
An Efficient Explicit Moving Particle Simulation Solver for Simulating Free Surface Flow on Multicore CPU/GPUs


Abstract
:1. Introduction
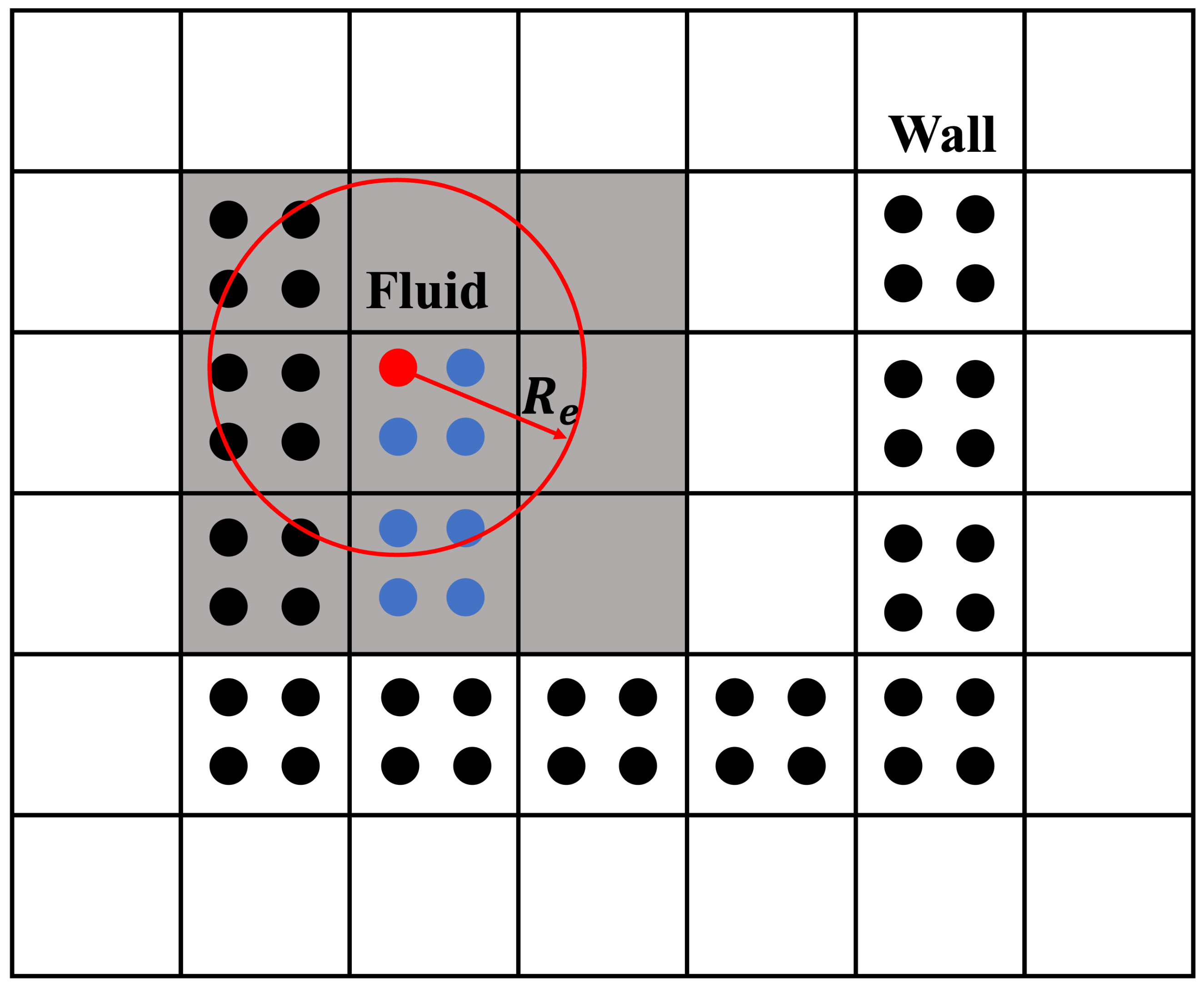
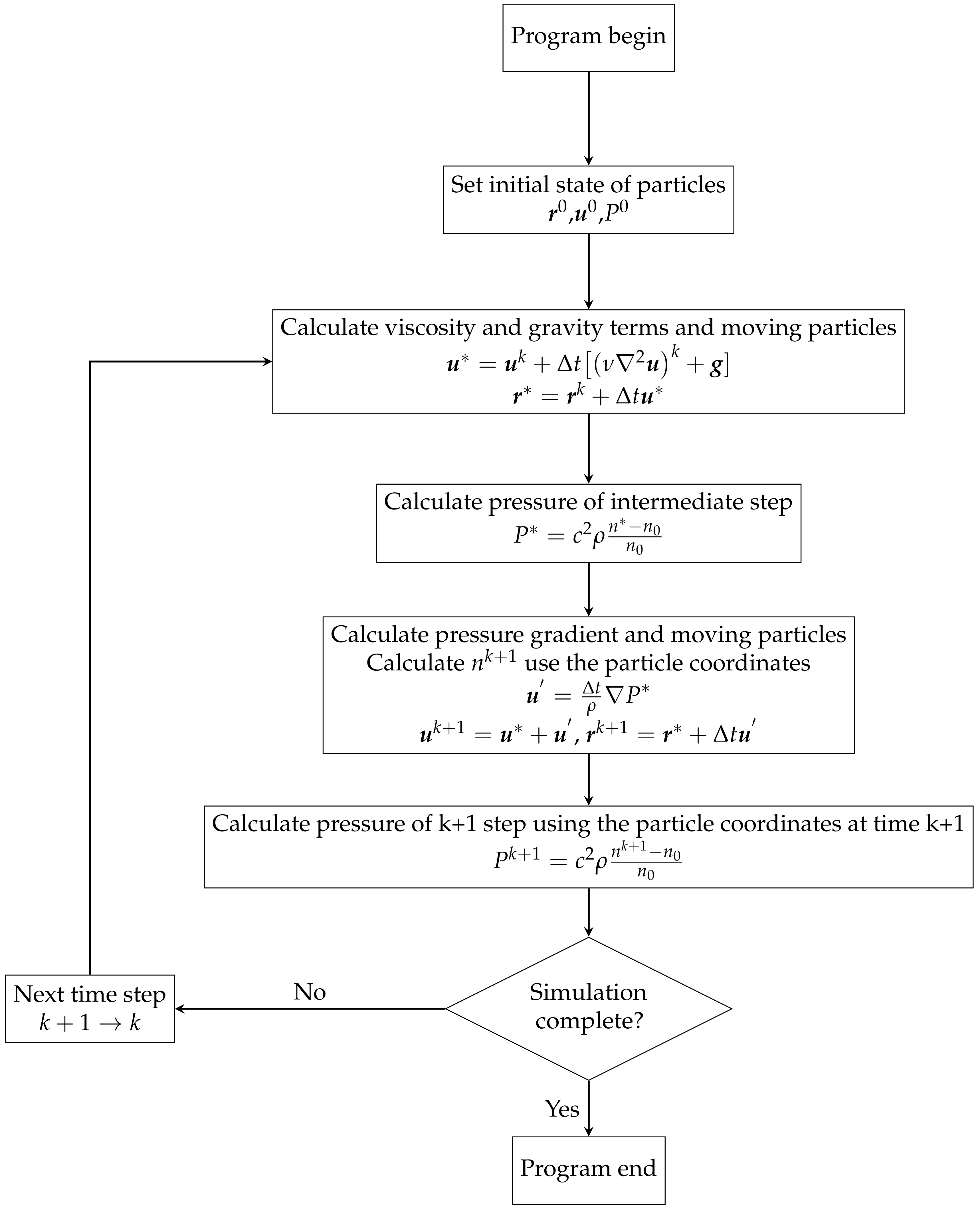
2. Explicit MPS Method
3. Implementation of EMPS Using Taichi
| Algorithm 1: Taichi kernel used to calculate acceleration |
 |
| Algorithm 2: Bucket method in EMPS |
 |
4. Numerical Benchmark
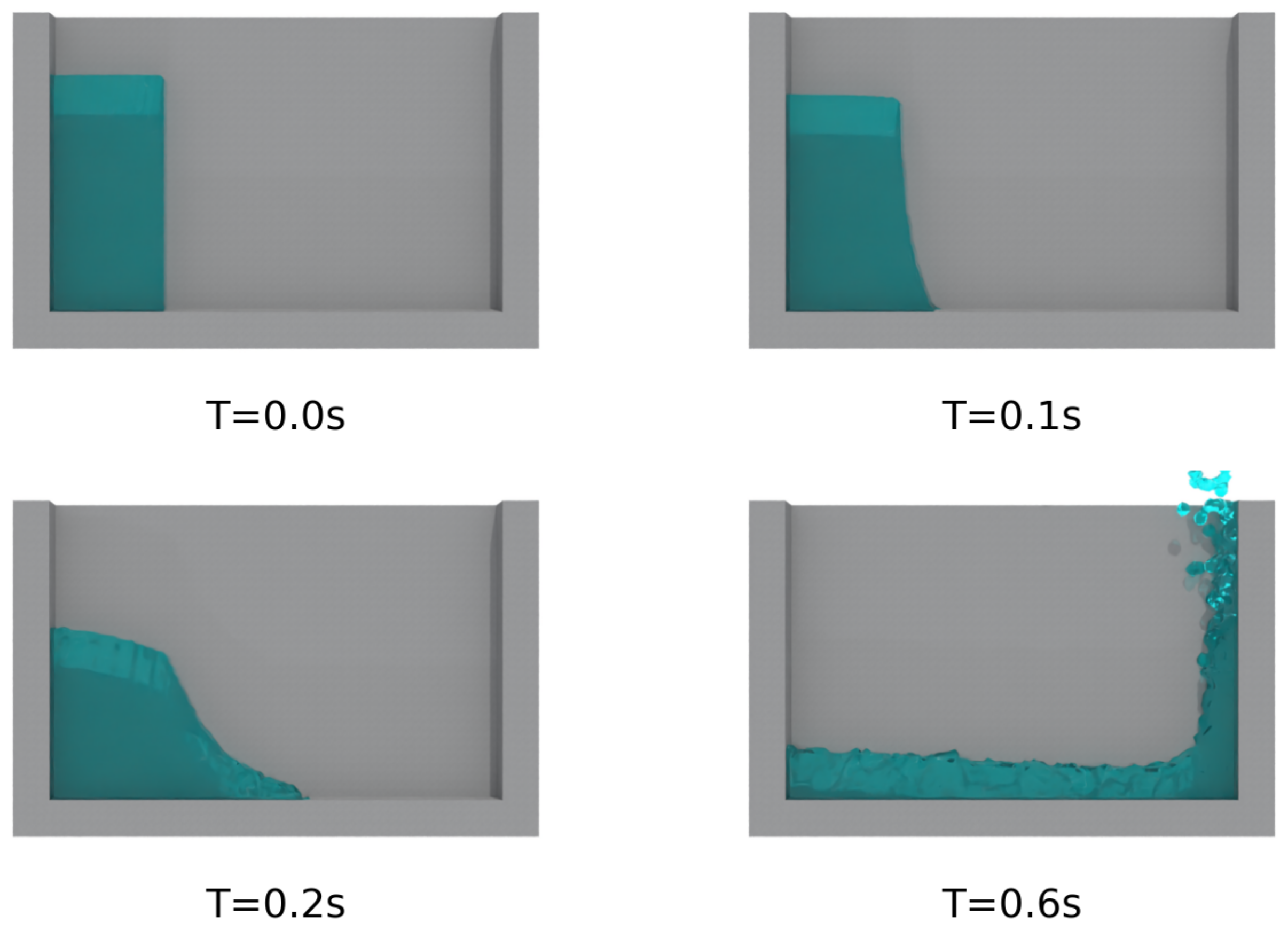
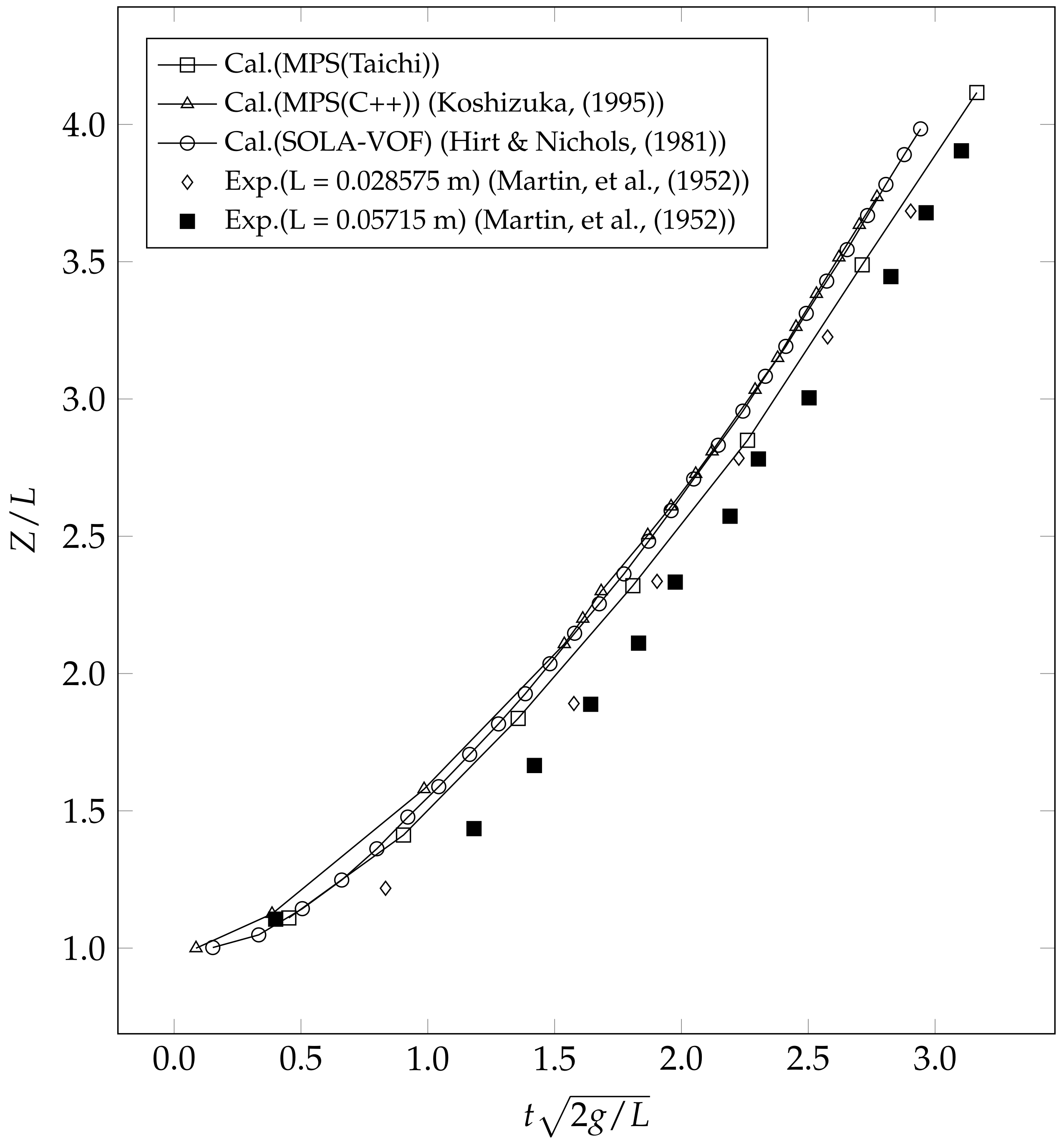
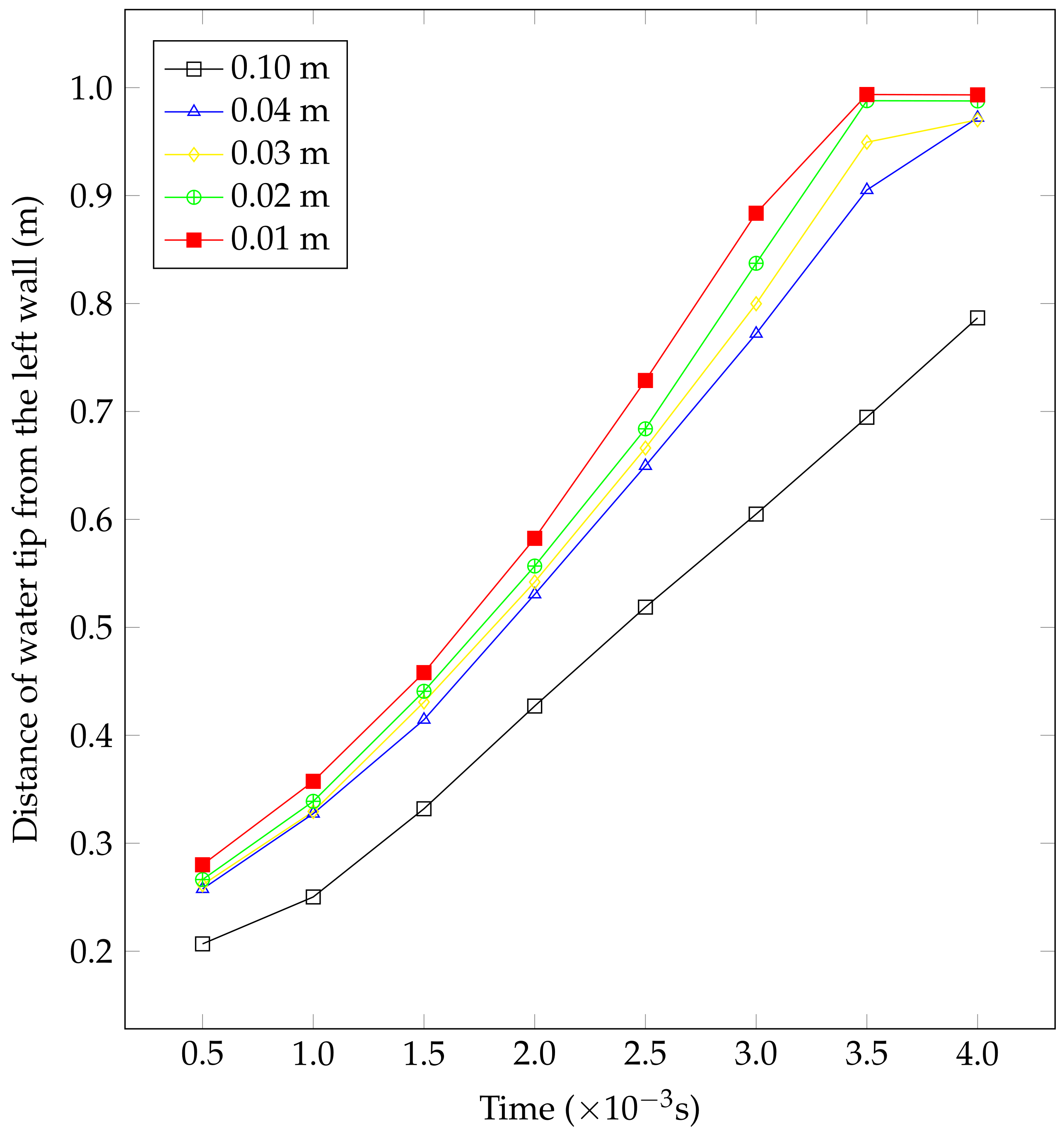
4.1. Dam Break Flow
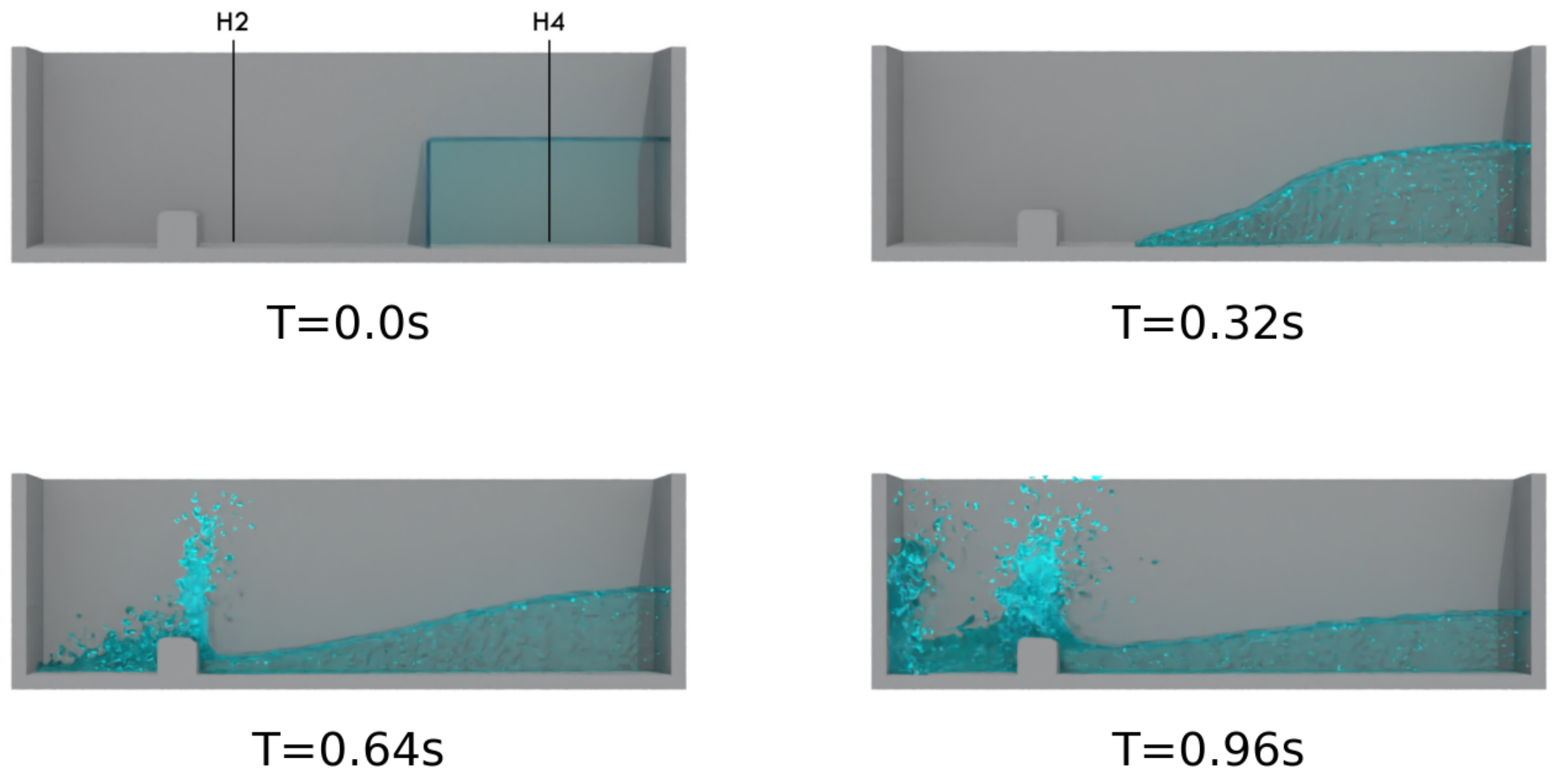
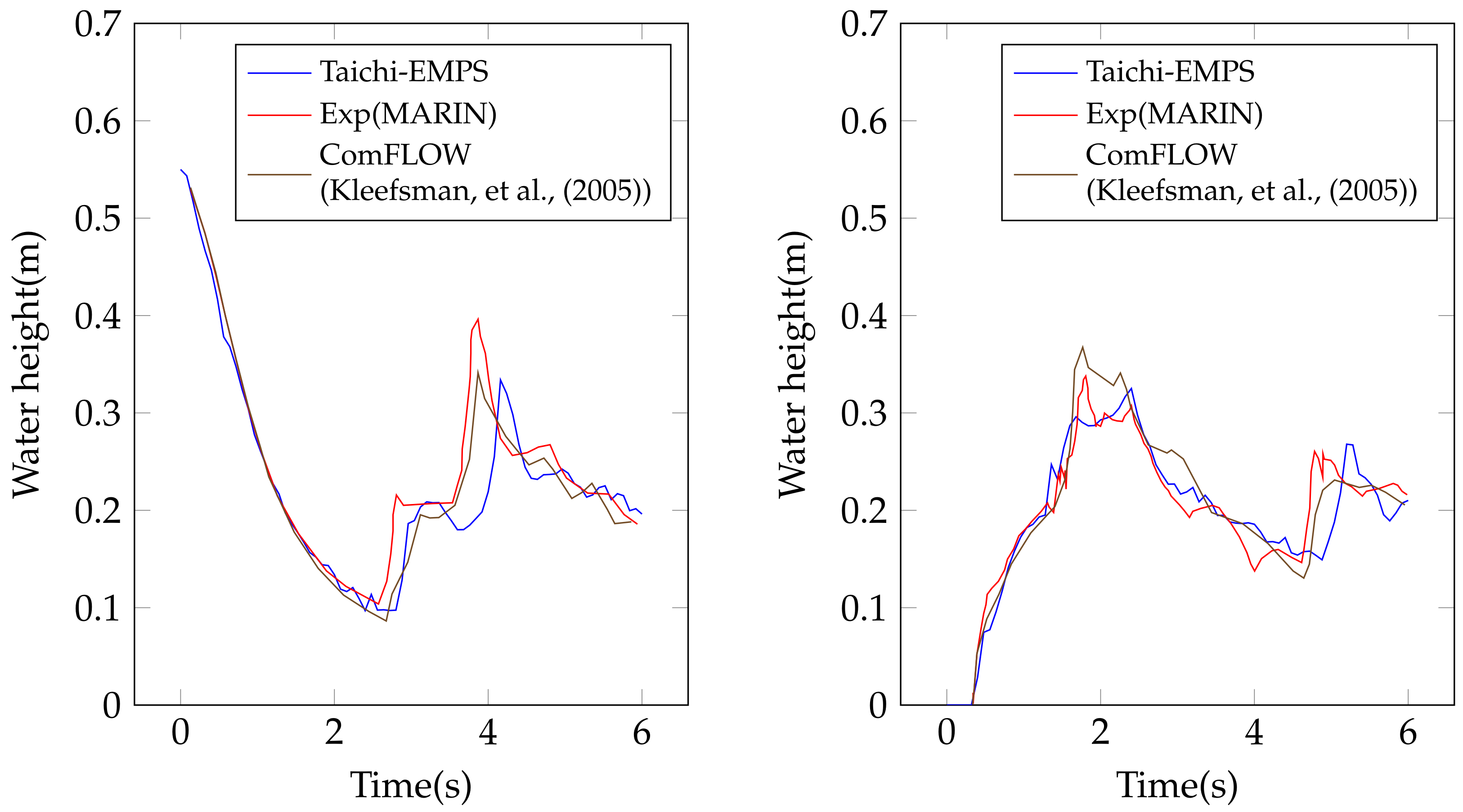
4.2. Dam Break Impact on a Solid Obstacle
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Grid-Independent Test

References
- Tomé, M.F.; Mangiavacchi, N.; Cuminato, J.A.; Castelo, A.; Mckee, S. A finite difference technique for simulating unsteady viscoelastic free surface flows. J. Non–Newton. Fluid Mech. 2002, 106, 61–106. [Google Scholar] [CrossRef]
- Casulli, V. A semi-implicit finite difference method for non-hydrostatic, free-surface flows. Int. J. Numer. Methods Fluids 1999, 30, 425–440. [Google Scholar] [CrossRef]
- Muzaferija, S.; Perić, M. Computation of free-surface flows using the finite-volume method and moving grids. Numer. Heat Transf. 1997, 32, 369–384. [Google Scholar] [CrossRef]
- Jiang, F.; Matsumura, K.; Ohgi, J.; Chen, X. A GPU-accelerated fluid–structure-interaction solver developed by coupling finite element and lattice Boltzmann methods. Comput. Phys. Commun. 2021, 259, 107661. [Google Scholar] [CrossRef]
- Jiang, F.; Yang, J.; Boek, E.; Tsuji, T. Investigation of viscous coupling effects in three-phase flow by lattice Boltzmann direct simulation and machine learning technique. Adv. Water Resour. 2021, 147, 103797. [Google Scholar] [CrossRef]
- Jiang, F.; Liu, H.; Chen, X.; Tsuji, T. A coupled LBM-DEM method for simulating the multiphase fluid-solid interaction problem. J. Comput. Phys. 2022, 454, 110963. [Google Scholar] [CrossRef]
- Gingold, R.; Monaghan, J. Smoothed Particle Hydrodynamics - Theory and Application to Non-Spherical Stars. Mon. Not. R. Astron. Soc. 1977, 181, 375–389. [Google Scholar] [CrossRef]
- Dalrymple, R.; Rogers, B. Numerical modeling of water waves with the SPH method. Coast. Eng. 2006, 53, 141–147. [Google Scholar] [CrossRef]
- Hu, X.; Adams, N. A multi-phase SPH method for macroscopic and mesoscopic flows. J. Comput. Phys. 2006, 213, 844–861. [Google Scholar] [CrossRef]
- Koshizuka, S.; Nobe, A.; Oka, Y. Numerical Analysis of Breaking Waves using the Moving Particle Semi-implicit Method. Int. J. Numer. Methods Fluids 1998, 26, 751–769. [Google Scholar] [CrossRef]
- Koshizuka, S.; Oka, Y. Moving-Particle Semi-Implicit Method for Fragmentation of Incompressible Fluid. Nucl. Sci. Eng. 1996, 123, 421–434. [Google Scholar] [CrossRef]
- Cummins, S.J.; Rudman, M. An SPH projection method. J. Comput. Phys. 1999, 152, 584–607. [Google Scholar] [CrossRef]
- Shakibaeinia, A.; Jin, Y.C. A weakly compressible MPS method for modeling of open-boundary free-surface flow. Int. J. Numer. Methods Fluids 2010, 63, 1208–1232. [Google Scholar] [CrossRef]
- Tayebi, A.; Jin, Y.C. Development of moving particle explicit (MPE) method for incompressible flows. Comput. Fluids 2015, 117, 1–10. [Google Scholar] [CrossRef]
- Jandaghian, M.; Shakibaeinia, A. An enhanced weakly-compressible MPS method for free-surface flows. Comput. Methods Appl. Mech. Eng. 2020, 360, 112771. [Google Scholar] [CrossRef]
- Murotani, K.; Masaie, I.; Matsunaga, T.; Koshizuka, S.; Shioya, R.; Ogino, M.; Fujisawa, T. Performance improvements of differential operators code for MPS method on GPU. Comput. Part. Mech. 2015, 2, 261–272. [Google Scholar] [CrossRef]
- Gou, W.; Zhang, S.; Zheng, Y. Implementation of the moving particle semi-implicit method for free-surface flows on GPU clusters. Comput. Phys. Commun. 2019, 244, 13–24. [Google Scholar] [CrossRef]
- Khayyer, A.; Gotoh, H. Enhancement of performance and stability of MPS mesh-free particle method for multiphase flows characterized by high density ratios. J. Comput. Phys. 2013, 242, 211–233. [Google Scholar] [CrossRef]
- Green, S. Particle simulation using cuda. NVIDIA Whitepaper 2010, 6, 121–128. [Google Scholar]
- Goodnight, N. CUDA/OpenGL fluid simulation. NVIDIA Corp. 2007, 548, 1–11. [Google Scholar]
- Kim, K.S.; Kim, M.H.; Park, J.C. Development of Moving Particle Simulation Method for Multiliquid-Layer Sloshing. Math. Probl. Eng. 2014, 2014, 350165. [Google Scholar] [CrossRef]
- Yang, Y.H.C.; Briant, L.; Raab, C.; Mullapudi, S.; Maischein, H.M.; Kawakami, K.; Stainier, D. Innervation modulates the functional connectivity between pancreatic endocrine cells. eLife 2022, 11, e64526. [Google Scholar] [CrossRef]
- Hu, Y.; Li, T.M.; Anderson, L.; Ragan-Kelley, J.; Durand, F. Taichi: A language for high-performance computation on spatially sparse data structures. ACM Trans. Graph. 2019, 38, 1–16. [Google Scholar] [CrossRef]
- Hu, Y.; Anderson, L.; Li, T.M.; Sun, Q.; Carr, N.; Ragan-Kelley, J.; Durand, F. Difftaichi: Differentiable programming for physical simulation. arXiv 2019, arXiv:1910.00935. [Google Scholar]
- Hu, Y. The Taichi Programming Language: A Hands-on Tutorial. ACM SIGGRAPH 2020 Courses. 2020, 21, 1–50. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, J.; Yang, X.; Xu, M.; Kuang, Y.; Xu, W.; Dai, Q.; Freeman, W.T.; Durand, F. QuanTaichi: A Compiler for Quantized Simulations. ACM Trans. Graph. (TOG) 2021, 40, 1–16. [Google Scholar] [CrossRef]
- Yang, J.; Xu, Y.; Yang, L. Taichi-LBM3D: A Single-Phase and Multiphase Lattice Boltzmann Solver on Cross-Platform Multicore CPU/GPUs. Fluids 2022, 7, 270. [Google Scholar] [CrossRef]
- Wu, Y.C.; Shao, J.L. mdapy: A flexible and efficient analysis software for molecular dynamics simulations. Comput. Phys. Commun. 2023, 290, 108764. [Google Scholar] [CrossRef]
- Dave, S.; Baghdadi, R.; Nowatzki, T.; Avancha, S.; Shrivastava, A.; Li, B. Hardware acceleration of sparse and irregular tensor computations of ml models: A survey and insights. Proc. IEEE 2021, 109, 1706–1752. [Google Scholar] [CrossRef]
- Sun, X.; Sun, M.; Takabatake, K.; Pain, C.; Sakai, M. Numerical Simulation of Free Surface Fluid Flows Through Porous Media by Using the Explicit MPS Method. Transp. Porous Media 2019, 127, 7–33. [Google Scholar] [CrossRef]
- Monaghan, J. Simulating Free Surface Flows with SPH. J. Comput. Phys. 1994, 110, 399–406. [Google Scholar] [CrossRef]
- OOchi, M. Explicit MPS algorithm for free surface flow analysis. Trans. JSCES 2010, 20100013. [Google Scholar] [CrossRef]
- Idelsohn, S.; Oñate, E.; Del Pin, F. The Particle Finite Element Method; A Powerful tool to Solve Incompressible Flows with Free-surfaces and Breaking Waves. Numer. Methods Eng. 2004, 61, 964–989. [Google Scholar] [CrossRef]
- Lee, B.H.; Park, J.C.; Kim, M.H.; Hwang, S.C. Step-by-step improvement of MPS method in simulating violent free-surface motions and impact-loads. Comput. Methods Appl. Mech. Eng. 2011, 200, 1113–1125. [Google Scholar] [CrossRef]
- Mattson, W.; Rice, B.M. Near-neighbor calculations using a modified cell-linked list method. Comput. Phys. Commun. 1999, 119, 135–148. [Google Scholar] [CrossRef]
- Nishiura, D.; Sakaguchi, H. Parallel-vector algorithms for particle simulations on shared-memory multiprocessors. J. Comput. Phys. 2011, 230, 1923–1938. [Google Scholar] [CrossRef]
- Ha, L.; Krüger, J.; Silva, C. Fast 4-way parallel radix sorting on GPUs. Comput. Graph. Forum 2009, 28, 2368–2378. [Google Scholar] [CrossRef]
- Hirt, C.W.; Nichols, B.D. Volume of fluid (VOF) method for the dynamics of free boundaries. J. Comput. Phys. 1981, 39, 201–225. [Google Scholar] [CrossRef]
- Koshizuka, S. A particle method for incompressible viscous flow with fluid fragmentation. Comput. Fluid Dyn. J. 1995, 4, 29. [Google Scholar]
- Martin, J.C.; Moyce, W.J.; Martin, J.; Moyce, W.; Penney, W.G.; Price, A.; Thornhill, C. Part IV. An experimental study of the collapse of liquid columns on a rigid horizontal plane. Philos. Trans. R. Soc. London. Ser. A Math. Phys. Sci. 1952, 244, 312–324. [Google Scholar]
- Kleefsman, K.; Fekken, G.; Veldman, A.; Iwanowski, B.; Buchner, B. A Volume-of-Fluid Based Simulation Method for Wave Impact Problems. J. Comput. Phys. 2005, 206, 363–393. [Google Scholar] [CrossRef]
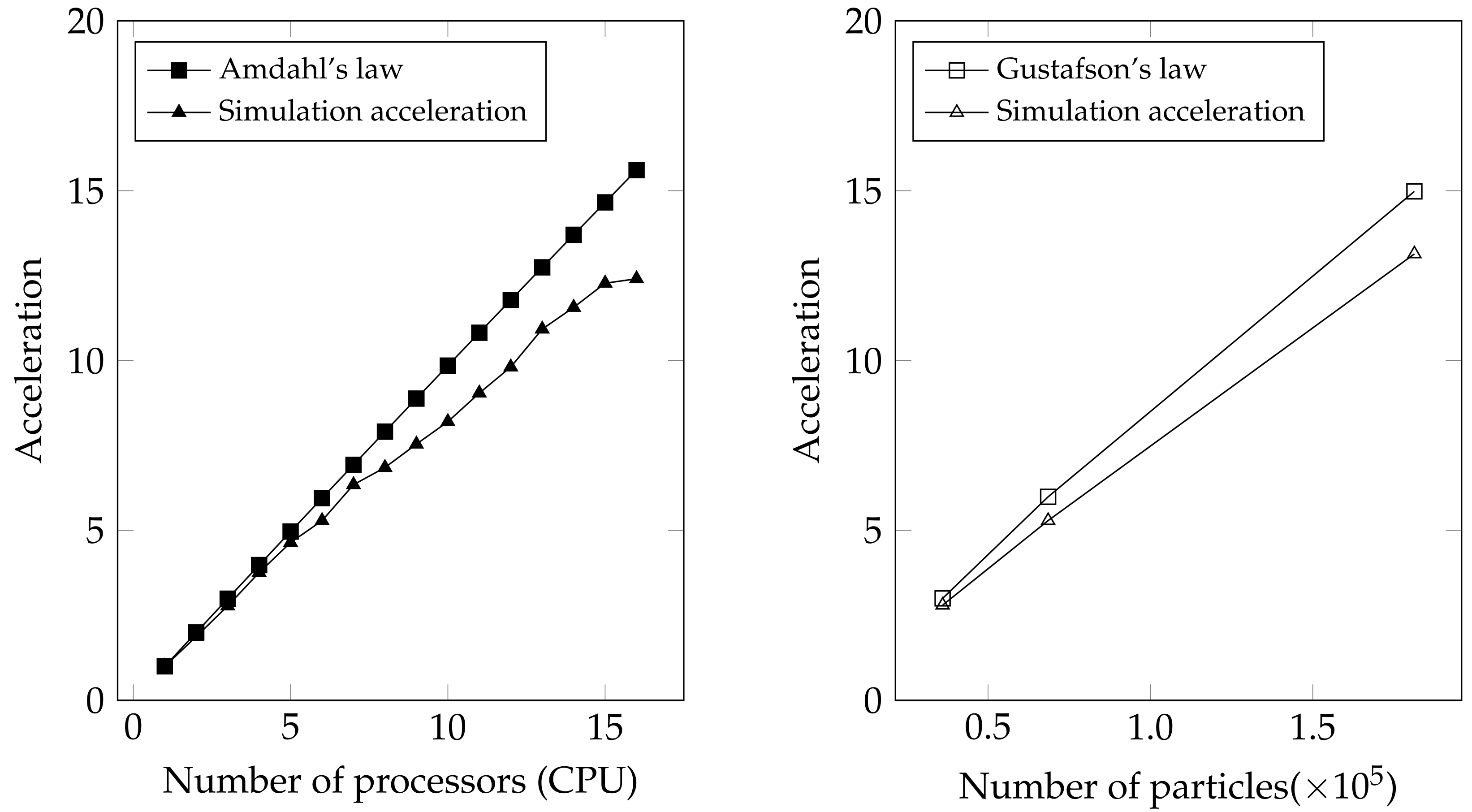
- Amdahl, G.M. Validity of the single processor approach to achieving large scale computing capabilities. In Proceedings of the Spring Joint Computer Conference, Atlantic City, NJ, USA, 18–20 April 1967; pp. 483–485. [Google Scholar]
- Gustafson, J.L.; Montry, G.R.; Benner, R.E. Development of parallel methods for a 1024-processor hypercube. SIAM J. Sci. Stat. Comput. 1988, 9, 609–638. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | C++ | Python | Taichi (1 Core) | Taichi (6 Cores) | OpenMP (6 Cores) | Taichi (GPU) | CUDA |
|---|---|---|---|---|---|---|---|
| Time [s] | 200.54 | 47,540.92 | 200.51 | 38.87 | 38.60 | 23.58 | 9.64 |
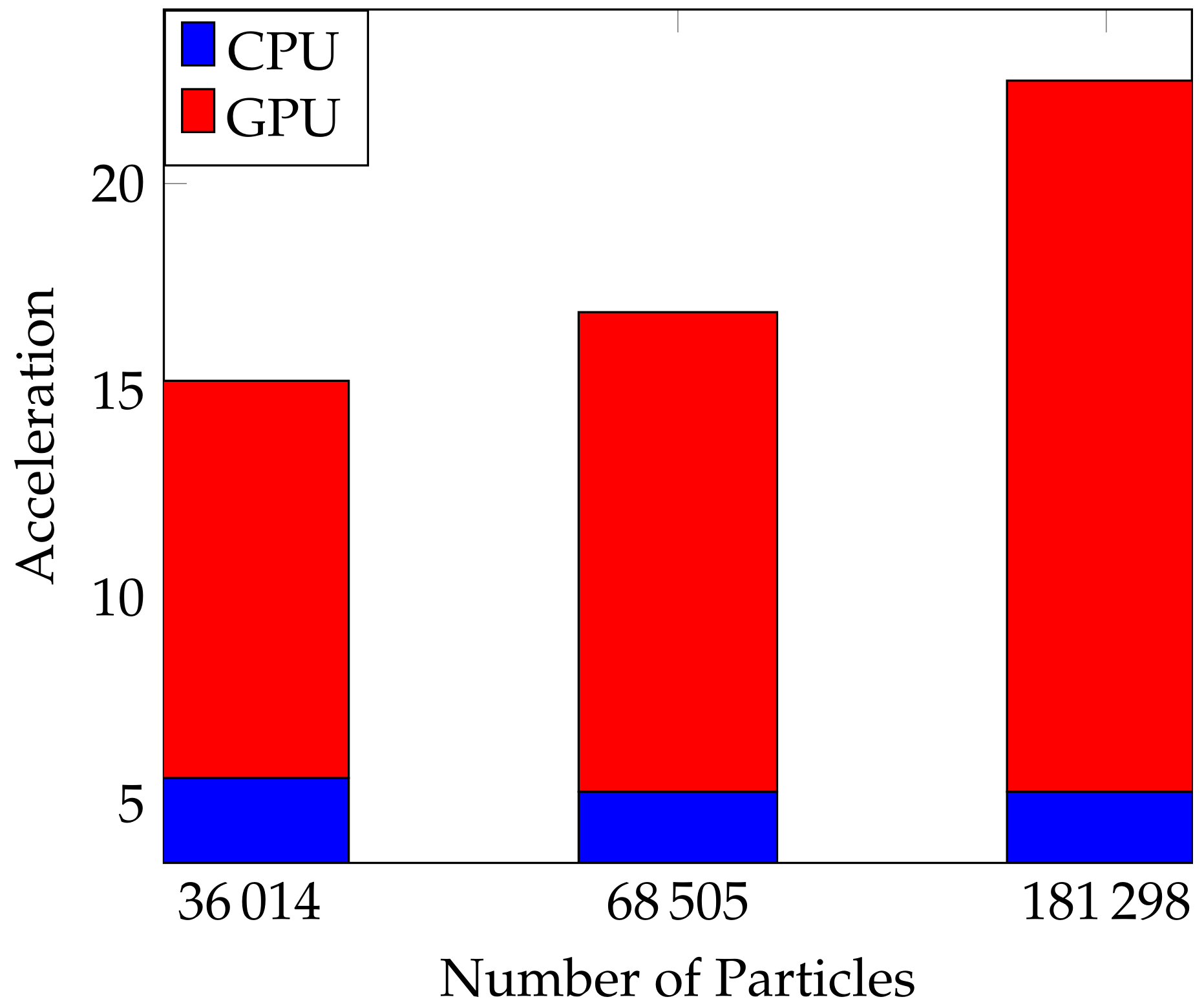
| Particle Spacing [m] | Particle Number | CPU [s] | Parallel CPU (6 Cores) [s] | Acceleration (CPU) | GPU [s] | Acceleration (GPU) |
|---|---|---|---|---|---|---|
| 0.04 | 36,014 | 1214.80 | 216.21 | 5.85 | 4144 | 9.61 |
| 0.03 | 68,505 | 2921.88 | 552.34 | 5.82 | 81,340 | 11.60 |
| 0.02 | 181,298 | 11,640.41 | 2200.46 | 5.82 | 2150.03 | 17.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Jiang, F.; Mochizuki, S. An Efficient Explicit Moving Particle Simulation Solver for Simulating Free Surface Flow on Multicore CPU/GPUs. Modelling 2024, 5, 276-291. https://doi.org/10.3390/modelling5010015
Zhao Y, Jiang F, Mochizuki S. An Efficient Explicit Moving Particle Simulation Solver for Simulating Free Surface Flow on Multicore CPU/GPUs. Modelling. 2024; 5(1):276-291. https://doi.org/10.3390/modelling5010015
Chicago/Turabian StyleZhao, Yu, Fei Jiang, and Shinsuke Mochizuki. 2024. "An Efficient Explicit Moving Particle Simulation Solver for Simulating Free Surface Flow on Multicore CPU/GPUs" Modelling 5, no. 1: 276-291. https://doi.org/10.3390/modelling5010015
APA StyleZhao, Y., Jiang, F., & Mochizuki, S. (2024). An Efficient Explicit Moving Particle Simulation Solver for Simulating Free Surface Flow on Multicore CPU/GPUs. Modelling, 5(1), 276-291. https://doi.org/10.3390/modelling5010015