
Exploring Approaches for Estimating Parameters in Cognitive Diagnosis Models with Small Sample Sizes

 ,
, 
 ,
,  and
and 
Abstract
:1. Introduction
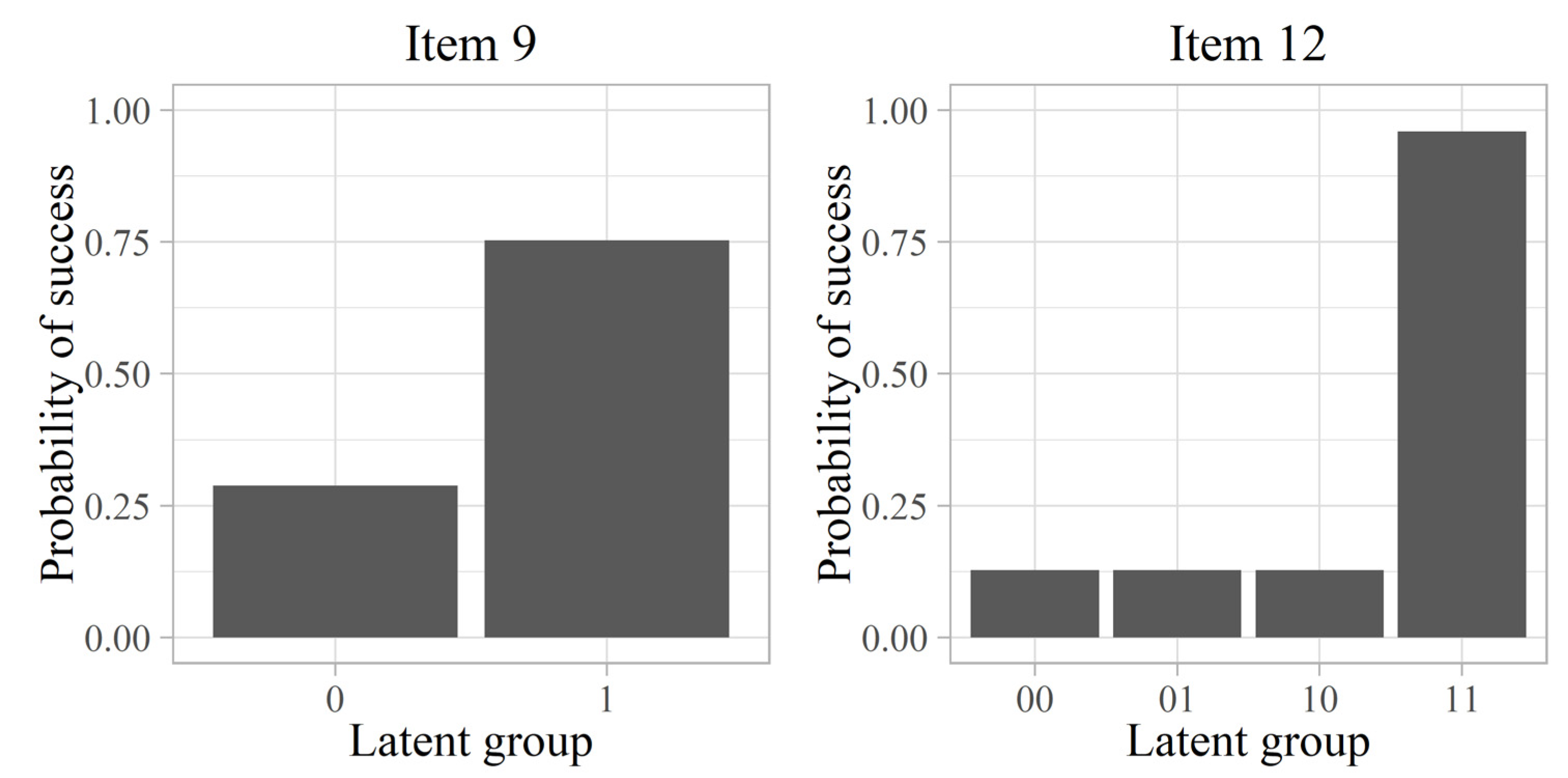
1.1. The DINA Model
1.2. Estimation Procedures
2. Materials and Methods
2.1. Item Parameter Estimation Methods and Attribute Profile Classification
- -
- For the MMLE-EM method we used the GDINA package. Sen and Terzi (2020) [40] compared different software (CDM R package, flexMIRT, Latent GOLD, mdltm, Mplus, and OxEdit) to estimate the DINA model using this estimation procedure. The differences between estimated item parameters were always marginal. The same holds true for Rupp and van Rijn’s (2018) [41] comparison of the R packages GDINA and CDM, whereby the results reported here for the GDINA R package should be largely generalizable to any other software. Details on MMLE-EM estimation can be found in de la Torre (2009) [42]. This procedure uses the marginalized likelihood of the data:where is the marginalized likelihood of the response vector for examinee i and is the prior probability of the attribute vector . In the same paper, the author provides the ML estimators of the guessing and slip parameters. Specifically, and , where () indicates the number of people in () and () indicates how many of those people get item j right. As specified by default in the package, three sets of starting values have been generated and the best set according to the observed log-likelihood is used. This is performed to avoid the problem of local optima using MMLE.
- -
- For the BM estimation, we applied the R code provided by Ma and Jiang (2021) [34]. The BM or posterior model estimation incorporates prior information about model parameters into the EM algorithm. In a way, it can be seen as a computationally efficient version of MCMC estimation. Specifically, the BM estimation of the guessing parameter adopts ), where and are the parameters for a beta distribution . The same consideration is taken for the slip parameter. The interested reader is referred to the appendix of the original article for more technical details. For BM and MCMC (described below), initial values were drawn from a uniform distribution between 0.10 and 0.30. A β(5, 25) distribution was used for the item parameters. This is a distribution centered at 0.166 (i.e., examinees are expected to produce guessing and slip 1/6 (=5/(5 + 25)) of the times. We refer to this procedure as BM-info. On the other hand, in all cases the maximum a posteriori estimator was adopted as the estimator of the attribute profile of the examinees using a uniform distribution as the prior distribution.
- -
- For the MCMC estimation, we used the Gibbs sampling estimator using the JAGS code via the R package R2jags [43] provided by Zhan et al. (2019) [44]. The algorithm was set to 2500 iterations and 500 burn-in in two chains as performed by Culpepper (2015) [27]. We considered both a non-informative, flat prior [MCMC-unif; β(1, 1)] and an informative prior [MCMC-info; β(5, 25)]. We tested that this estimator provided almost identical results as the ones that could be obtained using Stan via the R code provided by Lee (2016) [45] and the rstan package [46]. The computation times with Stan were considerably slower than those of JAGS. For example, in the simulation study, for a replication with 100 examinees, JAGS required 1.108 min and Stan 11.252. Since the results were basically identical, we conducted the complete study using JAGS. Another reason to prefer this software is that Zhan et al. (2019) [44] provide in their article the codes for other models besides DINA, so the researcher interested in applying other models can take advantage of this.
- -
- The nonparametric classification (NPC) method [35] was implemented using the NPCD package [47]. No parameter estimation is conducted in the NPC method; instead, ideal response patterns () are formulated for each possible attribute profile based on a conjunctive, , or disjunctive, ), condensation rule. Here, we adopted the conjunctive condensation rule that accommodates non-compensatory processes such as the DINA model. Then, examinees’ observed response patterns () are compared with the attribute profiles’ ideal response patterns with the so-called Hamming distances, , so that the attribute profile assigned to examinee i is the one that minimizes such distances. Note that ties can be found for two or more attribute profiles; in this case, the assigned attribute profile would be randomly selected among those with the lowest Hamming distance.
- -
- The Restricted DINA model (R-DINA) [36] was estimated with the cdmTools package [23]. In the R-DINA model, a single parameter φ is estimated for the whole model, which is defined as the proportion of observed responses that depart from the ideal responses. Making a comparison with the more traditional DINA model, . The estimation procedure used in the package provides equivalent results to the MMLE-EM estimation. The R-DINA model has been shown to provide the same attribute profile classifications as the NPC method when no prior information on the attribute joint distribution is incorporated. Small differences can be found between both methods due to the randomness implied in the selection of the attribute profile when there are ties between two or more attribute profiles (i.e., same, lowest Hamming distance or, equivalently, same, largest likelihood).
2.2. Data
2.2.1. Simulation Study
2.2.2. Empirical Study
2.3. Dependent Variables
3. Results
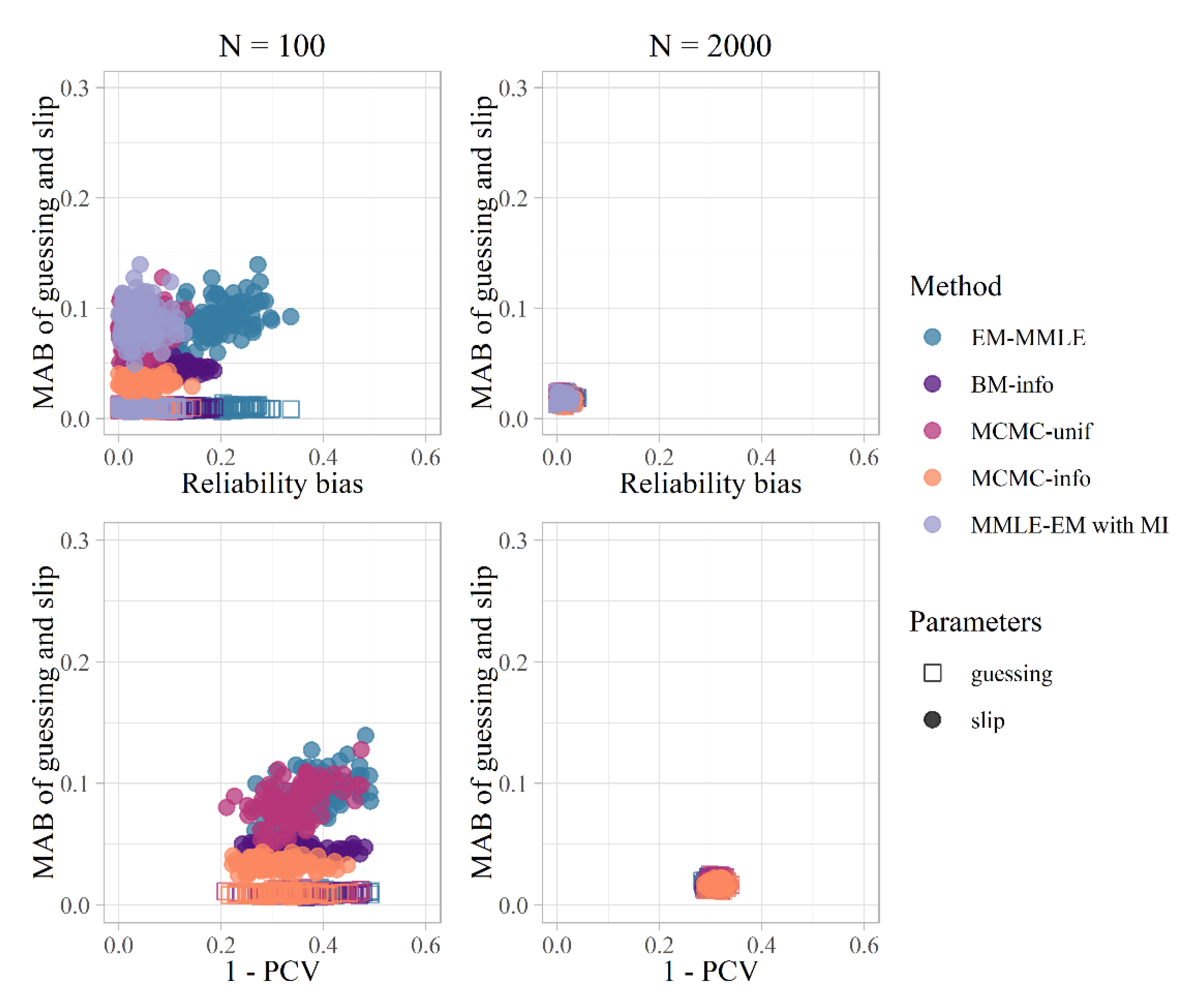
3.1. Simulation Study
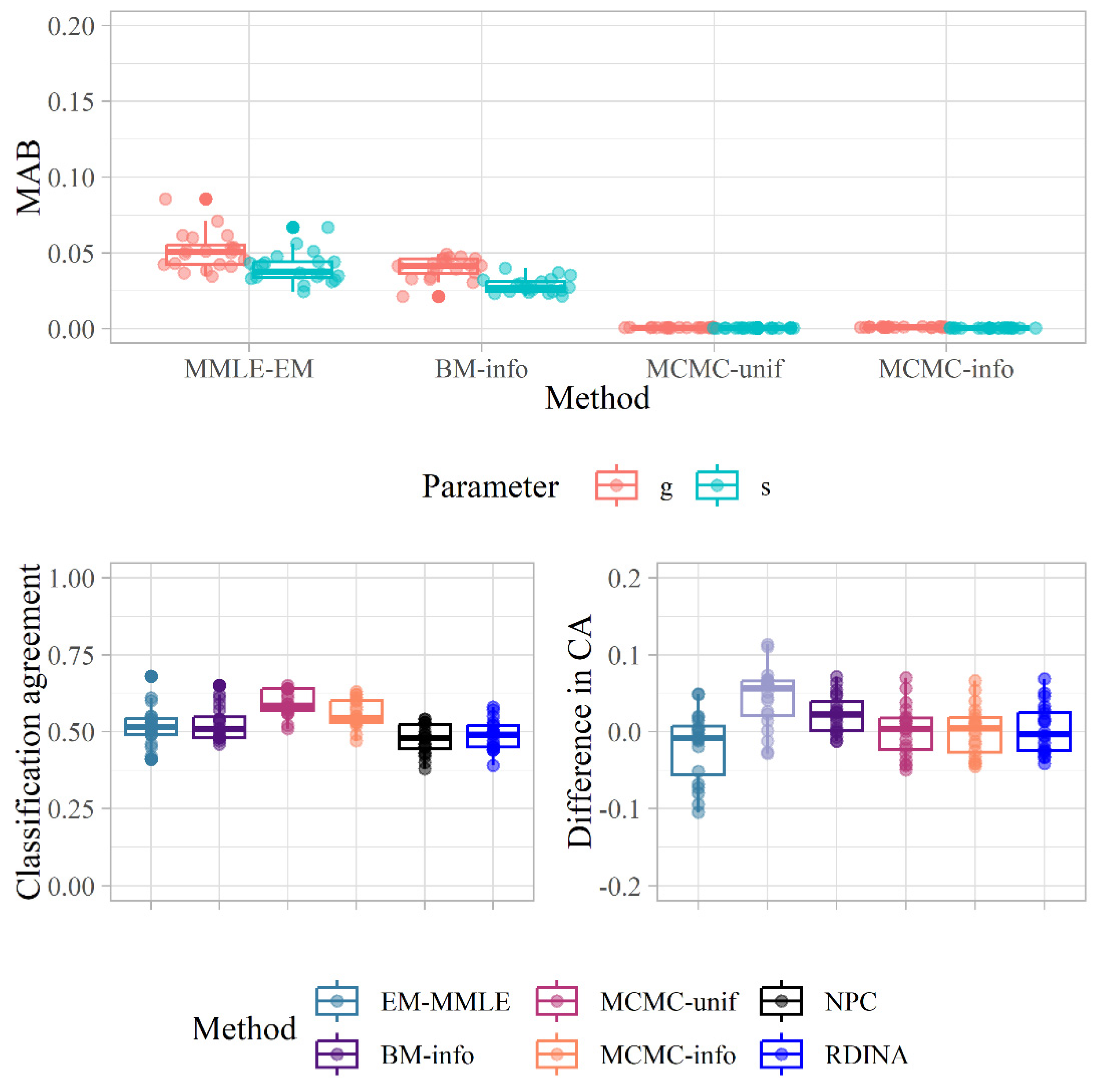
3.2. Empirical Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ren, H.; Xu, N.; Lin, Y.; Zhang, S.; Yang, T. Remedial teaching and learning from a cognitive diagnostic model perspective: Taking the data distribution characteristics as an example. Front. Psychol. 2021, 12, 628607. [Google Scholar] [CrossRef] [PubMed]
- Sorrel, M.A.; Abad, F.J.; Olea, J.; de la Torre, J.; Barrada, J.R. Inferential item-fit evaluation in cognitive diagnosis modeling. Appl. Psychol. Meas. 2017, 41, 614–631. [Google Scholar] [CrossRef] [PubMed]
- Tan, Z.; de la Torre, J.; Ma, W.; Huh, D.; Larimer, M.E.; Mun, E.Y. A tutorial on cognitive diagnosis modeling for characterizing mental health symptom profiles using existing item responses. Prev. Sci. 2022, 24, 480–492. [Google Scholar] [CrossRef] [PubMed]
- Templin, J.L.; Henson, R.A. Measurement of psychological disorders using cognitive diagnosis models. Psychol. Methods 2006, 11, 287–305. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; de la Torre, J. A general cognitive diagnosis model for expert-defined polytomous attributes. Appl. Psychol. Meas. 2013, 37, 419–437. [Google Scholar] [CrossRef]
- Ravand, H.; Baghaei, P. Diagnostic classification models: Recent developments, practical issues, and prospects. Int. J. Test. 2020, 20, 24–56. [Google Scholar] [CrossRef]
- Shi, Q.; Ma, W.; Robitzsch, A.; Sorrel, M.A.; Man, K. Cognitively diagnostic analysis using the G-DINA model in R. Psych 2021, 3, 812–835. [Google Scholar] [CrossRef]
- Sessoms, J.; Henson, R.A. Applications of diagnostic classification models: A literature review and critical commentary. Measurement 2018, 16, 1–17. [Google Scholar] [CrossRef]
- Junker, B.W.; Sijtsma, K. Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Appl. Psychol. Meas. 2001, 25, 258–272. [Google Scholar] [CrossRef]
- Tatsuoka, C. Data analytic methods for latent partially ordered classification models. J. R. Stat. Soc. Ser. C Appl. Stat. 2002, 51, 337–350. [Google Scholar] [CrossRef]
- De La Torre, J. The generalized DINA model framework. Psychometrika 2011, 76, 179–199. [Google Scholar] [CrossRef]
- Sorrel, M.A.; Abad, F.J.; Nájera, P. Improving accuracy and usage by correctly selecting: The effects of model selection in cognitive diagnosis computerized adaptive testing. Appl. Psychol. Meas. 2021, 45, 112–129. [Google Scholar] [CrossRef]
- de la Torre, J.; Minchen, N. Cognitively diagnostic assessments and the cognitive diagnosis model framework. Psicol. Educ. 2014, 20, 89–97. [Google Scholar] [CrossRef]
- Wu, H.M. Online individualised tutor for improving mathematics learning: A cognitive diagnostic model approach. Educ. Psychol. (Lond.) 2019, 39, 1218–1232. [Google Scholar] [CrossRef]
- Sanz, S.; Kreitchmann, R.S.; Nájera, P.; Moreno, J.D.; Martínez-Huertas, J.A.; Sorrel, M.A. FoCo: A Shiny app for formative assessment using cognitive diagnosis modeling. Psicol. Educ. 2023; in press. [Google Scholar]
- Li, F.; Cohen, A.; Bottge, B.; Templin, J. A latent transition analysis model for assessing change in cognitive skills. Educ. Psychol. Meas. 2016, 76, 181–204. [Google Scholar] [CrossRef]
- Sun, Y.; Suzuki, M. Diagnostic assessment for improving teaching practice. Int. J. Inf. Educ. Technol. 2013, 3, 607–610. [Google Scholar] [CrossRef]
- Ma, W.; de la Torre, J. GDINA: An R package for cognitive diagnosis modeling. J. Stat. Softw. 2020, 93, 1–26. [Google Scholar] [CrossRef]
- Ma, W.; de la Torre, J. GDINA: The Generalized DINA Model Framework. R Package Version 2.9.3. 2022. Available online: https://CRAN.R-project.org/package=GDINA (accessed on 1 March 2023).
- George, A.C.; Robitzsch, A.; Kiefer, T.; Groß, J.; Ünlü, A. The R package CDM for cognitive diagnosis models. J. Stat. Softw. 2016, 74, 1–24. [Google Scholar] [CrossRef]
- Robitzsch, A.; Kiefer, T.; George, A.C.; Ünlü, A. CDM: Cognitive Diagnosis Modeling. R Package Version 8.2-6. 2022. Available online: https://CRAN.R-project.org/package=CDM (accessed on 1 March 2023).
- Nájera, P.; Abad, F.J.; Sorrel, M.A. Determining the number of attributes in cognitive diagnosis modeling. Front. Psychol. 2021, 12, 614470. [Google Scholar] [CrossRef]
- Nájera, P.; Sorrel, M.A.; Abad, F.J. cdmTools: Useful Tools for Cognitive Diagnosis Modeling. R Package Version 1.0.3. 2023. Available online: https://github.com/Pablo-Najera/cdmTools (accessed on 30 March 2023).
- Sorrel, M.A.; Nájera, P.; Abad, F.J. cdcatR: An R package for cognitive diagnostic computerized adaptive testing. Psych 2021, 3, 386–403. [Google Scholar] [CrossRef]
- Kreitchmann, R.S.; de la Torre, J.; Sorrel, M.A.; Nájera, P.; Abad, F.J. Improving reliability estimation in cognitive diagnosis modeling. Behav. Res. Methods, 2022; in press. [Google Scholar] [CrossRef] [PubMed]
- Yamaguchi, K. On the boundary problems in diagnostic classification models. Behaviormetrika 2023, 50, 399–429. [Google Scholar] [CrossRef]
- Culpepper, S.A. Bayesian estimation of the DINA model with Gibbs sampling. J. Educ. Behav. Stat. 2015, 40, 454–476. [Google Scholar] [CrossRef]
- Culpepper, S.A.; Hudson, A. An improved strategy for Bayesian estimation of the reduced reparametrized unified model. Appl. Psychol. Meas. 2018, 42, 99–115. [Google Scholar] [CrossRef]
- van Ravenzwaaij, D.; Cassey, P.; Brown, S.D. A simple introduction to Markov Chain Monte–Carlo sampling. Psychon. Bull. Rev. 2018, 25, 143–154. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equations of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1091. [Google Scholar] [CrossRef]
- Kruschke, J.K. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan, 2nd ed.; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Plummer, M. JAGS Version 4.3.1 User Manual. 2015. Available online: http://sourceforge.net/projects/mcmc-jags/ (accessed on 1 March 2023).
- Stan Development Team. Stan Modeling Language Users Guide and Reference Manual, Version 2.32. 2022. Available online: https://mc-stan.org/users/documentation/ (accessed on 1 March 2023).
- Ma, W.; Jiang, Z. Estimating cognitive diagnosis models in small samples: Bayes modal estimation and monotonic constraints. Appl. Psychol. Meas. 2021, 45, 95–111. [Google Scholar] [CrossRef]
- Chiu, C.Y.; Douglas, J. A nonparametric approach to cognitive diagnosis by proximity to ideal response patterns. J. Classif. 2013, 30, 225–250. [Google Scholar] [CrossRef]
- Nájera, P.; Abad, F.J.; Chiu, C.-Y.; Sorrel, M.A. A comprehensive cognitive diagnostic method for classroom-level assessments. J. Educ. Behav. Stat. 2023; in press. [Google Scholar] [CrossRef]
- Chiu, C.Y.; Sun, Y.; Bian, Y. Cognitive diagnosis for small educational programs: The general nonparametric classification method. Psychometrika 2018, 83, 355–375. [Google Scholar] [CrossRef]
- Paulsen, J.; Valdivia, D.S. Examining cognitive diagnostic modeling in classroom assessment conditions. J. Exp. Educ. 2022, 90, 916–933. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. 2022. Available online: https://www.R-project.org/ (accessed on 1 March 2023).
- Sen, S.; Terzi, R. A comparison of software packages available for DINA model estimation. Appl. Psychol. Meas. 2020, 44, 150–164. [Google Scholar] [CrossRef]
- Rupp, A.A.; van Rijn, P.W. GDINA and CDM packages in R. Measurement 2018, 16, 71–77. [Google Scholar] [CrossRef]
- de la Torre, J. DINA model and parameter estimation: A didactic. J. Educ. Behav. Stat. 2009, 34, 115–130. [Google Scholar] [CrossRef]
- Su, Y.-S.; Yajima, M. R2jags: Using R to Run “JAGS”. R Package Version 0.5-7. 2015. Available online: http://CRAN.R-project.org/package=R2jags (accessed on 1 March 2023).
- Zhan, P.; Jiao, H.; Man, K.; Wang, L. Using JAGS for Bayesian cognitive diagnosis modeling: A tutorial. J. Educ. Behav. Stat. 2019, 44, 473–503. [Google Scholar] [CrossRef]
- Lee, S.Y. DINA Model with Independent Attributes. 2016. Available online: http://mc-stan.org/documentation/case-studies/dina_independent.html (accessed on 1 March 2023).
- Stan Development Team. RStan: The R Interface to Stan. R Package Version 2.21.8. 2023. Available online: https://mc-stan.org/ (accessed on 1 March 2023).
- Zheng, Y.; Chiu, C. NPCD: Nonparametric Methods for Cognitive Diagnosis. R Package Version 1.0-11. 2019. Available online: https://CRAN.R-project.org/package=NPCD (accessed on 1 March 2023).
- Gu, Y.; Xu, G. The sufficient and necessary condition for the identifiability and estimability of the DINA model. Psychometrika 2019, 84, 468–483. [Google Scholar] [CrossRef]
- Sorrel, M.A.; de la Torre, J.; Abad, F.J.; Olea, J. Two-step likelihood ratio test for item-level model comparison in cognitive diagnosis models. Methodology 2017, 13, 39–47. [Google Scholar] [CrossRef]
- Chen, J.; de la Torre, J.; Zhang, Z. Relative and absolute fit evaluation in cognitive diagnosis modeling. J. Educ. Meas. 2013, 50, 123–140. [Google Scholar] [CrossRef]
- DeCarlo, L.T. On the analysis of fraction subtraction data: The DINA model, classification, latent class sizes, and the Q-matrix. Appl. Psychol. Meas. 2011, 35, 8–26. [Google Scholar] [CrossRef]
- Iaconangelo, C. Uses of Classification Error Probabilities in the Three-Step Approach to Estimating Cognitive Diagnosis Models. Ph.D. Thesis, Rutgers University, New Brunswick, NJ, USA, 2017. [Google Scholar]
- Jiang, Z.; Carter, R. Using Hamiltonian Monte Carlo to estimate the log-linear cognitive diagnosis model via Stan. Behav. Res. Methods 2018, 51, 651–662. [Google Scholar] [CrossRef] [PubMed]
- Yamaguchi, K.; Templin, J. A Gibbs sampling algorithm with monotonicity constraints for diagnostic classification models. J. Classif. 2022, 39, 24–54. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Guessing Parameter | Slip Parameter | |||||||
|---|---|---|---|---|---|---|---|---|
| Item | MMLE-EM | BM-Info | MCMC-Unif | MCMC-Info | MMLE-EM | BM-Info | MCMC-Unif | MCMC-Info |
| 1 | 0.030 | 0.049 | 0.045 | 0.065 | 0.089 | 0.094 | 0.078 | 0.085 |
| 2 | 0.016 | 0.041 | 0.025 | 0.048 | 0.041 | 0.045 | 0.040 | 0.045 |
| 3 | 0.000 | 0.021 | 0.008 | 0.026 | 0.134 | 0.127 | 0.132 | 0.124 |
| 4 | 0.224 | 0.218 | 0.236 | 0.228 | 0.110 | 0.110 | 0.111 | 0.112 |
| 5 | 0.301 | 0.287 | 0.310 | 0.292 | 0.172 | 0.167 | 0.153 | 0.152 |
| 6 | 0.095 | 0.116 | 0.198 | 0.176 | 0.044 | 0.047 | 0.038 | 0.045 |
| 7 | 0.025 | 0.041 | 0.035 | 0.049 | 0.197 | 0.182 | 0.201 | 0.184 |
| 8 | 0.444 | 0.376 | 0.434 | 0.370 | 0.182 | 0.176 | 0.164 | 0.163 |
| 9 | 0.288 | 0.212 | 0.237 | 0.182 | 0.247 | 0.238 | 0.248 | 0.237 |
| 10 | 0.029 | 0.041 | 0.035 | 0.047 | 0.214 | 0.203 | 0.193 | 0.187 |
| 11 | 0.066 | 0.074 | 0.067 | 0.076 | 0.082 | 0.083 | 0.084 | 0.086 |
| 12 | 0.127 | 0.140 | 0.265 | 0.233 | 0.041 | 0.050 | 0.038 | 0.048 |
| 13 | 0.013 | 0.026 | 0.017 | 0.030 | 0.335 | 0.312 | 0.336 | 0.313 |
| 14 | 0.062 | 0.087 | 0.162 | 0.146 | 0.061 | 0.066 | 0.045 | 0.056 |
| 15 | 0.031 | 0.053 | 0.032 | 0.055 | 0.105 | 0.103 | 0.113 | 0.112 |
| 16 | 0.109 | 0.118 | 0.184 | 0.163 | 0.111 | 0.110 | 0.092 | 0.098 |
| 17 | 0.038 | 0.051 | 0.044 | 0.054 | 0.138 | 0.136 | 0.142 | 0.139 |
| 18 | 0.119 | 0.124 | 0.130 | 0.133 | 0.138 | 0.136 | 0.135 | 0.133 |
| 19 | 0.022 | 0.034 | 0.026 | 0.037 | 0.240 | 0.221 | 0.235 | 0.214 |
| 20 | 0.013 | 0.027 | 0.020 | 0.031 | 0.157 | 0.154 | 0.144 | 0.144 |
| Method | MAB (g/s) | PCV | Reliability Bias | |||
|---|---|---|---|---|---|---|
| n = 100 | n = 2000 | n = 100 | n = 2000 | n = 100 | n = 2000 | |
| MMLE-EM | 0.048/0.089 | 0.010/0.018 | 0.622 | 0.692 | 0.191 | 0.011 |
| MMLE-EM with MI | - | - | - | - | 0.000 | −0.003 |
| BM-info | 0.033/0.044 | 0.010/0.017 | 0.660 | 0.692 | 0.086 | 0.009 |
| MCMC-unif | 0.044/0.084 | 0.010/0.018 | 0.660 | 0.686 | 0.026 | 0.010 |
| MCMC-info | 0.029/0.033 | 0.010/0.017 | 0.688 | 0.687 | 0.041 | 0.013 |
| NPC | - | - | 0.692 | 0.692 | - | - |
| R-DINA | - | - | 0.690 | 0.691 | 0.002 | 0.000 |
| True, generating model | 0.692 | 0.692 | 0.001 | −0.001 | ||
| Method | MAB (g/s) | Classification Agreement | Difference in Estimated Classification Accuracy |
|---|---|---|---|
| MMLE-EM | 0.051/0.040 | 0.519 | −0.019 |
| MMLE-EM with MI | - | - | 0.044 |
| BM-info | 0.040/0.029 | 0.528 | 0.023 |
| MCMC-unif | 0.001/0.001 | 0.593 | 0.001 |
| MCMC-info | 0.001/0.001 | 0.558 | 0.001 |
| NPC | - | 0.476 | - |
| R-DINA | - | 0.487 | 0.003 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sorrel, M.A.; Escudero, S.; Nájera, P.; Kreitchmann, R.S.; Vázquez-Lira, R. Exploring Approaches for Estimating Parameters in Cognitive Diagnosis Models with Small Sample Sizes. Psych 2023, 5, 336-349. https://doi.org/10.3390/psych5020023
Sorrel MA, Escudero S, Nájera P, Kreitchmann RS, Vázquez-Lira R. Exploring Approaches for Estimating Parameters in Cognitive Diagnosis Models with Small Sample Sizes. Psych. 2023; 5(2):336-349. https://doi.org/10.3390/psych5020023
Chicago/Turabian StyleSorrel, Miguel A., Scarlett Escudero, Pablo Nájera, Rodrigo S. Kreitchmann, and Ramsés Vázquez-Lira. 2023. "Exploring Approaches for Estimating Parameters in Cognitive Diagnosis Models with Small Sample Sizes" Psych 5, no. 2: 336-349. https://doi.org/10.3390/psych5020023
APA StyleSorrel, M. A., Escudero, S., Nájera, P., Kreitchmann, R. S., & Vázquez-Lira, R. (2023). Exploring Approaches for Estimating Parameters in Cognitive Diagnosis Models with Small Sample Sizes. Psych, 5(2), 336-349. https://doi.org/10.3390/psych5020023