

Initial-Value vs. Model-Induced Forecast Error: A New Perspective




Abstract
:1. Introduction
2. Skill and Scale
2.1. Error and Skill
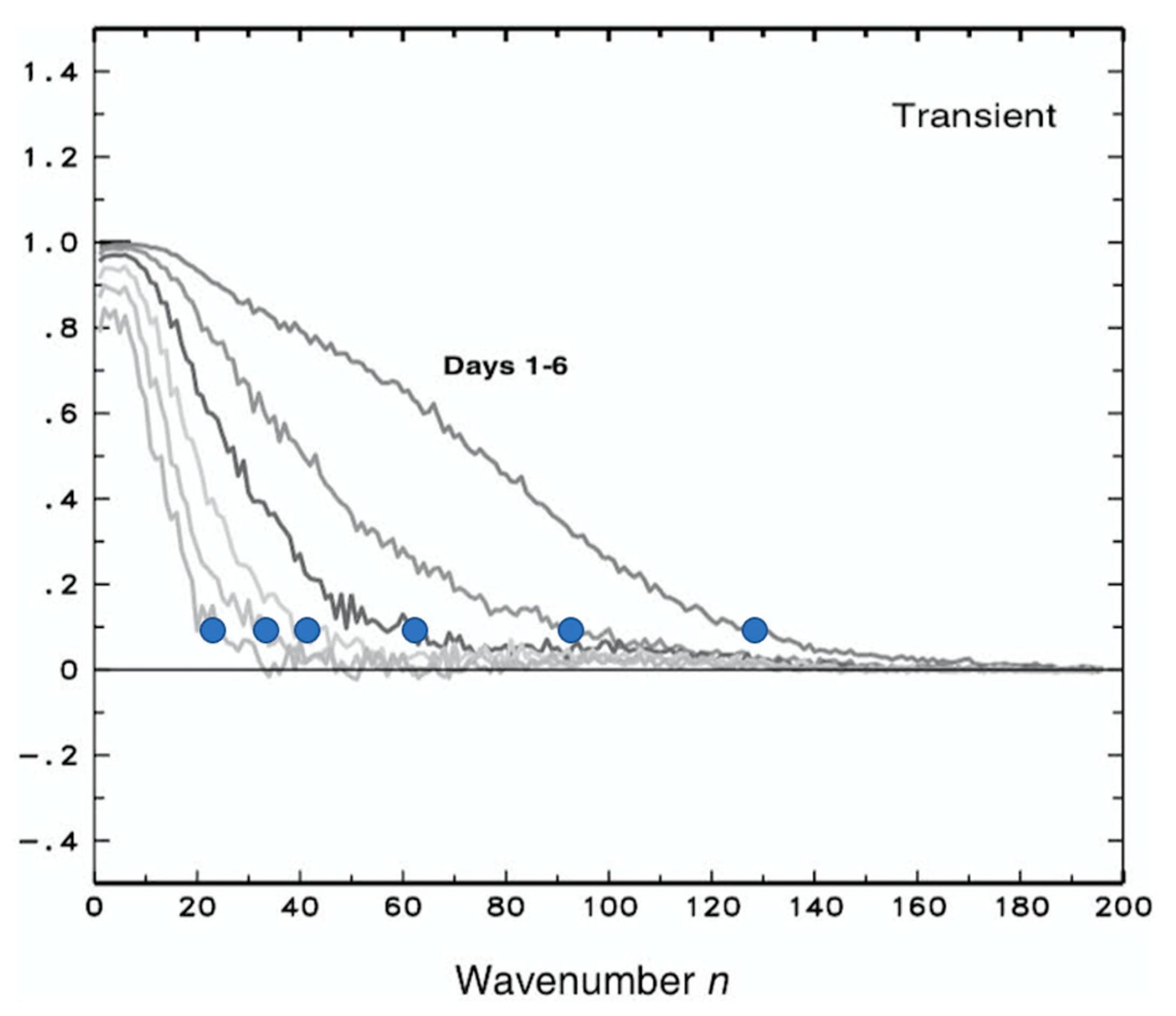
2.2. Loss of Skill as a Function of the Scale
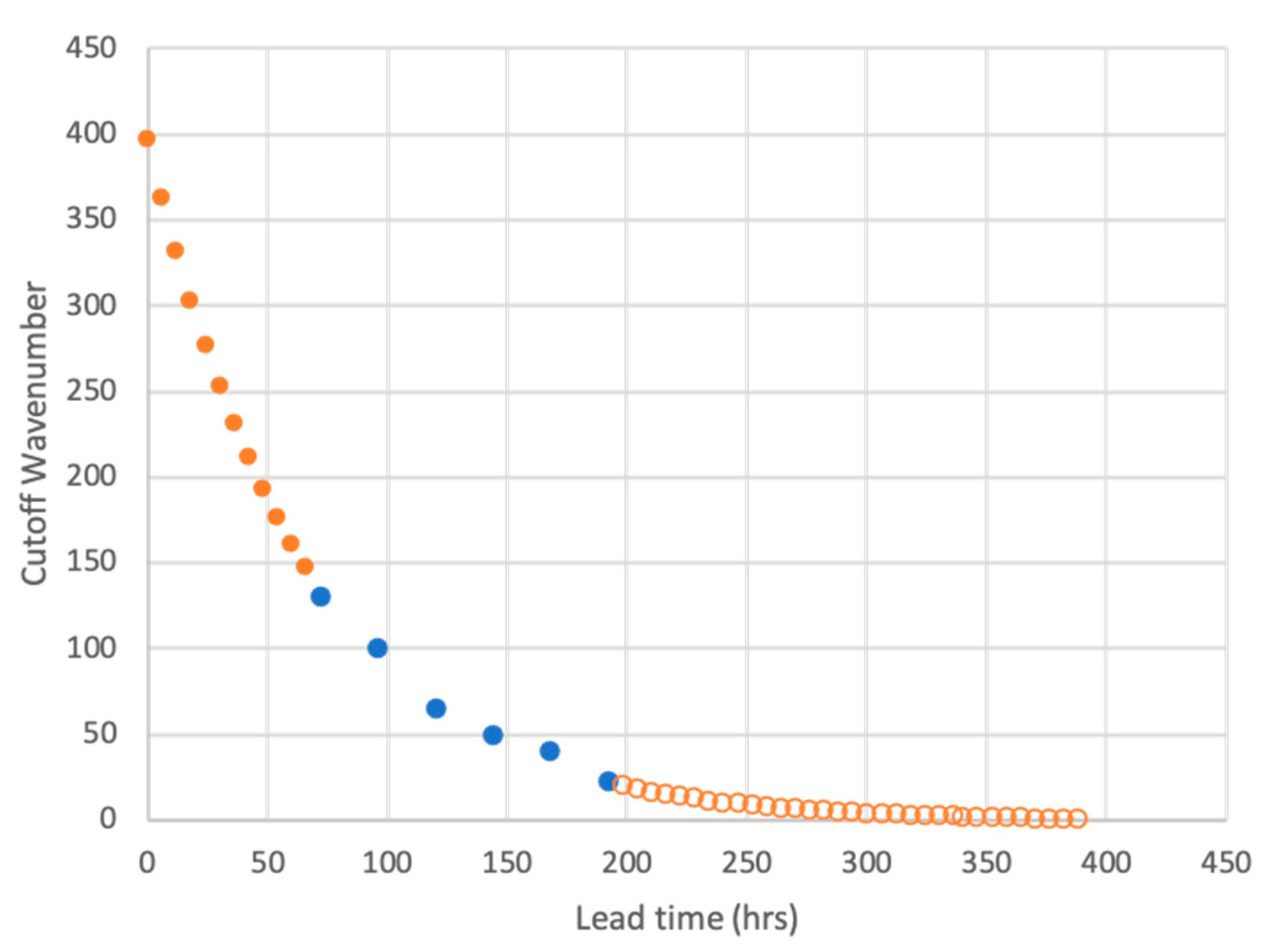
2.3. Quantitative Estimate
3. Approach
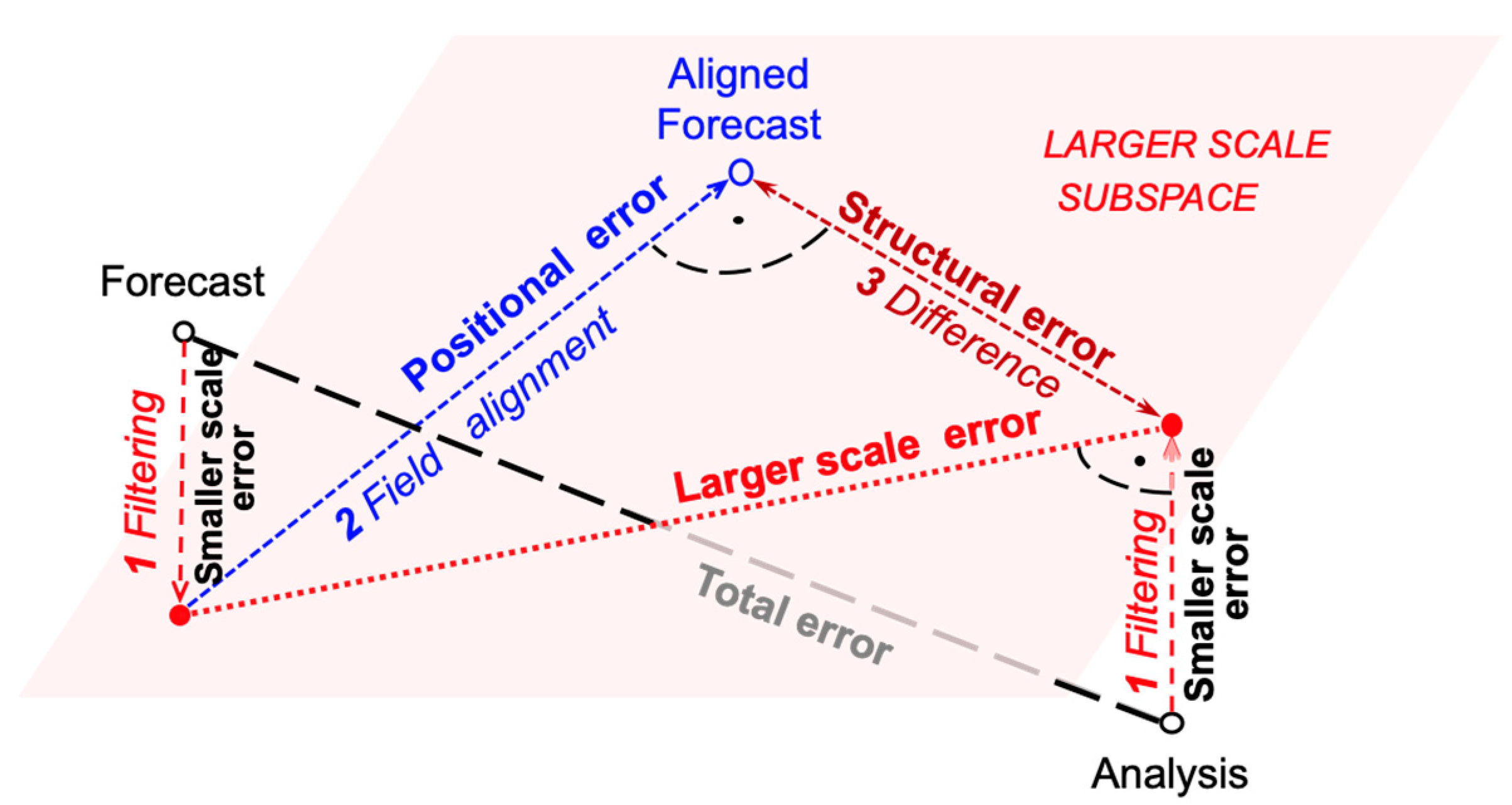
3.1. The Concept of Error Decomposition
3.2. Experimental Data
3.3. Methodology
4. Decomposition of Error and Perturbation Variances
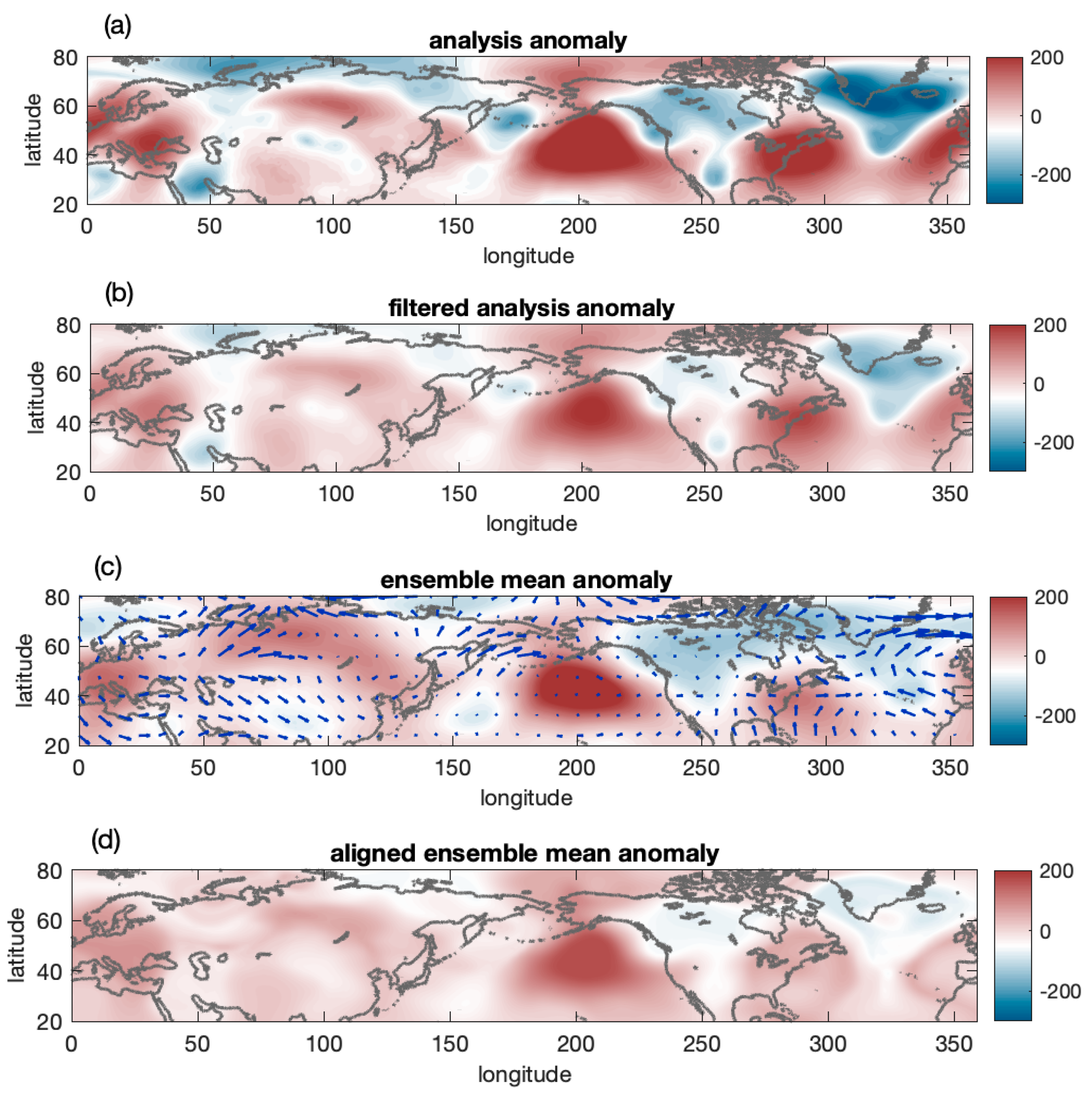
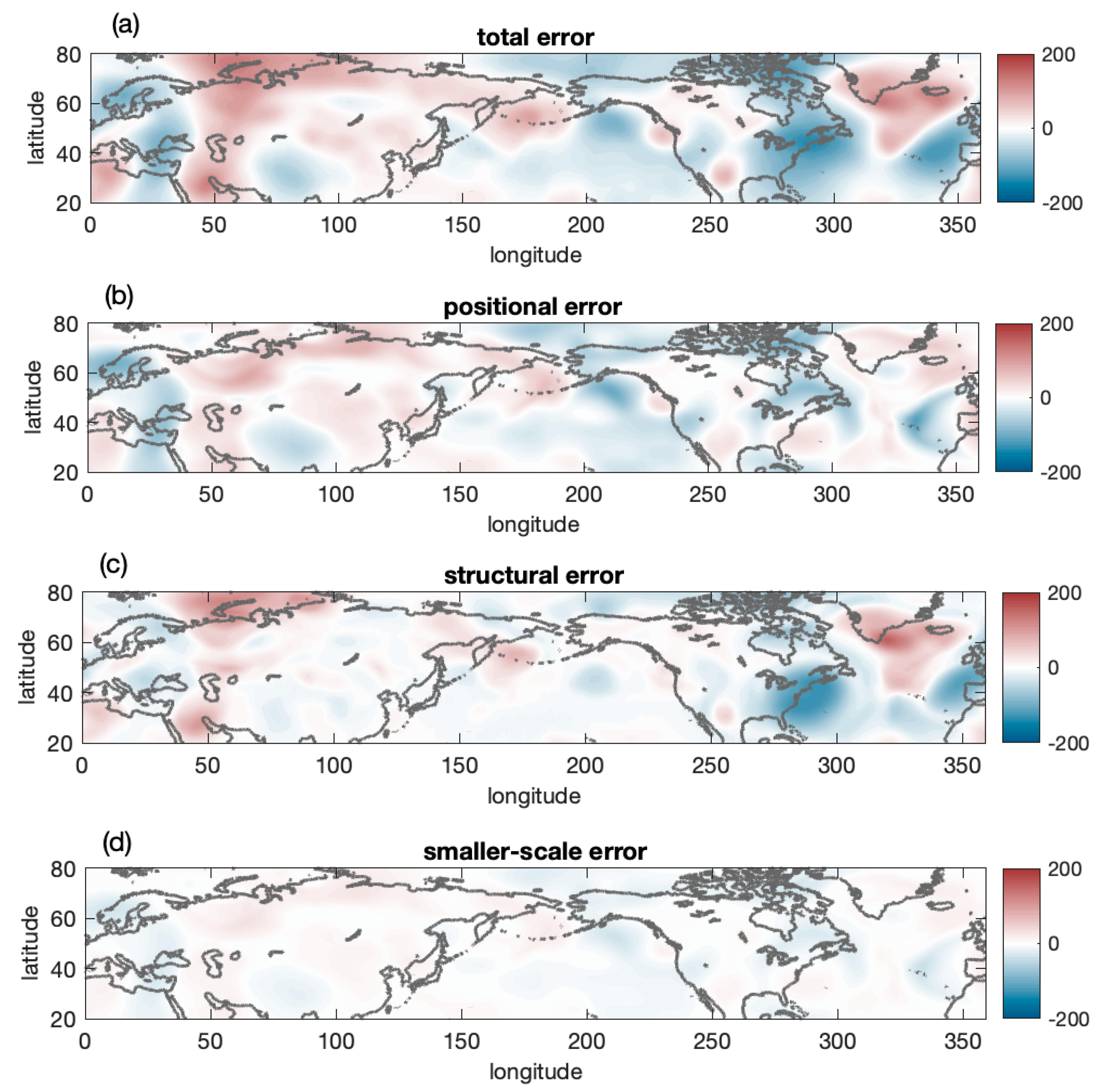
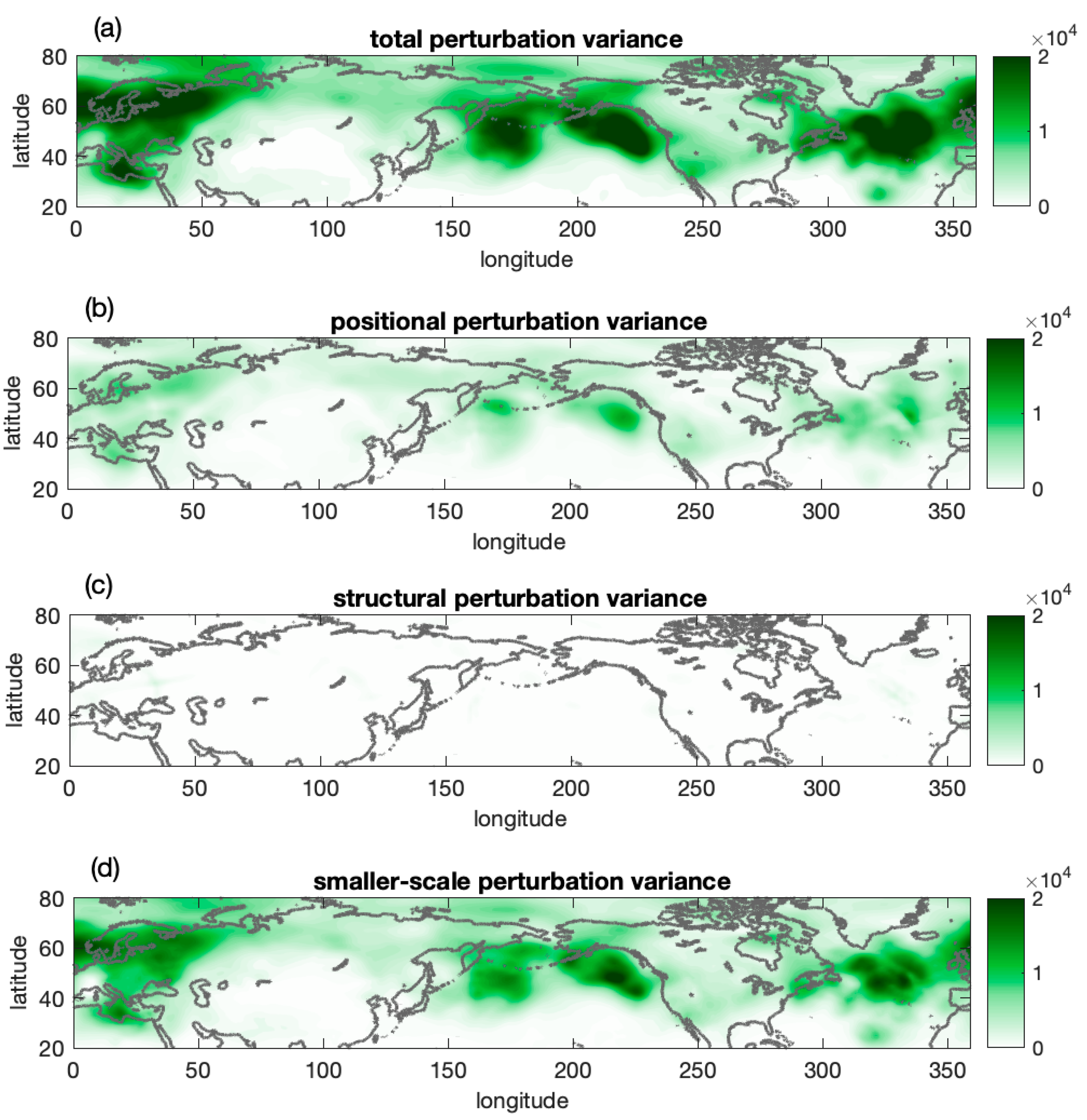
4.1. An Example
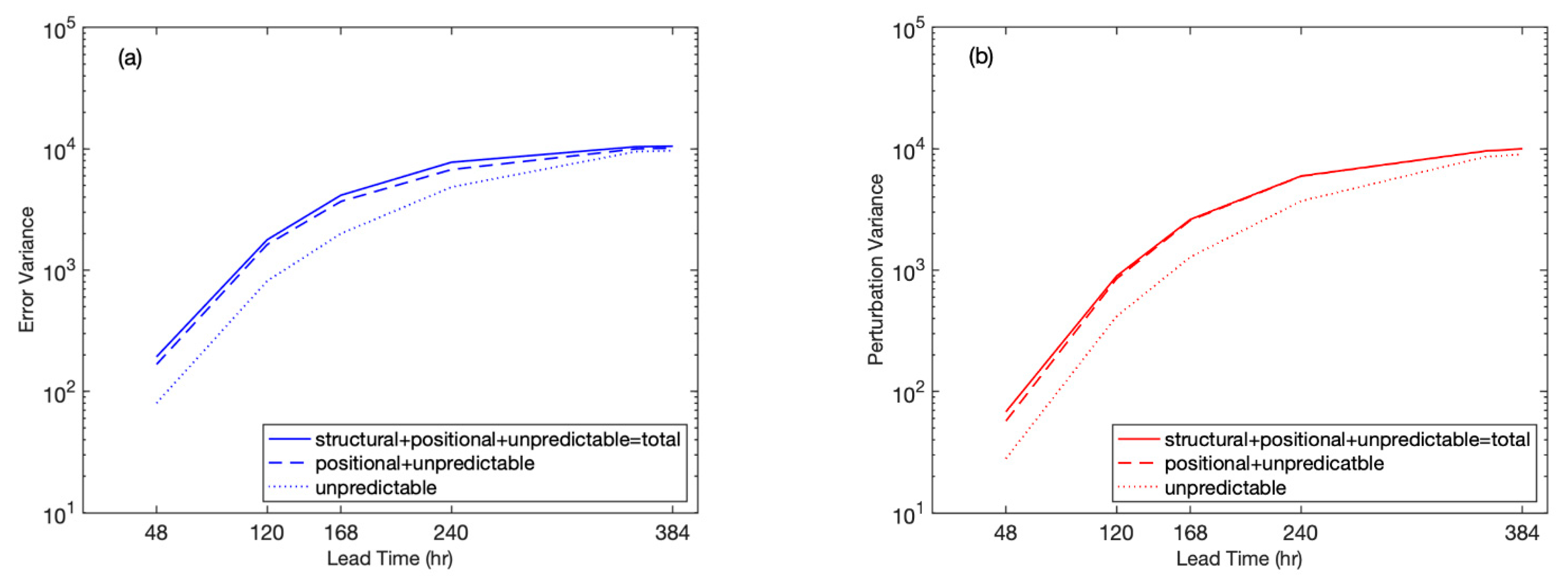
4.2. Statistics
4.2.1. Total and Scale Dependent Variances
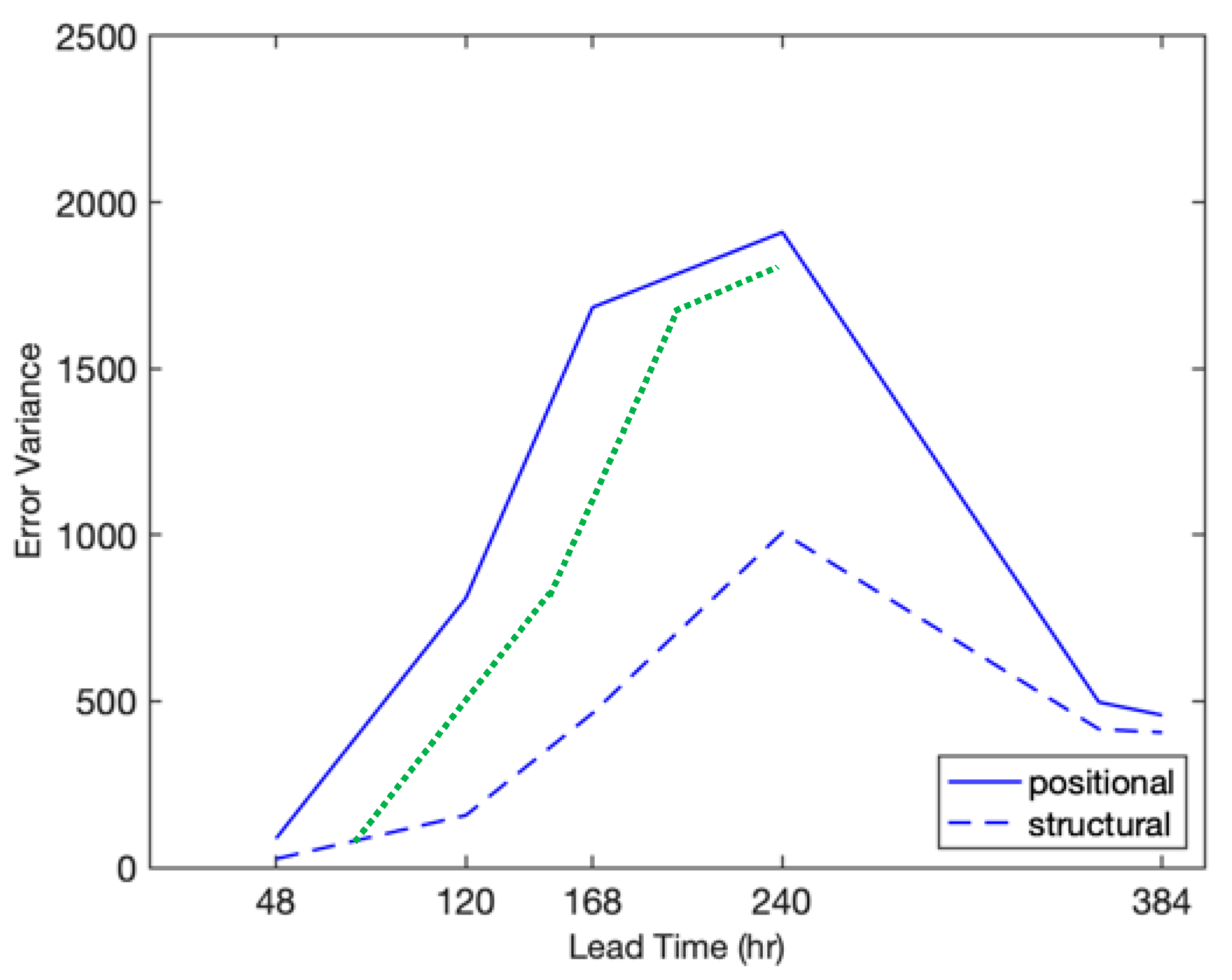
4.2.2. Positional and Structural Variances
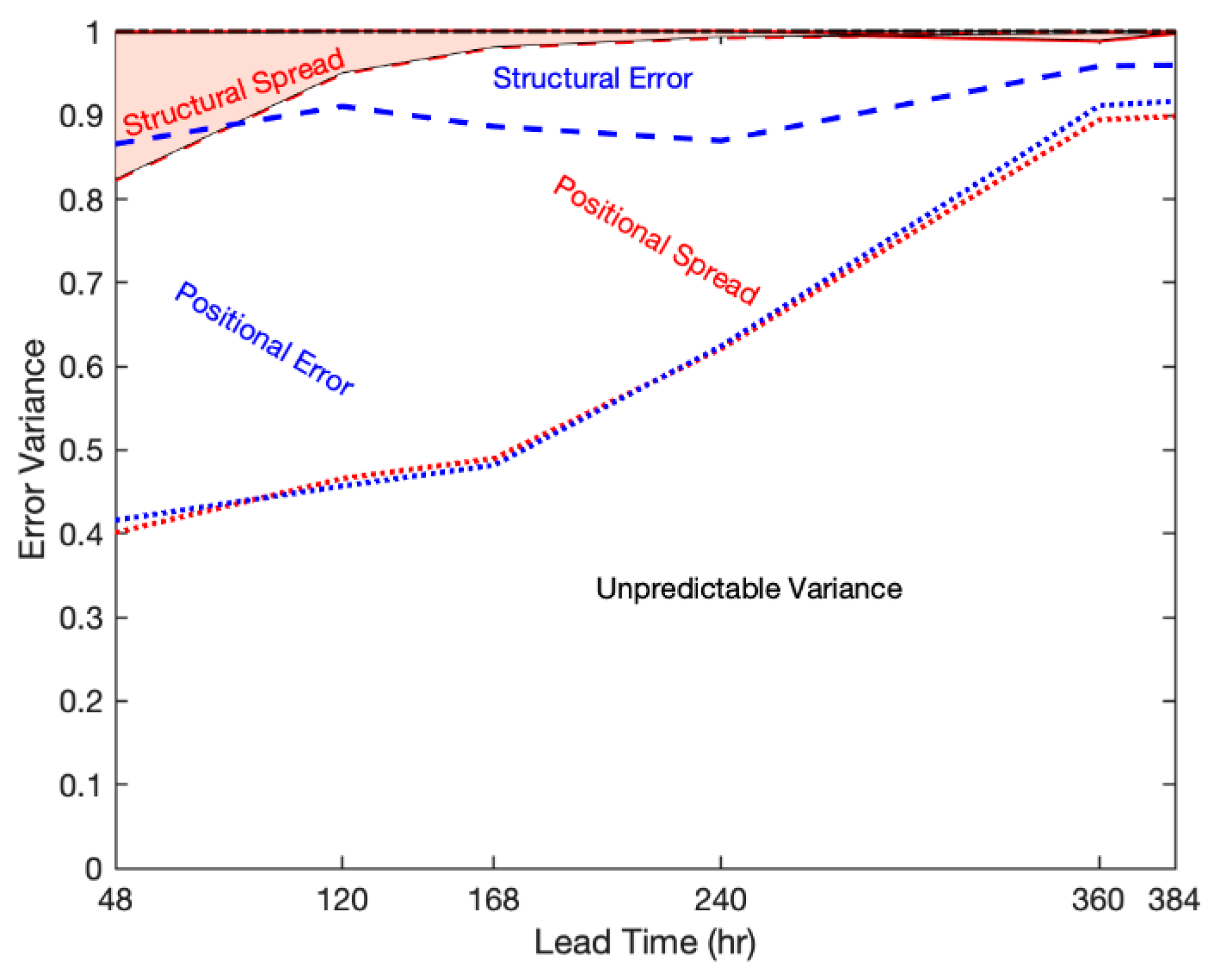
5. Interpretation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Buizza, R.; Houtekamer, P.L.; Pellerin, G.; Toth, Z.; Zhu, Y.; Wei, M. A comparison of the ECMWF, MSC, and NCEP global ensemble prediction systems. Mon. Weather Rev. 2005, 133, 1076–1097. [Google Scholar] [CrossRef]
- Duan, W.; Liu, X.; Zhu, K.; Mu, M. Exploring the initial errors that cause a significant “spring predictability barrier” for El Niño events. J. Geophys. Res. Ocean. 2009, 114, C04022. [Google Scholar] [CrossRef]
- Grams, C.M.; Magnusson, L.; Madonna, E. An atmospheric dynamics perspective on the amplification and propagation of forecast error in numerical weather prediction models: A case study. Q. J. R. Meteorol. Soc. 2018, 144, 2577–2591. [Google Scholar] [CrossRef]
- Houtekamer, P.L.; Mitchell, H.L. Data assimilation using an ensemble Kalman filter technique. Mon. Weather Rev. 1998, 126, 796–811. [Google Scholar] [CrossRef]
- Molteni, F.; Buizza, R.; Palmer, T.N.; Petroliagis, T. The ECMWF ensemble prediction system: Methodology and validation. Q. J. R. Meteorol. Soc. 1996, 122, 73–119. [Google Scholar] [CrossRef]
- Toth, Z.; Kalnay, E. Ensemble forecasting at NCEP and the breeding method. Mon. Weather Rev. 1997, 125, 3297–3319. [Google Scholar] [CrossRef]
- Buizza, R.; Milleer, M.; Palmer, T.N. Stochastic representation of model uncertainties in the ECMWF ensemble prediction system. Q. J. R. Meteorol. Soc. 1999, 125, 2887–2908. [Google Scholar] [CrossRef]
- Palmer, T.N.; Buizza, R.; Doblas-Reyes, F.; Jung, T.; Leutbecher, M.; Shutts, G.J.; Steinheimer, M.; Weisheimer, A. Stochastic Parametrization and Model Uncertainty; European Centre for Medium-Range Weather Forecasts: Reading, UK, 2009. [Google Scholar]
- Shutts, G. A kinetic energy backscatter algorithm for use in ensemble prediction systems. Q. J. R. Meteorol. Soc. 2005, 131, 3079–3102. [Google Scholar] [CrossRef]
- Craig, G.; Forbes, R.M.; Abdalla, S.; Balsamo, G.; Bechtold, P.; Berner, J.; Buizza, R.; Pallares, A.C.; De Meutter, P.; Düben, P.D.; et al. What Are the Sources of Model Error and How Can We Improve the Physical Basis of Model Uncertainty Representation? Available online: https://www.researchgate.net/publication/311283383_What_are_the_sources_of_model_error_and_how_can_we_improve_the_physical_basis_of_model_uncertainty_representation (accessed on 12 August 2022).
- Nicolis, C.; Perdigao, R.A.; Vannitsem, S. Dynamics of prediction errors under the combined effect of initial condition and model errors. J. Atmos. Sci. 2009, 66, 766–778. [Google Scholar] [CrossRef]
- Feng, J.; Toth, Z.; Peña, M. Spatially extended estimates of analysis and short-range forecast error variances. Tellus A Dyn. Meteorol. Oceanogr. 2017, 69, 1325301. [Google Scholar] [CrossRef] [Green Version]
- Feng, J.; Toth, Z.; Peña, M.; Zhang, J. Partition of analysis and forecast error variance into growing and decaying components. Q. J. R. Meteorol. Soc. 2020, 146, 1302–1321. [Google Scholar] [CrossRef]
- Peña, M.; Toth, Z. Estimation of analysis and forecast error variances. Tellus A Dyn. Meteorol. Oceanogr. 2014, 66, 21767. [Google Scholar] [CrossRef]
- Dalcher, A.; Kalnay, E. Error growth and predictability in operational ECMWF forecasts. Tellus A 1987, 39, 474–491. [Google Scholar] [CrossRef]
- Hopson, T.M. Assessing the ensemble spread–error relationship. Mon. Weather Rev. 2014, 142, 1125–1142. [Google Scholar] [CrossRef]
- Whitaker, J.S.; Loughe, A.F. The relationship between ensemble spread and ensemble mean skill. Mon. Weather Rev. 1998, 126, 3292–3302. [Google Scholar] [CrossRef]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef]
- Yuan, H.; Toth, Z.; Peña, M.; Kalnay, E. Overview of weather and climate systems. In Handbook of Hydrometeorological Ensemble Forecasting; Springer: Berlin/Heidelberg, Germany, 2019; pp. 35–65. [Google Scholar]
- Du, J.; Berner, J.; Buizza, R.; Charron, M.; Houtekamer, P.L.; Hou, D.; Jankov, I.; Mu, M.; Wang, X.; Wei, M.; et al. Ensemble Methods for Meteorological Predictions; National Centers for Environmental Prediction (NCEP): College Park, MD, USA, 2018. [Google Scholar]
- Leith, C.E. Theoretical skill of Monte Carlo forecasts. Mon. Weather Rev. 1974, 102, 409–418. [Google Scholar] [CrossRef]
- Kleeman, R. Information theory and dynamical system predictability. Entropy 2011, 13, 612–649. [Google Scholar] [CrossRef]
- Zhou, F.; Toth, Z. On the prospects for improved tropical cyclone track forecasts. Bull. Am. Meteorol. Soc. 2020, 101, E2058–E2077. [Google Scholar] [CrossRef]
- Lorenz, E.N. Irregularity: A fundamental property of the atmosphere. Tellus A 1984, 36, 98–110. [Google Scholar] [CrossRef]
- Lorenz, E.N. The predictability of a flow which possesses many scales of motion. Tellus 1969, 21, 289–307. [Google Scholar] [CrossRef]
- Weisstein, E.W. CRC Concise Encyclopedia of Mathematics; Chapman and Hall: London, UK; CRC: Boca Raton, FL, USA, 2002. [Google Scholar]
- Murphy, A.H.; Epstein, E.S. Skill scores and correlation coefficients in model verification. Mon. Weather Rev. 1989, 117, 572–582. [Google Scholar] [CrossRef]
- Kim, H.; Kim, H.; Son, S.W. The influence of MJO initial condition on the extratropical prediction skills in subseasonal-to-seasonal prediction model. In Proceedings of the EGU General Assembly 2022, Vienna, Austria, 23–27 May 2022. [Google Scholar]
- Roads, J.O. Forecasts of time averages with a numerical weather prediction model. J. Atmos. Sci. 1986, 43, 871–893. [Google Scholar] [CrossRef]
- Roads, J.O. Predictability in the extended range. J. Atmos. Sci. 1987, 44, 3495–3527. [Google Scholar] [CrossRef]
- Clark, A.J.; Kain, J.S.; Stensrud, D.J.; Xue, M.; Kong, F.; Coniglio, M.C.; Thomas, K.W.; Wang, Y.; Brewster, K.; Gao, J.; et al. Probabilistic precipitation forecast skill as a function of ensemble size and spatial scale in a convection-allowing ensemble. Mon. Weather Rev. 2011, 139, 1410–1418. [Google Scholar] [CrossRef]
- Buizza, R.; Leutbecher, M. The forecast skill horizon. Q. J. R. Meteorol. Soc. 2015, 141, 3366–3382. [Google Scholar] [CrossRef]
- Toth, Z.; Buizza, R. Weather forecasting: What sets the forecast skill horizon? In Sub-Seasonal to Seasonal Prediction; Elsevier: Amsterdam, The Netherlands, 2019; pp. 17–45. [Google Scholar]
- Boer, G.J. Predictability as a function of scale. Atmos. Ocean 2003, 41, 203–215. [Google Scholar] [CrossRef]
- Zhang, F.; Sun, Y.Q.; Magnusson, L.; Buizza, R.; Lin, S.J.; Chen, J.H.; Emanuel, K. What is the predictability limit of midlatitude weather? J. Atmos. Sci. 2019, 76, 1077–1091. [Google Scholar] [CrossRef]
- Privé, N.C.; Errico, R.M. Spectral analysis of forecast error investigated with an observing system simulation experiment. Tellus A Dyn. Meteorol. Oceanogr. 2015, 67, 25977. [Google Scholar] [CrossRef]
- Deveson, A.C.; Browning, K.A.; Hewson, T.D. A classification of FASTEX cyclones using a height-attributable quasi-geostrophic vertical-motion diagnostic. Q. J. R. Meteorol. Soc. 2002, 128, 93–117. [Google Scholar] [CrossRef]
- Schumacher, R.S.; Davis, C.A. Ensemble-based forecast uncertainty analysis of diverse heavy rainfall events. Weather Forecast. 2010, 25, 1103–1122. [Google Scholar] [CrossRef]
- DeMaria, M.; Sampson, C.R.; Knaff, J.A.; Musgrave, K.D. Is tropical cyclone intensity guidance improving? Bull. Am. Meteorol. Soc. 2014, 95, 387–398. [Google Scholar] [CrossRef]
- Charles, M.E.; Colle, B.A. Verification of extratropical cyclones within the NCEP operational models. Part I: Analysis errors and short-term NAM and GFS forecasts. Weather Forecast. 2009, 24, 1173–1190. [Google Scholar] [CrossRef]
- Bullock, R.G.; Brown, B.G.; Fowler, T.L. Method for Object-Based Diagnostic Evaluation; NCAR Technical Note; The National Center for Atmospheric Research (NCAR): Boulder, CO, USA, 2016. [Google Scholar]
- Gilleland, E. Comparing Spatial Fields with SpatialVx: Spatial Forecast Verification in R. J. Stat. Softw. 2021, 55, 69. [Google Scholar]
- Jankov, I.; Gregory, S.; Ravela, S.; Toth, Z.; Peña, M. Partition of forecast error into positional and structural components. Adv. Atmos. Sci. 2021, 38, 1012–1019. [Google Scholar] [CrossRef]
- Rossa, A.; Nurmi, P.; Ebert, E. Overview of methods for the verification of quantitative precipitation forecasts. In Precipitation: Advances in Measurement, Estimation and Prediction; Springer: Berlin/Heidelberg, Germany, 2008; pp. 419–452. [Google Scholar]
- Tallapragada, V. Recent updates to NCEP Global Modeling Systems: Implementation of FV3 based Global Forecast System (GFS v15. 1) and plans for implementation of Global Ensemble Forecast System (GEFSv12). In AGU Fall Meeting Abstracts; American Geophysical Union: Washington, DC, USA, 2019; Volume 2019, p. A34C-01. [Google Scholar]
- Hamill, T.M.; Whitaker, J.S.; Shlyaeva, A.; Bates, G.; Fredrick, S.; Pegion, P.; Sinsky, E.; Zhu, Y.; Tallapragada, V.; Guan, H.; et al. The Reanalysis for the Global Ensemble Forecast System, Version 12. Mon. Weather Rev. 2022, 150, 59–79. [Google Scholar] [CrossRef]
- Selesnick, I.W.; Burrus, C.S. Generalized digital Butterworth filter design. IEEE Trans. Signal Process. 1998, 46, 1688–1694. [Google Scholar] [CrossRef]
- Feng, J.; Zhang, J.; Toth, Z.; Peña, M.; Ravela, S. A new measure of ensemble central tendency. Weather Forecast. 2020, 35, 879–889. [Google Scholar] [CrossRef]
- Kalnay, E. Atmospheric Modeling, Data Assimilation and Predictability; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Ravela, S.; Emanuel, K.; McLaughlin, D. Data assimilation by field alignment. Phys. D Nonlinear Phenom. 2007, 230, 127–145. [Google Scholar] [CrossRef]
- Zhou, X.; Zhu, Y.; Hou, D.; Luo, Y.; Peng, J.; Wobus, R. Performance of the new NCEP Global Ensemble Forecast System in a parallel experiment. Weather Forecast. 2017, 32, 1989–2004. [Google Scholar] [CrossRef]
- Atger, F. The skill of ensemble prediction systems. Mon. Weather Rev. 1999, 127, 1941–1953. [Google Scholar] [CrossRef]
- Jankov, I.; Berner, J.; Beck, J.; Jiang, H.; Olson, J.B.; Grell, G.; Smirnova, T.G.; Benjamin, S.G.; Brown, J.M. A performance comparison between multiphysics and stochastic approaches within a North American RAP ensemble. Mon. Weather Rev. 2017, 145, 1161–1179. [Google Scholar] [CrossRef]
- Leith, C.E. Objective methods for weather prediction. Annu. Rev. Fluid Mech. 1978, 10, 107–128. [Google Scholar] [CrossRef]
- Rotunno, R.; Snyder, C.A. A generalization of Lorenz’s model for the predictability of flows with many scales of motion. J. Atmos. Sci. 2008, 65, 1063–1076. [Google Scholar] [CrossRef]
- Zheng, M.; Chang, E.K.; Colle, B.A. Ensemble sensitivity tools for assessing extratropical cyclone intensity and track predictability. Weather Forecast. 2013, 28, 1133–1156. [Google Scholar] [CrossRef]
- Inness, P.M.; Slingo, J.M. Simulation of the Madden–Julian oscillation in a coupled general circulation model. Part I: Comparison with observations and an atmosphere-only GCM. J. Clim. 2003, 16, 345–364. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variance Type | Error Variance in the Mean | Ensemble Variance around the Mean |
|---|---|---|
| Total | Difference between the original ensemble mean and the analysis | Difference between the original/unmodified ensemble members and the original ensemble mean |
| Larger-scale | Difference between the filtered ensemble mean and the filtered analysis | Difference between the filtered ensemble members and the original ensemble mean |
| Smaller-scale (unpredictable) | Difference between the original and filtered verifying analysis | Difference between original and filtered ensemble members |
| Positional | Difference between the filtered ensemble mean and the aligned filtered ensemble mean | Difference between the filtered ensemble members and the aligned filtered ensemble members |
| Structural | Difference between the aligned filtered ensemble mean and the filtered analysis | Difference between the aligned ensemble members and the original ensemble mean |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jankov, I.; Toth, Z.; Feng, J. Initial-Value vs. Model-Induced Forecast Error: A New Perspective. Meteorology 2022, 1, 377-393. https://doi.org/10.3390/meteorology1040024
Jankov I, Toth Z, Feng J. Initial-Value vs. Model-Induced Forecast Error: A New Perspective. Meteorology. 2022; 1(4):377-393. https://doi.org/10.3390/meteorology1040024
Chicago/Turabian StyleJankov, Isidora, Zoltan Toth, and Jie Feng. 2022. "Initial-Value vs. Model-Induced Forecast Error: A New Perspective" Meteorology 1, no. 4: 377-393. https://doi.org/10.3390/meteorology1040024
APA StyleJankov, I., Toth, Z., & Feng, J. (2022). Initial-Value vs. Model-Induced Forecast Error: A New Perspective. Meteorology, 1(4), 377-393. https://doi.org/10.3390/meteorology1040024