1. Introduction
The DFT is a function that decomposes a discrete signal into its constituent frequencies. Computing the DFT is often an integral part of DSP systems, and so its efficient computation is very important. As is well known, the founding of DSP was significantly impacted by the development of the Cooley–Tukey FFT (Fast DFT) algorithm [
1]. If
x is a discrete signal of length
N, the DFT of
x is given by
where
. If
F is the Fourier transform matrix whose elements are the complex exponentials given in (
1) taken in the proper order, the DFT
X of
x can be written
The matrix
F is unitary, i.e., the scaling factor
from (
1) is included in
F. This is in contrast to the conventional DSP definition of
F, where the
scaling factor is pushed into the inverse transform as the scale
. Here, we assume that this scaling factor is included in
F.
As is well known, multiplication of two complex numbers in requires either four real multiplications and two real additions or three real multiplications and five real additions. Using traditional approaches of calculating the DFT using the various FFT algorithms does not completely eliminate the need for complex multiplications. Although complex multiplications can be easily implemented in sophisticated software like MATLAB or high level programming languages like Python, it is a harder task in hardware or low cost/low performance digital signal processors. For example, complex multiplication in VHDL or C programming language needs additional libraries, and the code or hardware produced is irregular (not vectorizable). Thus, we were motivated to look into a DFT computation method that eliminates the need for complex multiplications and additions.
The aforementioned Cooley–Tukey FFT algorithm is the most common method used for computing the DFT [
1], though in a modified form to exploit the advantages of the
butterfly using the split-radix method [
2]. This algorithm uses the divide and conquer approach that decomposes the DFT of a composite length
N into smaller DFTs to reduce the resulting computational complexity. As mentioned before, using the Cooley–Tukey FFT algorithm requires the multiplication by complex twiddle factors (these are constants of magnitude 1 in
) which stitch the smaller length DFTs together when recombining to produce the larger
N length DFT. Even considering the prime factor FFT algorithm [
3], the smallest un-factorizable DFT will require complex arithmetic.
Our proposed method uses the real-valued eigenvectors of the DFT for computation and a combiner matrix that essentially replaces the twiddle factor multiplications. Our method uses only vector dot products and vector-scalar products. Therefore, our method has the potential to perform well on hardware with dedicated multiply-and-accumulate (MAC) units or on hardware designed to operate on one-dimensional arrays like vector processors. The eigenvectors obtained from the ortho-normalization of DFT projection matrices are slightly sparse, which further improves computational efficiency. However, there are a few disadvantages with our method. If the size of the DFT is a power of 2, the Cooley–Tukey FFT outperforms our method. Furthermore, the CORDIC algorithm [
4] will perform better on hardware that can efficiently do bit shifts. Another limitation, though relatively unimportant in today’s environment of inexpensive memory, is the need for extra memory to store the pre-computed eigenvectors. Our work done in [
5] showed the relationship between the eigenstructure of the discrete Hirschman transform and the eigenstructure of the DFT. That work inspired us to develop the method presented here. By extension, our method can also be used to calculate the discrete Hirschman transform first introduced in [
6]. This method can also be extended to other ortho-normal transforms which have real eigenvectors.
Our analysis has found that the proposed method requires fewer multiplications than when using a single stage Cooley–Tukey algorithm. In fact, if the proposed method is combined with recursive algorithms like the prime factor FFT, the number of multiplications are comparable to the Cooley–Tukey FFT of size ; . Moreover, this method is not restricted by the size of the DFT; unlike the Cooley–Tukey FFT which requires the input length N to be an integer power of 2, or the prime factor FFT which requires N to be a product of coprime numbers.
The methodology is derived in
Section 2, which shows the relationship between an input (data) vector, the DFT eigenvectors, and the Fourier transform output.
Section 3 deals with the computation of the inverse DFT. The DFT eigenvectors with some favourable properties were derived by Matveev [
7] and
Section 4 provides a brief description of that technique to find the eigenvectors. In
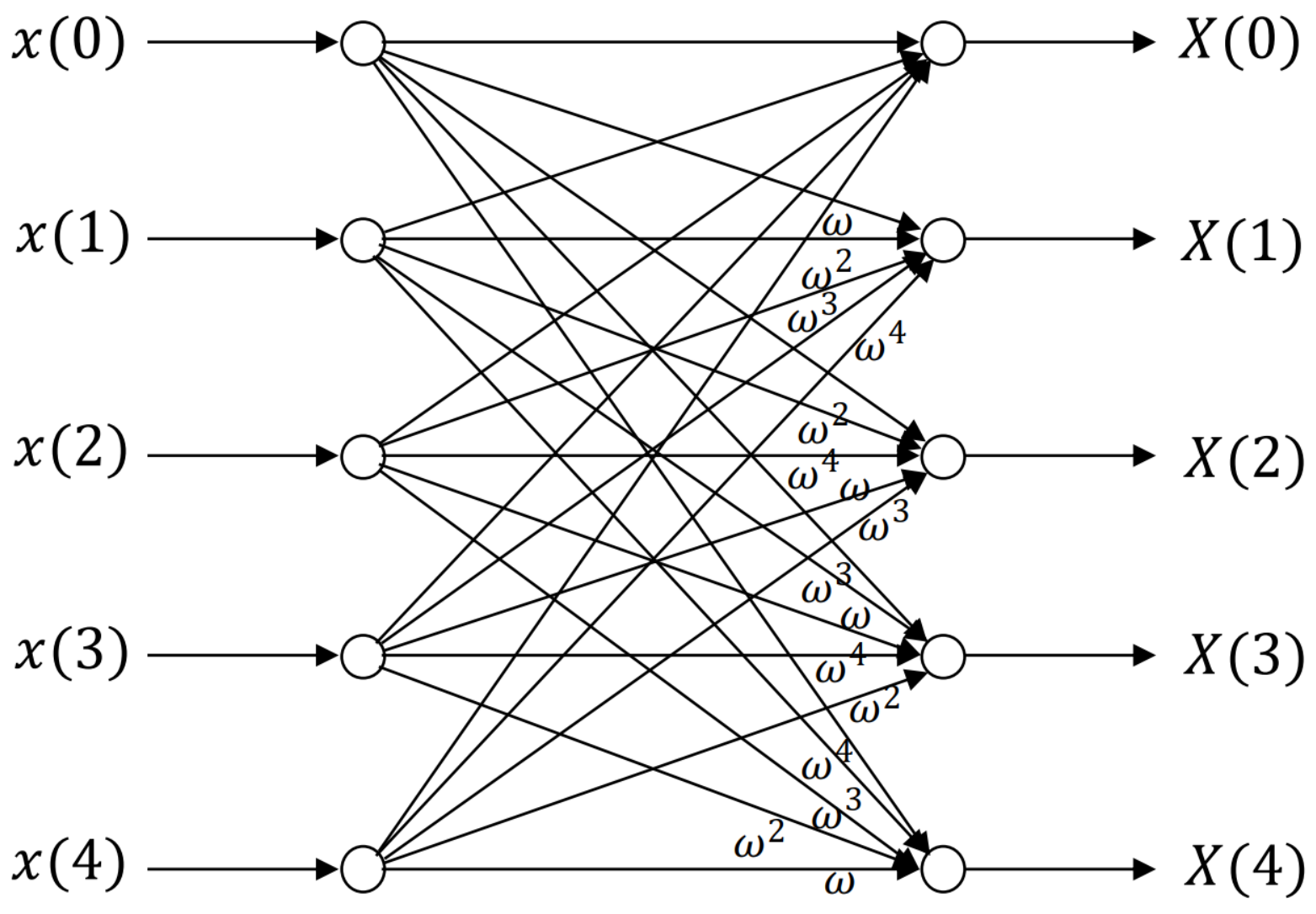
Section 5, a 5-point DFT example is shown using our method developed in this work. Accuracy of the proposed method is discussed in
Section 6. In
Section 7, the number of real-valued operations required for calculating the DFT using our algorithm is derived.
2. Methodology
A Fourier transform matrix
F is diagonalizable and can be decomposed into its Jordan form
where
V is a matrix whose columns are the eigenvectors of
F and
is a purely diagonal matrix containing the eigenvalues of
F. Since
F is unitary, the eigenvalues in
have magnitude one and the eigenvector matrix
V is also unitary. What may be less well-known is that it is possible find a real and orthonormal set of eigenvectors for
F [
7]. We use
as the complex conjugate transpose of
V and
as the transpose of
V. However, since
V is real,
is the transpose of
V, i.e.,
. Of course, since
V is unitary,
. So, we have the more useful Jordan form
Definition 1. The function converts a vector to a diagonal matrix.
Let
be a Euclidean basis vector where the
ith element is 1 and all other elements are zero. Thus,
,
and so on. If
,
is defined as
Theorem 1. If a and b are vectors, and and , then .
Proof. Let
and
.
This completes the proof. □
If
X is the Fourier transform of the vector
x and
F is the Fourier transform matrix,
where
,
and
such that
is a column vector containing the eigenvalues of
F. Note that
from Theorem 1.
In (
4),
adds the columns of the matrix product
in a particular manner defined by the eigenvalues of
F. It is well known that there are only four unique eigenvalues for the Fourier transform:
and
, where
is the imaginary unit [
8,
9]. Denote the algebraic multiplicity of the DFT eigenvalues as
,
,
and
for the eigenvalues 1,
,
j and
, respectively. So, for an
N-point DFT, we have
. From [
7], these multiplicities are
Without loss of generality, let
in (
4) be constructed such that the unique eigenvalues are grouped together as shown in (
6). This grouping simplifies our derivation. Note that the eigenvectors in the columns of
V will correspond with their respective eigenvalues in the vector
.
Let
u be an
matrix as defined in (
7) where the first row contains
1’s and
’s and the second row contains
1’s and
’s.
From (
6) and (
7) it is clear that
where
. Now (
4) can be rewritten
2.1. Formulations of Equation (8)
If the input vector
x is complex such that
, we can split the real and imaginary components by
where
and
. Since
, we can rewrite (
8) by splitting the real and imaginary parts such that
and
. It is clear that
. Now (
8) becomes
where
. Alternatively, (
9) can be implemented by modifying
u and keeping
z unchanged for the imaginary part. In this case (
9) changes to
where
is given by (
12). The first column of
contains
-1’s and
1’s and the second column contains
1’s and
-1’s. Thus,
can be formed by swapping the columns of
u followed by negating the first column.
In (
10) and (
11) both terms on the right-hand-side contain real and imaginary parts. This can be shown by factoring ():
where the
matrix
. The first column of
W contributes to the real part of the DFT and its second column contributes to the imaginary part of DFT. Therefore, (
8) and (
9) can be manipulated such that the components of the input that lead to the real and imaginary parts of the DFT are grouped together before computing
W. Let
,
and
. Create vectors
and
such that
where the notation
represents the
kth element of the vector
and
. Let
where
and
. It is clear that
is a
matrix. Define a
matrix
as given in (
13). The first column of
is comprised of
1’s,
-1’s followed by
1’s; and the second column consists of
1’s,
-1’s,
1’s and
-1’s.
With this information, the third formulation of (
9) is obtained:
Another method to implement (
9) is by rearranging the
matrix. Define
as
where the column vector
is the
kth eigenvector of
F.
is a
matrix. Let
and
, where the semicolon represents the start of a new row. Thus,
and
are
vectors. Let
,
and
, where
has size
. Now (
9) can be rephrased as
Here we have presented four different formulations of (
9) via (
10), (
11), (
14) and (
15). Each of these formulations affects a different factor in (
8). In these equations the only complex component is contained in either
z or
. The vector
z or
is not necessary for the computational algorithm, only for theoretical completeness. Thus, all the multiplications and additions are real-valued. Therefore, we say that this method of computing the DFT is natively-real valued because it can be computed using operations whose operands are all real numbers (in
).
2.2. Real Inputs
If
x is real such that
, the four different forms given in (
10), (
11), (
14) and (
15) simplify to
which is exactly (
8) since
. This is very straightforward in (
10) and (
11). In both these cases the second term is 0 since
. For the other terms, the matrix product
or
simplifies to
. Since
x is real, the product
in (
8) results in an
matrix whose first column contains the real component of the DFT
X, and the second column is the imaginary component of
X. As mentioned before, the vector
z is not necessary for the computational algorithm;
z just clarifies that the first column is real and the second column is imaginary.
2.3. A Filter Bank Model/Interpretation
Since
, the diagonal entries of
are formed by the inner product of the DFT eigenvectors and the input
x. Let
where the column vector
is a DFT eigenvector. Thus
where the notation
represents the inner (dot) product of two vectors
a and
b. We use this to develop a filter bank description for the linear algebra in the above discussion. Specifically, we define the time reversed vector
of
. Now, filter the sequence
x through the FIR filter
to produce the
length output sequence
. Down-sample this output
by
N (i.e., selecting the middle term) yields the dot product
, i.e.,
, where
is the
Nth element of
. A similar procedure is applied to the other eigenvectors.
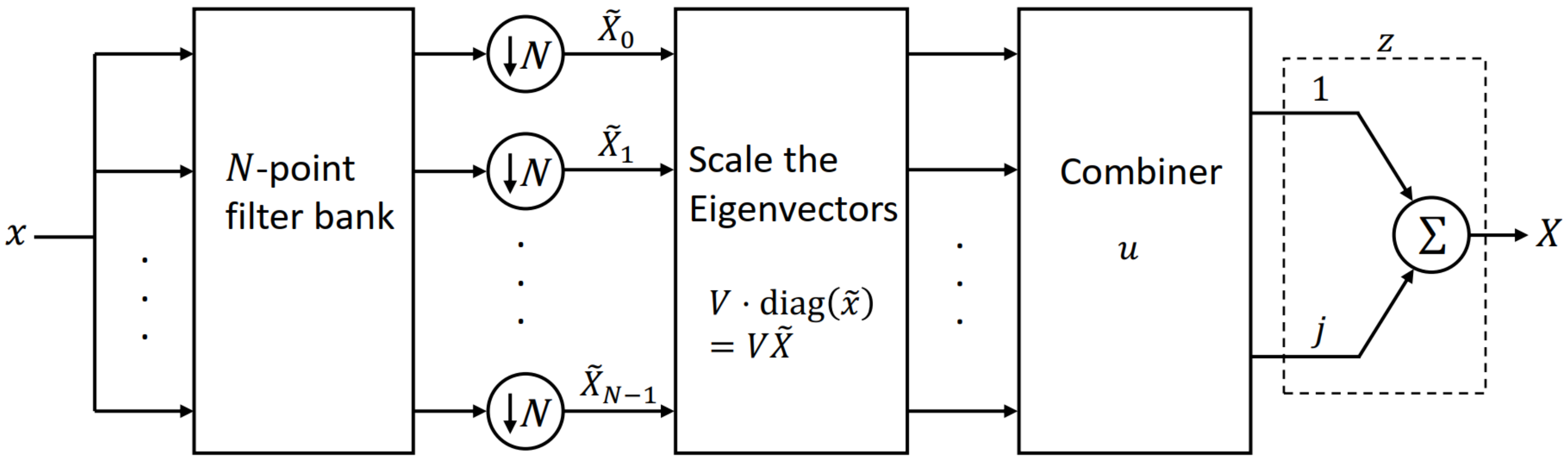
Now consider the matrix product
. Each diagonal entry of
scales the corresponding column of
V, i.e., each eigenvector is scaled by the corresponding filter output. These scaled eigenvectors are then added or subtracted in the specific manner defined by
u to give the real and imaginary components of the DFT result. This is why we call
u the “combiner”. The combiner adds and subtracts the real parts (from the
elements of
u) and the imaginary components (from the
of
u). The vector
z is only provided for theoretical completeness so that we can combine the real and imaginary components for the DFT
X. These steps are summarized in
Figure 1.
3. Inverse DFT
The IDFT (inverse DFT) computation follows a similar development. The IDFT has the same unique eigenvalues as the DFT, only they differ in the eigenvalue multiplicity for eigenvalues
j and
. Due to the conjugation difference in the DFT and the IDFT, the multiplicities of these eigenvalues are exchanged. Consequently, the eigenvalue multiplicities of the IDFT are
Similarly, the eigenvectors are unchanged from the DFT for the eigenvalues 1 and , but they are exchanged for eigenvalues j and . Thus, the eigenvector matrix for the IDFT can be obtained directly from the DFT eigenvector matrix V.
Using
, the steps described in
Section 2 can be used to compute the IDFT. The block diagram of the IDFT follows directly from these definitions used to replace the DFT computations used to derive
Figure 1. As in the case for the DFT, symmetries found in the input sequence can be used to improve the computational efficiency. Moreover, if the input or the output sequence is known to be real valued, the computational efficiency can be improved further. If the input to the IDFT is real, the procedure is similar to the DFT with real inputs.
However, if the output of the IDFT is known to be real, the input will be complex and will have some symmetries which can be exploited to improve computational performance. Let
, where
such that
and
. If
x is real,
will be even symmetric and
will be odd symmetric (ch. 5 [
10]). It is also known that the DFT eigenvectors are either even symmetric (for eigenvalues
) or odd symmetric (for eigenvalues
) [
8]. These eigenvector symmetries are further explored in
Section 7. Let
represent an even symmetric eigenvector for eigenvalues
and
denote an odd symmetric eigenvector for eigenvalues
. It is well understood that the product (Hadamard product) of two even sequences or two odd sequences will be even, and the product of an even and an odd sequence will be odd. We also know that the sum of the elements of an even sequence will be twice the sum of the first half of the sequence and the sum of the elements of an odd sequence will be zero. Combining this information for the calculation of the inner products for
and
in (
10), we get
and
,
require approximately
multiplications each. Therefore, the last
diagonal entries of
and the first
diagonal elements of
will be 0 where
. Thus, both the terms of (
10) will be purely real. Similarly, for (
14),
since
again leading to a reduction in the number of operations. Comparable patterns also exist for (
11) and (
15).
6. Accuracy and Performance of DFT Eigenvector
Computation
The two different methods used to calculate the orthonormal eigenvectors yield different computational accuracies. These differences arise due to the limitations imposed by the finite-precision data types that are used in real-world machines, and the varying methods used to produce the sparse eigenvectors. We compare the DFTs created using the Matveev method and the Gram–Schmidt orthonormalization of DFT projection matrices. All tests are run using the double-precision floating point data type on MATLAB version 2020b on a machine with Intel(R) Core(TM) i7-6700HQ @ 2.60GHz 4 core CPU, 8 GB RAM and Windows 10 operating system.
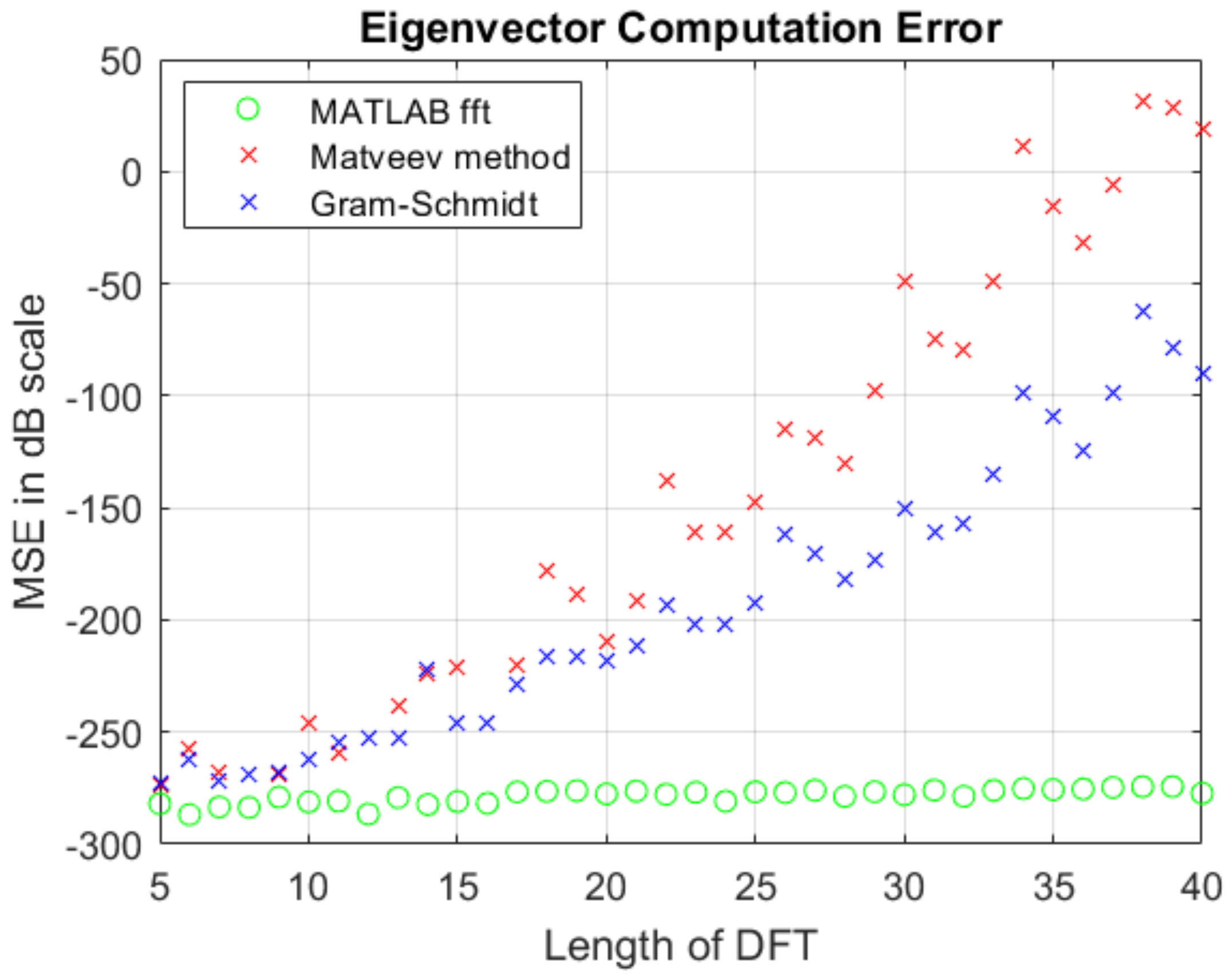
Figure 3 indicates the computational error due to imprecise DFT eigenvectors. Suppose
x is a vector in
and
. The figure shows the mean squared error (MSE) of
in decibels. The DFT and IDFT is calculated using Matveev eigenvectors, Gram–Schmidt orthonormalization of DFT projection matrices, and using the MATLAB fft() and ifft() functions. The MSE is calculated via (
21), (
22) and (
23) where
n is the length of the vectors
x and
y and the operator
represents the 2-norm of
x. The error shown in
Figure 3 is caused by the limitation imposed by the machine that was used to compute the eigenvectors. More powerful machines can be used to pre-compute the eigenvectors to a high enough precision such that this error can be eliminated.
where
and
Here represents sample out of 1000 samples as explained below.
For each
n-point DFT, 1000 vectors are randomly generated such that each element of a vector
x is an integer that lies between −128 and 127. These limits are chosen because we can represent the pixels of an 8-bit image after centering the pixel values to 0. For each vector
x, the corresponding
y and
are computed. Equation (
22) gives the average
value of the 1000 samples and (
21) gives the average MSE in dB. The plot in
Figure 3 shows the error after computing the forward and inverse DFT. Therefore, the error while finding the DFT in one direction will be slightly lower than what is shown and will depend on the size of DFT. Clearly, the computational performance of the eigenvector methods suffers a bit, especially as the length of the DFT increases. The differences are not significant for lengths up to 20, and the method’s complexity analysis in
Section 7 will show why these approaches are attractive.
The time required to calculate the eigenvectors from the DFT projection matrices and orthonormalizing them with Matveev method and Gram–Schmidt process is summarized in
Table 1. In this table, the time is calculated for 10,000 executions of each of the methods and is shown in units of seconds. This is consistent with our rudimentary analysis of the computational complexity of each of the methods:
for Gram–Schmidt and
for Matveev method (assuming the required matrix determinant is computed in
complexity). This discrepancy arises from the need for calculating the determinant of the
matrix in the Matveev method, whereas the vector dot product can be calculated in
time for the Gram–Schmidt process.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}