1. Introduction
Named entity recognition (NER) is an important task in natural language processing (NLP) [
1] and information extraction, aiming to identify named entities in text and predict their types. NER serves as a necessary component for various NLP tasks such as relation extraction, syntax parsing, and knowledge question answering. The task provides entity information for these higher-level tasks. However, named entities exhibit subjectivity, complexity, and variability, and the contextual features of named entities are sparse. As a result, NER has always been a challenging research topic in NLP.
For example, in the sentence “李健平常与王林通电话” (“Li Jianping usually talks on the phone with Wang Lin”), under normal circumstances, “李健平” (“Li Jianping”) should be recognized as a person entity, as “李健平” is the subject of the sentence. However, in some special cases, there may exist a person named “李健” (“Li Jian”), and the true meaning of the sentence is that “李健” usually talks on the phone with Wang Lin. In this case, the entity recognition model should identify “李健” as the person entity.
Based on whether entities can overlap in the text, entity recognition can be divided into flat entity recognition and nested entity recognition. In flat entity recognition tasks, entities do not share any overlapping characters. Each character is either an invalid character or belongs to a unique entity. For example, in the text “北京有故宫” (“Beijing has the Forbidden City”), there are only two entities, “北京” (“Beijing”) and “故宫” (“Forbidden City”), and these two entities do not share any characters. Therefore, the entity recognition task for this text can be achieved through a flat entity recognition model. However, in reality, text context is complex, and there may exist nested entities within an entity. For example, in the text “北京大学坐落在海淀区” (“Peking University is located in Haidian District, Beijing”), there are three entities, “北京大学” (“Peking University”), “北京” (“Beijing”), and “海淀区” (“Haidian District”). In this case, the entity “北京大学” contains the nested entity “北京”. Thus, in complex contexts, nested entities occur more frequently, and the entity recognition task for such texts cannot be achieved through a flat entity recognition model. To address this issue, nested entity recognition methods have been developed, allowing various types of entities to exist within an entity. For example, in the aforementioned text “北京大学坐落在海淀区” (“Peking University is located in Haidian District, Beijing”), the organization entity “北京大学” (“Peking University”) contains the location entity “北京” (“Beijing”).
With the emergence of the neural network model AlexNet, deep learning gained significant popularity, and various classic neural network modules were proposed. Along with the popularity of deep learning, many researchers began to focus on deep learning-based models for natural language processing. NER systems based on deep learning have achieved remarkable performance improvement. Many studies have used deep learning models to enhance the feature extraction layer of NER models, allowing them to extract more semantic information from text. Dai et al. [
2] added an attention mechanism to improve the quality of semantic features. Zhang et al. [
3] added deep belief network (DBN) to the entity recognition model, which improved the classification accuracy of the model. Wang et al. [
4] used the BILSTM-CRF model to realize entity recognition, and obtained text timing information through BILSTM. Robert et al. [
5] added a CNN module to improve the local feature extraction capability of the entity recognition model. Therefore, this paper adopts an entity recognition model based on deep learning to implement the nested entity recognition task. As the feature capacity of classical neural network models is insufficient, this paper constructs a deep semantic extraction module called IDCNNLR. To enhance feature quality, this paper incorporates multi-head self-attention mechanisms at multiple positions in the model. Finally, the model predicts nested entities and their categories through the GlobalPointer module. The paper proposes a Chinese nested entity recognition model called BERT-ATT-IDCNNLR-ATTR-GlobalPointer.
Currently, the medical field contains a large amount of information, covering a wide range of content. It is necessary to perform the timely processing of disease, medication, and medical device information. Qi et al. [
6] realized entity recognition of electronic medical records through Multi-Neural Network Fusion. Wang et al. [
7] integrated a knowledge graph and attention mechanism into the entity recognition model to realize entity recognition of Internet medical consultation texts. Tan et al. [
8] used a pre-trained language model to implement entity recognition in clinical medical texts. In real life, text contexts are complex, and commonly used texts like medical data inevitably contain numerous nested entities. To validate the nested entity recognition capability of our model on medical information, the paper selected the CMeEE dataset as the first experimental dataset. The CMeEE dataset is a nested entity recognition dataset for Chinese medical texts, categorizing medical named entities into nine classes: diseases (dis), clinical symptoms (sym), medications (dru), medical equipment (equ), medical procedures (pro), body parts (bod), medical examination items (ite), microorganisms (mic), and departments (dep). By performing nested entity recognition on medical information, medical institutions can efficiently extract useful entities from medical data, thereby accelerating the operational efficiency of medical institutions.
Currently, the content of real-life texts covers a wide range, and a paragraph of text may contain various types of data. To validate the entity recognition capability of our model on everyday life texts, the paper selected the CLUENER2020 dataset as the second dataset. The Chinese fine-grained named entity recognition dataset CLUENER2020 is based on the THUCTC text classification dataset released by Tsinghua University, with a portion of the data selected for fine-grained named entity annotation. CLUENER2020 includes a total of 10 label types: organization, name, address, company, government, book title, game, movie, organization institution, and scenic spot. The “company” and “government” categories are quite similar and both belong to the “institution” category. These two categories are not as easily distinguishable as the “address” and “institution” categories. Therefore, this dataset can verify the model’s ability to differentiate similar fine-grained categories. In entity recognition, the number of entity categories is about ten, and this entity recognition task is called fine-grained entity recognition.
This paper is divided into five chapters: introduction, related work, model, experiments, conclusion, and future work. In terms of structure, the introduction and related work sections first present the current status and significance of nested entity recognition research. Then, the model section describes the specific details of the model. The effectiveness of the model is analyzed through experiments. Finally, the conclusion and future work sections summarize the main contributions of this paper and provide prospects for future research in nested entity recognition.
2. Related Work
Entity recognition methods can be categorized into three types: sequence labeling-based methods, hypergraph-based methods, and span-based methods. Sequence labeling-based methods assign labels to each character in the text to predict the entities and their categories.
Common sequence labeling methods include “BIO” and “BMES” methods. For example, in the “BIO” labeling method, “B-Category” represents the beginning character of an entity, “I-Category” represents the internal characters of an entity, and “O” represents non-entity characters. Early sequence labeling methods assigned only one label to each character, making it impossible to assign corresponding labels to nested entities. To address this issue, researchers have proposed multi-label sequence labeling methods that allow a character to have multiple entity labels. These methods recognize nested entities through the multi-label annotations of characters. To enhance the capability of sequence labeling methods in nested entity recognition, researchers have proposed three strategies: hierarchical, cascaded, and structured (joint labeling) labeling approaches [
9].
The hierarchical approach overlays a flat entity recognition layer based on the hierarchical information of nested entity structures, and multiple hierarchical entity recognition layers are used to recognize nested entities within entities. Ju et al. [
10] dynamically stacked multiple flattened feature extraction layers (BiLSTM+CRF) in the decoding part of entity recognition, and the study uses a hierarchical entity recognition model to recognize nested entities in biomedical texts. However, this stacking approach may introduce error propagation in the model structure, and the data in the model can only be transmitted in one direction, making it unable to utilize the information of outer entities when recognizing inner entities. Wang et al. [
11] proposed a pyramid NER model, which is also constructed based on the hierarchical approach. This model first stacks characters towards entity mentions from bottom to top to obtain the forward pyramid structure of entity mentions, which represents all possible entity fragments in the text. Then, the model decodes the forward pyramid in a reverse hierarchical manner to recognize all nested entities in the text.
The cascaded approach builds a binary classifier for each entity category to predict nested entities and their categories. Shibuya et al. [
12] viewed the label sequence of nested entities as the second-best path within the long entity scope, and iteratively decoded the path from outer to inner layers to extract inner entities. This model used a single-layer CRF as the classifier for each cascade, and the CRF layer predicted the entity category. This method combines the hierarchical and cascaded approaches but also suffers from error propagation between layers, which can affect model performance.
The structured strategy predicts each nested entity separately and assigns a separate character label to each nested entity. This method assigns multiple nested entity character labels to characters in the text. For example, in the text segment “北京大学” (Peking University), the character “北” (“north”) is the first character of both entities “北京” (Beijing) and “北京大学” (“Peking University”), so the character “北” would be labeled as “B-ORG” and “B-LOC”, indicating the first character of an organization entity and a location entity, respectively. Straková et al. [
13] used a BERT layer as the word embedding layer to extract word-level information from the text. The study assigned multiple entity labels to each character in the text and introduced other semantic features such as part-of-speech tags to improve feature quality. However, this model requires a significant amount of human resources to annotate transformations in the corpus and perform complex feature engineering when dealing with nested entities. Additionally, expanding the label set in this way may lead to label sparsity issues and reduce the model’s recognition ability. This is an introduction to the sequence-based approach.
The hypergraph-based approach constructs a hypergraph of a sentence, with each character as a node and the connections between characters as edges, based on the nested entity structure information. This approach performs well in recognizing nested entities and avoids the complexity issue of the structured strategy’s multi-labeling problem. However, in cases where the sentence is too long or there are numerous entity categories, the hypergraph in this approach can become very complex, which can impact model performance. Lu et al. [
14] proposed a hypergraph-based model that utilizes the hypergraph to represent semantic information between characters and performs entity boundary detection and category prediction through hypergraph computation. By processing the sub-hypergraph structure of a sentence, this model can recognize nested entities with infinitely long text fragments. However, this model may identify erroneously nested entities, where one entity is contained within another entity, the boundaries of the two entities do not overlap, and both entities have the same type. In such cases, the model may calculate ambiguous structural representations, leading to incorrect predictions. To address this issue, Wang et al. [
15] introduced a neural segment hypergraph model that obtains distributed feature representations with neural networks. This model reduces the probability of computing ambiguous structural representations but may have longer training and inference times and higher time complexity compared to the previous model. Katiyar et al. [
16] used a recursive neural network to extract features from directed hypergraph representations and constructed an LSTM-based sequence labeling model to learn the hypergraph representation of nested entities in the text. This model performs multi-label predictions on characters during hypergraph construction and uses LSTM module to learn the features of the hypergraph. The model finds the sub-hypergraph with the highest confidence, which represents all nested entities in the text. The hypergraph-based methods can effectively represent and recognize nested entities, reducing the complexity of models that assign multiple labels to a character.
The span-based methods enumerate all possible entity boundaries and then perform recognition and classification on the entity boundaries. Yi et al. [
17] concatenated feature vectors of entity boundaries to obtain entity boundary representations using pre-trained models. These representations were then fed into fully connected layers or a biaffine mechanism for entity classification, thus identifying all nested entities and their types. Building upon the previous research, Sohrab et al. [
18] set a maximum length for entity boundaries and enumerated all possible entity boundaries. The study used a bidirectional LSTM module to extract semantic features from the entity boundaries and predicted and classified the entity boundaries based on their feature vectors, thus recognizing all nested entities and their types in the text. Chen et al. [
19] proposed the NNBA model, which separately extracts the starting and ending boundaries of entities. The model combines the starting and ending boundaries of entities using a forward matching algorithm and predicts and classifies all possible entity boundaries using a final classifier. Lin et al. [
20] used a head-driven phrase structure for nested named entity recognition. Xia et al. [
21] proposed an MGNER neural network model that predicts each possible entity boundary, extracts all nested entities, and then classifies the recognized entities using a classification network module. While these methods can recognize nested entities, they have drawbacks such as high computational cost, insensitivity to boundary information, underutilization of partially matching entity boundary information, and difficulty in identifying entities in long texts. To address these issues, Shen et al. [
22] divided the entity recognition task into two stages: entity boundary filtering and entity category prediction. In the first stage, this method extracts the boundaries of nested entities through filtering and boundary regression of seed spans. In the second stage, the extracted nested entities are classified. This method effectively utilizes the boundary information of entities and partially matching spans during the training process through these two stages.
The span-based approach can also be implemented using pointer networks. Pointer networks can generate variable-length output sequences, breaking the limitation of fixed sequence length in general sequence-to-sequence models. In entity recognition models based on pointer networks, the text is used as input data. The model first predicts the start and end boundaries of entities to obtain entity spans, and then computes the representation of the entity spans to predict the entity types corresponding to the entity boundaries. Zhai et al. [
23] introduced pointer networks in their model to perform sequence chunking and labeling. Li et al. [
24] used GRU neural networks at the feature extraction layer to extract semantic features of the data and used pointer networks to eliminate the ambiguity of entity boundaries. Pointer networks have shown significant effectiveness in handling nested entities. However, in general, pointer networks treat multi-entity extraction tasks as multiple binary classification problems, which may lead to slow convergence when dealing with long sequences. Additionally, adding effective features or incorporating multi-task learning mechanisms can improve the recognition ability of span-based models. Zheng et al. [
25] first extract all possible entity boundaries and then perform boundary detection and entity classification simultaneously. Eberts et al. [
26] utilize a pre-trained Transformer model to jointly perform entity recognition and relation extraction in the span-based approach, and experiments show that pre-trained Transformer modules can enhance model performance. Yuan et al. [
27] proposes a three-affine attention mechanism that incorporates label information into the span-based approach, using the three-affine mechanism to calculate entity scores for recognizing nested entities. This model interacts with both the span boundaries and the entity boundaries, and extends the two-affine mechanism with an additional dimension to obtain the three-affine mechanism. The span boundaries and the embeddings of the spans are used as the query vectors
Q, while the word embeddings of each word within the span are used as the key vectors
K and value vectors
V in the attention mechanism. Compared to the general attention mechanism, this approach facilitates higher-dimensional interactions between
Q and
K. Although this method handles the internal information within spans, the three-affine mechanism introduces an additional dimension compared to the two-affine mechanism, which may result in increased computational overhead when processing entity classification.
In summary, the previous two methods, namely the sequence labeling-based method and the hypergraph-based method, are not sensitive to entity boundary information. These methods may exhibit boundary ambiguity when dealing with nested entities, which affects the extraction of entity boundaries. To address these issues, this paper adopts the span-based method, which processes each potential entity boundary to extract all nested entities. Su et al. [
28] proposed a nested entity recognition module called GlobalPointer in 2022. This module enumerates all potential entity boundaries of the text using upper triangular matrices. Each category has such an upper triangular matrix. The module calculates these matrices to obtain scores for each entity boundary in each category, thereby recognizing all nested entities in the text. However, a single GlobalPointer module may struggle to extract sufficient semantic information to distinguish similar categories in fine-grained entity recognition datasets. Therefore, this paper constructs a deep semantic extraction module called ATT-IDCNNLR-ATTR, which leverages multiple layers of convolution, residual structures, and attention mechanisms to handle complex semantic information in the text and enable the model to extract more semantic information. Finally, this paper proposes a Chinese nested entity recognition model called BERT-ATT-IDCNNLR-ATTR-GlobalPointer, which can extract sufficient semantic information from the text, effectively distinguish similar fine-grained categories, and predict all nested entities and their corresponding entity types.
The innovations of this paper are as follows:
Replacing the classic conditional random field (CRF) of the traditional model with the GlobalPointer module, which is more suitable for nested entity recognition;
Using the classic IDCNN neural network module as the feature extraction layer of the model, optimizing the internal structure of IDCNN, incorporating attention mechanisms at multiple positions, and using residual structures to fuse various features, ultimately constructing a deep semantic extraction module called ATT-IDCNNLR-ATTR;
Creating multiple module combinations for each innovation point of the model and conducting multiple ablation experiments. In total, 20 ablation experiments were performed.
3. Model
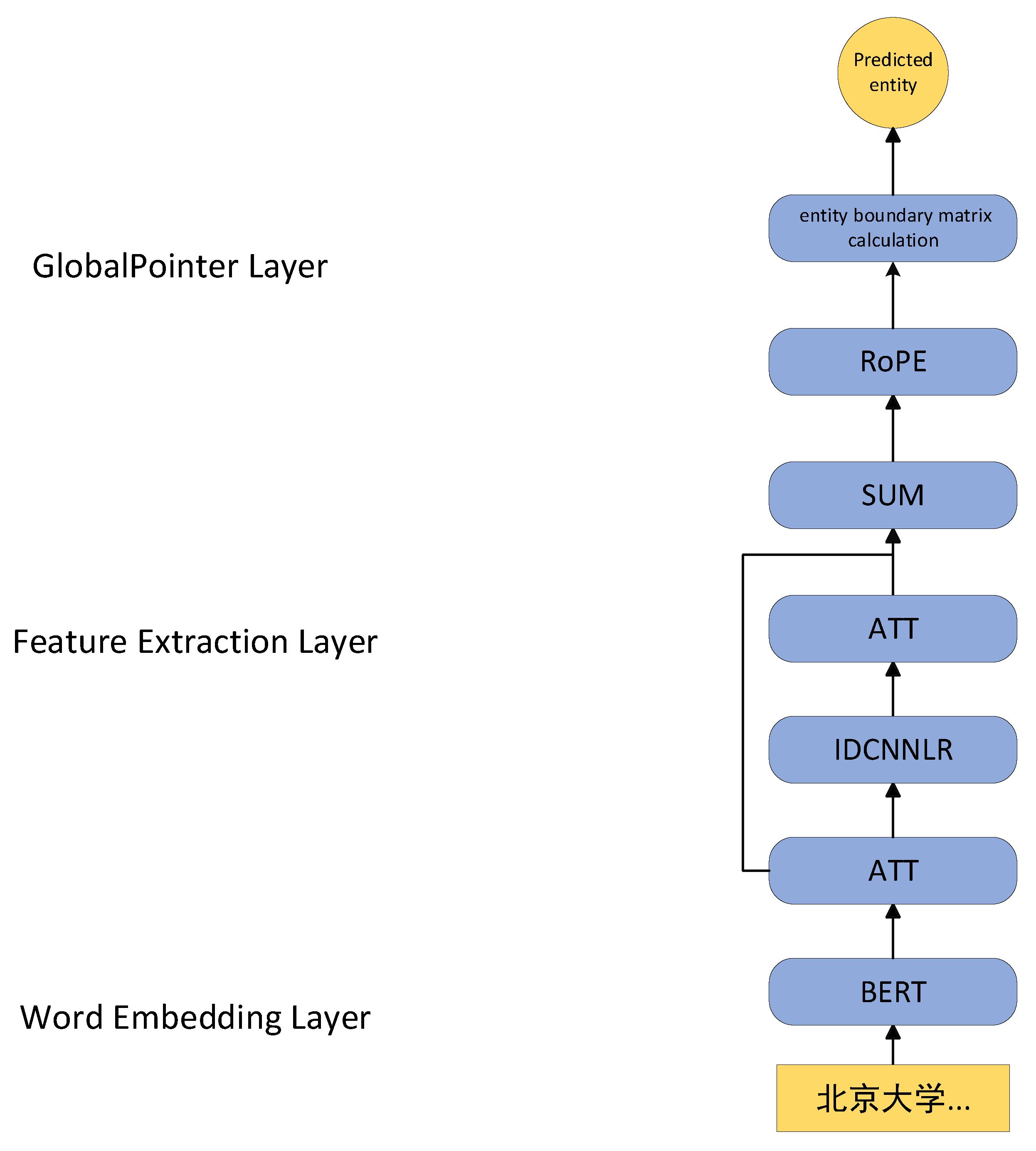
The paper constructs the BERT-ATT-IDCNNLR-ATTR-GlobalPointer Chinese nested entity recognition model. In this model, BERT model is used as the word embedding layer, and data denoising is realized by multi-position multi-head attention mechanism. In order to improve the semantic extraction ability of the model, the paper constructs a deep semantic extraction module IDCNNLR, which extracts features through multi-layer convolution and fuses features of different levels to obtain richer features. In this model, position information is added to feature vectors by rotating position coding. The model uses the GlobalPointer module as the output layer to predict nested entities by calculating the entity boundary matrix. The overall frame diagram of the model in the paper is shown in
Figure 1. The round block represents the entity predicted by the model, the rectangle represents the input text, and the rounded rectangle represents the module. In
Figure 1, “北京大学… “(“ Peking University.”) is the input text instance of the model.
3.1. BERT
The first step in entity recognition is to convert the text into word vectors that can be used for numerical computations. In deep learning, there are generally two main methods for converting word vectors, namely word embedding layers and the BERT model. Both methods extract the semantic information of a word based on its surrounding context. For example, in the text “北方有许多城市,如北京市、石家庄市和哈尔滨市” (“There are many cities in the north, such as Beijing, Shijiazhuang, and Harbin”), the word “石家庄市” (“Shijiazhuang City”) can be inferred as a word related to cities based on the surrounding words “北京” (“Beijing City”) and “哈尔滨市” (“Harbin City”). To enhance the ability to extract semantic information of a specific word from its surrounding context, the BERT model uses a masked language model task for pre-training. The masked language model task randomly masks some vocabulary, and the model predicts the masked words by considering the context of the masked words, thereby improving the model’s ability to extract semantic information from each position. Sometimes, relying solely on the surrounding words may be insufficient to extract the true semantic information of a specific word. For example, in the two texts “You came too early today” and “You came too late today”, the context of the words “early” and “late” is exactly the same, but their semantics are completely opposite. In such cases, the word embedding layer, which relies on the surrounding words to extract the semantic information of a specific word, may struggle to capture the correct semantics of the specific word. To address this issue, the BERT model incorporates the next sentence prediction task to enhance the model’s perception of semantic relationships between sentences. The next sentence prediction task selects one sentence as the previous sentence and randomly selects the next sentence of that sentence as the next sentence with a probability of 50%. The model predicts whether these two sentences are consecutive. Through the next sentence prediction task, the model can better perceive the semantic connections between sentences. In summary, this paper adopts the BERT model as the word embedding layer of the proposed model, leveraging the BERT model to extract more semantic information from the text and improve the quality of word vectors. The pre-training file name used for the BERT model in this paper is bert-base-chinese.
3.2. Multi-Head Self-Attention Mechanism
Attention mechanism is a method that emphasizes important information in data. By using the attention mechanism, the model can enhance its perception of important information and extract more semantic information. For example, in the task of entity recognition, in the text “Peking University is located in Haidian District, Beijing”, the word “in” is a preposition that often does not carry much actual meaning. The model can utilize the attention mechanism to identify that “in” is likely not an important character for entity recognition and assign it a lower weight during computation, thereby weakening the contribution of non-important information. The attention mechanism highlights the semantic information of important characters, improving the quality of data features.
In deep learning, attention mechanisms can be categorized into three types: global attention mechanism, local attention mechanism, and self-attention mechanism. A character in the text has a certain semantic correlation with other characters, and this character can represent more semantic information of the text. The self-attention mechanism improves the weight of characters that have strong correlations with other characters, thereby increasing the semantic information of features. The attention score in the self-attention mechanism is obtained through matrix multiplication between key vectors and query vectors, where the attention score represents the similarity between each position element of the key vector and the query vector. The matrix product of the query vector and the key vector is matrix multiplication. The higher the similarity between a character and other characters, the stronger the semantic correlation the character has with all the characters in the text. As a result, the character can express more semantic information of the text, and it will have a larger value in the attention score matrix, indicating the character has higher weight and more semantic information in the feature vector. For example, in the text “中国有56个民族,包括汉族、满族和回族” (“There are 56 ethnic groups in China, including Han, Manchu and Hui”), there are four entities representing ethnic groups: “汉族” (“Han nationality”), “满族” (“Manchu”), “回族” (“Hui nationality”) and “民族” (“nation”). The character “族” appears in all four entities, indicating a high probability of being an entity character. The attention mechanism assigns a higher weight to the character “族”, increasing the model’s focus on this character. As a result, the model can recognize more entities that contain the character “族” and represent ethnic groups, such as “维吾尔族” (“Uighur nationality”) and “苗族” (“Miao nationality”).
In summary, the attention mechanism enhances the quality of data features by emphasizing important information. It can be categorized into a global attention mechanism, local attention mechanism, and self-attention mechanism. Unlike the other two attention mechanisms, the self-attention mechanism improves the weight of characters with strong correlations, allowing the model to extract more semantic information.
The self-attention mechanism calculates attention scores based on the matrix computation of feature vectors themselves, providing global attention scores for the text. However, the single-head self-attention mechanism has limited dimensions in processing data, leading to insufficient extraction of semantic information. Liao et al. [
29] introduced the multi-head self-attention mechanism to solve the problem that military named entity recognition requires a lot of domain specific knowledge. Therefore, in this paper, the single-head self-attention mechanism is replaced with the multi-head self-attention mechanism to enhance the perception of semantic connections between characters. The multi-head self-attention mechanism changes the dimensions of key, value, and query vectors compared to the single-head self-attention mechanism. The last dimension of the feature vectors is divided into
head_num parts, adjusting the feature vector dimension from (
batch_size,
seq_size,
word_embedding_size) to (
batch_size,
seq_size,
word_embedding_size/8). This mechanism splits a feature vector into multiple groups on the corresponding dimension of the word vectors, perceiving the semantic connections between characters from more dimensions.
batch_size is the batch size during training,
seq_len is the text sequence length, and
word_embedding_size is the dimension of the word vector.
The workflow of the multi-head attention mechanism is as follows. Firstly, the feature vectors undergo dimension transformation to obtain multiple sets of feature vectors. In this paper, the key
k, value
v, and query vectors
q in the attention mechanism are all feature vectors from the input. The key
k, value
v, and query vectors
q pass through their respective fully connected layers to obtain three new feature vectors:
qall,
kall, and
vall. These three new feature vectors undergo internal computations within the attention mechanism to obtain the output vectors
hi for each attention head. These attention head outputs
hi are concatenated in the last dimension in sequence to obtain the overall output vector
hall. Finally, the output vector goes through fully connected layers, dropout layers, and layer normalization to obtain the final output vector
hlast. The calculation formulas are shown in Equations (1) and (2). The internal structure of the multi-head attention mechanism is shown in
Figure 2. In
Figure 2, the yellow circular icon represents the feature vector in data transmission, and the blue rounded rectangle represents the feature processing layer.
3.3. IDCNNLR
There has been numerous research on entity recognition based on Bidirectional LSTM (BiLSTM), which can extract more sequential information to capture the semantic relationships between words. Wei et al. [
30] used BILSTM to extract the time sequence information of texts and built a BERT-BILSTM-CRF entity recognition model to realize entity recognition of texts in educational emergencies. Yang et al. [
31] add BILSTM and Transformer to the entity recognition model. These two modules improve the semantic extraction capability of the feature extraction layer. However, BiLSTM cannot fully utilize the computational power brought by GPU parallelism, thus being unable to significantly improve the model performance. Each step of the CNN calculation is relatively independent for the GPU, and each step of the CNN calculation can be carried out at the same time, so as to achieve parallel computing. Because of the different calculation methods, LSTM and other modules do not have this feature. CNN has also been widely applied in entity recognition research, as it possesses strong capabilities in extracting local features to capture the semantic relationships between words. Since CNN can only extract local semantic information, many studies increase the depth of the CNN network to extract broader semantic information, which may lead to overfitting issues. Pooling layers have been used to aggregate text information from multiple convolution scales, which can lead to the loss of necessary information. To address these challenges, Strubell et al. [
32] proposed an Induced Dilated Convolutional Neural Network (IDCNN). IDCNN replaces the ordinary CNN with dilated convolutions, enlarging the receptive field of the convolution kernels without changing the number of model parameters. This allows the convolutional layers to learn global semantic information from the text.
The internal structure of the IDCNN model is four layers of DCNN, where each DCNN layer contains two standard convolutions and one dilated convolution with a dilation value of 2. Before each convolutional layer, the LeakyReLU function is applied to ensure that the input data remains within an appropriate range. Following the activation function layer, a Layer Normalization (LayNorm) layer is added to prevent the gradient vanishing problem after several convolutional layers. The internal structure of DCNN is shown in
Figure 3. The convolutional layers of DCNN are one-dimensional, and the data is propagated forward through four layers of DCNN sequentially. IDCNN swaps the second and third dimensions of the input data and then swaps them again to obtain the output vector.
The paper improved the internal structure of the classical module IDCNN and obtained IDCNNLR module. Compared with IDCNN module, the extraction capability of IDCNNLR module has been enhanced to some extent. The data is sequentially propagated forward through four layers of DCNN of the IDCNN model, and these layers extract text features at different depths. IDCNNLR module does residuals summation of the output features for four layers of DCNN, and obtains the fusion features at different text depths. The information contained in features at different depths is non-overlapping, and fusing features from different depths provides the model with more semantic information. The internal structure of IDCNNLR is shown in
Figure 4.
The ReLU activation function can address the gradient vanishing problem in LSTM. It sets the gradient of negative input to 0, preventing the update of these parameters, and sets the gradient of positive input to 1, allowing the update of data gradients, ensuring that the model parameters are not difficult to update with low gradients. However, ReLU sets the gradient of negative values to 0, making it difficult for negative values to be updated, resulting in suboptimal training performance. To address this issue, IDCNNLR replaces the ReLU activation function with the LeakyReLU activation function. The LeakyReLU function is based on the ReLU activation function but changes the gradient of negative values to a positive parameter, typically set to 0.01. Through ablation experiments in subsequent chapters, it is concluded that replacing the ReLU function with the LeakyReLU function in the model leads to improved performance.
3.4. GlobalPointer
Research on flat entity recognition has been extensive, and many flat entity recognition models have achieved high performance on multiple flat entity recognition datasets. Yin et al. [
33] proposed a Multi-criteria Fusion Model, which has achieved excellent experimental results on the flat entity recognition dataset MSRA. Cao et al. [
34] constructed a Bert-MRC-Biaffine entity recognition model, which has achieved excellent experimental results on the flat entity recognition dataset CCKS2017. These flat entity recognition datasets are characterized by the fact that each text fragment can represent only one entity, and entities cannot share the same characters. However, in a complex context, one entity may contain another entity, which is impossible in a flat entity recognition dataset. It is necessary to evaluate the capability of entity recognition models with nested entity recognition datasets. In real life, nested entities are quite common. For example, in the text segment “北京大学” (“Peking University”), the text segment “北京大学” is an organizational entity, and the text segment “北京” (“Beijing, China”) is a location entity. These two entities overlap in the text segment “北京大学”. The annotation method based on individual character labels alone cannot identify multiple overlapping entities. To address this issue, Su et al. proposed a nested entity recognition model called GlobalPointer, which considers all entity boundaries in the text. The model constructs a score matrix for entity boundaries to calculate the scores of entity boundaries for different categories, predicting the nested entities and their types in the text.
The GlobalPointer module first splits the input feature vectors into two equally sized feature vectors
q and
k in the last dimension and adds positional encoding information using RoPE [
35]. The two feature vectors
q and
k undergo multiple steps of multidimensional matrix multiplication to obtain the raw score matrix of entity boundaries
Logitsfirst. The module uses masking matrix to discard the entity boundary that exceeds the length of the sequence, eliminates invalid entity boundary from the lower triangular matrix, and finally obtains the score matrix of entity boundary
Logitsfinal. The score matrix contains confidence scores for each entity boundary in each category, and the model predicts nested entities and their entity types based on these confidence scores.
The RoPE (Rotation Positional Encoding) method incorporates positional information into the feature vectors. The working principle of RoPE is to first calculate the position embedding vectors
pos_emb based on the size of the feature vectors
q and
k. The odd-indexed and even-indexed data of the embedding vectors
pos_emb are separately extracted, and each element is duplicated in its original position, resulting in sine positional vectors
possin and cosine embedding vectors
poscos. The feature vectors
q and
k are split into odd-indexed and even-indexed data, respectively, which are then concatenated to obtain new feature vectors
q2 and
k2. The original eigenvector takes the matrix product of the sinusoidal embedding vector
possin, the new eigenvector takes the matrix product of the cosine embedding vector
poscos, and the sum of the two product results is the final eigenvector containing the sum of the position information
qw and
kw. The calculation formulas of
qw and
kw are shown in Equations (3) and (4).
5. Conclusions and Future Work
In real-life scenarios, text context can be complex, and texts such as medical information and daily expression often contain a large number of nested entities. The task of nested entity recognition in complex text is an important challenge. Improving the model’s ability to recognize nested entities can enhance the processing speed of organizations, such as medical institutions, in handling large volumes of textual data. Enhancements to nested entity recognition models are also crucial for the development of knowledge graphs. The identified nested entities and entity categories can serve as knowledge for downstream tasks such as knowledge fusion and reasoning within the knowledge graph. Improving the entity recognition capability in each knowledge graph task can reduce error propagation from the entity recognition stage and improve the performance of each downstream task.
Currently, there is relatively limited research on nested entity recognition in Chinese, with most Chinese entity recognition studies focusing on flat entity recognition tasks. General flat entity recognition models, such as sequence labeling-based models, cannot handle the recognition of nested entities in text. To address this issue, our model adopts the GlobalPointer module to handle potential entity boundaries and extract nested entities from the text. Classical entity recognition models lack sufficient feature extraction capabilities to capture deep semantic relationships between nested entities. To tackle this problem, our model incorporates the BERT model as the word embedding layer to extract word-level semantic information. It also employs a combination of the multi-position multi-head attention mechanism and the semantic extraction module, IDCNNLR, to extract more semantic information from the text. Experimental results demonstrate that the GlobalPointer module exhibits certain effectiveness in handling nested entities. With a combination of BERT layers, attention mechanisms, and IDCNNLR modules, our model can capture deeper semantic information between nested entities, thereby improving recognition performance. In summary, the future work of Chinese nested entity recognition is prospected as follows in this chapter.
In the future, further improvements to the IDCNNLR module can be made by incorporating more complex network structures. Stronger semantic extraction modules enable the model to capture deeper semantic features, thereby enhancing overall performance. The optimization of the GlobalPointer module can be explored to improve the model’s ability to compute entity boundaries.








{kind=link}
{kind=link}
{kind=link}
{kind=link}