
A Novel Similarity Measure of Spatiotemporal Event Setting Sequences: Method Development and Case Study


Abstract
:1. Introduction
2. Materials and Methods
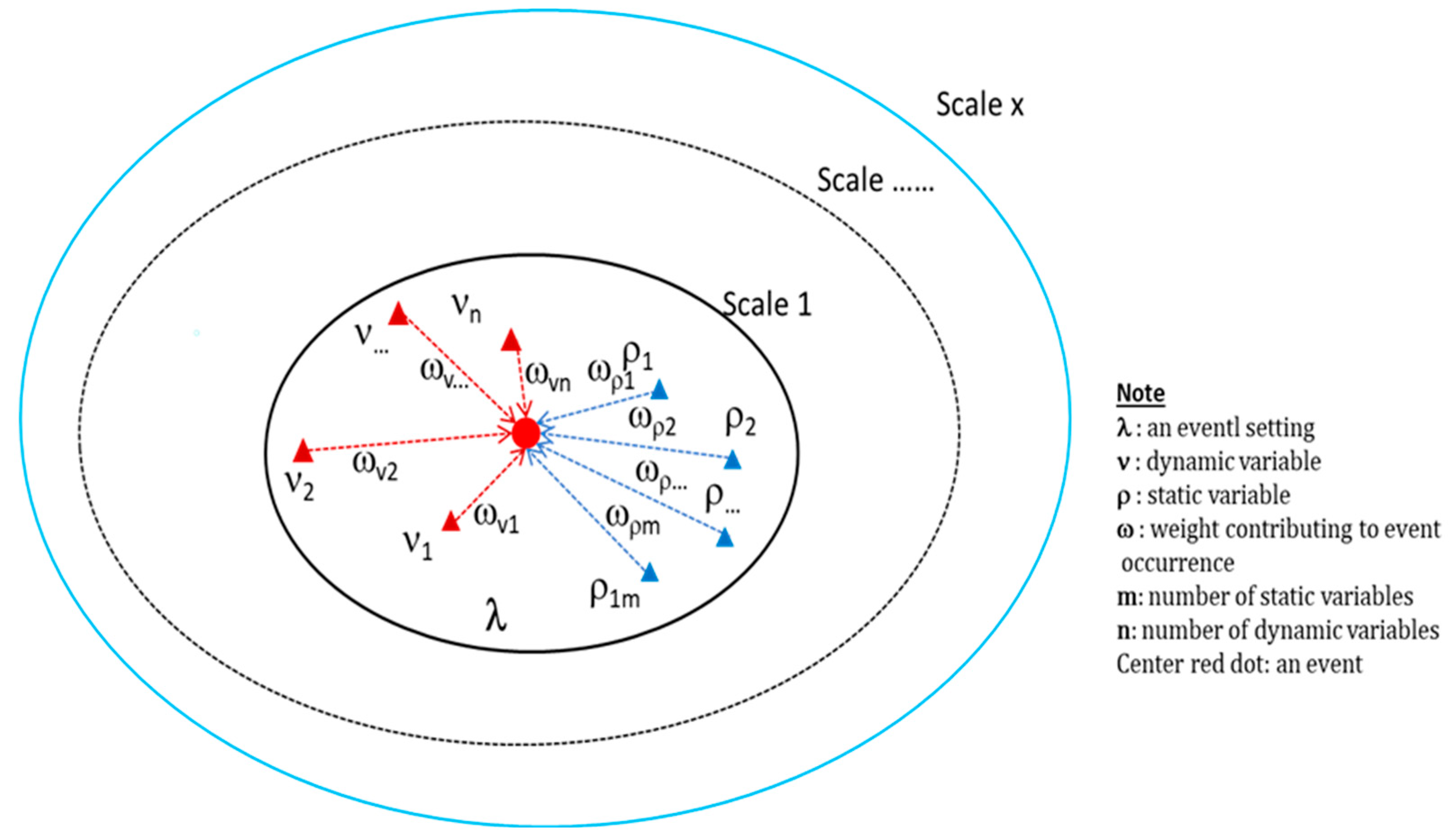
2.1. Model for Event Sequence Settings
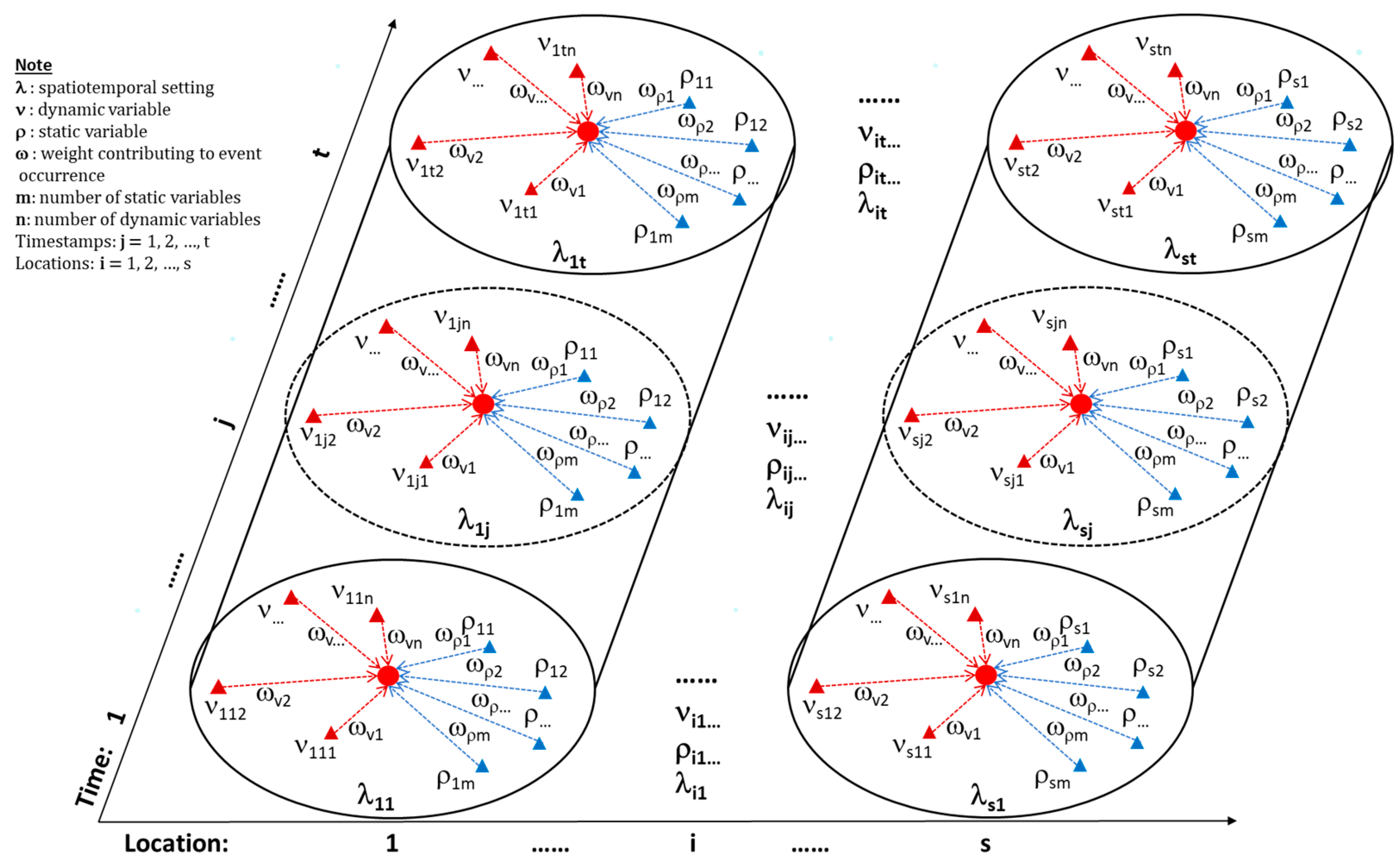
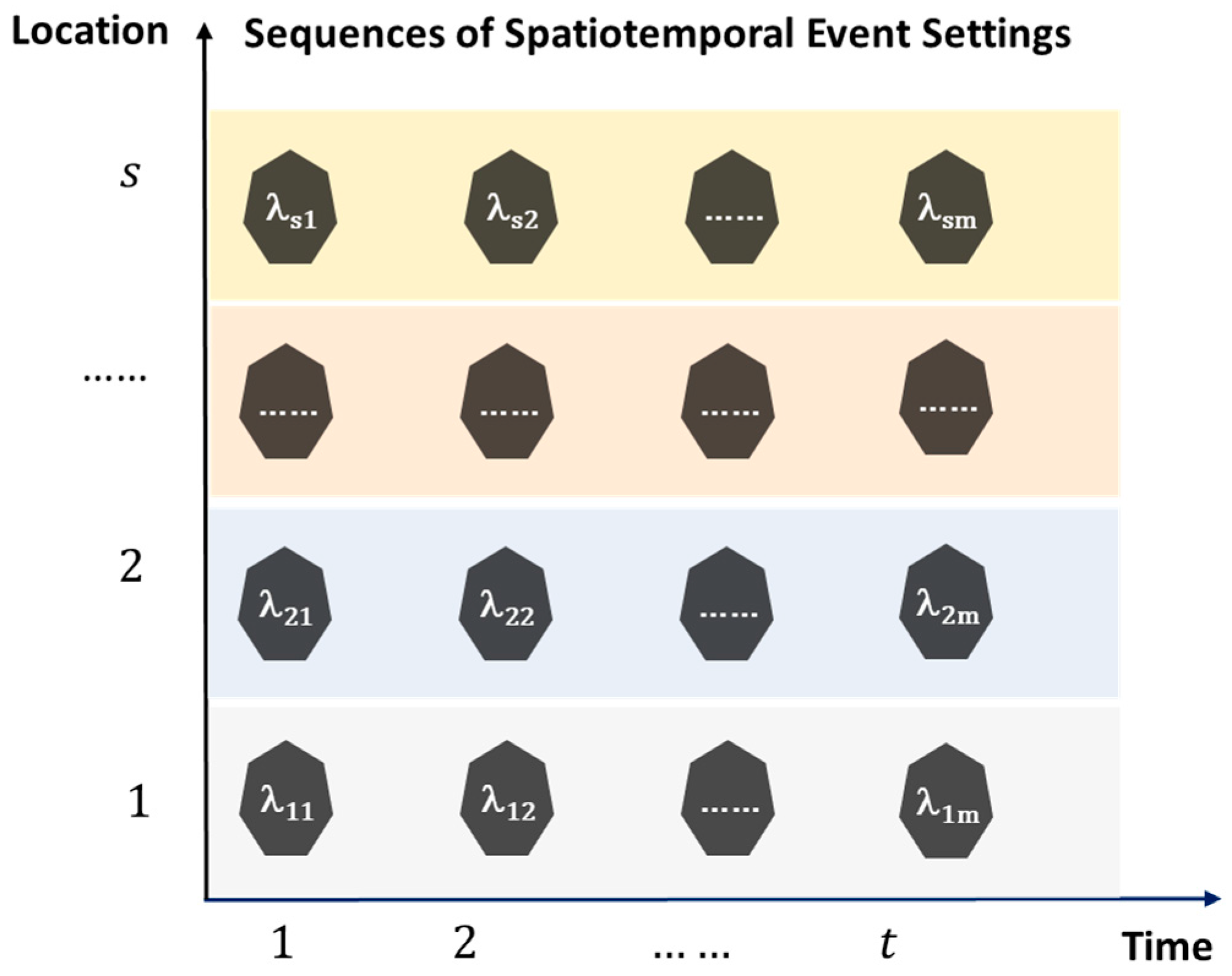
2.2. Matrix Representation of Sequences of Spatiotemporal Settings
2.3. Similarity Measures of Spatial Settings
2.3.1. Pairwise Similarity between Individual Spatial Settings
2.3.2. Pairwise Similarity between Sequences of Spatial Settings
- (1)
- Variable type: interval, ratio, binary and categorical; not considering the weights of individual variables:
- (2)
- Variable type: interval, ratio, binary and categorical; considering the weights of individual variables:
- (3)
- Variable type: ordinal; not considering the weights of individual variables:
- (4)
- Variable type: ordinal; considering the weights of individual variables:
2.4. Setting Similarity Analysis Workflow
3. Case study: Setting Similarity of Coastal Monitoring Stations for Fecal Pollution
3.1. Experimental Site and Design
3.1.1. Site and Variables
3.1.2. Data Collection
3.1.3. Methods
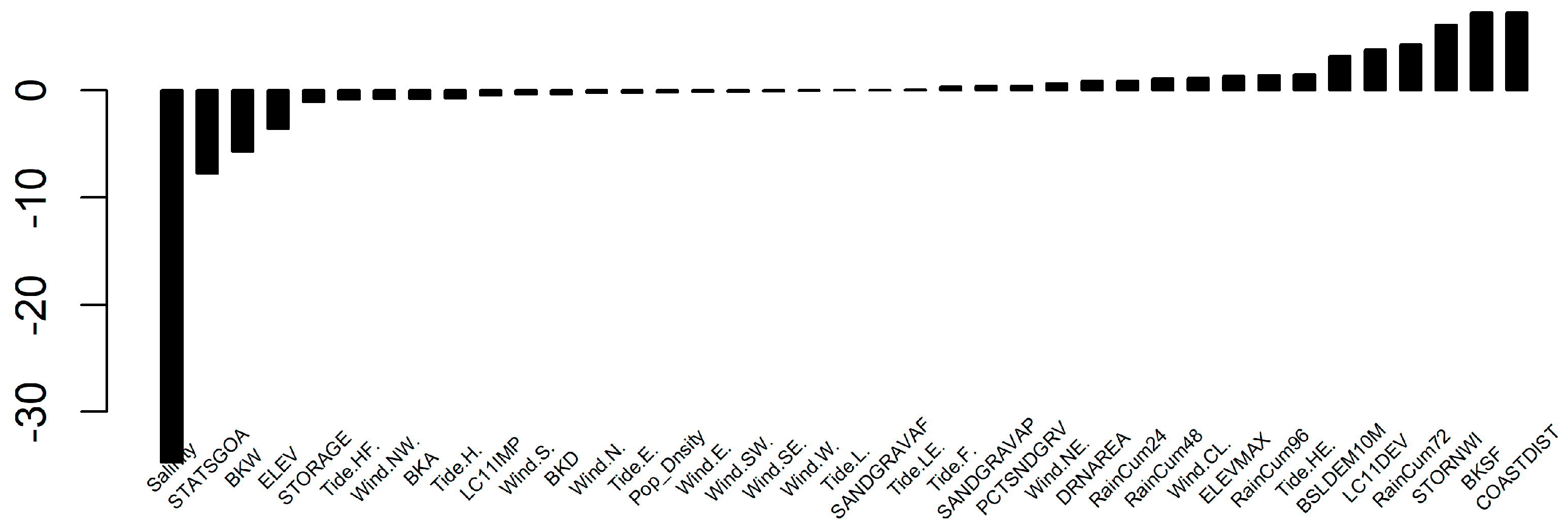
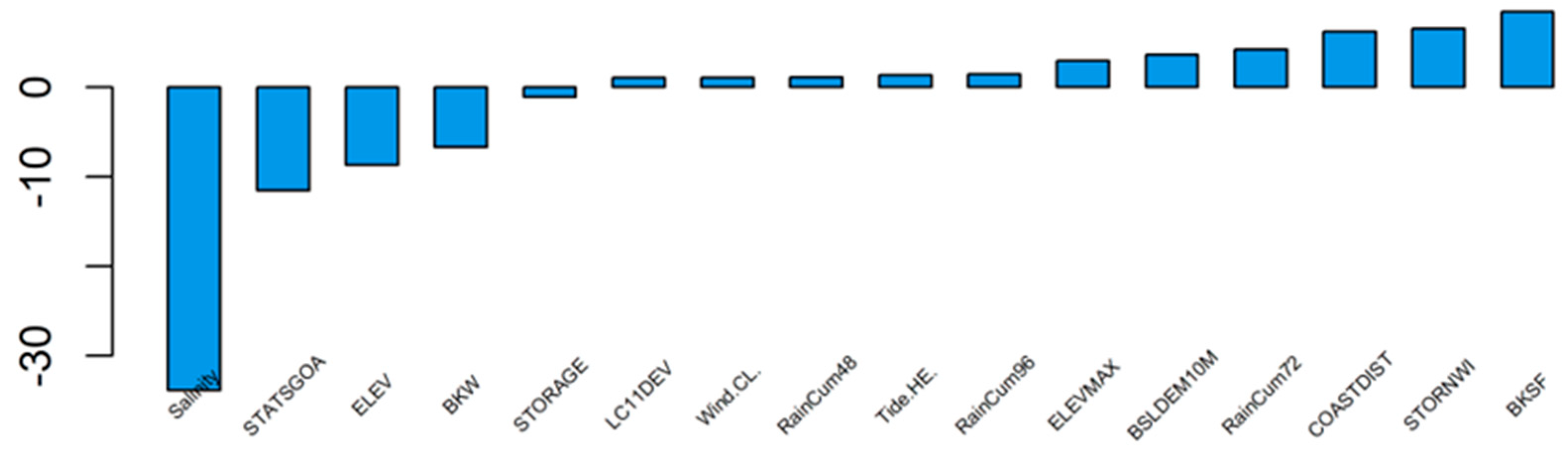
3.2. Relative Weights and Selection of Representative Variables for Spatial Settings
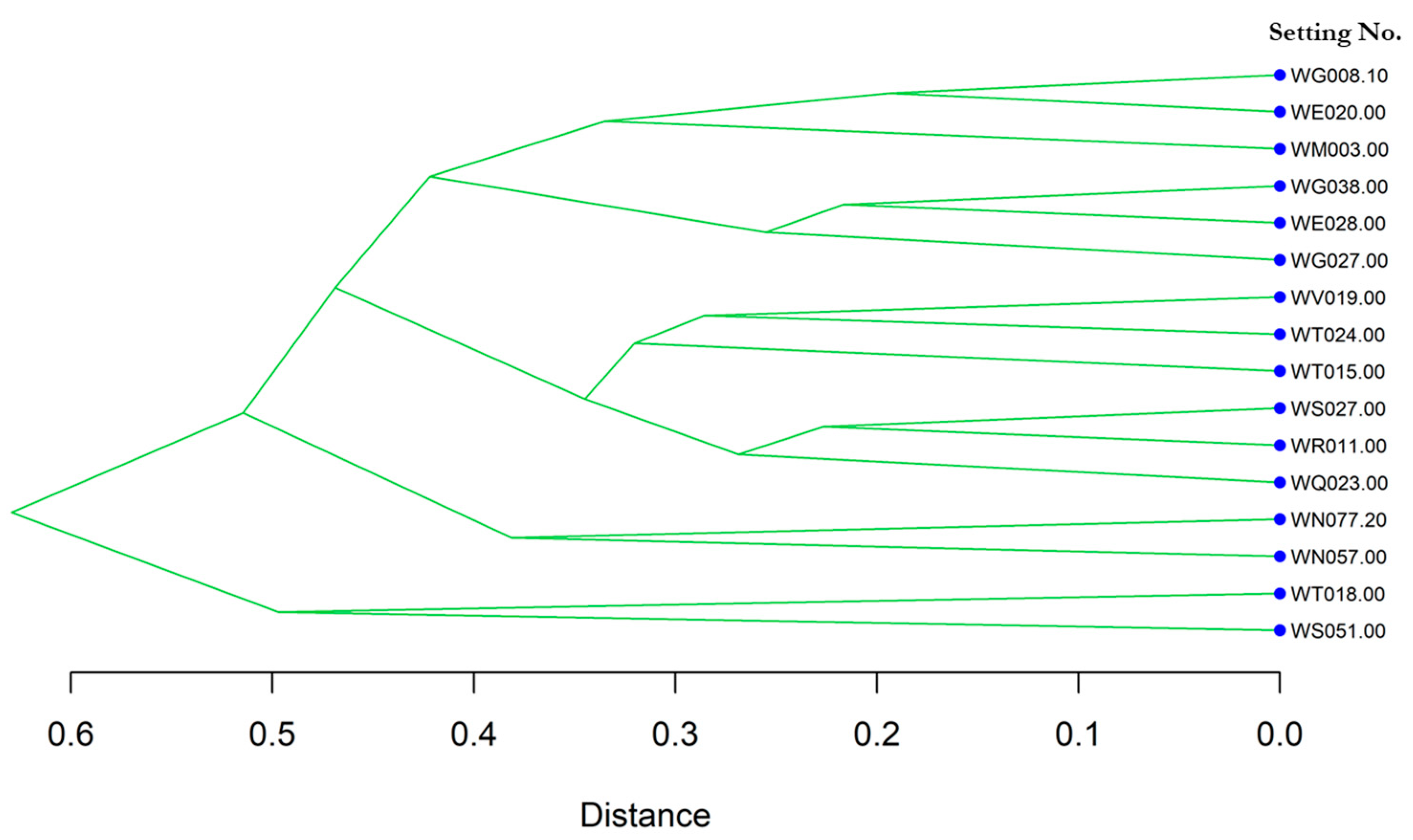
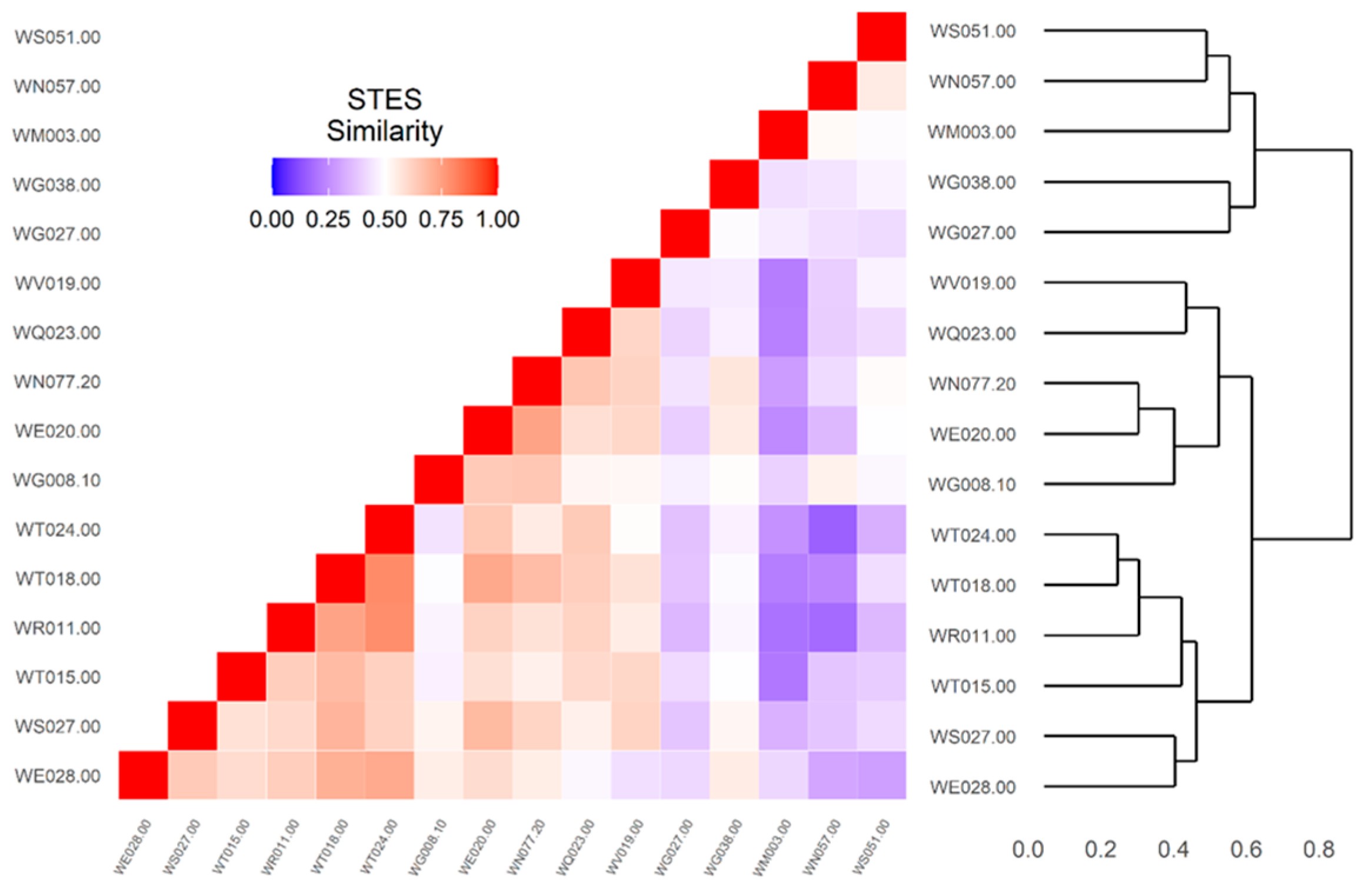
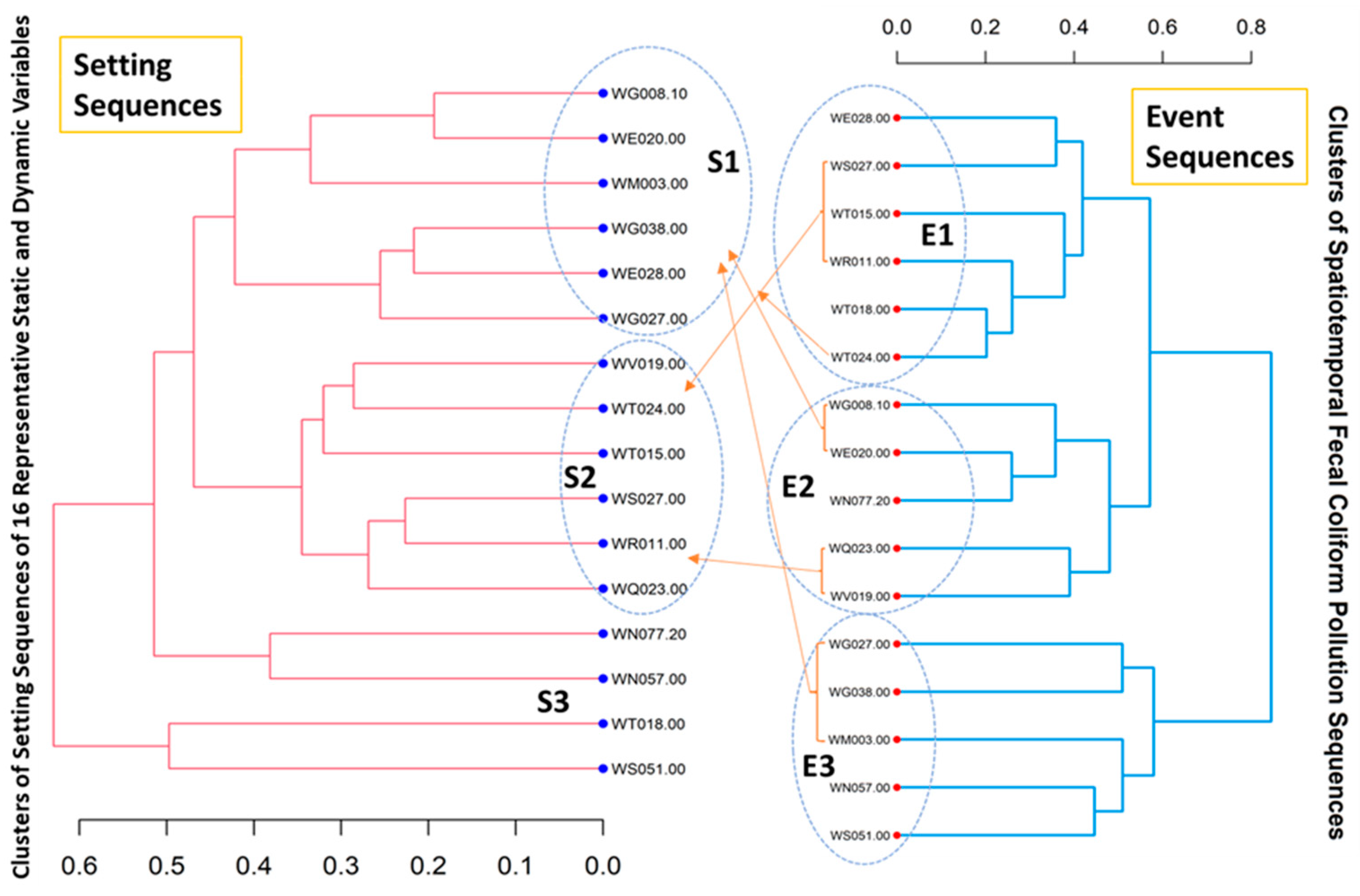
3.3. Clustering Analysis of Spatial Setting Sequences and Fecal Pollution Event Sequences
3.4. Cross Analysis between Clusters of Setting Sequences and Clusters of Event Sequences
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Xu, F.; Beard, K. A Unifying Framework for Analysis of Spatial-Temporal Event Sequence Similarity and Its Applications. ISPRS Int. J. Geo-Inf. 2021, 10, 594. [Google Scholar] [CrossRef]
- Lupiani, E.; Sauer, C.; Roth-Berghofer, T.; Juarez, J.M.; Palma, J. Implementation of similarity measures for event sequences in myCBR. In Proceedings of the 18th UKCBR Workshop, Cambridge, UK, 10 December 2012. [Google Scholar]
- Guralnik, V.; Srivastava, J. Event detection from time series data. In Proceedings of the fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 1 August 1999; pp. 33–42. [Google Scholar]
- Moen, P. Attribute, Event Sequence, and Event Type Similarity Notions for Data Mining. Ph.D. Thesis, University of Helsinki, Helsinki, Finland, 2000. [Google Scholar]
- Mannila, H.; Ronkainen, P. Similarity of event sequences. In Temporal Representation and Reasoning, Proceedings of the Fourth International Workshop; IEEE Computer Society Press: Washington, DC, USA, 1997; pp. 136–139. [Google Scholar]
- Obweger, H.; Suntinger, M.; Schiefer, J.; Raidl, G. Similarity searching in sequences of complex events. In the 2010 Fourth IEEE International Conference on Research Challenges in Information Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 631–640. [Google Scholar]
- Wongsuphasawat, K.; Plaisant, C.; Taieb-Maimon, M.; Shneiderman, B. Querying event sequences by exact match or similarity search: Design and empirical evaluation. Interact. Comput. 2012, 24, 55–68. [Google Scholar] [CrossRef]
- Simandan, D. Being surprised and surprising ourselves: A geography of personal and social change. Prog. Hum. Geogr. 2020, 44, 99–118. [Google Scholar] [CrossRef]
- Paasi, A. Place and region: Looking through the prism of scale. Prog. Hum. Geogr. 2004, 28, 536–546. [Google Scholar] [CrossRef]
- Malpas, J. Putting space in place: Philosophical topography and relational geography. Environ. Plan D Soc. Space 2012, 30, 226–242. [Google Scholar] [CrossRef]
- Schatzki, T.R. The Site of the Social: A Philosophical Account of the Constitution of Social Life and Change; Penn State University Press: University Park, PA, USA, 2002. [Google Scholar]
- Marston, S.A.; Jones, J.P., III; Woodward, K. Human geography without scale. Trans. Inst. Br. Geogr. 2005, 30, 416–432. [Google Scholar] [CrossRef]
- Woodward, K.; Jones, J.P., III; Marston, S.A. The politics of autonomous space. Prog. Hum. Geogr. 2012, 36, 204–224. [Google Scholar] [CrossRef]
- Worboys, M.; Hornsby, K. From objects to events: GEM, the geospatial event model. In Proceedings of the International Conference on Geographic Information Science, Adelphi, MD, USA, 20–23 October 2004; pp. 327–343. [Google Scholar]
- Moore, A. Rethinking scale as a geographical category: From analysis to practice. Prog. Hum. Geogr. 2008, 32, 203–225. [Google Scholar] [CrossRef]
- Jiang, B.; Yao, X. Location based services and GIS in perspective. In Location Based Services and Telecartography; Springer: Berlin/Heidelberg, Germany, 2007; pp. 27–45. [Google Scholar]
- Dey, A.K. Understanding and using context. Pers. Ubiquitous Comput. 2001, 5, 4–7. [Google Scholar] [CrossRef]
- Brézillon, P.; Gonzalez, A.J. Context in Computing: A Cross-Disciplinary Approach for Modeling the Real World; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Loke, S. Context-Aware Pervasive Systems: Architectures for a New Breed of Applications; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Zolnik, E.J. Context in human geography: A multilevel approach to study human–environment interactions. Prof. Geogr. 2009, 61, 336–349. [Google Scholar] [CrossRef]
- Sunley, P. Context in economic geography: The relevance of pragmatism. Prog. Hum. Geogr. 1996, 20, 338–355. [Google Scholar] [CrossRef]
- Weber, J.; Kwan, M.-P. Evaluating the effects of geographic contexts on individual accessibility: A multilevel Approach1. Urban Geogr. 2003, 24, 647–671. [Google Scholar] [CrossRef]
- Gong, H.; Hassink, R. Context sensitivity and economic-geographic (re) theorising. Camb. J. Reg. Econ. Soc. 2020, 13, 475–490. [Google Scholar] [CrossRef]
- Simandan, D. Revisiting positionality and the thesis of situated knowledge. Dialogues Hum. Geogr. 2019, 9, 129–149. [Google Scholar] [CrossRef]
- Delbosc, A.; Currie, G. The spatial context of transport disadvantage, social exclusion and well-being. J. Transp. Geogr. 2011, 19, 1130–1137. [Google Scholar] [CrossRef]
- Timmermans, H.; van der Waerden, P.; Alves, M.; Polak, J.; Ellis, S.; Harvey, A.S.; Kurose, S.; Zandee, R. Spatial context and the complexity of daily travel patterns: An international comparison. J. Transp. Geogr. 2003, 11, 37–46. [Google Scholar] [CrossRef]
- Cutter, S.L. Vulnerability to environmental hazards. Prog. Hum. Geogr. 1996, 20, 529–539. [Google Scholar] [CrossRef]
- Roux, A.V.D.; Mair, C. Neighborhoods and health. Ann. N. Y. Acad. Sci. 2010, 1186, 125–145. [Google Scholar] [CrossRef]
- Sampson, R.J. The neighborhood context of well-being. Perspect. Biol. Med. 2003, 46, S53–S64. [Google Scholar] [CrossRef]
- Yang, D.-H.; Goerge, R.; Mullner, R. Comparing GIS-based methods of measuring spatial accessibility to health services. J. Med. Syst. 2006, 30, 23–32. [Google Scholar] [CrossRef]
- Wolpert, J. The decision process in spatial context. Ann. Assoc. Am. Geogr. 1964, 54, 537–558. [Google Scholar] [CrossRef]
- Gripenberg, S.; Roslin, T. Up or down in space? Uniting the bottom-up versus top-down paradigm and spatial ecology. Oikos 2007, 116, 181–188. [Google Scholar] [CrossRef]
- Tilman, D.; Kareiva, P. Spatial Ecology: The Role of Space in Population Dynamics and Interspecific Interactions (MPB-30); Princeton University Press: Princeton, NJ, USA, 2018; Volume 30. [Google Scholar]
- Singhal, A.; Luo, J.; Zhu, W. Probabilistic spatial context models for scene content understanding. In the Computer Vision and Pattern Recognition, 2003, Proceedings of the 2003 IEEE Computer Society Conference; IEEE: Piscataway, NJ, USA, 2003; p. I. [Google Scholar]
- Heitz, G.; Koller, D. Learning spatial context: Using stuff to find things. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2008; pp. 30–43. [Google Scholar]
- Keßler, C. Similarity measurement in context. In Proceedings of the International and Interdisciplinary Conference on Modeling and Using Context, Roskilde, Denmark, 20–24 August 2007; pp. 277–290. [Google Scholar]
- Keßler, C.; Raubal, M.; Janowicz, K. The effect of context on semantic similarity measurement. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Rhodes, Greece, 21–25 October 2007; pp. 1274–1284. [Google Scholar]
- Levin, S.A. The problem of pattern and scale in ecology: The Robert H. MacArthur award lecture. Ecology 1992, 73, 1943–1967. [Google Scholar] [CrossRef]
- Choi, S.-S.; Cha, S.-H.; Tappert, C.C. A survey of binary similarity and distance measures. J. Syst. Cybern. Inform. 2010, 8, 43–48. [Google Scholar]
- Chao, Y.-C.E.; Zhao, Y.; Kupper, L.L.; Nylander-French, L.A. Quantifying the relative importance of predictors in multiple linear regression analyses for public health studies. J. Occup. Environ. Hyg. 2008, 5, 519–529. [Google Scholar] [CrossRef] [PubMed]
- Tonidandel, S.; LeBreton, J.M. RWA web: A free, comprehensive, web-based, and user-friendly tool for relative weight analyses. J. Bus. Psychol. 2015, 30, 207–216. [Google Scholar] [CrossRef]
- Tonidandel, S.; LeBreton, J.M.; Johnson, J.W. Determining the statistical significance of relative weights. Psychol. Methods 2009, 14, 387. [Google Scholar] [CrossRef]
- Ali, F.; Rasoolimanesh, S.M.; Sarstedt, M.; Ringle, C.M.; Ryu, K. An assessment of the use of partial least squares structural equation modeling (PLS-SEM) in hospitality research. Int. J. Contemp. Hosp. Manag. 2018, 30, 514–538. [Google Scholar] [CrossRef]
- Noble, R.T.; Moore, D.F.; Leecaster, M.K.; McGee, C.D.; Weisberg, S.B. Comparison of total coliform, fecal coliform, and enterococcus bacterial indicator response for ocean recreational water quality testing. Water Res. 2003, 37, 1637–1643. [Google Scholar] [CrossRef]
- Dong, J.; Wang, G.; Yan, H.; Xu, J.; Zhang, X. A survey of smart water quality monitoring system. Environ. Sci. Pollut. Res. 2015, 22, 4893–4906. [Google Scholar] [CrossRef] [PubMed]
- Prasad, A.; Mamun, K.A.; Islam, F.; Haqva, H. Smart water quality monitoring system. In Proceedings of the 2015 2nd Asia-Pacific World Congress on Computer Science and Engineering (APWC on CSE), Nadi, Fiji, 2–4 December 2015; pp. 1–6. [Google Scholar]
- Hughes, K.A. Influence of seasonal environmental variables on the distribution of presumptive fecal coliforms around an Antarctic research station. Appl. Environ. Microbiol. 2003, 69, 4884–4891. [Google Scholar] [CrossRef] [PubMed]
- Kettenring, J.R. The practice of cluster analysis. J. Classif. 2006, 23, 3–30. [Google Scholar] [CrossRef]
- Castellarin, A.; Burn, D.; Brath, A. Assessing the effectiveness of hydrological similarity measures for flood frequency analysis. J. Hydrol. 2001, 241, 270–285. [Google Scholar] [CrossRef]
- Kamarinas, I.; Julian, J.P.; Hughes, A.O.; Owsley, B.C.; De Beurs, K.M. Nonlinear changes in land cover and sediment runoff in a New Zealand catchment dominated by plantation forestry and livestock grazing. Water 2016, 8, 436. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation/Code | Description | Unit |
|---|---|---|
| Static Variables | (Basin Characteristics) | |
| BSLDEM10M | Mean basin slope computed from 10 m DEM | percent |
| COASTDIST | Shortest distance from the coastline to the basin centroid | miles |
| DRNAREA | Area that drains to a point on a stream | square miles |
| ELEV | Mean Basin Elevation | feet |
| ELEVMAX | Maximum basin elevation | feet |
| LC11DEV | Percentage of developed (urban) land from NLCD 2011 classes 21–24 | percent |
| LC11IMP | Average percentage of impervious area determined from NLCD 2011 impervious dataset | percent |
| PCTSNDGRV | Percentage of land surface underlain by sand and gravel deposits | percent |
| SANDGRAVAF | Fraction of land surface underlain by sand and gravel aquifers | dimensionless |
| SANDGRAVAP | Percentage of land surface underlain by sand and gravel aquifers | percent |
| STATSGOA | Percentage of area of Hydrologic Soil Type A from STATSGO | percent |
| STORAGE | Percentage of area of storage (lakes ponds reservoirs wetlands) | percent |
| STORNWI | Percentage of storage (combined water bodies and wetlands) from the National Wetlands Inventory | percent |
| BKSF | Bank-full Streamflow | ft^3/s |
| BKW | Bank-full Width | ft |
| BKD | Bank-full Depth | ft |
| BKA | Bank-full Area | ft^2 |
| Pop_Dnsity | Population Density | persons/mi^2 |
| Dynamic Variables | ||
| Tide | Tide stages: H, L, F, E, HF, HE, LF, LE | 3 h |
| Salinity | Ocean water salinity | |
| Wind | Wind direction: E, S, W, N, NW, NE, SW, SE | Direction |
| RainCum24 | Cumulative precipitation in 24 h | inch |
| RainCum48 | Cumulative precipitation in 48 h | inch |
| RainCum72 | Cumulative precipitation in 72 h | inch |
| RainCum96 | Cumulative precipitation in 96 h | inch |
| Negative Variables | Relative Importance | Positive Variables | Relative Importance |
|---|---|---|---|
| Salinity | −34.696 | COASTDIST | 7.252 |
| STATSGOA | −7.763 | BKSF | 7.217 |
| BKW | −5.725 | STORNWI | 6.092 |
| ELEV | −3.630 | RainCum72 | 4.256 |
| STORAGE | −1.069 | LC11DEV | 3.789 |
| Tide.HF. | −0.817 | BSLDEM10M | 3.200 |
| Wind.NW. | −0.790 | Tide.HE. | 1.455 |
| BKA | −0.778 | RainCum96 | 1.389 |
| Tide.H. | −0.771 | ELEVMAX | 1.298 |
| LC11IMP | −0.472 | Wind.CL. | 1.121 |
| Wind.S. | −0.373 | RainCum48 | 1.082 |
| BKD | −0.372 | RainCum24 | 0.878 |
| Wind.N. | −0.247 | DRNAREA | 0.871 |
| Tide.E. | −0.218 | Wind.NE. | 0.654 |
| Pop_Dnsity | −0.186 | PCTSNDGRV | 0.399 |
| Wind.E. | −0.109 | SANDGRAVAP | 0.393 |
| Wind.SW. | −0.106 | Tide.F. | 0.325 |
| Wind.SE. | −0.095 | Tide.LE. | 0.042 |
| Wind.W. | −0.056 | SANDGRAVAF | 0.004 |
| Tide.L. | −0.015 |
| Negative Variables | Relative Importance | Positive Variables | Relative Importance |
|---|---|---|---|
| Salinity | −33.900 | BKSF | 8.500 |
| STATSGOA | −11.500 | STORNWI | 6.500 |
| ELEV | −8.700 | COASTDIST | 6.200 |
| BKW | −6.700 | RainCum72 | 4.200 |
| STORAGE | −1.100 | BSLDEM10M | 3.700 |
| ELEVMAX | 3.000 | ||
| Tide.HE. | 1.400 | ||
| RainCum96 | 1.400 | ||
| LC11DEV | 1.100 | ||
| Wind.CL. | 1.100 | ||
| RainCum48 | 1.100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Beard, K. A Novel Similarity Measure of Spatiotemporal Event Setting Sequences: Method Development and Case Study. Geographies 2023, 3, 303-320. https://doi.org/10.3390/geographies3020016
Xu F, Beard K. A Novel Similarity Measure of Spatiotemporal Event Setting Sequences: Method Development and Case Study. Geographies. 2023; 3(2):303-320. https://doi.org/10.3390/geographies3020016
Chicago/Turabian StyleXu, Fuyu, and Kate Beard. 2023. "A Novel Similarity Measure of Spatiotemporal Event Setting Sequences: Method Development and Case Study" Geographies 3, no. 2: 303-320. https://doi.org/10.3390/geographies3020016
APA StyleXu, F., & Beard, K. (2023). A Novel Similarity Measure of Spatiotemporal Event Setting Sequences: Method Development and Case Study. Geographies, 3(2), 303-320. https://doi.org/10.3390/geographies3020016