1. Introduction
Bearings are the most frequently used component in a rotary machine. Bearing failures could lead to unpredictable productivity losses for production facilities. Therefore, bearing fault diagnosis has attracted significant attention from the research and engineering communities over the past decades. Generally, a bearing fault diagnosis process can be decomposed into three steps: data acquisition, feature extraction, and fault condition classification.
Vibration-based signal analysis in the time-frequency domain has been a major technique for bearing fault diagnosis. Several statistical parameters in the time domain and the frequency domain, such as the root mean square, kurtosis, and skewness, have been shown to be capable of fault detection [
1,
2]. In [
1], nine features in the time domain and seven features in the frequency domain were used for bearing fault detection. We call this method the time domain and frequency domain statistical formulas (TDFDSFs) method throughout this paper.
Time-frequency analysis methods, such as the short-time Fourier transform [
3], the Wigner Ville distribution [
4], and the wavelet transform [
5], have been widely used to detect bearing faults since they can provide abundant information about machine faults. However, these time-frequency based methods often require a lot of computation time, as they involve a lot of Fourier transforms or convolution operations. Moreover, due to the factors of clearance and nonlinear stiffness of bearings, the vibration signals are often characterized by nonlinearity. Therefore, these commonly used time-frequency analysis techniques may exhibit limitations because of their linearity assumption.
In order to overcome this problem, several nonlinear parameter estimation techniques were applied to extract defect-related features hidden in the measured signals. In [
6], Hong and Liang combined the Lempel-Ziv complexity with the continuous wavelet transform and found that the new method was more effective in bearing fault diagnosis. Then, the methods based on approximate entropy (ApEn) [
7] and multiscale entropy (MSE) [
8] were used for bearing fault diagnosis. Both ApEn and MSE can be used for measuring the regularity of a time series. Although these entropy-based methods are simple and require much less computation time, they have very good performance in bearing fault diagnosis.
In [
9], a new entropy based method named permutation entropy (PE) was exploited to assess the status of a rotary machine. The PE was introduced by Bandit [
10]. It estimates the complexity of time series through the comparison of neighboring values. The PE has been widely used in a number of applications, such as electroencephalography (EEG) signal analysis [
11,
12], stock market analysis [
13], tool breakage detection in end milling [
14], and chatter detection in turning processes [
15]. Time series derived from physiological and mechanical systems are usually complicated and consist of multiple temporal scale structures. Based on a single scale algorithm, the PE based method has limited performance in analyzing these complicated data. To overcome this shortcoming, based on the concept of multiscale [
16], Aziz proposed a new method termed mutliscale permutation entropy (MPE) to calculate entropy over multiple scales [
17]. In addition, Li employed the MPE method to track the effect of anesthetic drug sevoflurane on the brain and showed that the MPE index outperforms the single scale PE index [
18].
In this paper, we introduce MPE as a feature extractor of the bearing fault diagnosis system. After extracting feature vectors by MPE, the multi-class support vector machine (SVM) [
19] is used as a classifier. The SVM is probably the most popular and powerful machine learning algorithm because of its well established theoretical background and intuitive geometrical interpretation. Nowadays, the SVM is widely applied and has even served as the baseline in computer vision, pattern recognition, information retrieval, and data mining,
etc. In our simulations, the vibration signal datasets of bearing from Case Western Reserve University (CWRU) [
20] are utilized. Experimental results demonstrate that the proposed MPE-based algorithm provides a significantly higher accuracy of prediction than the traditional feature extraction methods.
The remainder of this paper is organized as follows:
Section 2 provides a review of permutation entropy. In
Section 3, the proposed algorithm based on multiscale permutation entropy is introduced. In
Section 4, several examples are presented to demonstrate the effectiveness of the proposed MPE algorithm. A conclusion is given in
Section 5.
2. Permutation Entropy
Given a time series {
x(
k),
k = 1, 2, …,
N}, the
m-dimensional delay embedding vector at time
i is defined as:
where
m is the embedded dimension and
τ is time delay. We say that
has a permutation
if it satisfies:
where 0 ≤
ri ≤
m − 1 and
ri ≠
rj.
There are
m! possible permutations of for an
m-tuple vector. For each permutation
π, we determine the relative frequency by:
The PE of
m dimension is then defined as:
The maximum value of
HPE(
m) is log(
m!) when all possible permutations appear with the same probability. Therefore, the normalized permutation entropy (NPE) can be obtained as:
For any time series, 0 ≤
HNPE(
m) ≤ 1 is satisfied.
In the remainder of this section, we explain the PE algorithm by using an example of the time series in Equation (6):
We set the parameter of time delay
τ to be 1. When the embedded dimension
m is 3, five embedding vectors can be obtained as:
There are six (3!) possible permutations of dimension 3, which are denoted by
π012,
π021,
π102,
π120,
π201, and
π210, respectively. The embedding vectors
and
have the permutation type
π012, the vector
has the permutation type
π102, while both
and
correspond to
π201. Therefore, the probability of each permutation is given by:
The PE and the NPE of dimension 3 are then calculated by:
The value of PE depends on the selection of the embedding dimension
m and delay
τ. If
m is too small, the scheme will not work since there are too few distinct states. However, it is often inappropriate to choose
m as a large value for detecting the dynamic change of a time series [
17]. Moreover, Cao [
21] indicated that the delay
τ is related to the signal for analysis and its sampling rate.
3. Proposed Bearing Fault Diagnosis System Based on Multiscale Permutation Entropy and Support Vector Machine
The concept of multiscale analysis was originally proposed by Costa [
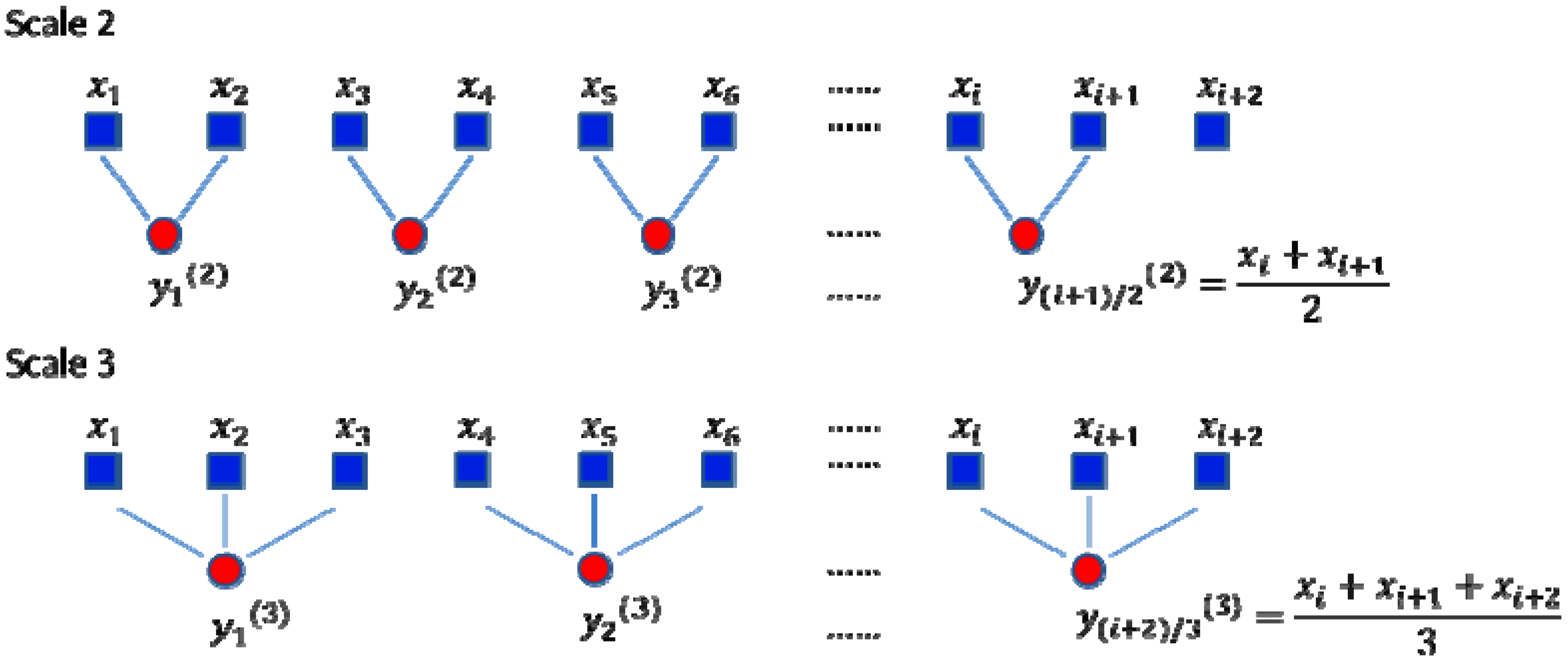
16], who indicated that the single scale entropy algorithm yielded contradictory results when applied to real-world datasets obtained in health and disease states. In regard to this, Costa proposed a coarse-grained procedure to obtain multiple scale time series from the original time series. Then, the entropy at each scale is calculated to analyze the physiological signal. Given a time series
x = {
x1,
x2, …,
xN}, one can construct a consecutive coarse-grained time series
y(s) corresponding to the time scale
s. First, the original time series is divided into non-overlapping windows of length
s. Second, the data points inside each window are averaged by Equation (11). The schematic illustration of the coarse-grained procedure is shown as in
Figure 1:
Figure 1.
Schematic illustration of the coarse-grained procedure modified from [
16].
Figure 1.
Schematic illustration of the coarse-grained procedure modified from [
16].
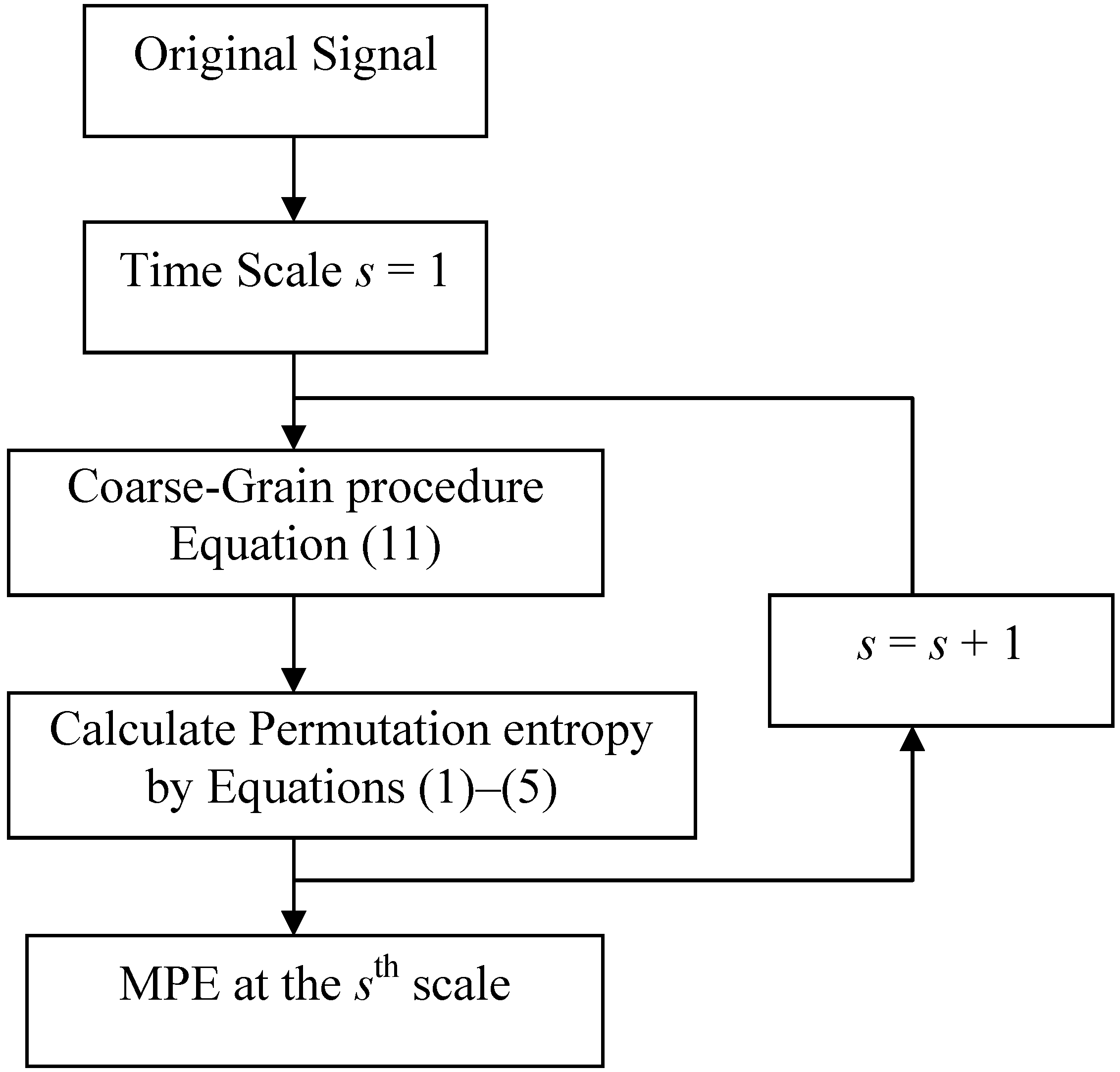
Based on the concepts of multiscale and PE, Aziz proposed a new method termed mutliscale permutation entropy (MPE). In MPE analysis, the entropy of the coarse-grained time series at each scale is calculated by the NPE algorithm defined in Equations (3)–(5). Li employed MPE analysis to track the effect of anesthetic drug sevoflurane on the brain and showed that the MPE index outperforms the single scale PE index [
18]. In this paper, motivated by the previous efforts, we investigate the utility of MPE for detecting a variety of bearing faults in rotary machines. The flowchart of the multiscale permutation entropy algorithm is as seen in
Figure 2.
Figure 2.
Flowchart of the multiscale permutation entropy algorithm.
Figure 2.
Flowchart of the multiscale permutation entropy algorithm.
In addition to multiscale permutation entropy, our proposed method also adopts the SVM technique. The SVM was originally a deterministic algorithm for finding the linear separating hyperplane of a binary labeled dataset. Compared to the perceptron learning algorithm (PLA), which eventually finds a random separating hyperplane in a linear-separable dataset, the SVM generates a unique hyperplane in a given dataset. This hyperplane provided by the SVM not only has an intuitive geometrical interpretation, but also been proved theoretically to balance the in-sample error (Ein) and the generalization error.
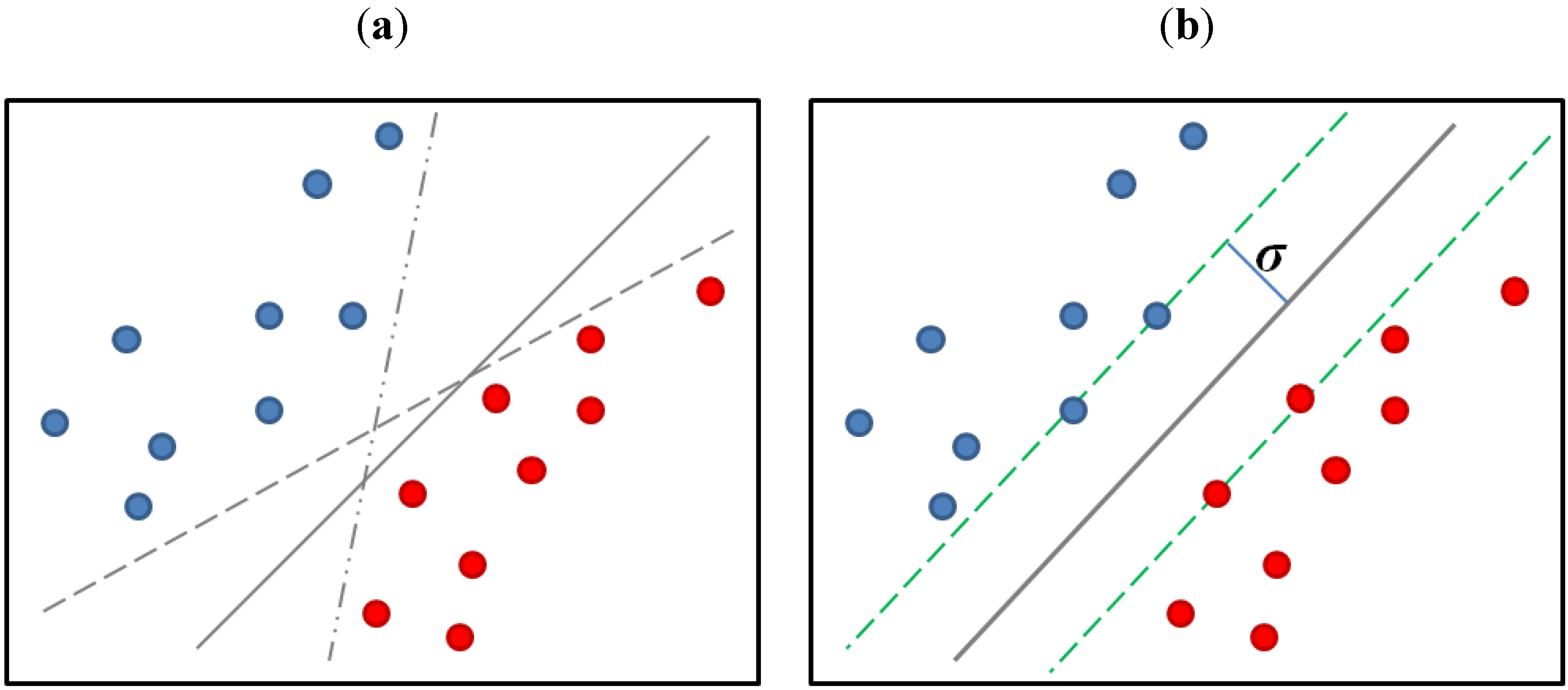
Given a binary labeled dataset as shown in
Figure 3, we found that there are many hyperplanes that can be used to separate red circles (positive: 1) from blue circles (negative: −1), such as the three gray lines plotted in
Figure 3a. These gray lines may come from the PLA, the Adaline algorithm, the least square regression algorithm, or the logistic regression algorithm, where the last three ones determine their separating hyperplanes based on the corresponding objective functions but without a direct geometrical interpretation. By contrast, the SVM was originated from a geometrical view as shown in
Figure 3b. It seeks a separating hyperplane which keeps its distance from the positive and negative samples as far as possible without training error. In other words, the SVM desires a separating hyperplane that can maximize the
margin σ between the positive and the negative samples. It can effectively tolerate the error of the unseen samples and was claimed to have good generalization ability. The objective function of the SVM is then modeled as a constraint optimization problem. In our algorithm, the SVM classifier is implemented by the LIBSVM software [
20].
Figure 3.
Different separating hyperplanes resulted from different algorithms: (a) the hyperplanes (three gray lines) resulted from general linear classification algorithms; (b) the hyperplane (gray line) resulted from the linear SVM algorithm where the margin σ is the distance between the hyperplane and the nearest sample.
Figure 3.
Different separating hyperplanes resulted from different algorithms: (a) the hyperplanes (three gray lines) resulted from general linear classification algorithms; (b) the hyperplane (gray line) resulted from the linear SVM algorithm where the margin σ is the distance between the hyperplane and the nearest sample.
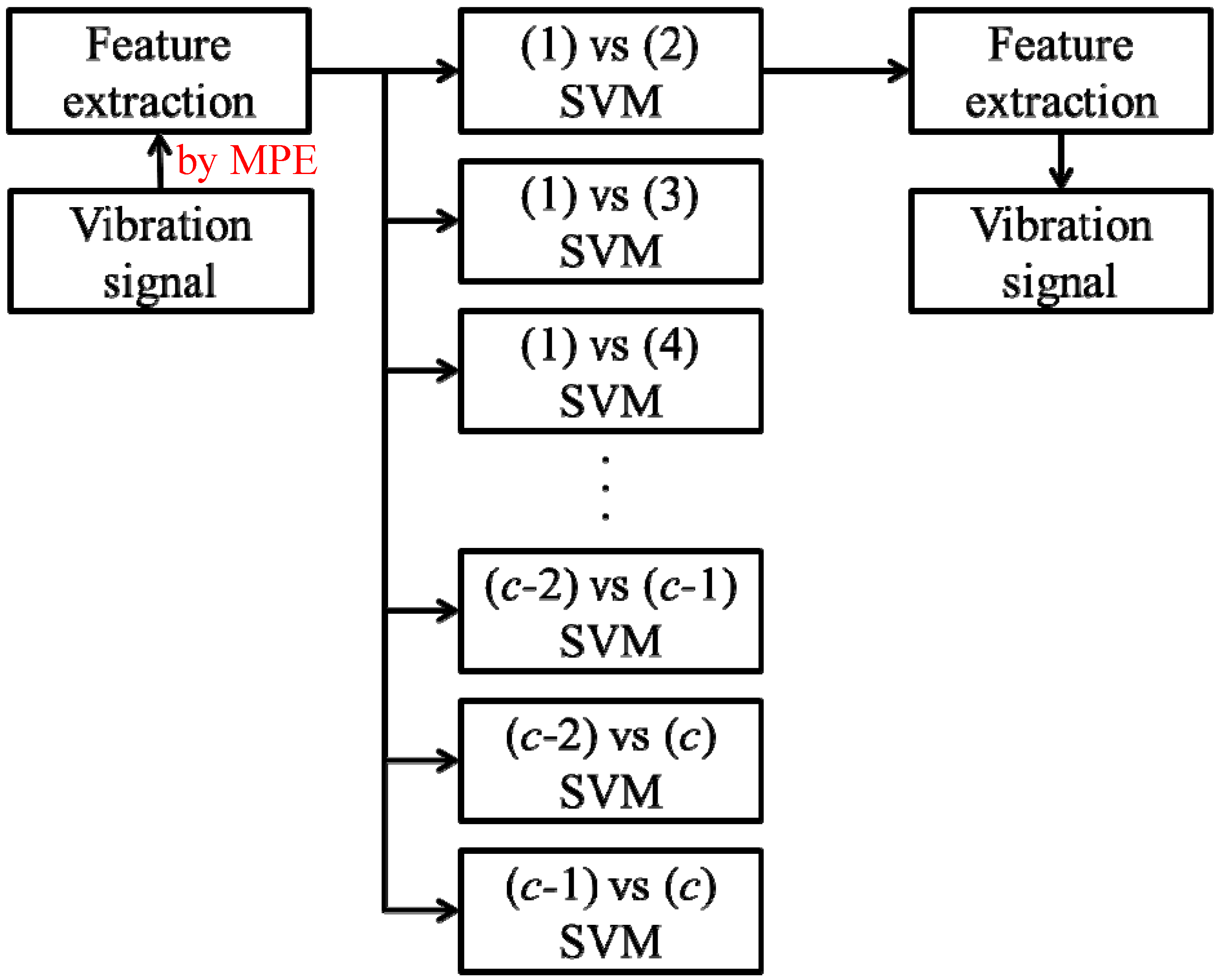
The overall flowchart of our proposed framework is shown in
Figure 4. As recommended in [
20], each feature is rescaled to the range of 0 to 1. The one-
versus-one (OVO) SVM is chosen to classify different bearing faults. Assume that there are totally
c classes. The OVO SVM builds a binary classifier for each pair of classes, which means that, in sum,
c(
c − 1)/2 binary classifiers are built. When given an input sample
x, each classifier predicts a possible class label. The final predicted label is the one with the most votes among all
c(
c − 1)/2 classifiers.
Figure 4.
The flowchart of our framework with the one-versus-one SVM of c classes.
Figure 4.
The flowchart of our framework with the one-versus-one SVM of c classes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}