1. Introduction
Fractional differential equations have recently become an active research area due to the applications in fields including mechanics, computer science, and biology [
1,
2,
3,
4]. There are different fractional derivatives, e.g., Caputo, Riemman–Liouville, Riesz, etc. Such fractional derivatives are well studied in literature. One particular fractional derivative, the Hadamard fractional derivative, is also important and has been used to model physical problems in many fields [
5,
6,
7,
8,
9,
10,
11]. The Hadamard fractional derivative was first introduced in early 1892 [
12], and the Caputo–Hadamard derivative was suggested by Jarad et al. [
8]. In this paper, we will discuss the numerical method for solving a Caputo–Hadamard fractional initial value problem. We will be analyzing the smoothness properties of various aspects of such equations and explain how these properties will affect the convergence order of the numerical method.
Consider the following Caputo–Hadamard fractional differential equation, with
, [
8]
for
. Here,
denotes the least integer bigger than or equal to
. Here,
is a nonlinear function with respect to
, and the initial values
are given. We also define
such that
, for
. Here, the fractional derivative
denotes the Caputo–Hadamard derivative defined as,
with
. It is well known that (
1) is equivalent to the following Volterra integral equation, with
[
13,
14],
Let us begin by reviewing some different numerical methods for solving (
1). Diethelm et al. [
15] first introduced the fractional Adams method for the Caputo fractional differential equation as a generalization of the classical numerical method for solving first-order ODEs. They discussed the error estimates for the proposed method, including the convergence orders under the different smoothness assumptions of
y and
f. This work was then extended by Liu et al. [
16] to show that when
, the optimal convergence order is not achieved but can be recovered by implimenting a graded mesh. Gohar et al. [
7] studied the existence and uniqueness of the solution of (
1), and several numerical methods were introduced including the Euler and predictor–corrector methods. Gohar et al. [
13] extended their work by introducing the rectangular, trapezoidal, and predictor–corrector methods for solving (
1) with a uniform mesh under the smooth assumptions
with
. Green et al. [
14] extended the results in [
16] to the Caputo–Hadamard differential Equation (
1). Numerical methods for solving Caputo–Hadamard time fractional partial differential equations can be found in [
7,
17]. More recent works on numerical methods for solving fractional differential equations can be referred to [
17,
18,
19,
20,
21].
Caputo–Hadamard type fractional differential equations have the significant interests when they come to real applications due to the logarithmic nature of the integral kernel. This is especially true in mechanics and engineering. An example of this is the use of Hadamard type equations in fracture analysis and the modeling of elasticity [
22]. Furthermore, the Caputo–Hadamard fractional derivative has been used in fractional turbulent flow models [
23]. In biology, the Hadamard fractional derivative has been used in modeling for cancer treatments by radiotherapy [
24]. Many of these models require efficient numerical methods for solving them. In literature, the error estimates of the numeircal methods proposed for solving the Caputo–Hadamard fractional differential Equation (
1) are based on the assumptions that the solution
y and
f are sufficiently smooth [
7,
13]. In this paper, we will consider the error estimates of the numerical methods under the different smoothness assumptions of
y and
f.
Diethelm et al. [
15] considered a variety of smoothness assumptions of
y and
f to the fractional Adams method for solving Caputo differential equations. The aim of this work is to extend the ideas in [
15] for solving Caputo fractional differential equation to Caputo–Hadamard fractional differential Equation (
1).
Let us start by briefly recalling the Adams–Bashforth–Moulton method for the Caputo–Hadamard fractional derivative. To construct such a method, we require an approximation of the integral in (
3). We will apply the following product trapezoidal quadrature rule,
where the approximation
is the piecewise linear interpolant for g at
. Using the standard techniques from quadrature theory, we can write the right hand side integral as,
where,
and,
Evaluating the integral, we get,
This gives us the formula for the corrector, known as the fractional one-step Adams–Moulton method,
We now must determine the predictor formula required to calculate
. For this, we will generalize the one-step Adams–Bashforth method for ODEs. To do this, we follow a similar method, but now, we will be replacing the integral on the right-hand side by the product rectangle formula rule,
where,
Therefore, the predictor can be calculated using the fractional Adams–Bashforth method,
Finally, we can conclude that our basic method, the fractional Adams–Bashforth–Moulton method, is described with the predictor Equation (
12), the corrector Equation (
9), and weights (
8) and (
11). For this method, however, we will be using a uniform mesh defined below.
Let N be a positive integer and let
be the partition on
. We define the following uniform mesh on
with
which implies that,
when
we have
and when
, we have
. By applying such a mesh on our weights, we can simplify them to,
and
The fractional Adams–Bashforth–Moulton method has many useful properties. First, we may use this method to solve nonlinear fractional differential equation by transforming the nonlinear equation into a Volterra integral equation with a singular kernel and approximating the corresponding Volterra integral equation with some suitable quadrature formula. Second, the fractional Adams–Bashforth–Moulton method is an explicit method, and as such, it can save computer memory and can be more computationally time-efficient. Finally, this method has been shown to have a convergence order of for suitable meshes.
We shall consider the error estimates of the predictor–corrector schemes (
9) and (
12) under the various smoothness assumptions of
f and
y in this paper. The paper is organized as follows. In
Section 2, we will consider some auxiliary results that will aid us for the remainder of the paper in proving the error estimates. In
Section 3, we consider the error estimates of the predictor–corrector method for solving (
1) with a uniform mesh under different smoothness conditions. In
Section 4, we will provide several numerical examples that support the theoretical conclusions made in
Section 2 and
Section 3.
2. Auxiliary Results
For the remainder of this work, we will be using the Adams method described by the predictor Equation (
12) and the corrector Equation (
9) and the uniform mesh described by (
13) to solve the fractional initial value problem (
1). To begin, we must apply some conditions on the function
f, namely that
f is continuous and follows the Lipschitz condition with respect to its second argument with the Lipschitz constant,
L, on a suitable set
G. By forcing these conditions, we may use [
25] to show that a unique solution
y of the initial value problem exists on the interval
. Our goal is to find a suitable approximation for this unique solution.
As such, we will introduce several auxiliary results on certain smoothness properties to help us in our error analysis of this method. Our first result is taken from [
13].
Theorem 1. (a) Let . Assume that where is a suitable set. Define . Then, there exists a function and some constants such that the solution y of (1) can be expressed in the following form:(b) Assume that . Define . and . Then, there exists a function and some constants and such that the solution y of (1) can be expressed in the form, We can also relate such smoothness properties of the solution with that of the Caputo–Hadamard derivatives. From [
13], we have,
Theorem 2. If for some and , then,where and with . Moreover, the (th derivative of g satisfies a Lipschitz condition of order . A useful corollary can then be drawn from this theorem and can be used to generalize the classical result for derivatives of integer order.
Corollary 1. Let for some and assume that . Then, .
We will now introduce some error estimates for both the product rectangle rule and product trapezoidal rule, which we have implemented as the predictor and corrector of our method. Doing so will aid us in producing error estimates and convergence orders of the fractional Adams method.
Theorem 3. (a) Let and . Let h be defined by (14). Then,(b) Let for some . Then, Proof. Using the construction of the product rectangle formula rule, we can show that in both cases above, the quadrature error can be represented by,
We will begin by proving statement (a). We first apply the Mean Value Theorem on
z in the second factor of the integrand and note that
. This gives us, with
,
The final bracket can be interpreted as the remainder of the standard rectangle quadrature formula for the function
over the interval
. We can then apply a standard result from quadrature theory that states that this term is bounded by the total variation of the integrand,
. Therefore, we can conclude that,
Now to prove (b). We use the fact that is monotonic and repeated applications of the Mean Value Theorem. We are required to take cases when and .
Assuming (
25) holds at the moment, we then have,
It remains to prove (
25), which we shall do now.
Let
for
. Then,
By letting the parenthesis equal zero, we find that
has a turning point at
, meaning
is decreasing on
and increasing on
. Therefore,
Assuming (
26) holds at the moment, we then have,
It remains to prove (
26), which we shall do now.
Let
for
. Then,
By letting the parenthesis equal zero, we find that has a turning point at , meaning F(x) is decreasing on and increasing on . Therefore,
- (i)
If
, then
. Therefore,
- (ii)
If
, then
. This means that
and shows that
is a decreasing function. Therefore,
which gives us the desired result. □
Next, we come to corresponding results for the trapezoidal formula that has been used for the corrector of our method. The proofs of this theorem are similar to those of the previous theorem.
Theorem 4. (a) Let and . Let h be defined by (14). Then, there exists a constant depending on α such that,(b) Let and assume that fulfils a Lipschitz condition of order μ for some . Then, there exists a positive constant and such that,(c) Let for some and . Then, Proof. By construction of the product trapezoidal formula rule, we can show that in the first two cases above, the quadrature error can be represented as,
where,
We will begin by proving statement (a). To find an estimate for (
30), we must simplify the second factor of the integrand by applying the Mean Value Theorem. Therefore,
Applying the above to (
30), we get,
Now to prove (b). As
, this time, we are unable to apply the mean value theorem for a second time. Instead, we will apply the Lipschitz condition of order
on
for some
. Therefore,
where
M is a constant depending on
z and
. Applying the above to (
30), we get,
Finally, we shall prove (c). We will start by proving the theorem when .
Similar to our previous proof, we now must find the bounds for the summation.
Thus, we get the desired result.
Similar to our previous proof, we now must find the bounds for the summation.
Thus, we get the desired result. The proof for this theorem when is similar to when . As such, it has been omitted. □
Remark 1. In the final part of Theorem 4, there is a case when . This would result in a , and, in turn, this would make the right hand side exponent of become negative, taking a value of . This results in a case in which the error increases as the interval of integration decreases. The explanation for such a situation is that as the interval of integration decreases, so too does the weight function, making the integral more difficult to calculate and resulting in an increase in error.
3. Error Analysis for the Adams Method
In this section, we will be presenting the main error estimates for the Adams method for solving (
1). We will be investigating different smoothness conditions for each of
y and
f and how they affect the error and convergence order.
3.1. A General Result
Using the error estimates established in the previous section, we will present the general convergence order of the Adams–Bashforth–Moulton method relating to the smoothness properties of the given function f and the solution y.
Lemma 1. Assume that the solution y of (1) is such that,and,with some and . Let be the approximate solution of (1). Then, for some suitably chosen , we have,where . Proof. We will show that, for sufficiently small
h,
for all
, where C is a suitable constant. This proof will be based on mathematical induction. By using the initial conditions, we can confirm the basis step at
. We now assume that (
34) is true for all
for some
. Finally, we will prove that inequality (
34) is true for
. To show this, we must start by finding the error of the predictor
. By the definition of the predictor, we can show the following:
For this proof, we have used several properties. These include the Lipschitz condition placed on
f, the assumption of the error on the rectangle formula, and the understanding of the underlying predictor weights,
for all
j and
k and,
Now, we have a bound for the predictor error. We also need to analyze the corrector error. To do so, we will be using a similar argument as with the predictor case as well as using the assumption made for mathematical induction. Note that,
Due to both and being non-negative and the relations and , we may choose a sufficiently small T such that the second summand in the parentheses is bounded above by . Then, by fixing the value of T, we may bound the rest of the terms by as well, given a small enough value of h and by choosing a large C value. Finally, we can state that the error estimate for the corrector is now bounded above by . □
3.2. Error Estimates with Smoothness Assumptions on the Solution
In this subsection, we will be introducing some error estimates given certain smoothness assumptions being placed on the solution of our inital value problem. To do this, we will be using the general error estimate introduced above as well as the auxiliary results demonstrated in
Section 2. For our first case, we will assume that
y is sufficiently differentiable. This means the outcome is dependent on
—more specifically, when
and when
.
Theorem 5. Let and assume for some suitable T. Then, We can note from this theorem that the order of convergence depends on . More specifically, a larger value of gives a better order of convergence. The reason for this is due to the fact that we have chosen to discretize an integral operator that will behave more smoothly as the value of increases, thus creating a higher order. We could have chosen to discretize the differential operator directly from the inital value problem. It can be shown that the opposite result occurs compared to the integral operator. As increases, the smoothness of the operator deteriorates, and the convergence order diminishes. More specifically, it has been shown that when , no convergence is achieved. This means that such a method is effective when is small but will be ineffective for larger values. This is one of the main advantages of this method for the Caputo–Hadamard derivative, as convergence is not only achieved but is most optimal at larger values of .
Proof. By applying Theorems 3 and 4 and Lemma 1 with
,
, and
, we can show that the an
error bound where,
□
We can note from this theorem that this is for an optimal situation. The function we must approximate when applying the Adams method is the function . Therefore, the error bound is heavily dependent on obtaining a good approximations of f. To obtain such good error bounds, we can look to quadrature theory, which gives a well-known condition for obtaining this, namely the function over the interval of the integral. As we can see from the above theorem, that is the case that we are looking at here. Therefore, this can be considered as an optimal situation. However, this can be also considered as an unusual situation. Rarely are we given enough information such that we can determine the smoothness of y or, in this case, , so we cannot rely on such a theorem. In general, we must formulate our theorems using the data given on the function f, which will be considered in the next subsection.
We next move on to giving some theorems that now give the smoothness assumptions based on the unknown solution y instead of . Theorem 2 implies that the smoothness of y often implies the nonsmoothness of ; we are expecting some difficulties in finding the error estimates. However, Theorem 2 also gives us the form of under such smoothness conditions and gives us information about the singularities and smoothness of . As such, we can use this information to give the following result.
Theorem 6. Let and assume that for some suitable T. Then, Proof. By applying Theorem 2, we have that where and follows the Lipschitz condition of order . Therefore, by applying Theorems 3 and 4 and Lemma 1, we get that , and . With , we can say that . Therefore, , so an error bound of is finally given. □
From the above theorem, we can draw some conclusions, namely that the fractional part of plays a huge role in the overall convergence order. More specifically, as increases or the fractional part of decreases, the convergence order improves. This means that the convergence order no longer forms a monotonic function of but rather oscillates between 1 and 2 depending on . However, this theorem does show that under such smoothness properties, this method converges for all .
Theorem 7. Let and assume that for some suitable T. Then, for ,where C is a constant independent of j. From this, we can take the following corollary.
Corollary 2. Under the assumption of Theorem 7, we have, Moreover, for every , we have, Proof of Theorem 7. For this proof, we would be following that of Theorem 6. However, as
, we have that
, meaning that we can no longer apply Lemma 1. We will need to adapt the proof of this lemma in order to apply it to this case. To do so, we will retain the main structure of the proof and application of mathematical induction but will now change the induction hypothesis to that of (
39). With such a change in hypothesis, we must now find estimates for the terms
and
. By applying the Mean Value Theorem, it is known that
and
for
and
c is independent of
j and
k. Applying these bounds for the weights, we reduce the problem to finding bounds for the sum
. Looking back at Theorems 3 and 4, we have shown similar results, and it is easily shown that
when both the indices
and
are in the interval
. By applying this, we can complete this proof using structure of Lemma 1. □
3.3. Error Estimates with Smoothness Assumptions on the Given Data
In this final subsection, we will be looking at how changing the smoothness assumptions of the given function f can change the error and convergence order for this method. We will be looking at both when and when .
Theorem 8. Let . Then, with , Proof. We will split this proof into when
an when
. When
, we can adapt a result from Miller and Feldstein [
26] to apply here which shows that
. Then, given the smoothness assumpions on
f, and applying the chain rule,
. This then fulfills the conditions of Theorem 5, which gives the desired result.
Now, for when
, we wish to apply Lemma 1. To do this, we must find the constants
and
in the lemma. As in the case of our previous theorems, we must determine the behavior and smoothness of
y. We find this information by applying Theorem 1b, which tells us that
y is in the form,
As , this implies that . Similar to the case of , we can deduce . This then fulfills the conditions of Theorem 3a, giving us that and . Furthermore, we may apply Theorem 4a,c to find the remaining values such that and . By applying Lemma 1, the required result is achieved. □
4. Numerical Examples
In this section, we will be considering some numerical examples to confirm the theoretical results presented in the previous sections. We will be presenting examples below with as the applications for are not currently of interest. We will be solving the following examples for and . The following examples and graphs were created in blueMATLAB using the following algorithm.
Give an initial value .
Find
using (
11) and (
12) such that,
where,
Find
using (
8) and (
9) such that,
Repeat steps 2–3 to find .
Example 1 (
is smooth).
Consider the following nonlinear fractional differential equation, with ,where, This example has a nonlinear and non smooth
f. However, due to the form of this equation, it is well known that the solution
y is given as,
For
, we have that
; this fulfills the requirements for Theorem 5. As such, we can show the theorem holds for such an example. Let N be a positive integer and let
be the uniform mesh on the interval
. such that
for
and
. Therefore, we have by Theorem 5,
In
Table 1 and
Table 2, we can see the maximum absolute error and experimental order of convergence (EOC) for the predictor–corrector method at varying
and
N values. For our different
, we have chosen N values as
.The maximum absolute errors
were obtained as shown above with respect to N, and we calculate the experimental order of convergence or EOC as
As we can see, the EOCs for the above example follow that of Theorem 5.
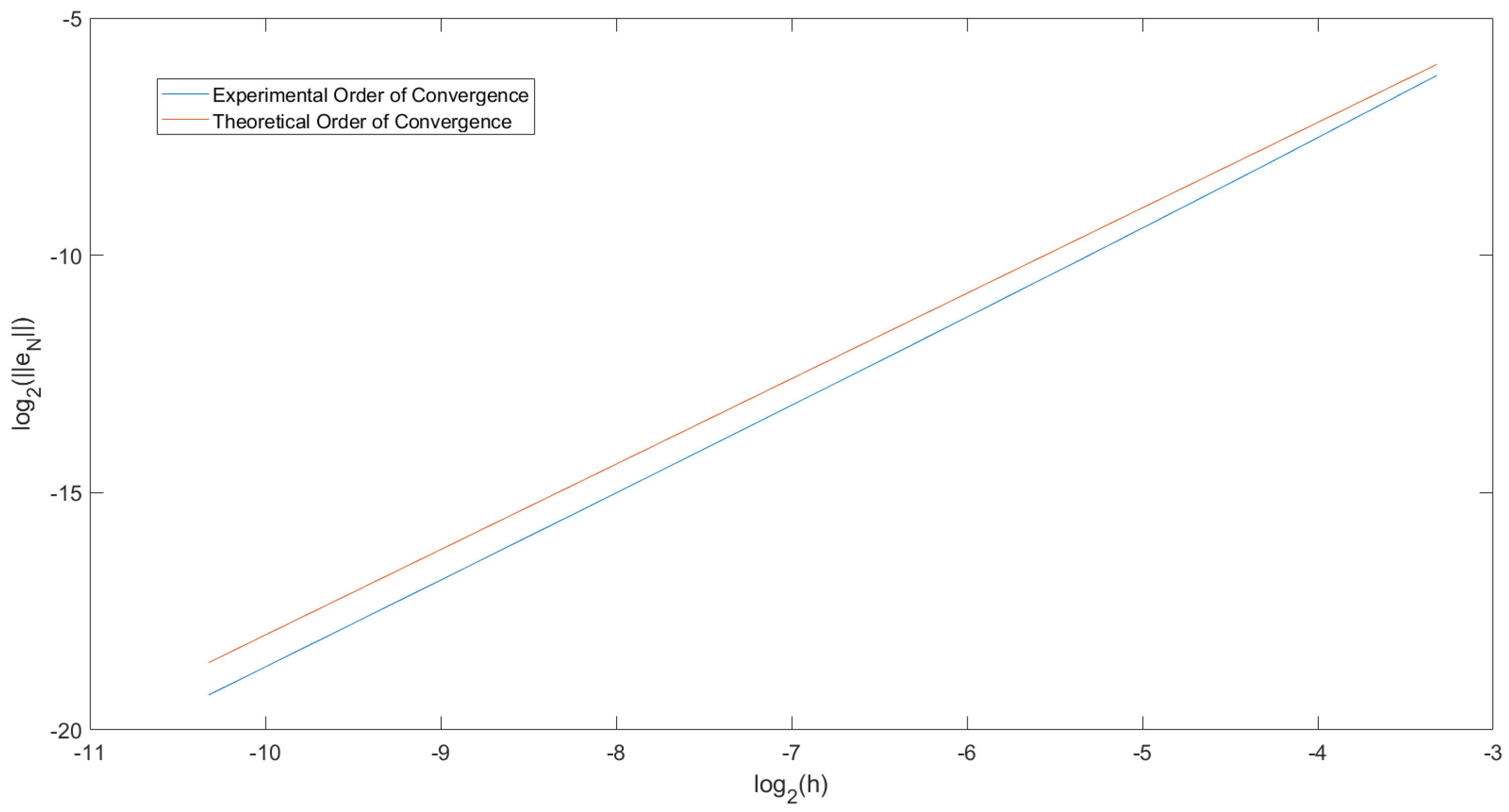
In
Figure 1, we have plotted the order of convergence for Example 1. From Equation (
51), we have for
,
We can now plot this graph such that
and let
and
. Doing this, we get that the gradient of the graph would equal the EOC. To compare this to the theoretical order of convergence, we have also plotted the straight line
. For
Figure 1, we use
. We can observe that the two lines drawn are parallel. Therefore, we can conclude that the order of convergence of this predictor–corrector method is
for when
. A similar result can be obtained for when
.
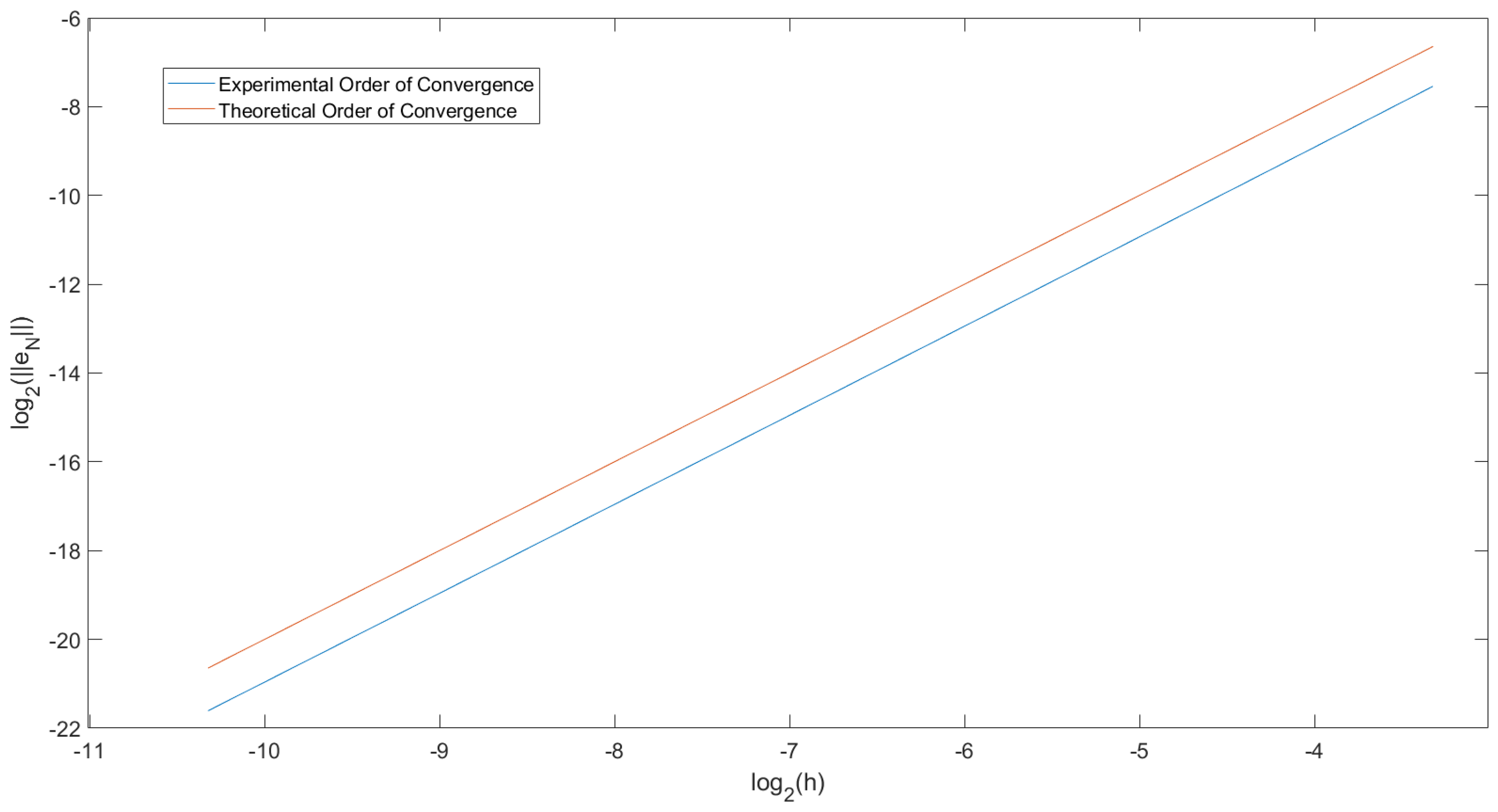
Figure 2 shows the same graph but for
. However, now we can see that the line is parallel to the straight line
, which is what we expected as the convergence order should tend to 2 for
.
Example 2 (
y is smooth).
Consider the following nonlinear fractional differential equation, with ,where, The exact solution of this equation is,
In
Table 3,
Table 4 and
Table 5, we can see the maximum absolute error and experimental order of convergence (EOC) for the predictor–corrector method at varying
and
N values. For our different
, we have chosen N values as
. As
we can apply Theorems 6 and 7 and more specifically, Corollary 2. As we can see, the EOCs for the above example verifies these theorems. When
, we find that the EOC is close to
and when
, we find that the EOC is close to
. Finally, when
, we have that the EOC is close to
.
Example 3 (
f is smooth).
Consider the following nonlinear fractional differential equation, with , The exact solution of this equation is
. Therefore,
, where
is defined as the Mittag–Leffler function,
Therefore,
f is smooth. As such, this equation fulfils the conditions of Theorem 8. In
Table 6 and
Table 7, we can see the maximum absolute error and experimental order of convergence (EOC) for the predictor–corrector method at varying
and
N values. For our different
, we have chosen N values as
. As
f is sufficiently smooth, we can apply Theorem 8. As we can see, the EOCs for the above example verifies these theorems. When
, we have that the EOC is close to
. For
, we have the EOC is close to 2.






{kind=link}
{kind=link}