1. Introduction
Strawberry powdery mildew (
Sphaerotheca macularis) is a polycyclic disease, caused by a fungal pathogen, which affects petioles, leaves, runners, flowers, and fruits that appear to be specific to strawberry plants [
1,
2]. Particularly, powdery mildew (PM) disease begins with white powder on the leaf surface, so the front side of the leaf images are needed to detect the disease [
3]. Healthy leaves are saw-tooth shape in the edge with dark green colour and have no discoloration or defect on the leaf surface. However, strawberry leaves infected with PM are deformed as the edge faces upward. The edges of the leaves have a purplish hue, and the underside and upside of the leaves appear to have been coated with fine white powder [
4]. The disease also impacts the plant’s photosynthetic ability influencing fruit quality, growth potential, and productivity [
5]. Plant fruit quality and yield are closely tied to appropriate disease management and control of this disease. The ability to detect disease at early stages when less than 10 white spots begin to appear is essential to be able to apply suitable controls in order to decrease impacts on fruit quality [
6]. Plant diseases have unique developmental characteristics and behaviors that can aid in their detection [
7]. Although the application of fungicides is the most effective way to control the disease of the crops, it is desirable to minimize the use of fungicides as cost and environmental problems increase for growers. Therefore, understanding the distribution and severity of disease before applying fungicides is very useful information for growers [
8]. Development of accurate and rapid techniques to detect plant diseases is of critical importance to the fruit and crop industry.
Image processing-based approaches can be fast and accurate in detecting plant diseases [
9]. Digital images form important data units that can be analyzed to generate key pieces of information across a range of applications [
10]. Since the early 2000s, imaging techniques such as hyperspectral, multispectral, thermal, and colour imaging have been developed to solve various problems in agriculture. In terms of hyperspectral imaging, Qin et al. [
11] extracted the information from the spectrum which was used to determine the health of the crops. The ultra-spectral images of 450–930 nm was utilized to distinguish the canker and other damages on the Ruby red grapefruit with 96% accuracy. Rumpf et al. [
12] automatically detected the early disease of the sugar beet leaves with 97% of the classification accuracy by using SVM based on hyperspectral reflectance. In terms of multispectral imaging, Laudien et al. [
13] found that red spectra from 630 nm to 690 nm and near infrared spectra from 760 nm to 900 nm are important areas in agricultural applications. They detected and analyzed a fungal sugar beet disease with high resolution multispectral and hyperspectral remote sensing data. In terms of thermal imaging, Chaerle et al. [
14] reported that heat around the tobacco mosaic virus (TMV) disease spots on the leaves was monitored before the disease symptoms appeared on the tobacco leaves, and thermal imaging technique was used to visualize that heat in areas infected with TMV. Besides, the red-green-blue (RGB) colour coordinates are cost-effective and the most general colour system. Kutty et al. [
15] extracted regions of interest from the RGB colour model and categorized watermelon anthracnose and downy mildew leaf disease by using neural network. Khirade and Patil [
16] converted RGB images into Hue, Saturation, and Intensity (HSI) and used them for disease identification. Green pixels were recognized using k-means clustering, and various threshold values were obtained using the Otsu’s method. Kim et al. [
17] analyzed images collected for grapefruit peel disease recognition and achieved the best classification accuracy of 96.7%.
Various studies have reported success with image processing-based technology, as a plant disease identification mechanism [
18,
19]. Schor et al. [
20] applied image processing techniques as an automated diseases detection tool capable of ensuring timely control of PM and
Tomato spotted wilt virus (TSWV) diseases. This system also increased crop yield, improved crop quality and reduced the quantity of applied pesticides on bell pepper. A thresholding-based imaging method proposed by Sena Jr et al. [
21] aimed to distinguish fall armyworm affected maize plants from healthy ones. Camargo and Smith [
22] used colour transformation-based image processing technique to identify the visual symptoms of cotton diseases. Textural feature analysis is also widely used as an image processing approach to extract key plant health information. Spatial variation pixel values are described by image textures [
23] to explain regional properties like smoothness, coarseness, and regularity [
24]. Colour co-occurrence matrix (CCM) based textural analysis was introduced for plant identification [
25] and leaf and stem disease classification [
26]. Xie et al. [
27] extracted eight features to develop a detection model for leaf early and late blight diseases from tomato leaves with co-occurrence matrix. However, it should be noted that the features themselves are not enough for object identification and need classifiers for further plant disease recognition.
Machine learning techniques, such as artificial neural networks (ANNs), support vector machines (SVMs), k-nearest neighbors (kNNs), and decision trees have been utilized in agricultural research [
28] as part of supervised learning. The ANNs, SVMs and kNNs classifiers have classified different plant diseases with higher success rate [
29,
30,
31]. Wang et al. [
32] reported improved control of tomato diseases by predicting late blight infections using ANNs. Pydipati et al. [
33] utilized backpropagation ANNs algorithm and colour co-occurrence textural analysis for citrus disease detection and achieved classification accuracies of over 95% for all classes. The researchers also claimed that an overall 99% mean accuracy was achieved when using hue and saturation textural features. Camargo and Smith [
22] detected visual symptoms of cotton crop diseases using SVMs classifier. The measurement of texture used as a useful discriminator for this detection. A method using kNNs to detect nitrogen and potassium deficiencies in tomato crops was proposed by Xu et al. [
34]. Conversely, VijayaLakshmi and Mohan [
35] suggested some limitations using SVM and kNN for leaf type detection by using colour, shape and texture features. Yano et al. [
36] found artificial neural network provide better accuracy compared with kNN and Random Forest (RF) classifier.
The potential to combine image texture-based machine vision and machine learning algorithms for plant disease detection is significant. To date, there has been no research conducted applying machine vision with different machine learning algorithms for PM disease detection in strawberry cropping systems. As the first step of detecting PM disease, an RGB camera was used as an image source, which can be extended to hyper-/multi-spectral camera or thermal camera as in other crop disease detection. Therefore, the main purpose of this research is to compare image texture-based machine vision techniques for PM disease classification using a series of supervised classifiers.
2. Materials and Methods
2.1. Study Area and Experimental Overview
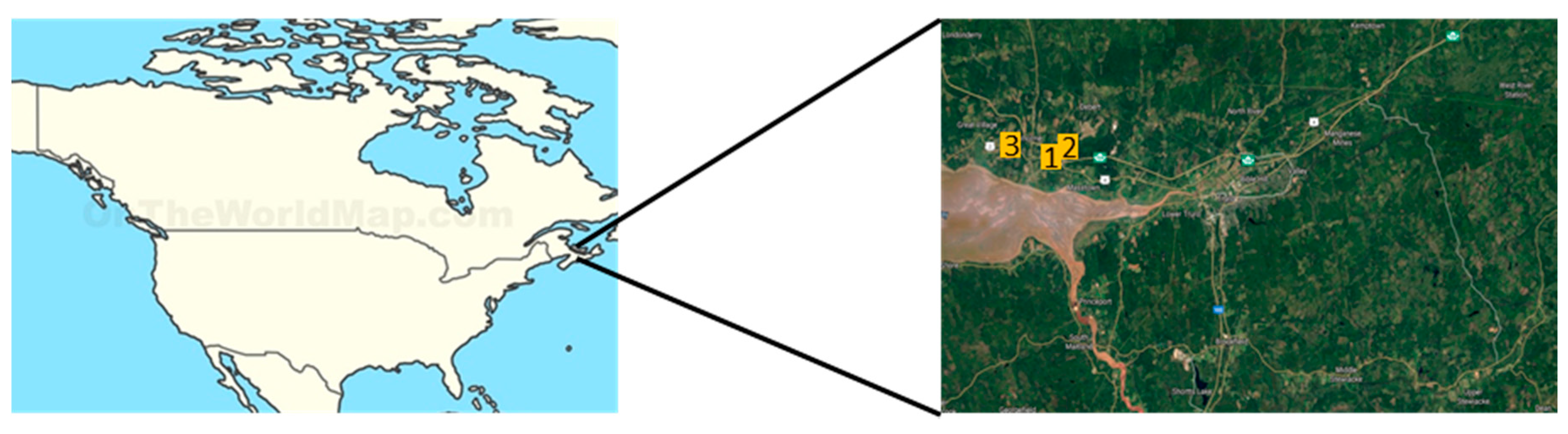
Three strawberry fields were selected in western Nova Scotia, Canada to collect PM infected and healthy plant strawberry image samples. The selected fields were located on two farms in Great Village: the Millen farm site I (Field I: 45.398° N, 63.562° W), Millen farm site II (Field II: 45.404° N, 63.549° W), and the Balamore farm site III (Field III: 45.413° N, 63.567° W). Strawberry leaves were collected throughout two growing seasons of the strawberry, summer and fall, between 10 a.m. and 4 p.m. in 2017–2018. They were randomly selected from fully grown plants which were producing strawberries. Separated leaves (from the plants) were stored in the icebox which had 5–7 °C internal environment and were brought to the lab directly. The images of the leaves were taken around 5–6 p.m. at the same day of leaf collection. Regional climate of
Figure 1 is the same as condition of the usual Nova Scotia, with the hottest temperatures of 24 °C in July and August in summer and the coldest of −11.8 °C in January in winter. The average annual precipitation in this area is 779.66 mm [
37]. Three strawberry varieties, Albion, Portola and Ruby June, were cultivated in Field I, Field II and Field III, respectively (
Figure 1).
Images can be collected under different lighting conditions, which means collection under natural light, and controlled lighting condition. In this experiment, initially two lighting conditions were set and processed for preliminary image acquisition. The first lighting condition was sunny condition and the second lighting condition was cloudy condition which we made the artificial cloud condition (ACC) with the black cloth. According to Steward and Tian [
38], they implemented segmentation algorithm with two sets of weed images which were photographed under sunny and cloud conditions. Estimation of weed density was highly related to lighting conditions. The variability occurred more in images that were taken under sunny conditions. The results of the correlation coefficient for images taken under cloud conditions was closer to 1 which means more stable about the variability. This aligned with our preliminary results that showed less accuracy under sunny conditions.
Thus, leaves were harvested from randomly selected plants across each of the fields and individual leaf images were taken under artificial cloud conditions (ACCs) to increase the accuracy.
2.2. Performance Evaluation
A total of 450 images were collected from all fields, specifically, 150 leaves from each field (total 3 fields). Each field data consisted of 75 healthy and 75 infected leaves. The 450 images were divided into two sets containing 300 images for training and 150 images for validation in three different classifiers. Internal, external and cross-validations were experimented for performance evaluation () of this study. Internal validations were conducted with different set of data from same field. Cross-validations were done with 4-fold and 5-fold, splitting the total data from all fields in 4 or 5 different subsets and then 3 or 4 sets of data were utilized for training and one set for validation. K-folds is the method used to maximize the use of available data for model training and testing. This avoids overfitting the predictive model and solves the problem of low data count. The data set was divided into k subsets and a holdout method was repeated k times. At each time, k-1 subsets were utilized for training and kth subsets was utilized for testing. Finally, the average error across all k trials was computed. Thereafter, every data point gets to be in a test set exactly once and gets to be in a training set k-1 times. In terms of external validation, Field I and Field II images were used to train the classifiers and Field III images were used for validation. Accordingly, Field I and Field III were used for training and Field II for validation. Final external validation was conducted with Field II and Field III for training and Field I for validation.
2.3. Image Acquisition
The image acquisition system consisted of two major components: an artificial cloud chamber and a digital single lens reflex (DSLR) camera model: EOS 1300D (Canon Inc., Tokyo, Japan) with a sensor resolution of 5184 × 3456 pixels and a 30 mm focal length lens for taking very detailed images. Individual leaves were collected by separating them from each bundle and the images were taken while the leaf sat on a white paper under the controlled environment, ACC. The images were taken at a height of 30 cm above the leaves and the same height was maintained for all image acquisitions. Exposure time and ISO gain were automatically controlled with an F/8.0 aperture to maintain both same depth of field and same ACCs. The images were processed with a hardware system of Intel® Core™ i5-3320M CPU @ 2.60 gigahertz (GHz) and 4.00 gigabyte (GB) Random Access Memory (RAM) laptop (Lenovo Group Ltd., Morrisville, NC, USA). The images were saved from the camera in the RAW format and were subsequently converted to Windows Bitmap (BMP) format to overcome loss related issues caused by image compressions.
2.4. Image Processing and Data Normalization
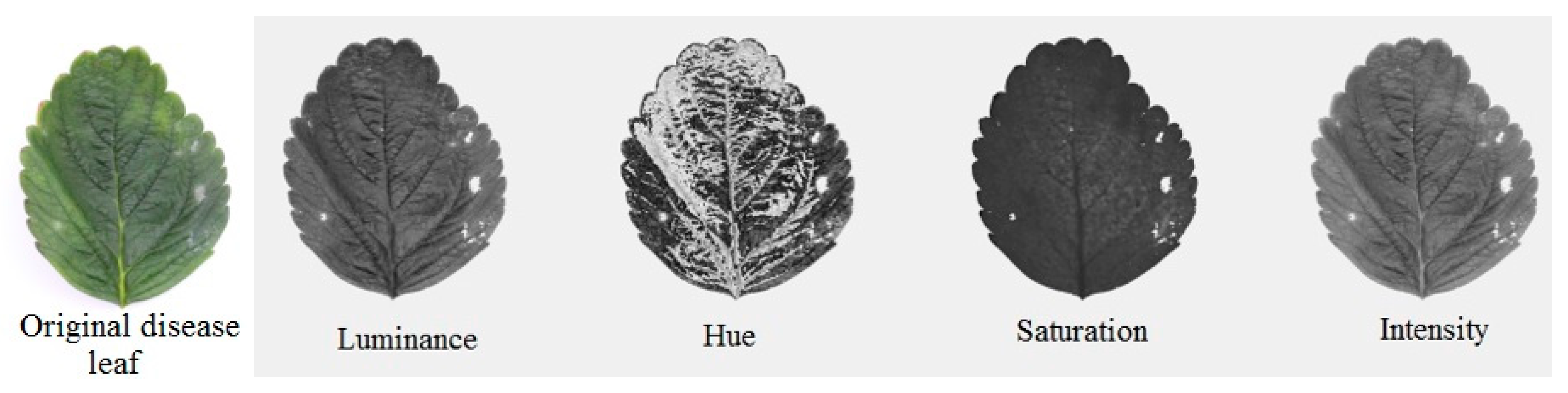
A graphic user interface (GUI) program was developed for image pre-processing, textural features extraction, and to save the features in a text file. The first step embraced in textural features extraction was the conversion of Blue, Green, and Red (BGR) channels to National Television System Committee (NTSC) standard for luminance and HSI colour models. Windows Graphics Device Interface (GDI) uses BGR channel space for bitmap representation, so BGR channel was selected when image processing in order to match with the GDI information. The luminance (Lm) of each pixel constituting the image was converted from 24-bit Bitmap (BMP) into 8-bit brightness image of NTSC standard, and Lm was calculated by the following equation by using BGR [
24].
In this study, BGR channels were converted to HSI, which represents the colour similar to how the human eye senses colour, to create three 2-dimensional arrays. The principle of converting BGR to HSI was calculated by Equations (2)–(5). First, θ
h represents the angle in Equation (2) then Hue (H) was calculated and normalized into [0,255]. The original BGR, Luminance, Hue, Saturation, and Intensity based images of healthy and PM infected leaves can be seen
Figure 2 and
Figure 3.
In Equation (6), p (m, n) represents the marginal probability function. Inside of p (m, n), m is the intensity level at a particular pixel, and n is the intensity level of a matching pixel with an offset. Of the offsets from 1 to 5, offset 1 gives the best results at any orientation angle such as 0°, 90°, 180°, and 360° [
39]. Shearer and Homes (1990) extracted 10 features based on CCM which contains the luminance and HSI [
24] (
Table 1).
A total of 40 features, 10 from each color plane (Luminance, Hue, Saturation, and Intensity), were extracted from one image which were utilized as inputs for classifiers. In order to improve the performance of the classifiers, the input data were normalized [
40]. The following equation was used for the normalization of the data.
where,
= Normalized value of input;
= Actual value of input;
= Minimum value of input;
= Maximum value of input.
2.5. Classifiers
In this study different types of classifiers were evaluated to determine the most effective ones at classifying strawberry PM disease characteristics using CCM based textural features analysis. In MATLAB software, various classification models from the data were trained by using classification learners. The three classifiers evaluated including the ANN, SVM, and kNN. Firstly, 9 parameters were used for ANN tuning. The epoch size of 15,000 was determined to be enough for the model structure to perform the classification rather than other epochs. The output range of tanh sigmoid was −1 to 1, that is, the transformed version of the logistic sigmoid with an output range of 0 to 1 and it was used as a mathematical function because it tends to be more fit well with neural networks [
41]. The proposed settings of the developed model are given in
Table 2.
Secondly, 4 different kernels were used as a parameter for SVM: Linear, Quadratic, Cubic, and Fine Gaussian. SVM can train when there is more than one class in the data in the classification learner. Each classifier type differs depending on prediction speed, memory usage, interpretability, and model flexibility. Linear SVM is the most commonly used because of its fast prediction speed and easy interpretability compared to other kernels. Fine Gaussian SVM, on the other hand, is more difficult to interpret than Linear SVM, but offer more model flexibility and finer separation of classes than other kernels.
Lastly, 4 different kernels were used as a parameter for kNN: Fine, Cosine, Coarse, and Cubic. Model flexibility decrease with the number of neighbours setting. kNN with Fine is showing the detailed distinctions between classes and the number of neighbours was set to 1. kNN with Coarse is showing the medium distinctions between classes and the number of neighbours is set to 10. kNN with Cosine uses Cosine distance metric and kNN with Cubic has slower prediction speed than Cosine kNN [
42].
2.5.1. ANN Classifier
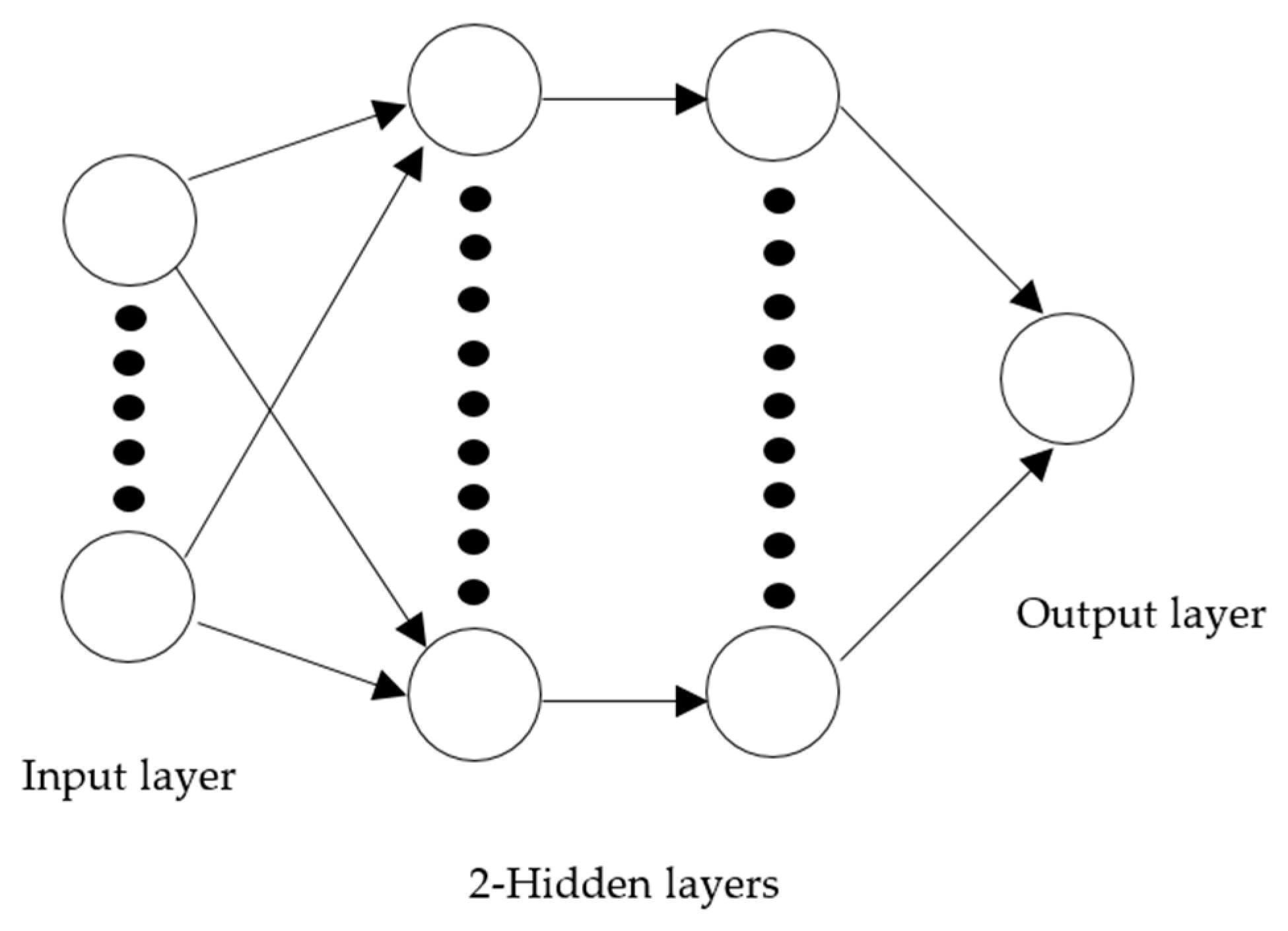
In this study, textural features of the CCMs were used to provide the input data for training the ANN model. Neural network models were found to incorporate all the textural features in the discrimination scheme. Peltarion Synapse (Peltarion Corp., Stockholm, Sweden) was used for classifying the textural features, as well as images of healthy and PM affected leaves. A back-propagation artificial neural network (BP-ANN) algorithm was applied for training of the proposed network. Total three model structures were examined in this experiment, and one of example is the 40-80-1 ANN network structure which represents forty nodes for the input layer, eighty nodes for two hidden layers, and one node for the output layer for the data analysis (
Figure 4). The extracted textural features were selected as inputs for the input layer and corresponding healthy or disease labels were established as an output in the output layer with Synapse Peltarion software. Four different functions, such as the tanh sigmoid, exponential, logistic sigmoid, and linear transfer were used to translate the input signals into output signals ranging from 1 to 2. The predictor model was used Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) to find the best model structure. The formulas for MAE is given by
, that is, multiplication between a division the total number of data point and the sum of the absolute value of the residual of the subtraction from actual output value,
to the predicted output value,
. The formulas for RMSE is given by
, that is, measurement of the differences between values predicted by a model and the values observed by giving how much error there is between two data sets.
The training process was initiated using randomly selected initial weights and biases. The experimental conditions involved a supervised training mechanism providing the network output by labelling. The MSE and RMSE values were used to determine the performance of the model structures. The activation, or non-linear function, was determined by the presence of particular neural features that determined the optimal weights. The neural network performed a non-linear transformation on the input variables (N) to achieve an output (M) by Equation (8).
where, M = Output;
f = Non-linear function; and
N = Input variables.
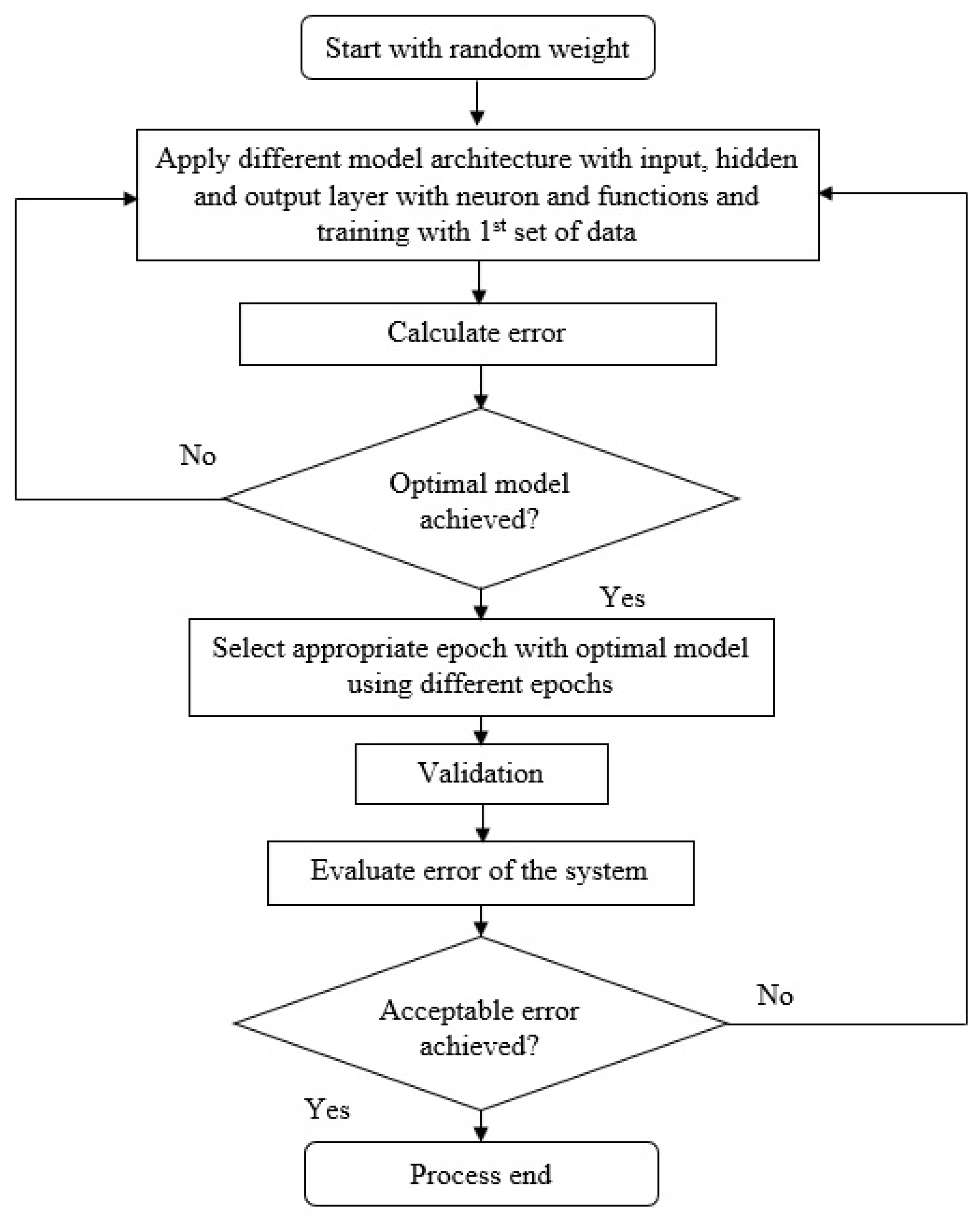
Three ANN model structures were developed and tested to discover a satisfactory mathematical function to process image data. Around twenty simulations of the ANN model were conducted to select the three optimal model structures. Although a complex network can be used, it is claimed that a hidden layer is sufficient to represent a continuous nonlinear function because overfitting can occur, as the number of hidden layers increases [
43]. All the selected models were run at an epoch size (iterative steps) of 15,000 with learning rate of 0.1. To determine the optimal epoch size, the best selected ANN model was operated at different epoch sizes at an interval of 1000 and the error values of MAE and RMSE were calculated at each interval. According to Madadlou et al. [
44], the epoch size has a major influence on error terms. The momentum rule of the developed models was 0.7 to establish a comparison of the processing capabilities of the different mathematical functions. The best model structure and mathematical function were selected based on lower MAE and RMSE values and by comparing the actual and predicted values. Finally, the model developmental process was completed having the acceptable errors (i.e., MAE < 0.003 and RMSE < 0.005) from predicted data set compared with actual data set. The MAE is a measure of absolute difference between actual and predicted observation and the RMSE is the square root of the average of squared differences between prediction and actual observation that measures the average magnitude of the error. After training the model, the performance of the ANN model was tested by employing the internal, external, and cross-validation separately (
Figure 5).
2.5.2. SVM Classifier
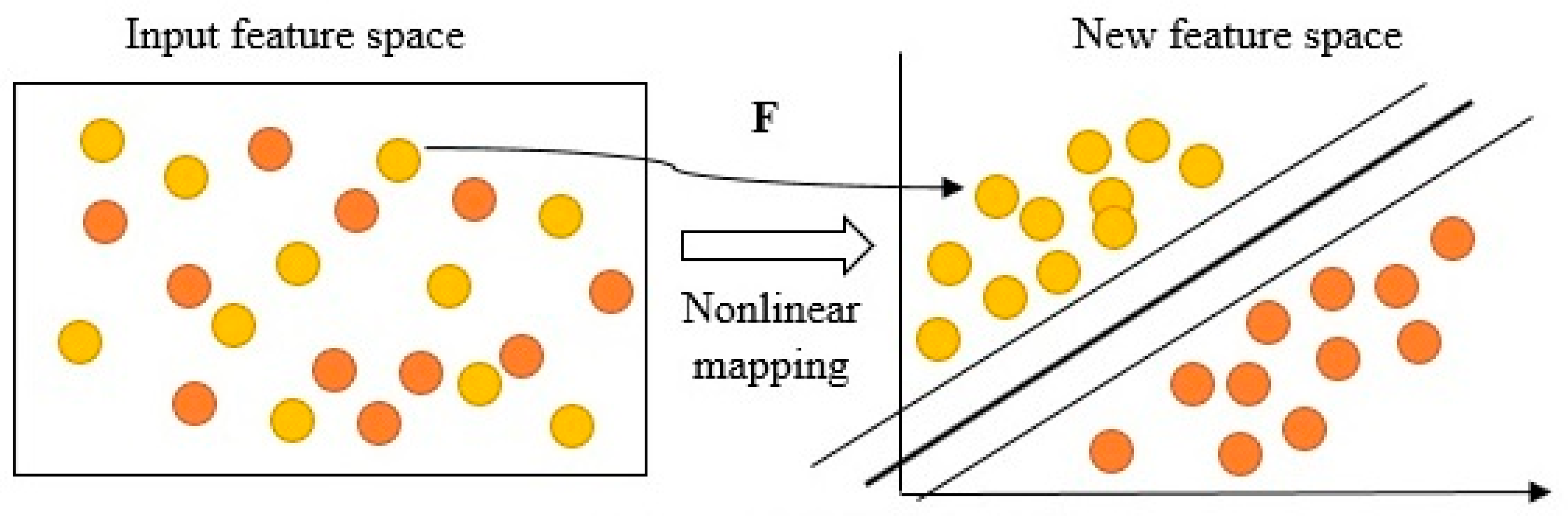
An SVM classifier was selected for the experiments based on previously established studies reporting efficient implementation and performance for high dimensional problems and small datasets. MATLAB
® Classification Toolbox version 2017a (MathWorks, Natick, MA, USA) was used for SVM classifier evaluation. The general concept of SVM (
Figure 6) is to provide a solution of classification problems by plotting the input vectors into a new high-dimensional space through some nonlinear mapping and constructing an optimal separating hyperplane that measures the maximum margin to separate positive and negative classes [
45]. The SVM constructs a hyperplane in the space to observe the training input vector in an n-dimensional space for classification that has the largest distance to the closest training data point of any class. A linear and separable sample sets belonging to separate classes are separated by the hyperplane. The generalization ability of SVM model is usually better as the distance between the closest vectors to the hyperplane is maximized. The mathematical form of SVM classifier is as follows:
where, specified data set mapping is made via a map function F from input space into higher dimension feature space Q (dot product space).
A linear learning algorithm was performed in Q which required the evaluation of dot products. If Q is of a higher dimensional value, then the right-hand side of Equation (9) will be very costly to compute [
46]. Hence, kernel functions are utilized using the input parameters to compute the dot product in the feature space.
Four different kernels such as linear, quadratic, cubic, and fine Gaussian were utilized for experimentation. Internal, external, and cross-validations were tested for performance evaluation of classifier. Two fields of data were used for training and one field of data was simultaneously utilized for the model validation. The external validation process began with exporting the model after development. The exported model tested the data from separate fields that were not used for training the model. Finally, the accuracy was determined based on correctly classified textural features from disease and healthy strawberry leaves.
2.5.3. kNN Classifier
Another supervised learning classifier evaluated in this study was the kNN. The kNN classifier is a non-parametric method that separates a test object according to the class of majority of its k
th nearest neighbour in the training set. It applies the Euclidean distance in the multidimensional space as a similarity measurement to separate the test objects. K represents the number of highly data-dependent tuning of neighbours and uses uniform weights meaning which is assigned the value to a query point is computed from a simple majority vote of the nearest neighbours. In other word, the unknown object in the query object is compared to every sample of objects which are previously being used to train the kNN classifier. The distance measurements of kNN classifier were conducted using Euclidean distance with the following equation:
where P and Q are represented by feature vectors
and
and x is the dimensionality of the feature space. The equation measures the Euclidean distance between two points P and Q.
The performance of kNN varies with different kernel functions. Fine, cosine, coarse and cubic kernels were used for performance evaluation in this study. Like previous classifiers, kNN performance was evaluated by using internal, external, and cross-validations.
4. Conclusions
In this study, colour co-occurrence matrix textural analysis and supervised learning classifiers were implemented for classification of healthy and PM disease leaves. The CCM based textural analysis was executed for extracting image features. Forty features were extracted, which were utilized for classification after normalization. Three supervised classifiers, i.e., ANN, SVM, and kNN were evaluated and the best result was generated using the ANN classifier while the kNN had the lowest overall accuracy. The SVM had high accuracy of disease detection but some limitations associated with speed of training and testing of data were found. Results suggested that the ANN is capable to model non-linear relationships and performed better classification. The study experimented on ACCs, artificial cloud conditions, environment, which reduced different environmental factors like light and leaf density during image acquisition.
The smaller image size used as an input in the machine learning process, the more information could be vanished because the value of the pixel is summarizing. However, the smaller size of the image, the less processing time is required to train and evaluate the model [
53]. Also, different image processing techniques besides colour co-occurrence matrix, will need to be examined to find optimum supervised machine learning technique. Histogram of Oriented Gradients (HOG), Scale Invariant Feature Transform (SIFT), and Speeded up Robust Features (SURF) are possible follow up research areas for the detection of PM. Therefore, it is necessary to study the variation of classification accuracy and processing time according to various image sizes and different image processing techniques. As an area for following study, inclusion of other factors would need to occur in model development for utilization in real-time PM disease classification under field conditions.
Also, the development of an unmanned ground vehicle (UGV) to collect the image data automatically will be an essential tool. The camera will be set up in the proper place on the UGV to take a row of crops in the field and a custom image acquisition program should be developed to save images or videos in the computer. In that case, segmentation techniques and adjusting the height due to the resolution could be needed to consider overlapping leaves. Furthermore, deep learning would be more effective than traditional machine learning approaches because it performs automatic feature extraction. Fast processing of deep learning can be effectively used in robots for real-time decision making, which also needs to be explored as a following study. This paper would motivate more researcher to experiment with machine learning and deep learning to solve agricultural problems involving classification or prediction.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}