1. Introduction
In the last decade, there has been a growing interest in the development of implanted neural interfaces for monitoring brain activity with very high temporal and spatial resolution. Implantable microelectrodes arrays, implemented in microelectromechanical system (MEMS) technology, are used to record electrical signals from surrounding neurons and have led to outstanding and innovative results in recent neuroscience research. These electrodes are able to detect action potentials (APs) from individual neurons, which are very important not only for studying individual neurons but networks of neurons in order to understand how the activity of interconnected neurons results in higher-order functions such as perception, understanding, movement, and memory [
1,
2,
3].
In neural microsystems, neural signals, captured from MEMS microelectrodes, are passed to the analog front-end chain, which is devoted to signal conditioning, and whose first stage is a front-end amplifier, followed by an additional filter/amplification stage that drives an analog-to-digital (ADC) converter. The overall bandwidth of the neural recording interfaces typically ranges from 0.1 Hz up to 10 kHz. The high-frequency content (about 200 Hz to 5000 Hz) is referred to as single unit action potentials (AP), while the low-frequency signal content (below about 200 Hz) is referred to as local field potentials (LFP) [
4].
This processing chain is replicated many times to achieve a multichannel acquisition system, which is essential for monitoring several neurons belonging to different brain regions. The information acquired through such neural microsystems can be used for the prevention and treatment of many neurological diseases (such as epilepsy or Parkinson’s) and in the so-called brain–machine–interfaces (BMI) [
5,
6]. Therefore, the system is composed of a network of MEMS sensors which are devoted to the acquisition of neural signals, known as “action potentials” or “spikes”, for the realization of implantable multi-electrodes arrays (MEA). Then, the acquired very weak neural signals, with amplitudes in the order of 10 µV to 100 µV, are amplified and filtered before the A/D conversion process takes place because different cellular mechanisms are responsible for different frequency components of the recorded signals, as mentioned above. This chain is usually replicated several times in order to obtain a multi-channel system able to monitor wide brain regions and collect information from a high number of neurons. Communications between neurons happen through the aforementioned spike signals. Each microelectrode captures neural activity from multiple surrounding neurons. These extracellular recordings are called multi-unit activities because they involve spikes from different source neurons and are useful only in specific cases. However, several applications, ranging from clinical diagnostic and medical technology to BMI, which are used to control external devices such as neural robotic prosthesis and so on, require single-unit activity, that is, classification of spikes based on source neurons from which they were emitted. The process of classifying spikes with the corresponding source neurons, namely, the process of separating multi-unit activity into groups of single-unit activity, is called “spike sorting”, and it consists of three main phases: “Detection and Alignment”, “Features Extraction”, and “Clustering” [
7,
8,
9,
10,
11,
12].
Reducing the output sorting data rate while minimizing the latency between spike detection and spike classification is the primary objective of real-time spike-sorting solutions. This is due to the fact that stimulating neurons during certain temporal windows is necessary to cause synaptic change. Different types of synaptic modifications are produced, for instance, by stimulation that occurs 20 ms before or after pre-synaptic activation [
7]. Therefore, in closed-loop BMI applications, the sorting latency is a critical consideration.
Hardware design solutions to implement the different algorithms for each task of the spike-sorting chain are currently being investigated in order to obtain optimal performance for the entire neural spike-sorting system. Several techniques and digital architectures, able to achieve a reduction of hardware resources, have been presented in the literature in order to process a higher and higher number of neurons with minimal hardware resources and power consumption [
7,
8,
9,
10,
11,
12]. Indeed, integrated circuits of such complexity have to satisfy stringent requirements related to power density since it has been demonstrated that the power density has to be less than 277 μW/mm
2 to be safe because high power values generate heat that damages the surrounding brain tissue [
13]. Another important requirement is to avoid circuits with heat flux over 40 mW/mm
2, which may damage the brain tissue [
14]. Finally, the minimization of the silicon area is very important for implantable devices devoted to the processing of signals coming from a larger and larger number of neurons.
Moreover, real-time processing of neural data is essential to control neural robotic applications and for several experiments which cannot be performed otherwise. Sorted results are preferably wirelessly transmitted to avoid issues such as risk of injury and infection as well as the degradation of the signal quality. For instance, among the previous spike-sorting digital signal processing (DSP) cores proposed in the literature, a single-channel real-time spike-sorting chip with a silicon area of 2.57 mm
2 and a power consumption of 2.78 μW from a 1.16 V power supply has been presented in [
7]. A 16-channel spike-sorting chip, which occupies 0.07 mm
2 of area per channel (i.e., a total of 1.23 mm
2) with a power consumption of 4.68 μW per channel (i.e., a total of 75 μW) from a 0.27 V supply voltage implemented in a 65-nm CMOS process, has been reported in [
12].
From the perspective of the design of integrated circuits dedicated to these applications, the miniaturization of these systems presents many challenges. Indeed, modern neural recording microsystems involve different trade-offs between the area and power consumption constraints on one side, and performance requirements in terms of accuracy, speed, and latency of the sorting operations on the other side.
The aim of this work is to develop the processing chain of a CMOS-integrated circuit for implantable neural spike-sorting systems, able to operate with ultra-low power consumption as well as with minimum silicon area footprint. The focus is oriented on a fixed-point digital architecture for the detection and clustering phases in which the tradeoff between performance parameters (such as accuracy, maximum number of clusters, and maximum number of waveforms to be stored) and silicon area and power consumption constraints has to be optimized.
The paper is organized as follows.
Section 2 summarizes the background of spike-sorting systems and discusses the selection of the algorithms which have been implemented.
Section 3 provides simulation and synthesis results both for detection and clustering block, which allow us to identify the digital architecture to be implemented. In
Section 4, the digital architecture and its hardware implementation on two different CMOS processes is described, and finally,
Section 5 is devoted to the conclusion.
2. Background and Algorithms Selection
The main blocks of a typical spike-sorting signal processing chain are shown in
Figure 1, where the different phases are highlighted. The digitized neural signals, available at the output of the ADC block, are sent through the “Detection and Alignment” module, where spikes are extracted from background noise and aligned to a common temporal reference point relative to the spike waveform.
These aligned spikes are sent to the “feature extraction” module, where the latter are processed to extract a set of features of the spike shape to allow for a better separation of the different spike classes. At this point, some sort of dimensionality reduction process takes place, whose target is the identification of feature coefficients that best separate spikes. More specifically, starting from all the samples used to represent the spike waveform, the most discriminative features are extracted, thus reducing the dimensionality of the neural waveform and allowing for a simpler discrimination process between the different spikes. Finally, based on the extracted features coefficients, spikes are mapped into different groups associated to the different neurons; this process is known as “clustering”. The result of the whole process is the train of spike times for each neuron, namely, the desired single-unit activity.
Accurate selection of the most suitable state-of-the-art algorithms for each of the main tasks in the spike-sorting process is crucial. Indeed, algorithms directly affect hardware resources, and consequently, different trade-offs are involved, principally in terms of silicon area and power consumption, bearing in mind that another essential factor lies in the accuracy of the results that can be achieved with a given type of algorithm, which, among other things, has to be unsupervised and real-time. Moreover, neuronal activity produces a dynamic environment; thus, in order to identify clusters of arbitrary shape and size, adaptability is another important characteristic. Therefore, complexity/accuracy of algorithms must be taken into account in order to find the optimal trade-off.
2.1. Detection Strategies
The detection phase is very critical, and since it is the first step in the processing of the neural spikes, it has to be performed with high accuracy. Indeed, the aim of this task is to discriminate the neural spike signals from the background noise. Moreover, since neuronal activity produces a dynamic environment, the detection algorithms have to be able to overcome non-ideality issues, such as non-Gaussian noise, non-stationarities, and overlapping spikes.
There are different thresholding methods for the detection phase [
15,
16,
17]:
The absolute value technique performs better than applying a simple thresholding technique, but it is still weak in handling different SNR scenarios and other non-idealities such as non-Gaussian noise. The non-linear energy operators are very attractive techniques with which to process the neural data coming from the ADC in order to emphasize the high-frequency and high-energy content (related to neural spikes) and to attenuate the low-frequency and low-energy content (related to noise). Indeed, the first refers to the presence of a spike signal which is characterized by a rapid variation in the time domain of the waveform, which is a high-frequency event in the frequency domain. Moreover, the energy of the spike is higher than the energy of the noise; therefore, these techniques are very helpful for detection purposes. In this context, by defining
, the output of the conventional NEO method applied on the current sample
, the following formulation can be defined [
17]:
The threshold can be computed as a simple average on the NEO waveform, weighted by a constant
to be found empirically from the processing of different datasets [
16].
The KNEO method is very similar to the conventional NEO, except for the
k parameter used as shift factor; indeed, in the standard NEO,
, but in the general case, any value of
k can be chosen. The formulation is very straightforward, and with the same convention used before, the output of the KNEO processing can be defined as [
16]
where
k can be any integer value (coherent with the application). The thresholding method is the same as the NEO.
The SNEO is based on the application of a smoothing window to the neural data processed with the KNEO method. In particular, once the KNEO is performed, a convolution of the entire sequence with a suitable filter window is performed. The approach can be defined as [
16]
where
represents the output of the KNEO process, and
is a given filtering window selected with a proper length and type (for instance, a Hamming window of length 25 samples). The thresholding technique is selected to be the same as the other NEO variants, and it is reported in the following equation [
16]:
In this work, the focus is on the non-linear energy operator algorithm and its variants because of their simple hardware implementation (which is suitable for applications with stringent area and power consumption requirements) and their ability to guarantee good detection accuracy. This point will be better assessed in the next section, where the three NEO variants will be compared both in terms of detection accuracy and hardware resources.
2.2. Features Extraction Approaches
The step of feature extraction within the spike-sorting system is used in order to select, among all the samples collected to represent the spike waveform, the more discriminative ones, which are used to obtain a sort of dimensionality reduction of the data, to be used in the following clustering phase. The main features extraction approaches adopted in the literature are [
18] as follows:
In the PCA technique, the signal samples are processed in order to build the orthogonal basis (i.e., the principal components (PC)), which are used to address the directions in the data with the largest variation. This orthogonal bases are calculated through the eigenvalue decomposition of the covariance matrix of the data and then each spike is represented with coefficients [
18].
The wavelet transform approach is used to decompose the signal into shifted and scaled version of a so called “wavelet”; this method, unlike the Fourier analysis, which uses decomposition of the signal through a sine wave, is able to detect abrupt changes in the signal which cannot be appreciated with sinusoidal decomposition. Indeed, a wavelet, unlike a sine wave, is a rapidly decaying wave-like oscillation. There are different types of “mother wavelet”, each with different shapes in order to select the one that best fits the particular changes in the signals under analysis [
18].
The DD method is based on the computation of the slope at each sample point with different time scales:
where
is the time shift used for the processing and can be an integer, like the following:
The samples windowing approach simply involves the selection of a window of
samples of the signal waveform around the peak identified with the NEO operator. This last technique can be successfully applied when adopting the OSort clustering algorithm, as in [
7], and provides the advantage that the average of each cluster is itself a spike waveform representing the whole cluster.
2.3. Clustering
Clustering, in the general meaning of the word, is related to the identification of common characteristics of the data within a particular set and it is very widely used in the field of data science to analyze very large datasets. In particular, different data are evaluated in order to separate them into the corresponding membership groups. In the field of neural spike sorting, only some subsets of this type of algorithm are used to separate the multi-unit activity into single-unit activities. These single units are a better approximation of neuronal activity than unclustered data. The spike analysis is heavily dependent on the clustering phase which allows us to obtain the separation of groups of neurons based on the spatiotemporal behavior of the single spike signal. One of the most discriminative characteristics of choosing one clustering algorithm rather than another one is the possibility to perform it in a real-time environment. Indeed, not all the clustering algorithms can be used in real-time (unsupervised) applications, since some of them require the knowledge of some information before the scenario can be analyzed and processed. The latter are called offline or supervised, and in the context of neural spike-sorting systems, dedicated to real-time processing they cannot be used. Clearly, another key factor is the classification accuracy that can be reached with a given type of algorithm, and in this respect, the offline algorithms are most attractive.
Clustering algorithms are categorized based on the nature of their working mechanism, such as partitional, hierarchical, probabilistic, graph-theory, fuzzy logic, density-based, and learning-based. For a complete comprehension of each of the latter, the reader can refer to [
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33].
In order to choose the most suitable algorithm for our hardware implementation, we analyzed the literature with a particular focus on algorithms suitable to be implemented in real time. The results of this literature survey are reported in
Table 1, where a comparison of the key parameters involved in the selection phase of the clustering algorithm is provided. Data summarized in
Table 1 have been extracted mainly from [
18,
24,
25,
29,
30].
The OSort algorithm was chosen for our implementation because it is able to work in real time and its hardware implementation is much simpler than the other machine learning implementations that have been recently presented.
Osort is a very attractive approach since its working mechanism is very intuitive and simple. It is a clustering algorithm used in real-time application which uses an iterative process based on a comparison of “distances” between the extracted features or the time domain, windowed, spike waveforms. In fact, it can work properly with or without an explicit feature extraction process; indeed, it can also be used directly to process a window of samples of the dataset (SW feature extraction approach).
The algorithm flow graph is shown in
Figure 2. The incoming spike waveform is used as input, and the Euclidean distance is calculated between the incoming spike waveform with samples
s(
n) and the mean waveform of the existing clusters with samples
c(
n):
where
represents the number of samples in the spike window. The parameter “
d” is calculated for all the available existing clusters (clearly, if no clusters have been generated yet, the spike is assigned to the first generated one, and it coincides also with the mean value of the cluster since no other spikes are present within the cluster). If more clusters are present, different Euclidean distances will be calculated, and the minimum ones are used to be compared with a given threshold parameter
, extracted as the variance of the noise of the dataset.
When a given spike is assigned to a given cluster, the mean value of the latter will be updated with the information contained in the new spike, and the updating of the mean value is performed according to the following equation:
where
N defines the number of spikes present in the particular cluster. When this process is terminated, a further check is performed in which the distance “k” between the generated clusters is also computed in order to verify if some clusters can be merged together. If, again, the minimum one is less than the same threshold, then the clusters can be merged; otherwise, the algorithm starts again with the first step through an iteration process that ends only when all the spikes have been processed.
4. Implementation of Real-Time Detection and Sorting Chain
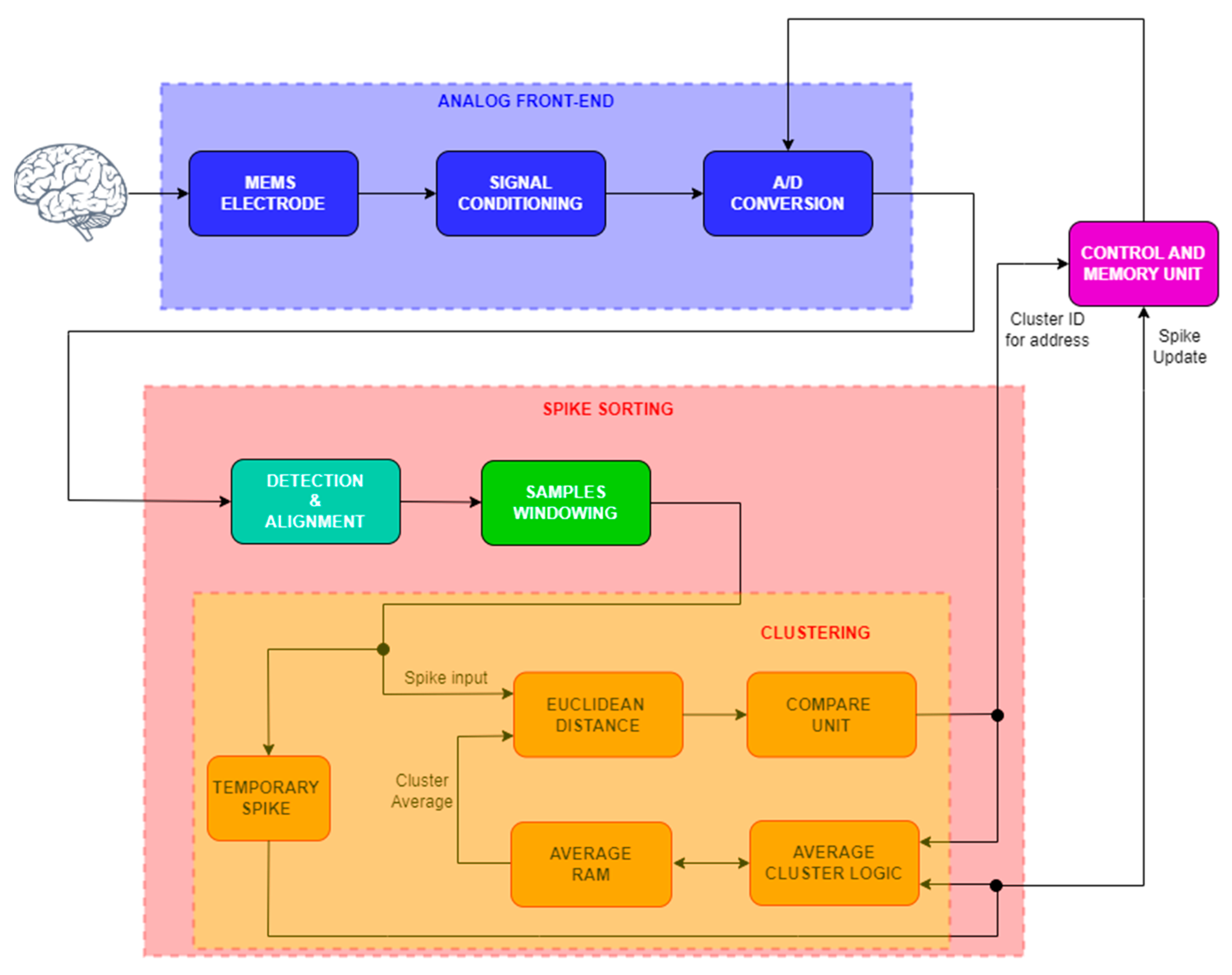
The proposed architecture for the neural spike detection and sorting channel is reported in
Figure 5. The signal conditioning block within the analog front-end is used for amplification and filtering of the neural signals taken from the MEMS microelectrode array, which are then converted into the proper binary format by the ADC block for subsequent digital processing. The digitized neural spikes are passed to the digital processing chain for detection and alignment operations and are then sent to the spike-sorting unit through a windowing module. The data flow from the ADC to the digital blocks is managed by the control and memory unit block. More specifically, the control and memory unit has in charge the generation of the signals controlling the ADC conversion, the optional storing of all the incoming waveforms (if needed), and the management of detection and sorting operations within the digital processing chain.
The operations of NEO detection, alignment, and samples windowing are performed in the first part of the digital processing chain. NEO is chosen because it involves less hardware resources and enough accuracy of detection compared to other NEO variants which are similar in terms of accuracy but require a little bit more resources. To minimize the area footprint, a window of 32 samples of the detected and aligned spikes is sent to the OSort unit, as explained in
Section 3.
This architecture has been designed in order to enable the simultaneous processing of several channels, which has now become mandatory for future neural recording applications [
31,
33].
It has to be noted that when operating in real-time, the OSort algorithm should continue to accept incoming identified spikes in order to compute fresh cluster averages and perform cluster merger checks. Using a queue to hold all recently discovered spikes is one way to solve the problem, but doing so would need a significant amount of silicon area. As an alternative, we propose to compare incoming spikes to the pre-existing clusters while simultaneously performing cluster merging and averaging.
The proposed digital clustering channel is made up of the following blocks:
The “Euclidean distance” block is used to compute the Euclidean distance, already described in (8); it is designed as a simple accumulator which accumulates the results between the squared distance among the samples of the spike and the samples of the actual spike average, which is representative of the cluster mean waveform and stores it in the average memory. This operation is replicated a number of times equal to the number of clusters present in the memory. The proposed architecture is thought to handle a maximum of eight clusters. This distance is passed to the “Compare unit” block, which contains several flip-flops (FFs) used as registers to store the minimum distance among all the computed distances (one for each cluster); a comparison between the next distance and the actual stored is performed, and if the new distance is less than the actual one, then it will be stored into the FFs, overwriting the past data.
The “Compare unit” then sends to its output the cluster ID (a simple number from 0 to 7) for which the distance is the minimum one. The ID is used to perform the write operation in the proper cluster address into the “Average memory” unit, which takes as input the new average computed between the old average and the actual spike, present at the input of the digital core sorter and maintained in a temporary file register for all the time needed to complete the operations. At the end of the process, the classified spikes can be stored into the proper cluster address region related to the cluster ID computed by the compare unit. The merging step of the OSort algorithm is performed as in [
7].
The main design parameters assumed for the implementation of the proposed spike-sorting module are as follows:
The choice of a data size of only 8 bits is due to the main aim of this work, which is an aggressive reduction of the area footprint of the spike-sorting module. For this purpose, it has to be noted that the effective number of bits (ENOB) of most ADCs for neural recording applications is typically limited to 8–9 bits [
34].
Due to its limited size, and to allow for fully parallel access to all locations, the “Average memory” module has been implemented with conventional D flip-flops from the standard-cell library.
The synthesis and place and route of the proposed digital processing chain have been performed using the Cadence Genus Synthesis Solution and the Cadence Innovus tool, respectively. The spike sampling frequency is 24 kHz, and each detected spike is saved as a 32 samples window, namely, a window of 1.3 ms duration.
The digital verification of the whole architecture was carried out by developing a dedicated SystemVerilog test for each designed block and performing a simulation in the Cadence Xcelium tool. Then, the whole architecture was verified with a bit true test between the RTL and the Simulink architecture developed through SystemVerilog direct programming interface (DPI) generation, which is an interface between SystemVerilog and programming languages such as C. The HDL verifier can generate SystemVerilog DPI components from MATLAB code or Simulink models for use in ASIC verification [
35]. Finally, post-layout simulations (PLS) were performed.
The implementation has been carried out in two different technologies: a well-established bulk 130 nm CMOS technology; and a recently developed 28 nm fully depleted silicon on insulator (FDSOI) CMOS process. A summary of area requirements is reported in
Table 8, in which the results of the synthesis have been reported for detection with the SW feature extraction module (second column) and for the clustering block (third column).
The area estimation is very low; indeed, only about 0.00862 mm2 is reported for the single channel, and a clock frequency of about 200 MHz can be reached.
Detection and clustering blocks have then been placed and routed in the Cadence environment using the Innovus tool and referring to both the 130 nm and 28 nm technologies. The layout of the single channel digital processing chain implemented within the Cadence Innovus place and route tool in the 28 nm technology is reported in
Figure 6, showing an area footprint as low as 125 μm × 125 μm.
Since the proposed implementation can be operated with a clock frequency as high as 200 MHz, which is about 8333 times the typical sampling frequency of neural recording systems, the proposed clustering unit can be time shared between several neural recording channels. In this case, the main design constraint would be the memory to store all the neural spikes coming from the different channels. For example, to save a maximum of 16 waveforms made up of 32 8-bit samples for a maximum of eight clusters, 32 kbits of memory for each channel are needed. If an 8192-channel sorting is considered, the clock frequency has to be set at 196.6 MHz, which is compatible with the proposed design, but the memory requirement to store all the spike waveforms would be 256 Mbits, which is clearly not compatible with conventional on-chip integration.
To save this huge amount of memory, two possible strategies can be devised. The first approach, which we have considered in our work, is to store on chip only the average waveforms of the spikes, with the associated cluster IDs and spike times providing the address of the clustered spikes to an optional external memory. Another approach, which could be explored in future research, would be to consider time-division-multiplexed systems, such as the high-density CMOS neural probes [
36,
37,
38,
39,
40], which allow for the recording of a large number of neurons at single-cell resolution. For example, referring to the system in [
38], the ADC directly converts 1024-time-division-multiplexed channels with a sampling frequency in the range of 24.6 MHz, allowing for the exploitation of the high clock frequency achieved by the proposed spike-sorting module in a simpler manner.
A comparison against the state of the art is reported in
Table 9, showing how the proposed digital processing chain implemented in the 28 nm technology achieves the lowest silicon area footprint and power consumption per channel.
The closest competitor with the proposed spike-sorting module is the implementation in [
31] based on the binary decision tree (DT) clustering approach. Considering a technology scaling from a 130 nm process to a 28 nm process, the DT spike-sorting module would outperform the proposed one in terms of area and power consumption per channel. It has to be noted, however, that the area and power consumption estimations provided in [
31] are based on post-synthesis results.
5. Conclusions
In the first part of this work, a comparison and an evaluation of the most used detection algorithms is performed, and in particular, the focus is oriented towards the energy operator type, which are very prone to be used in this field of application since they require very low hardware resources. Indeed, their simple hardware implementation and its capacity to achieve high accuracy results are very attractive in the context of neural spike detection applications. Based on the information acquired during the simulation phase, the SNEO technique seems to be the best candidate for the detection step and can be used in future design of CMOS integrated circuits for an implantable neural spike-sorting system framework. However, in this work, the simple NEO algorithm is chosen since the difference in terms of accuracy results does not justify the extra use of area resources.
Then, two features extraction approaches applied to the OSort algorithm have been considered in the simulation phase. Since the OSort clustering technique using the SW features has demonstrated a good accuracy with the most commonly adopted datasets, and since its implementation is the simplest one, it has been chosen for the implementation of the digital processing chain developed in this work.
The implementation results have demonstrated an area occupation and power consumption of the proposed detection and clustering module of 0.2659 mm2/ch, 7.16 μW/ch, 0.0168 mm2/ch, and 0.47 μW/ch for the 130 nm and 28 nm implementation, respectively. The comparison against the state of the art has shown how the proposed spike-sorting module achieves the lowest silicon area footprint and power consumption per channel. In fact, even if the proposed architecture moves some functions in the control and memory unit to simplify the implementation of the clustering module, this results in a strongly reduced area and power consumption when several digital channels have to be elaborated. The achieved low area occupation is also related to the adopted data size of only 8 bits, which, even if lower than the one adopted in other works, is acceptable for neural recording applications due to the limited ENOB (in the range of 8–9 bits) of ADCs used in such systems.
The proposed spike-sorting module could be exploited in time-division-multiplexed systems, which, in the near future, will rely on ADCs able to convert 8192-time-division-multiplexed channels directly with a sampling frequency in the range of 196.6 MHz and will allow us to exploit, fully, the 200 MHz clock frequency achieved by this implementation.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}