Investigation of Pig Activity Based on Video Data and Semi-Supervised Neural Networks



Abstract
:1. Introduction
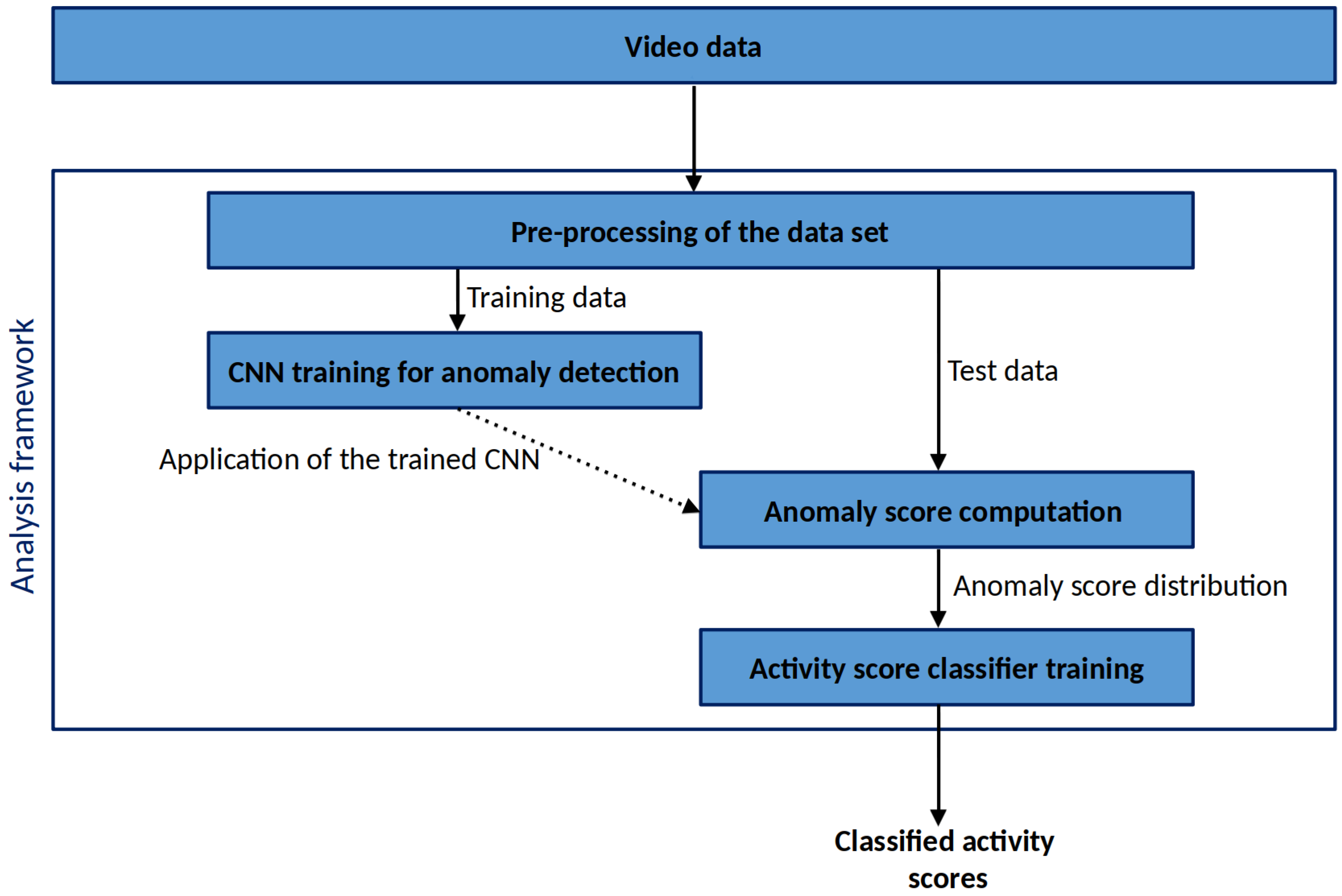
2. Materials and Methods
2.1. Video Data
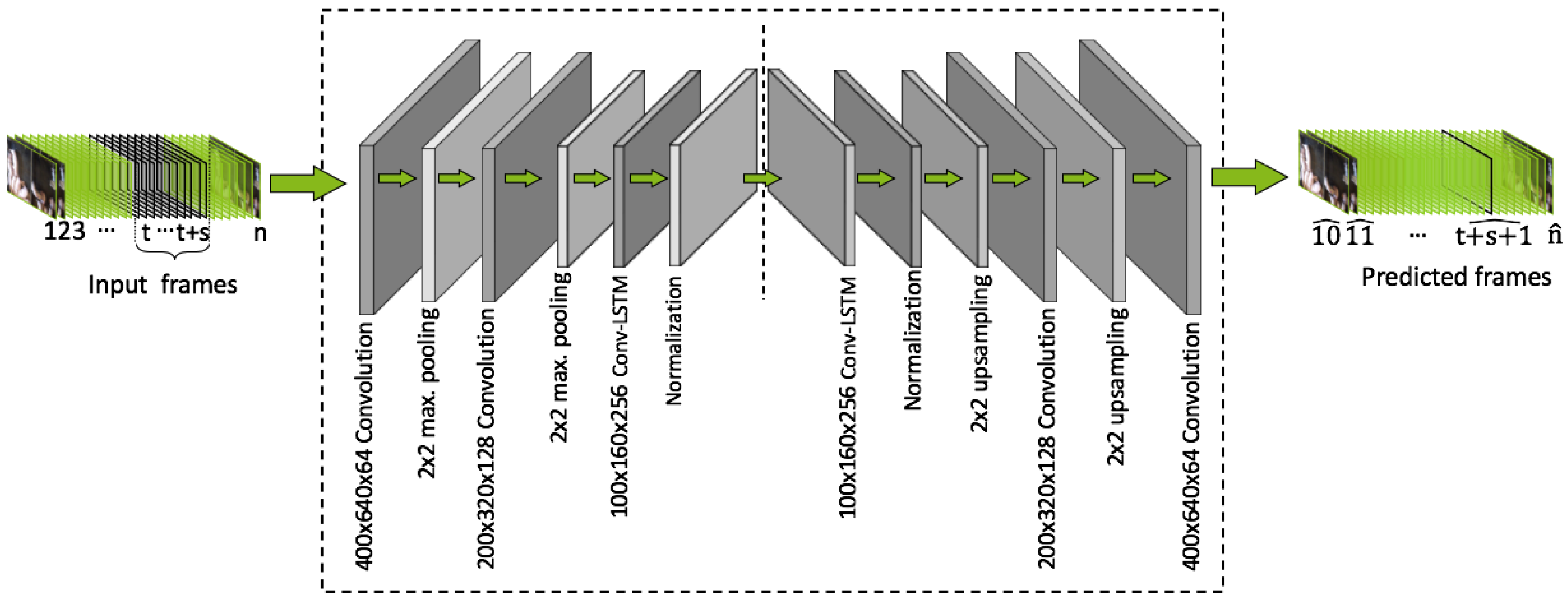
2.2. Convolutional Autoencoder Network
2.3. Threshold-Based Activity Score Classification
2.4. Model Validation
2.4.1. Comparison with Manual Observations
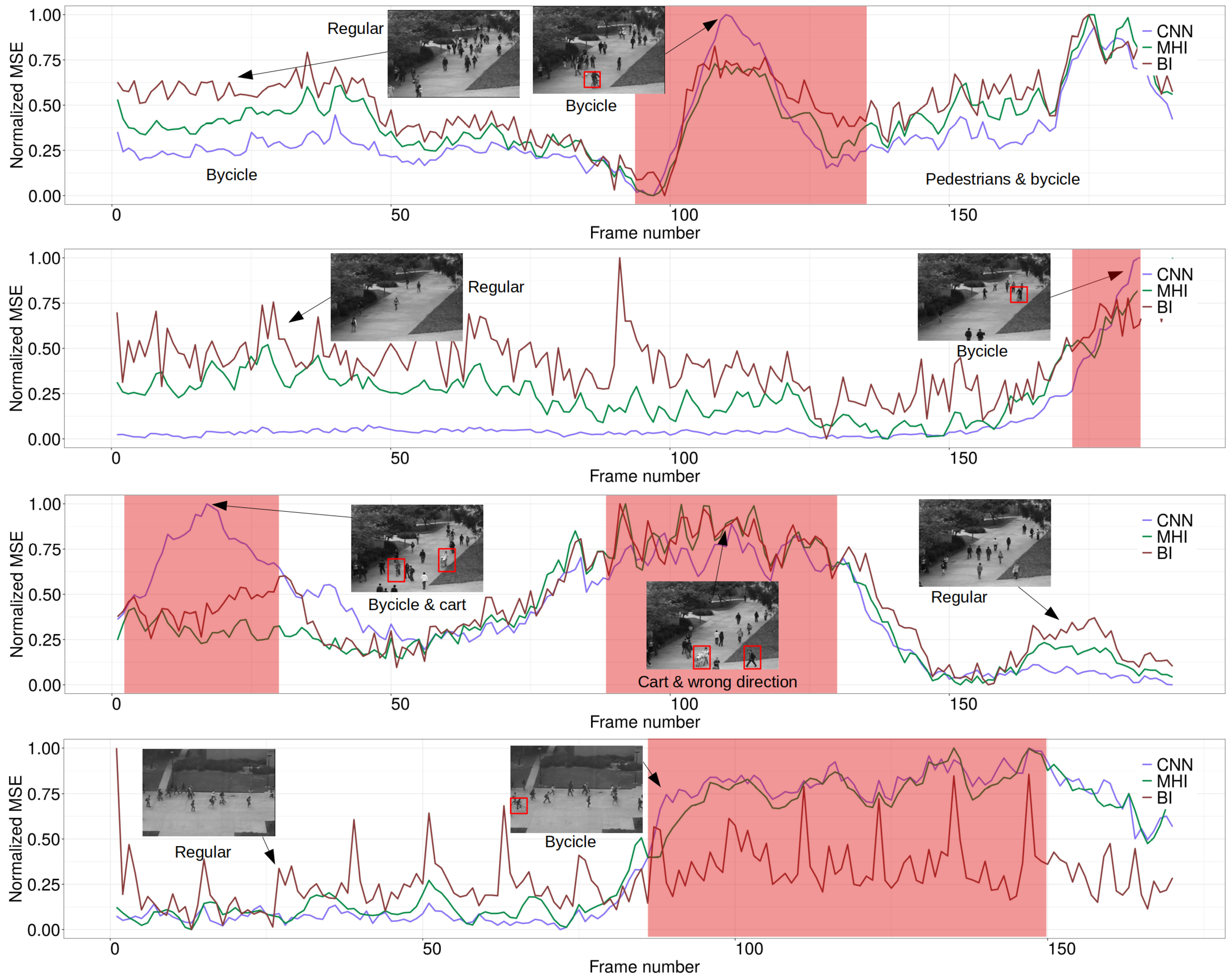
2.4.2. Performance Assessment on Benchmark Data Sets
3. Results
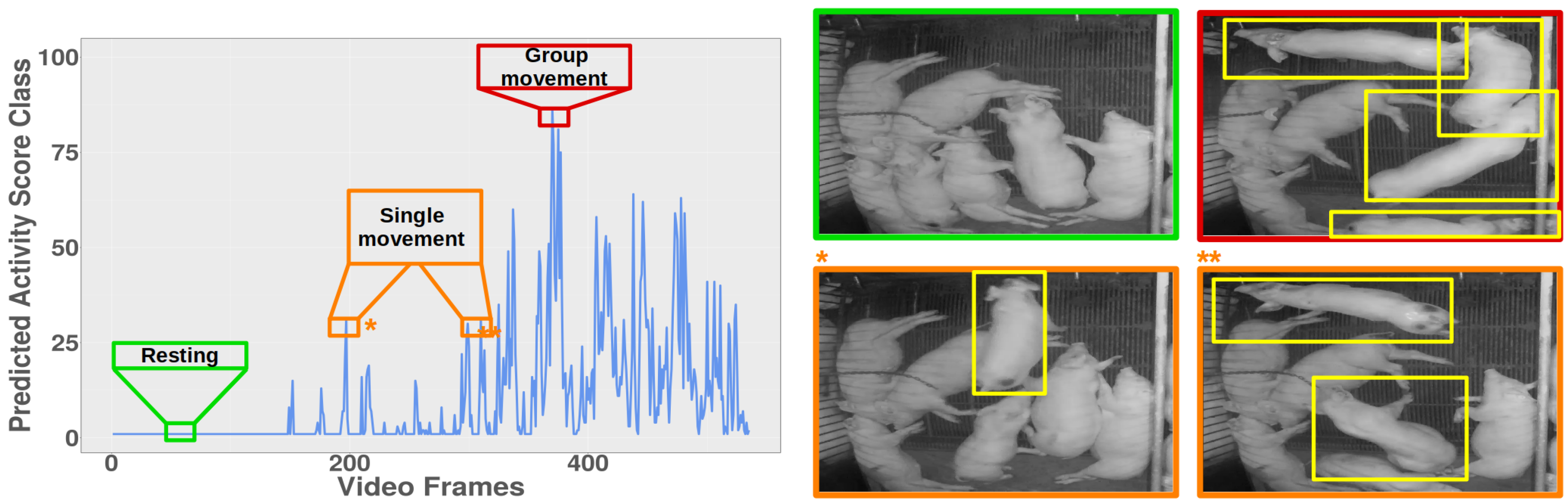
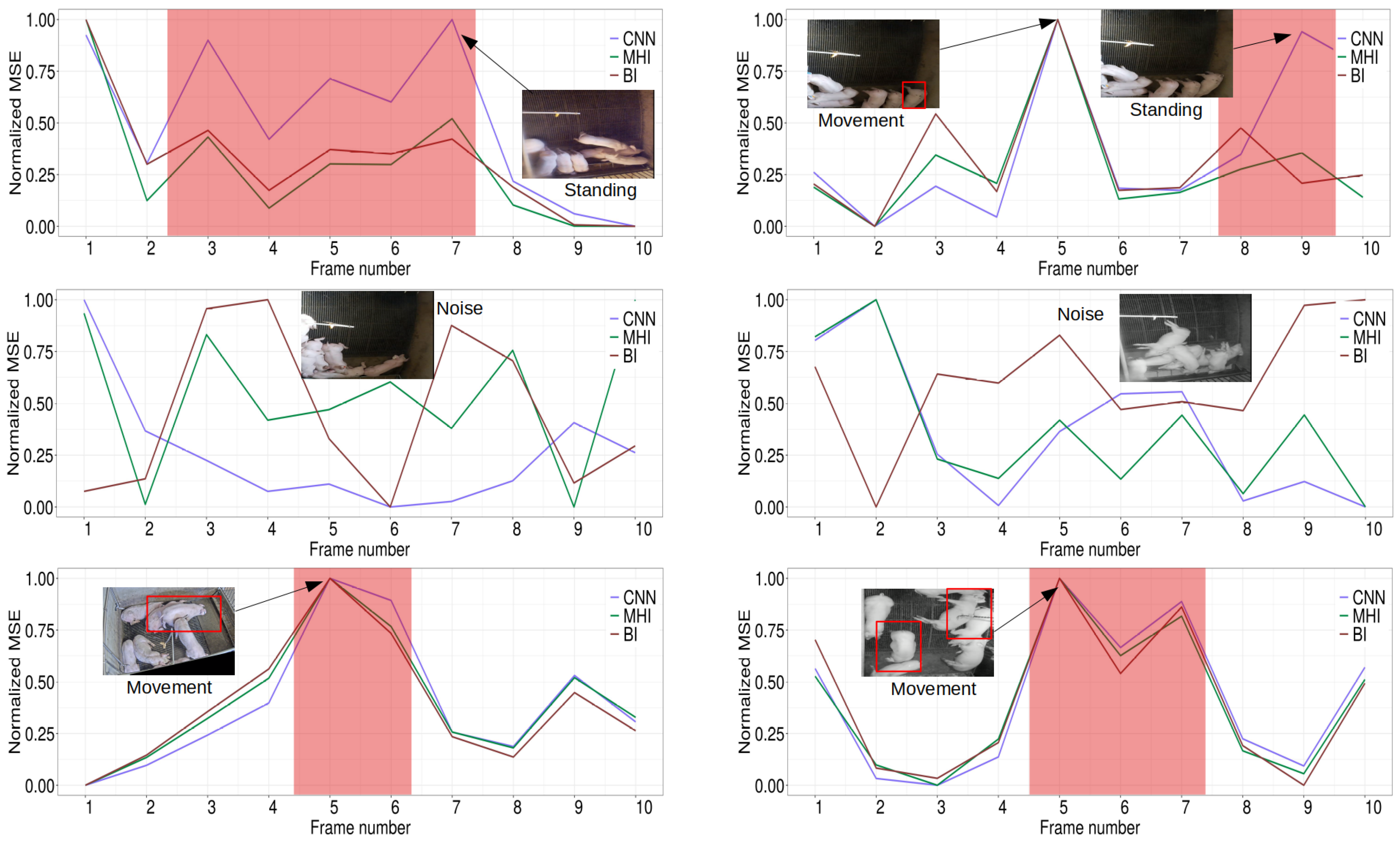
3.1. Anomaly Detection and Classification
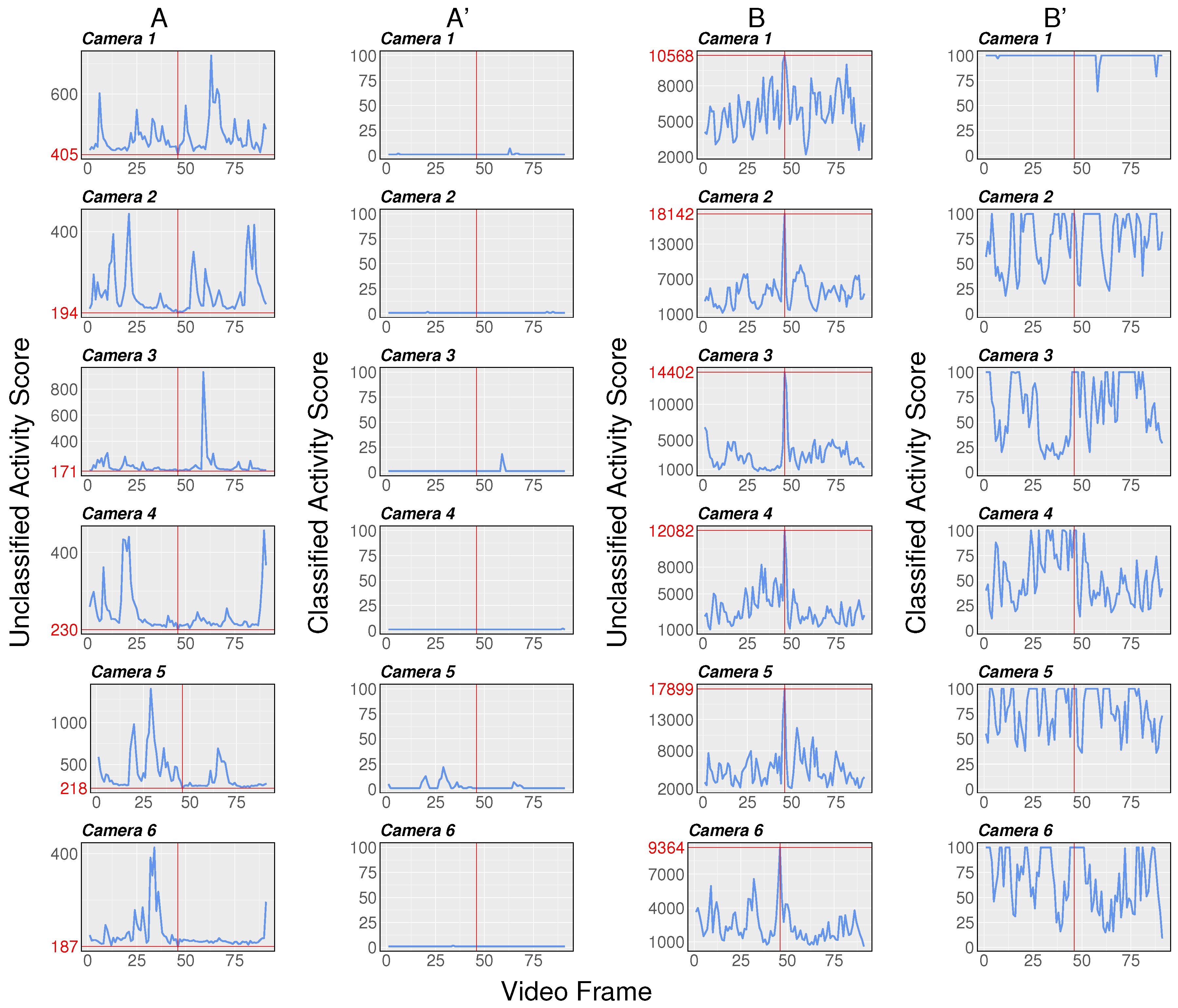
3.2. Model Validation
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FPS | Frames per Second |
| MHI | Motion History Image |
| MSE | Mean Squared Error |
References
- McGlone, J.J. A quantitative ethogram of aggressive and submissive behaviors in recently regrouped pigs. J. Anim. Sci. 1985, 61, 556–566. [Google Scholar] [CrossRef]
- Cross, A.J.; Rohrer, G.A.; Brown-Brandl, T.M.; Cassady, J.P.; Keel, B.N. Feed-forward and generalised regression neural networks in modelling feeding behaviour of pigs in the grow-finish phase. Biosyst. Eng. 2018, 173, 124–133. [Google Scholar] [CrossRef]
- Matthews, S.G.; Miller, A.L.; PlÖtz, T.; Kyriazakis, I. Automated tracking to measure behavioural changes in pigs for health and welfare monitoring. Sci. Rep. 2017, 7, 17582. [Google Scholar] [CrossRef] [PubMed]
- Zonderland, J.; Schepers, F.; Bracke, M.; Den Hartog, L.; Kemp, B.; Spoolder, H. Characteristics of biter and victim piglets apparent before a tail-biting outbreak. Animal 2011, 5, 767–775. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bracke, M.B.; Hulsegge, B.; Keeling, L.; Blokhuis, H.J. Decision support system with semantic model to assess the risk of tail biting in pigs: 1. Modelling. Appl. Anim. Behav. Sci. 2004, 87, 31–44. [Google Scholar] [CrossRef]
- Moinard, C.; Mendl, M.; Nicol, C.; Green, L. A case control study of on-farm risk factors for tail biting in pigs. Appl. Anim. Behav. Sci. 2003, 81, 333–355. [Google Scholar] [CrossRef]
- Van Putten, G. An investigation into tail-biting among fattening pigs. Br. Vet. J. 1969, 125, 511–517. [Google Scholar] [CrossRef]
- Ewbank, R. Abnormal behaviour and pig nutrition. An unsuccessful attempt to induce tail biting by feeding a high energy, low fibre vegetable protein ration. Br. Vet. J. 1973, 129, 366–369. [Google Scholar] [CrossRef]
- Wedin, M.; Baxter, E.M.; Jack, M.; Futro, A.; D’Eath, R.B. Early indicators of tail biting outbreaks in pigs. Appl. Anim. Behav. Sci. 2018, 208, 7–13. [Google Scholar] [CrossRef]
- D’Eath, R.B.; Jack, M.; Futro, A.; Talbot, D.; Zhu, Q.; Barclay, D.; Baxter, E.M. Automatic early warning of tail biting in pigs: 3D cameras can detect lowered tail posture before an outbreak. PLoS ONE 2018, 13, e0194524. [Google Scholar] [CrossRef] [Green Version]
- Matthews, S.G.; Miller, A.L.; Clapp, J.; Plötz, T.; Kyriazakis, I. Early detection of health and welfare compromises through automated detection of behavioural changes in pigs. Vet. J. 2016, 217, 43–51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schrøder-Petersen, D.L.; Simonsen, H. Tail biting in pigs. Vet. J. 2001, 162, 196–210. [Google Scholar] [CrossRef] [PubMed]
- Brunberg, E.; Wallenbeck, A.; Keeling, L.J. Tail biting in fattening pigs: Associations between frequency of tail biting and other abnormal behaviours. Appl. Anim. Behav. Sci. 2011, 133, 18–25. [Google Scholar] [CrossRef]
- Statham, P.; Green, L.; Bichard, M.; Mendl, M. Predicting tail-biting from behaviour of pigs prior to outbreaks. Appl. Anim. Behav. Sci. 2009, 121, 157–164. [Google Scholar] [CrossRef] [Green Version]
- Larsen, M.L.V.; Andersen, H.M.L.; Pedersen, L.J. Can tail damage outbreaks in the pig be predicted by behavioural change? Vet. J. 2016, 209, 50–56. [Google Scholar] [CrossRef]
- Fernández-Carrión, E.; Martínez-Avilés, M.; Ivorra, B.; Martínez-López, B.; Ramos, Á.M.; Sánchez-Vizcaíno, J.M. Motion-based video monitoring for early detection of livestock diseases: The case of African swine fever. PLoS ONE 2017, 12, e0183793. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nasirahmadi, A.; Hensel, O.; Edwards, S.; Sturm, B. A new approach for categorizing pig lying behaviour based on a Delaunay triangulation method. Animal 2017, 11, 131–139. [Google Scholar] [CrossRef] [Green Version]
- Angarita, B.K.; Cantet, R.J.; Wurtz, K.E.; O’Malley, C.I.; Siegford, J.M.; Ernst, C.W.; Turner, S.P.; Steibel, J.P. Estimation of indirect social genetic effects for skin lesion count in group-housed pigs by quantifying behavioral interactions. J. Anim. Sci. 2019, 97, 3658–3668. [Google Scholar] [CrossRef]
- Büttner, K.; Czycholl, I.; Mees, K.; Krieter, J. Temporal development of agonistic interactions as well as dominance indices and centrality parameters in pigs after mixing. Appl. Anim. Behav. Sci. 2020, 222, 104913. [Google Scholar] [CrossRef]
- Büttner, K.; Czycholl, I.; Mees, K.; Krieter, J. Social network analysis in pigs: Impacts of significant dyads on general network and centrality parameters. Animal 2020, 14, 368–378. [Google Scholar] [CrossRef] [Green Version]
- Veit, C.; Traulsen, I.; Hasler, M.; Tölle, K.H.; Burfeind, O.; Grosse Beilage, E.; Krieter, J. Influence of raw material on the occurrence of tail-biting in undocked pigs. Livest. Sci. 2016, 191, 125–131. [Google Scholar] [CrossRef]
- Seo, J.; Ahn, H.; Kim, D.; Lee, S.; Chung, Y.; Park, D. EmbeddedPigDet—Fast and Accurate Pig Detection for Embedded Board Implementations. Appl. Sci. 2020, 10, 2878. [Google Scholar] [CrossRef]
- Psota, E.T.; Mittek, M.; Pérez, L.C.; Schmidt, T.; Mote, B. Multi-pig part detection and association with a fully-convolutional network. Sensors 2019, 19, 852. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nasirahmadi, A.; Sturm, B.; Edwards, S.; Jeppsson, K.H.; Olsson, A.C.; Müller, S.; Hensel, O. Deep Learning and Machine Vision Approaches for Posture Detection of Individual Pigs. Sensors 2019, 19, 3738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, D.; Zhang, K.; Li, Z.; Chen, Y. A Spatiotemporal Convolutional Network for Multi-Behavior Recognition of Pigs. Sensors 2020, 20, 2381. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Li, D.; Huang, J.; Chen, Y. Automated Video Behavior Recognition of Pigs Using Two-Stream Convolutional Networks. Sensors 2020, 20, 1085. [Google Scholar] [CrossRef] [Green Version]
- Khetan, A.; Lipton, Z.C.; Anandkumar, A. Learning from noisy singly-labeled data. arXiv 2017, arXiv:1712.04577. [Google Scholar]
- Bengio, Y.; Courville, A.C.; Vincent, P. Unsupervised feature learning and deep learning: A review and new perspectives. CoRR 2012, 1, 2012. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef] [Green Version]
- Ahad, M.A.R.; Ogata, T.; Tan, J.; Kim, H.; Ishikawa, S. Comparative analysis between two view-based methods: MHI and DMHI. In Proceedings of the 2007 10th International Conference on Computer and Information Technology, Roukela, India, 27–29 December 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–6. [Google Scholar]
- Alp, E.C.; Keles, H.Y. A comparative study of HMMs and LSTMs on action classification with limited training data. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 6–7 September 2018; Springer: Cham, Switzerland, 2018; pp. 1102–1115. [Google Scholar]
- Thummala, J.; Pumrin, S. Fall Detection using Motion History Image and Shape Deformation. In Proceedings of the 2020 8th International Electrical Engineering Congress (iEECON), Chiang Mai, Thailand, 4–6 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Pampouchidou, A.; Pediaditis, M.; Maridaki, A.; Awais, M.; Vazakopoulou, C.M.; Sfakianakis, S.; Tsiknakis, M.; Simos, P.; Marias, K.; Yang, F.; et al. Quantitative comparison of motion history image variants for video-based depression assessment. EURASIP J. Image Video Process. 2017, 2017, 64. [Google Scholar] [CrossRef] [Green Version]
- Ahad, M.A.R.; Tan, J.K.; Kim, H.; Ishikawa, S. Motion history image: Its variants and applications. Mach. Vis. Appl. 2012, 23, 255–281. [Google Scholar] [CrossRef]
- Ott, S.; Moons, C.; Kashiha, M.A.; Bahr, C.; Tuyttens, F.; Berckmans, D.; Niewold, T.A. Automated video analysis of pig activity at pen level highly correlates to human observations of behavioural activities. Livest. Sci. 2014, 160, 132–137. [Google Scholar] [CrossRef]
- Tsai, D.M.; Huang, C.Y. A motion and image analysis method for automatic detection of estrus and mating behavior in cattle. Comput. Electron. Agric. 2014, 104, 25–31. [Google Scholar] [CrossRef]
- Su, K.; Liu, X.; Shlizerman, E. Predict & cluster: Unsupervised skeleton based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9631–9640. [Google Scholar]
- Cui, J.; Gong, K.; Guo, N.; Wu, C.; Meng, X.; Kim, K.; Zheng, K.; Wu, Z.; Fu, L.; Xu, B.; et al. PET image denoising using unsupervised deep learning. Eur. J. Nucl. Med. Mol. Imaging 2019, 46, 2780–2789. [Google Scholar] [CrossRef]
- Xu, J.; Huang, Y.; Liu, L.; Zhu, F.; Hou, X.; Shao, L. Noisy-As-Clean: Learning unsupervised denoising from the corrupted image. arXiv 2019, arXiv:1906.06878. [Google Scholar]
- Kiran, B.; Thomas, D.; Parakkal, R. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef] [Green Version]
- Al-Ajlan, A.; El Allali, A. CNN-MGP: Convolutional neural networks for metagenomics gene prediction. Interdiscip. Sci. Comput. Life Sci. 2019, 11, 628–635. [Google Scholar] [CrossRef] [Green Version]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Khalid, S. Activity classification and anomaly detection using m-mediods based modelling of motion patterns. Pattern Recognit. 2010, 43, 3636–3647. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 15. [Google Scholar] [CrossRef]
- Finn, C.; Goodfellow, I.; Levine, S. Unsupervised learning for physical interaction through video prediction. In Proceedings of the Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 64–72. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 843–852. [Google Scholar]
- Denton, E.L. Unsupervised learning of disentangled representations from video. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 4414–4423. [Google Scholar]
- Lotter, W.; Kreiman, G.; Cox, D. Deep predictive coding networks for video prediction and unsupervised learning. arXiv 2016, arXiv:1605.08104. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised learning of visual representations using videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2794–2802. [Google Scholar]
- Medel, J.R.; Savakis, A. Anomaly detection in video using predictive convolutional long short-term memory networks. arXiv 2016, arXiv:1612.00390. [Google Scholar]
- Chong, Y.S.; Tay, Y.H. Abnormal event detection in videos using spatiotemporal autoencoder. In Proceedings of the International Symposium on Neural Networks, Hokkaido, Japan, 16–21 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 189–196. [Google Scholar]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, UAE, 4–7 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 22 October 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 22 October 2020).
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kashiha, M.A.; Bahr, C.; Ott, S.; Moons, C.P.; Niewold, T.A.; Tuyttens, F.; Berckmans, D. Automatic monitoring of pig locomotion using image analysis. Livest. Sci. 2014, 159, 141–148. [Google Scholar] [CrossRef]
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Chan, A.; Vasconcelos, N. Ucsd pedestrian dataset. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2008, 30, 909–926. [Google Scholar] [CrossRef] [Green Version]
- Chan, A.B.; Vasconcelos, N. Modeling, clustering, and segmenting video with mixtures of dynamic textures. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 909–926. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Deng, B.; Shen, C.; Liu, Y.; Lu, H.; Hua, X.S. Spatio-temporal autoencoder for video anomaly detection. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1933–1941. [Google Scholar]
- Ursinus, W.W.; Van Reenen, C.G.; Kemp, B.; Bolhuis, J.E. Tail biting behaviour and tail damage in pigs and the relationship with general behaviour: Predicting the inevitable? Appl. Anim. Behav. Sci. 2014, 156, 22–36. [Google Scholar] [CrossRef]
- Arias, P.; Morel, J.M. Video denoising via empirical Bayesian estimation of space-time patches. J. Math. Imaging Vis. 2018, 60, 70–93. [Google Scholar] [CrossRef]
- Buades, A.; Lisani, J.L.; Miladinović, M. Patch-based video denoising with optical flow estimation. IEEE Trans. Image Process. 2016, 25, 2573–2586. [Google Scholar] [CrossRef]
- Chen, X.; Song, L.; Yang, X. Deep rnns for video denoising. In Proceedings of the Applications of Digital Image Processing XXXIX—International Society for Optics and Photonics, San Diego, CA, USA, 28 August–1 September 2016; Volume 9971, p. 99711T. [Google Scholar]
- Rahman, S.M.; Ahmad, M.O.; Swamy, M. Video denoising based on inter-frame statistical modeling of wavelet coefficients. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 187–198. [Google Scholar] [CrossRef]
- Ali, R.A.; Hardie, R.C. Recursive non-local means filter for video denoising. EURASIP J. Image Video Process. 2017, 2017, 29. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.; Rajora, S.; Vishwakarma, D.K.; Tripathi, G.; Kumar, S.; Walia, G.S. Crowd anomaly detection using aggregation of ensembles of fine-tuned ConvNets. Neurocomputing 2020, 371, 188–198. [Google Scholar] [CrossRef]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Label propagation for deep semi-supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5070–5079. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manual Rating | Low Activity (n = 18) | Medium Activity (n = 33) | High Activity (n = 31) | |
|---|---|---|---|---|
| CNN Prediction | ||||
| Low activity | 17 | 1 | 0 | |
| Medium activity | 1 | 27 | 0 | |
| High activity | 0 | 5 | 31 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wutke, M.; Schmitt, A.O.; Traulsen, I.; Gültas, M. Investigation of Pig Activity Based on Video Data and Semi-Supervised Neural Networks. AgriEngineering 2020, 2, 581-595. https://doi.org/10.3390/agriengineering2040039
Wutke M, Schmitt AO, Traulsen I, Gültas M. Investigation of Pig Activity Based on Video Data and Semi-Supervised Neural Networks. AgriEngineering. 2020; 2(4):581-595. https://doi.org/10.3390/agriengineering2040039
Chicago/Turabian StyleWutke, Martin, Armin Otto Schmitt, Imke Traulsen, and Mehmet Gültas. 2020. "Investigation of Pig Activity Based on Video Data and Semi-Supervised Neural Networks" AgriEngineering 2, no. 4: 581-595. https://doi.org/10.3390/agriengineering2040039
APA StyleWutke, M., Schmitt, A. O., Traulsen, I., & Gültas, M. (2020). Investigation of Pig Activity Based on Video Data and Semi-Supervised Neural Networks. AgriEngineering, 2(4), 581-595. https://doi.org/10.3390/agriengineering2040039