1. Introduction
Copula representations and sample estimates of the correlation measures attributed to Spearman, Kendall, Blomqvist and Hoeffding are provided in this paper. All these measures of association depend on the ranks of the observations on each variable. They can reveal the strength of the dependence between two variables that are not necessarily linearly related, as is required in the case of Pearson’s correlation. They can as well be applied to ordinal data. While the Spearman, Kendall and Blomqvist measures of association are suitable for observations exhibiting monotonic relationships, Hoeffding’s index can also ascertain the extent of the dependence between the variables, regardless of the patterns that they may follow. Thus, these four measures of association prove quite versatile when it comes to assessing the strength of various types of relationships between variables. Moreover, since they are rank-based, they are all robust with respect to outliers. What is more, they can be readily evaluated.
Copulas are principally utilized for modeling dependency features in multivariate distributions. They enable one to represent the joint distribution of two or more random variables in terms of their marginal distributions and a specific correlation structure. Thus, the effect of the dependence between the variables can be separated from the contribution of each marginal. As measures of dependence, copulas have found applications in numerous fields of scientific investigations, including reliability theory, signal processing, geodesy, hydrology, finance and medicine. We now review certain basic definitions and results on the subject.
In the bivariate framework, a copula function is a distribution whose support is the unit square and whose marginals are uniformly distributed. A more formal definition is now provided.
A function is a bivariate copula if it satisfies the two following properties:
For every
such that
and
,
This last inequality implies that is increasing in both variables.
We now state a result due to Sklar (Theorem 1) [
1].
Theorem 1. Let be the joint cumulative distribution function of the random variables X and Y whose continuous marginal distribution functions are denoted by and . Then, there exists a unique bivariate copula such thatwhere is a joint cumulative distribution function having uniform marginals. Conversely, for any continuous cumulative distribution functions and and any copula , the function , as defined in (1), is a joint distribution function with marginal distribution functions and . Sklar’s theorem provides a technique for constructing copulas. Indeed, the function
is a bivariate copula, where the quasi-inverses
and
are defined by
and
Copulas are invariant with respect to strictly increasing transformations. More specifically, assuming that
X and
Y are two continuous random variables whose associated copula is
, and letting
and
be two strictly increasing functions and
be the copula obtained from
and
, then for all
one has
We shall denote the probability density function corresponding to the copula
by
The following relationship between
, the joint density function of the random variables
X and
Y as defined in Sklar’s theorem, and the associated copula density function
can then be readily obtained from Equation (
1) as
where
and
denote the marginal density functions of
X and
Y, respectively. Accordingly, a copula density function can be expressed as follows:
Now, given a random sample
generated from the continuous random vector
, let
where
and
are the usually unknown marginal cumulative distribution functions (cdfs) of
X and
Y. The empirical marginal cdfs
and
are then utilized to determine the
pseudo-observations:
where the empirical cdfs (ecdfs) are given by
and
, with
denoting the indicator function which is equal to one if the condition
ℵ is verified and zero, otherwise. Equivalently, one has
where
is the rank of
among
, and
is the rank of
among
.
The frequencies or probability mass function of an empirical copula can be expressed as
and the corresponding empirical copula (distribution function) is then given by
which is a consistent estimate of
. We note that, in practice, the ranks are often divided by
instead of
n in order to mitigate certain boundary effects, and that other adjustments that are specified in
Section 2 may also be applied. As pointed out by [
2], who refers to [
3], “Empirical copulas were introduced and first studied by Deheuvels who called them empirical dependence functions”.
Additional properties of copulas that are not directly relevant to the results presented in this article are discussed for instance in [
4,
5,
6].
This article contains certain derivations that do not seem to be available in the literature and also provides missing steps that complete the published proofs. It is structured as follows:
Section 2,
Section 3,
Section 4 and
Section 5, which, respectively, focus on Spearman’s, Kendall’s, Blomqvist’s and Hoeffding’s correlation coefficients, include representations of these measures of dependence in terms of copulas, in addition to providing sample estimates thereof and pointing out related distributional results of interest. The effectiveness of these correlation coefficients in assessing the trends present in five data sets exhibiting distinctive patterns is assessed in a numerical study that is presented in
Section 6.
Section 7 is dedicated to multivariate extensions of the four measures of association and their copula representations.
To the best of our knowledge, the four major dependence measures discussed here, along with their representations in terms of copulas, have not been previously covered in a single source.
2. Spearman’s Rank Correlation
Spearman’s rank correlation statistic, also referred to as Spearman’s , measures the extent to which the relationship between two variables is monotonic—either increasing or decreasing.
First, Spearman’s is expressed in terms of a copula denoted by . Then, some equivalent representations of Spearman’s rank correlation statistic are provided; one of them is obtained by replacing by its empirical counterpart.
Let be a bivariate continuous random vector having as its joint density function, and and denote the respective marginal distribution functions of X and Y.
Theoretically, Spearman’s correlation is given by
where
and
, respectively, denote the copula and copula density function associated with
, and
represents the set of real numbers. In [
7,
8], it is taken as a given that the double integral appearing in (
16) can be expressed as that appearing in (
17). We now prove that this is indeed the case. First, recall that
, the copula density function. On integrating by parts twice, one has
Now, let
be a random sample generated from the random vector
, and denote by
and
the respective empirical distribution functions of
X and
Y. Throughout this article, the sample size is assumed to be
n. On denoting by
and
, the rank of
among
and the rank of
among
, respectively, one has
and
, where
and
denote the canonical pseudo-observations on each component. Note that the rank averages
and
are both equal to
. Then, Spearman’s rank correlation estimator admits the following equivalent representations:
where
and
.
Of course, (24) readily follows from (
20), and it is seen from either one of these expressions that Spearman’s rank correlation is not be affected by any monotonic affine transformation, whether applied to the ranks or the canonical pseudo-observations. As pointed out for instance in [
9], the pseudo-observations are frequently taken to be
and
Alternatively, one can define the pseudo-observations so that they be uniformly—and less haphazardly—distributed over the unit interval as follows:
and
In a simulation study, Dias (2022) [
10] observed that such pseudo-observations have a lower bias than those obtained by dividing the ranks by
. What is more, it should be observed that if we extend the pseudo-observations
and
by
on each side and assign their respective probability, namely,
, to each of the
n resulting subintervals, the marginal distributions is then uniformly distributed within the interval
, which happens to be a requirement for a copula density function. However, this is not the case for any other affine transformation of the ranks. The alternative transformations
and
were also considered by [
10,
11], respectively. As established in [
10], the pseudo-observation estimators resulting from any of the above-mentioned transformations as well as the canonical pseudo-observations are consistent estimators of the underlying distribution functions.
Kojanovik and Yan (2010) [
7] pointed out that
, as specified in (21), can also be expressed as
where
is a consistent estimator of
.
Moreover, it can be algebraically shown that, alternatively,
when the ranks are distinct integers.
On writing (
17) as
and replacing
by
as defined in (
13), the double integral becomes
For instance, on integrating the first integral by parts, one has
Thus, the resulting estimator of Spearman’s rank correlation is given by
which is approximately equal to that given in (
29).
Now, letting
be a copula whose functional representation is known, and assuming that it is a one-to-one function of the dependence parameter
, it follows from (
17) that
which provides an indication of the extent to which the variables are monotonically related. Moreover, since
, as defined in (21), (
29) or (
30), tends to
,
can serve as an estimate of
.
It follows from (
17) that Spearman’s
can be expressed as
On replacing
in (
33) by
, one obtains a measure based on the
distance between the copula
C and the product copula
( [
5]). This is the so-called Schweizer–Wolff’s sigma as defined in [
12], which is given by
The expression (
34) is a measure of dependence which satisfies the properties of Rényi’s axioms [
13] for measures of dependence [
12], [
14] (p. 145).
Note that Pearson’s correlation coefficient,
only measures the strength of a
linear relationship between
X and
Y, whereas Spearman’s rank correlation
assesses the strength of
any monotonic relationship between
X and
Y. The latter is always well-defined, which is not the case for the former. Both vary between
and 1 and
indicates that
Y is either an increasing or a decreasing function of
X. Moreover, it should be noted that Pearson’s correlation coefficient cannot be expressed in terms of copulas since its estimator is a function of the observations themselves rather than their ranks.
The next three sections include results that were gleaned from the following books among others: [
4,
5,
15,
16].
3. Kendall’s Rank Correlation Coefficient
Kendall’s
, also referred to as Kendall’s rank correlation coefficient, was introduced by [
17]. Maurice Kendall also proposed an estimate thereof and published several papers as well as a monograph in connection with certain ordinal measures of correlation. Further historical details are available from [
18].
Kendall’s is a nonparametric measure of association between two variables, which is based on the number of concordant pairs minus the number of discordant pairs. Consider two observations and with such that , that are generated from a vector of continuous random variables. Then, for any such assignment of pairs, define each pair as being concordant, discordant or equal, as follows:
- ○
and are concordant if
, or equivalently
, i.e., the slope of the line connecting the two points is positive.
- ○
and are discordant if
, or equivalently
, i.e., the slope of the line connecting the two points is negative.
- ○
are equal if . Actually, pair equality can be disregarded as the random variables X and Y are assumed to be continuous.
3.1. The Empirical Kendall’s τ
Let be a random sample of n pairs arising from the vector of continuous random variables. There are possible ways of selecting distinct pairs and of observations in the sample, with each pair being either concordant or discordant.
Let
be defined as follows:
where
Then, the values that
can take on are
Kendall’s sample
is defined as follows:
Alternatively, on letting
c denote the number of concordant pairs and
d the number of discordant pairs in a given sample of size
n, one can express the estimate of Kendall’s
as
As it is assumed that there can be no equality between pairs,
, so that
In fact,
is an unbiased estimator of
. As well, Kendall and Gibbons (1990) [
19] (Chapter 5) established that Var
. A coefficient related to that specified in (
39) was discussed in [
20,
21,
22] in the context of double time series.
3.2. The Population Kendall’s τ
Letting
and
be independent and identically distributed random vectors, with the joint distribution function of
being
,
and
denote the respective distribution functions of
and
,
and the associated copula be
, the population Kendall’s
is defined as follows:
where
have a Uniform distribution, their joint cdf being ;
and ;
;
.
Clearly, (41) follows from (
40) since
We now state Theorem 5.1.1 from [
5]:
Theorem 2. Let and be independent vectors of continuous random variables with joint distributions functions and , respectively, with common marginals and . Let and be the copulas of and , respectively, so that and . LetThen, If
X and
Y are continuous random variables whose copula is
C, then Equation (44) follows from (
40), (46) and (47).
3.3. Marginal Probability of Sij
The marginal probability of
is
Gibbons and Chakraborti (2003) [
15] proved that
3.4. Certain Properties of
- ○
The correlation coefficient is invariant with respect to strictly increasing transformations.
- ○
If
and
are independent, then the value of
is zero:
- ○
Kendall’s takes on values in the interval .
- ○
As stated in [
4], when the number of discordant pairs is 0, the value of
is maximum and equals 1, which means a perfect relationship; the variables are then comonotonic, i.e., one variable is an increasing transform of the other; if the variables are countermonotonic, i.e., one variable is a decreasing transform of the other, the correlation coefficient
equals
. Note that these two properties do not hold for Pearson’s correlation coefficient. Moreover, it proves more appropriate to make use of Kendall’s
when the joint distribution is not Gaussian.
4. Blomqvist’s Correlation Coefficient
Blomqvist (1950) [
23] proposed a measure of dependence that was similar in its structure to Kendall’s correlation coefficient, except that in this instance, medians were utilized. Blomqvist’s correlation coefficient can be defined as follows:
where
and
are the respective medians of
X and
Y, which explains why this coefficient is also known as the median correlation coefficient.
Now, letting
X and
Y be continuous random variables whose joint cdf is
,
and
denote the respective marginal cdfs, and
be the associated copula, then,
and
In the development of these equations, the following relationships were utilized in addition to
:
4.1. Estimation of β
Let and be the respective medians of the samples and . The computation of Blomqvist’s correlation coefficient is based on a contingency table that is constructed from these two samples.
According to Blomqvist’s suggestion, the -plane is divided into four regions by drawing the lines and . Let and be the number of points belonging to the first or third quadrant and to the second or fourth quadrant, respectively.
Blomqvist’s sample
or the median correlation coefficient is defined by
If the sample size n is even, then clearly, no sample points fall on the lines and . Moreover, and are then both even. However, if n is odd, then one or two sample points must fall on the lines and . In the first case (a single point lying on a median), Blomqvist proposed that this point shall not be counted. For the second case, one point has to fall on each line; then, one of the points is assigned to the quadrant touched by both points, while the other is not counted.
Genest et al. (2013) [
24] provided an accurate interpretation of
as “the difference between the proportion of sample points having both components either smaller or greater than their respective medians, and the proportion of the other sample points”. Finally, as pointed out by [
23], the definition of
as given in (55) was not new [
25]; however, its statistical properties had not been previously fully investigated.
4.2. Some Properties of Blomqvist’s Correlation Coefficient
- ○
The coefficient is invariant under strictly increasing transformations of X and Y.
- ○
The correlation coefficient takes on values in the interval .
- ○
If X and Y are independent, then , and
5. Hoeffding’s Dependence Index
To measure the strength of relationships that are not necessarily monotonic, one may make use of Hoeffding’s dependence coefficient. Letting
denote the joint distribution function of
X and
Y, and
and
stand for the marginal distribution functions of
X and
Hoeffding’s nonparametric rank statistic for testing bivariate independence is based on
which is equal to zero if and only if
X and
Y are independently distributed.
The nonparametric estimator of the quantity
results in the statistic
where
and
with
and
representing the rank of
among
and the rank of
among
, respectively, and
denoting the number of bivariate observations
for which
and
.
We now state Hoeffding’s Lemma [
26]:
Let X and Y be random variables with joint distribution function and marginal distributions and . If and are finite, then This result became known when it was cited by [
27]. Refs. [
28,
29] discussed multivariate versions of this lemma.
The correlation coefficient is thus given by
or
with (63) resulting from Sklar’s theorem.
Invoking Hoeffding’s lemma, Hofert et al. (2019) [
16] (p. 47) pointed out two fallacies about the uniqueness and independence of random variables. Hoeffding appealed to his lemma to identify the bivariate distributions with given marginal distribution functions
and
, which minimize or maximize the correlation between
X and
Y.
Hoeffding’s Φ2
Hoeffding (1940) [
26] defined the stochastic dependence index of the random variables
X and
Y as
where
Hoeffding (1940) [
26] showed that
takes the value one in the cases of monotonically increasing and monotonically decreasing continuous functional dependence; it is otherwise less than one and greater than zero.
Let
be a simple random sample generated from the two-dimensional random vector
whose distribution function and copula are denoted by
and
, respectively, and assumed to be unknown. The copula
C is then estimated by the empirical copula
, which is defined as
with the pseudo-observations
and
. Since
(rank of
in
), statistical inference is based on the ranks of the observations.
A nonparametric estimator of
is then obtained by replacing the copula
in (64) by the empirical copula
, i.e.,
where
denotes the independence copula.
As explained in [
30], this estimator can be evaluated as follows:
The asymptotic distribution of
can be deduced from the asymptotic behavior of the empirical copula process which, for instance, has been discussed by [
31,
32,
33].
The quantity
was introduced by [
34] without the normalizing factor 90, as a distribution-free statistic for testing the independence of
X and
Y.
Referring to [
12], Nelsen (2006) [
5] (p. 210) states that “… any
distance should yield a symmetric nonparametric measure of dependence”. For any
, the
distance between the copula
and the product copula
is given by the following expression:
where
is the normalizing factor. On letting
, one obtains
.
6. Illustrative Examples
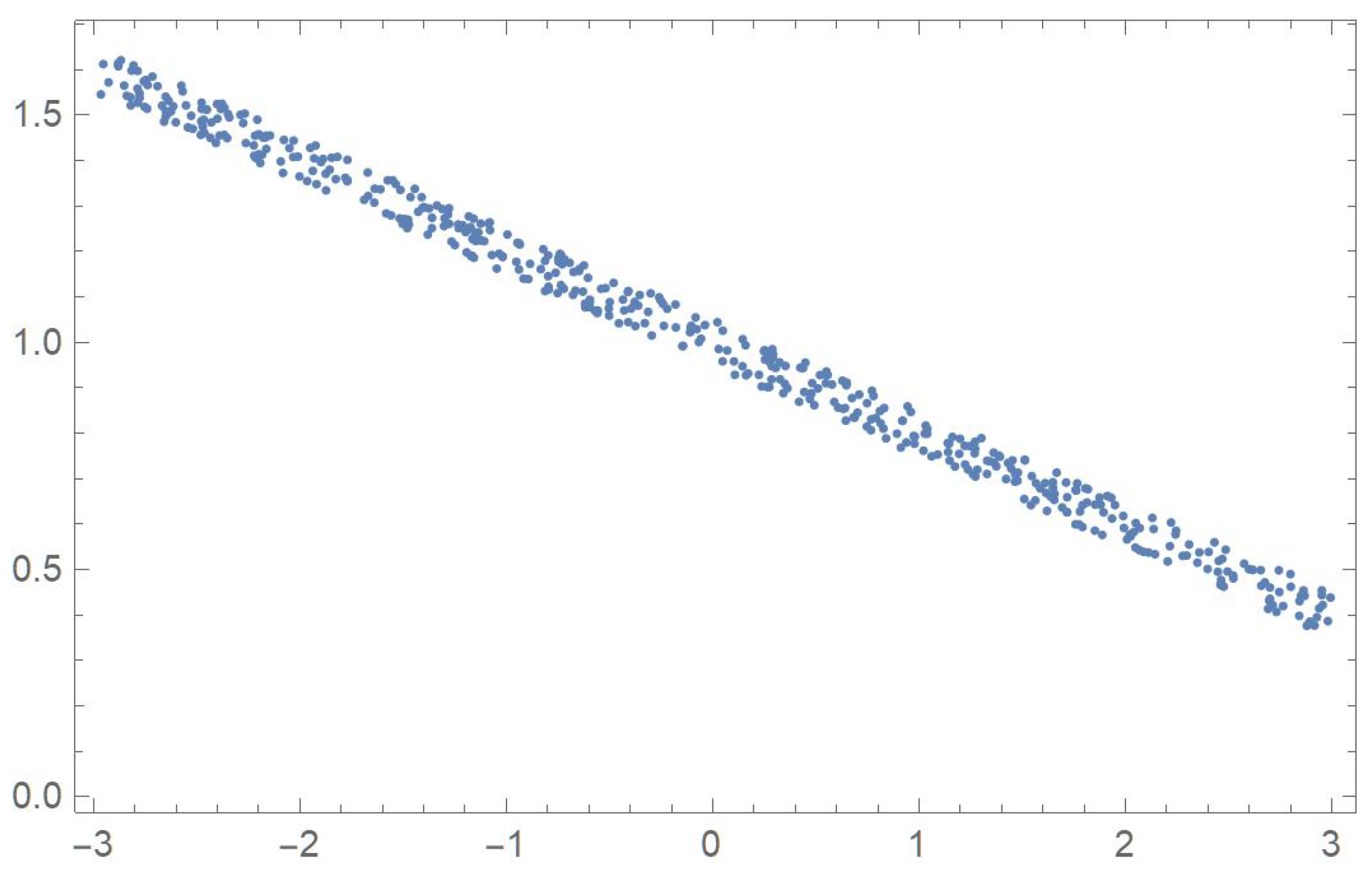
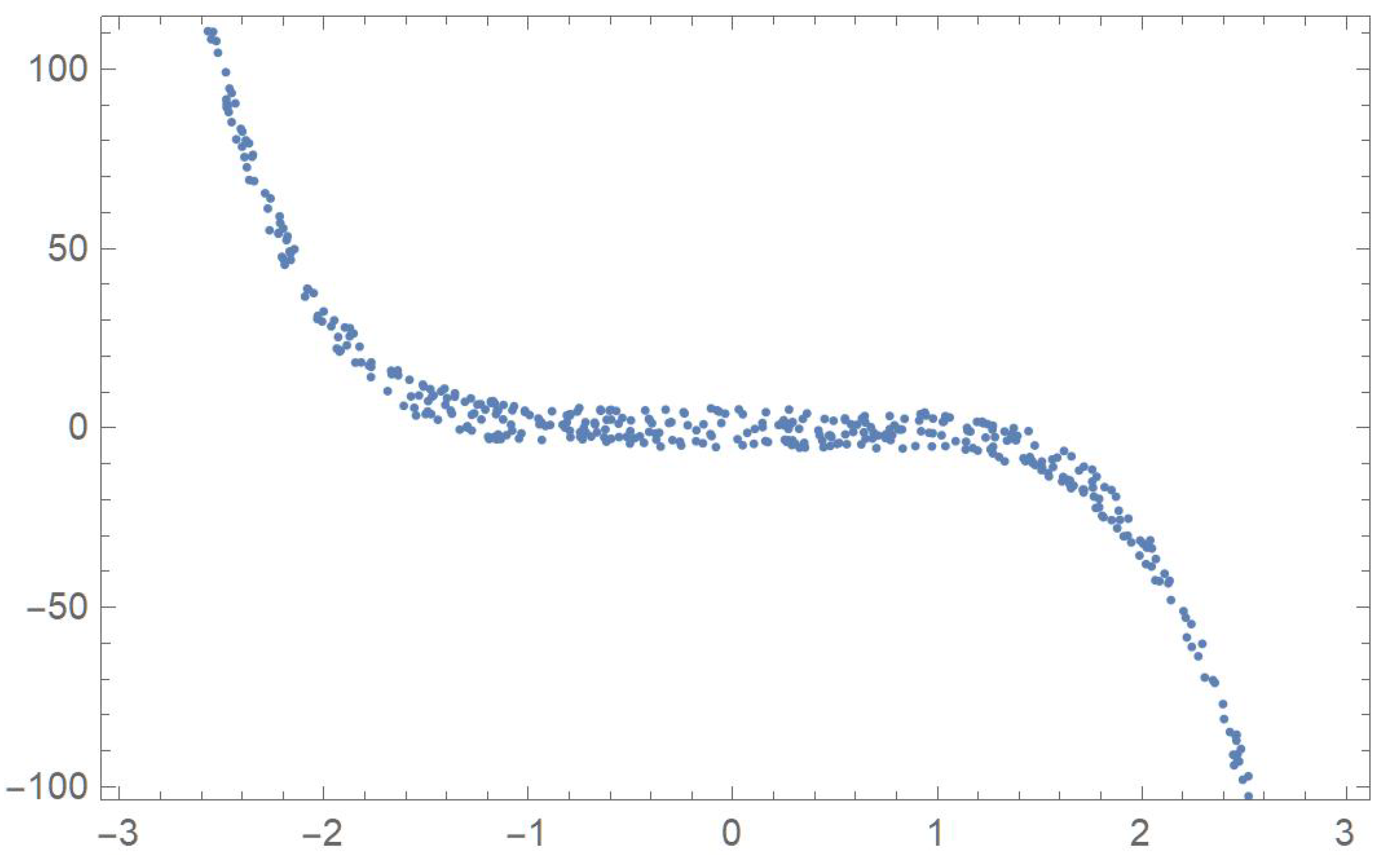
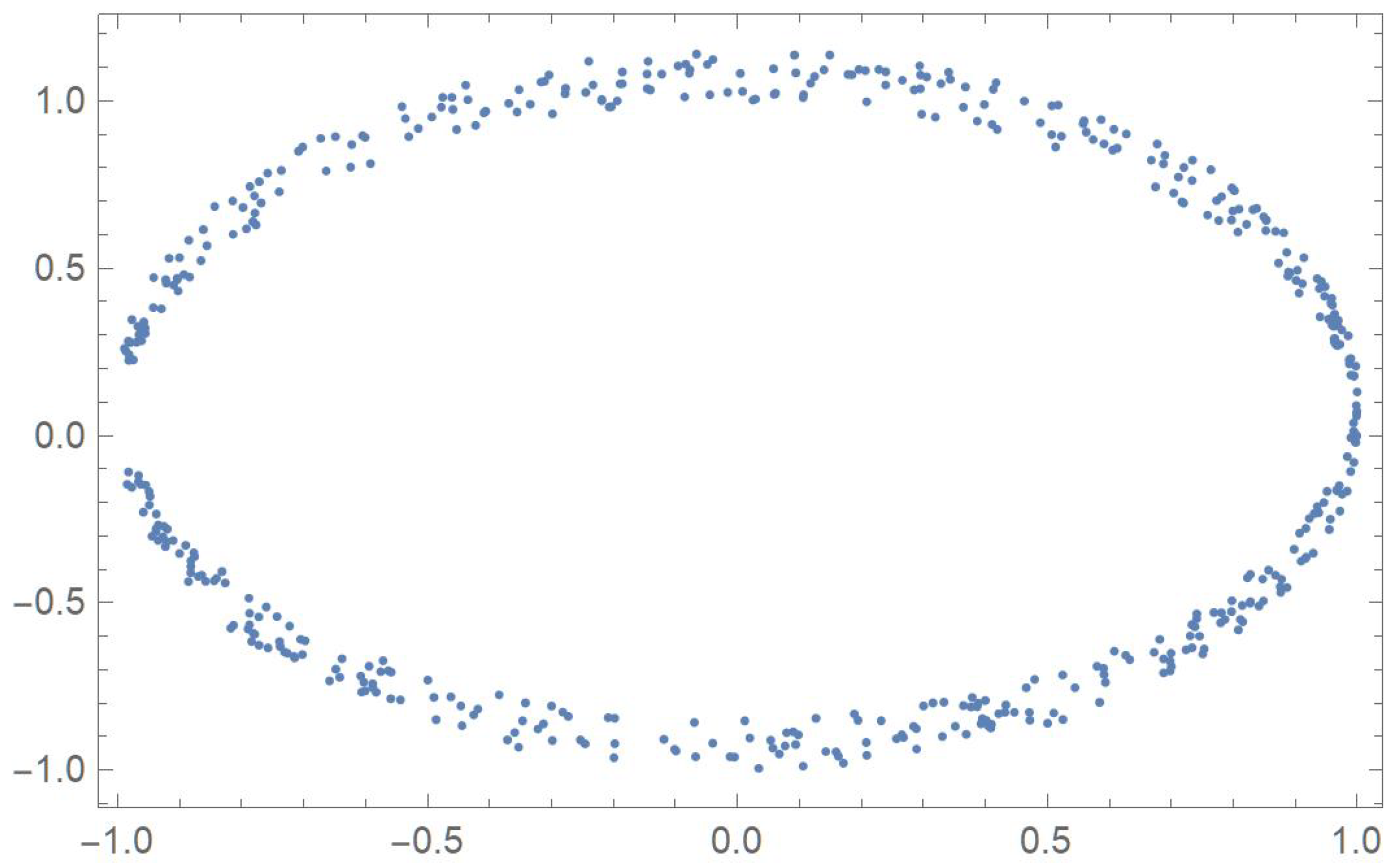
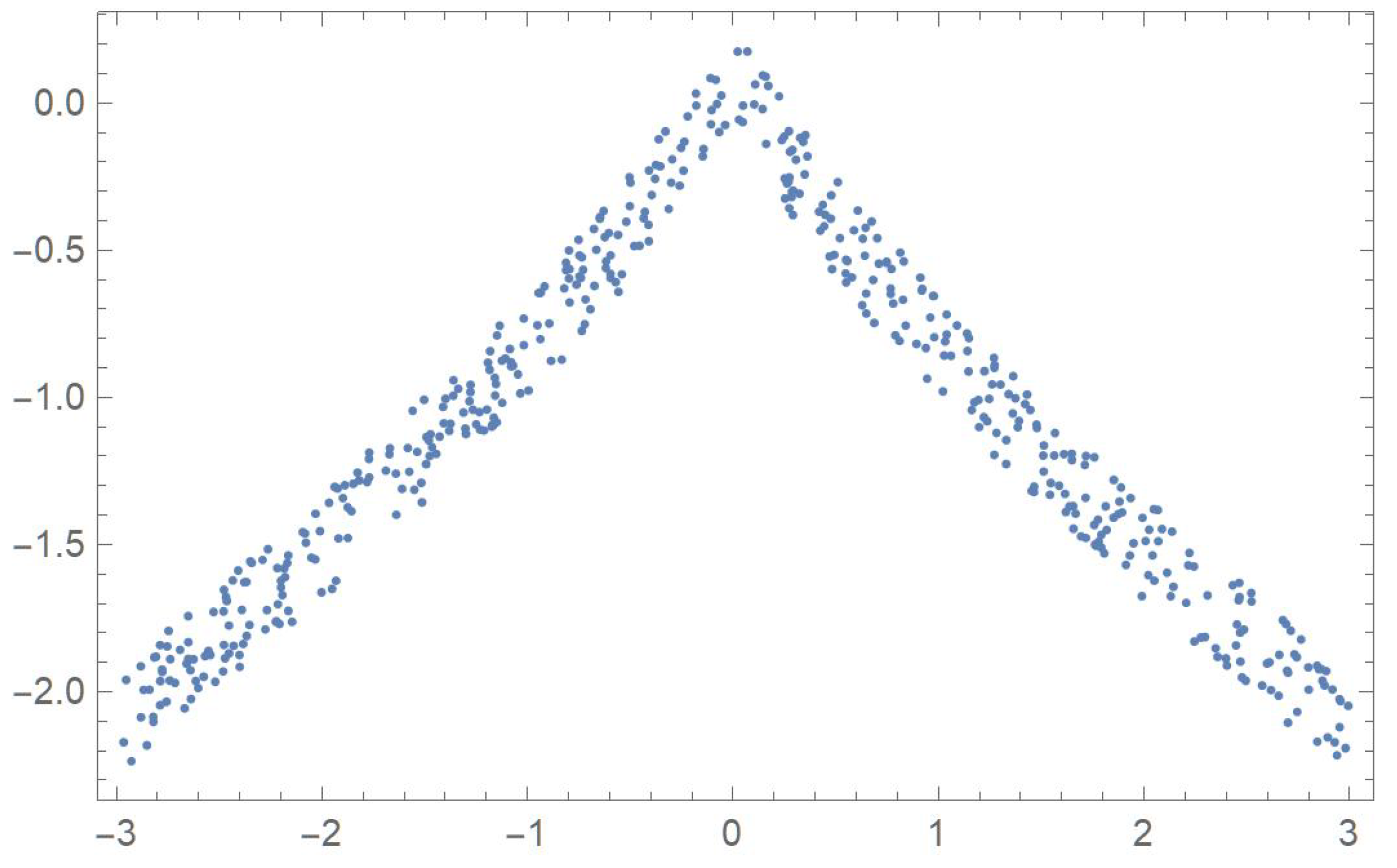
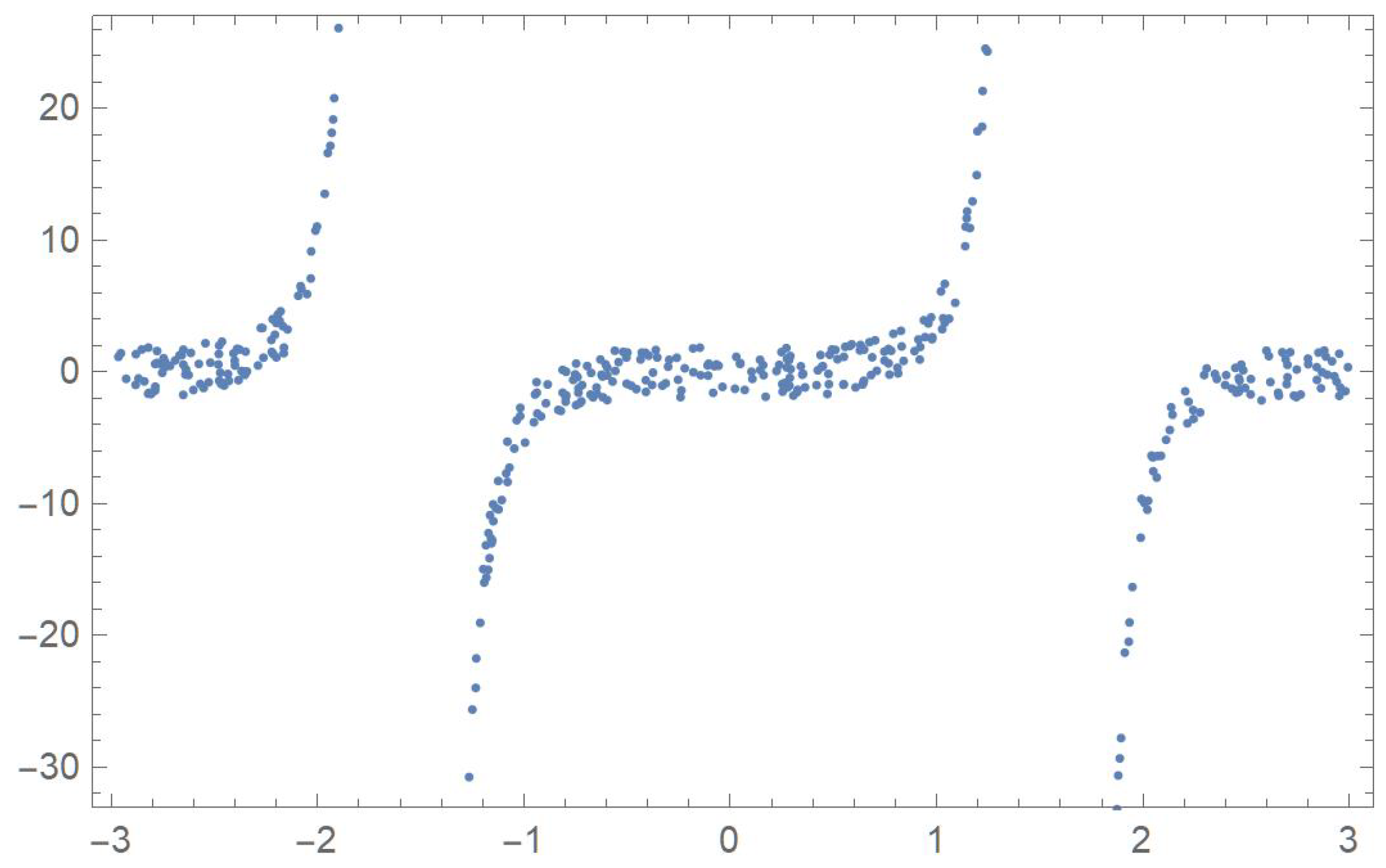
In order to compare the measures of association discussed in the previous sections, five two-dimensional data sets exhibiting different patterns that will be identified by the letters A, B, C, D and E, are considered. The first one was linearly decreasing, in which case Pearson’s correlation ought to be the most appropriate coefficient. The strictly monotonic pattern of the second set ought to be readily detected by Spearman’s, Kendall’s and Blomqvist’s coefficients, whose performance is assessed when applied to the fourth pattern, which happens to be piecewise monotonic. In the case of patterns C and E, whose points exhibit distinctive patterns, Hoeffding’s measure of dependence is expected to be more suitable than any of the other measures of association.
First, 500 random values of x, denoted by , were generated within the interval . Now, let
,
,
,
and
where
represents a slight perturbation consisting of a multiple of random values generated from a uniform distribution on the interval
. The five resulting data sets,
,
,
,
and
are plotted in
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5.
We then evaluated Spearman’s, Kendall’s, Blomqvist’s and Hoeffding’s statistics, as well as Pearson’s sample correlation coefficient for each data set. Their numerical values and associated
p-values are reported in
Table 1.
Hoeffding’s statistic strongly rejects the null hypothesis of independence since the p-values are all virtually equal to zero. This correctly indicates that, in all five cases, the variables are functionally related.
As anticipated, Pearson’s correlation coefficient is larger in absolute value in the case of a linear relationship (data set A) with a value of than in the case of a monotonic relationship (data set B) with a value of .
Spearman’s, Kendall’s and Blomqvist’s statistics readily detect the monotonic relationships that data sets A and B exhibit. Interestingly, in the case of data set D, which happens to be monotonically increasing and then decreasing, at the 5% significance level, both Spearman’s and Kendall’s statistics manage to reject the independence assumption.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}