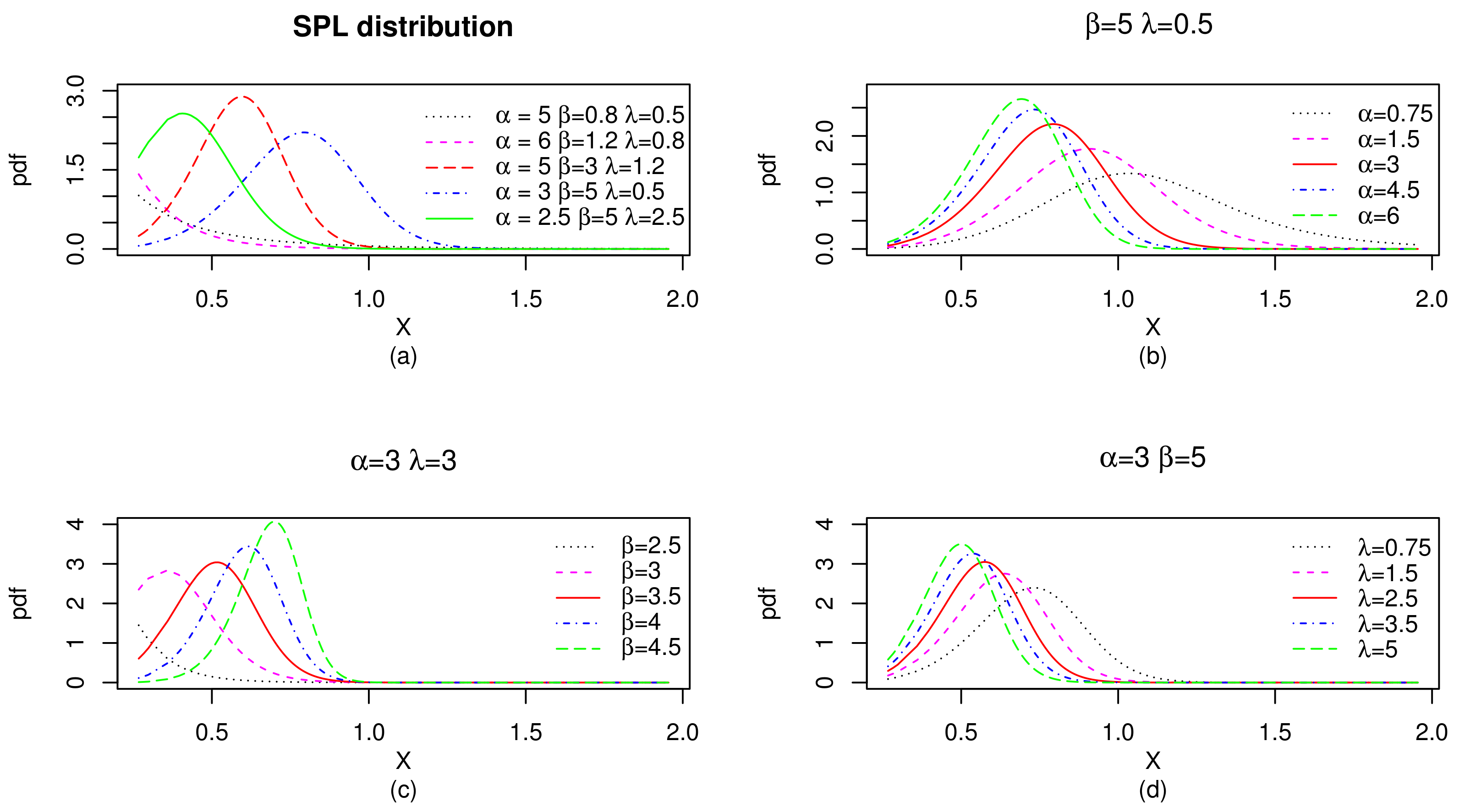
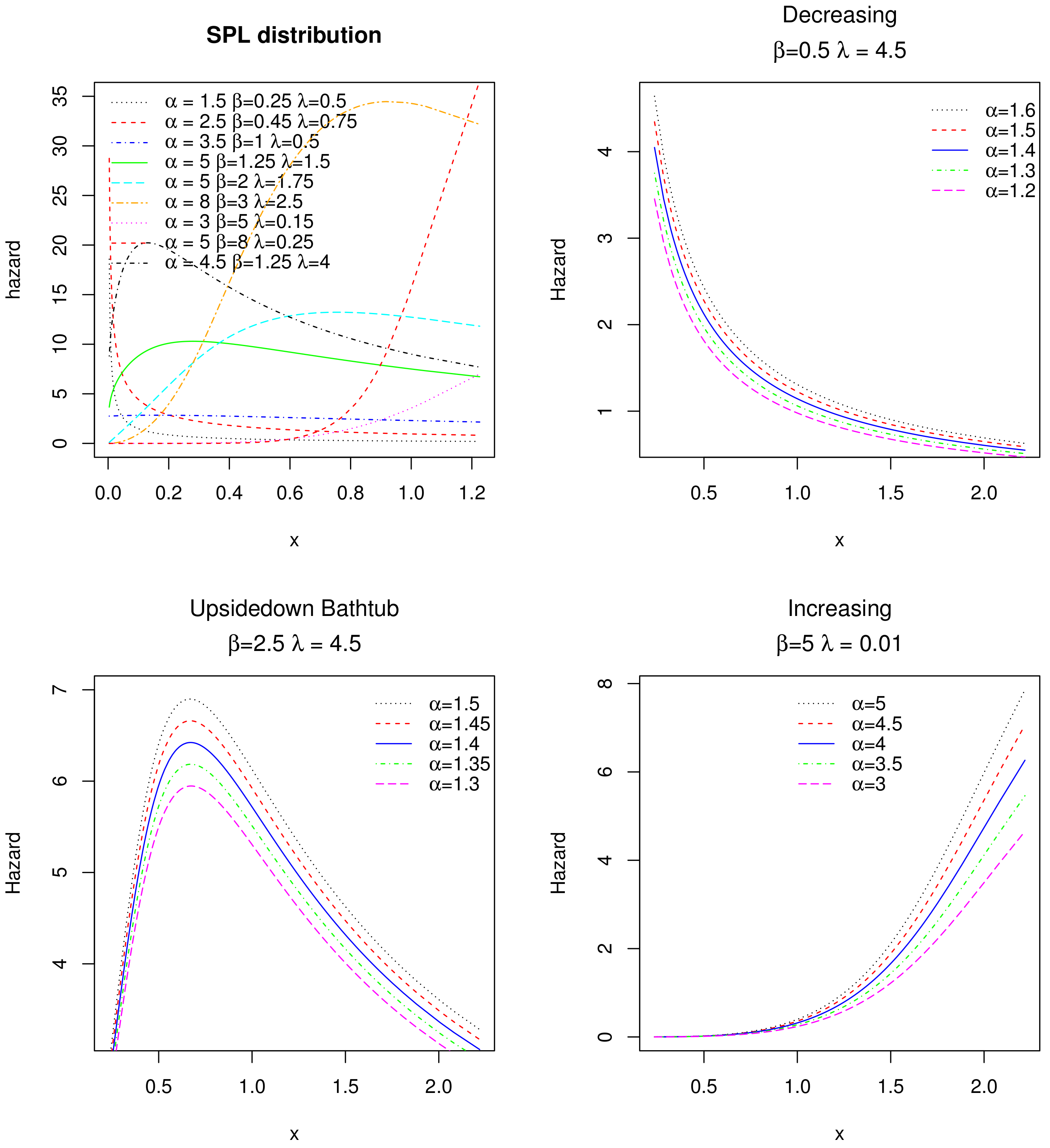
4. Applications of the SPL Model
Based on the above methodology, we apply the SPL model on nine datasets. They differ mainly in size, characteristics or background, but all of them are of modern interest to their respective fields. For each dataset, we proceed as follows:
We briefly present the data, with reference(s).
We provide a table that summarizes the main statistical characteristics of the data.
We assess the quality of the fit measures of the models considered and organize them in a table in order of the model performance.
As complementary work, we indicate the MLES of the model parameters as well as the related SEs.
We end with a visual approach by plotting the histogram of the data and the fitted pdfs, and, in another graph, the probability-probability (PP) plot for the SPL model only.
Data set 1: We consider a real dataset on the remission times (in months) of a random sample of 128 bladder cancer patients. This dataset is given by Lee and Wang [
40] and it contains the following values: 0.08, 2.09, 3.48, 4.87, 6.94, 8.66, 13.11, 23.63, 0.20, 2.23, 3.52, 4.98, 6.97, 9.02, 13.29, 0.40, 2.26, 3.57, 5.06, 7.09, 9.22, 13.80, 25.74, 0.50, 2.46, 3.64, 5.09, 7.26, 9.47, 14.24, 25.82, 0.51, 2.54, 3.70, 5.17, 7.28, 9.74, 14.76, 26.31, 0.81, 2.62, 3.82, 5.32, 7.32, 10.06, 14.77, 32.15, 2.64, 3.88, 5.32, 7.39, 10.34, 14.83, 34.26, 0.90, 2.69, 4.18, 5.34, 7.59, 10.66, 15.96, 36.66, 1.05, 2.69, 4.23, 5.41, 7.62, 10.75, 16.62, 43.01, 1.19, 2.75, 4.26, 5.41, 7.63, 17.12, 46.12, 1.26, 2.83, 4.33, 5.49, 7.66, 11.25, 17.14, 79.05, 1.35, 2.87, 5.62, 7.87, 11.64, 17.36, 1.40, 3.02, 4.34, 5.71, 7.93, 11.79, 18.10, 1.46, 4.40, 5.85, 8.26, 11.98, 19.13, 1.76, 3.25, 4.50, 6.25, 8.37, 12.02, 2.02, 3.31, 4.51, 6.54, 8.53, 12.03, 20.28, 2.02, 3.36, 6.76, 12.07, 21.73, 2.07, 3.36, 6.93, 8.65, 12.63, 22.69.
A summary measure of descriptive statistics of dataset 1 is provided in
Table 4.
We see in
Table 4 that the data are right skewed and highly leptokurtic with high variance. With respect to model adequacy, the measures W*, A*,
,
p-Value, AIC, CAIC, BIC and HQIC are reported in
Table 5.
From
Table 5, we observe that the SPL model possesses the lowest values for W*, A*,
, AIC, CAIC, BIC and HQIC, and the highest value for
p-Value compared to the other models. It can be considered the best. The second best model is the PL model.
Please note that for this dataset, the results for the TLGL and EL models are almost identical due to their similar nature, but small numerical variations are observed without rounding.
For additional information, the MLEs of the model parameters as well as their SEs are reported in
Table 6.
From
Table 6, among other, we see that the parameters
,
and
of the SPL model have been estimated by
,
and
, respectively, with quite small SEs.
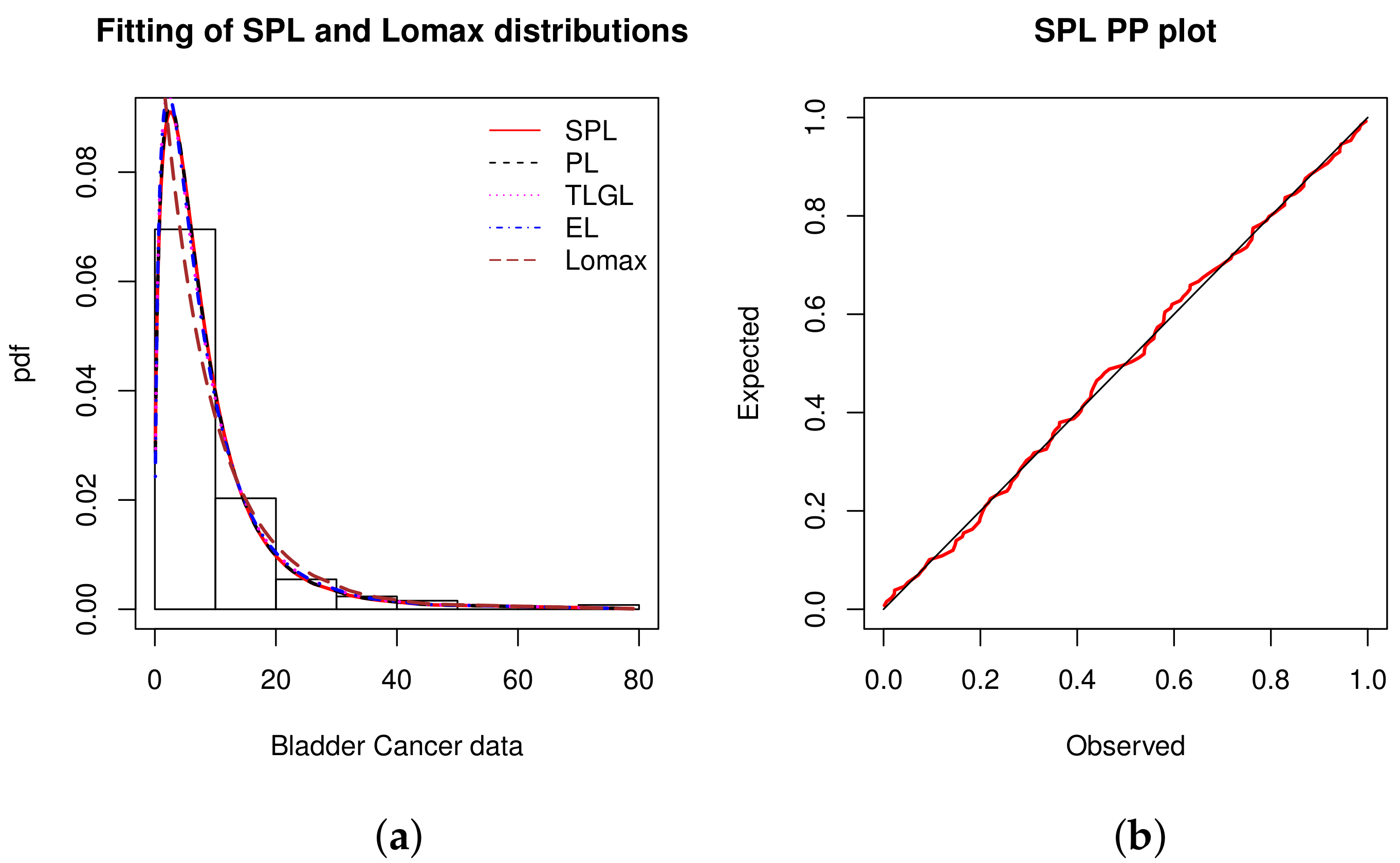
Figure 3 shows two graphics: the histogram of the data fitted by the estimated pdfs, and the PP plot for the SPL model only.
In
Figure 3, we observe that the empirical objects are almost perfectly adjusted by the estimated objects. In particular, in the PP plot, the black line is almost confused with the estimated red line related to the SPL model.
Data set 2: The considered data represent the failure times of the mechanical components of the aircraft windshield. They are taken from [
41]. They were recently reviewed by [
42]. The data are: 0.040, 1.866, 2.385, 3.443, 0.301, 1.876, 2.481, 3.467, 0.309, 1.899, 2.610, 3.478, 0.557, 1.911, 2.625, 3.578, 0.943, 1.912, 2.632, 3.595, 1.070, 1.914, 2.646, 3.699, 1.124, 1.981, 2.661, 3.779, 1.248, 2.010, 2.688, 3.924, 1.281, 2.038, 2.823, 4.035, 1.281, 2.085, 2.890, 4.121, 1.303, 2.089, 2.902, 4.167, 1.432, 2.097, 2.934, 4.240, 1.480, 2.135, 2.962, 4.255, 1.505, 2.154, 2.964, 4.278, 1.506, 2.190, 3.000, 4.305, 1.568, 2.194, 3.103, 4.376, 1.615, 2.223, 3.114, 4.449, 1.619, 2.224, 3.117, 4.485, 1.652, 2.229, 3.166, 4.570, 1.652, 2.300, 3.344, 4.602, 1.757, 2.324, 3.376, 4.663.
A summary of descriptive statistics for dataset 2 is provided in
Table 7.
Based on the information of
Table 7, we can say that the data are approximately symmetric and platykurtic, with little dispersion. One more point, we observe that the data have a negative kurtosis value which means that the underlying distributions should have lighter tails.
The statistical measures considered for the comparison of the models are given in
Table 8.
From
Table 8, the values of the model adequacy measures and goodness of fit test are clearly in favor of the SPL model. The second best model is the PL model.
The MLEs of the parameters of the SPL model and other models with their SEs are reported in
Table 9.
In addition, the estimated pdfs over the histogram and PP plot of the SPL model are displayed in
Figure 4.
From
Figure 4, it is obvious that the light tails of the SPL model are instrumental in having a better fit. In addition, the PP plot underlines this power of adaptation; the black line is almost confused with the estimated red line.
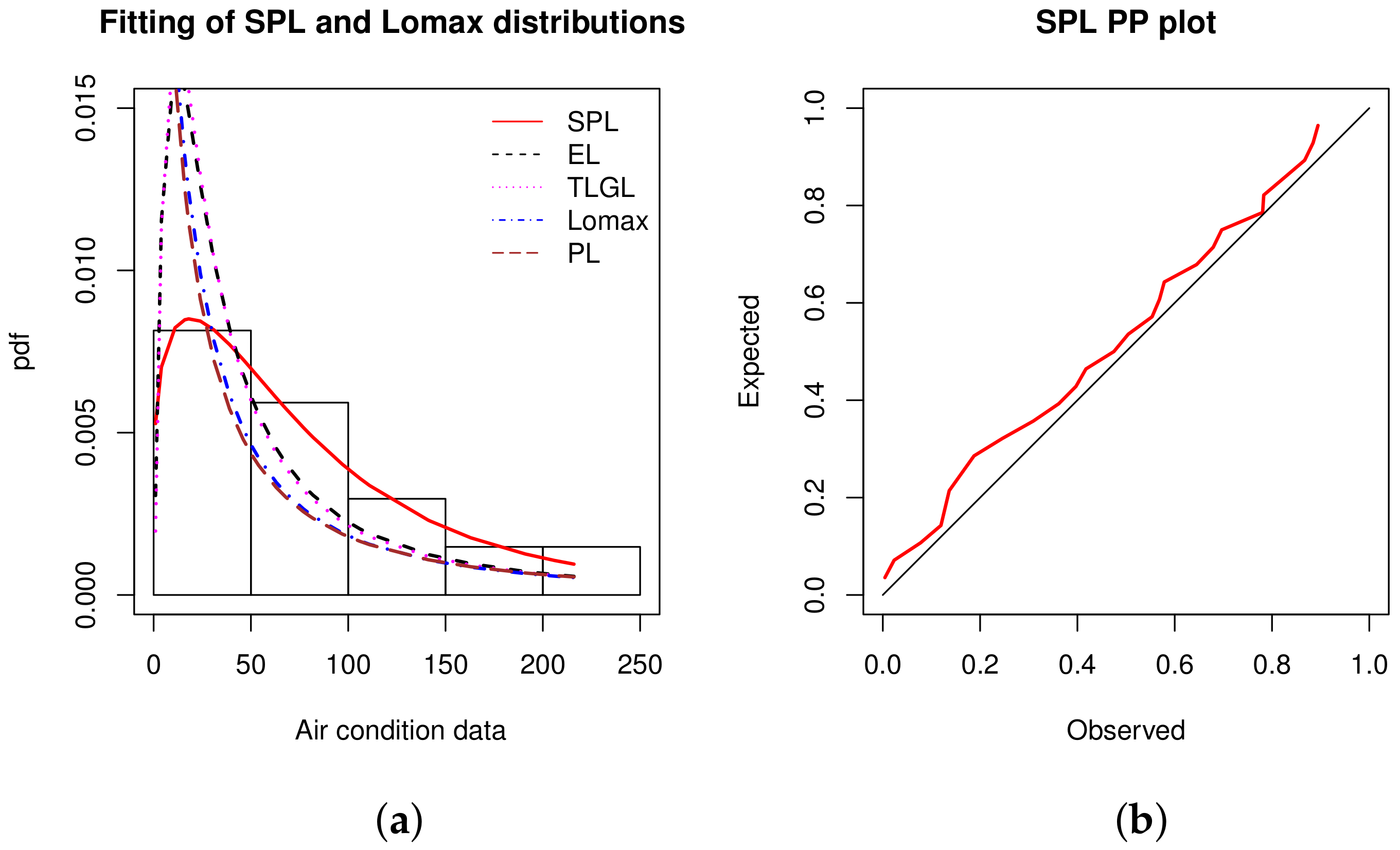
Data set 3: We now consider a dataset containing 27 observations of time of successive failures of the air conditioning system of jets in a fleet of Boeing 720 as reported in Proschan [
43]. Recently, this data was studied by [
44] and the data are: 1, 4, 11, 16, 18, 18, 18, 24, 31, 39, 46, 51, 54, 63, 68, 77, 80, 82, 97, 106, 111, 141, 142, 163, 191, 206, 216.
Some descriptive measures of dataset 3 are provided in
Table 10.
From
Table 10, we see that the data are right skewed and platykurtic with a high variance.
Table 11 indicates the values of the statistical measures considered to compare the models.
The analysis of
Table 11 ensures that the SPL model is the best with, in particular,
p-Value
. The second best model is the EL model.
The MLEs of the model parameters as well as their SEs are reported in
Table 12.
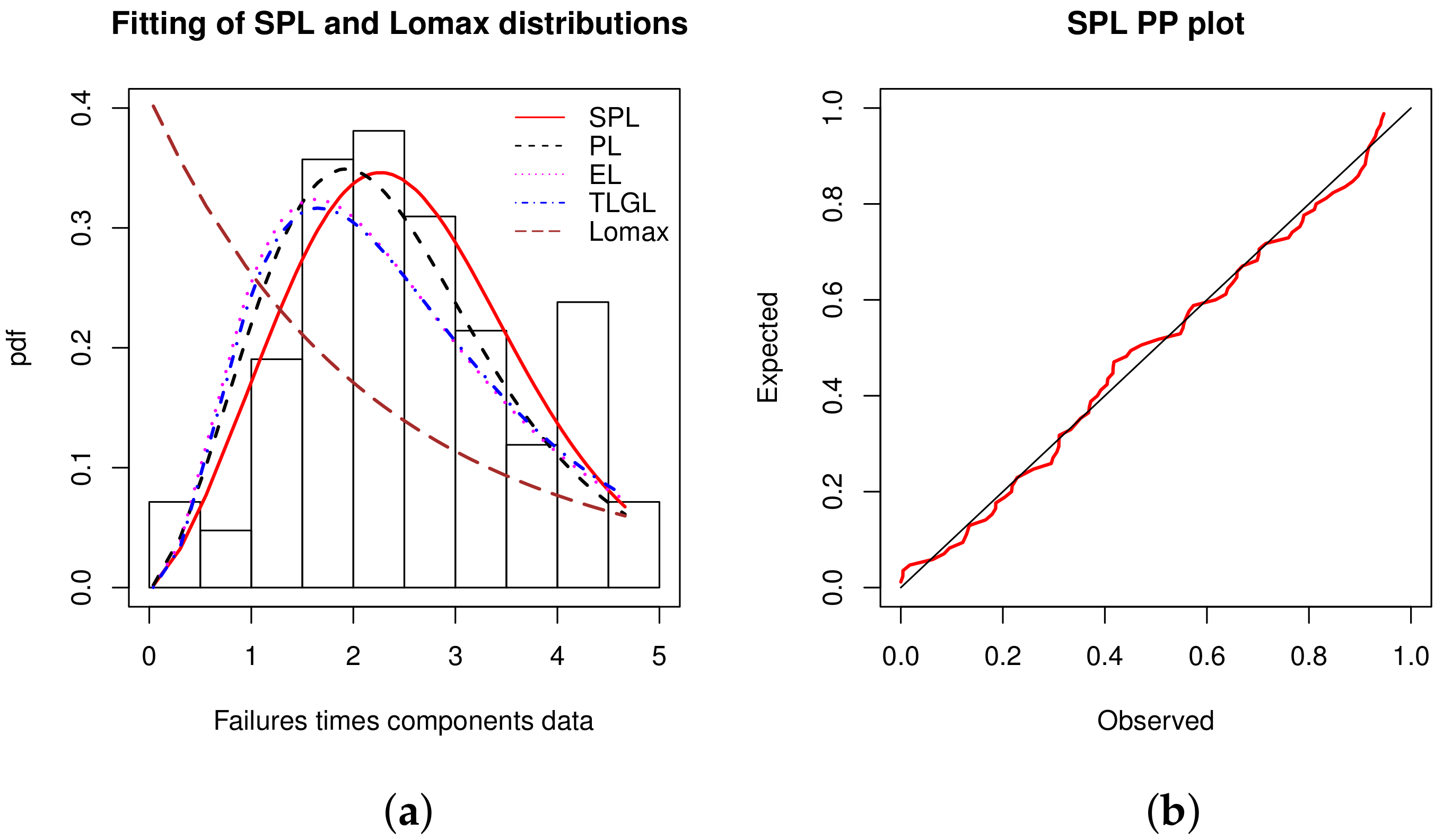
The estimated pdfs over the histogram and the PP plot of the SPL model are shown in
Figure 5.
In
Figure 5, the fitted power of the SPL model is flagrant; the corresponding estimated pdf has captured the decreasing roundness shape of the histogram, contrary to the other estimated pdfs. In addition, the red line of the PP plot is generally close to the black line.
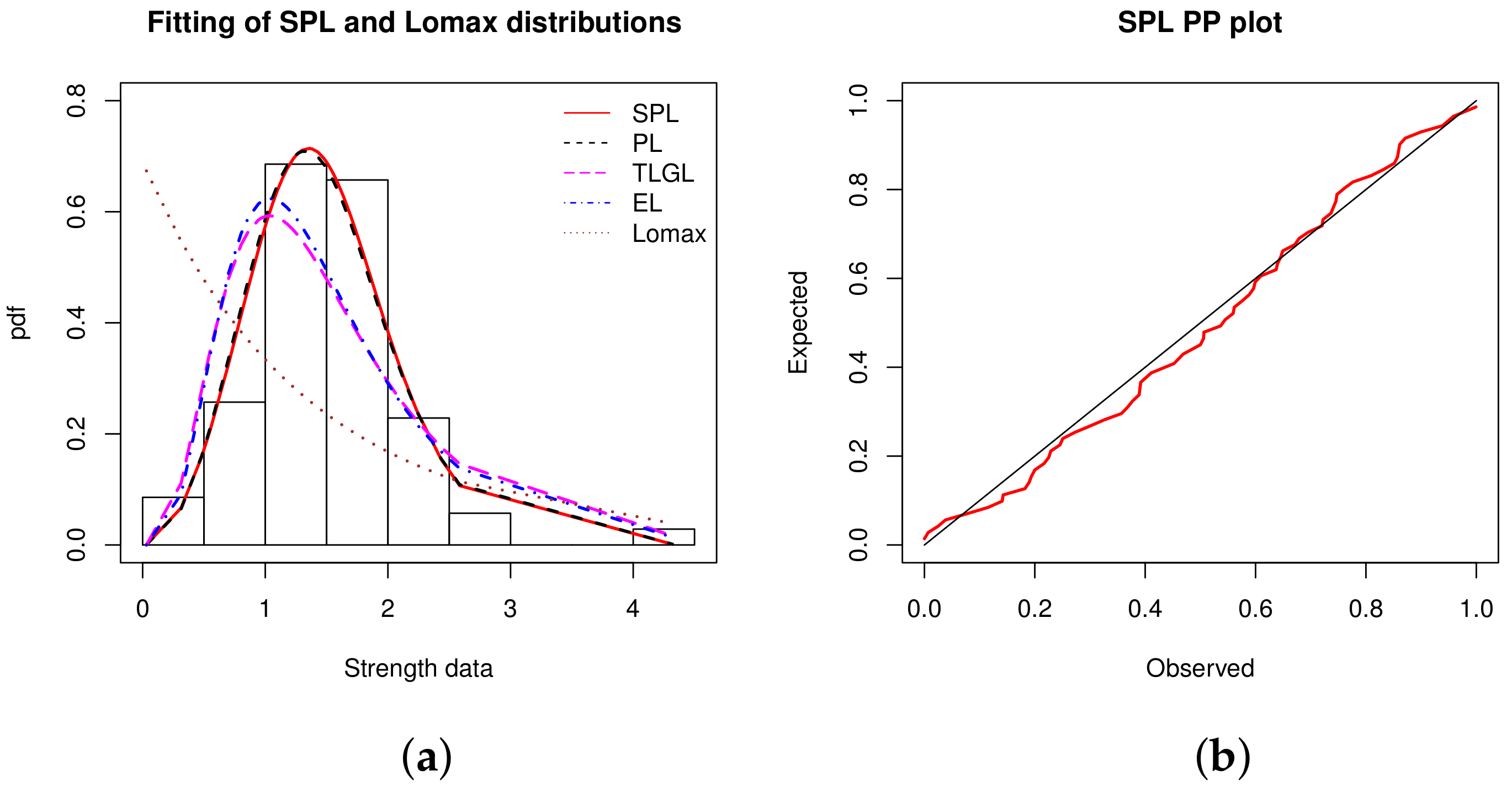
Data set 4: The data represent 69 strength measures for single carbon fibers (and impregnated 1000-carbon fiber tows). They are given by [
45]. The measures in GPA by subtracting 1 are: 0.0312, 0.314, 0.479, 0.552, 0.700, 0.803, 0.861, 0.865, 0.944, 0.958, 0.966, 0.977, 1.006, 1.021, 1.027, 1.055, 1.063, 1.098, 1.140, 1.179, 1.224, 1.240, 1.253, 1.270, 1.272, 1.274, 1.301, 1.301, 1.359, 1.382, 1.382, 1.426, 1.434, 1.435, 1.478, 1.490, 1.511, 1.514, 1.535, 1.554, 1.566, 1.570, 1.586, 1.629, 1.633, 1.642, 1.648, 1.684, 1.697, 1.726, 1.770, 1.773, 1.800, 1.809, 1.818, 1.821, 1.848, 1.880, 1.954, 2.012, 2.067, 2.084, 2.090, 2.096, 2.128, 2.233, 2.433, 2.585, 2.585,4.32.
A statistical description of dataset 4 is given in
Table 13.
Table 13 shows that the data are almost symmetric and leptokurtic, with a low variance.
The fitting performance of the considered models are investigated numerically in
Table 14.
From
Table 14, we see that the SPL model is more relevant for the fit of the dataset than the other models. Indeed, it has the lowest value for all the statistical measures considered, except for the
p-Value where it has the highest value. The second best model is the PL model.
Table 15 contains the MLEs of the considered models along with their SEs.
The fitted histogram of the data is shown in
Figure 6, along with the PP plot of the SPL model.
From
Figure 6, the curve of the estimated pdf of the SPL model is close to the shape of the histogram and has captured the ‘elbow phenomena’ in the right. The corresponding PP plot is also convincing.
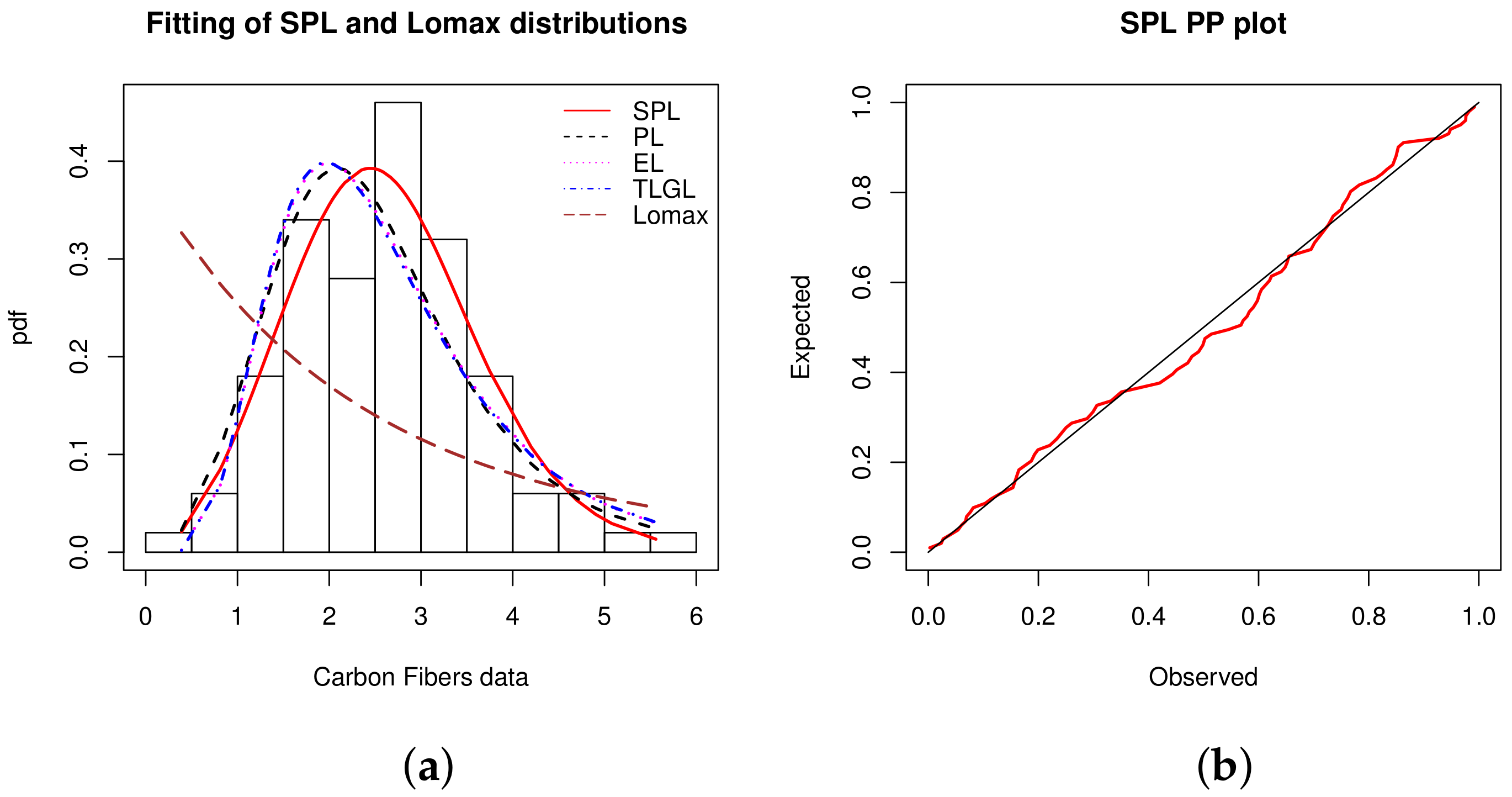
Data set 5: We now consider a dataset containing 100 observations on breaking stress of carbon fibers (in Gba). It was studied by [
46] and the data are: 3.7, 2.74, 2.73, 2.5, 3.6, 3.11, 3.27, 2.87, 1.47, 3.11,4.42, 2.41, 3.19, 3.22, 1.69, 3.28, 3.09, 1.87, 3.15, 4.9, 3.75, 2.43, 2.95, 2.97, 3.39, 2.96, 2.53,2.67, 2.93, 3.22, 3.39, 2.81, 4.2, 3.33, 2.55, 3.31, 3.31, 2.85, 2.56, 3.56, 3.15, 2.35, 2.55, 2.59,2.38, 2.81, 2.77, 2.17, 2.83, 1.92, 1.41, 3.68, 2.97, 1.36, 0.98, 2.76, 4.91, 3.68, 1.84, 1.59, 3.19,1.57, 0.81, 5.56, 1.73, 1.59, 2, 1.22, 1.12, 1.71, 2.17, 1.17, 5.08, 2.48, 1.18, 3.51, 2.17, 1.69,1.25, 4.38, 1.84, 0.39, 3.68, 2.48, 0.85, 1.61, 2.79, 4.7, 2.03, 1.8, 1.57, 1.08, 2.03, 1.61, 2.12,1.89, 2.88, 2.82, 2.05, 3.65.
A summary of descriptive statistics for these data is presented in
Table 16.
From
Table 16, we see that the data are approximately symmetric and platykurtic with a low variability.
The statistical measures considered for the comparison of the models are given in
Table 17.
In our framework,
Table 17 attests to the superior adequacy of the SPL model.
The MLEs of the model parameters and their SEs are reported in
Table 18.
A visual work is performed in
Figure 7, showing the histogram and PP plot of the SPL model.
In
Figure 7, the flexible skewness of the SPL model is clearly the key, allowing the symmetrical nature of the data to be fully captured. The observation of the PP plot confirm the high quality of the fit of the SPL model.
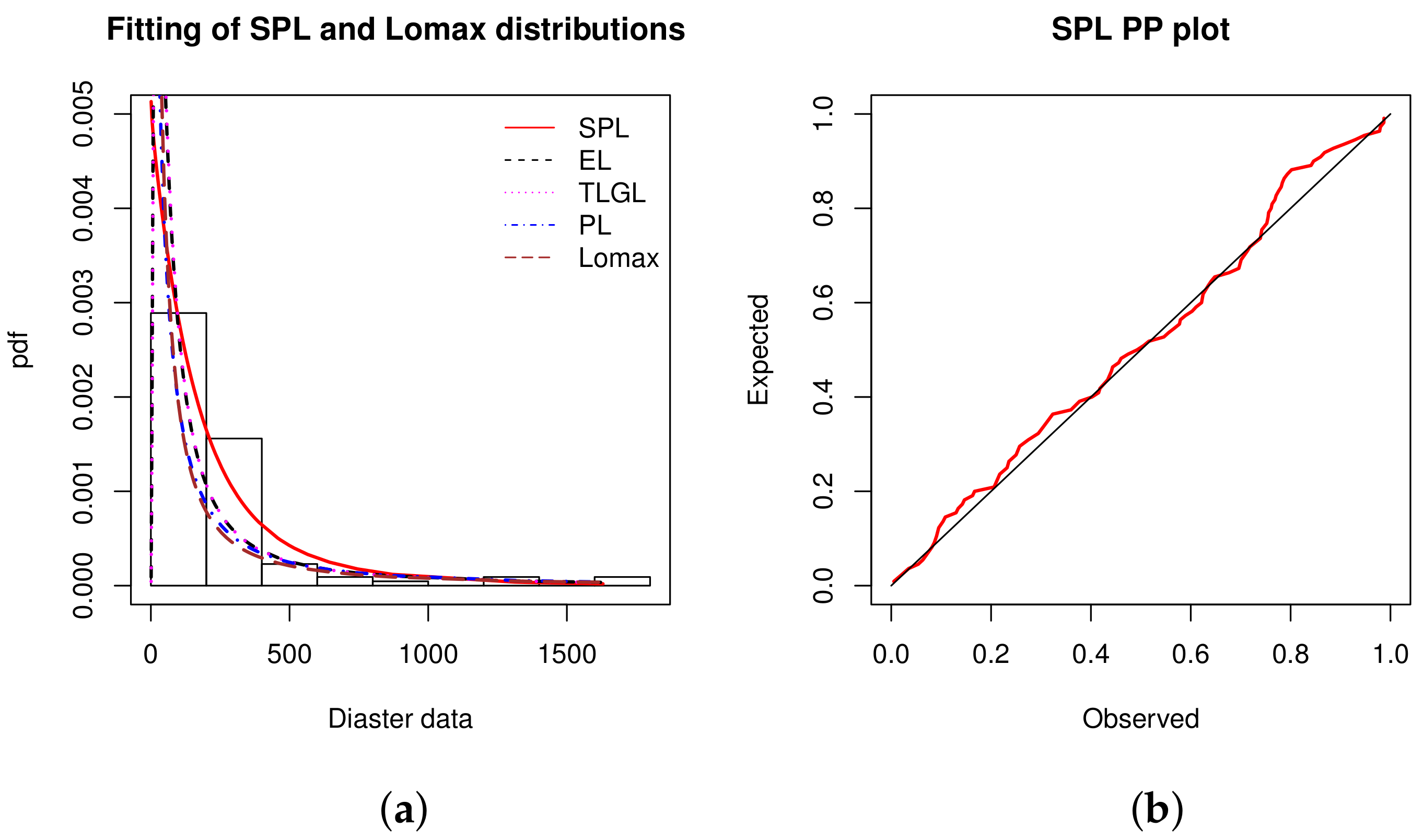
Data set 6: The data correspond to times in days between 109 successive mining catastrophes in Great Britain, for the period 1875-1951, as published in [
47]. The sorted data are given as follows: 1, 4, 4, 7, 11, 13, 15, 15, 17, 18, 19, 19, 20, 20, 22, 23, 28, 29, 31, 32, 36, 37, 47, 48, 49, 50, 54, 54, 55, 59, 59, 61, 61, 66, 72, 72, 75, 78, 78, 81, 93, 96, 99, 108, 113, 114, 120, 120, 120, 123, 124, 129, 131, 137, 145, 151, 156, 171, 176, 182, 188, 189, 195, 203, 208, 215, 217, 217, 217, 224, 228, 233, 255, 271, 275, 275, 275, 286, 291, 312, 312, 312, 315, 326, 326, 329, 330, 336, 338, 345, 348, 354, 361, 364, 369, 378, 390, 457, 467, 498, 517, 566, 644, 745, 871, 1312, 1357, 1613, 1630.
A descriptive statistical summary of dataset 6 is presented in
Table 19.
From
Table 19, we can say that the data are right skewed and leptokurtic, with a very high variance.
The goodness of fit measures of the considered models are calculated and collected in
Table 20.
From
Table 20, the SPL model shows the best results, far superior to those of the competition. The second best model is the EL model.
The MLEs of the model parameters along with their SEs are reported in
Table 21.
Figure 8 illustrates the nice fit of the SPL model by two different graphical approaches.
From
Figure 8, we observe that the adjustment of the SPL model proposes a slope more adapted to the form of the histogram of the data, compared to those of the other models. A nice result in the PP plot is also observed.
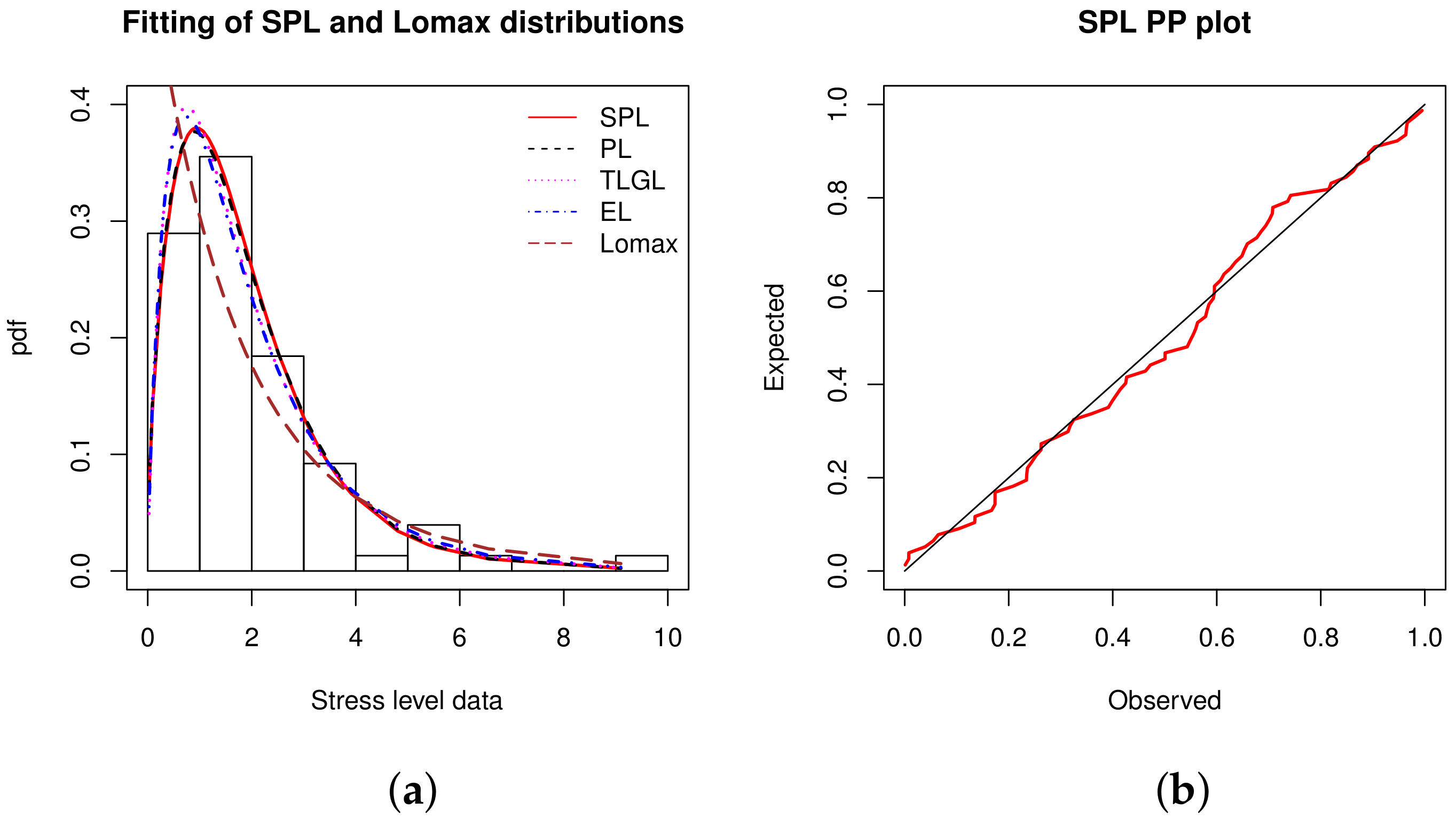
Data set 7: The data are measures of life of Kevlar 373/epoxy fatigue fractures that are subjected to constant pressure (at the 90% stress level) until all has failed. These data was recently studied by [
13] and they are: 0.0251, 0.0886, 0.0891, 0.2501, 0.3113, 0.3451, 0.4763, 0.5650, 0.5671, 0.6566, 0.6748, 0.6751, 0.6753, 0.7696, 0.8375, 0.8391, 0.8425, 0.8645, 0.8851, 0.9113, 0.9120, 0.9836, 1.0483, 1.0596, 1.0773, 1.1733, 1.2570, 1.2766, 1.2985, 1.3211, 1.3503, 1.3551, 1.4595, 1.4880, 1.5728, 1.5733, 1.7083, 1.7263, 1.7460, 1.7630, 1.7746, 1.8275, 1.8375, 1.8503, 1.8808, 1.8878, 1.8881, 1.9316, 1.9558, 2.0048, 2.0408, 2.0903, 2.1093, 2.1330, 2.2100, 2.2460, 2.2878, 2.3203, 2.3470, 2.3513, 2.4951, 2.5260, 2.9911, 3.0256, 3.2678, 3.4045, 3.4846, 3.7433, 3.7455, 3.9143, 4.8073, 5.4005, 5.4435, 5.5295, 6.5541, 9.0960.
Table 22 presents a brief summary of descriptive statistics for these data.
From
Table 22, it can be deduced that the data are right skewed and leptokurtic, with a low variability.
According to
Table 23, for the purpose of optimal data fit, the SPL model is more pertinent than the other models. The second best model is the PL model.
We numerically complete the above results by showing the MLEs of the model parameters as well as the SEs in
Table 24.
The histogram and PP plot of the data with the model fits are shown in
Figure 9.
From
Figure 9, in the fitting exercise, we see that the SPL model is slightly better than the competing models. A favorable PP plot is also observed.
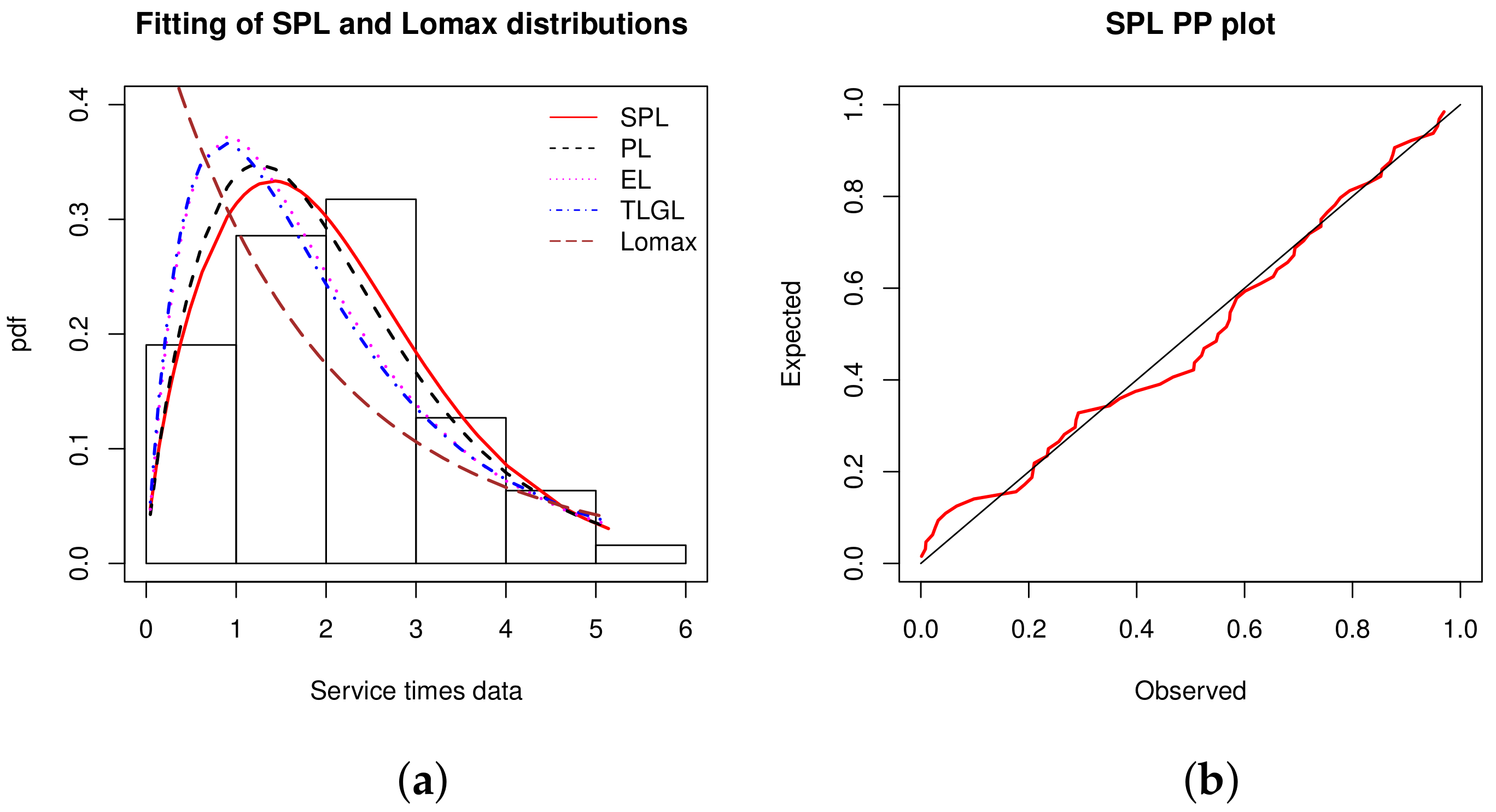
Data set 8: Data on service times for a particular model windshield are now considered. They are given from [
41]. The unit for measurement is 1000 h and the data are: 0.046, 1.436, 2.592, 0.140, 1.492, 2.600, 0.150, 1.580, 2.670, 0.248, 1.719, 2.717,0.280, 1.794, 2.819, 0.313, 1.915, 2.820, 0.389, 1.920, 2.878, 0.487, 1.963, 2.950, 0.622, 1.978, 3.003, 0.900, 2.053, 3.102, 0.952, 2.065, 3.304, 0.996, 2.117, 3.483, 1.003, 2.137, 3.500, 1.010, 2.141, 3.622, 1.085, 2.163, 3.665, 1.092, 2.183, 3.695, 1.152, 2.240, 4.015, 1.183, 2.341, 4.628, 1.244, 2.435, 4.806, 1.249, 2.464, 4.881, 1.262, 2.543, 5.140.
Table 25 presents a concise statistical description of these data.
We see in
Table 25 that the data are right skewed and platykurtic, with a moderate variability.
Table 26 indicates that the SPL model is the most appropriate fitted model. The second best model is the PL model.
Some additional elements are now given. The MLEs of the models along with their SEs are shown in
Table 27.
We visually see the adjustability of the SPL model in
Figure 10.
From
Figure 10, it is evident that the histogram of the data is better fitted by the estimated pdf of the SPL model. The red line of the PP plot is relatively close to the black line, confirming the SPL model fitting power.
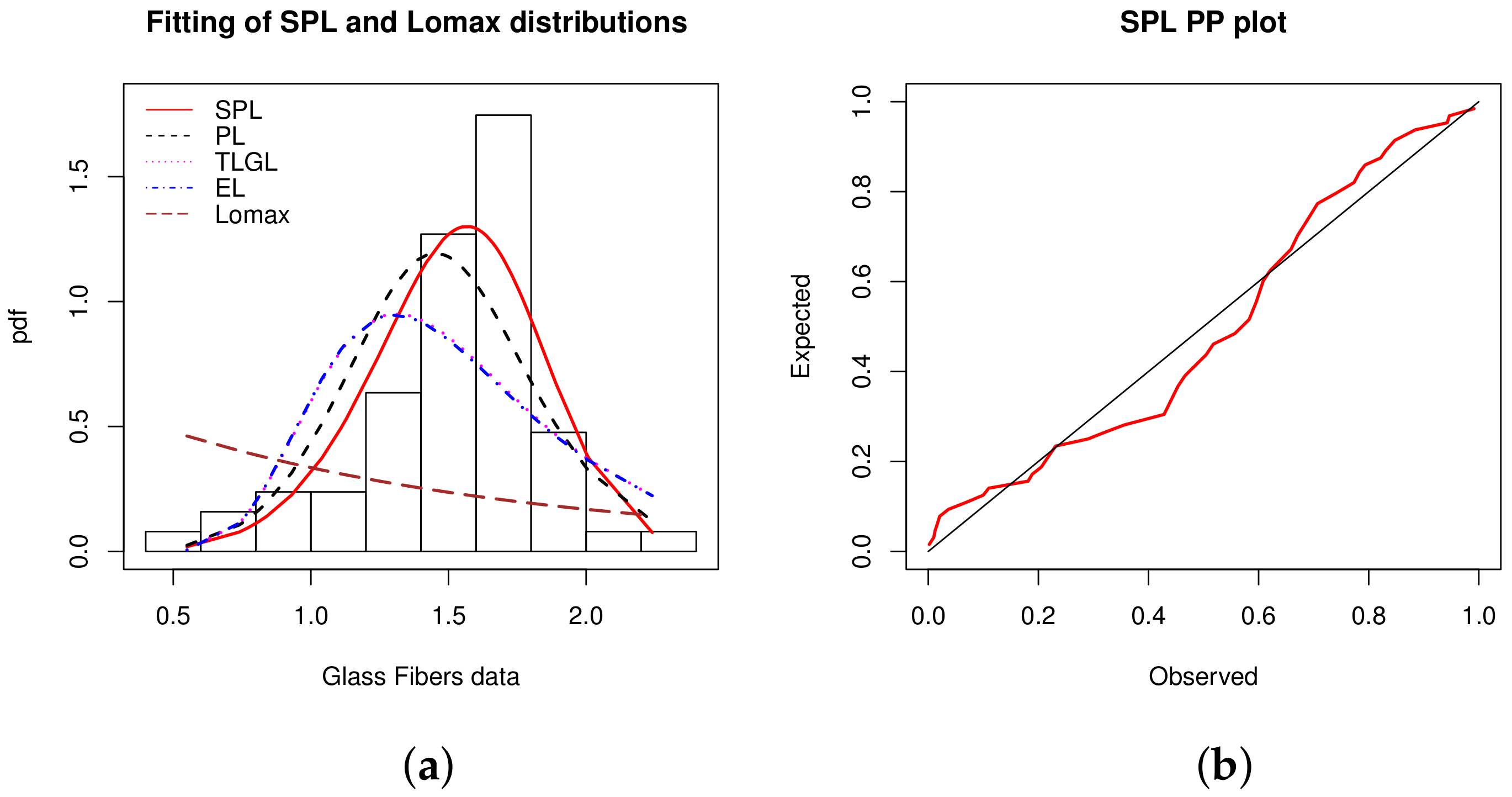
Data set 9: Data relating to the strengths of 1.5 cm glass fibres which was obtained by workers at the UK National Physical Laboratory are now used. They were previously analysed by [
48]. The data are: 0.55, 0.74, 0.77, 0.81, 0.84, 1.24, 0.93, 1.04, 1.11, 1.13, 1.30, 1.25, 1.27, 1.28, 1.29, 1.48, 1.36, 1.39, 1.42, 1.48, 1.51, 1.49, 1.49, 1.50, 1.50, 1.55, 1.52, 1.53, 1.54, 1.55, 1.61, 1.58, 1.59, 1.60, 1.61, 1.63, 1.61, 1.61, 1.62, 1.62, 1.67, 1.64, 1.66, 1.66, 1.66, 1.70, 1.68, 1.68, 1.69, 1.70, 1.78, 1.73, 1.76, 1.76, 1.77, 1.89, 1.81, 1.82, 1.84, 1.84, 2.00, 2.01, 2.24.
A first statistical approach of these data is proposed in
Table 28.
From
Table 28, we observe that the data are left skewed and platykurtic, with almost negligible dispersion.
The goodness of fit measures of the considered models are calculated and collected in
Table 29.
According to
Table 29, we assert that the SPL model has a better goodness of fit than the other models. The second best model is the PL model.
The MLEs of the model parameters and their SEs are shown in
Table 30.
Estimated pdfs over the histogram of the data and PP plot of the SPL model are shown in
Figure 11.
From
Figure 11, unsurprisingly in view of
Table 30, the SPL model shows the best fit curve of the histogram. A nice fit of the SPL model is also validated by the PP plot.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}