


Privacy-Preserving Convolutional Bi-LSTM Network for Robust Analysis of Encrypted Time-Series Medical Images


Abstract
:1. Introduction
- This article proposes evaluating homomorphic-encrypted time-series medical pictures with a convolutional Bi-LSTM network. Encrypted frames have discriminative spatial characteristics extracted using convolutional blocks.
- A weighted unit and sequence voting layer integrate geographical various weights in the suggested technique.
- This study compares the recommended technique to a zero-watermarking solid system that meets security issues during medical photo storage and transmission, notably lesion zone protection. This comparison shows that the suggested framework protects the privacy and improves medical picture analysis.
2. Related Works
3. Methods and Materials
3.1. Problem Formulation
3.2. Dataset
3.3. Methodology
| Algorithm 1 of MORE (Matrix Operation for Randomization or Encryption) |
| Secret Key Generation Input: None Output: Secret key SK Steps:
Input: Plain text matrix P, Secret key SK Output: Encrypted matrix C Steps:
Input: Encrypted matrix C, Secret key SK Output: Decrypted matrix P Steps:
|
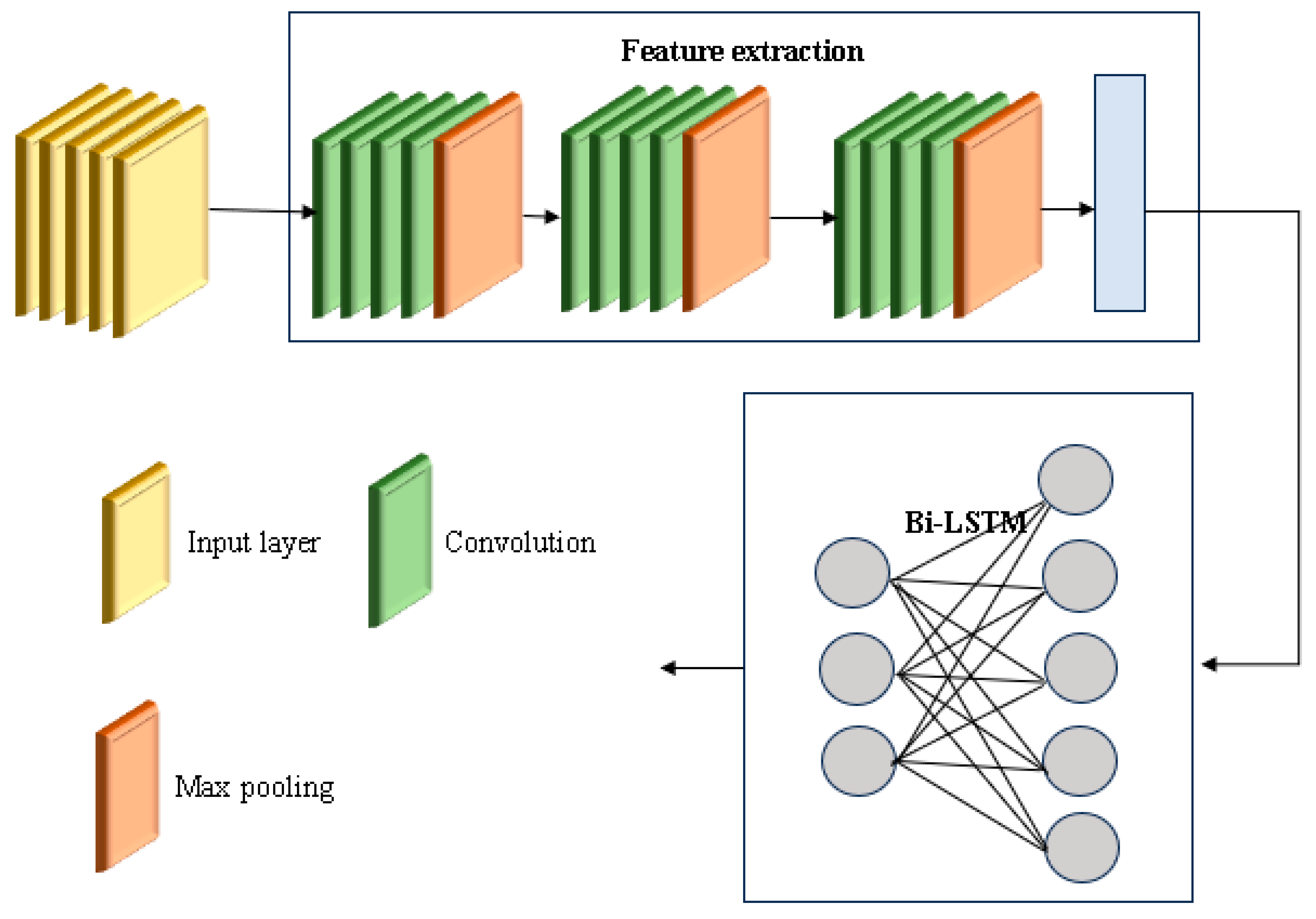
3.4. Convolutional Bi-LSTM
4. Experimental Setup
5. Result and discussion
Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Anand, A.; Singh, A.K. An improved DWT-SVD domain watermarking for medical information security. Comput. Commun. 2020, 152, 72–80. [Google Scholar] [CrossRef]
- Garcia-Hernandez, J.J.; Gomez-Flores, W.; Loyola, J.R. Analysis of the impact of digital watermarking on computer-aided diagnosis in medical imaging. Comput. Biol. Med. 2016, 68, 37–48. [Google Scholar] [CrossRef]
- Fan, T.-Y.; Chao, H.-C.; Chieu, B.-C. Lossless medical image watermarking method based on significant difference of cellular automata transform coefficient. Signal Process. Image Commun. 2019, 70, 174–183. [Google Scholar] [CrossRef]
- Ali, Z.; Imran, M.; Alsulaiman, M.; Shoaib, M.; Ullah, S. Chaos-based robust method of zero-watermarking for medical signals. Future Gener. Comput. Syst. 2018, 88, 400–412. [Google Scholar] [CrossRef]
- Wang, X.; Wan, L.; Huang, M.; Shen, C.; Han, Z.; Zhu, T. Low-complexity channel estimation for circular and noncircular signals in virtual MIMO vehicle communication systems. IEEE Trans. Veh. Technol. 2020, 69, 3916–3928. [Google Scholar] [CrossRef]
- Natarajan, V. Hybrid local prediction error-based difference expansion reversible watermarking for medical images. Comput. Electr. Eng. 2016, 53, 333–345. [Google Scholar]
- Gangadhar, Y.; Akula, V.S.G.; Reddy, P.C. An evolutionary programming approach for securing medical images using watermarking scheme in invariant discrete wavelet transformation. Biomed. Signal Process. Control 2018, 43, 31–40. [Google Scholar] [CrossRef]
- Sharma, A.; Singh, A.K.; Ghrera, S.P. Secure hybrid robust watermarking technique for medical images. Procedia Comput. Sci. 2015, 70, 778–784. [Google Scholar] [CrossRef]
- Bouslimi, D.; Coatrieux, G. A crypto-watermarking system for ensuring reliability control and traceability of medical images. Signal Process. Image Commun. 2016, 47, 160–169. [Google Scholar] [CrossRef]
- Liu, C.; Zhong, D.; Shao, H. Data protection in palmprint recognition via dynamic random invisible watermark embedding. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6927–6940. [Google Scholar] [CrossRef]
- Malayil, M.V.; Vedhanayagam, M. A novel image scaling based reversible watermarking scheme for secure medical image transmission. ISA Trans. 2021, 108, 269–281. [Google Scholar] [CrossRef]
- Li, X.-B.; Qin, J. Anonymizing and sharing medical text records. Inf. Syst. Res. 2017, 28, 332–352. [Google Scholar] [CrossRef] [PubMed]
- Price, W.N.; Cohen, G. Privacy in the age of medical big data. Nat. Med. 2019, 25, 37–43. [Google Scholar] [CrossRef]
- Hua, Z.; Yi, S.; Zhou, Y. Medical image encryption using high-speed scrambling and pixel adaptive diffusion. Signal Process. 2018, 144, 134–144. [Google Scholar] [CrossRef]
- Silva-García, V.M.; Flores-Carapia, R.; Rentería-Márquez, C.; Luna-Benoso, B.; Aldape-Pérez, M. Substitution box generation using Chaos: An image encryption application. Appl. Math. Comput. 2018, 332, 123–135. [Google Scholar] [CrossRef]
- Liu, Y.; Tang, S.; Liu, R.; Zhang, L.; Ma, Z. Secure and robust digital image watermarking scheme using logistic and RSA encryption. Expert Syst. Appl. 2018, 97, 95–105. [Google Scholar] [CrossRef]
- Wang, Z.; Li, M.; Wang, H.; Jiang, H.; Yao, Y.; Zhang, H.; Xin, J. Breast cancer detection using extreme learning machine based on feature fusion with CNN deep features. IEEE Access 2019, 7, 105146–105158. [Google Scholar] [CrossRef]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep learning to improve breast cancer detection on screening mammography. Sci. Rep. 2019, 9, 12495. [Google Scholar] [CrossRef]
- Lee, R.S.; Gimenez, F.; Rubin, A.D.H. Curated breast imaging subset of DDSM. Cancer Imag. Arch. Tech. Rep. 2016. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-attention networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Zhang, Y.; Wang, S.; Wu, H.; Hu, K.; Ji, S. Brain Tumors Classification for MR images based on Attention Guided Deep Learning Model. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Jalisco, Mexico, 1–5 November 2021; pp. 3233–3236. [Google Scholar] [CrossRef]
- Jin, Y.; Dou, Q.; Chen, H.; Yu, L.; Heng, P.A. EndoRCN: Recurrent convolutional networks for recognition of surgical workflow in cholecystectomy procedure video. IEEE Trans. Med. Imaging 2016, 53347671. [Google Scholar]
- Ghosh, P.; Azam, S.; Hasib, K.M.; Karim, A.; Jonkman, M.; Anwar, A. A Performance Based Study on Deep Learning Algorithms in the Effective Prediction of Breast Cancer. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Zheng, J.; Lin, D.; Gao, Z.; Wang, S.; He, M.M.; Fan, J. Deep Learning Assisted Efficient AdaBoost Algorithm for Breast Cancer Detection and Early Diagnosis. IEEE Access 2020, 8, 96946–96954. [Google Scholar] [CrossRef]
- Yan, Y.; Zhao, K.; Cao, J.; Ma, H. Prediction research of cervical cancer clinical events based on recurrent neural network. Procedia Comput. Sci. 2021, 183, 221–229. [Google Scholar] [CrossRef]
- Zhang, X.; Li, R.; Dai, H.; Liu, Y.; Zhou, B.; Wang, Z. Localization of Myocardial Infarction With Multi-Lead Bidirectional Gated Recurrent Unit Neural Network. IEEE Access 2019, 7, 161152–161166. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat practical fully homomorphic encryption. Cryptology ePrint Arch. 2012, 144. [Google Scholar]
- Samardzic, N.; Feldmann, A.; Krastev, A.; Manohar, N.; Genise, N.; Devadas, S.; Eldefrawy, K.; Peikert, C.; Sanchez, D. CraterLake: A hardware accelerator for efficient unbounded computation on encrypted data. In Proceedings of the 49th Annual International Symposium on Computer Architecture (ISCA ‘22). Association for Computing Machinery, New York, NY, USA, 18–22 June 2022; pp. 173–187. [Google Scholar] [CrossRef]
- Mert, A.C.; Öztürk, E.; Savaş, E. Design and implementation of encryption/decryption architectures for BFV homomorphic encryption scheme. IEEE Trans. Very Large Scale Integr VLSI Syst. 2019, 28, 353–362. [Google Scholar] [CrossRef]
- Ibarrondo, a.; Chabanne, H.; Despiegel, V.; Önen, M. Colmade: Collaborative Masking in Auditable Decryption for BFV-based Homomorphic Encryption. In Proceedings of the 2022 ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec ‘22), New York, NY, USA, 27–28 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 129–139. [Google Scholar] [CrossRef]
- Yang, H.; Liang, S.; Zhang, Y.; Li, X. Cloud-based privacy-and integrity-protecting density peaks clustering. Cloud-based privacy and integrity-protecting density peaks clustering. Future Gener. Comput. Syst. 2021, 125, 758–769. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, C.; Xie, Y.; Chen, X.; Zhang, J.; Xiang, Y. A survey on privacy inference attacks and defenses in cloud-based Deep Neural Network. Comput. Stand. Interfaces 2023, 83, 103672. [Google Scholar] [CrossRef]
- Natsheh, Q.; Sălăgean, A.; Zhou, D.; Edirisinghe, E. Automatic Selective Encryption of DICOM Images. Appl. Sci. 2023, 13, 4779. [Google Scholar] [CrossRef]
- Kanso, A.; Ghebleh, M. An efficient and robust image encryption scheme for medical applications. Commun. Nonlinear Sci. Numer. Simul. 2015, 24, 98–116. [Google Scholar] [CrossRef]
- Song, W.; Fu, C.; Zheng, Y.; Tie, M.; Liu, J.; Chen, J. A parallel image encryption algorithm using intra bitplane scrambling. Math. Comput. Simul. 2023, 204, 71–88. [Google Scholar] [CrossRef]
- Ding, Y.; Wu, G.; Chen, D.; Zhang, N.; Gong, L.; Cao, M.; Qin, Z. DeepEDN: A deep-learning-based image encryption and decryption network for internet of medical things. IEEE Internet Things J. 2021, 8, 1504–1518. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the NIPS2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2672–2680. [Google Scholar]
- Liu, W.; Liu, X.; Ma, H.; Cheng, P. Beyond Human-level License Plate Super-resolution with Progressive Vehicle Search and Domain Priori GAN. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1618–1626. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the IEEE ICCV2017, Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Radanliev, P.; De Roure, D. Epistemological and bibliometric analysis of ethics and shared responsibility—Health policy and IoT systems. Sustainability 2021, 13, 8355. [Google Scholar] [CrossRef]
- Jain, D. Regulation of Digital Healthcare in India: Ethical and Legal Challenges. Healthcare 2023, 11, 911. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, Q.; Liu, L.; He, Y. A High-Quality Rice Leaf Disease Image Data Augmentation Method Based on a Dual GAN. IEEE Access 2023, 11, 21176–21191. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, T.; Zhang, J. Toward visual quality enhancement of dehazing effect with improved Cycle-GAN. Neural Comput. Appl. 2023, 35, 5277–5290. [Google Scholar] [CrossRef]
- Panzade, P.; Takabi, D. FENet: Privacy-preserving Neural Network Training with Functional Encryption. In Proceedings of the 9th ACM International Workshop on Security and Privacy Analytics (IWSPA ‘23), Charlotte, NC, USA, 26 April 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 33–43. [Google Scholar] [CrossRef]
- Zhao, D. Communication-Efficient Search under Fully Homomorphic Encryption for Federated Machine Learning. arXiv 2023, arXiv:2308.04648. [Google Scholar]
- Li, Q.; Lai, Y.; Adamu, M.J.; Qu, L.; Nie, J.; Nie, W. Multi-Level Residual Feature Fusion Network for Thoracic Disease Classification in Chest X-ray Images. IEEE Access 2023, 11, 40988–41002. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CheXpert | BreakHis | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
| CNN | 0.924 | 0.932 | 0.928 | 0.930 | 0.935 | 0.936 | 0.940 | 0.951 |
| LSTM | 0.944 | 0.945 | 0.952 | 0.944 | 0.945 | 0.942 | 0.948 | 0.943 |
| Bi-LSTM | 0.954 | 0.962 | 0.951 | 0.968 | 0.956 | 0.957 | 0.952 | 0.945 |
| CNN-LSTM | 0.972 | 0.984 | 0.977 | 0.976 | 0.964 | 0.962 | 0.963 | 0.970 |
| CNN-Bi-LSTM | 0.999 | 0.998 | 0.991 | 1.00 | 0.999 | 0.998 | 0.997 | 0.998 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kolhar, M.; Aldossary, S.M. Privacy-Preserving Convolutional Bi-LSTM Network for Robust Analysis of Encrypted Time-Series Medical Images. AI 2023, 4, 706-720. https://doi.org/10.3390/ai4030037
Kolhar M, Aldossary SM. Privacy-Preserving Convolutional Bi-LSTM Network for Robust Analysis of Encrypted Time-Series Medical Images. AI. 2023; 4(3):706-720. https://doi.org/10.3390/ai4030037
Chicago/Turabian StyleKolhar, Manjur, and Sultan Mesfer Aldossary. 2023. "Privacy-Preserving Convolutional Bi-LSTM Network for Robust Analysis of Encrypted Time-Series Medical Images" AI 4, no. 3: 706-720. https://doi.org/10.3390/ai4030037
APA StyleKolhar, M., & Aldossary, S. M. (2023). Privacy-Preserving Convolutional Bi-LSTM Network for Robust Analysis of Encrypted Time-Series Medical Images. AI, 4(3), 706-720. https://doi.org/10.3390/ai4030037