Data Driven Modelling of Nuclear Power Plant Performance Data as Finite State Machines

 ,
,
Abstract
:1. Introduction
- Outline a visual analytics approach that facilitates feature exploration, visual analysis, pattern discovery and effective modelling of the NPP time-series data.
- Use Finite State Machine representation to visualise and model the working principle of NPP.
- Compare the behaviour of NPP over the years with the help of state machine diagrams and introduce the concept of normal and abnormal plant operations.
2. Related Work
2.1. Pattern Discovery Using k-Means Clustering
2.2. Dimensionality Reduction Techniques
2.3. Modelling Problems Using a Finite State Machine
2.4. Nuclear Power Plant Data Modelling
3. System Model
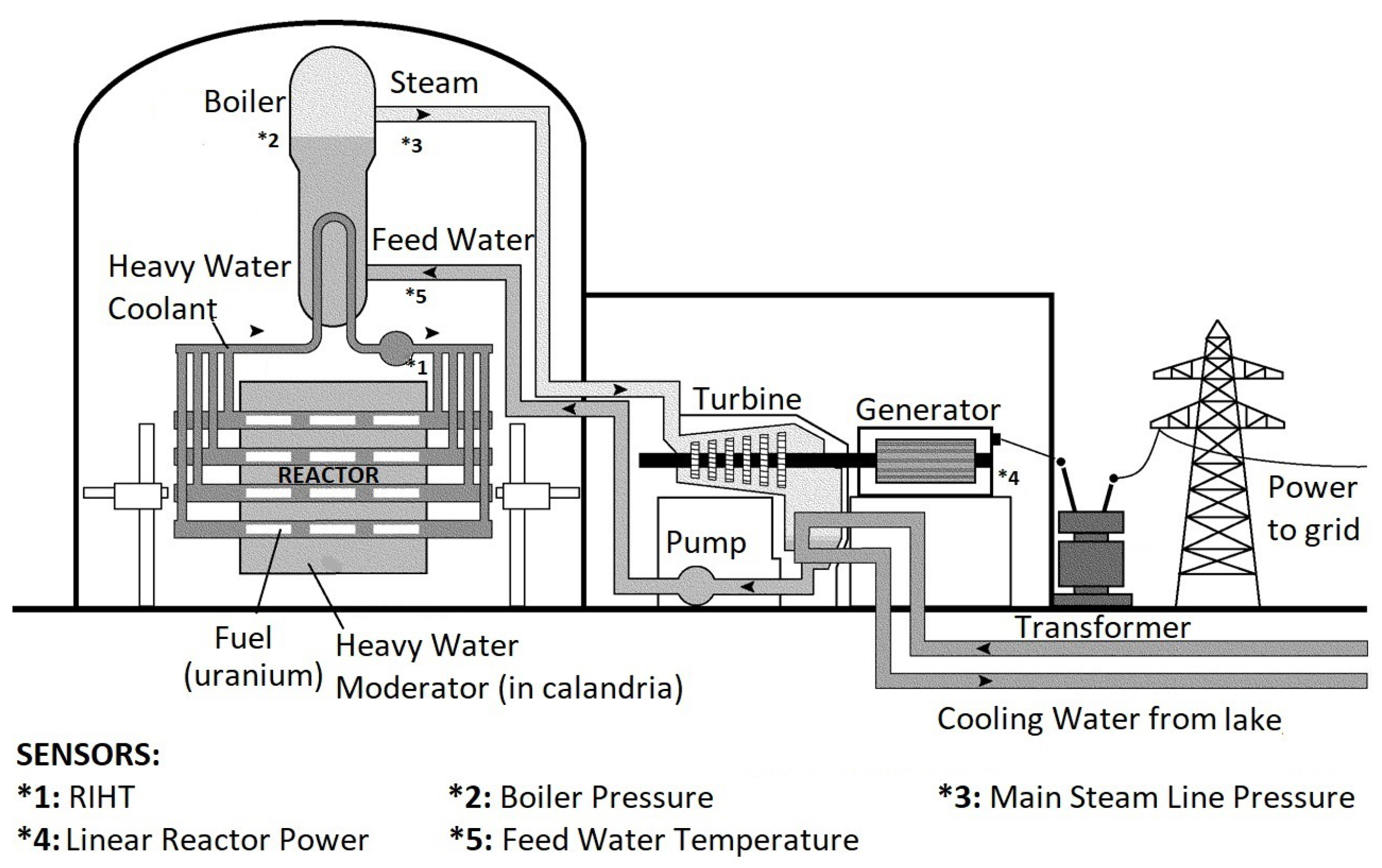
- Fuel: The most commonly used nuclear fuels around the world are isotopes of Uranium.
- Core: The core of a reactor contains uranium fuel. It is kept in a horizontal or vertical cylindrical tank known as calandria based on a heavy water reactor or light water reactor. Calandria comprises of concentric fuel channels that run from its one end to the other [23].
- Control rods: Based on neutron-absorbing materials, these rods are inserted or withdrawn from the core to control the rate of reaction [23].
- Moderator: Nuclear fuels such as isotopes of uranium requires a moderator to slow down neutrons in order to absorb them. Depending on the reactor, the moderator can be ordinary water (for light water reactors) or deuterium oxide (for heavy water reactors) [23].
- Coolant: It is used to maintain the reactor core temperature at a safe operating temperature. It also helps in reactor cooldown to avoid a meltdown that can halt the production of energy [23].
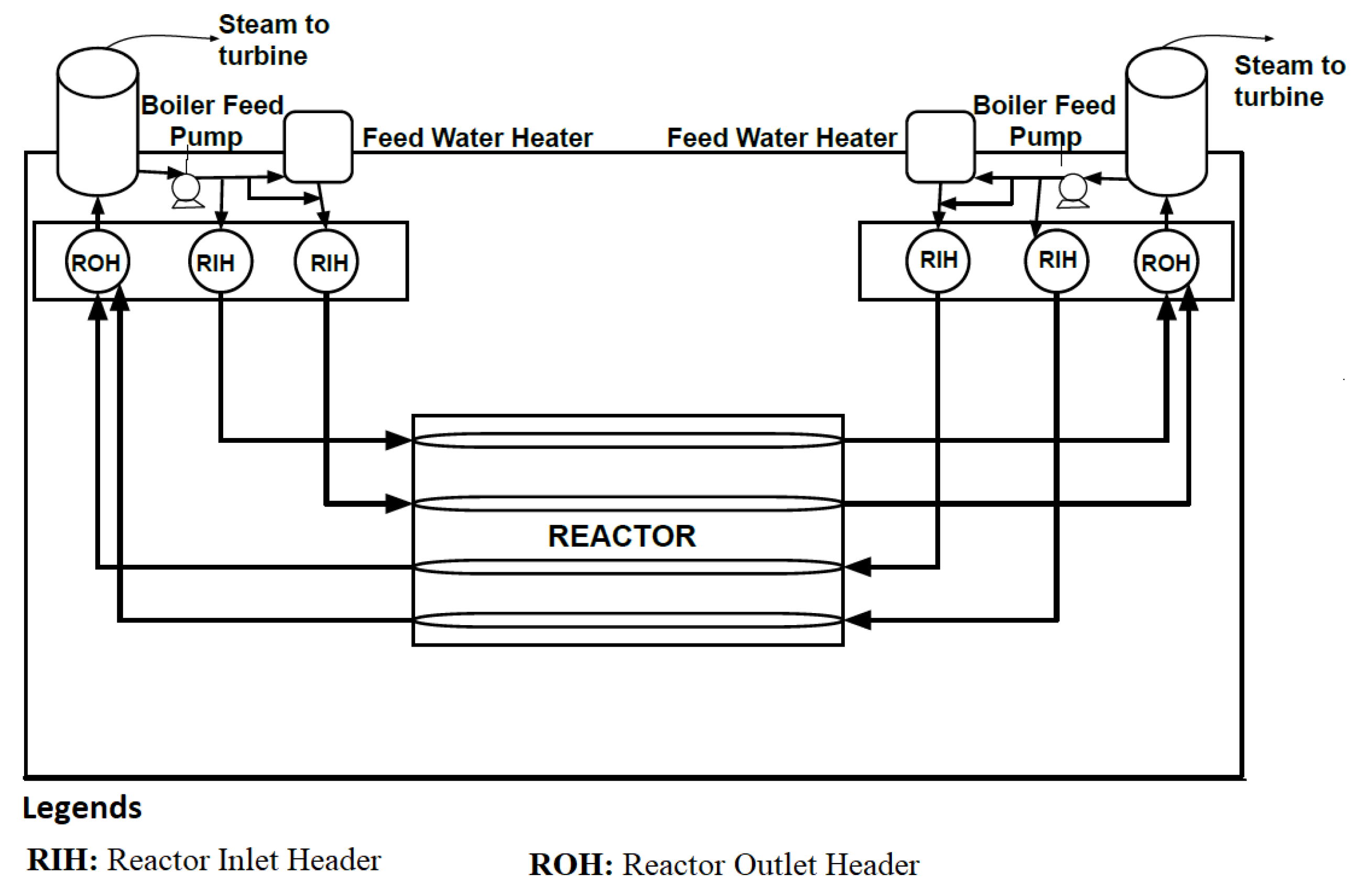
- Boiler Feed Pump: It increases the pressure of feed water and then moves it to the feed water heaters.
- Feed Water Heater: High pressure feed water is preheated to be supplied to the boiler.
- Boiler Drum: Boilers are used to produce high pressure steam which further generates electricity.
- Steam Generation: The high-pressure water from the reactor cooling circuit transfers heat to the feed water in the boiler producing steam to drive the turbine. This steam is then transferred to the turbine for driving the generator to produce electrical energy.
- Reactor Headers: Several Reactor Inlet Headers (RIH) form a part of the reactor’s Primary Heat Transport (PHT) System. The PHT is a closed circulating system that maintains the flow from Inlet Headers through the reactor to the Outlet Header (ROH). The basic arrangement of reactor headers is shown in Figure 1.
4. Methodology Overview
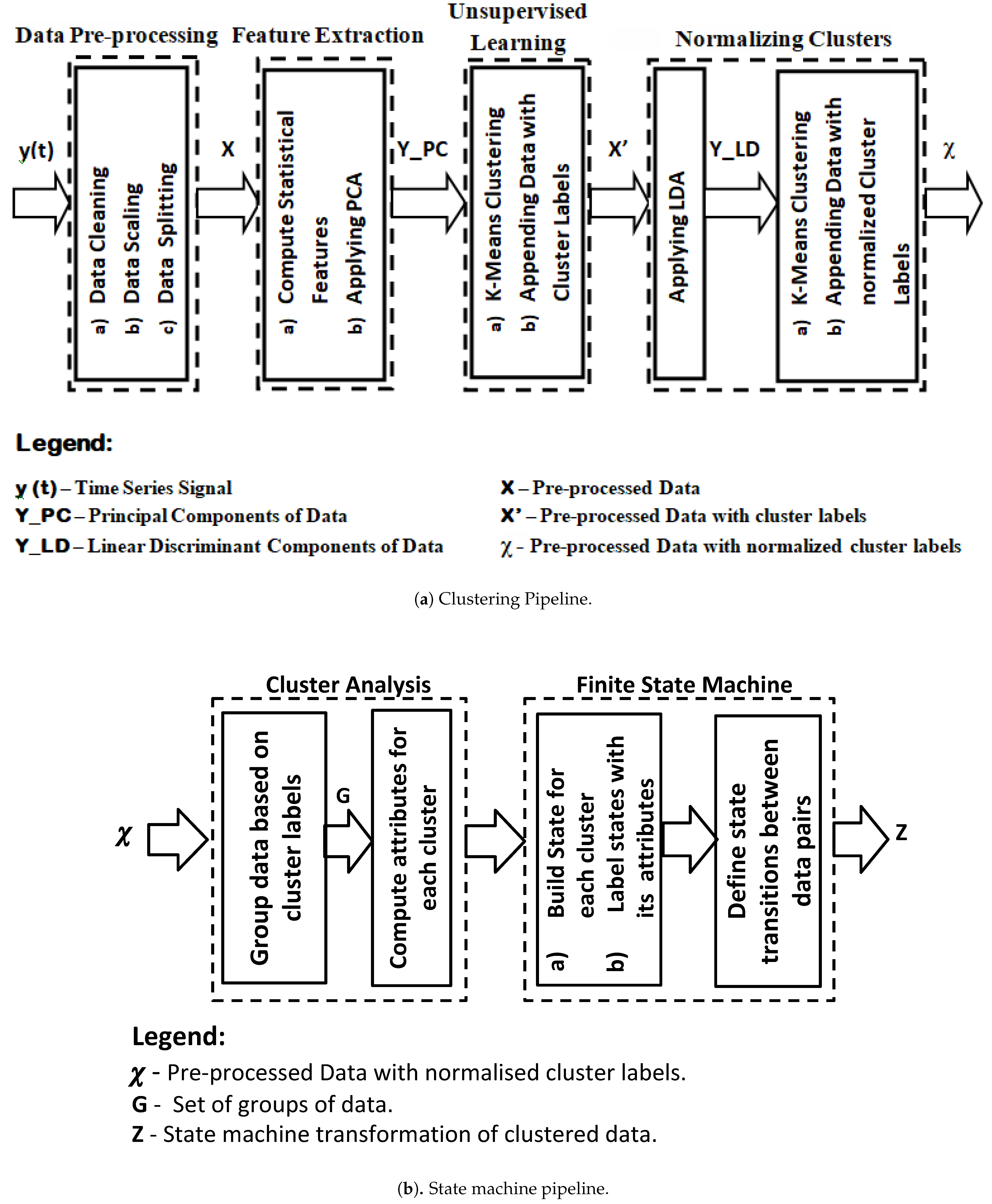
4.1. Clustering Pipeline
| Algorithm 1: Feature Extraction and Clustering of time series data. |
 |
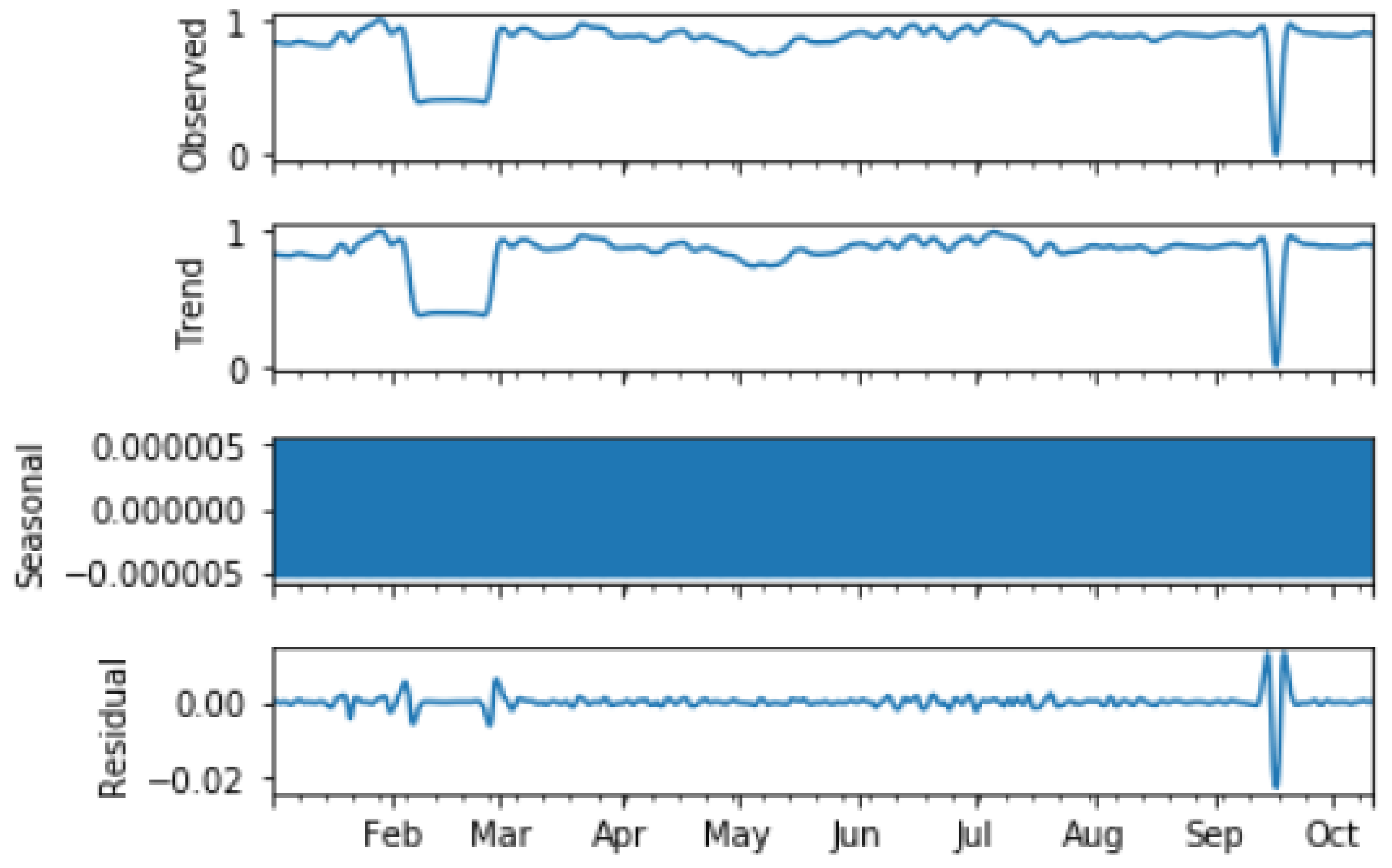
4.1.1. Data Preprocessing
4.1.2. Feature Extraction
4.1.3. Unsupervised Learning
4.1.4. Normalising Clusters
4.2. State Machine Pipeline
| Algorithm 2: Finite State Machine Representation |
 |
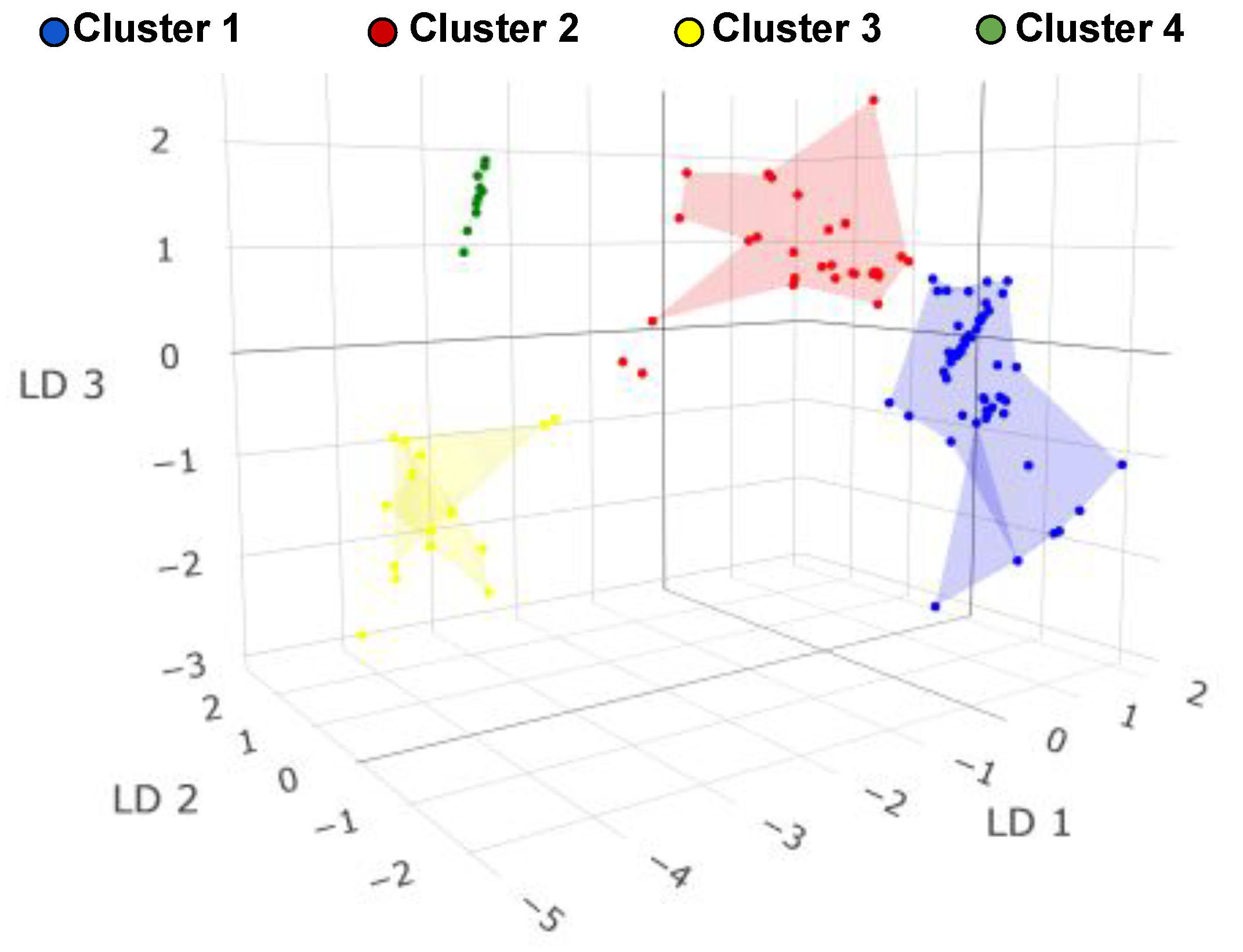
4.2.1. Cluster Analysis
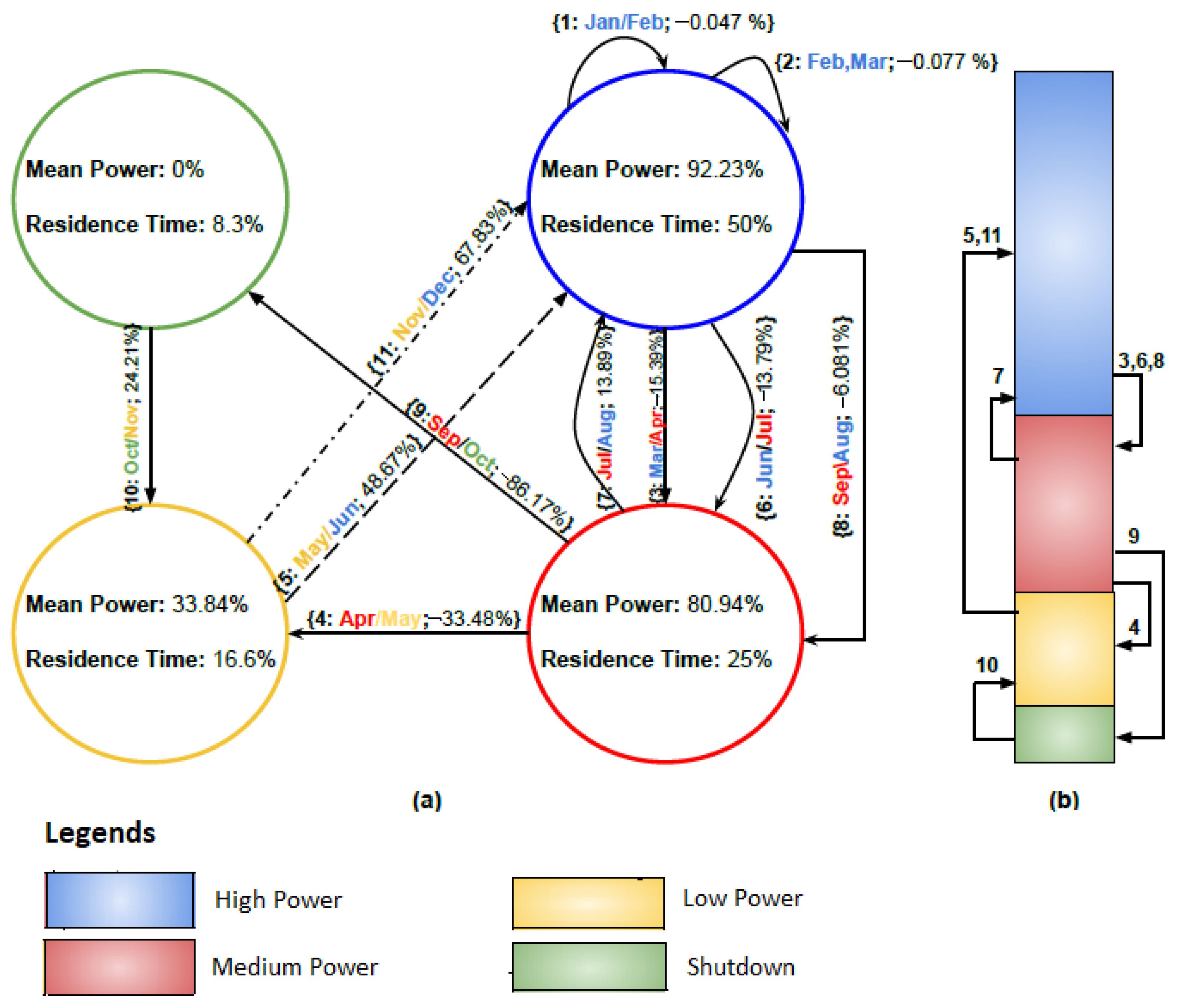
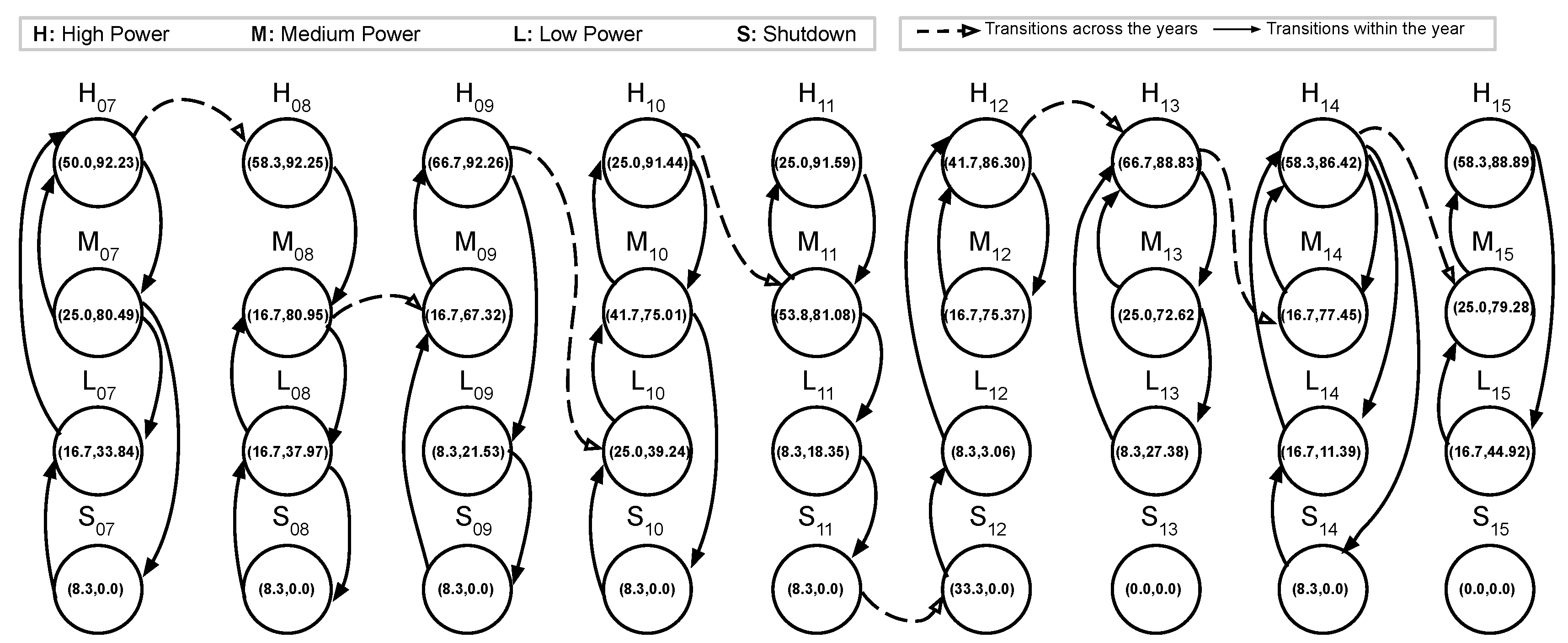
4.2.2. Finite State Machine
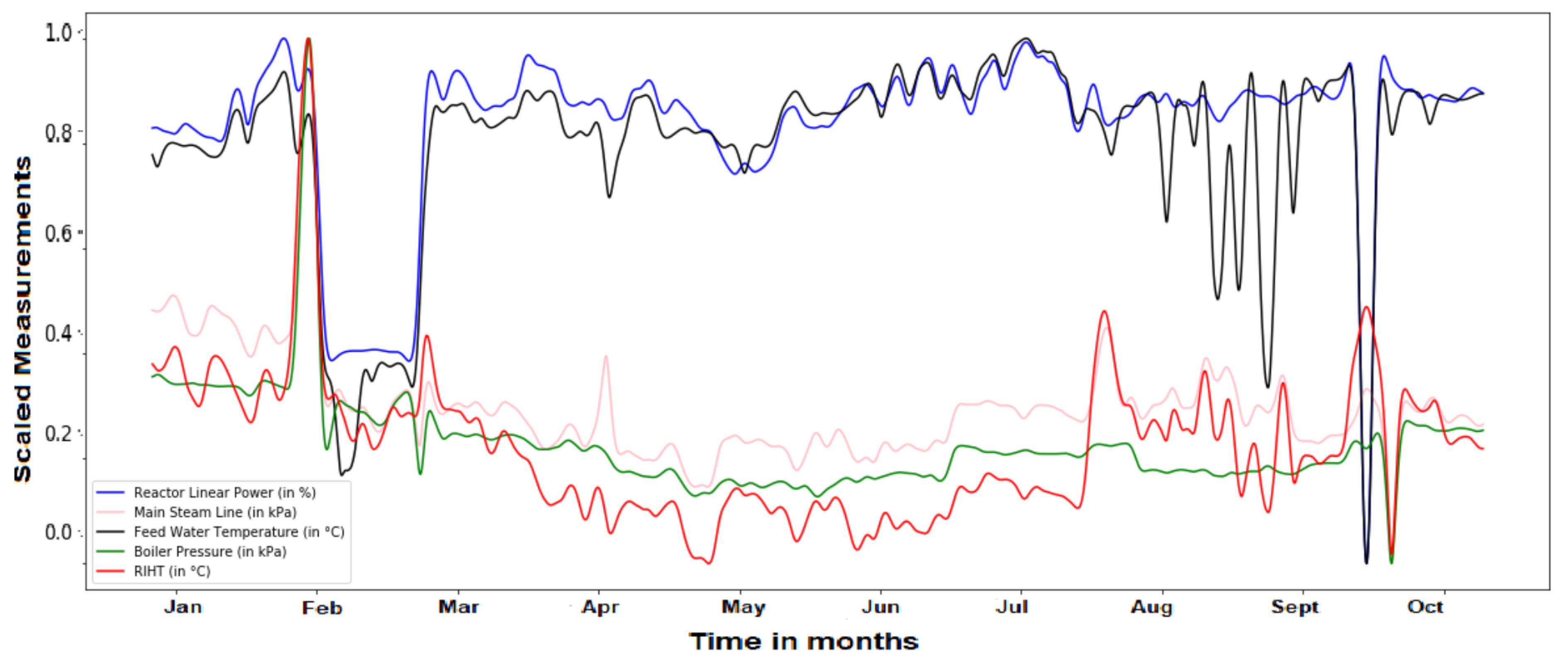
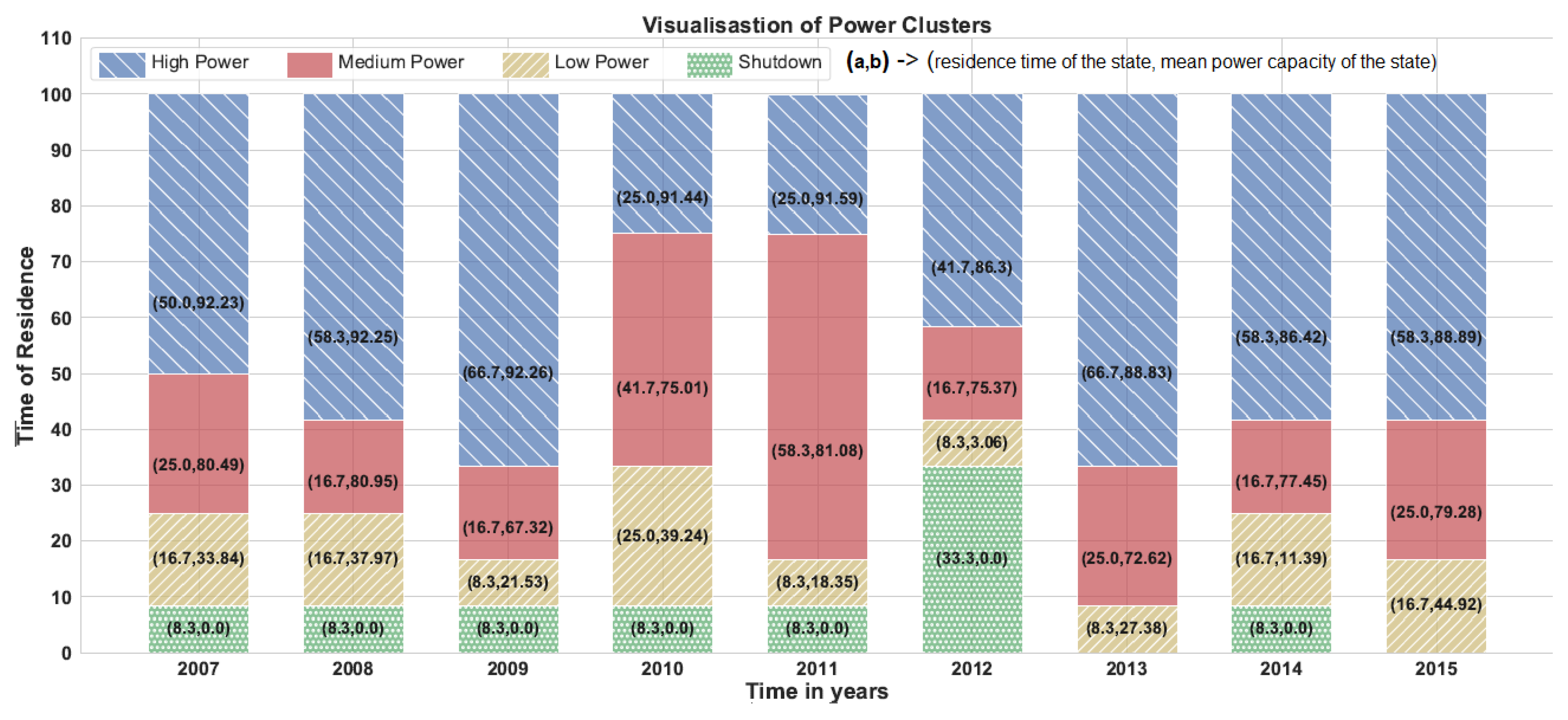
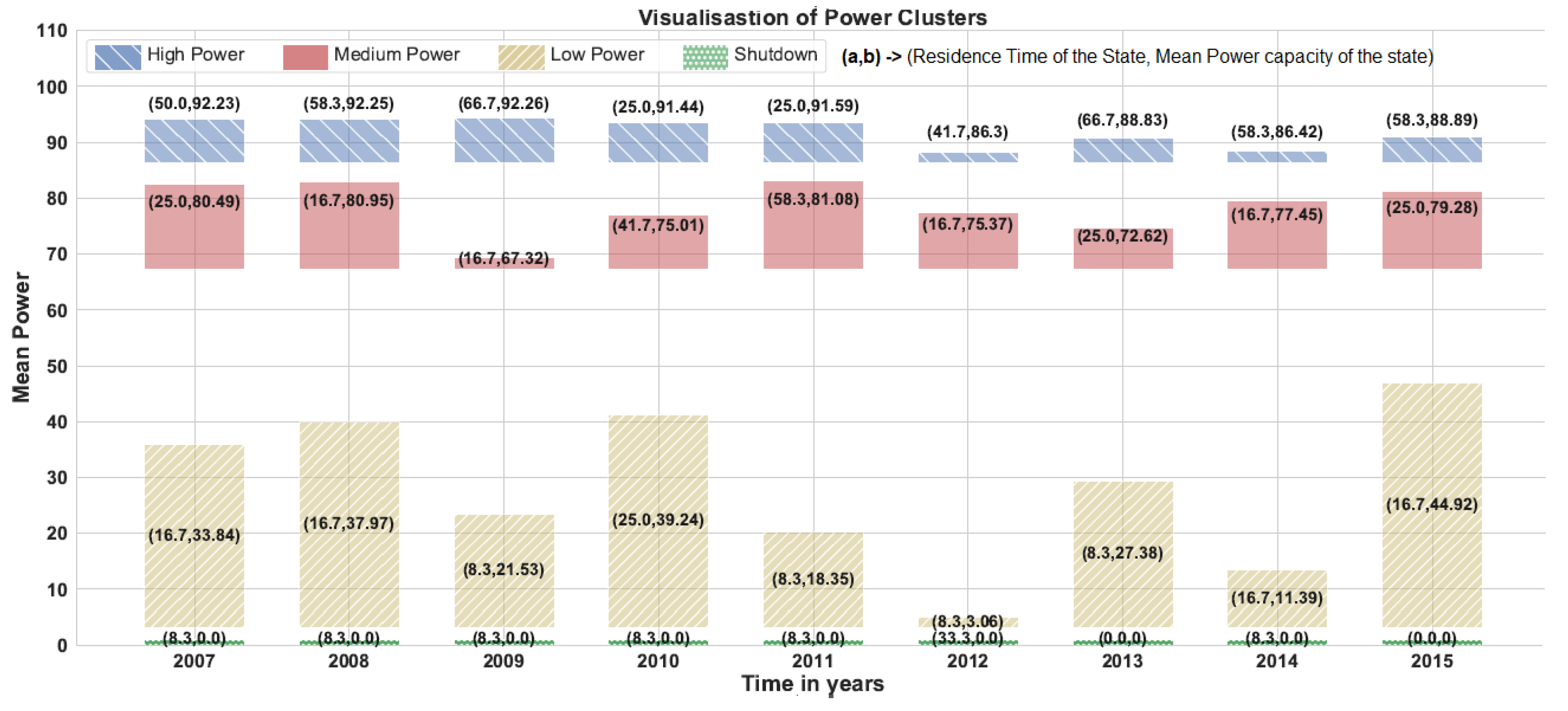
5. Visualisation of NPP’s Power Data
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| NPP | Nuclear Power Plant |
| CPS | Cyber Physical Systems |
| PCA | Principal Component Analysis |
| PC | Principal Components |
| LDA | Linear Discriminant Analysis |
| LD | Linear Discriminant |
| FSM | Finite State Machine |
| RVM | Relevant Vector Machine |
| PHT | Primary Heat Transport |
| RIH | Reactor Inlet Header |
| ROH | Reactor Outlet Header |
| ADF | Augmented Dickey Fuller |
Appendix A
Appendix A.1. Principal Component Analysis
Appendix A.2. Linear Discriminant Analysis
Appendix A.3. K-Means Clustering
Appendix A.4. Silhouette Analysis
References
- Derler, P.; Lee, E.A.; Vincentelli, A.S. Modeling cyber—Physical systems. Proc. IEEE 2011, 100, 13–28. [Google Scholar] [CrossRef]
- Galvão, J.; Machado, J.; Prisacaru, G.; Olaru, D.; Bujoreanu, C. Modelling cyber-physical systems: Some issues and directions. In Proceedings of the IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2018; Volume 444, p. 042007. [Google Scholar]
- Ayo-Imoru, R.M.; Cilliers, A.C. Continuous machine learning for abnormality identification to aid condition-based maintenance in nuclear power plant. Ann. Nucl. Energy 2018, 118, 61–70. [Google Scholar] [CrossRef]
- Ali, M.; Jones, M.W.; Xie, X.; Williams, M. TimeCluster: Dimension reduction applied to temporal data for visual analytics. Vis. Comput. 2019, 35, 1013–1026. [Google Scholar] [CrossRef] [Green Version]
- Martin, F.L.; German, M.J.; Wit, E.; Fearn, T.; Ragavan, N.; Pollock, H.M. Identifying variables responsible for clustering in discriminant analysis of data from infrared microspectroscopy of a biological sample. J. Comput. Biol. 2007, 14, 1176–1184. [Google Scholar] [CrossRef] [PubMed]
- Oza, N.; Tumer, K. Dimensionality Reduction through Classifier Ensembles; Technical Report NASA-ARC-IC-1999-126; NASA Ames Labs: Mountain View, CA, USA, 1999. [Google Scholar]
- Martínez, A.M.; Kak, A.C. Pca Versus lda. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar]
- Haraty, R.A.; Dimishkieh, M.; Masud, M. An enhanced k-means clustering algorithm for pattern discovery in healthcare data. Int. J. Distrib. Sens. Netw. 2015, 11, 615740. [Google Scholar] [CrossRef]
- Münz, G.; Li, S.; Carle, G. Traffic anomaly detection using k-means clustering. In Proceedings of the GI/ITG Workshop MMBnet, Hamburg, Germany, 2 September 2007; pp. 13–14. [Google Scholar]
- Bellman, R. Dynamic programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef] [PubMed]
- Lonardi, J.L.E.K.S.; Patel, P. Finding motifs in time series. In Proceedings of the 2nd Workshop on Temporal Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 53–68. [Google Scholar]
- Cao, D.; Tian, Y.; Bai, D. Time series clustering method based on Principal Component Analysis. In Proceedings of the 5th International Conference on Information Engineering for Mechanics and Materials, Huhhot, China, 25–26 July 2015; Atlantis Press: Paris, France, 2015. [Google Scholar]
- Pechenizkiy, M.; Tsymbal, A.; Puuronen, S. On combining principal components with Fisher’s linear discriminants for supervised learning. Found. Comput. Decis. Sci. 2006, 31, 59–74. [Google Scholar]
- Zhang, N.; Leatham, K.; Xiong, J.; Zhong, J. PCA-K-Means Based Clustering Algorithm for High Dimensional and Overlapping Spectra Signals. In Proceedings of the 2018 Ninth International Conference on Intelligent Control and Information Processing (ICICIP), Wanzhou, China, 9–11 November 2018; pp. 349–354. [Google Scholar]
- Long, D.W.; Brown, M.; Harris, C. Principal components in time-series modelling. In Proceedings of the 1999 European Control Conference (ECC), Karlsruhe, Germany, 31 August–3 September 1999; pp. 1705–1710. [Google Scholar]
- Kryvyi, S.L. Finite-state automata in information technologies. Cybern. Syst. Anal. 2011, 47, 669. [Google Scholar] [CrossRef]
- Zhou, Z.-Q.; Zhu, Q.-X.; Xu, Y. Time Series Extended Finite-State Machine-Based Relevance Vector Machine Multi-Fault Prediction. Chem. Eng. Technol. 2017, 40, 639–647. [Google Scholar] [CrossRef]
- Kerr, W.; Tran, A.; Cohen, P. Activity recognition with finite state machines. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Ahsan, S.N.; Hassan, S.A. Machine learning based fault prediction system for the primary heat transport system of CANDU type pressurized heavy water reactor. In Proceedings of the 2013 International Conference on Open Source Systems and Technologies, Lahore, Pakistan, 16–18 December 2013; pp. 68–74. [Google Scholar]
- Gohel, H.A.; Upadhyay, H.; Lagos, L.; Cooper, K.; Sanzetenea, A. Predictive maintenance architecture development for nuclear infrastructure using machine learning. Nucl. Eng. Technol. 2020, 52, 1436–1442. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, J. Semisupervised classification for fault diagnosis in nuclear power plants. Nucl. Eng. Technol. 2015, 47, 176–186. [Google Scholar] [CrossRef] [Green Version]
- Chandrakar, A.; Datta, D.; Nayak, A.K.; Vinod, G. Statistical analysis of a time series relevant to passive systems of nuclear power plants. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 89–108. [Google Scholar] [CrossRef]
- Lamarsh, J.R.; Anthony, J.B. Introduction to Nuclear Engineering; Prentice Hall: Upper Saddle River, NJ, USA, 2001; Volume 3. [Google Scholar]
- Zohuri, B.; McDaniel, P. Thermodynamics in Nuclear Power Plant Systems; Springer: New York, NY, USA, 2015. [Google Scholar]
- Garland, W.J. The Essential CANDU; University Network of Excellence in Nuclear Engineering (UNENE): Harbin, China, 2014. [Google Scholar]
- Jolliffe, I.T. Principal components in regression analysis. In Principal Component Analysis; Springer: New York, NY, USA, 1986; pp. 129–155. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Augmented Dickey Fuller Test for Stationarity | ||||
|---|---|---|---|---|
| ADF-Statistic | p-Value | Critical Value at 1% | Critical Value at 5% | Critical Value at 10% |
| 0.370 | 0.980 | −3.431 | −2.861 | −2.566 |
| State Transitions for 2007 | ||
|---|---|---|
| Month-Pair | Change of Value () | Cluster Label Transition (E) |
| January–February | −0.047 | 1-1 |
| February–March | 0.077 | 1-1 |
| March–April | −15.392 | 1-2 |
| April–May | −33.489 | 2-3 |
| May–June | 48.678 | 3-1 |
| June–July | −13.793 | 1-2 |
| July–August | 13.899 | 2-1 |
| August–September | −6.081 | 1-2 |
| September–October | −86.170 | 2-4 |
| October–November | 24.215 | 4-3 |
| November–December | 67.833 | 3-1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naik, K.; Pandey, M.D.; Panda, A.; Albasir, A.; Taneja, K. Data Driven Modelling of Nuclear Power Plant Performance Data as Finite State Machines. Modelling 2021, 2, 43-62. https://doi.org/10.3390/modelling2010003
Naik K, Pandey MD, Panda A, Albasir A, Taneja K. Data Driven Modelling of Nuclear Power Plant Performance Data as Finite State Machines. Modelling. 2021; 2(1):43-62. https://doi.org/10.3390/modelling2010003
Chicago/Turabian StyleNaik, Kshirasagar, Mahesh D. Pandey, Anannya Panda, Abdurhman Albasir, and Kunal Taneja. 2021. "Data Driven Modelling of Nuclear Power Plant Performance Data as Finite State Machines" Modelling 2, no. 1: 43-62. https://doi.org/10.3390/modelling2010003
APA StyleNaik, K., Pandey, M. D., Panda, A., Albasir, A., & Taneja, K. (2021). Data Driven Modelling of Nuclear Power Plant Performance Data as Finite State Machines. Modelling, 2(1), 43-62. https://doi.org/10.3390/modelling2010003