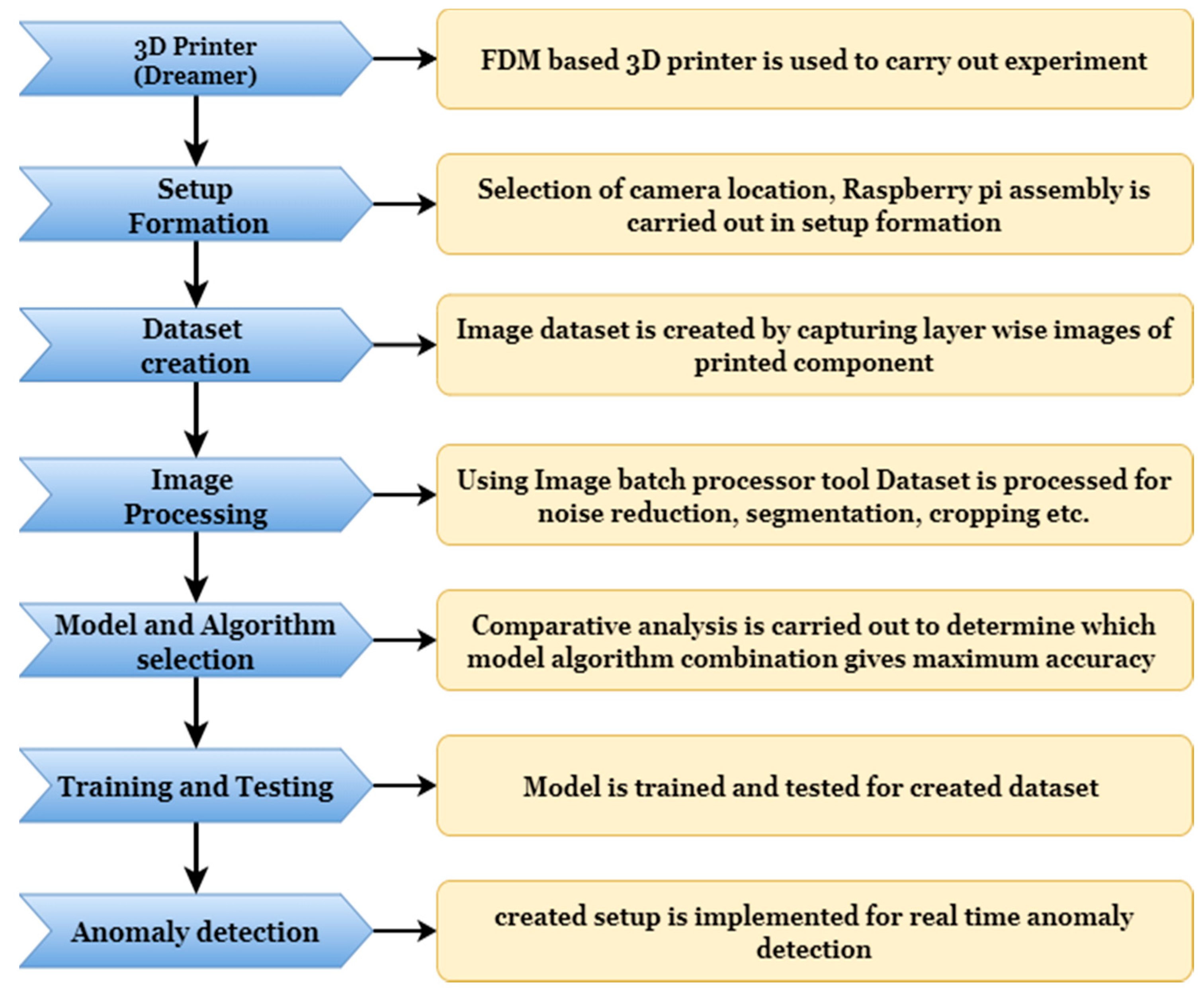
The experimental process flowchart is shown in
Figure 1; the study starts with setup formation to capture layer-wise images. In the second stage, an image dataset is created by capturing multiple layer-wise images of the printing component. The prepared image dataset is processed for noise reduction, segmentation, and cropping in the next step. After successfully creating the dataset, a combination of a model algorithm is selected for training and testing. Upon identifying optimal combination, a model is implemented for real-time fault detection.
Pre-trained models are used only for feature extraction purposes. Training and validation are carried out with different algorithms such as Support Vector Machine (SVM), K-Nearest Neighbor (KNN), Random Forest, etc.
Polylactic Acid (PLA) material is selected as the printing material; PLA is a polymer made from corn starch and other organic materials. PLA becomes slightly more liquid and harder during printing than ABS. As a consequence, the prints are typically more informative than Acrylonitrile Butadiene Styrene (ABS) prints. PLA and ABS are almost indistinguishable visually, with PLA being slightly shinier.
3.2. Algorithm Study
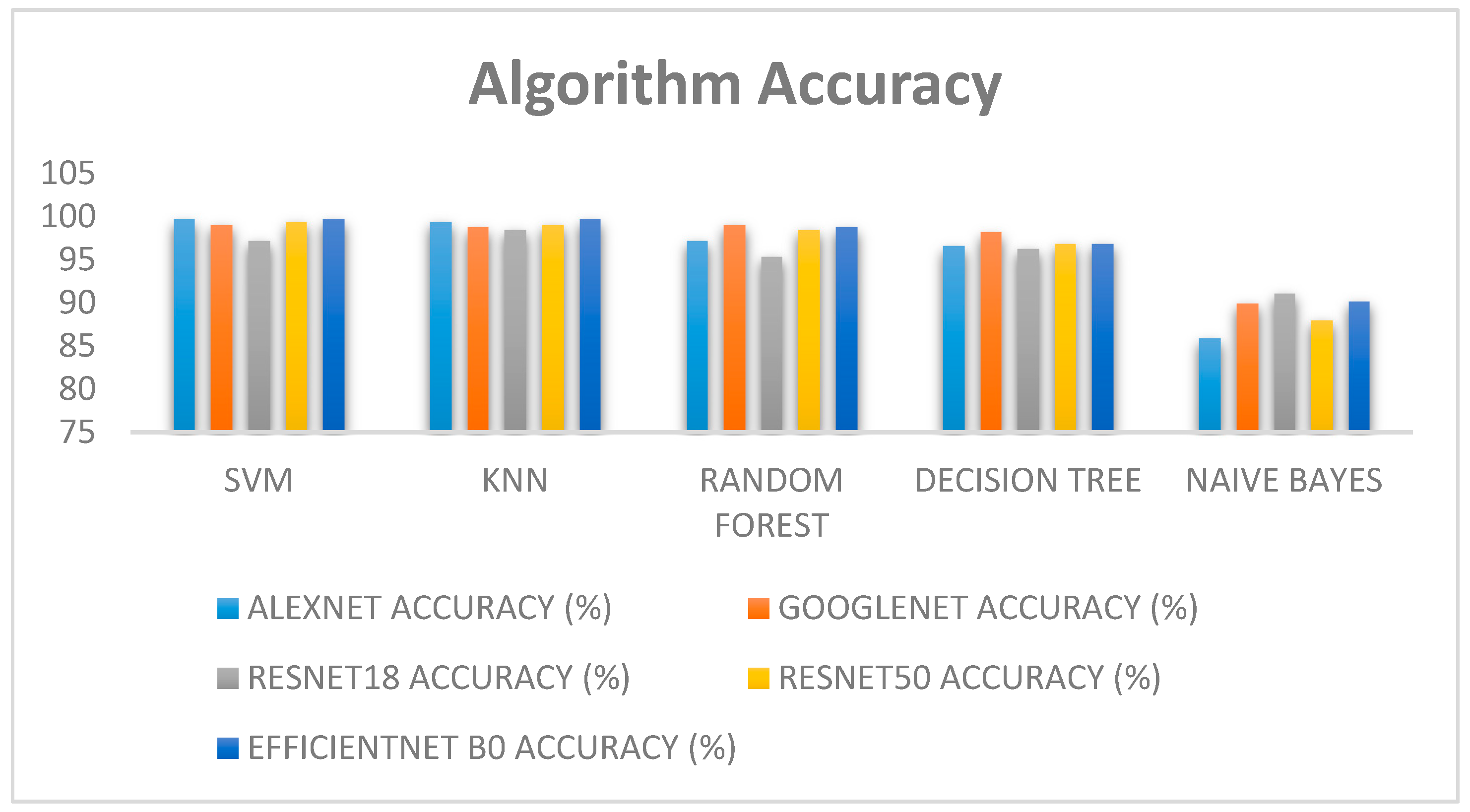
Various current state-of-the-art algorithms are available, with different training speeds, accuracy, and testing speeds in benchmark datasets. Since the aim of the model is to be deployed in a live setting, we considered the need to strike a balance between good accuracies and quick detection in our case.
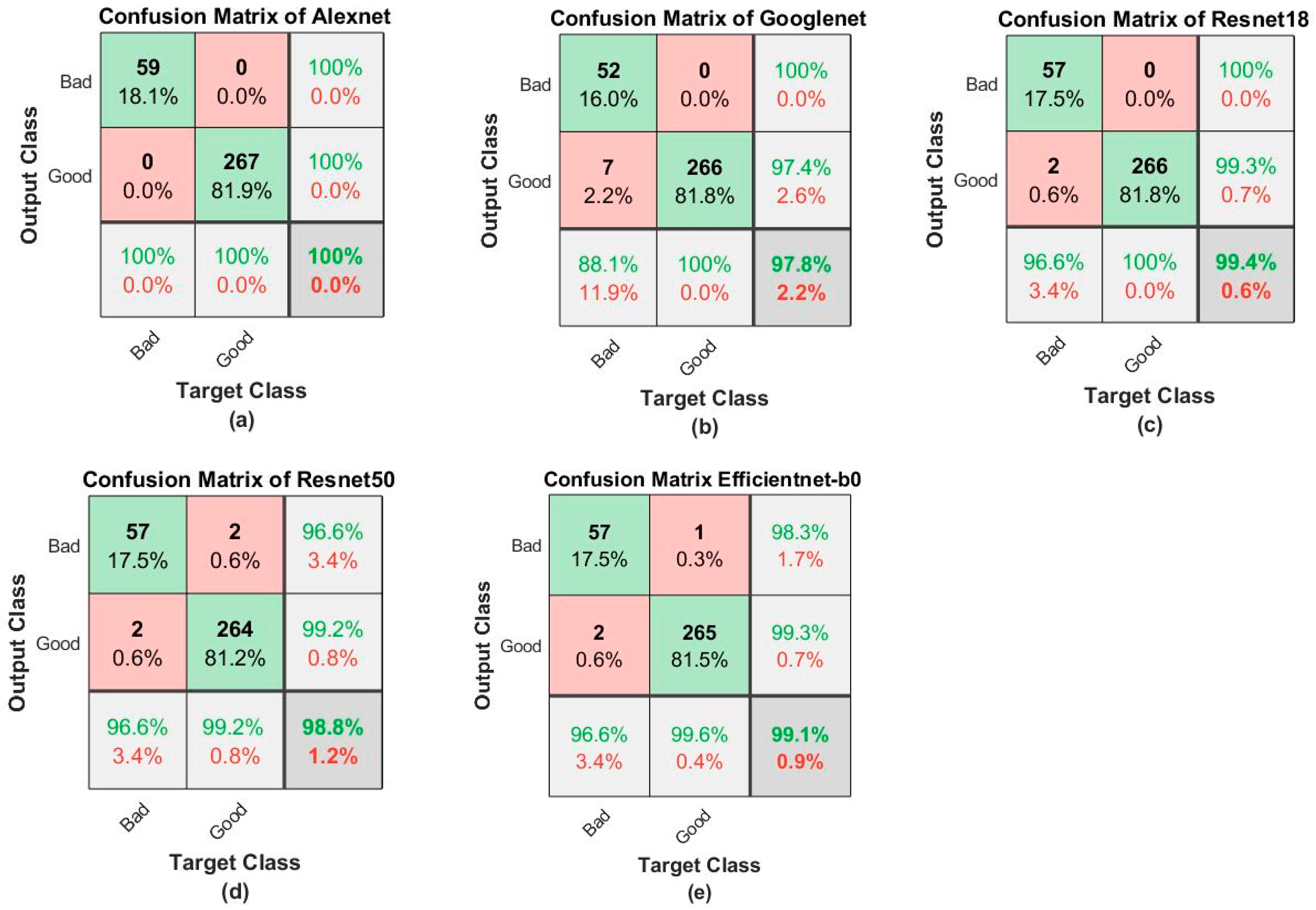
MATLAB is used for feature extraction and anomaly detection since it provides a variety of pre-trained models, image processing tools, algorithms readily available with a handful of command lines. A pre-trained model is used for training; Alexnet, Googlenet, Resnet18, Resnet50, and Efficientnet-b0 are the different pre-trained models used for feature extraction and training purposes. The image dataset is pre-processed as per the model’s requirement since different pre-trained models have different image input sizes.
Pre-trained models are only used for feature extraction purposes. For training and classification, different algorithms are used to improve model accuracy further. The different algorithms used are
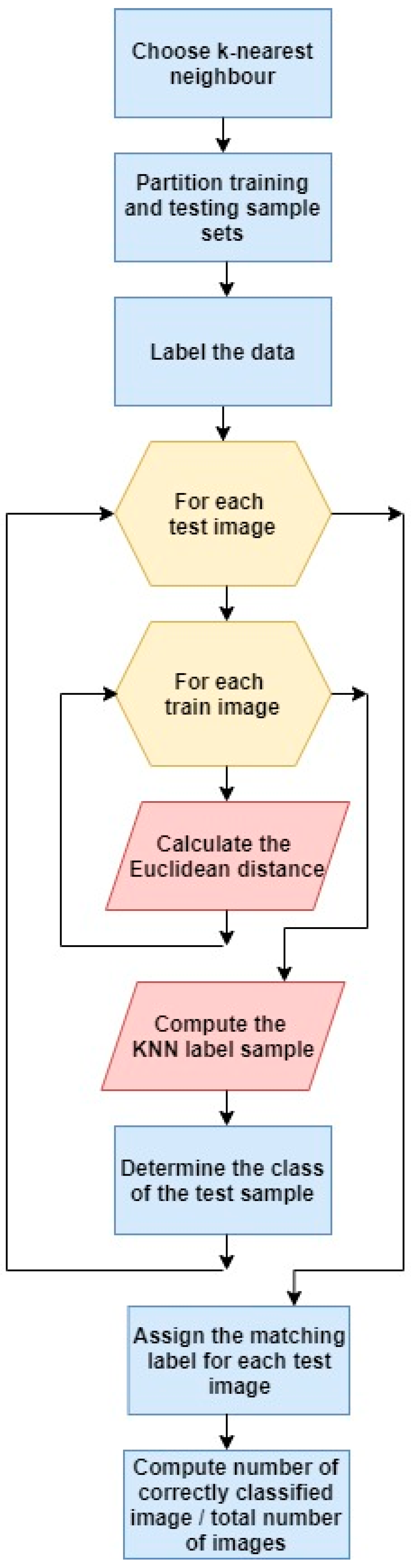
K-Nearest Neighbor (KNN): In KNN, the labeled dataset created for training purposes is fed into the classifier/learner, then the learner classifies the sets of data inputted. K most correlated data from the training set is chosen. Most of K is selected, and test data is assigned to a new class [
30].
Figure 2 shows the architecture of the K-nearest neighbor classifier [
31].
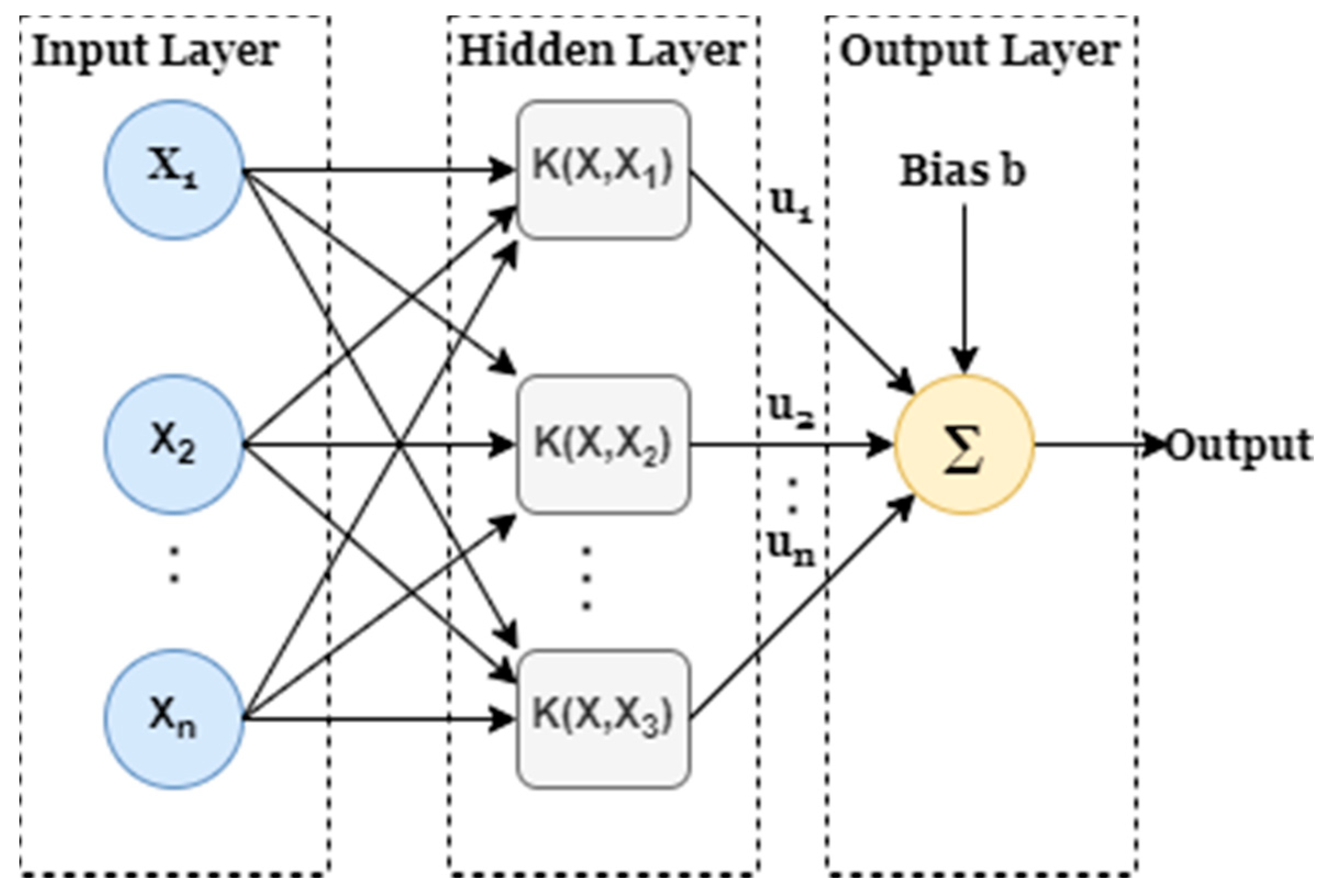
Support Vector Machine (SVM): SVM is another state of art algorithm which is mostly used for categorization. SVM is based on the concept of calculating margins. It is used to separate groups of data by drawing a line in between. The margins are selected such that there is a minimum difference between margin and labeled classes resulting in reducing classification error [
32].
Figure 3 shows the architecture of the support vector machine classifier [
33].
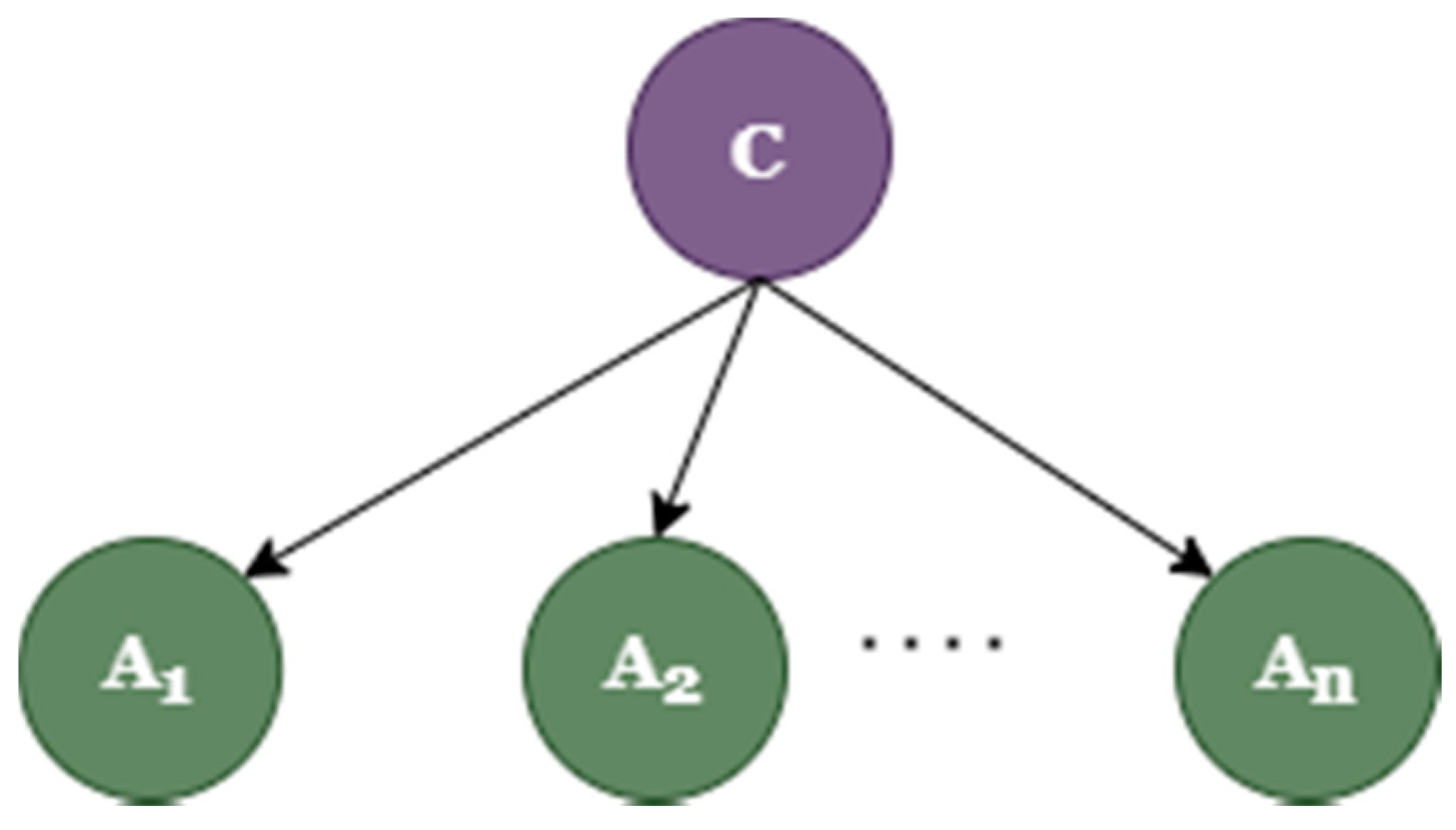
Naive Bayes: Naive Bayes is primarily employed for clustering and classification. The Bayesian network is mainly used for probability distribution, which is described by direct acyclic graphs (DACG). Nodes in the Bayesian network represent the variable, and the connecting arc means probabilistic dependency between variables. The conditional probability is used in the underlying architecture of Naive Bayes. It produces trees dependent on the likelihood of them occurring. Bayesian Network is another name for these trees [
34].
Figure 4 shows the Naive Bayes classifier structure [
35].
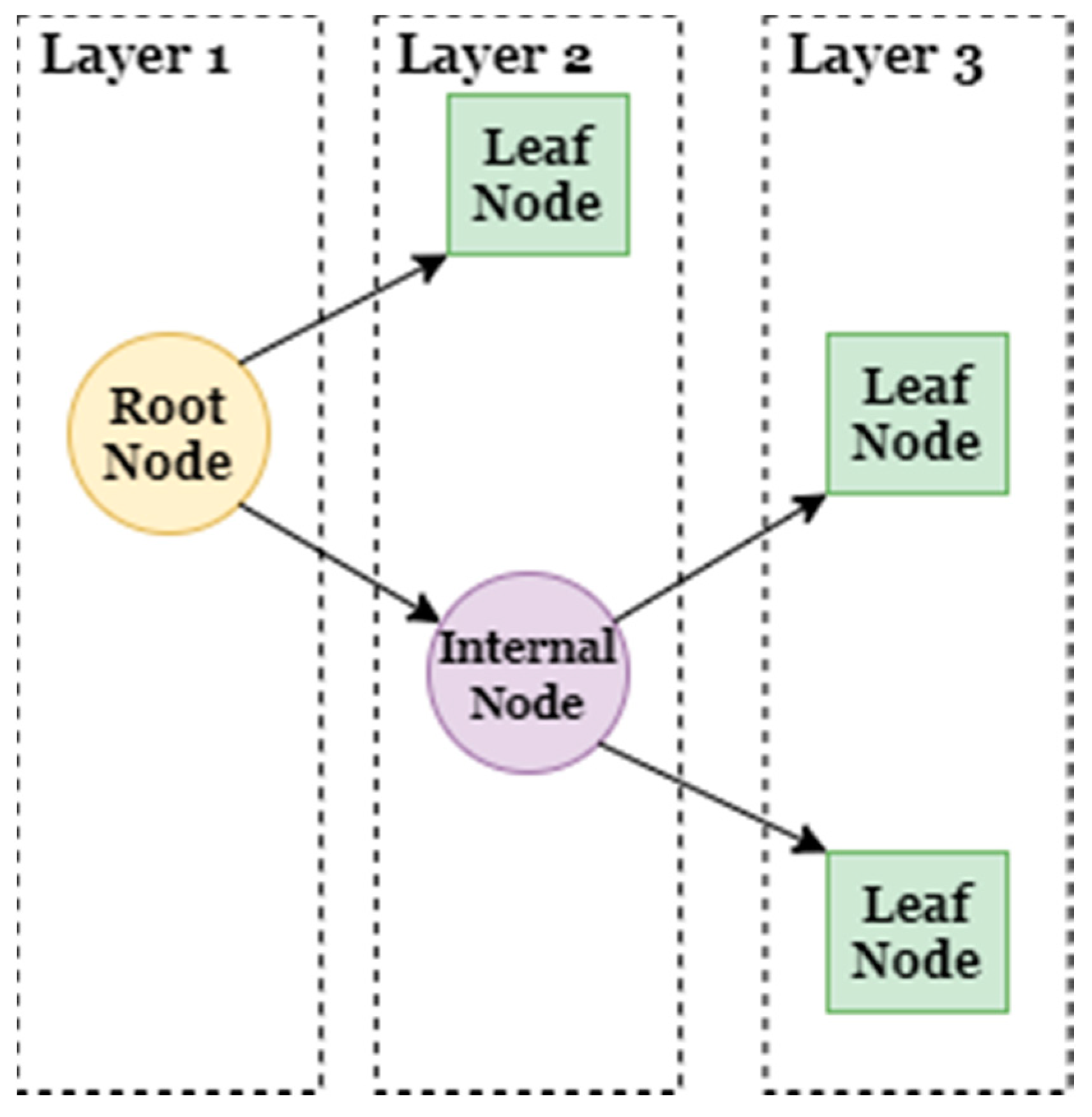
Decision Tree: A decision tree is made of nodes and branches; it is primary used for classification purposes. It sorts the attribute as per their values and groups them together. A node represents an attribute that needs to be categorized, and a branch represents a value taken by a node [
36].
Figure 5 shows the basic architecture of the decision tree [
37].
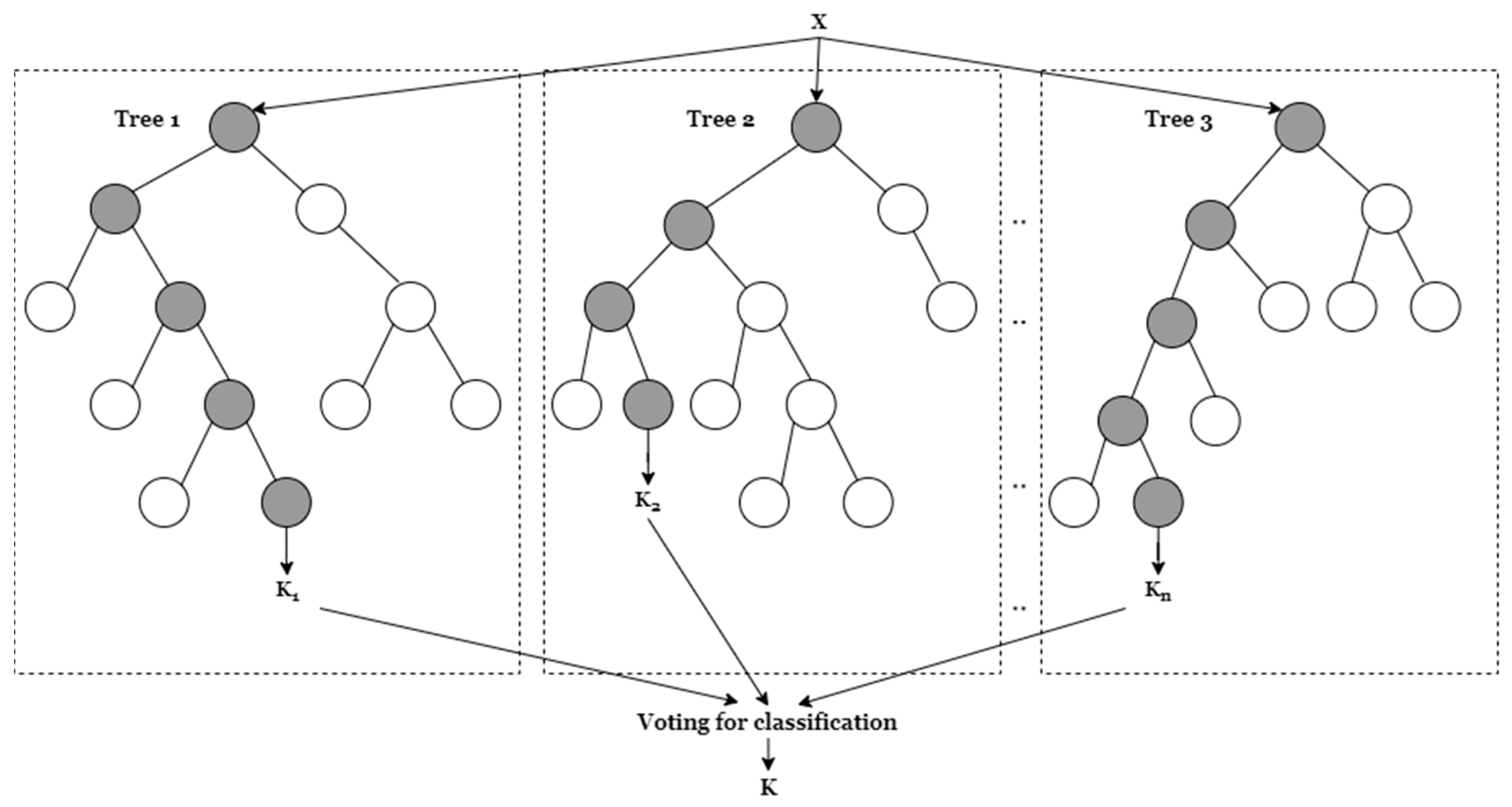
Random Forest: As per the name, a random forest is made of many decision trees employed together for working, resulting in an ensemble. Each tree in a random forest generates class data prediction, depending upon the majority of votes forecast for the model [
38].
Figure 6 shows the basic architecture of random forest [
39].
A further comparative study is performed to identify which model gives maximum accuracy. As mentioned above, different pre-trained models are used in combination with a different algorithm to calculated combined accuracy. By this comparative study, we are able to find out the quickest and most accurate model and algorithm combination for our dataset.
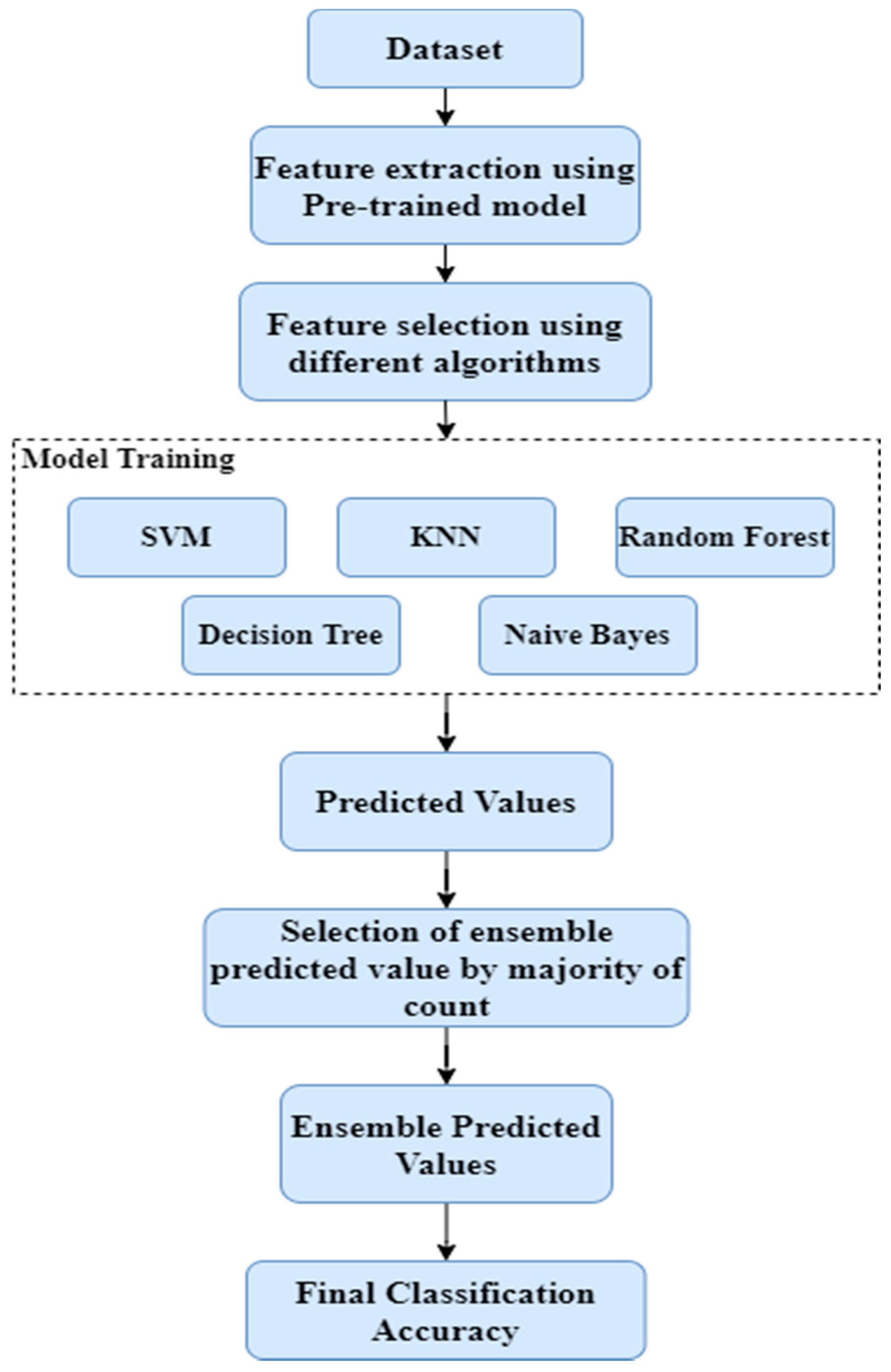
3.3. Ensemble Learning
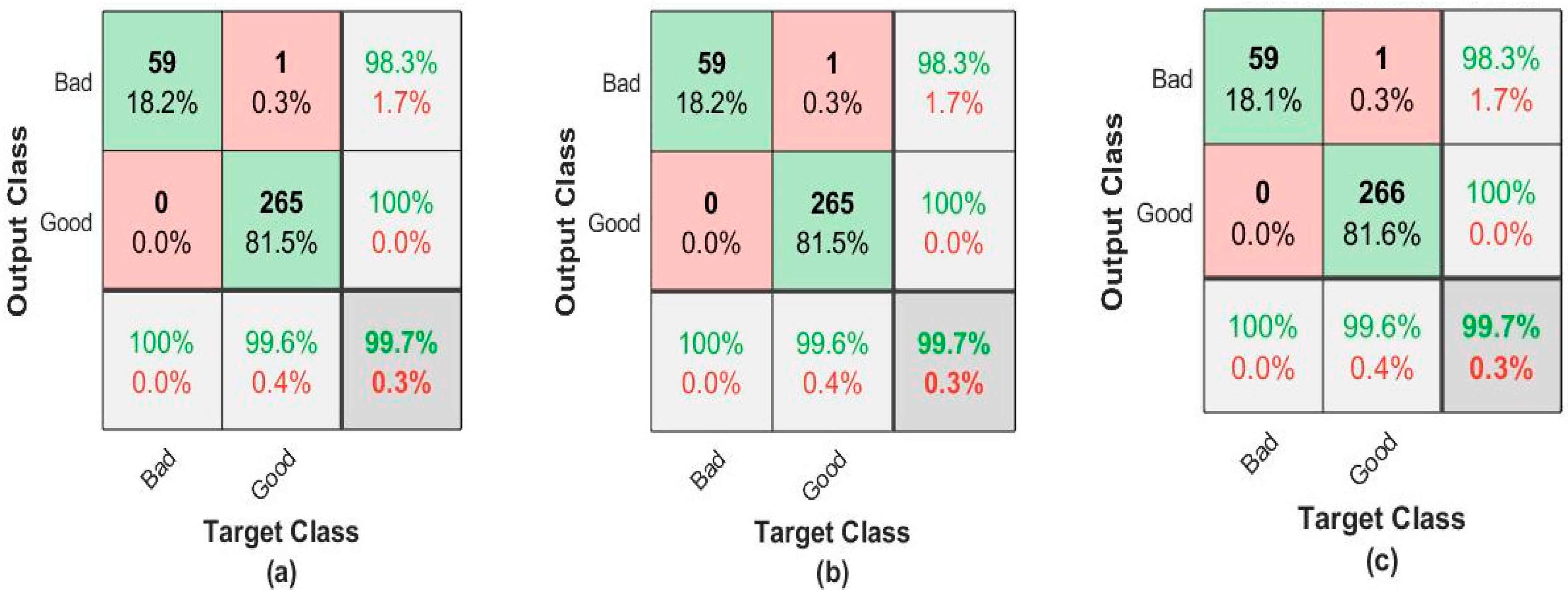
The art of integrating a diverse set of learners (individual models, algorithms) to boost the model’s stability and predictive capacity is known as ensemble learning. It is a powerful tool for improving model efficiency and accuracy. A pre-trained model is an ensemble with different algorithms used to increase model accuracy. In ensemble learning, predictive results obtained by different classification algorithms are compared for count generation. If the count value of the non-defective result (Good) is greater than two out of five, then the ensemble result is selected as non-defective, or else, it is chosen as defective (Bad).
Figure 7 shows the process flowchart of ensemble learning.
3.4. Evaluation Principle
For evaluation of defective and non-defective layers, images are captured of both defective and non-defective layers. After successfully creating a dataset, a dataset is labeled as good and bad. Good for non-defective layer and bad for defective layer. Labeling is done manually as per eye inspection. Errors observed during labeling the dataset are improper filling of material, improper pattern development, and stringing problem. Two different datasets are created for defective and non-defective components, and error detection is carried out for errors observed and occurred.
Figure 8 shows the example of non-defective layers or defect-free layers in the printing process. As shown in
Figure 8, layer-wise images of each layer are captured and labeled accordingly.
Visualization of the defective layer or defect that occurred in the printing layer is shown in
Figure 9. Most defects have occurred in the first and last two to three layers in the component; much less errors are observed in the pattern filling part.
3.5. Density Wise Classification
The study also includes the identification of components based on process parameters. Parameter variation consists of temperature, printing speed, and density but a part to be printed or layers to be printed is the same for temperature and speed variation. Due to this reason, one cannot identify printing components based on these parameters. However, density-wise identification of printed parts is possible. For density-wise classification, again, these pre-trained models are used, but for this time, pre-trained models are used for feature extraction and also for training and testing purposes.
3.6. Pre-Trained Models Used
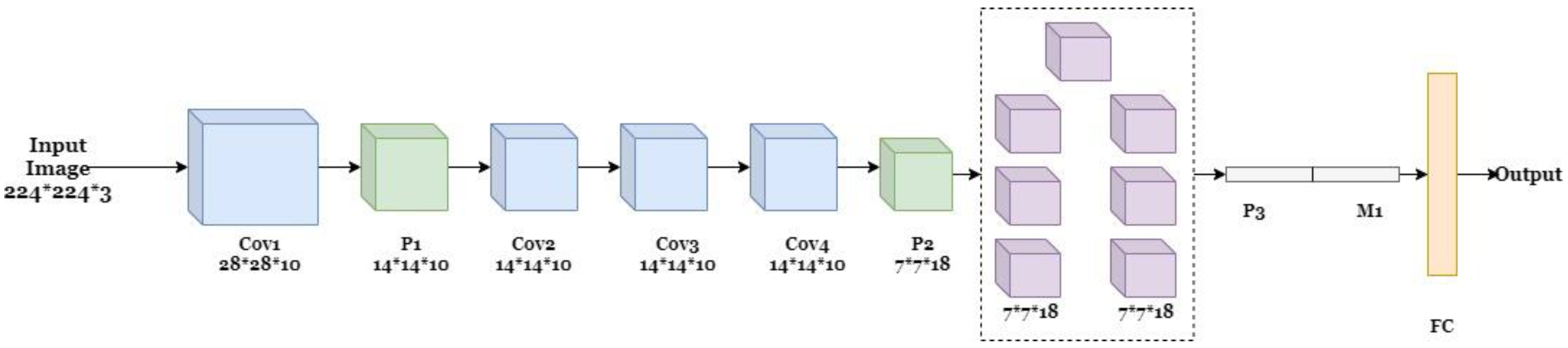
Alexnet: Alexnet is an eight-layer convolutional neural network (CNN) in which the first five layers are convolutional, and the last three are fully connected layers [
40]. It can classify 1000 different classes; the input image size for Alexnet is 227 by 227.
Figure 10 shows the architecture of the pre-trained model Alexnet.
Googlenet: Googlenet is a 22-layer convolutional neural network, the image input size for this network is 224 by 224 [
41]. It can predict classes up to 1000 classes.
Figure 11 shows a simplified block diagram of the Googlenet architecture.
Resnet18: Resnet is a short form for the residual net; it is a classic neural network, and as the name suggests, it is an 18-layer network [
42]. It takes image input size as 224 by 224. It takes an image in the form of Red-Green-Blue (RGB).
Figure 12 shows the architecture of Resnet18.
Resnet50: As the name suggests, it is a 50-layer deep CNN [
43]; the required image input size for this network is also 224 by 224. It has a 1-maxpool layer, 1-average pool layer, and 48 convolutional layers.
Figure 13 shows the basic architecture of Resnet50.
Efficientnet-b0: there are 237 layers in Efficientnet [
44]; it can train a database of up to 1000 classes. The image input size for this network is 224 by 224, and the required format is RGB.
Figure 14 shows the basic architecture of Efficientnet-b0.



 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}