1. Introduction
Social media platforms are virtual communication channels for sharing local and international news and opinions [
1]. The advent of smartphones facilitated the collection of accurate location information within various operating systems and applications based on built-in Global Navigation Satellite System (GNSS) capabilities and WiFi modules [
2]. The most prominent among over 100 social media platforms include Twitter for microblogging, YouTube for videos, Facebook for social networking, and LinkedIn for jobs [
3]. Social media content shared can be classified by information type, such as geotagged text (Twitter), geotagged photos (Instagram, Flickr), and check-in information (Swarm) [
4]. Geotagged social media messages are increasingly used for a better understanding of public behavior patterns [
5,
6], the monitoring and prediction of worldwide events [
7,
8] and natural disasters [
9], and to support public health essential services [
10,
11]. Its information can supplement or replace data collected from traditional surveys, e.g., for modeling urban mobility patterns [
12], visitation rates in protected natural areas [
13], or the use of building blocks [
14,
15]. Social media platforms also help governmental sectors improve communication with citizen participation in community-related questions and the transfer of best practices [
16,
17]. Social media usage varies over time, and its use is affected by local, regional, and global events [
18,
19].
Twitter is one of the most popular social media apps. It allows registered users to communicate and share information through posts (tweets). Each tweet can hold up to 280 characters and may contain location data with exact coordinates, a place name from a variety of administrative levels, and a bounding box with the coordinates of its four corners [
20,
21,
22]. Twitter geolocation contributions are used to identify human flow patterns based on the characteristics of mobility rate, the radius of gyration, diversity of destinations, and inflow–outflow balance [
23,
24].
Despite the abundance, extensive spatial and temporal coverage, and an enormous user base of social media data, they come with various types of biases that can lead to inaccurate analysis results [
25,
26,
27]. Data bias exists not only on social media but generally in user-generated content and may be caused by user selection, socioeconomic factors, or specially targeted user groups for certain social media platforms [
26,
28,
29,
30]. For example, users of bicycle tracking apps are not representative of the general cyclist population because the app user base is skewed towards male and younger cyclists in the case of Strava [
31,
32]. An examination of user samples from several bicycle smartphone apps in North America revealed that the apps tended to under-sample females, older adults, and lower-income populations [
33].
User selection bias varies across different social media platforms, in part because different social media platforms have different target users. In addition, social media use varies by socioeconomic factors, including education, type of occupation, income, age, and race [
34]. One study found that black and Hispanic neighborhoods feature fewer PokéStops than commercial, recreational, touristic, and university locations and thus disadvantage the local population in black and Hispanic neighborhoods [
31,
35]. Gender bias was observed in OpenStreetMap (OSM) editing and tagging activities, which were primarily conducted by male users [
36]. In addition, platform policy and app functionality also affect user contribution behavior. For example, the Twitter policy change, which increased the maximum allowable tweet length from 140 to 280 characters in 2017, resulted in tweets containing more hashtags, definite articles, characters per sentence, and punctuation marks, but also in tweets with fewer abbreviations [
37,
38]. Twitter has gone through multiple policy updates. Whereas various studies analyzed the character change policy from 2017, other policy changes are rarely discussed. This may be because these policy changes do not directly change constraints on tweets themselves but rather on tweet metadata (i.e., sharing of exact coordinates). As for the 2017 policy change, previous studies analyzed primarily linguistic effects, whereas other changes, such as the use of geographic placenames or photos, or users’ traveled activity space, were not discussed, although these characteristics can be of interest for spatial analysis tasks.
User behavior and information diffusion in social media can be analyzed from different perspectives, e.g., alongside a spatial and temporal dimension [
39]. User policies can affect how users interact and share data on a social media platform [
40] and, in consequence, the information that can be harvested from shared information, such as user posts. Policy changes have, for example, been implemented to reduce the spread of false content on Twitter and Facebook [
41]. Another study reviewed how changes in the functionality (e.g., privacy settings, accepting friendships) on social networking sites, such as Facebook, Twitter, and YouTube, may make these technologies less perilous for health professionals [
42].
The main objective of this paper was to identify the underexplored effects of three policy changes for the Twitter app on user contribution behavior and, thus, the spatial information that can be retrieved from contributed data, i.e., posts. These effects are identified by comparing contributed data before and after the following three Twitter policy changes: (1) The removal of a default option to share exact coordinates with each tweet (April 2015); (2) The increase in the allowable tweet length from 140 to 280 characters (November 2017); (3) Limiting the sharing of exact coordinates to the Twitter photo app only (June 2019) [
43]. In order to quantify the change in user behavior, six behavioral characteristics (variables) were extracted from one month before and after the policy update period. These variables are the proportion of tweets with exact coordinates, tweet length, the average number of placenames in tweet text or hashtag per tweet (rate), the proportion of tweets with images among tweets with exact coordinates, and the radius of gyration of tweet locations.
The remainder of the paper is structured as follows:
Section 2 describes data collection, data processing, and data analysis methods and formulates research hypotheses.
Section 3 shows the results of pre-post policy comparisons of user contribution behavior along the six contribution variables, which is followed by a discussion of the results in
Section 4 and conclusions and directions for future work in
Section 5.
2. Materials and Methods
2.1. Study Area
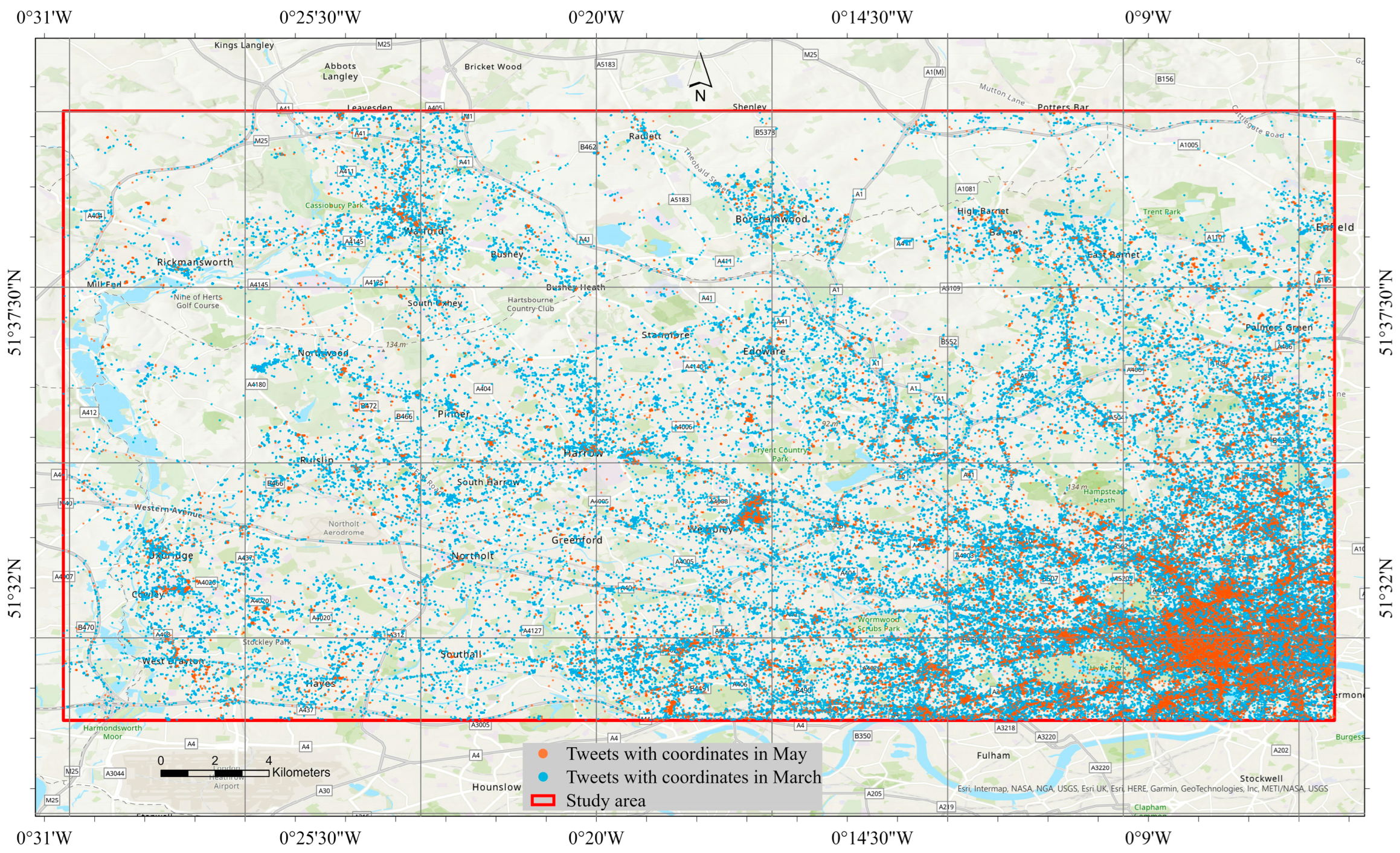
Geotagged tweets were collected from the northwestern part of London, which covers approximately 659 km
2 (red rectangle in
Figure 1). This London test region was chosen since it covers both urban and suburban areas, provides sufficient data for the analysis of the three policy changes, and has most tweets posted in English.
Blue dots in
Figure 1 show the location of tweets with exact coordinates in March 2015, which was before the first policy change. As opposed to this, orange dots show tweet locations after the policy change in May 2015.
Figure 1 clearly illustrates the decline in the number of tweets with exact coordinates through the 2015 policy change. The same study area was used to assess the effects of 2017 and 2019 policy changes on contribution patterns.
2.2. Data Collection
Geotagged tweets were downloaded in JavaScript Object Notation (JSON) format through the Twitter Application Programming Interface (API) in combination with the “request” Python library. To specify the download area, the “bounding_box” operator was applied, which allows a maximum allowable length of each bounding box side of 25 miles.
For each policy change analyzed, the data of one month before and one month after the policy updates were collected (
Table 1) and stored in a PostgreSQL database. This procedure resulted in the download of tweets that were mostly geotagged with exact coordinates, whereas a small number of tweets were geocoded at the city-, administrative-, or country level or through a Point of Interest (POI).
The following attributes were extracted for each tweet from the raw JSON data: tweet id, text, language, time created, author id, source platform, place id, geotag type, coordinates, hashtags, bounding box, feature type, place name, place name code, country, place type.
Tweets can come in over 50 languages from over 180 sources, including Flickr, the Twitter Web client, or Instagram. For this study, only tweets in English were considered. Moreover, since the focus of this research is on assessing the effect of changes in the Twitter app on tweeting behavior, only tweets posted from mobile tweeting platforms were used for the analysis, which includes the following sources: Twitter for iPhone, Twitter for Android, Twitter for iPad, and Twitter for Android Tablets.
Table 1 shows the number of tweets in the study area before and after language and source filtering for the months around the three considered policy changes.
2.3. Research Hypotheses
A research hypothesis can be defined by posing the expected direction of change, i.e., larger (>) or smaller (<), for each of the six behavioral variables that are assessed with respect to policy changes. Technically, in connection with the Monte Carlo permutation tests, these hypotheses denote alternative hypotheses since a null hypothesis in a statistical test postulates no change in the population parameter under consideration (e.g., mean or median) [
44]. The six hypotheses are stated for each policy change, resulting in a total of 18 hypotheses (H1 through H18) across the three years (
Table 2).
The alternative assumptions were made based on the expected effect of a policy update on a variable of interest. Explanations for the expected directional change of variable means after a policy change for the 18 hypotheses are detailed in
Table 3.
In addition, it was hypothesized that when expanding the comparison period beyond the month before and after a policy, the change results in a more distinct observed effect on the analyzed variables. This is because there may be a delay in updating apps on mobile devices to the newest app version for various reasons and hence a delay in policy changes taking effect for some users. To test this hypothesis, change in variable means across multiple years, i.e., between March 2015 and December 2017 and between March 2015 and July 2019, was compared to changes associated with individual policy updates in the corresponding years. The first multi-year time span comprises two policy changes, and the second one three policy changes.
2.4. Variable Calculation
The following items describe the steps involved in computing the behavioral variables for one month before and one month after the month of the policy update. The sample size for before and after equals the number of users who meet the criteria to be included in the pre-post comparison.
This is the number of tweets with exact coordinates divided by the total number of geotagged tweets posted by a user. Only tweets from users who posted at least one tweet with exact coordinates in the month before and in the month after the policy change period were considered;
- 2.
Tweet length
The tweet length is the average text length of tweets posted by a user. Only tweets from users who posted at least one tweet in the month before and in the month after the policy change period were considered. Although the maximum tweet length was set to 280 characters after the policy change in November 2017, tweets can sometimes exceed 280 characters. This is because, through the Twitter API, some symbols are replaced with a string of characters. For example, “>” is converted to “>” during the download process;
- 3.
Rate of placename mentions in the text and hashtags
These rates are computed as the number of times a placename is mentioned in the text or in the hashtags, respectively, divided by the number of tweets posted by that user. Only tweets from users who posted at least one tweet in the month before and in the month after the policy change period were considered. In order to identify a placename in a post, the Python language processing library “spaCy” was applied, which can recognize entity names, such as companies, agencies, or countries. The “en_core_web_sm” model was applied to extract geopolitical entities such as countries, cities, and streets. Due to potential false positives, identified place names had to be checked manually regarding their existence using Google Maps. Further, to disambiguate ambiguous terms, the entire tweet text was used in a manual check. For example, the ambiguous name “Primark” can point to a brand or a store. The correct meaning becomes evident when reviewing the tweet text;
- 4.
Proportion of tweets with images among tweets with exact coordinates
The first step in this computation involves the identification of images or videos attached to tweets. An image or video in tweets is shown as a link. However, a link does not always point toward a picture or video. Instead, it could also, for example, point to a website a user wants to share. Therefore, each link needed to be checked.
For this analysis, only tweets from users who posted at least one tweet in the month before or after the policy change period were considered. In order to check each link for the presence of images or videos, several libraries were applied. The Python library “Selenium” was used to simulate the browser to call the extracted links one after another. Xpath is an XML (Extensible Markup Language) Path language and can be used to navigate to elements and attributes of an XML document. Upon server return, the loaded website source code is parsed for “Alt = Image” using XPath. If this relation is present, at least one image exists in the tweet content.
In addition, the presence of videos was checked manually for tweets whose links were not pointing towards an image. Whenever the image or video exists, the corresponding tweet is counted as one. The sum of all tweets with images or videos by a user was then divided by the total number of tweets of that user;
- 5.
Radius of gyration
The radius of gyration,
rg, measures the geometric spread of locations, in this case, tweets, and is computed as
where
is the number of geotagged tweet locations of an individual user,
is the location of tweet
, and
is the geometric center of the geotagged tweets.
For this analysis, only tweets from users who posted at least two tweets with exact coordinates before or after the policy change period were considered. The radius of gyration of each user was computed using the R package “Mobility” in the month before and after the policy change.
2.5. Monte Carlo Permutation Test
The mean values of variables across eligible users before and after the policy change were compared through a Monte Carlo permutation test [
45] to identify whether the means changed as hypothesized.
The null hypothesis of the Monte Carlo permutation test is that both samples (i.e., before and after policy change variable values) come from the same distribution. The distribution of the test statistic, i.e., the mean difference between before and after policy variable values, was obtained through permutation, that is, by randomly assigning all observed variable values (e.g., average tweet length of each user from before and after policy change) to a before and after bin, followed by taking mean differences between both bins, and repeating this step 10,000 times. Next, the difference of means between observed variable values from tweets before and after the policy change was computed. The one-sided p-value of the test was computed as the proportion of sampled permutations for which the difference in means is greater (or smaller) than the mean difference of the randomized sample, where the direction of testing depends on the hypothesis (compare
Table 2).
4. Discussion
This study analyzed the change in tweeting behavior and information sharing for six variables in response to policy changes on Twitter apps. The six variables cover different aspects of user contribution behavior and their spatial information.
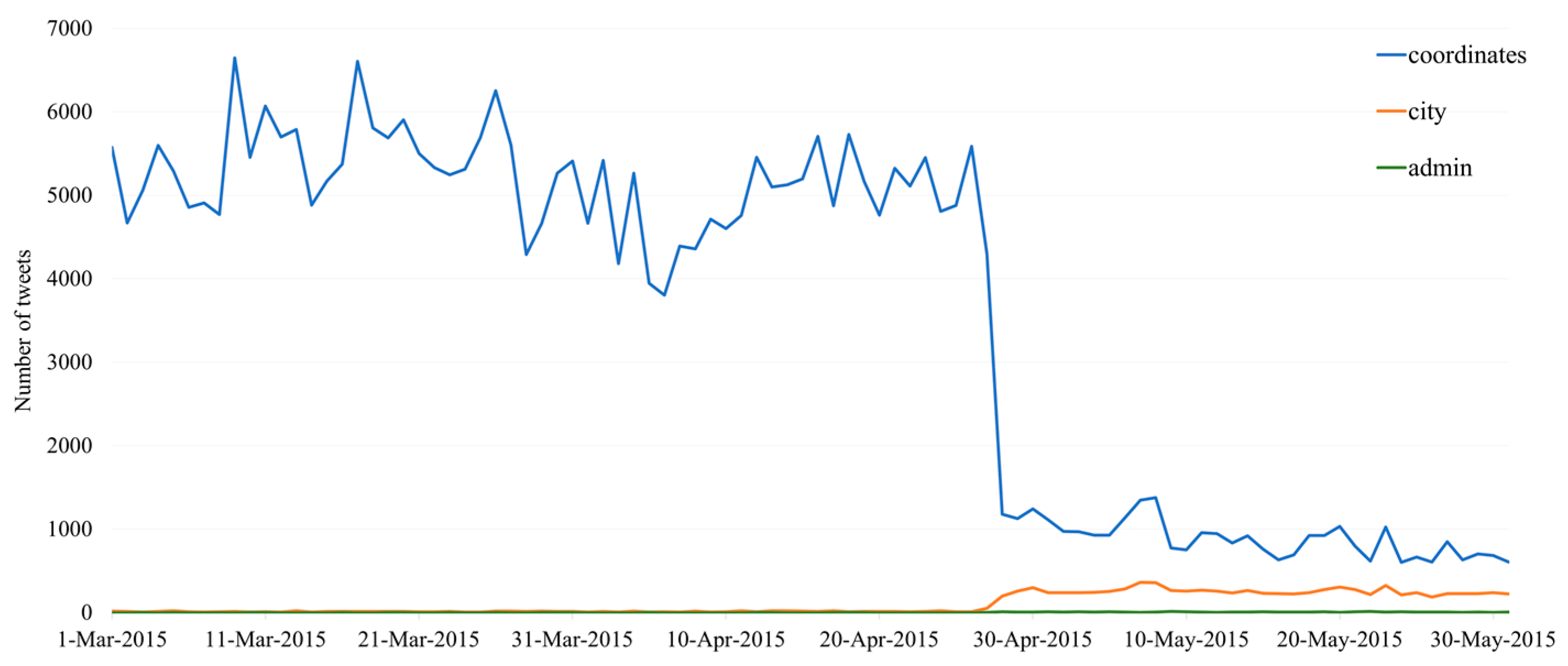
After the 2015 policy update, which removed the function to opt-in for default sharing of exact coordinates with each tweet, the proportion of tweets with exact coordinates among geotagged tweets decreased from 97.3% to 17.5%, which is consistent with H1. The policy, therefore, clearly contributed to a drop in precise location information available in tweets [
46]. Whereas the number of tweets with exact coordinates declined through this policy change, tweets with other types of geotags (e.g., at the city level) increased at the same time, albeit to a much lesser degree, leading to an overall decline in geotagged information (compare
Figure 2). This can affect travel behavioral analyses at multiple geographic levels. Tweets have been used in longitudinal studies to analyze traffic flows between geographic regions, such as between countries, e.g., for tourism management and policy [
47]. A change in the number of geotagged tweets posted per user, e.g., caused by the 2015 policy change, introduces biases when comparing traveler flow data between periods before and after the policy change and would therefore have to be mathematically corrected. Tweets have also been used in the context of natural disasters, such as tracking evacuation travels prior and concurrent to hurricanes. One study, which collected tweets between September and November 2016 for the U.S., found that around 11.34% of tweets had coordinates [
48]. This percentage was considered too small to capture enough movements between cities during the evacuation, so more coarse data with a bounding box diagonal of up to 20 km had to be used instead. Tweets with exact coordinates also play a critical role in intra-urban mobility analysis in the context of different domains, such as epidemiological modeling, since human mobility contributes to the spread of viruses at different scales, and humans tend to contract an infection outside the place of residence [
49]. These examples of mobility analysis demonstrate how a reduction in tweets with exact coordinates due to policy change limits fine-grained analysis of people’s movement associated with natural disasters or epidemiological modeling.
The 2015 policy update also led to a significant decrease in the radius of gyration derived from tweets. This does not mean that the actual user mobility changed but rather that the extracted information became more biased by omitting part of a user’s local travel patterns, which adds to the general problem of sampling bias for any technology capturing mobility dynamics [
50]. It also adds to other Twitter contribution biases that exist. For example, Twitter users’ age and income do not represent the demographic composition of the general population [
51]. The radius of gyration is often used to describe people’s activity or travel areas, such as visiting patterns and travel distances to football games [
52].
Doubling the number of allowable characters through the 2017 policy led to the expected increase in tweet length (14.0%) but also to a slight increase in the rate of placenames in tweets. This means that more users use the opportunity to specify a location of interest via textual description. The periodic ups and downs in the average length of tweets (
Figure 3) suggest that when investigating the twitter length, the analyzed period should be at least one week, where holidays may have additional short-term effects. The increased twitter length in 2017 helped to mitigate the difficulty of sentiment analysis using Twitter data because the 140-character restriction posed a challenge for sentiment information mining [
53]. The increase in placenames in tweets after the 2017 policy change also helped to construct placename corpora from tweets where mentioned location entities are identified and geolocated to toponyms in existing geographical gazetteers [
54].
The 2019 policy, which restricts sharing of exact coordinates, led to an additional drop in the proportion of tweets with exact coordinates by about 50%, leading to further data scarcity of this type of positional information. As expected, the proportion of tweets with images among tweets with exact coordinates increased, although it did not reach 100%. A possible reason might be the delay of Twitter app updates to the latest version for some users. Whereas the positional accuracy of Twitter images was in the range of multiple kilometers before [
55], it can be expected to be much improved through the policy change and the attachment of exact coordinates to images. While the decline in the share of tweets with exact coordinates reduces the possibilities for analysis at a refined spatial level, e.g., that of intra-urban mobility or land use identification [
56], it was suspected that a large share of the provided coordinates does not truly correspond to GPS coordinates [
43]. This can be the case when a user picks a pre-defined location in an app, such as on Instagram, for a Twitter cross-post, and this information is then represented as exact coordinates in the tweet. On the positive side, the 2019 policy change, which tightens the use of Twitter images and videos with exact coordinates, opened the possibility for advanced analyses, such as AI technologies, to mine the image and location information together, as used in social sensing for policy implementation [
57]. The increased use of geonames in hashtags that comes with the 2019 policy change offsets partially for a decline in exact tweets. Geo-hashtags are commonly used to pinpoint the location of events, such as mobile network outages [
58], or to infer sentiments between cities mentioned in tweets [
59].
Mean comparisons across multiple years and hence covering more than one policy change showed increased differences for some variables, which partially supports the corresponding hypothesis. The increase in the difference over time may be due to the gradual effect of the policy change on some mobile devices where the update of the app lags behind.








{kind=link}
{kind=link}
{kind=link}