

Vegetation Cover Type Classification Using Cartographic Data for Prediction of Wildfire Behaviour


Abstract
:1. Introduction
- (i)
- Capturing individual structural features such as height, diameter at breast height (DBH), branching structure, canopy volume, and single-tree biomass (e.g., [18]).
- (ii)
2. Materials and Methods
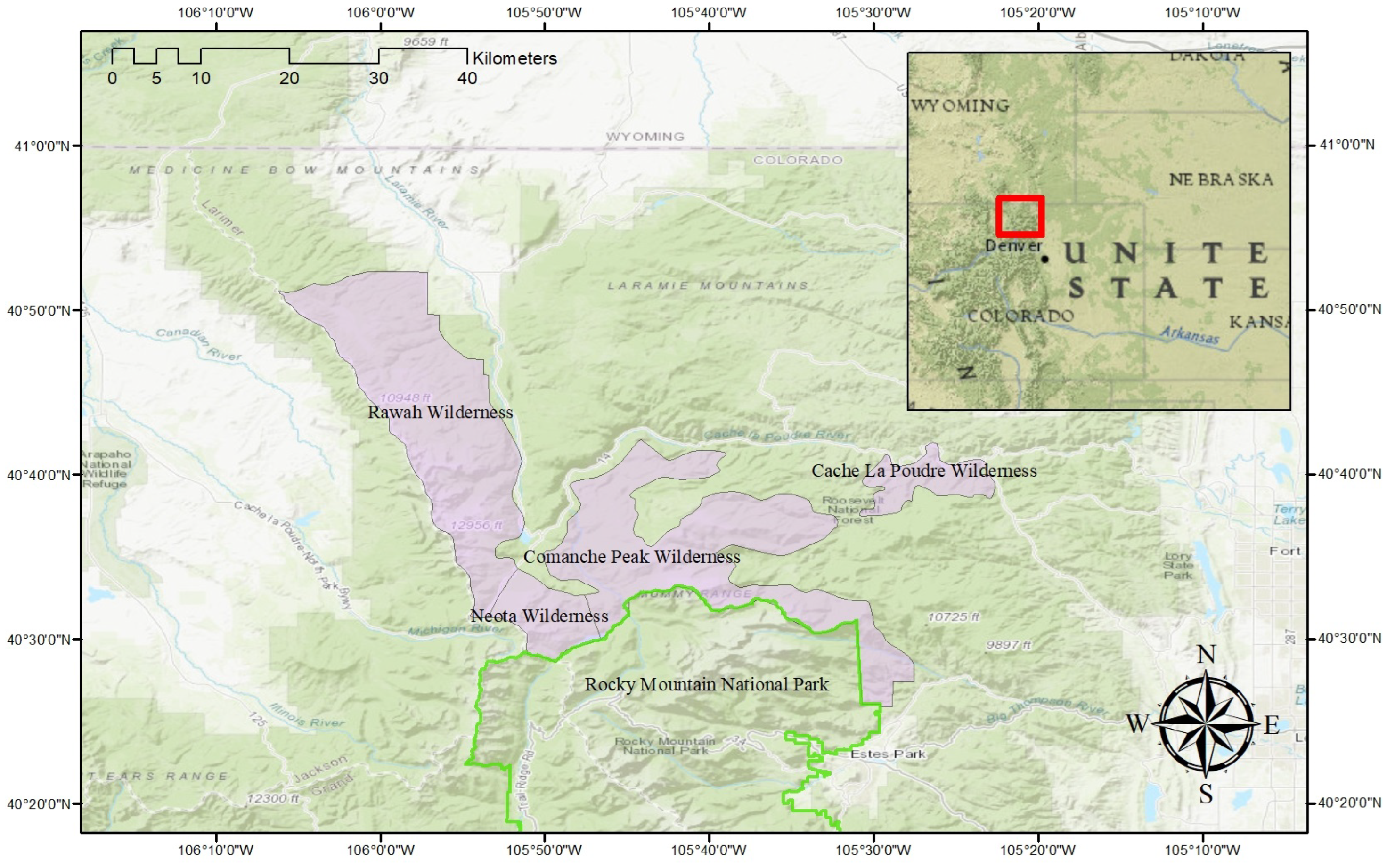
2.1. Dataset
2.2. Base and Ensemble Learning Algorithms
2.2.1. Support Vector Machine
2.2.2. Decision Trees
2.2.3. Random Forest
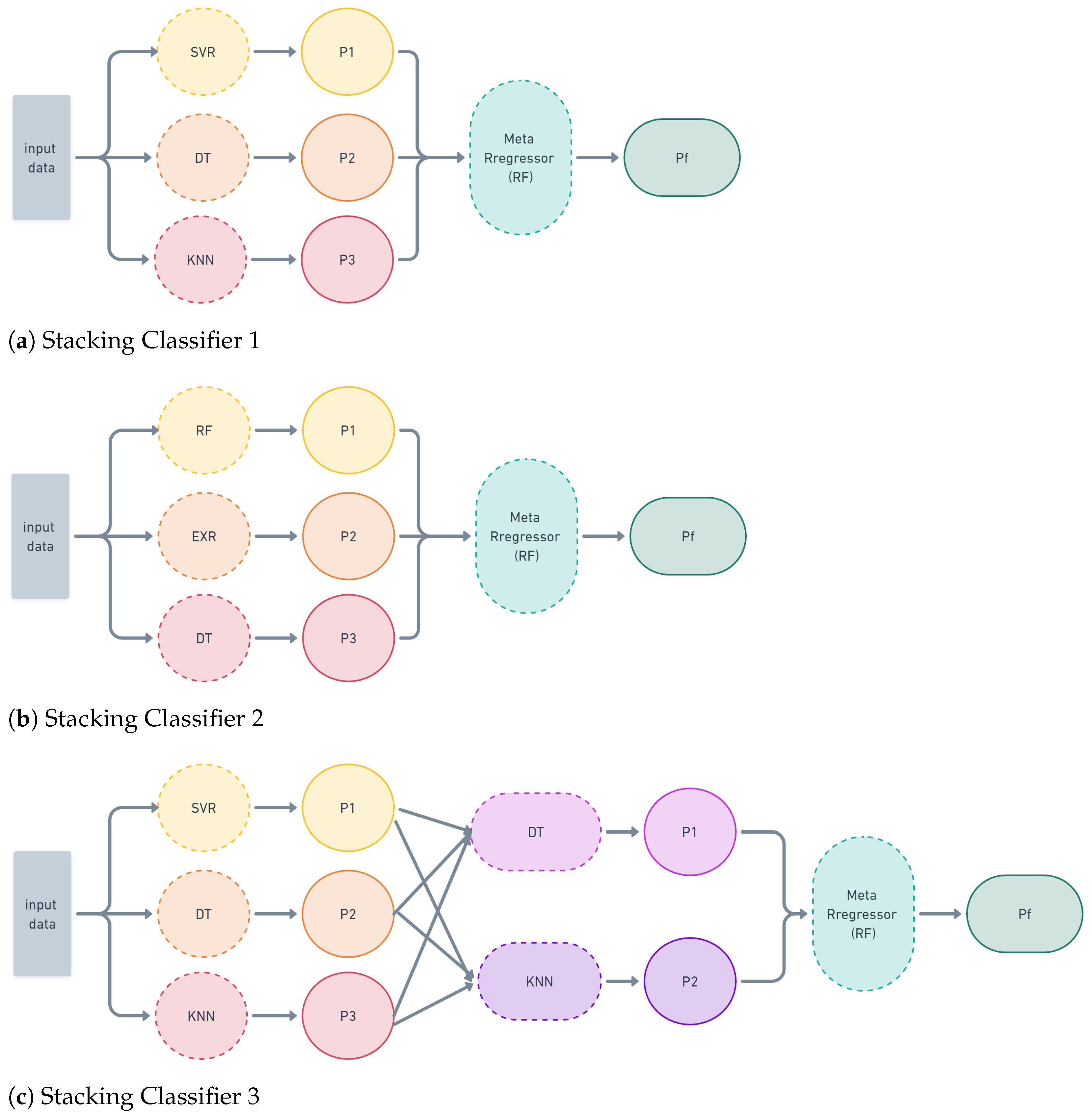
2.2.4. Stacked Models
2.2.5. Extreme Gradient Boosting
2.2.6. K-Nearest Neighbour
2.2.7. Adaptive Boosting
2.2.8. Categorical Boosting
- It is generally more rigorous at handling categorical data, and uses one-hot encoding for categories with low cardinality.
- It utilises the Ordered Boosting technique, which means that it is able to use the same examples used for computation of Ordered Target Statistics to compute by assuming D to be the set of all available data for training the GBDT model, keeping in mind that the DT is the tree that minimises the loss function .
- Its approach to building DTs relies heavily on Oblivious Decision Trees (ODTs). CatB creates a number of ODTs, which are full binary trees. Hence, there will be nodes if there are n levels. The ODT’s non-leaf nodes divide according to the same standard. In order to increase confidence in the selection of the most productive feature combinations by CatB during training, the capabilities of GBDT are expanded to enable it to consider feature interactions. [56,61].
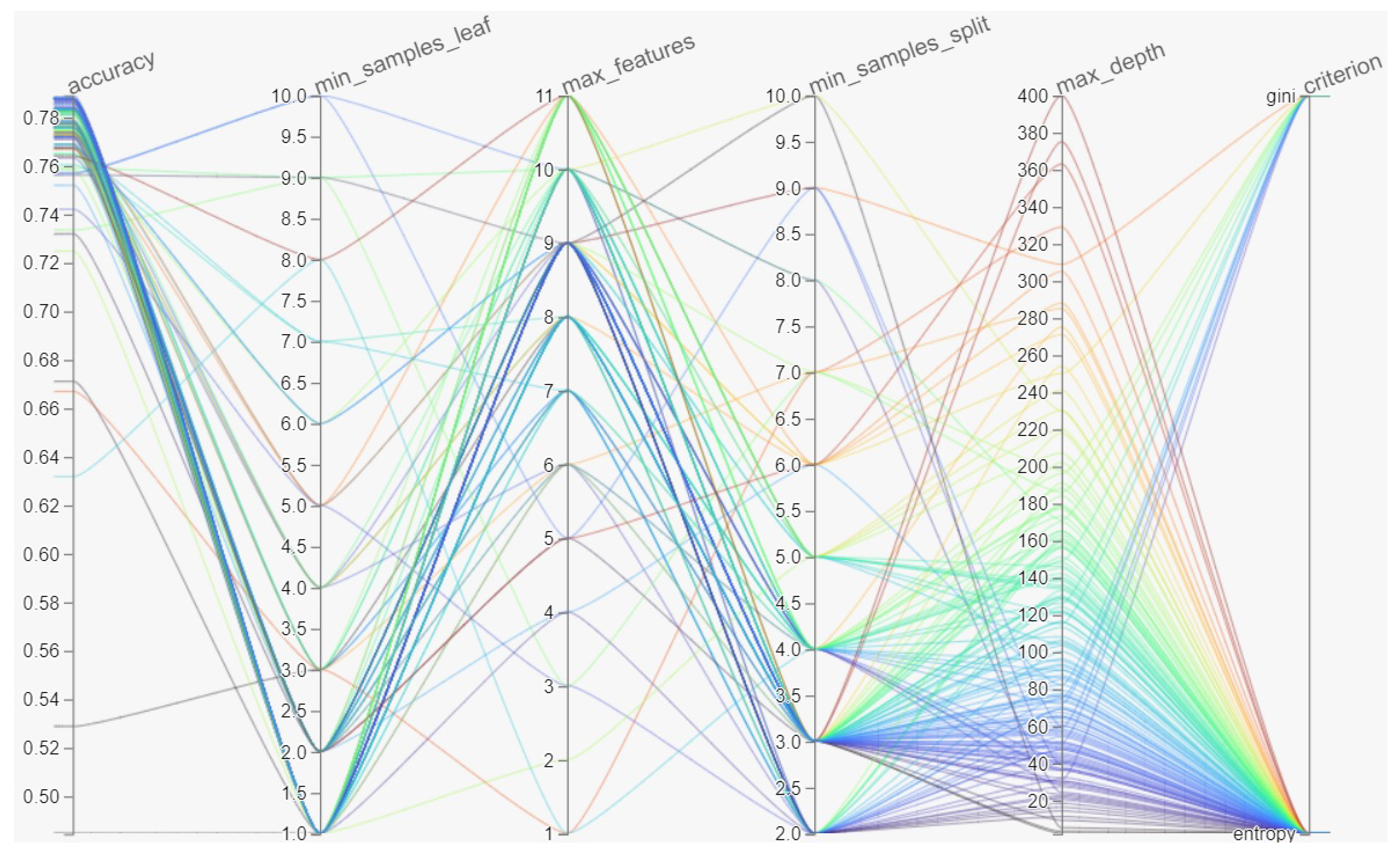
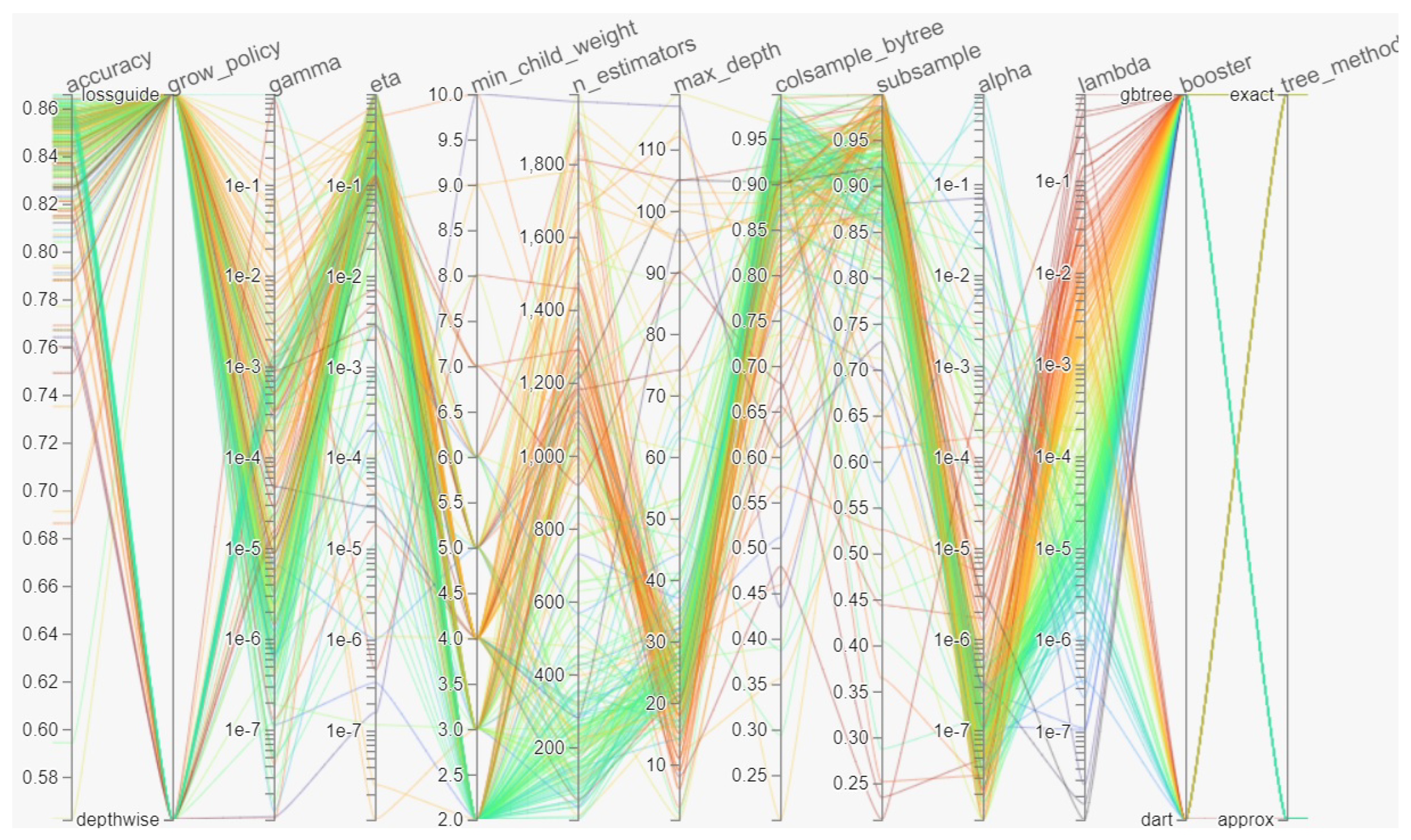
2.3. Hyperparameter Optimisation
2.4. Model Development and Accuracy Assessment
- Accuracy is defined as the ratio of correct predictions over the total number of instances evaluated, and is calculated as in Equation (4).
- Precision is defined as positive patterns that are correctly predicted from the total predicted patterns in a positive class, and is calculated as in Equation (5).
- Recall is defined as the percentage of positive patterns that are correctly categorised, as in Equation (6).
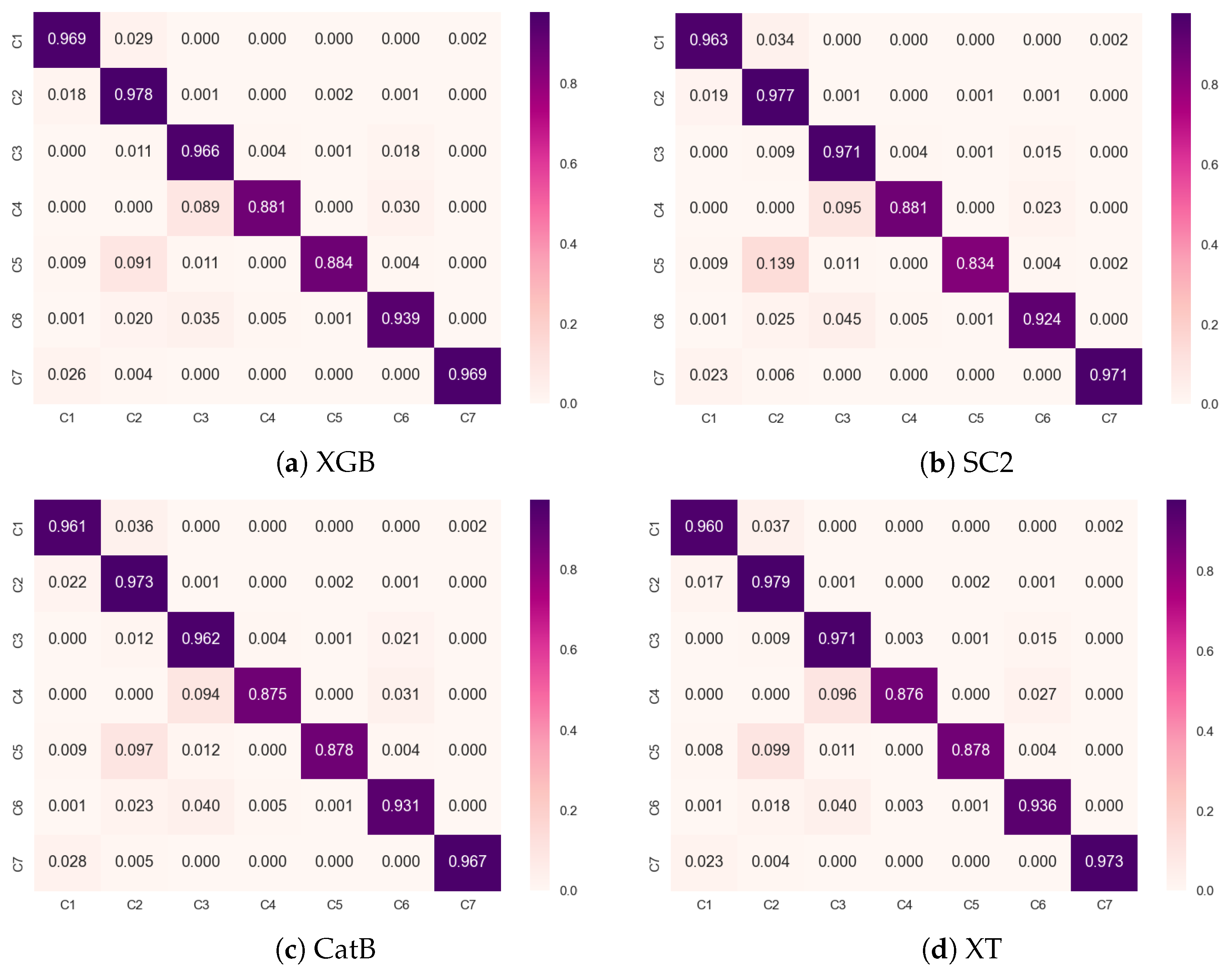
3. Results
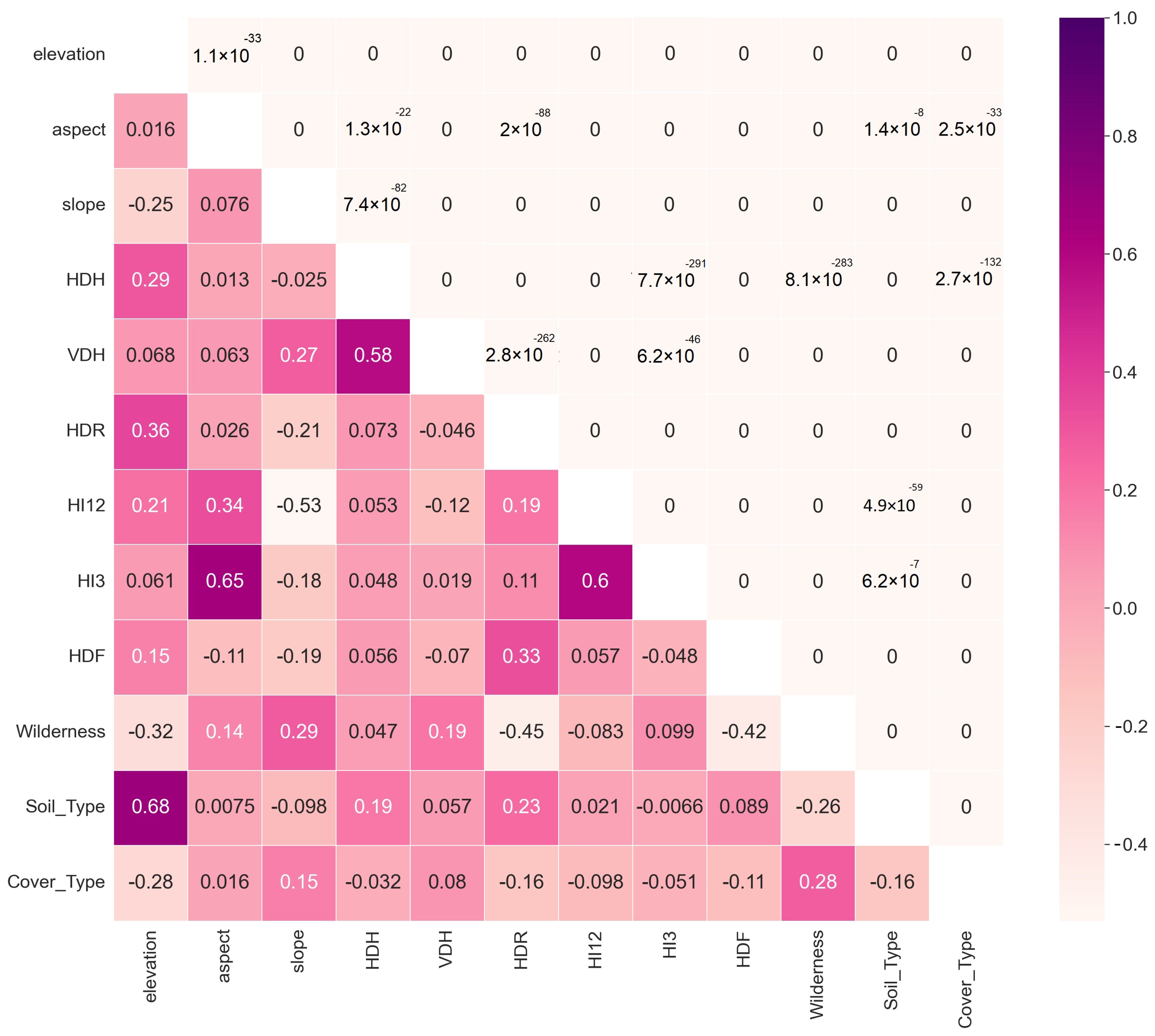
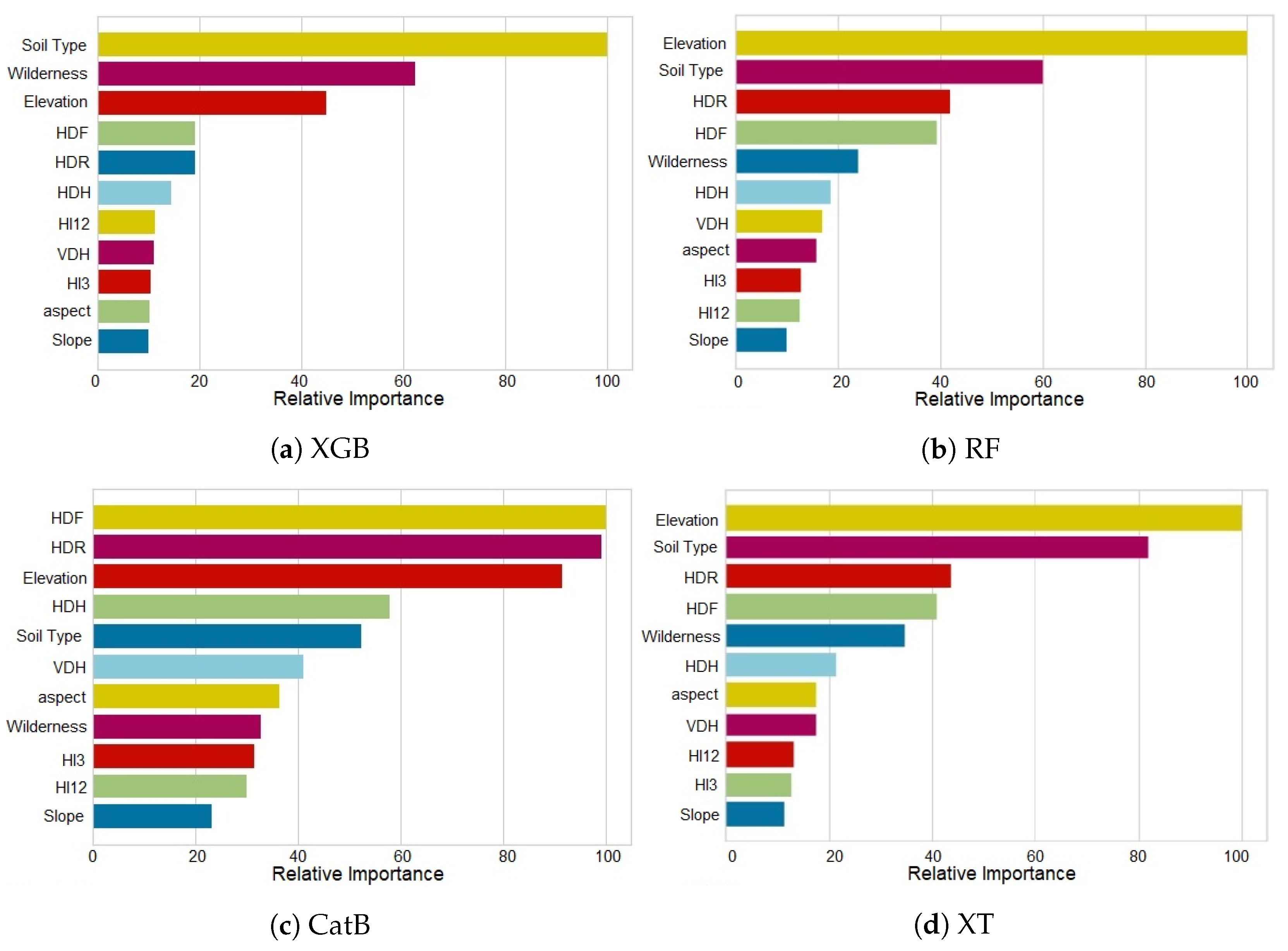
3.1. Model Feature Importance
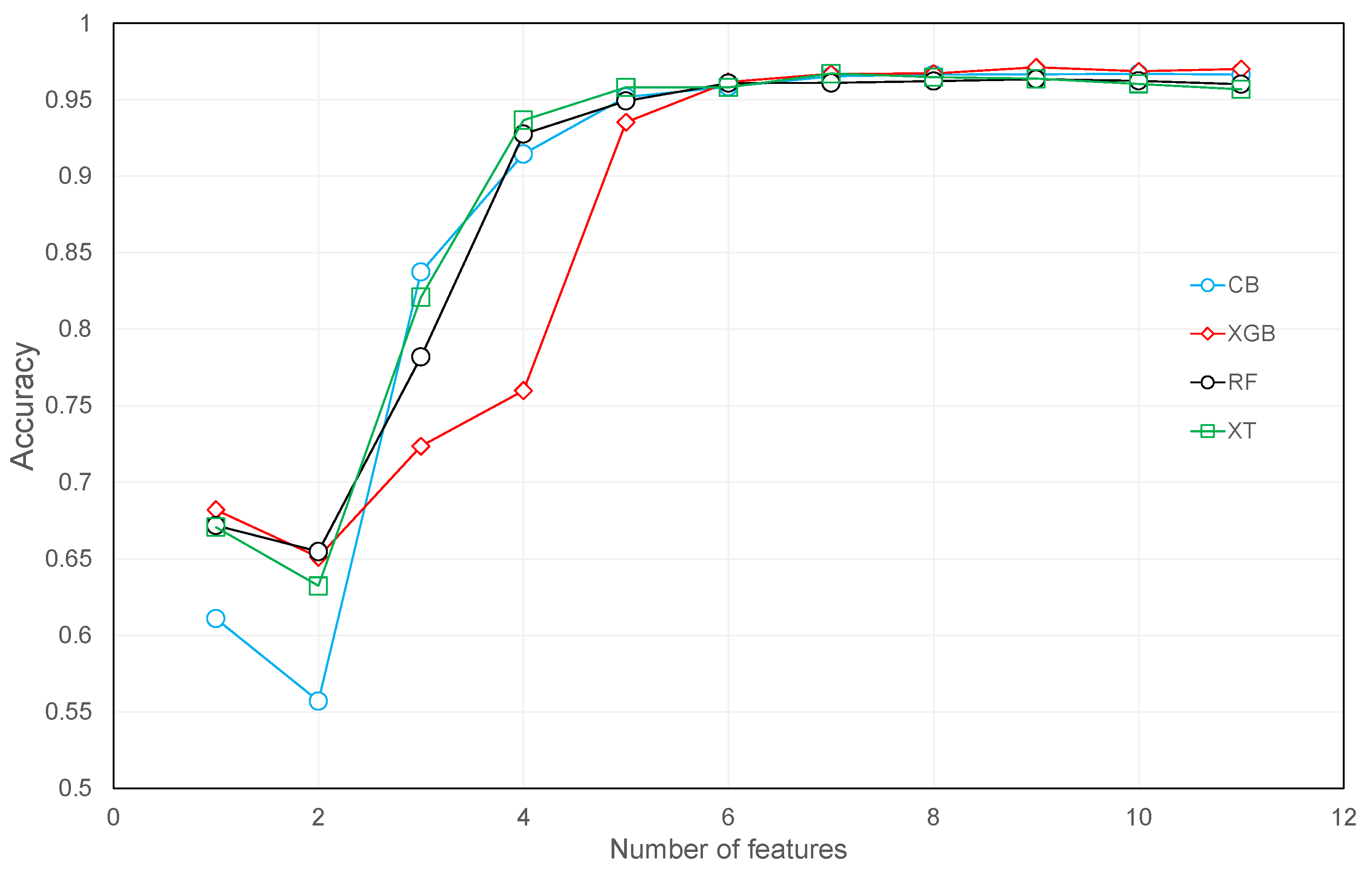
3.2. Recursive Feature Elimination
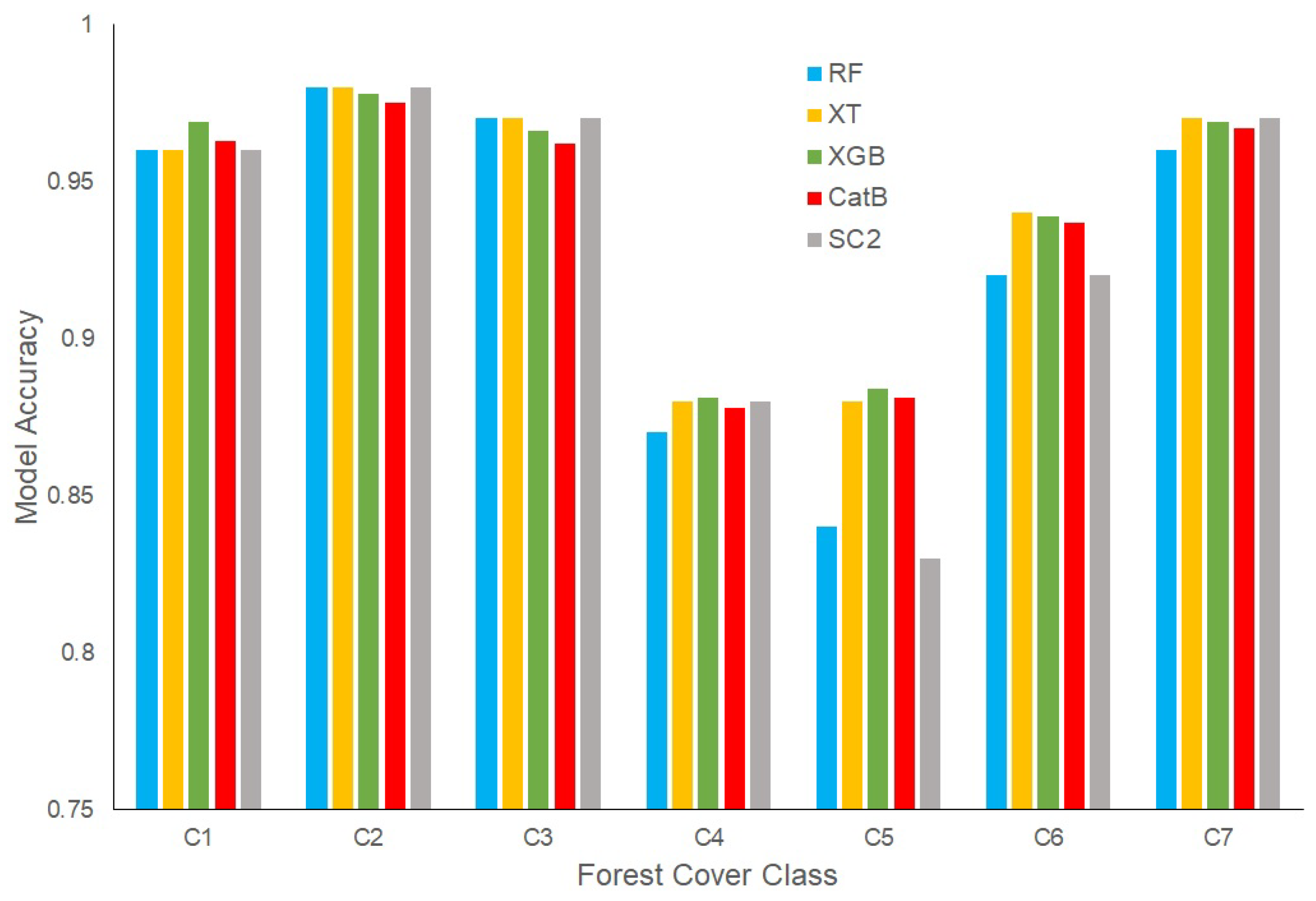
3.3. Accuracy Measures
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AdaB | Adaptive Boosting |
| AutoML | Automated Machine Learning |
| CatB | Categorical Boosting |
| DEM | Digital elevation model |
| DOAJ | Directory of open access journals |
| DT | Decision Tree |
| EDT | Ensemble Decision Trees |
| FFNN | Feed-forward neural network |
| FARSITE | Fire Area Simulator |
| GBDT | Gradient Boosting Decision Tree |
| GDA | Gaussian Discriminant Analysis |
| GIS | Geographic information system |
| HDF | Horizontal distance to nearest fire ignition point |
| HDH | Horizontal distance to Hydrology |
| HDR | Horizontal distance to roadway |
| HI | Hillshade index |
| LD | Linear dichroism |
| ML | Machine learning |
| NB | Naïve Bayes |
| PCA | Principle Component Analysis |
| RF | Random Forest |
| SVM | Support Vector Machine |
| TLA | Three letter acronym |
| UCI | University of California Irvine |
| USFS | United States Forest Service |
| USGS | United States Geological Survey |
| VDH | Vertical distance to hydrology |
| WFDS | Wildfire Dynamic Simulator |
| XGB | Extreme Gradient Boosting |
| XT | Extremely Randomised Trees |
References
- Giglio, L.; Boschetti, L.; Roy, D.P.; Humber, M.L.; Justice, C.O. The Collection 6 MODIS burned area mapping algorithm and product. Remote Sens. Environ. 2018, 217, 72–85. [Google Scholar] [CrossRef]
- Jurvélius, M. Forest Fires (Prediction, Prevention, Preparedness and Suppression). In Encyclopedia of Forest Sciences; Elsevier: Amsterdam, The Netherlands, 2004; pp. 334–339. [Google Scholar] [CrossRef]
- Bond, W.J.; Keeley, J.E. Fire as a global ‘herbivore’: The ecology and evolution of flammable ecosystems. Trends Ecol. Evol. 2005, 20, 387–394. [Google Scholar] [CrossRef]
- Innocente, M.S.; Grasso, P. Self-organising swarms of firefighting drones: Harnessing the power of collective intelligence in decentralised multi-robot systems. J. Comput. Sci. 2019, 34, 80–101. [Google Scholar] [CrossRef]
- Coogan, S.C.; Robinne, F.N.; Jain, P.; Flannigan, M.D. Scientists’ warning on wildfire—A Canadian perspective. Can. J. For. Res. 2019, 49, 1015–1023. [Google Scholar] [CrossRef] [Green Version]
- Jain, P.; Coogan, S.C.; Subramanian, S.G.; Crowley, M.; Taylor, S.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- Scott, J.H.; Reinhardt, E.D. Assessing Crown Fire Potential by Linking Models of Surface and Crown Fire Behavior; Technical Report; U.S. Department of Agriculture: Fort Collins, CO, USA, 2001. [CrossRef] [Green Version]
- Finney, M.A. FARSITE: Fire Area Simulator-Model Development and Evaluation; Technical Report; U.S. Department of Agriculture: Fort Collins, CO, USA, 1998. [CrossRef]
- Linn, R.; Reisner, J.; Colman, J.J.; Winterkamp, J. Studying wildfire behavior using FIRETEC. Int. J. Wildland Fire 2002, 11, 233. [Google Scholar] [CrossRef]
- Mell, W.; Jenkins, M.A.; Gould, J.; Cheney, P. A physics-based approach to modelling grassland fires. Int. J. Wildland Fire 2007, 16, 1. [Google Scholar] [CrossRef]
- Grasso, P.; Innocente, M.S. A two-dimensional reaction-advection-diffusion model of the spread of fire in wildlands. In Advances in Forest Fire Research 2018; Imprensa da Universidade de Coimbra: Coimbra, Portugal, 2018; pp. 334–342. [Google Scholar] [CrossRef] [Green Version]
- Grasso, P.; Innocente, M.S. Physics-based model of wildfire propagation towards faster-than-real-time simulations. Comput. Math. Appl. 2020, 80, 790–808. [Google Scholar] [CrossRef]
- Kim, Y.H.; Bettinger, P.; Finney, M. Spatial optimization of the pattern of fuel management activities and subsequent effects on simulated wildfires. Eur. J. Oper. Res. 2009, 197, 253–265. [Google Scholar] [CrossRef]
- Arroyo, L.A.; Pascual, C.; Manzanera, J.A. Fire models and methods to map fuel types: The role of remote sensing. For. Ecol. Manag. 2008, 256, 1239–1252. [Google Scholar] [CrossRef] [Green Version]
- Martell, D.L. A Review of Recent Forest and Wildland Fire Management Decision Support Systems Research. Curr. For. Rep. 2015, 1, 128–137. [Google Scholar] [CrossRef] [Green Version]
- Ausonio, E.; Bagnerini, P.; Ghio, M. Drone Swarms in Fire Suppression Activities: A Conceptual Framework. Drones 2021, 5, 17. [Google Scholar] [CrossRef]
- Campbell, M.J.; Page, W.G.; Dennison, P.E.; Butler, B.W. Escape Route Index: A Spatially-Explicit Measure of Wildland Firefighter Egress Capacity. Fire 2019, 2, 40. [Google Scholar] [CrossRef] [Green Version]
- Kato, A.; Moskal, L.M.; Schiess, P.; Swanson, M.E.; Calhoun, D.; Stuetzle, W. Capturing tree crown formation through implicit surface reconstruction using airborne lidar data. Remote Sens. Environ. 2009, 113, 1148–1162. [Google Scholar] [CrossRef]
- Yebra, M.; Quan, X.; Riaño, D.; Larraondo, P.R.; van Dijk, A.I.; Cary, G.J. A fuel moisture content and flammability monitoring methodology for continental Australia based on optical remote sensing. Remote Sens. Environ. 2018, 212, 260–272. [Google Scholar] [CrossRef]
- Engelstad, P.S.; Falkowski, M.; Wolter, P.; Poznanovic, A.; Johnson, P. Estimating Canopy Fuel Attributes from Low-Density LiDAR. Fire 2019, 2, 38. [Google Scholar] [CrossRef] [Green Version]
- Rao, K.; Williams, A.P.; Flefil, J.F.; Konings, A.G. SAR-enhanced mapping of live fuel moisture content. Remote Sens. Environ. 2020, 245, 111797. [Google Scholar] [CrossRef]
- Marino, E.; Tomé, J.L.; Hernando, C.; Guijarro, M.; Madrigal, J. Transferability of Airborne LiDAR Data for Canopy Fuel Mapping: Effect of Pulse Density and Model Formulation. Fire 2022, 5, 126. [Google Scholar] [CrossRef]
- Vorster, A.G.; Evangelista, P.H.; Stovall, A.E.L.; Ex, S. Variability and uncertainty in forest biomass estimates from the tree to landscape scale: The role of allometric equations. Carbon Balance Manag. 2020, 15, 8. [Google Scholar] [CrossRef]
- Anderson, K.E.; Glenn, N.F.; Spaete, L.P.; Shinneman, D.J.; Pilliod, D.S.; Arkle, R.S.; McIlroy, S.K.; Derryberry, D.R. Estimating vegetation biomass and cover across large plots in shrub and grass dominated drylands using terrestrial lidar and machine learning. Ecol. Indic. 2018, 84, 793–802. [Google Scholar] [CrossRef]
- Hartley, R.J.L.; Davidson, S.J.; Watt, M.S.; Massam, P.D.; Aguilar-Arguello, S.; Melnik, K.O.; Pearce, H.G.; Clifford, V.R. A Mixed Methods Approach for Fuel Characterisation in Gorse (Ulex europaeus L.) Scrub from High-Density UAV Laser Scanning Point Clouds and Semantic Segmentation of UAV Imagery. Remote Sens. 2022, 14, 4775. [Google Scholar] [CrossRef]
- Zheng, Y.; Jia, W.; Wang, Q.; Huang, X. Deriving Individual-Tree Biomass from Effective Crown Data Generated by Terrestrial Laser Scanning. Remote Sens. 2019, 11, 2793. [Google Scholar] [CrossRef] [Green Version]
- Carpenter, J.; Jung, J.; Oh, S.; Hardiman, B.; Fei, S. An Unsupervised Canopy-to-Root Pathing (UCRP) Tree Segmentation Algorithm for Automatic Forest Mapping. Remote Sens. 2022, 14, 4274. [Google Scholar] [CrossRef]
- Hoffmann, C.W.; Usoltsev, V.A. Tree-crown biomass estimation in forest species of the Ural and of Kazakhstan. For. Ecol. Manag. 2002, 158, 59–69. [Google Scholar] [CrossRef]
- Fogarty, L.G.; Pearce, H.G. Draft field guides for determining fuel loads and biomassin New Zealand vegetation types. Fire Technol. Transf. Note 2000, 21, 2–15. [Google Scholar]
- Crespo-Peremarch, P.; Ruiz, L.; Balaguer-Beser, A. A comparative study of regression methods to predict forest structure and canopy fuel variables from LiDAR full-waveform data. Rev. Teledetección 2016, 27–40. [Google Scholar] [CrossRef] [Green Version]
- Chuvieco, E.; Riaño, D.; Wagtendok, J.V.; Morsdof, F. Fuel Loads and Fuel Type Mapping. In Series in Remote Sensing; World Scientific: Singapore, 2003; pp. 119–142. [Google Scholar] [CrossRef]
- Lasaponara, R.; Lanorte, A. Remotely sensed characterization of forest fuel types by using satellite ASTER data. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 225–234. [Google Scholar] [CrossRef]
- Pearce, H.; Anderson, W.; Fogarty, L.; Todoroki, C.; Anderson, S. Linear mixed-effects models for estimating biomass and fuel loads in shrublands. Can. J. For. Res. 2010, 40, 2015–2026. [Google Scholar] [CrossRef]
- Li, Y.; Li, C.; Li, M.; Liu, Z. Influence of Variable Selection and Forest Type on Forest Aboveground Biomass Estimation Using Machine Learning Algorithms. Forests 2019, 10, 1073. [Google Scholar] [CrossRef] [Green Version]
- Luo, M.; Wang, Y.; Xie, Y.; Zhou, L.; Qiao, J.; Qiu, S.; Sun, Y. Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass. Forests 2021, 12, 216. [Google Scholar] [CrossRef]
- Blackard, J.A.; Dean, D.J. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables. Comput. Electron. Agric. 1999, 24, 131–151. [Google Scholar] [CrossRef] [Green Version]
- Pierce, A.D.; Farris, C.A.; Taylor, A.H. Use of random forests for modeling and mapping forest canopy fuels for fire behavior analysis in Lassen Volcanic National Park, California, USA. For. Ecol. Manag. 2012, 279, 77–89. [Google Scholar] [CrossRef]
- Patil, P.R.; Sivagami, M. Forest Cover Classification Using Stacking of Ensemble Learning and Neural Networks. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; pp. 89–102. [Google Scholar] [CrossRef]
- Macmichael, D.; Si, D. Addressing Forest Management Challenges by Refining Tree Cover Type Classification with Machine Learning Models. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), Hong Kong, China, 4–6 August 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Samat, A.; Li, E.; Du, P.; Liu, S.; Xia, J. GPU-Accelerated CatBoost-Forest for Hyperspectral Image Classification Via Parallelized mRMR Ensemble Subspace Feature Selection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3200–3214. [Google Scholar] [CrossRef]
- Sjöqvist, H.; Längkvist, M.; Javed, F. An Analysis of Fast Learning Methods for Classifying Forest Cover Types. Appl. Artif. Intell. 2020, 34, 691–709. [Google Scholar] [CrossRef]
- Al Sameer, M.M.; Prasanth, T.; Anuradha, R. Rapid Forest Cover Detection Using Ensemble Learning. In Lecture Notes in Electrical Engineering; Springer: Singapore, 2021; pp. 181–190. [Google Scholar] [CrossRef]
- Kumar, A.; Sinha, N. Classification of Forest Cover Type Using Random Forests Algorithm. In Advances in Data and Information Sciences; Springer: Singapore, 2020; pp. 395–402. [Google Scholar] [CrossRef]
- Kumar, P.P.; Bai, V.M.A.; Nair, G.G. An efficient classification framework for breast cancer using hyper parameter tuned Random Decision Forest Classifier and Bayesian Optimization. Biomed. Signal Process. Control 2021, 68, 102682. [Google Scholar] [CrossRef]
- Subasree, S.; Sakthivel, N.; Tripathi, K.; Agarwal, D.; Tyagi, A.K. Combining the advantages of radiomic features based feature extraction and hyper parameters tuned RERNN using LOA for breast cancer classification. Biomed. Signal Process. Control 2022, 72, 103354. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, H.; Zhang, G. cPSO-CNN: An efficient PSO-based algorithm for fine-tuning hyper-parameters of convolutional neural networks. Swarm Evol. Comput. 2019, 49, 114–123. [Google Scholar] [CrossRef]
- ArcGIS—Wilderness Areas in the United States. 2023. Available online: https://www.arcgis.com/apps/mapviewer/index.html?layers=52c7896cdfab4660a595e6f6a7ef0e4d (accessed on 3 December 2022).
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Aizerman, M.A.; Braverman, E.A.; Rozonoer, L. Theoretical Foundations of the Potential Function Method in Pattern Recognition Learning. Autom. Remote Control 1964, 25, 821–837. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification And Regression Trees; Routledge: England, UK, 2017. [Google Scholar] [CrossRef]
- Caie, P.D.; Dimitriou, N.; Arandjelović, O. Precision medicine in digital pathology via image analysis and machine learning. In Artificial Intelligence and Deep Learning in Pathology; Elsevier: Amsterdam, The Netherlands, 2021; pp. 149–173. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Stacked regressions. Mach. Learn. 1996, 24, 49–64. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Gale, M.G.; Cary, G.J.; Dijk, A.I.V.; Yebra, M. Forest fire fuel through the lens of remote sensing: Review of approaches, challenges and future directions in the remote sensing of biotic determinants of fire behaviour. Remote Sens. Environ. 2021, 255, 112282. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for big data: An interdisciplinary review. J. Big Data 2020, 7, 1–45. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Cover, T. Estimation by the nearest neighbor rule. IEEE Trans. Inf. Theory 1968, 14, 50–55. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E. A brief introduction to boosting. In Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; NIPS’18. Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 6639–6649. [Google Scholar]
- Tao, H.; Habib, M.; Aljarah, I.; Faris, H.; Afan, H.A.; Yaseen, Z.M. An intelligent evolutionary extreme gradient boosting algorithm development for modeling scour depths under submerged weir. Inf. Sci. 2021, 570, 172–184. [Google Scholar] [CrossRef]
- Brochu, E.; Cora, V.; de Freitas, N. A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimizationb. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar] [CrossRef]
- Nguyen, V. Bayesian Optimization for Accelerating Hyper-Parameter Tuning. In Proceedings of the 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Sardinia, Italy, 3–5 June 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- XGBoost Project. 2022. Available online: https://github.com/dmlc/xgboost) (accessed on 3 December 2022).
- CatBoost. 2022. Available online: https://catboost.ai/ (accessed on 3 December 2022).
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SVR | DT | RF | XT |
|---|---|---|---|
| AdaB | XGB | CatB |
|---|---|---|
| 3500 | ||
| 1073 | ||
| Metric | DT | SVR | KNN | RF | XT | Ada | XGB | CatB | SC1 | SC2 | SC3 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| acc | 0.934 | 0.913 | 0.934 | 0.964 | 0.968 | 0.963 | 0.971 | 0.967 | 0.935 | 0.967 | 0.940 |
| prec | 0.901 | 0.897 | 0.897 | 0.951 | 0.955 | 0.952 | 0.952 | 0.951 | 0.898 | 0.955 | 0.895 |
| rec | 0.898 | 0.869 | 0.872 | 0.928 | 0.939 | 0.922 | 0.941 | 0.938 | 0.890 | 0.932 | 0.910 |
| F1-score | 0.900 | 0.882 | 0.884 | 0.939 | 0.947 | 0.936 | 0.946 | 0.943 | 0.893 | 0.943 | 0.902 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tavakol Sadrabadi, M.; Innocente, M.S. Vegetation Cover Type Classification Using Cartographic Data for Prediction of Wildfire Behaviour. Fire 2023, 6, 76. https://doi.org/10.3390/fire6020076
Tavakol Sadrabadi M, Innocente MS. Vegetation Cover Type Classification Using Cartographic Data for Prediction of Wildfire Behaviour. Fire. 2023; 6(2):76. https://doi.org/10.3390/fire6020076
Chicago/Turabian StyleTavakol Sadrabadi, Mohammad, and Mauro Sebastián Innocente. 2023. "Vegetation Cover Type Classification Using Cartographic Data for Prediction of Wildfire Behaviour" Fire 6, no. 2: 76. https://doi.org/10.3390/fire6020076
APA StyleTavakol Sadrabadi, M., & Innocente, M. S. (2023). Vegetation Cover Type Classification Using Cartographic Data for Prediction of Wildfire Behaviour. Fire, 6(2), 76. https://doi.org/10.3390/fire6020076