



Fuel Type Mapping Using a CNN-Based Remote Sensing Approach: A Case Study in Sardinia


Abstract
:1. Introduction
2. Dataset Definition
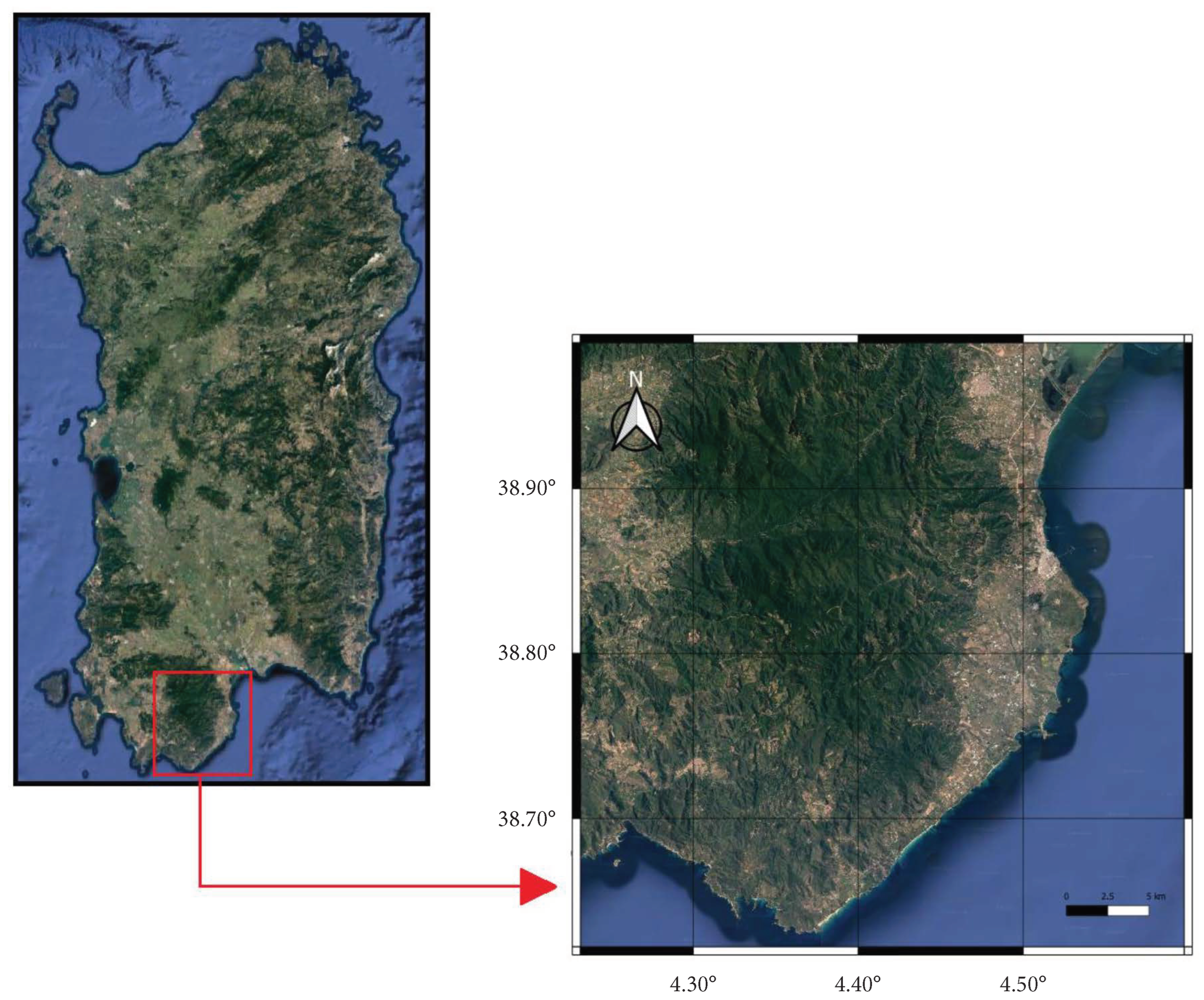
2.1. Area of Interest
2.2. Sentinel Data
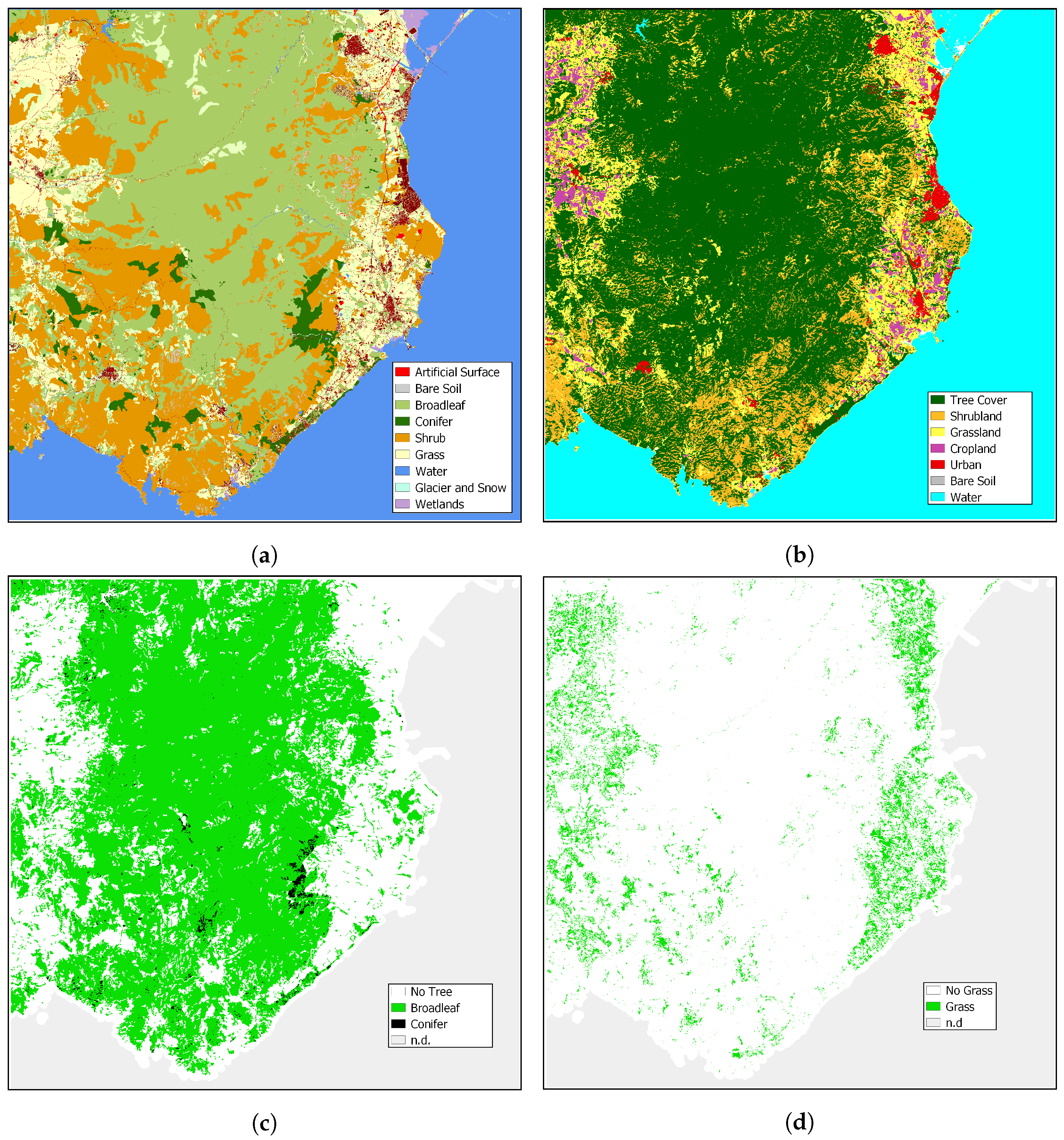
2.3. Ancillary Maps
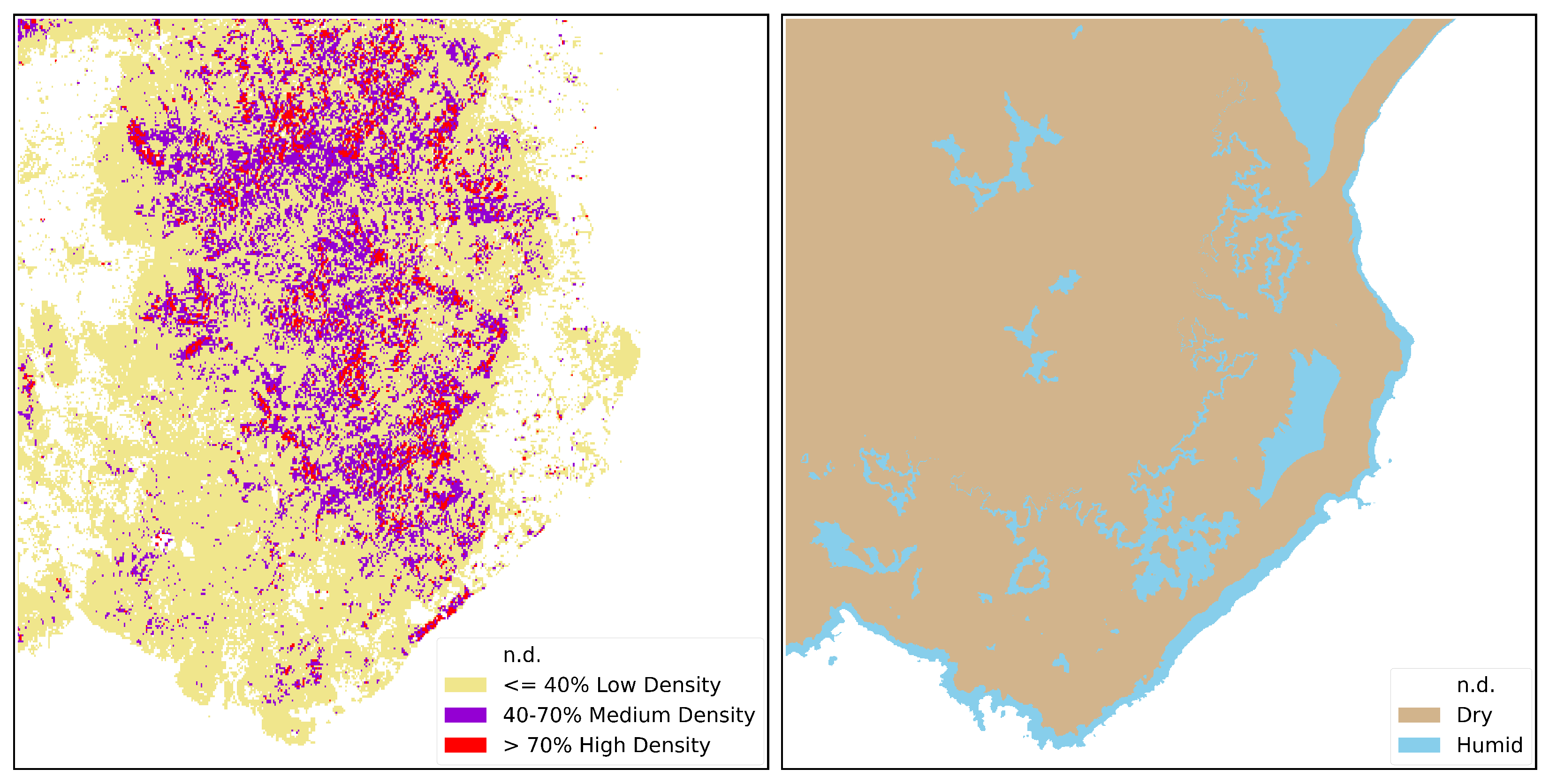
- The Above-Ground Biomass Map represents the total mass of living vegetation per unit area, typically expressed in metric tons per hectare (unit: tons/ha). The AGB map used in this study was obtained from the European Space Agency’s (ESA’s) Climate Change Initiative (CCI) program [46], which is an ESA project to provide long-term, high-quality climate data records to support climate change research and related applications (the AGB map can be downloaded for free at this link: https://data.ceda.ac.uk/neodc/esacci/biomass/data/agb/maps, accessed on 25 May 2023). The AGB map of ESA exhibits a continuous range of values; however, in this work, the biomass values are normalized as percentages relative to the maximum value. Subsequently, the AGB map is divided into three macrogroups based on the following percentage thresholds: the first group includes all values below 40%, the second group encompasses values between 40% and 70%, and the third group includes values exceeding 70%. This is performed to facilitate analysis and align with the Scott and Burgan fuel type classification. Indeed, this approach allowed us to establish a direct correlation between the biomass percentages and the Scott and Burgan fuel type classification, specifically the distinction between low, medium, and high forest density. Furthermore, due to the initial resolution of the raster being 100 m, it was imperative to rescale the map to a finer resolution of 10 m. This resampling process was performed using QGIS software, ensuring the preservation of relevant spatial information and maintaining data integrity throughout the analysis. The post-processed AGB map is shown on the left side of Figure 3, where the three main classes mentioned above are reported. As expected from the RGB image in Figure 1, a predominant representation of classes below the 70 percent threshold is observed, indicating a dense vegetation cover exclusively in the most remote regions of the study area, specifically the peaks located within the inner mountains. On the contrary, the remaining portion of the region of interest predominantly consists of agricultural fields, grasses, or sparsely forested areas. This finding emphasizes the crucial importance of incorporating the use of this map, as it clearly reveals the pronounced disparity in land cover composition and illuminates the unique ecological features present in the study area.
- The Climate Map is derived from the BC map of Sardinia that was developed through a collaboration among several institutions:
- –
- ARPAS—the Regional Agency for Environmental Protection of Sardinia (Agenzia Regionale per la Protezione dell’Ambiente della Sardegna)—Meteoclimatic Department, Sassari: ARPAS is the regional agency responsible for environmental protection in Sardinia. Their Meteoclimatic Department contributed to data collection.
- –
- University of Sassari, Department of Natural and Territorial Sciences, Sassari: the Department of Natural and Territorial Sciences at the University of Sassari provided scientific expertise and knowledge in the field of environmental sciences.
- –
- University of Basilicata, School of Agricultural, Forestry, Food, and Environmental Sciences, Potenza: The University of Basilicata contributed with their expertise in the fields of agricultural, forestry, food, and environmental sciences.
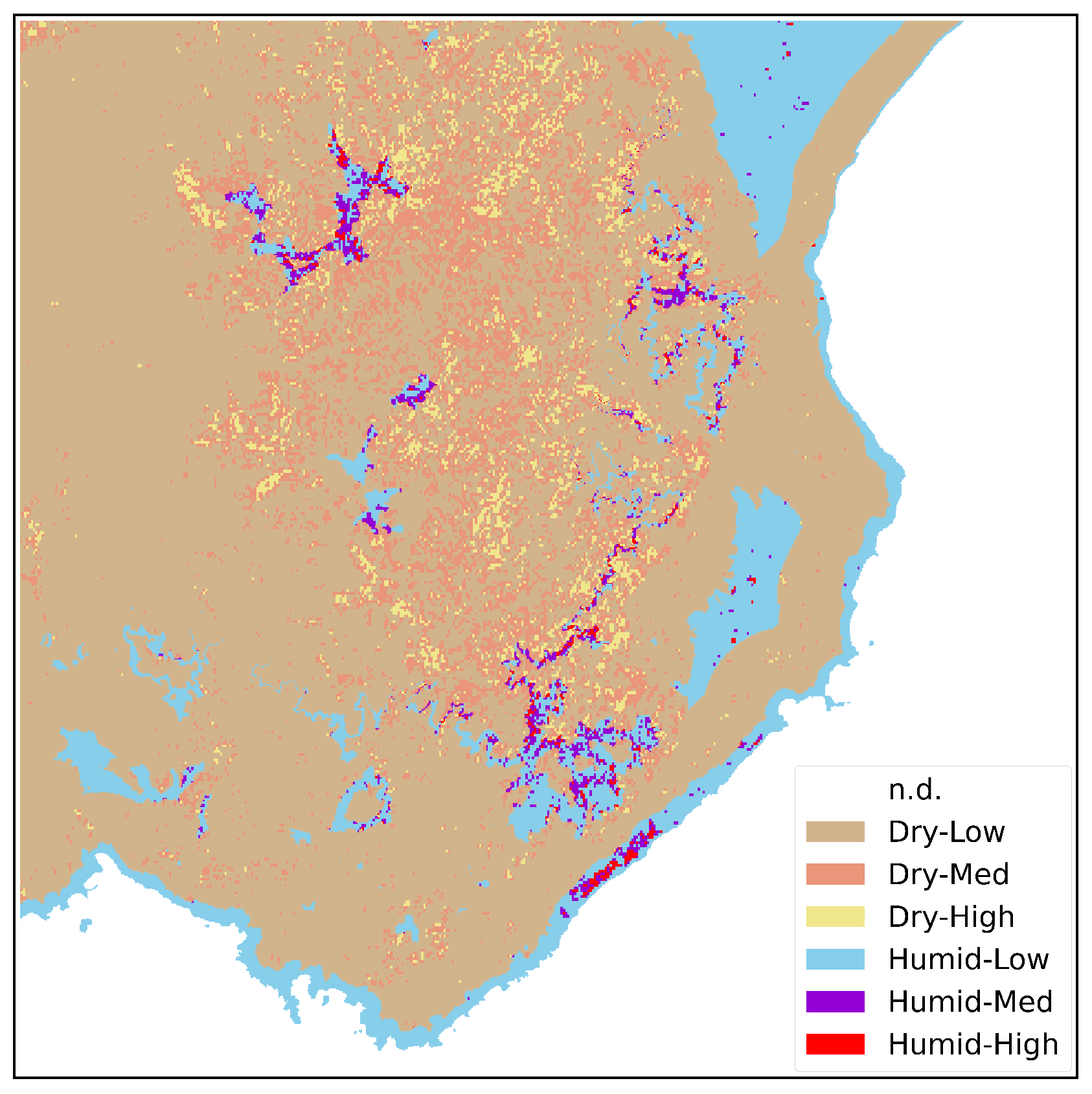
Through the synergy among these institutions, it was possible to create the BC map of Sardinia, an important tool for understanding and studying the climates and biodiversity of the island [47]. The BC map represents the final stage of processing, achieved through the overlay of multiple layers such as Macrobioclimates, Phytoclimatic Plans, Ombrothermal Index, and Continentality Index. This intricate overlay generates a new layer that encompasses diverse combinations of bioclimatic values for each polygon. The resulting BC map comprises 43 classes of Isobioclimates, reflecting the detailed classification approach employed to capture the intricate characteristics of Sardinia’s terrain. These 43 classes span a range of climate levels, encompassing dry, subhumid, humid, and hyperhumid conditions. Therefore, our focus lies on the subset of classes among the 43 available, specifically those that belong to one of the four predefined categories. By focusing on these, we generate a simplified map comprising two distinct macrogroups, categorized as follows: (1) “Dry”, encompassing all the dry classes, and (2) “Humid”, encompassing the remaining classes (subhumid, humid, and hyperhumid). The climate map carried out with this approach is reported on the right side of Figure 3.


2.4. Scott and Burgan Fuel Model
3. Method
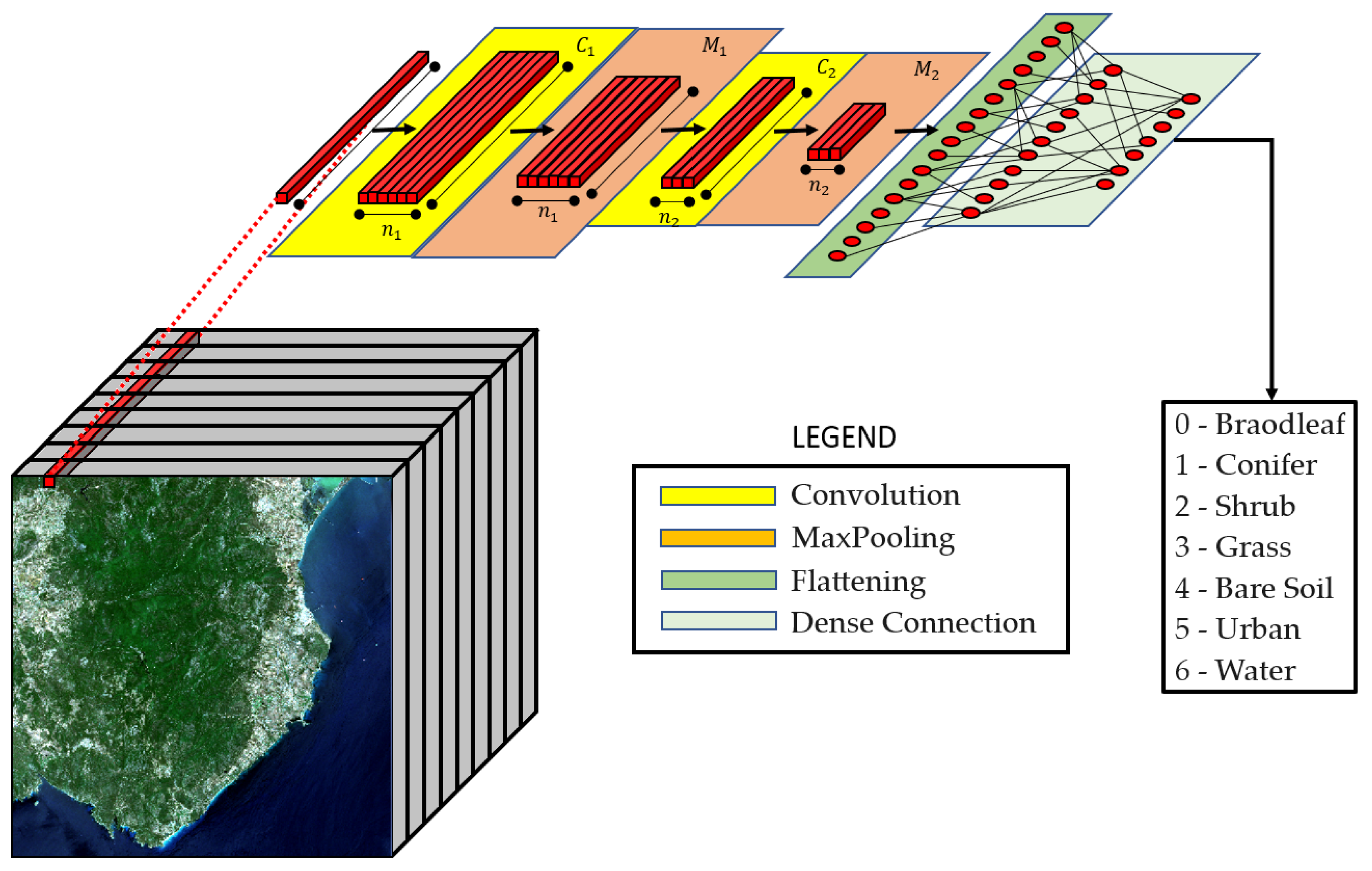
3.1. CNN Architecture
3.2. CNN-Based Unmixing
- If the highest probability is above 60%, assign the pixel to the correspondent class.
- If the highest probability is below 60%, the second highest probability is above 20%, and the third highest probability is below 20%, assign the pixel to the two classes corresponding to the first two highest probabilities.
- If the highest probability is below 60%, and both the second and the third highest probabilities are above 20%, assign the pixel to the three classes corresponding to the first three highest probabilities.
- If the highest probability is below 60% and all other probabilities are below 20%, assign the pixel only to the highest probabilities.
3.3. CNN Test on Sardinia
3.4. Fuel Map Adaptation
4. Results
4.1. Performances of CNN Classification
4.1.1. Model Accuracy
4.1.2. CNN Test and Comparative Analysis with RF and SVM
4.2. Fuel Map Generation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- McCaffrey, S. Thinking of wildfire as a natural hazard. Soc. Nat. Resour. 2004, 17, 509–516. [Google Scholar] [CrossRef]
- Bowman, D.M.; Balch, J.; Artaxo, P.; Bond, W.J.; Cochrane, M.A.; D’antonio, C.M.; DeFries, R.; Johnston, F.H.; Keeley, J.E.; Krawchuk, M.A.; et al. The human dimension of fire regimes on Earth. J. Biogeogr. 2011, 38, 2223–2236. [Google Scholar] [CrossRef] [PubMed]
- Knorr, W.; Arneth, A.; Jiang, L. Demographic controls of future global fire risk. Nat. Clim. Chang. 2016, 6, 781–785. [Google Scholar] [CrossRef]
- Pausas, J.G.; Keeley, J.E. A burning story: The role of fire in the history of life. BioScience 2009, 59, 593–601. [Google Scholar] [CrossRef]
- Eva, H.; Lambin, E.F. Fires and land-cover change in the tropics: A remote sensing analysis at the landscape scale. J. Biogeogr. 2000, 27, 765–776. [Google Scholar] [CrossRef]
- Cano-Crespo, A.; Oliveira, P.J.; Boit, A.; Cardoso, M.; Thonicke, K. Forest edge burning in the Brazilian Amazon promoted by escaping fires from managed pastures. J. Geophys. Res. Biogeosci. 2015, 120, 2095–2107. [Google Scholar] [CrossRef]
- Shaik, R.U.; Periasamy, S.; Zeng, W. Potential Assessment of PRISMA Hyperspectral Imagery for Remote Sensing Applications. Remote Sens. 2023, 15, 1378. [Google Scholar] [CrossRef]
- Congalton, R.G. Remote Sensing: An Overview. GISci. Remote Sens. 2010, 47, 443–459. [Google Scholar] [CrossRef]
- Navalgund, R.R.; Jayaraman, V.; Roy, P. Remote sensing applications: An overview. Curr. Sci. 2007, 93, 1747–1766. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Camps-Valls, G. Machine learning in remote sensing data processing. In Proceedings of the 2009 IEEE International Workshop on Machine Learning for Signal Processing, Grenoble, France, 1–4 September 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- Scheunders, P.; Tuia, D.; Moser, G. Contributions of machine learning to remote sensing data analysis. In Data Processing and Analysis Methodology; Liang, S., Ed.; Comprehensive Remote Sensing; Elsevier: Amsterdam, The Netherlands, 2018; pp. 199–243. [Google Scholar] [CrossRef]
- Chrysafis, I.; Damianidis, C.; Giannakopoulos, V.; Mitsopoulos, I.; Dokas, I.M.; Mallinis, G. Vegetation Fuel Mapping at Regional Scale Using Sentinel-1, Sentinel-2, and DEM Derivatives—The Case of the Region of East Macedonia and Thrace, Greece. Remote Sens. 2023, 15, 1015. [Google Scholar] [CrossRef]
- Ensley-Field, M.; Shriver, R.K.; Law, S.; Adler, P.B. Combining Field Observations and Remote Sensing to Forecast Fine Fuel Loads. Rangel. Ecol. Manag. 2023, 90, 245–255. [Google Scholar] [CrossRef]
- D’Este, M.; Elia, M.; Giannico, V.; Spano, G.; Lafortezza, R.; Sanesi, G. Machine Learning Techniques for Fine Dead Fuel Load Estimation Using Multi-Source Remote Sensing Data. Remote Sens. 2021, 13, 1658. [Google Scholar] [CrossRef]
- Santos, F.L.; Couto, F.T.; Dias, S.S.; de Almeida Ribeiro, N.; Salgado, R. Vegetation fuel characterization using machine learning approach over southern Portugal. Remote Sens. Appl. Soc. Environ. 2023, 32, 101017. [Google Scholar] [CrossRef]
- Aragoneses, E.; Chuvieco, E. Generation and Mapping of Fuel Types for Fire Risk Assessment. Fire 2021, 4, 59. [Google Scholar] [CrossRef]
- Shaik, R.U.; Laneve, G.; Fusilli, L. An automatic procedure for forest fire fuel mapping using hyperspectral (PRISMA) imagery: A semi-supervised classification approach. Remote Sens. 2022, 14, 1264. [Google Scholar] [CrossRef]
- Maniatis, Y.; Doganis, A.; Chatzigeorgiadis, M. Fire Risk Probability Mapping Using Machine Learning Tools and Multi-Criteria Decision Analysis in the GIS Environment: A Case Study in the National Park Forest Dadia-Lefkimi-Soufli, Greece. Appl. Sci. 2022, 12, 2938. [Google Scholar] [CrossRef]
- García, M.; Riaño, D.; Chuvieco, E.; Salas, J.; Danson, F.M. Multispectral and LiDAR data fusion for fuel type mapping using Support Vector Machine and decision rules. Remote Sens. Environ. 2011, 115, 1369–1379. [Google Scholar] [CrossRef]
- Alipour, M.; La Puma, I.; Picotte, J.; Shamsaei, K.; Rowell, E.; Watts, A.; Kosovic, B.; Ebrahimian, H.; Taciroglu, E. A Multimodal Data Fusion and Deep Learning Framework for Large-Scale Wildfire Surface Fuel Mapping. Fire 2023, 6, 36. [Google Scholar] [CrossRef]
- Spiller, D.; Ansalone, L.; Longépé, N.; Wheeler, J.; Mathieu, P.P. Wildfire detection and monitoring by using PRISMA hyperspectral data and convolutional neural networks. In Proceedings of the EGU General Assembly Conference Abstracts, Online, 19–30 April 2021; p. EGU21-12330. [Google Scholar]
- Khan, Z.A.; Hussain, T.; Ullah, F.U.M.; Gupta, S.K.; Lee, M.Y.; Baik, S.W. Randomly Initialized CNN with Densely Connected Stacked Autoencoder for Efficient Fire Detection. Eng. Appl. Artif. Intell. 2022, 116, 105403. [Google Scholar] [CrossRef]
- Srinivas, K.; Dua, M. Fog computing and deep CNN based efficient approach to early forest fire detection with unmanned aerial vehicles. In Inventive Computation Technologies, Proceedings of the ICICT 2019 Conference, Tamil Nadu, 29–30 August 2019; Springer: Cham, Switzerland, 2020; pp. 646–652. [Google Scholar]
- Khudayberdiev, O.; Butt, M.H.F. Fire detection in Surveillance Videos using a combination with PCA and CNN. Acad. J. Comput. Inf. Sci. 2020, 3, 27–33. [Google Scholar]
- Spiller, D.; Amici, S.; Ansalone, L. Transfer Learning Analysis For Wildfire Segmentation Using Prisma Hyperspectral Imagery And Convolutional Neural Networks. In Proceedings of the 2022 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Rome, Italy, 13–16 September 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Rahmatov, N.; Paul, A.; Saeed, F.; Seo, H. Realtime fire detection using CNN and search space navigation. J. Real-Time Image Process. 2021, 18, 1331–1340. [Google Scholar] [CrossRef]
- Amici, S.; Piscini, A. Exploring PRISMA Scene for Fire Detection: Case Study of 2019 Bushfires in Ben Halls Gap National Park, NSW, Australia. Remote Sens. 2021, 13, 1410. [Google Scholar] [CrossRef]
- Majid, S.; Alenezi, F.; Masood, S.; Ahmad, M.; Gündüz, E.S.; Polat, K. Attention based CNN model for fire detection and localization in real-world images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Spiller, D.; Ansalone, L.; Amici, S.; Piscini, A.; Mathieu, P.P. Analysis and detection of wildfires by using prisma hyperspectral imagery. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 43, 215–222. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- European Commission, Joint Research Centre; San-Miguel-Ayanz, J.; Durrant, T.; Boca, R. Forest Fires in Europe, Middle East and North Africa 2020; Technical Report; European Commission, Joint Research Centre: Luxembourg, 2021. [Google Scholar]
- Bajocco, S.; Dragoz, E.; Gitas, I.; Smiraglia, D.; Salvati, L.; Ricotta, C. Mapping forest fuels through vegetation phenology: The role of coarse-resolution satellite time-series. PLoS ONE 2015, 10, e0119811. [Google Scholar] [CrossRef]
- Oliveira, S.; Félix, F.; Nunes, A.; Lourenço, L.; Laneve, G.; Sebastián-López, A. Mapping wildfire vulnerability in Mediterranean Europe. Testing a stepwise approach for operational purposes. J. Environ. Manag. 2018, 206, 158–169. [Google Scholar] [CrossRef]
- Salis, M.; Arca, B.; Del Giudice, L.; Jahdi, R.; Pellizzaro, G.; Ager, A.A.; Urdiroz, F.A.; Scarpa, C.; Schirru, M.; Bacciu, V.; et al. Wildfire Simulation Modeling to Analyze Wildfire Hazard and Exposure in the Italy–France Maritime Cooperation Area (Sardinia, Corsica, Tuscany, Liguria and Provence–Alpes–Côte d’Azur). Environ. Sci. Proc. 2022, 17, 53. [Google Scholar] [CrossRef]
- Aragoneses, E.; García, M.; Salis, M.; Ribeiro, L.M.; Chuvieco, E. Classification and mapping of European fuels using a hierarchical, multipurpose fuel classification system. Earth Syst. Sci. Data 2023, 15, 1287–1315. [Google Scholar] [CrossRef]
- Scott, J.; Burgan, R. Standard Fire Behavior Fuel Models: A Comprehensive Set for Use with Rothermel’s Surface Fire Spread Model. USDA Forest Service; U.S. Department of Agriculture: Fort Collins, CO, USA, 2005. [CrossRef]
- Pungetti, G.; Marini, A.; Vogiatzakis, I. Sardinia. In Mediterranean Island Landscapes: Natural and Cultural Approaches; Springer: Berlin/Heidelberg, Germany, 2008; pp. 143–169. [Google Scholar]
- Xie, F.; Fan, H. Deriving drought indices from MODIS vegetation indices (NDVI/EVI) and Land Surface Temperature (LST): Is data reconstruction necessary? Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102352. [Google Scholar] [CrossRef]
- da Silva, V.S.; Salami, G.; da Silva, M.I.O.; Silva, E.A.; Monteiro Junior, J.J.; Alba, E. Methodological evaluation of vegetation indexes in land use and land cover (LULC) classification. Geol. Ecol. Landsc. 2020, 4, 159–169. [Google Scholar] [CrossRef]
- Lees, K.J.; Artz, R.R.; Khomik, M.; Clark, J.M.; Ritson, J.; Hancock, M.H.; Cowie, N.R.; Quaife, T. Using spectral indices to estimate water content and GPP in Sphagnum moss and other peatland vegetation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4547–4557. [Google Scholar] [CrossRef]
- Alvino, F.C.; Aleman, C.C.; Filgueiras, R.; Althoff, D.; da Cunha, F.F. Vegetation indices for irrigated corn monitoring. Eng. Agríc. 2020, 40, 322–333. [Google Scholar] [CrossRef]
- Srivastava, A.; Umrao, S.; Biswas, S. Exploring Forest Transformation by Analyzing Spatial-temporal Attributes of Vegetation using Vegetation Indices. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 1110–1117. [Google Scholar] [CrossRef]
- Santoro, M.; Cartus, O. ESA Biomass Climate Change Initiative (Biomass_cci): Global Datasets of Forest Above-Ground Biomass for the Years 2010, 2017, 2018, 2019 and 2020, v4; NERC EDS Centre for Environmental Data Analysis: Calgary, AB, Canada, 2023. [Google Scholar] [CrossRef]
- Canu, S.; Rosati, L.; Fiori, M.; Motroni, A.; Filigheddu, R.; Farris, E. Bioclimate map of Sardinia (Italy). J. Maps 2015, 11, 711–718. [Google Scholar] [CrossRef]
- Aghdam, H.H.; Heravi, E.J. Guide to Convolutional Neural Networks; Springer: New York, NY, USA, 2017; Volume 10, p. 51. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
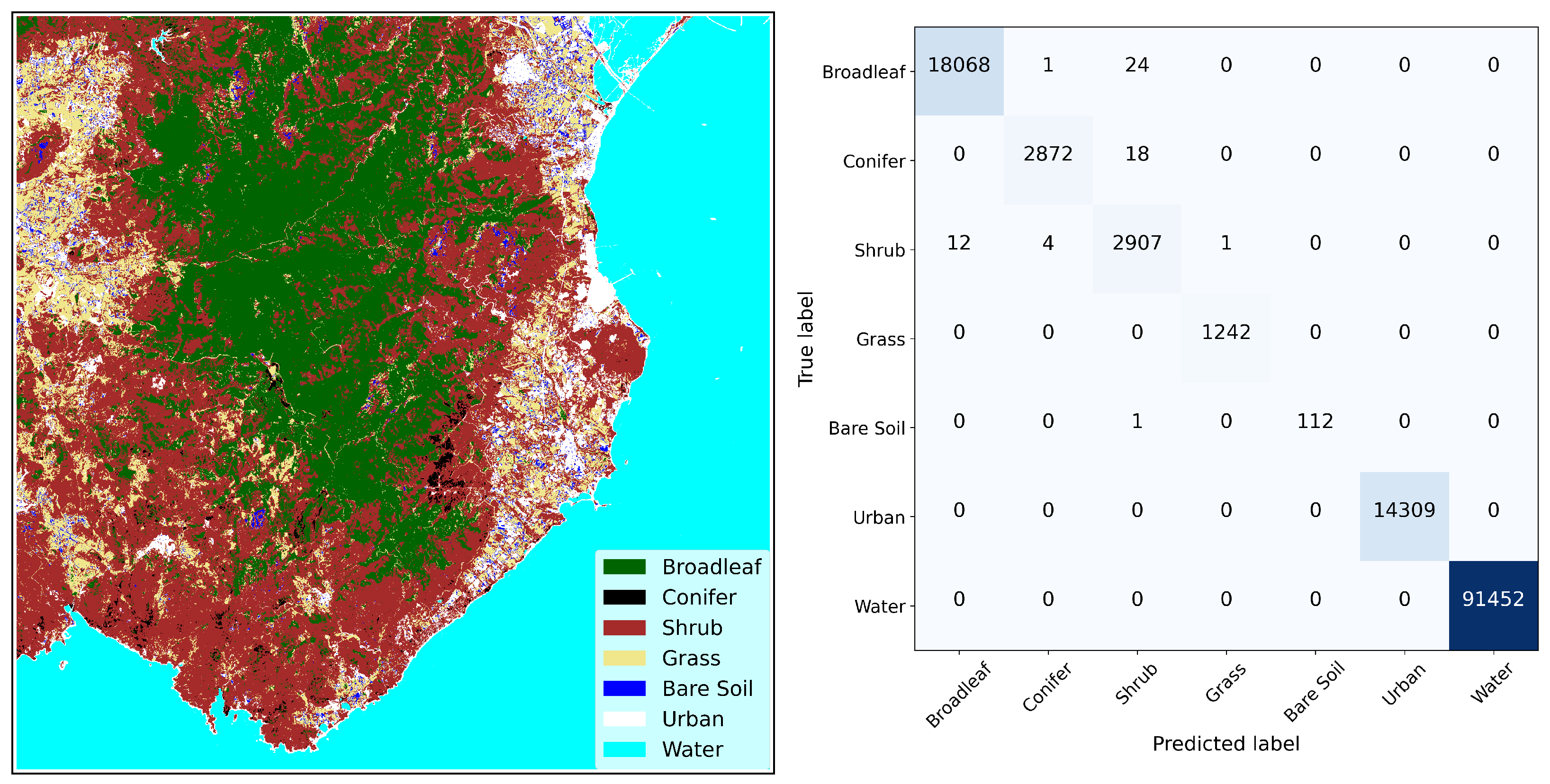
| Broadleaf | Conifer | Shrub | Grass | Bare Soil | Urban | Water |
|---|---|---|---|---|---|---|
| 18,093 | 2890 | 2924 | 1242 | 112 | 14,309 | 91,452 |
| Index | Description |
|---|---|
| Range between −1 (non-vegetated surfaces such as bare soil or water) and +1 (high density of healthy vegetation) | |
| Range between −1 (non-vegetated surfaces or stressed vegetation) and +1 (high density and healthier vegetation) | |
| Range between −1 (non-water surfaces) and +1 (high likelihood of water presence) |
| Index | Description | Index | Description |
|---|---|---|---|
| GR1 | Short, Sparse, Dry Climate Grass | SH8 | High Load, Humid Climate Shrub |
| GR2 | Low Load, Dry Climate Grass | SH9 | Very High Load, Humid Climate Shrub |
| GR3 | Low Load, Very Coarse, Humid Climate Grass | TU1 | Low Load Dry Climate Timber–Grass–Shrub |
| GR4 | Moderate Load, Dry Climate Grass | TU2 | Moderate Load, Humid Climate Timber–Shrub |
| GR5 | Low Load, Humid Climate Grass | TU3 | Moderate Load, Humid Climate Timber–Grass–Shrub |
| GR6 | Moderate Load, Humid Climate Grass | TU4 | Dwarf Conifer With Understory |
| GR7 | High Load, Dry Climate Grass | TU5 | Very High Load, Dry Climate Timber–Shrub |
| GR8 | High Load, Very Coarse, Humid Climate Grass | TL1 | Low Load Compact Conifer Litter |
| GR9 | Very High Load, Humid Climate Grass | TL2 | Low Load Broadleaf Litter |
| GS1 | Low Load, Dry Climate Grass–Shrub | TL3 | Moderate Load Conifer Litter |
| GS2 | Moderate Load, Dry Climate Grass–Shrub | TL4 | Small Downed logs |
| GS3 | Moderate Load, Humid Climate Grass–Shrub | TL5 | High Load Conifer Litter |
| GS4 | High Load, Humid Climate Grass–Shrub | TL6 | Moderate Load Broadleaf Litter |
| SH1 | Low Load Dry Climate Shrub | TL7 | Large Downed Logs |
| SH2 | Moderate Load Dry Climate Shrub | TL8 | Long-Needle Litter |
| SH3 | Moderate Load, Humid Climate Shrub | TL9 | Very High Load Broadleaf Litter |
| SH4 | Low Load, Humid Climate Timber–Shrub | SB1 | Low Load Activity Fuel |
| SH5 | High Load, Dry Climate Shrub | SB2 | Moderate Load Activity Fuel or Low Load Blowdown |
| SH6 | Low Load, Humid Climate Shrub | SB3 | High Load Activity Fuel or Moderate Load Blowdown |
| SH7 | Very High Load, Dry Climate Shrub | SB4 | High Load Blowdown |
| Dry-Low | Dry-Med | Dry-High | Hum-Low | Hum-Med | Hum-High | |
|---|---|---|---|---|---|---|
| BL | TL2 | TL6 | TL9 | TL2 | TL6 | TL9 |
| CF | TL1 | TL3 | TL5 | TL1 | TL3 | TL5 |
| SH | SH2 | SH5 | SH7 | SH6 | SH3 | SH9 |
| GR | GR2 | GR4 | GR7 | GR5 | GR6 | GR9 |
| GS | GS1 | GS2 | SH7 | GS3 | GS4 | SH8 |
| TS | TU1 | TU1 | TU5 | SH4 | TU2 | TU2 |
| TSG | TU1 | TU1 | TU5 | SH4 | TU3 | TU3 |
| Accuracy | Recall | F1 Score | |
|---|---|---|---|
| CNN | 0.99% | 0.99% | 0.99% |
| RF | 0.99% | 0.99% | 0.98% |
| SVM | 0.99% | 0.98% | 0.98% |
| Broadleaf | Conifer | Shrub | Grass | |
|---|---|---|---|---|
| CNN | 0.99% | 0.79% | 0.76% | 0.84% |
| RF | 0.99% | 0.70% | 0.77% | 0.81% |
| SVM | 0.99% | 0.60% | 0.78% | 0.79% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carbone, A.; Spiller, D.; Laneve, G. Fuel Type Mapping Using a CNN-Based Remote Sensing Approach: A Case Study in Sardinia. Fire 2023, 6, 395. https://doi.org/10.3390/fire6100395
Carbone A, Spiller D, Laneve G. Fuel Type Mapping Using a CNN-Based Remote Sensing Approach: A Case Study in Sardinia. Fire. 2023; 6(10):395. https://doi.org/10.3390/fire6100395
Chicago/Turabian StyleCarbone, Andrea, Dario Spiller, and Giovanni Laneve. 2023. "Fuel Type Mapping Using a CNN-Based Remote Sensing Approach: A Case Study in Sardinia" Fire 6, no. 10: 395. https://doi.org/10.3390/fire6100395
APA StyleCarbone, A., Spiller, D., & Laneve, G. (2023). Fuel Type Mapping Using a CNN-Based Remote Sensing Approach: A Case Study in Sardinia. Fire, 6(10), 395. https://doi.org/10.3390/fire6100395