
Bearing Prognostics: An Instance-Based Learning Approach with Feature Engineering, Data Augmentation, and Similarity Evaluation


Abstract
:1. Introduction
- (i)
- instance retrieval from a historical dataset;
- (ii)
- prediction through local models based on the instances retrieved;
- (iii)
- aggregation of local predictions.
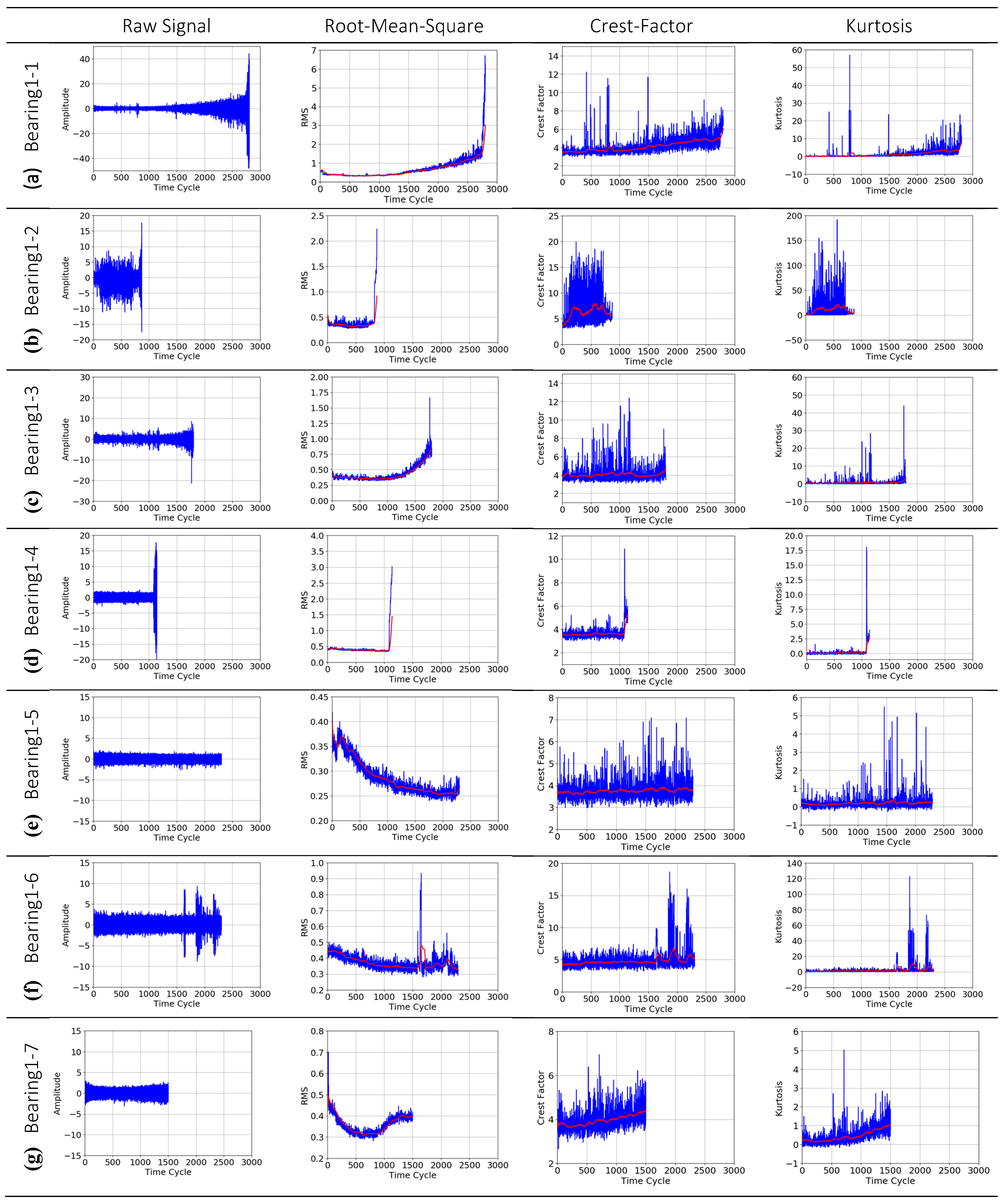
2. Problem Description
3. An Instance-Based Learning (IBL) Approach
3.1. Formulation of the RUL Estimation Problem
3.2. Overview of Methodology
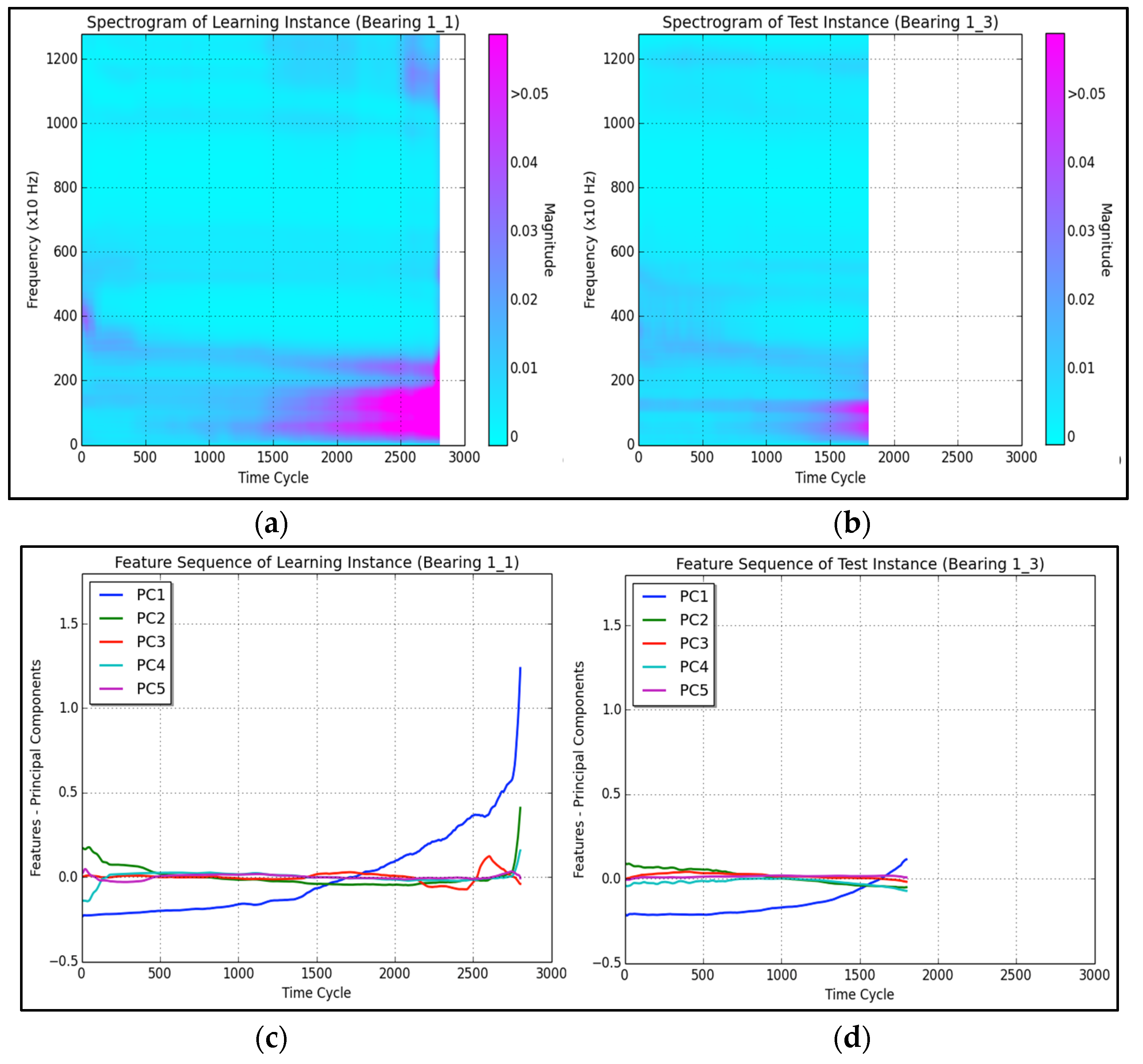
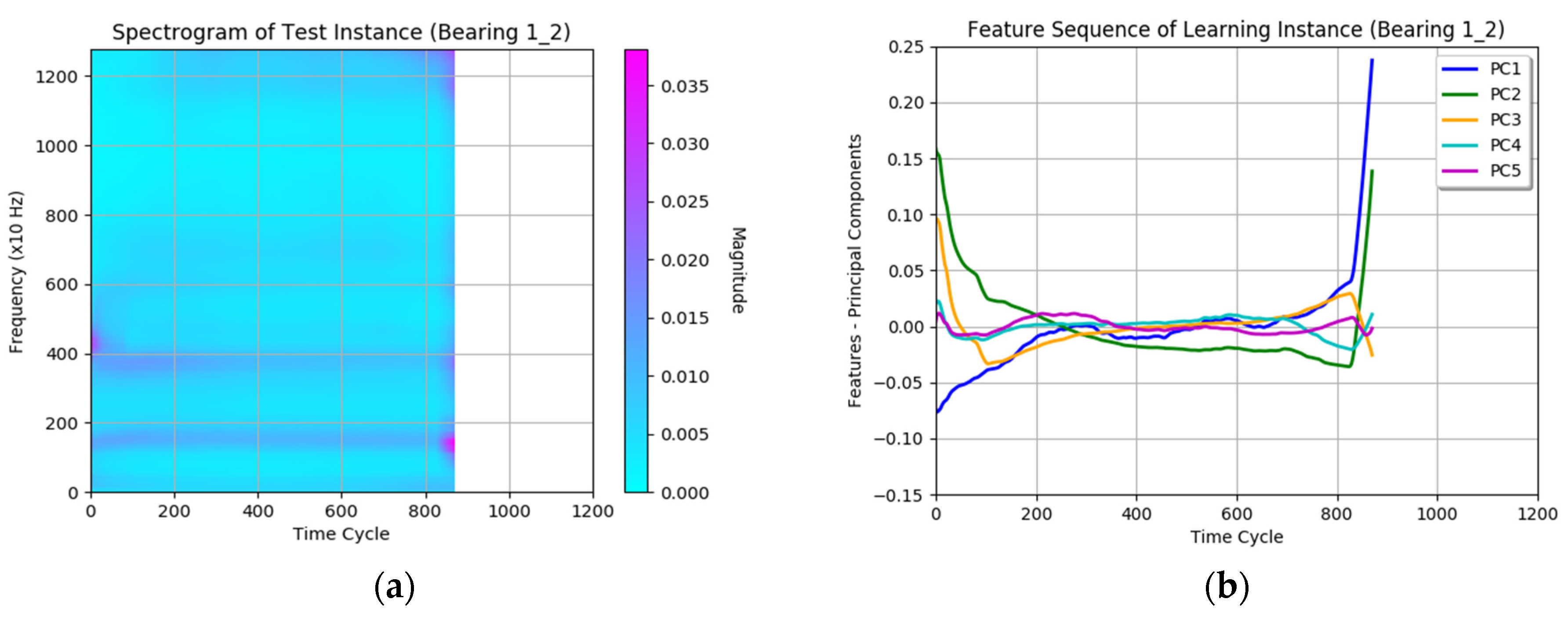
- Spectrogram generation applies the short-time-Fourier-transform (STFT) technique on the raw signals during each time cycle to generate frequency domain signals, so that spectrograms can be obtained for both learning and test instances.
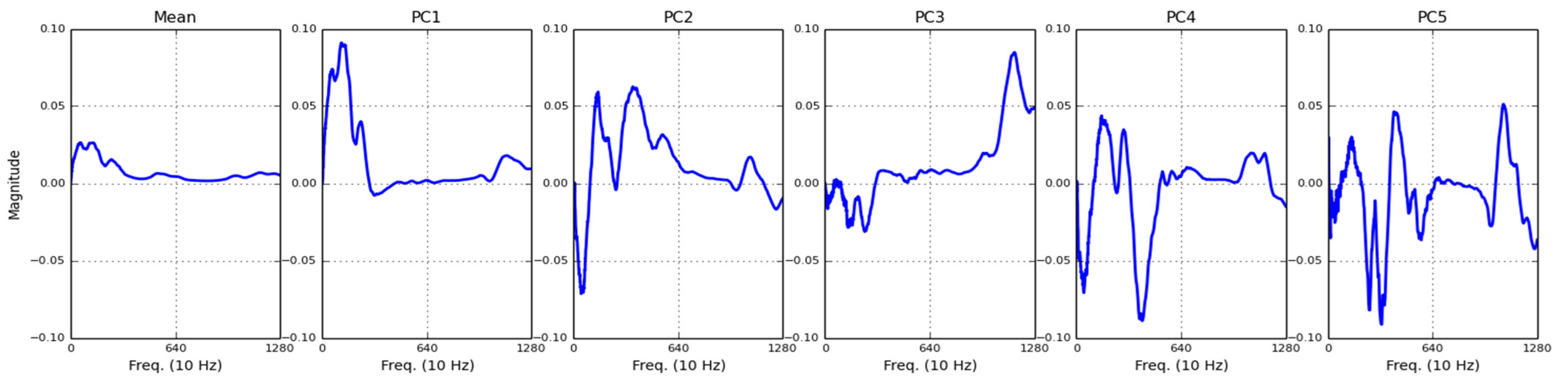
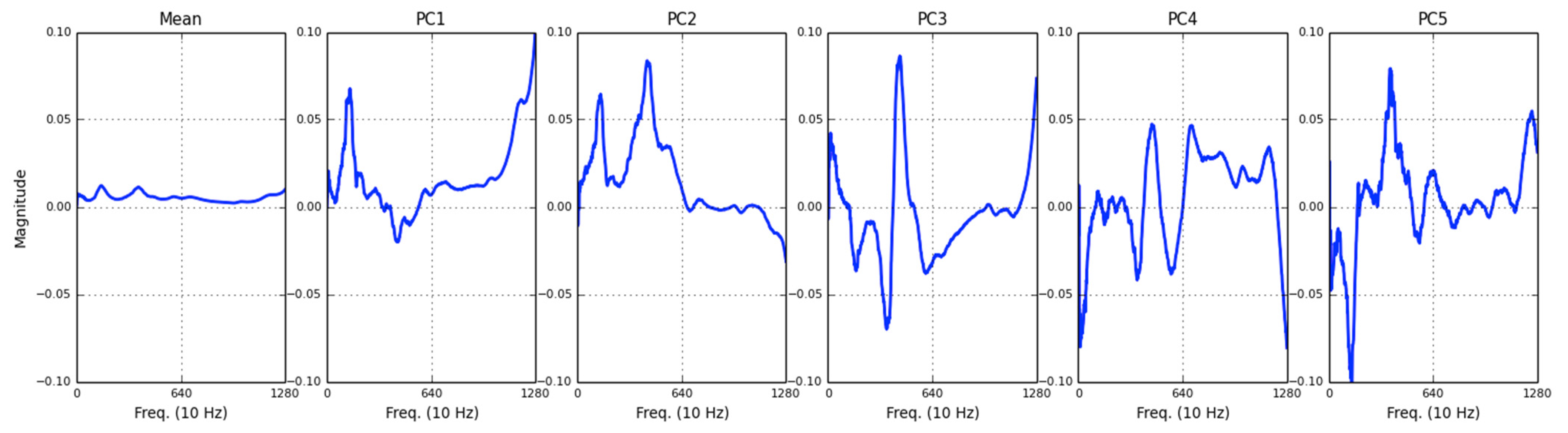
- Feature extraction is conducted using the principal component analysis (PCA) technique. The principal components (PCs) are calculated from the spectrogram of learning instances. Prognostic features are the coefficients of a spectrogram when projected onto the PCs.
- RUL estimation provides the RUL estimate for the test instance by identifying its similar prognostic feature sequences, which are generated synthetically from the learning instance using the data augmentation method.
3.3. Spectrogram Generation and Feature Extraction
- 1.
- Spectrogram Generation
- (1.a)
- Generate spectrograms from raw vibration signals using the STFT.
- (1.b)
- Smooth the spectrogram generated from (1.a) using a moving average filter in frequency.
- (1.c)
- Smooth the spectrogram obtained in (1.b) using a moving average filter on time.
- 2.
- Feature Extraction
- (2.a)
- Apply PCA to the spectrogram of the learning instance generated in (1.c) and select the first five eigenvectors as the principal components for dimension reduction.
- (2.b)
- Project the spectrograms onto the PC obtained in (2.a). The coefficients of projection are the prognostic features.
3.4. RUL Estimation
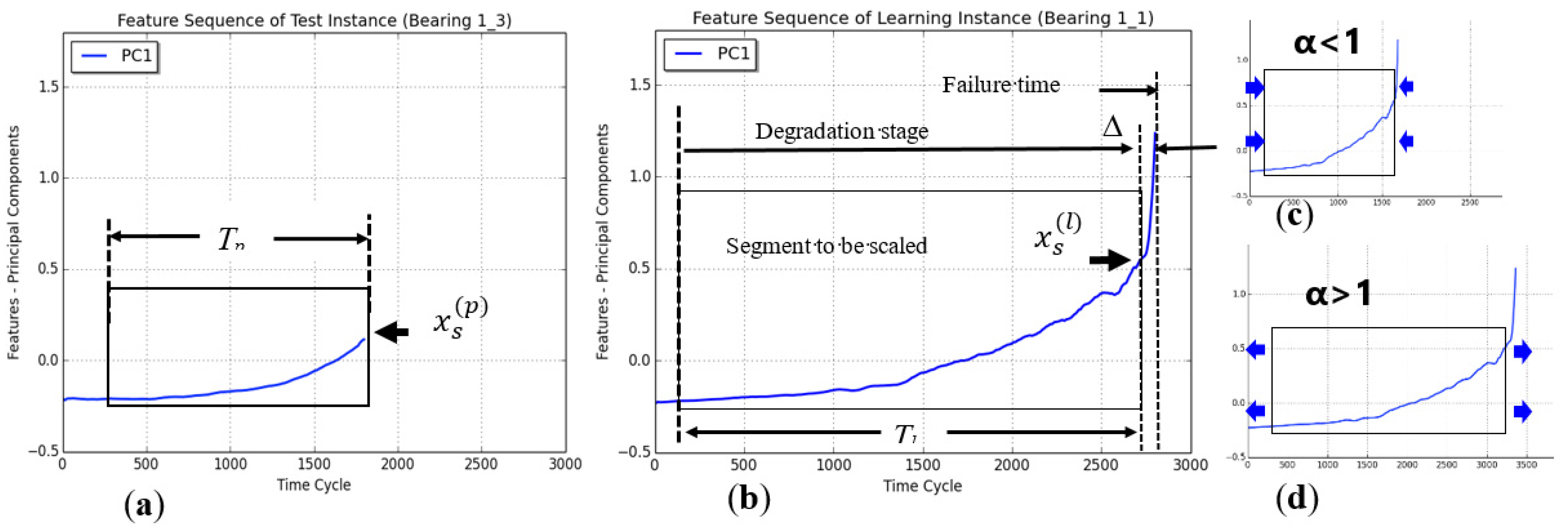
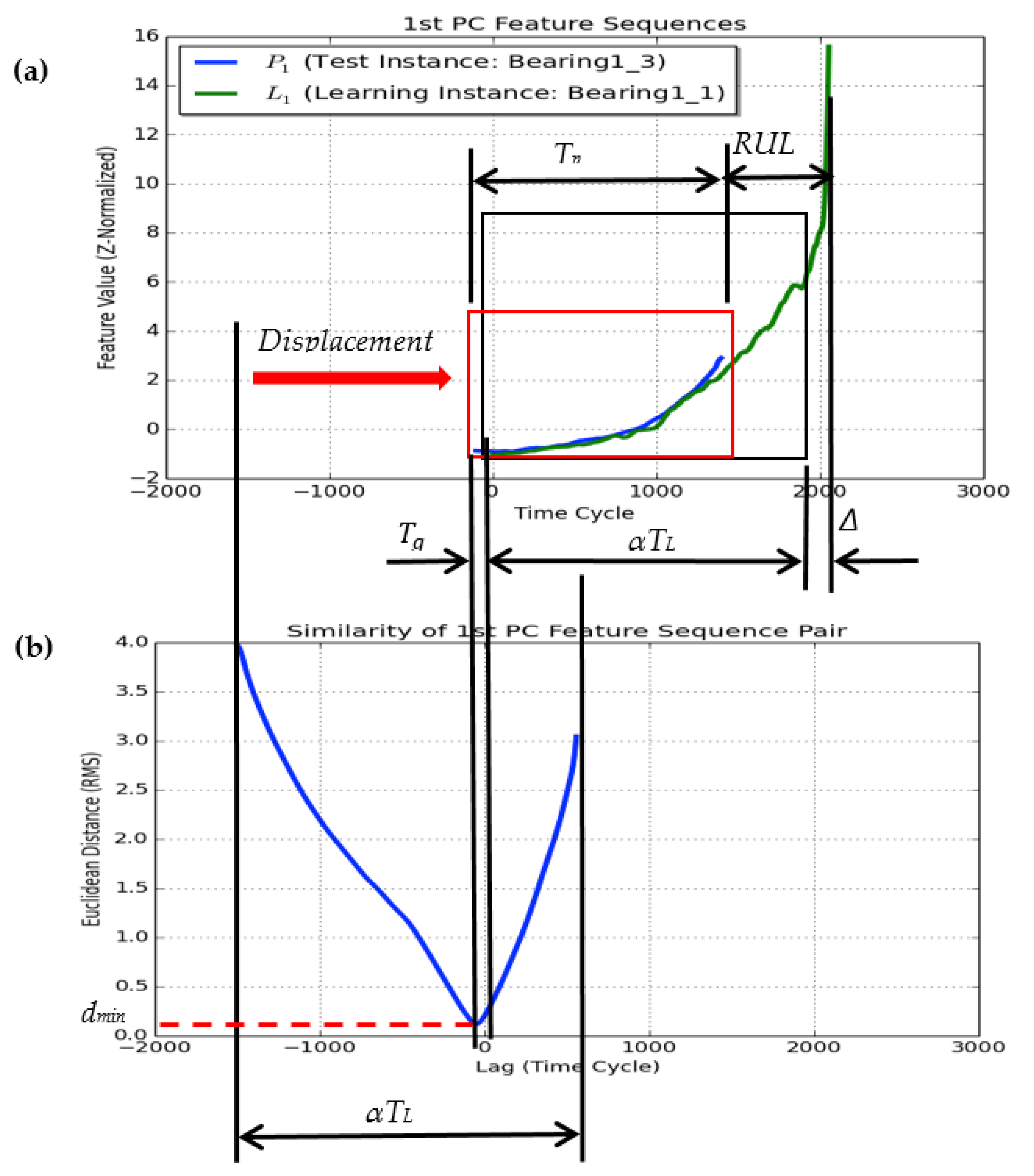
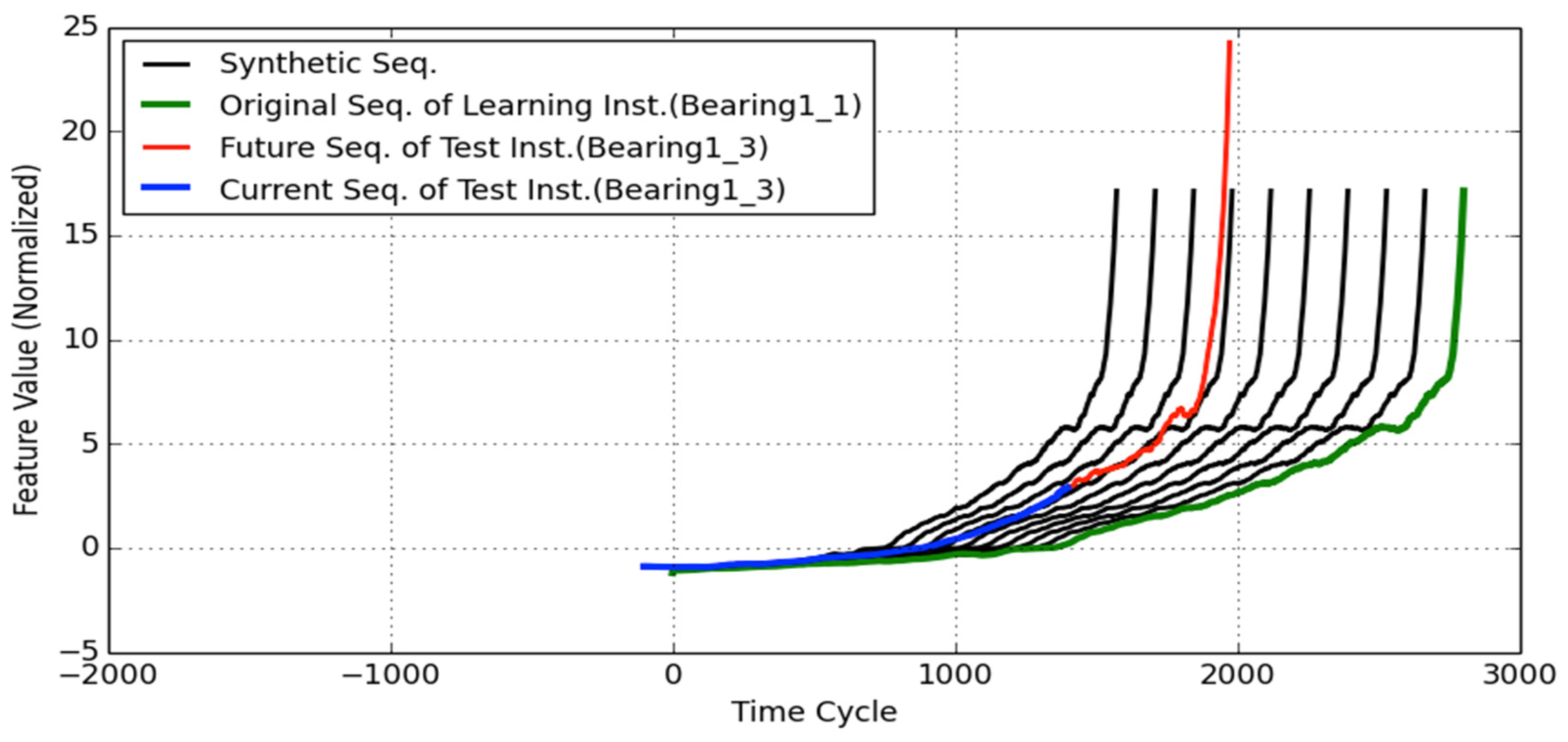
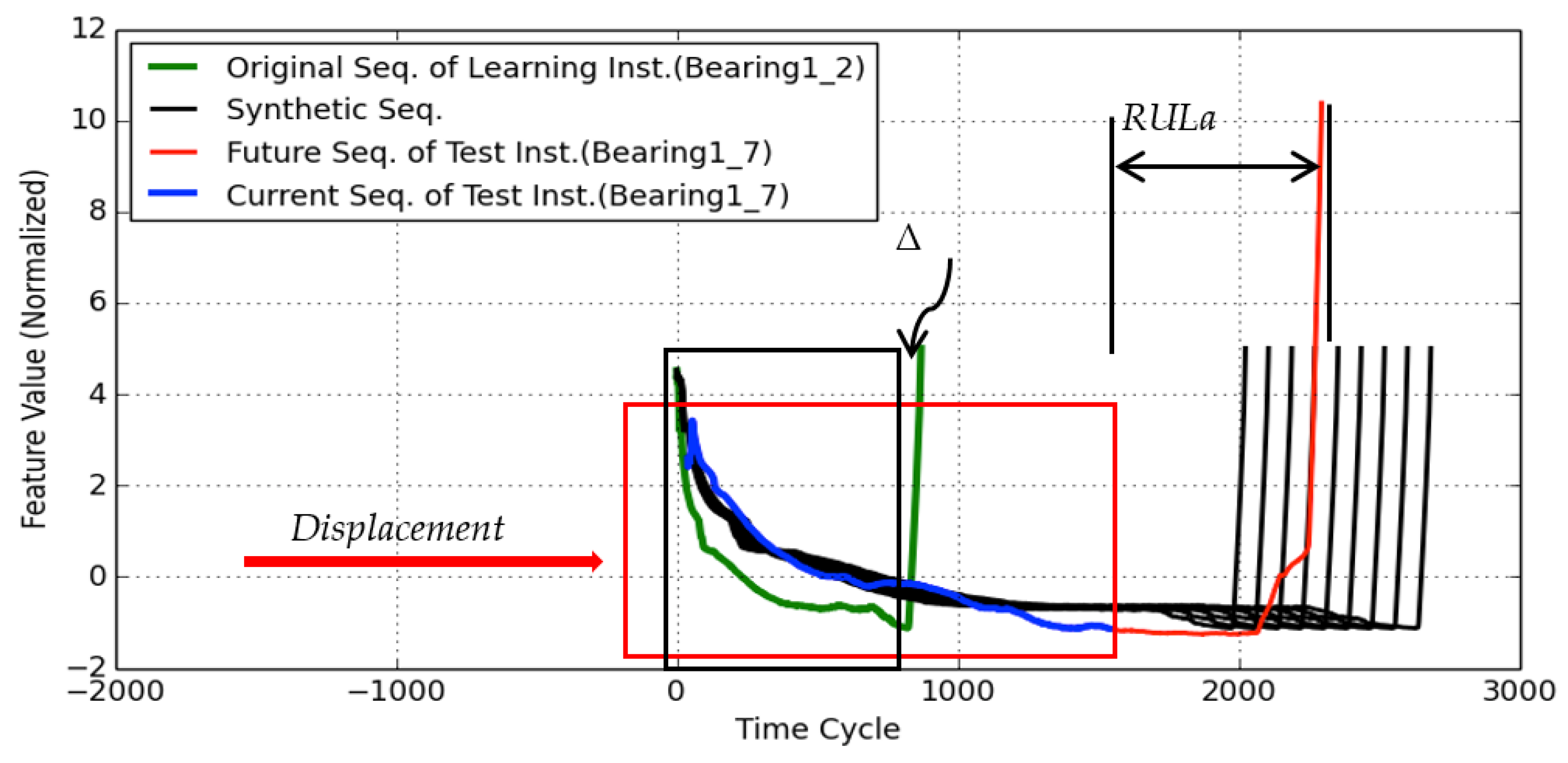
3.4.1. Data Augmentation
3.4.2. Similarity Evaluation
3.4.3. Estimate Ensemble
- 1.
- Data Augmentation
- (1.a)
- Specify the pair of comparison feature segments within the test instance and learning instance, Pk and Lk (i.e., α = 1.0).
- (1.b)
- Generate multiple synthetic sequences Lk (i.e., α > 1.0 or α < 1.0) from the original one using the segment scaling method described in Section 3.4.1.
- 2.
- Similarity Evaluation
- (2.a)
- Compute the similarity measure as expressed in Equation (12) between the Pk and each sequence Lk using the similarity evaluation method as described in Section 3.4.2
- (2.b)
- Identify the minimum similarity measure dmin and the corresponding displacement with respect to Pk.
- (2.c)
- Repeat the steps (2.a) and (2.b) for each pair of sequences Pk and Lk.
- 3.
- Estimate Ensemble
- (3.a)
- Identify the best similarity matching pair of sequences from all the similarity evaluation results.
- (3.b)
- Select several learning sequences (e.g., 4 sequences in this study) around the best similarity matching sequence identified in (3.a).
- (3.c)
- Compute the final RUL estimate using Equations (16) and (17) based on the results obtained from the best matching sequence in (3.a) and the sequences selected in (3.b).
4. Results and Comparison
4.1. RUL Estimation for Test Instance Bearings
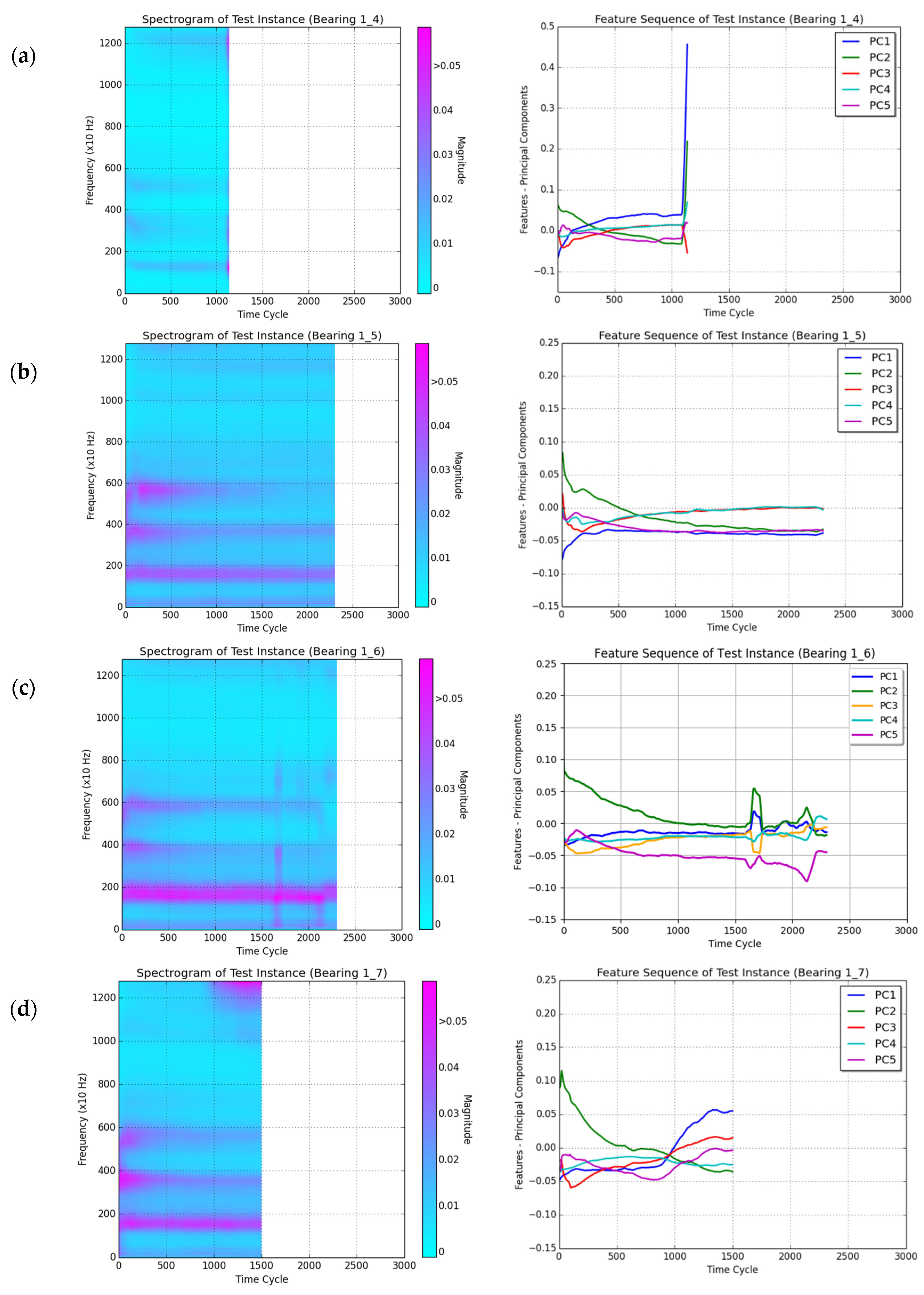
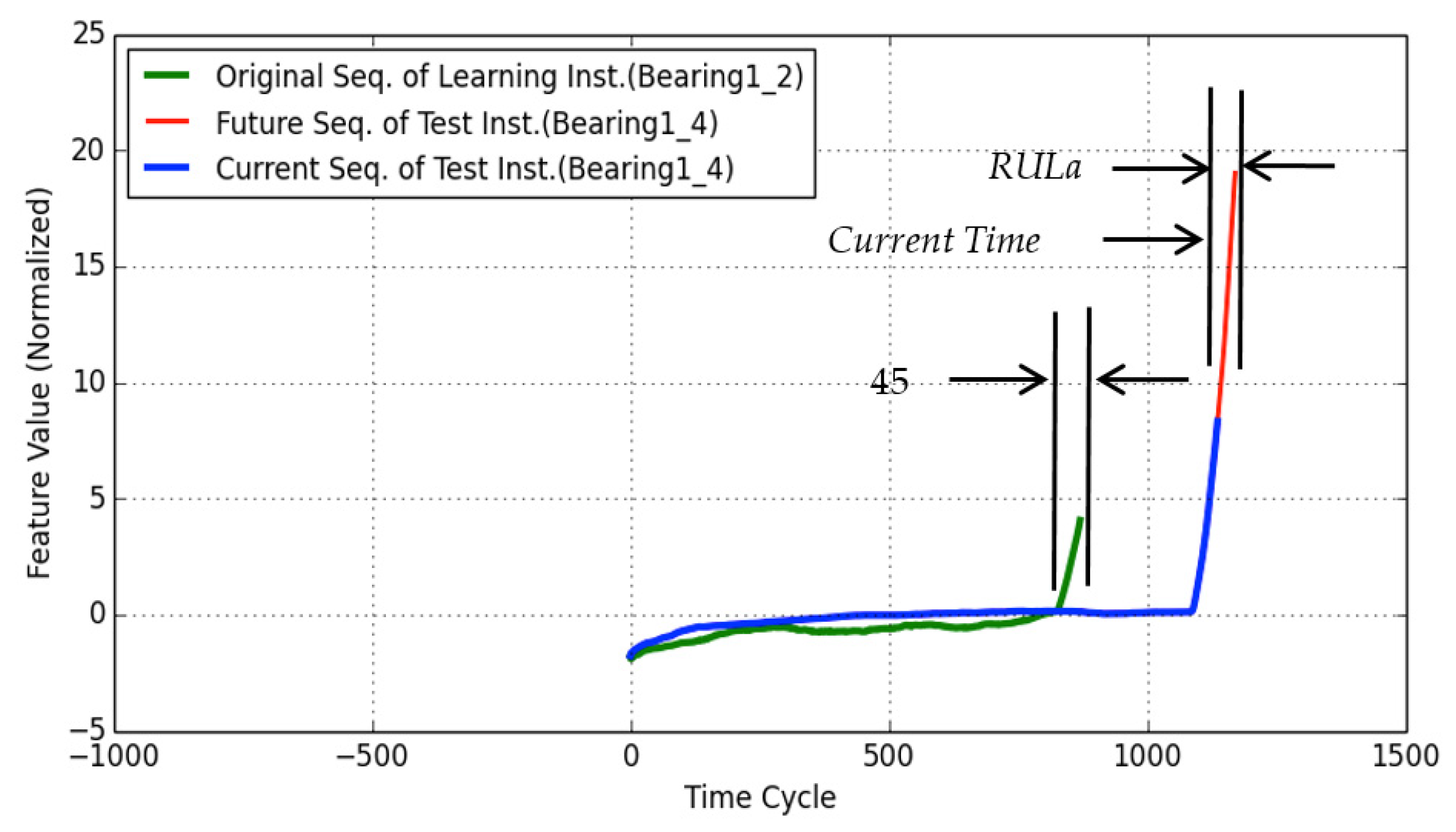
4.1.1. RUL Estimation for Test Instance Bearing1-4
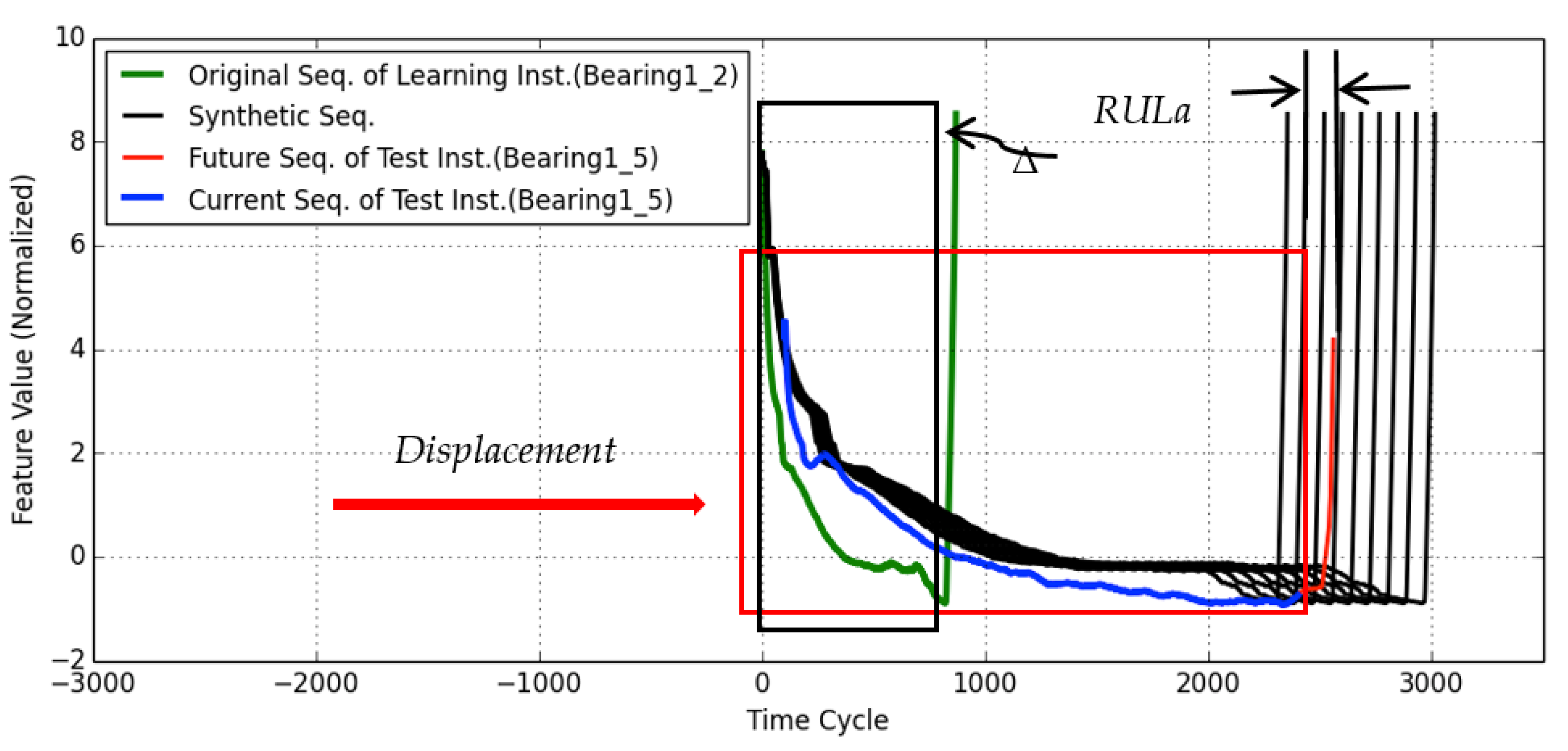
4.1.2. RUL Estimation for Test Instance Bearing1-5
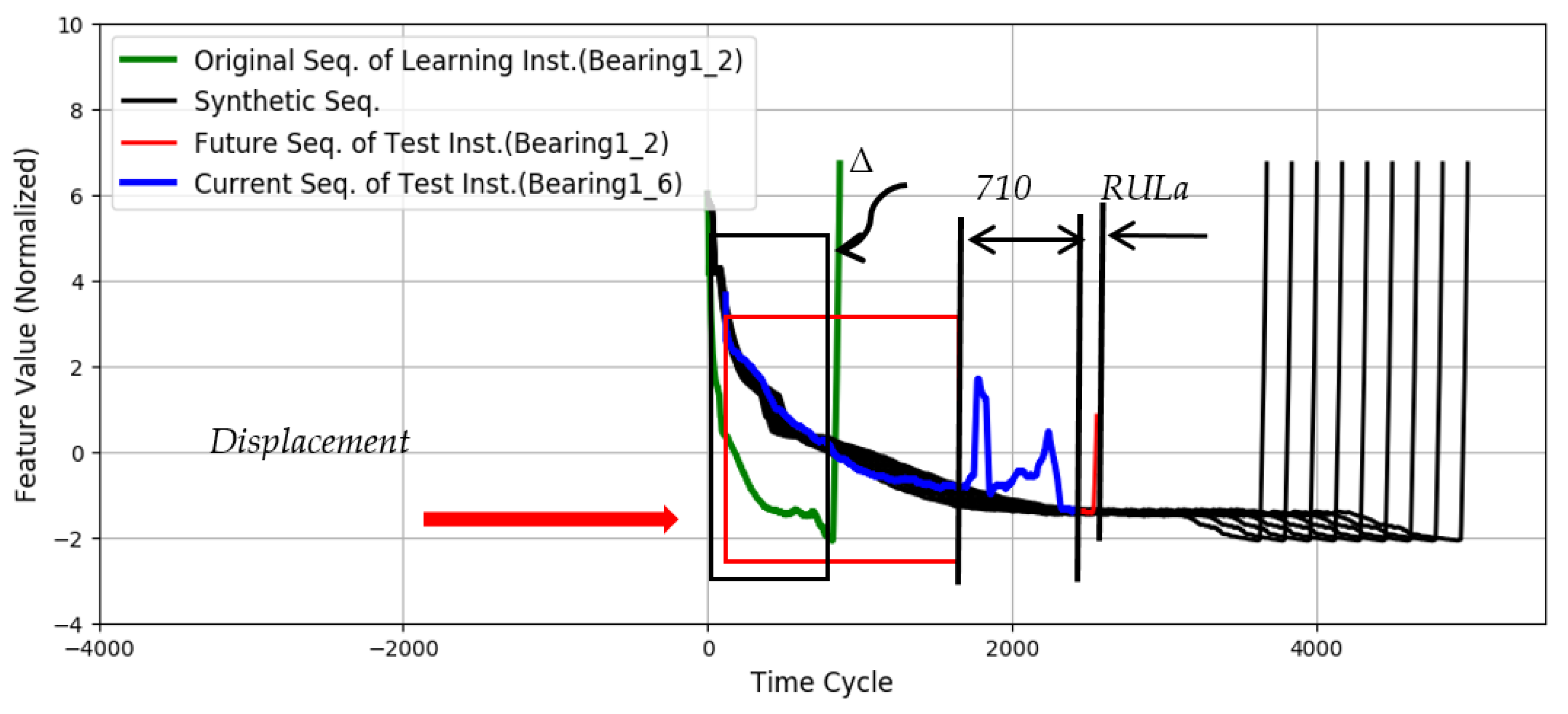
4.1.3. RUL Estimation for Test Instance Bearing1-6
4.1.4. RUL Estimation for Test Instance Bearing1-7
4.1.5. Summary of Results and Discussions
4.2. Comparison with Previous Studies
4.2.1. Review of Representative Solutions
4.2.2. Performance Comparison
5. Conclusions
- An efficient feature extraction method is employed for extracting the prognostic feature sequences. In this method, based on the spectrograms of vibration signals, the PCA technique is utilized to extract prognostic feature sequences for the bearing instance. For a pair of the learning and test instances to be compared, the data projection base (i.e., set of PCs) is derived from the spectrogram of the learning instance.
- Inspired by the data augmentation strategy adopted in the machine learning for image classification applications, the segment scaling method is proposed to generate a set of synthetic prognostic feature sequences by modifying the observed prognostic feature sequence of the learning instance.
- An ensemble method is used to aggregate the multiple RUL estimates obtained from similar prognostic feature sequences identified via the similarity evaluation. In the averaging function of the ensemble method, each RUL estimate is weighted by its corresponding similarity measure (i.e., RMS difference measure).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Liao, L.; Köttig, F. Review of hybrid prognostics approaches for remaining useful life prediction of engineered systems, and an application to battery life prediction. IEEE Trans. Reliab. 2014, 63, 191–207. [Google Scholar] [CrossRef]
- Tsui, K.L.; Chen, N.; Zhou, Q.; Hai, Y.; Wang, W. Prognostics and health management: A review on data driven approaches. Math. Probl. Eng. 2015, 2005, 481–495. [Google Scholar] [CrossRef] [Green Version]
- Filippenko, A.; Brown, S.; Neal, A. Vibration Analysis for Predictive Maintenance of Rotating Machines. U.S. Patent 6370957B1, 16 April 2002. [Google Scholar]
- Babu, G.S.; Zhao, P.; Li, X.L. Deep convolutional neural network-based regression approach for estimation of remaining useful life. In Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016; pp. 214–228. [Google Scholar]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long short-term memory network for remaining useful life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management, Dallas, TX, USA, 19–21 June 2017; pp. 88–95. [Google Scholar]
- Sun, Q.; Chen, P.; Zhang, D.; Xi, F. Pattern recognition for automatic machinery fault diagnosis. J. Vib. Acoust. 2004, 126, 307–316. [Google Scholar] [CrossRef]
- Khelif, R.; Malinowski, S.; Chebel-Morello, B.; Zerhouni, N. RUL prediction based on a new similarity-instance based approach. In Proceedings of the 23rd IEEE International Symposium on Industrial Electronics, Istanbul, Turkey, 1–4 June 2014; pp. 2463–2468. [Google Scholar]
- Ramasso, E.; Rombau, M.; Zerhouni, N. Joint prediction of continuous and discrete states in time-series based on belief function. IEEE Trans. Cybern. 2013, 43, 37–50. [Google Scholar] [CrossRef] [PubMed]
- Bonissone, P.P.; Varm, A.; Aggour, K. A fuzzy instance-based model for predicting expected life: A locomotive application. In Proceedings of the IEEE International Conference on Computational Intelligence for Measurement Systems and Applications, Messian, Italy, 20–22 July 2005; pp. 2–25. [Google Scholar]
- Xue, F.; Bonissone, P.; Varma, A.; Yan, W.; Eklund, N.; Goebel, K. An instance-based method for remaining useful life estimation for aircraft engines. J. Fail. Anal. Prev. 2008, 8, 199–206. [Google Scholar] [CrossRef]
- Wang, T.; Yu, J.; Siegel, D.; Lee, J. A similarity-based prognostics approach for remaining useful life estimation of engineered systems. In Proceedings of the 2008 IEEE International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–6. [Google Scholar]
- Wang, T. Trajectory Similarity Based Prediction for Remaining Useful Life Estimation. Doctoral Dissertation, University of Cincinnati, Cincinnati, OH, USA, 2010. [Google Scholar]
- Ramasso, E. Investigating computational geometry for failure prognostics. Int. J. Progn. Health Manag. 2014, 5, 1–18. [Google Scholar]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, Beijing, China, 23–25 May 2012; pp. 23–25. [Google Scholar]
- Pronostia. IEEE PHM 2012 Data Challenge Datasets. Available online: https://github.com/HBSG1996/phm-ieee-2012-data-challenge-dataset. (accessed on 21 September 2021).
- Jolliffe, I.T. Principal component analysis and factor analysis. In Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Forestier, G.; Petitjean, F.; Dau, H.A.; Webb, G.I.; Keogh, E. Generating synthetic time series to augment sparse datasets. In Proceedings of the 2017 IEEE International Conference on Data Mining, New Orleans, LA, USA, 18–21 November 2017; pp. 865–870. [Google Scholar]
- Le Guennec, A.; Malinowski, S.; Tavenard, R. Data augmentation for time series classification using convolutional neural networks. In Proceedings of the ECML/PKDD Workshop on Advanced Analytics and Learning on Temporal Data, Riva del Garda, Italy, 19–23 September 2016. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications, Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Harris, T.A.; Kotzalas, M.N. Essential Concepts of Bearing Technology; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Li, X.; Zhang, W.; Ding, Q.; Sun, J.Q. Intelligent rotating machinery fault diagnosis based on deep learning using data augmentation. J. Intell. Manuf. 2020, 31, 433–452. [Google Scholar] [CrossRef]
- Schilling, H.A.; Harris, S.L. Applied Numerical Methods for Engineers Using MATLAB; Brooks/Cole Publishing Co.: Pacific Grove, CA, USA, 1999. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1974, 18, 50–60. [Google Scholar] [CrossRef]
- González-Briones, A.; Villarrubia, G.; De Paz, J.F.; Corchado, J.M. A multi-agent system for the classification of gender and age from images. Comput. Vis. Image Underst. 2018, 172, 98–106. [Google Scholar] [CrossRef]
- Javed, K.; Gouriveau, R.; Zerhouni, N.; Nectoux, P. A feature extraction procedure based on trigonometric functions and cumulative descriptors to enhance prognostics modeling. In Proceedings of the IEEE Conference on Prognostics and Health Management, Gaithersburg, MD, USA, 24–27 June 2013; pp. 1–7. [Google Scholar]
- Mosallam, A.; Medjaher, K.; Zerhouni, N. Nonparametric time series modeling for industrial prognostics and health management. Int. J. Adv. Manuf. Technol. 2013, 69, 1685–1699. [Google Scholar] [CrossRef] [Green Version]
- Duong, B.P.; Khan, S.A.; Shon, D.; Im, K.; Park, J.; Lim, D.S.; Jang, B.; Kim, J.M. A reliable health indicator for fault prognosis of bearings. Sensors 2018, 18, 3740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cosme, L.B.; D’Anglo, M.F.S.; Caminhas, W.M.; Yin, S.; Palhares, R.M. A novel fault prognostic approach based on particle filters and differential evolution. Appl. Intell. 2018, 48, 834–853. [Google Scholar] [CrossRef]
- Kundu, P.; Chopra, S.; Lad, B.K. Multiple failure behaviours identification and remaining useful life prediction of ball bearings. J. Intell. Manuf. 2019, 30, 1795–1807. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. Deep learning-based remaining useful life estimation of bearings using multi-scale feature extraction. Reliab. Eng. Syst. Saf. 2019, 182, 208–218. [Google Scholar] [CrossRef]
- Xia, M.; Li, T.; Liu, L.; Xu, L.; Gao, S.; Silva, C.W. Remaining useful life prediction of rotating machinery using hierarchical deep neural network. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics, Banff, AB, Canada, 5–8 October 2017; pp. 2778–2783. [Google Scholar]
- Yoo, Y.; Baek, J.G. A novel image feature for the remaining useful lifetime prediction of bearings based on continuous wavelet transform and convolutional neural network. Appl. Sci. 2018, 8, 1102. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Zuo, M.J.; Qin, Y. Remaining useful life prediction of rolling element bearings based on health state assessment. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2015, 203–210, 1989–1996. [Google Scholar] [CrossRef] [Green Version]
- Sutrisno, E.; Oh, H.; Vasan, A.S.S.; Pecht, M. Estimation of remaining useful life of ball bearings using data driven methodologies. In Proceedings of the 2012 IEEE International Conference on Prognostics and Health Management, Denver, CO, USA, 18–21 June 2012; pp. 1–7. [Google Scholar]
- Wang, T. Bearing life prediction based on vibration signals: A case study and lessons learned. In Proceedings of the 2012 IEEE Conference on Prognostics and Health, Denver, CO, USA, 18–21 June 2012; pp. 1–7. [Google Scholar]
- Hong, S.; Zhou, Z.; Zio, E.; Hong, K. Condition assessment for the performance degradation of bearing based on a combinatorial feature extraction method. Digit. Signal Process. 2014, 27, 159–166. [Google Scholar] [CrossRef]
- Singleton, R.K.; Strangas, E.G.; Aviyente, S. Extended Kalman filtering for remaining-useful-life estimation of bearings. IEEE Trans. Ind. Electron. 2015, 62, 1781–1790. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Gontarz, S.; Li, J.; Radkowski, S.; Dybala, J. A model-based method for remaining useful life prediction of machinery. IEEE Trans. Reliab. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.; Jia, F.; Lei, Y.; Lin, J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, G.; Zhu, Z.; Li, S. A novel deep learning method based on attention mechanism for bearing remaining useful life prediction. Appl. Soft Comput. 2020, 86, 105919. [Google Scholar] [CrossRef]
- Huang, W.; Farahat, A.; Chetan, G. Similarity-based feature extraction from vibration data for prognostics. In Proceedings of the 2020 Annual Conference of the PHM Society, virtual conference, 9–13 November 2020; Volume 12, p. 10. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| α | 0.55 | 0.60 | 0.65 | 0.70 | 0.75 | 0.80 | 0.85 | 0.90 | 0.95 |
| dmin(α) | 0.2384 | 0.1857 | 0.1434 | 0.1190 | 0.1137 | 0.1225 | 0.1400 | 0.1621 | 0.1814 |
| RUL(α) | 423 | 473 | 523 | 578 | 635 | 693 | 756 | 823 | 887 |
| PC1 | PC2 | PC3 | PC4 | PC5 | |
|---|---|---|---|---|---|
| Bearing1-1 | 91.27% | 5.13% | 1.48% | 0.14% | 0.03% |
| Bearing1-2 | 49.78% | 37.45% | 9.24% | 1.71% | 0.98% |
| α | 2.80 | 2.90 | 3.00 | 3.10 | 3.20 | 3.30 | 3.40 | 3.50 | 3.60 |
| dmin(α) | 0.8149 | 0.4430 | 0.3562 | 0.3527 | 0.3750 | 0.3967 | 0.4166 | 0.4347 | 0.4495 |
| RUL(α) | 46 | 46 | 46 | 70 | 141 | 211 | 284 | 355 | 430 |
| α | 3.40 | 3.60 | 3.80 | 4.00 | 4.20 | 4.40 | 4.60 | 4.80 | 5.00 |
| dmin(α) | 0.2689 | 0.2371 | 0.2145 | 0.2009 | 0.1963 | 0.2000 | 0.2109 | 0.2264 | 0.2444 |
| RUL(α) | 2031 | 2187 | 2342 | 2497 | 2652 | 2806 | 2959 | 3111 | 3263 |
| α | 2.40 | 2.50 | 2.60 | 2.70 | 2.80 | 2.90 | 3.00 | 3.10 | 3.20 |
| dmin(α) | 0.2863 | 0.2741 | 0.2634 | 0.2537 | 0.2504 | 0.2517 | 0.2569 | 0.2644 | 0.2734 |
| RUL(α) | 481 | 581 | 661 | 740 | 819 | 908 | 977 | 1056 | 1135 |
| Test Instance (Bearing) | 1-3 | 1-4 | 1-5 | 1-6 | 1-7 |
|---|---|---|---|---|---|
| Learning Instance (Bearing) | 1-1 | 1-2 | 1-2 | 1-2 | 1-2 |
| Comparing PC Feature No. | 1st | 1st | 2rd | 2rd | 2rd |
| Similarity (dmin) | 0.1137 | - | 0.3750 | 0.1963 | 0.2504 |
| Last Time (time cycles) | 1800 | 1137 | 2303 | 2300 | 1500 |
| (time cycles) | 573 | 34 | 161 | 146 | 757 |
| (time cycles) | 642 | 23 | 160 | 45 | 822 |
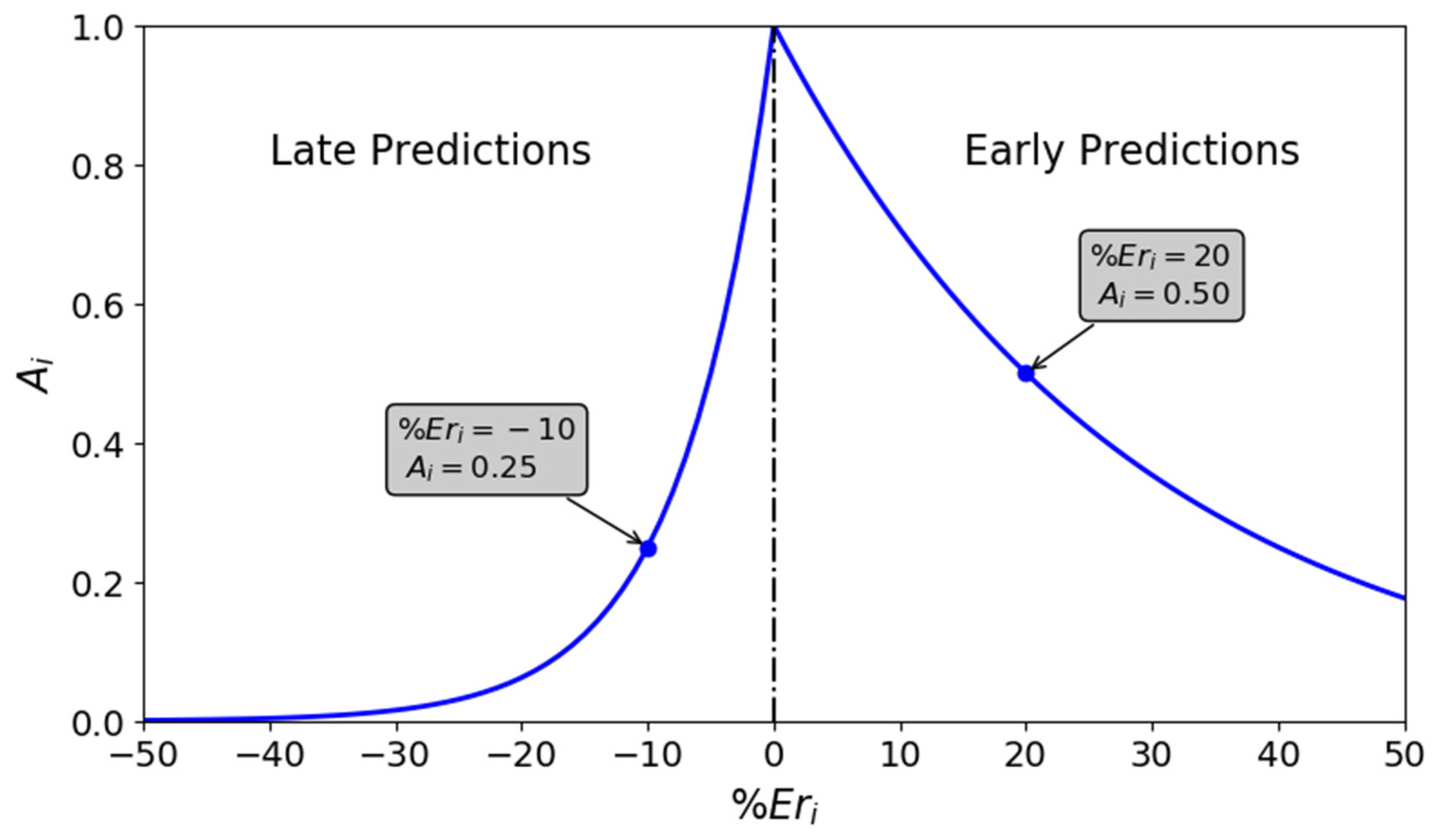
| Relative Error | −12.1% | 32.4% | 0.92% | 69.2% | −8.61% |
| Score | 0.1877 | 0.3229 | 0.9688 | 0.0909 | 0.3032 |
| M | 1 | 3 | 5 | 7 | 9 |
|---|---|---|---|---|---|
| Bearing1-3 | 0.2231 | 0.2243 | 0.2127 | 0.1877 | 0.1581 |
| Bearing1-5 | 0.6502 | 0.6082 | 0.7072 | 0.9688 | 0.1742 |
| Bearing1-6 | 0.0909 | 0.0909 | 0.0909 | 0.0909 | 0.0909 |
| Bearing1-7 | 0.3213 | 0.3011 | 0.3045 | 0.3032 | 0.311 |
| Overall (Average) | 0.3214 | 0.3061 | 0.3288 | 0.3877 | 0.1836 |
| Prognostic Features | RUL Prediction Model/Method | ||
|---|---|---|---|
| Extraction | Reduction | ||
| Sutrisno et al. [35] (2012) | * Average of Peaks | - Ratios of time durations of multiple degradation stages | |
| Wang [36] (2012) | * Peak, RMS, Kurtosis, Energy (in sub-frequency-band signals in both original and demodulated signals) | - PCA (Hoteling’s T2) | - Average of detect-to-failure times of learning samples (as the estimated RUL) |
| Hong et al. [37] (2014) | * IMFs from WPD-EMD | - SOM (MQE) | - GPR method for modeling degradation process |
| Singleton et al. [38] (2015) | * Variance * Entropy and Energy of a signature-frequency-band signal. | - Two exponential degradation models for the two extracted prognostic features, respectively. - EKF | |
| Lei et al. [39] (2016) | * Peak-to-Peak, Mean, Root-Mean-Square, Crest Factor, Shape Factor, Impulse Factor, Skewness, Kurtosis, Entropy, SD of IHC, SD of HIS * Energy of signals in sub-frequency-bands generated by WPD. | - SOM (WMQE) | - Paris-Erdogan model of degradation - PF |
| Guo et al. [40] (2017) | * Variance, Peak-to-Peak, Mean, Root-Mean-Square, Crest Factor, Wave Factor, Impulse Factor, Margin Factor, Skewness, Kurtosis, Entropy (in both original and sub-frequency-band signals) * Energy of sub-frequency-bands generated by WPD | - Similarity, monotonicity, and correlation metrics - RNN | - Double exponential model of degradation processes - PF |
| Chen et al. [41] (2020) | * Five band-pass energy values of frequency spectrum (at each time cycle) | - RNN based on encoder–decoder /with attention | - Linear regression/extrapolation |
| Huang et al. [42] (2020) | * Similarity based features * Mean, Peak-to-Peak, SD, Energy, Skewness, Kurtosis, Entropy, Energy/Entropy | - RNN | - Nonlinear regression/extrapolation |
| Proposed Approach | * Spectrogram (over all time cycles) | - PCA | - An IBL approach with data augmentation and similarity evaluation |
| Test Bearing | Relative Error of RULe (%*Er) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Sutrisno et al. [35] | Wang [36] | Hong et al. [37] | Singleton et al. [38] | Lei et al. [39] | Guo et al. [40] | Chen et al. [41] | Huang et al. [42] | Proposed Approach | |
| 1-3 | 37 | 91.4 | −1.04 | 4 | −0.35 | 43.28 | 7.62 | 73.89 | −12.1 |
| 1-4 | 80 | 97.1 | −20.94 | 0 | 5.60 | 67.55 | −157.71 | 65.19 | 32.4 |
| 1-5 | 9 | 69.6 | −278.26 | 54 | 100 | −22.98 | −72.52 | 12.24 | 0.92 |
| 1-6 | −6 | 66.4 | 19.18 | 46 | 28.08 | 21.23 | 0.93 | 3.29 | 69.2 |
| 1-7 | −2 | 93.5 | −7.13 | 60 | −19.55 | 17.83 | 85.99 | 10.74 | −8.61 |
| Test Bearing | Sutrisno et al. [35] | Wang [36] | Hong et al. [37] | Singleton et al. [38] | Lei et al. [39] | Guo et al. [40] | Chen et al. [41] | Huang et al. [42] | Proposed Approach |
|---|---|---|---|---|---|---|---|---|---|
| 1-3 | 0.2774 | 0.0420 | 0.8657 | 0.8706 | 0.9526 | 0.2231 | 0.7679 | 0.0772 | 0.1877 |
| 1-4 | 0.0625 | 0.0346 | 0.0549 | 1.0000 | 0.8236 | 0.0962 | 0.0000 | 0.1044 | 0.3299 |
| 1-5 | 0.7320 | 0.0897 | 0.0000 | 0.1539 | 0.0313 | 0.0413 | 0.0000 | 0.6543 | 0.9688 |
| 1-6 | 0.5000 | 0.1000 | 0.5144 | 0.2031 | 0.3779 | 0.4791 | 0.9683 | 0.8922 | 0.0909 |
| 1-7 | 0.7579 | 0.0391 | 0.3722 | 0.1250 | 0.0665 | 0.5391 | 0.0508 | 0.6892 | 0.3032 |
| Overall | 0.4660 | 0.0611 | 0.3614 | 0.4705 | 0.4504 | 0.2758 | 0.3574 | 0.4835 | 0.3747 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Sun, Q. Bearing Prognostics: An Instance-Based Learning Approach with Feature Engineering, Data Augmentation, and Similarity Evaluation. Signals 2021, 2, 662-687. https://doi.org/10.3390/signals2040040
Sun J, Sun Q. Bearing Prognostics: An Instance-Based Learning Approach with Feature Engineering, Data Augmentation, and Similarity Evaluation. Signals. 2021; 2(4):662-687. https://doi.org/10.3390/signals2040040
Chicago/Turabian StyleSun, Jun, and Qiao Sun. 2021. "Bearing Prognostics: An Instance-Based Learning Approach with Feature Engineering, Data Augmentation, and Similarity Evaluation" Signals 2, no. 4: 662-687. https://doi.org/10.3390/signals2040040
APA StyleSun, J., & Sun, Q. (2021). Bearing Prognostics: An Instance-Based Learning Approach with Feature Engineering, Data Augmentation, and Similarity Evaluation. Signals, 2(4), 662-687. https://doi.org/10.3390/signals2040040