3.1. Convergence and Improper Solutions
Warning messages for the model with heterogeneous trait factors (Model 1) are displayed in
Table 2, those for the model with interchangeable raters and homogeneous trait factors (Model 2) and for the model with a combination of interchangeable and structurally different raters (Model 3) are displayed in
Table 3. The proportions of warning messages were identical across the three M
plus versions for all three models.
In simulations concerning the first model, three different types of warning messages arose: (1) “The estimation has reached a saddle point or a point where the observed and the expected information matrices do not match”, (2) “The
model estimation did not converge”, and (3) “The latent variable covariance matrix [
] is not positive definite”. In general, the proportions of warning messages in almost all conditions for this model stayed below 5%. There was only one condition, the one with 500 targets, 2 raters, and a WTC of 0.95, in which M
plus issued warning messages for more than 5% (11.2%) of the replications, all of which concerned non-convergence of the
model estimation. Since for all conditions with 100 and 250 targets as well as for the conditions with 500 targets and 20 raters, proportions of warning messages stayed below 1% and, in many cases, were equal to 0, they are not displayed in
Table 2. A table with warning messages for the first model, which includes all simulated conditions, can be found in
Appendix A (
Table A1).
The types of warning messages that occurred in simulations with Model 3 were the same as those occurring in simulations with Model 1. For Model 2, in two replications, a non-positive definite first-order derivative product matrix appeared as a fourth type of warning. For both models (Model 2 and 3), a large proportion of warning messages (28.5% to 87.6%) appeared in conditions with two raters, most of them concerning the estimation reaching a saddle point or a point where the observed and the expected information matrices did not match. Additionally, in the second model, in all conditions with 500 targets, the model estimation did not converge in almost 50% of the replications. In all other conditions, only a negligible amount of warning messages emerged.
Across all models and conditions, the estimation reaching a saddle point or a point where the observed and the expected information matrices did not match was a problem that mainly occurred for models with unidimensional trait factors and only two within-level units. Nonconvergence was a problem that mainly affected the model with unidimensional trait factors and interchangeable raters only (Model 2) and only conditions with the largest number of targets (see
Table 3).
3.2. Chi-Square Test
Rejection rates based on the
test of model fit with a nominal alpha level of 0.05 are presented in
Table 4 and
Table 5 (Model 1) and in
Table 6 (Model 2 and Model 3). Rejection rates did not differ at all between the M
plus version in which the new correction was first implemented (version 8.7) and the most recent version (8.10) and are thus presented in shared columns.
In simulations applying the first model (Model 1,
Table 4), for all M
plus versions, the rejection rates were correct (4.5%
rejection rate
5.5%) or adequate (2.5%
rejection rate
7.5%) in all conditions with 20 within-level units but the one with 100 targets and a WTC of 0.95, in which they were inflated. In conditions with 10 raters, most rejection rates were adequate. However, in conditions with the highest WTC (0.95) and 100 or 250 targets, and in the condition with a WTC of 0.90 and 100 targets, rejection rates were inflated.
In conditions with five raters, while conditions with smaller WTC (0.60 and 0.80) and 250 or 500 targets yielded correct rejection rates, larger WTC (0.90 given 250 targets and 0.95 given 500 targets) went along with inflated rejection rates. In conditions with five raters and 100 targets, all rejection rates were inflated. Finally, in conditions with only two within-level units, rejection rates were inflated in all conditions but the one with 500 targets and the lowest WTC (0.60). Altogether, there were rather small differences between the version with the old (8.5) and the versions with the new correction factor (8.7 and 8.10). Overall, larger total sample sizes went along with fewer type-I errors. However, across conditions yielding the same total sample sizes (e.g.,
N = 1000), conditions with a smaller number of raters and a larger number of targets (e.g., two raters and 500 targets) often went along with higher rejection rates than those with a larger number of raters and a smaller number of targets (e.g., 10 raters and 100; see
Table 5).
In M
plus version 8.5, for both models with unidimensional trait factors (Models 2 and 3), rejection rates were inflated in all conditions but the one with 500 targets and 20 raters for Model 3 (see
Table 6). Overall, the rejection rates were smaller in conditions with the model with interchangeable as well as structurally different raters (Model 3) than in conditions with the model with interchangeable raters only (Model 2). Across M
plus versions and for both models, an increasing number of targets went along with lower rejection rates. The same applied to the number of raters. For both models and all M
plus versions, the highest rejection rates resulted from conditions with two within-level units.
Given five within-level units, although the rejection rates were smaller than in conditions with two, they were also inflated in almost all conditions. Only in one condition, namely the one with five within-level units and 250 targets, for the model with a combination of methods (Model 3), a previously inflated rejection rate (8.5%) was adequate (7.4%) in the more recent Mplus versions (8.7 and 8.10). In conditions with 10 and 20 raters, rejection rates further approached the nominal alpha level. In four conditions with 10 or 20 raters, the rejection rates were inflated in Mplus version 8.5 but adequate in the more recent versions (8.7 and 8.10): the conditions with 100 targets and more than five raters, as well as conditions with 500 targets and 20 raters for Model 2 and the condition with 250 targets and 10 raters for Model 3.
In three out of five conditions in which the more recent Mplus versions yielded adequate rejection rates, which were inflated prior to the implementation of the new correction factor, which were conditions with 250 or 500 targets, differences in the rejection rates within conditions between the old vs. more recent Mplus versions were rather small (around 1%). In the other two conditions, which were the conditions with 100 targets and 10 as well as 20 raters for Model 2, the differences between the Mplus versions were larger (6.6% and 6.2%, respectively).
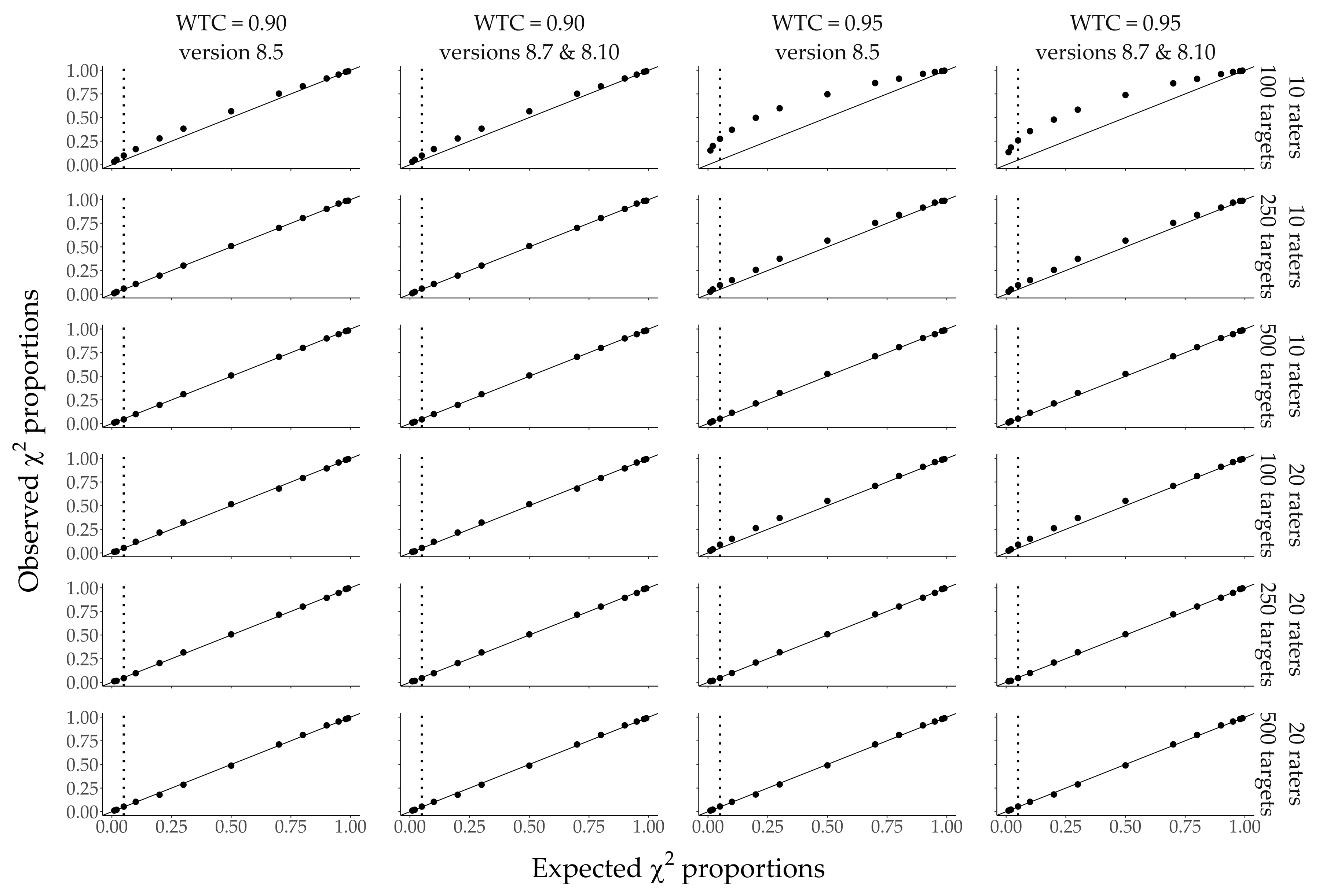
Figure 4,
Figure 5 and
Figure 6 display P-P plots with the simulated vs. expected proportions of
values exceeding theoretical quantiles of the corresponding theoretical
distribution in simulations applying the first model (
Figure 1). It is important to note that the simulated and expected proportions refer to the right tail of the
distribution. That means, for example, that the value 0.05 is the 0.95 quantile of the
distribution, the value 0.10 is the 0.90 quantile, etc.
Figure 4 and
Figure 5 cover conditions with few (two or five) raters and low (
Figure 4, WTC
= 0.60 or 0.80) vs. high WTC (
Figure 5, WTC = 0.90 or 0.95).
Figure 6 covers conditions with more (10 or 20) raters and a high WTC. The plot for more (10 and 20) raters and low WTC (0.60 or 0.80) is displayed in
Appendix A (
Figure A2); as for those conditions, the observed and expected proportions were (almost) identical across all target conditions and M
plus versions.
As seen in
Figure 4,
Figure 5 and
Figure 6, simulated proportions of
values exceeding other theoretical quantiles than the 0.05 quantiles (i.e., the rejection rates in
Table 4) also only differed marginally between the old and new M
plus versions. Just as for the rejection rates, as the (other) values displayed in the P-P plots did not differ at all between the M
plus version in which the new correction was first implemented (version 8.7) and the most recent version (8.10); they are presented in shared columns.
For the first model, given a WTC of 0.60, the first condition to yield an approximately correct
distribution was the condition with two raters and 500 targets (see
Figure 4). While in conditions with fewer targets (100 or 250), the simulated
values had a notable upward bias, all conditions with at least five raters and any number of targets yielded very close approximations of the corresponding
distributions. In conditions with WTC of 0.80, more units were necessary for a good approximation. In those conditions, while five raters and 100 targets only led to an approximately correct distribution, five raters and 250 targets led to a very good approximation. With increasing WTC, the number of units necessary for a good approximation of the theoretical
distribution increased further (see
Figure 5 and
Figure 6). With WTC of 0.90, while an approximately correct distribution was given in conditions with five raters and 350 targets, a very good approximation was attained in conditions with at least five raters and 500 targets. With WTC of 0.95, at least 10 raters and 250 targets were necessary for a very good approximation.
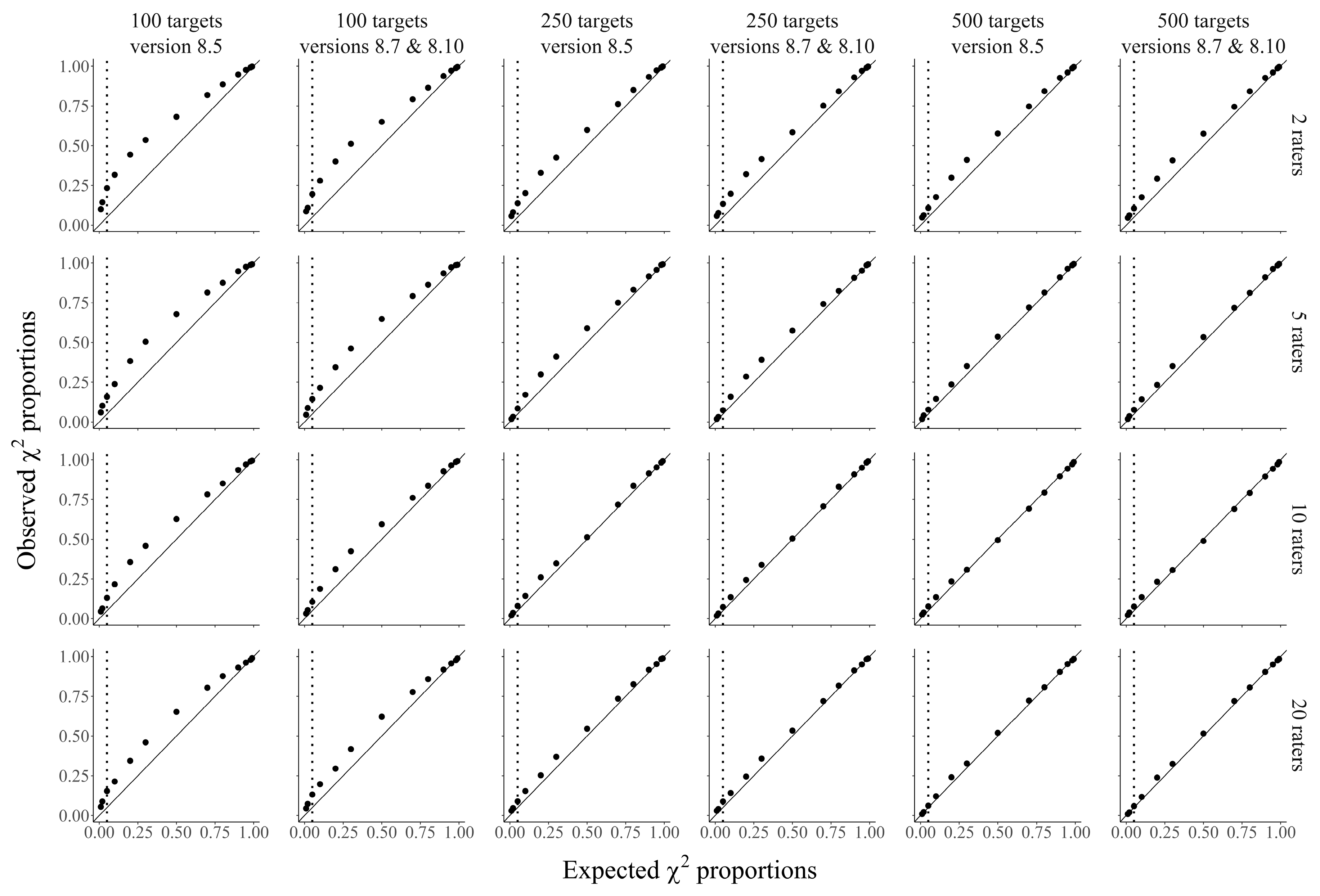
Figure 7 and
Figure 8 display P-P plots with the simulated vs. expected proportions of
values exceeding theoretical quantiles of the corresponding theoretical
distribution in simulations applying the second (
Figure 2) and third model (
Figure 3), respectively.
In the model with unidimensional traits and interchangeable raters only (
Figure 2), all WTC were one. In simulations applying this model, as compared to the model with heterogenous trait factors (
Figure 1), more differences occurred between M
plus versions with the old (8.5) and new correction factors (8.7 and 8.10, see
Figure 7). Especially in conditions with 100 targets and at least five raters, the new correction factor led to better approximations of
distributions for the upper tails of the distributions, where rejections happen. In the condition with 100 targets and two raters, the new correction factor also led to a small improvement, but the simulated test statistics were still clearly overestimated in the lower part of the distribution. Also, the new correction factor led to a downward bias in the upper parts of the distributions in conditions with at least five raters. In conditions with 250 and 500 targets, the simulated values were much closer to the expected ones than in those with 100 targets, and the new correction factor further enhanced the approximation, but only slightly. In the most recent M
plus version, five raters were sufficient for a good approximation of the theoretical
distributions across the four different target conditions. Given 500 targets, the distributions were also fairly well approximated with only two raters.
As seen in
Figure 8, in simulations applying the model with a combination of interchangeable and structurally different raters (
Figure 3), the new correction factor only led to very small improvements. In the third, most complex model, very good approximations of the expected quantiles could be attained in conditions with at least 250 targets and 10 raters or 500 targets and 5 raters. In conditions with fewer units, the simulated
values had a visible upward bias.
Differences between the
values in the old M
plus version without the correction factor (8.5) and the two versions with the new correction factor (8.7 and 8.10) were largest in conditions with unidimensional trait factors (WTC = 1) only (see
Figure 7). Within the model with heterogenous trait factors, differences between the old and new M
plus versions were not bigger for larger WTC (e.g., 0.95 and 0.90;
Figure 5 and
Figure 6) than for smaller WTC (e.g., 0.80 and 0.60;
Figure 4) but rather small in all conditions. In the most complex model with a combination of structurally different and interchangeable raters, differences between M
plus versions were also rather small (
Figure 8).
3.3. RMSEA and CFI
Just like the test of model fit values, the mean RMSEA and CFI values did not differ between Mplus versions 8.7 and 8.10. However, differences between version 8.5 and the more recent versions were also very small.
Please note that the following two paragraphs refer to mean values across replications instead of the fit indices’ distributions. This is only a rough exploration, and more complex analyses considering their distributions within simulation conditions are necessary to reliably derive sample size requirements for correct CFI and RMSEA in similar models (also see
Section 4.3).
Across all models, conditions, and M
plus versions, mean CFI were very close to one. In conditions applying the two models with unidimensional trait factors (models in
Figure 2 and
Figure 3), all mean CFI were
0.97, so based on the mean CFI across replications, there were no type-I errors. In the model with heterogenous trait factors (model in
Figure 1), based on the mean CFI, three conditions led to type-I errors: those with two raters, 100 targets, and WTC of 0.80, 0.90, and 0.95. The mean CFI in these conditions were 0.965 (
SD = 0.078), 0.944 (
SD = 0.123), and 0.934 (
SD = 0.147), respectively, in the more recent M
plus versions and slightly lower with 0.962 (
SD = 0.084), 0.939 (
SD = 0.130), and 0.927 (
SD = 0.176), respectively, in version 8.5.
A similar pattern occurred for the mean RMSEA: no type-I errors occurred based on the mean RMSEA when applying the rule RMSEA
0.05 for the models with unidimensional trait factors (models in
Figure 2 and
Figure 3). In conditions with heterogenous trait factors (
Figure 1), there were seven conditions in which the mean RMSEA across replications led to a type-I error:
All conditions with 100 targets and two raters, which had mean RMSEA of 0.066 (SD = 0.095), 0.098 (SD = 0.123), 0.125 (SD = 0.143), and 0.139 (SD = 0.193) for the lowest to highest WTC in the more recent Mplus versions (8.7 and 8.10) and the slightly lower means of 0.065 (SD = 0.058), 0.097 (SD = 0.091), 0.124 (SD = 0.134), and 0.132 (SD = 0.191) in Mplus version 8.5;
The condition with 100 targets, five raters, and a WTC of 0.95, which had a mean RMSEA of 0.051 (SD = 0.044) in the more recent and of 0.068 (SD = 0.152) in the older version;
The conditions with 250 targets, two raters, and WTC of 0.90 and 0.95, which had mean RMSEA of 0.055 (SD = 0.048) and 0.072 (SD = 0.070), respectively, in Mplus versions 8.7 and 8.10 and of 0.055 (SD = 0.050) and 0.076 (SD = 0.099), respectively, in version 8.5.
Apart from those seven conditions, the mean RMSEA across 1000 replications in all conditions led to accepting the correctly specified models.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









