1. Introduction
In this paper, we are particularly interested in providing new statistical tools that help in the process of modelling univariate time series processes. We are focused on the selection of the appropriate time lags when data faced by the modeller might potentially come from either a linear or a nonlinear dynamic time process. Needless to say, a correct estimate of the lag is essential in forecasting basically because the introduction of delayed information into the dynamic models significantly changes their asymptotic properties. Traditionally, autocorrelation and partial autocorrelation coefficients have been utilized by empirical modellers in specifying the appropriate delays. However, it is well established [
1] that processes with zero autocorrelation could still exhibit high order dependence or nonlinear time dependence. This is the case for some bilinear processes and even for purely deterministic chaotic models, among others. In general, autocorrelation-based procedures may be misleading for nonlinear models, and so might fail to detect important nonlinear relationships present in the data, and are therefore of limited utility in detecting appropriate time delays (lags), especially in those scenarios where nonlinear phenomena are more the rule than the exception. The relevance of non-linear time dependent processes in science and social sciences, as well as in macroeconomics and finance, is well established. However, statistical tools that help to specify what lag(s) to use in a nonlinear description of an observed time series are scarce.
From a statistical point of view, this situation has motivated the development of tests for serial independence (see [
2] for a review) with statistical power against alternative hypotheses that exhibit general types of dependence. The vast majority of these statistical tests are of nonparametric nature, hence trying to avoid restrictive assumptions on the marginal distributions of the model. However these tests are not designed for selecting relevant lags. This partly explains the relative scarcity of nonparametric techniques for investigating lag dependence, regardless the linear or nonlinear nature of the process, which is an aspect that is unknown in most of the practical cases. Some notable exceptions to this relative scarcity are [
3–
6]. A common characteristic of most of these techniques is the use of entropy-based measures to identify the correct lag. Particularly, in [
5,
6], the use of permutation entropy, evaluated at several delay times, is theoretically motived and then applied to identify from a time series the characteristic lag of the generating system. Interesting physical applications of this approach are [
7,
8]. In order to complete the paper, the new proposal technique is compared with the widely applied autocorrelation function and with recent techniques based on permutation entropy.
In this paper, we construct a new nonparametric runs statistic, based on symbolic analysis, which estimates the lag that best describes a time series sample. The versatile nature of runs tests is well-known for the relevant statistical literature as it has been used for analyzing independence, symmetries, randomness,
etc. Furthermore, symbolic analysis is a field of increasing interest in several scientific disciplines (see [
9]). It has foundations in information theory and in theory of dynamic systems. For example, properties of symbolic encodings are central to the theory of communication [
10]. Furthermore, there is a well-established mathematical discipline, namely, symbolic dynamics, that studies the behavior of dynamical systems. This discipline started in 1898 with the pioneering works of Hadamard, which developed a symbolic description of sequences of geodesic flows, and was later extended by [
11], who coined the name of symbolic dynamics. [
12] showed that a complete description of the behavior of a dynamical system can be captured in terms of symbols. This observation is crucial for understanding this paper because important characteristics of a random variable can be also captured by analyzing the symbols derived from it.
The paper finally shows that the new approach can be useful for model identification, and it is applied to the a real time series, particularly, to the New York Stock Exchange.
3. Constructing the Statistic
The classical runs test is defined for
q = 2 where only two categories or symbols are used. This can be considered in a multinomial scenario with
q > 2. For completeness we will give the construction of the runs test for i.i.d (identically and independently distributed) in the multinomial case that was developed in [
13].
Let
be the random variable counting the number of runs in {
Xi}
i∈I (if this sequence is not categorical we will use the symbolization procedure given by
Equation (1)). Define the following indicator function
The variable
is a Bernoulli variable
B(
p) with probability of success
for all
j = 2, 3,…,
n. Then the statistic
remains as:
and its expected value is
The estimation of the variance of
is more complicated and can be computed as follows (see [
13] for a detailed explanation of the computation):
When the lag order of the underlying process is known, say
p, one can consider the following
p time series
For each one of the time series Γ
j one can compute the normalized statistic
Under the null of i.i.d. the statistic
is asymptotically normal distributed (see [
13]).
Notice that if
p is the most relevant lag in the underlying data generating process, then the runs statistic
measured on each Γ
j will differ from its expected value more than for any other lag. Then we define
as the absolute value of the sum of the statistic
for
j = 1, 2,…,
p divided by the square root of
p. In the case that the time series {
Xi}
i∈I is i.i.d., and therefore no relevant lags are present, the distribution of the statistic
is the folded standard normal distribution, and hence its expected value is
.
Hence, if
p0 is the most relevant lag describing the dynamics of the underlying data generating process then
and
has to be greater than
.
4. Monte Carlo Simulation Experiments
In order to show the statistical power performance of the
statistic under different scenarios, we have considered (and therefore simulated) the following data generating processes (DGPs) because of its rich linear and nonlinear variety. The models are the following:
DGP 1 Xt = 0.3Xt−1 + ∈t,
DGP 2 Xt = |0.5Xt−1|0.8 + ∈t,
DGP 4 Xt = 0.7∈t−1Xt−2+∈t,
DGP 6 Xt = 4Xt−1(1 − Xt−1),
DGP 7 Xt = ∈t ∼ N(0, 1).
We have considered mainly nonlinear models, but also some linear ones in order to study and compare the procedure with other statistical tools that are commonly used for model specification. Model 1 is a linear processes while Models 2–6 are nonlinear. DGP 1 is an AR1 autoregressive with decaying memory at lag order 1, so the procedure should detect (select) p = 1. DGP 2 is a nonlinear autoregressive model of order 1. DGP 3 is a nonlinear moving average processes of order 2, and then the statistical process is expected to select p = 2. DGP 4 is bilinear with white noise characteristic of orders 2 and 1. Conditional heteroskedastic models (i.e., those with structure in the conditional variance) are commonly employed in financial applications (for example time series that show periods of high and low market uncertainty), and accordingly, it is interesting to know about the behavior of the procedure under these kind of nonlinearities in the conditional variance, so we have included DGP 5. Finally, a purely deterministic model (DGP 6) and an independent and identically distributed stochastic process (DGP 7) are incorporated as they represent two models of opposite nature.
To evaluate the performance of the nonparametric method in finite samples, we compute 1000 Monte Carlo replications of each model, and we consider 6 lags (p). In general, experiments using large data sets are desirable, however situations do occur in which the number of available data is small. Statistical techniques, especially those that are model-free, as it is the case, are very sensitive to the number of observations. For this reason, in the Monte Carlo experiment, we study the effect of small sample size on the outcome of the statistical procedure. We present the results for several different sample sizes, namely, T = 120, 360, 500, 1000, 5000 and 10,000. In order to estimate
it is necessary to fix the number of quantiles that we will use to symbolise the time series under consideration, in this case we select q = 3, thus only 3 symbols are used to obtain a conclusion about the dynamic structure of the time series under study.
As mentioned in the introduction, we also compare the proposed method with the widely applied autocorrelation functions and with the permutation entropy based technique, as used in [
5], which is related to [
6] in the sense that both papers look for the lag that minimizes the permutation entropy. In order to apply the procedure we also fix the embedding reconstruction dimension at
m = 3, and we will refer to it as
h3.
Tables 1–
7 show the percentage of times that the
statistic, autocorrelation function (ACF) and partial autocorrelation function (PAF), estimate the lag parameter
p in 1000 Monte Carlo replications. For sample sizes T = 1000 (or larger),
always selects the correct lag for the linear autoregressive process (DGP 1), the same can be said for ACF and PAF. As the sample size is reduced (to T = 360),
statistic reduces its statistical power to 93.2%, while autocorrelations functions only deteriorate their power to 99.7%. This is to be expected because autocorrelation functions are ideal for linear processes: even for the smallest sample size its empirical behavior is high (around 90%). According to these results, if the underlying process is linear, the researcher may either use autocorrelations functions or
for sample sizes above 500. It is not convenient to use
if sample is below 360 observations. Similarly, for DGP 2, which is a nonlinear variation of the autoregressive DGP 1, the both approaches perform extremely well for sample sizes large than 1000 observations. For these two processes, when compared with
h3 for DGP 1 and DGP 2, it can be observed that
outperforms
h3.
On the other hand, if the lag-dependence comes from a nonlinear moving average process, we can observe clear differences in favour of the symbolic-runs proposal: The results for DGP 3 show for large data sets (5000 and 10,000) that
is ideal, as it detects the correct lag 100% of the time, while autocorrelation functions correctly estimate the lag only 30% of the time, regardless the sample size, although a better performance is obtained for h3. With DGP 4 we study a combination of lag dependence in an autoregressive component of (dominant) order 2, and moving average lag dependence of order 1. Clearly, the results for this bilinear processes show that
captures the correct lag, while ACF and PAF do not. The empirical evidence is in favor of
when compared with h3.
As commented earlier, if delay structure is introduced via the second conditional moment of the stochastic process (variance), a practitioner would like to have a statistical procedure that might also detect the correct lag. This is what we study in DGP 5. The proposed statistic is very effective in detecting the correct lag for T = 1000 or higher. However, it is remarkable that autocorrelation functions correctly estimate lag less that 50% of the time for all sample sizes. In comparison with the permutation entropy based technique, h3,
outperforms it.
Finally, the last two models (DGP 6 and DGP 7) are also illuminating. The first one is a purely deterministic logistic model, so no stochastic terms are added into it; and the second one is a purely normal distribution. Autocorrelation based approaches perform poorly in detecting the correct lag (i.e., lag 1) for the logistic model. Further, the results of ACF and PAF for the normal samples are statistically not distinguished from those obtained for the logistic equation. In contrast the
procedure detects, even for small sample sizes, that there is a dependence structure and that it comes from lag 1. Interestingly, for this pure deterministic process, the entropy based procedure is superior in these terms, hinting that permutation entropy is very effective when there is no noise terms.
The results provided for DGP 7 allows to understand that to fail to detect the most relevant lag parameter(s) is equivalent to find that all considered lags are equally important, that is to say,
, where τ is the number of lags that the user has considered in the study. In our Monte Carlo experiment τ = 6 and then δ = 16.66667%. Therefore, for a lag parameter to be detected, the percentage of times
identify that lag should be above
, for a nominal level α, where n is the number of Monte Carlo replications and zα is the quantile 1 − α of the Normal standard distribution N(0, 1). In our experiment γ = 18.599 for a confidence level of α = 0.05.
5. Model Identification
In the previous sections we have shown, first theoretically and then empirically, that the proposed method correctly estimates the lag that a data analyst might use to modelling time series data. Now we are concerned with trying to identify the appropriate generating model with the help of
evaluated at several lags. For instance, we are particularly interested in studying the behavior of
when the data generating process is an autoregressive linear model (AR(p)-model) and how it behaves for a moving average model (MA(p)-model). In the case of being able to discriminate between models, the statistic would not only be useful for selecting lags, but also to distinguish between models of very different nature. To evaluate the performance of
for identifying models, the following stochastic models have been studied:
AR(1) Xt = 0.5Xt−1 +∈t,
MA(1) Xt = 0.5∈t−1 +∈t,
AR(2) Xt = 0.5Xt−2 + ∈t,
MA(2) Xt = 0.5∈t−2 + ∈t,
ARMA(1,1) Xt = 0.4Xt−1 + 0.4∈t−1 + ∈t,
ARMA(1,2) Xt = 0.4Xt−1 + 0.4∈t−2 + ∈t,
MA(2;4) Xt = 0.6∈t−2 + 0.3∈t−4 + ∈t.
The shared characteristic of these models is that they all have a linear conditional mean. However, some are autoregressive, some moving averages of external shocks and some are mixture of linear processes. These models are well-known in univariate time series analysis, so for the statistic to be of some utility a clear detection of the lag and of the model is expected. Autoregressive models have memory, while moving average models do not. Accordingly, this essential difference should be detected. We compute the average value of the
statistic for sample sizes
n = 120, 360, 500, 1000, 5000, 10000 of 1000 Monte Carlo simulations for the seven models. We also do the same for a benchmark normal (0,1) model, which is an i.i.d. process and allows us to show if the expected value of
. is achieved empirically. Averages are given in
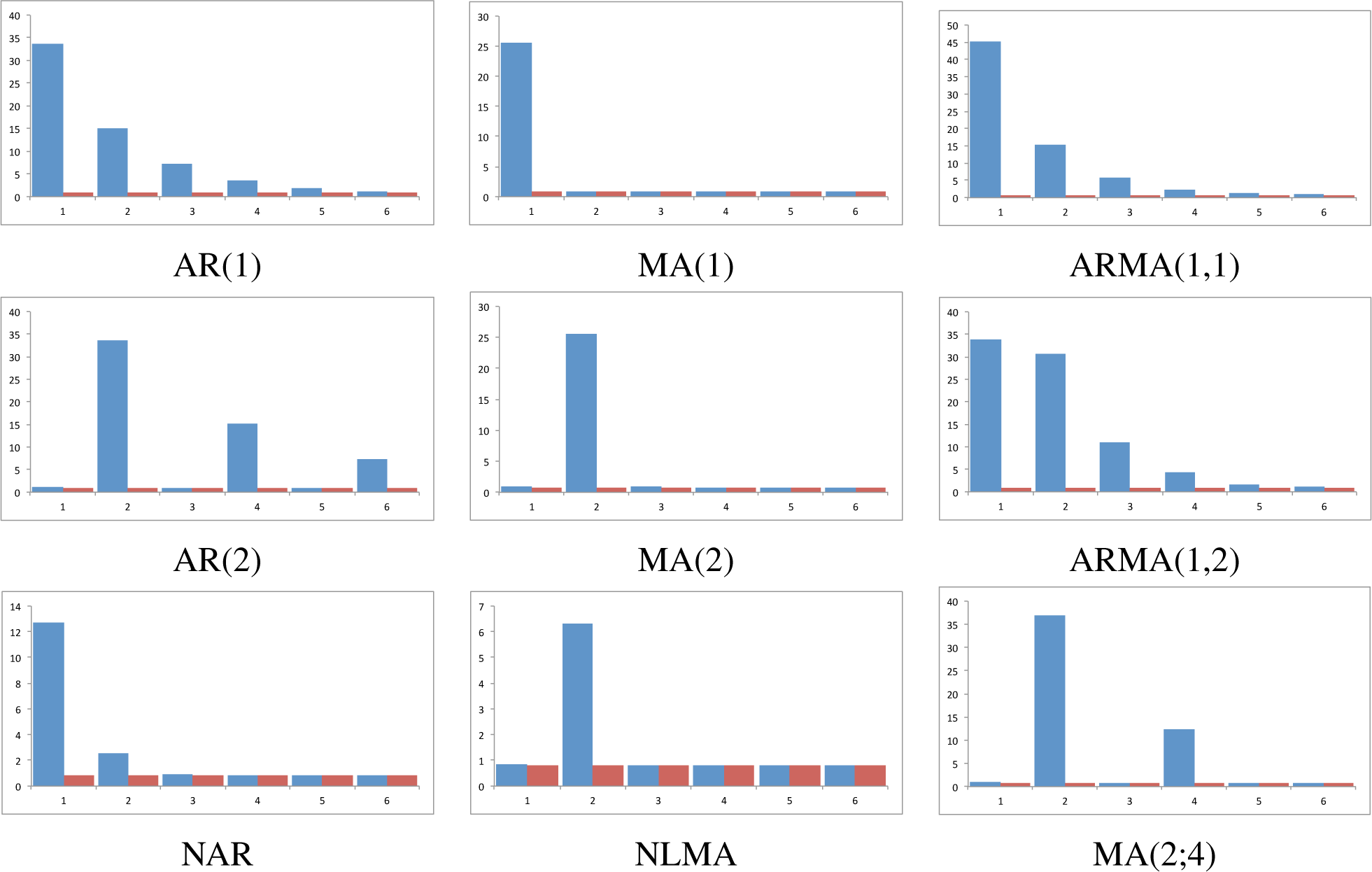
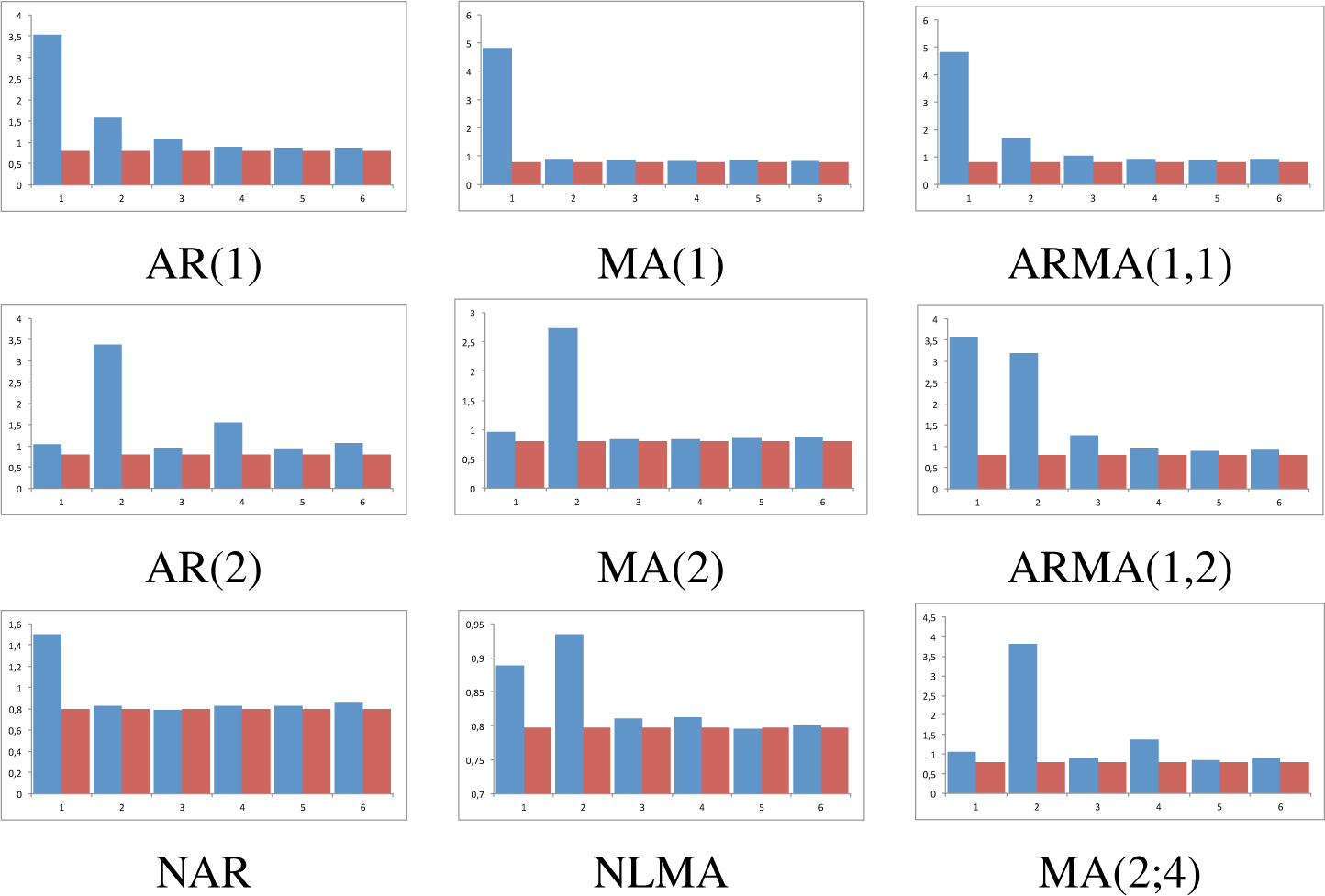
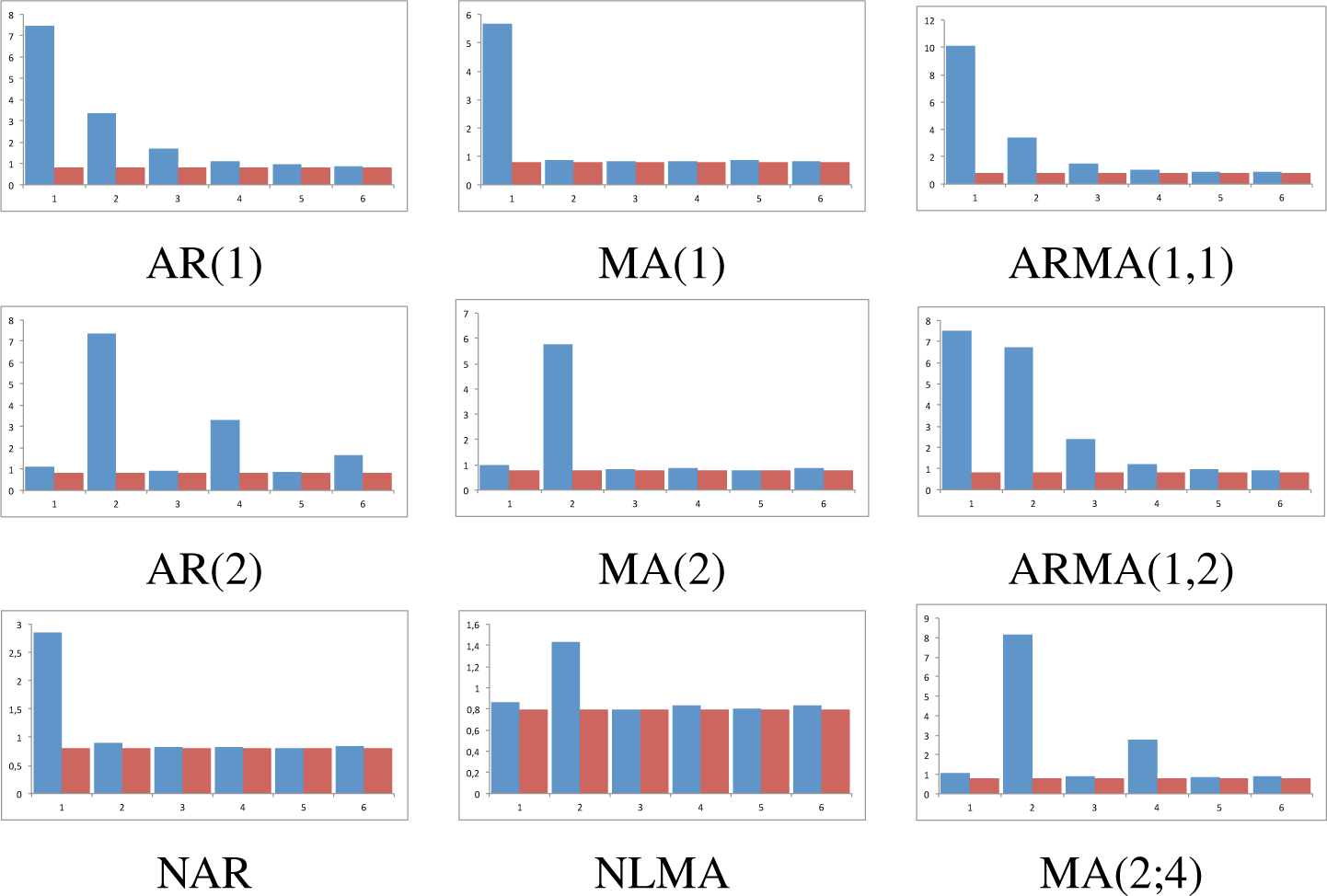
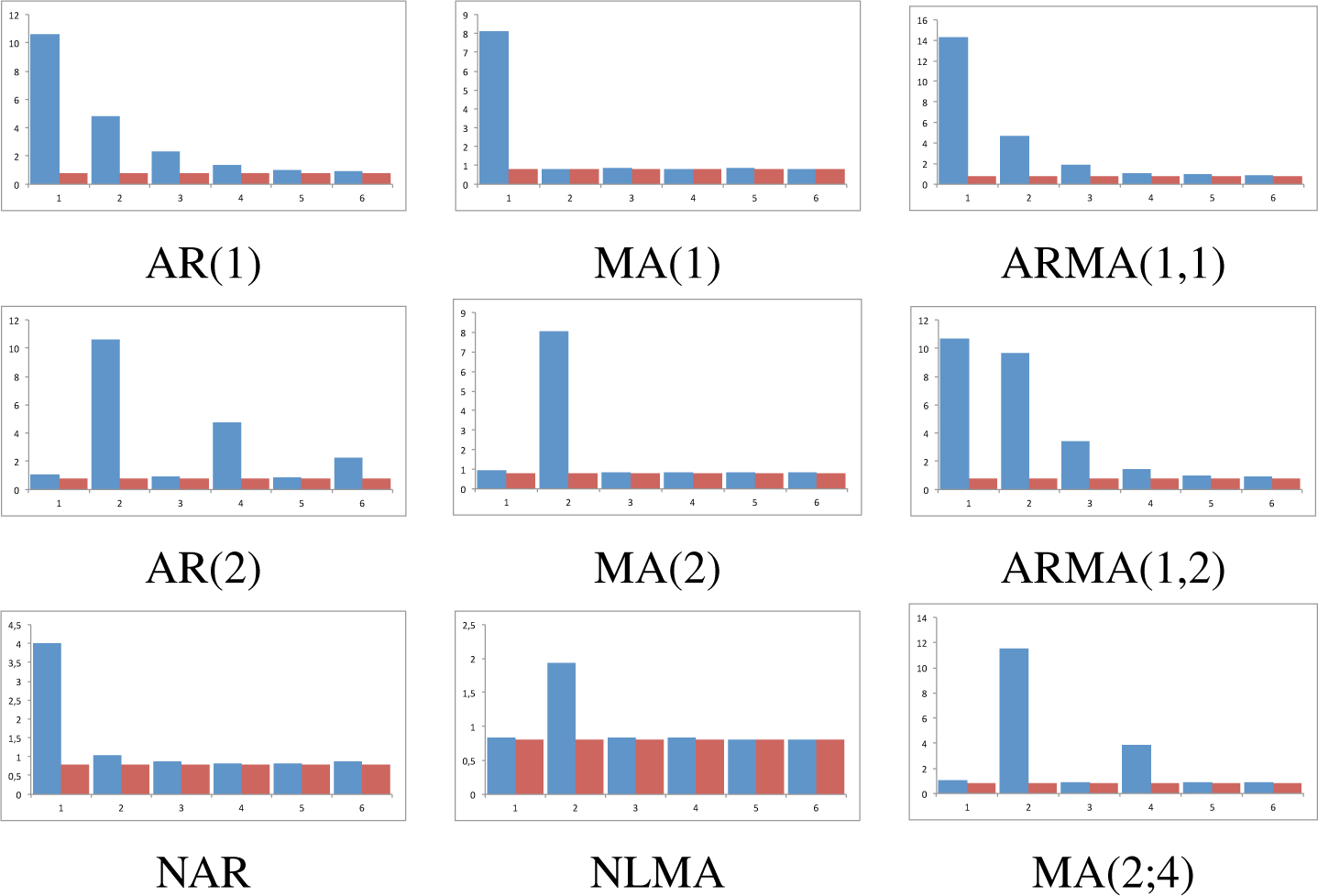
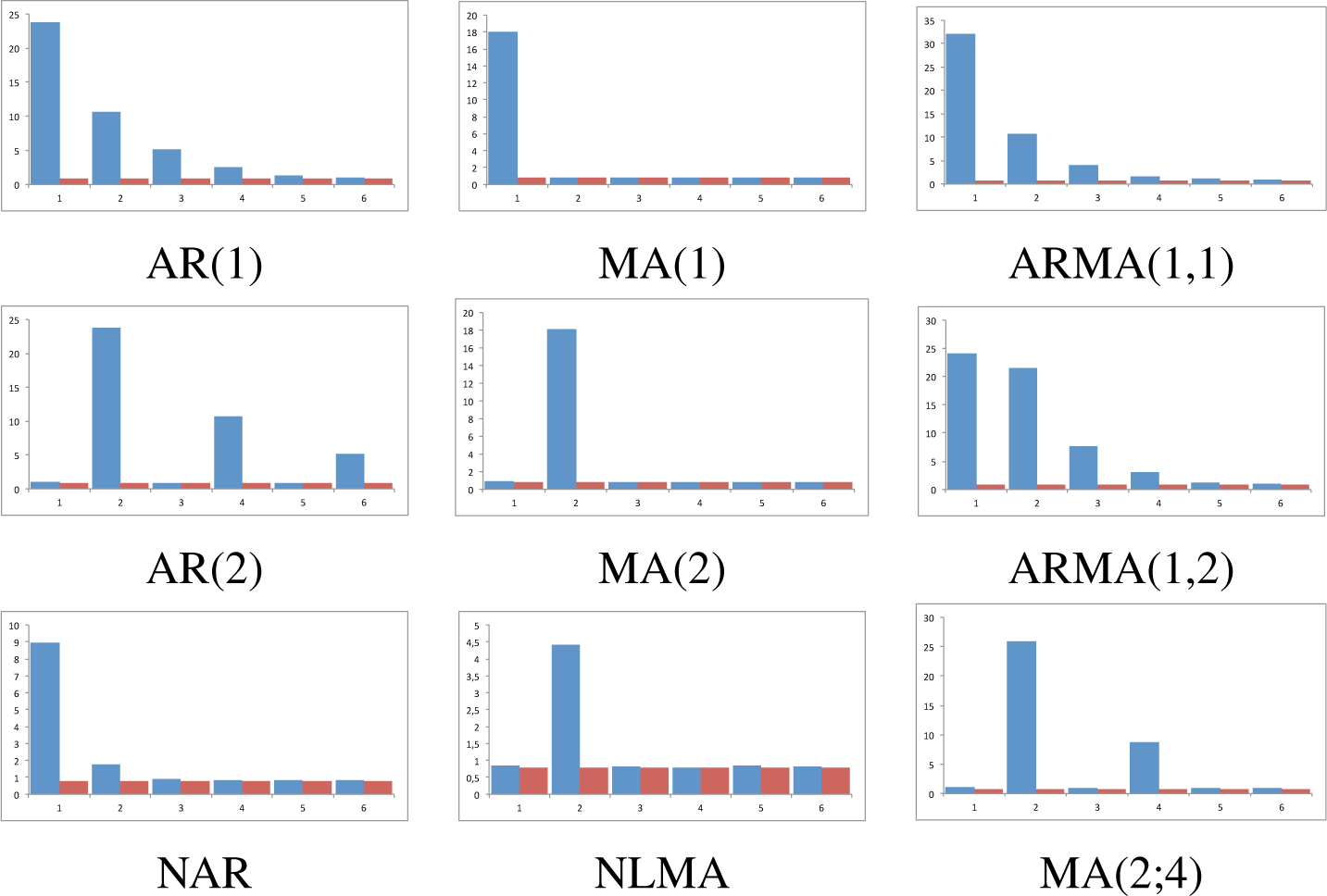
Figure 1, that reports the results for the largest sample size; while the behavior for the remaining sample sizes are given in
Figures 4–
8 which can be found in the
appendix.
For models AR(1) and AR(2) the statistic clearly shows an exponential decrease in
, indicating (a) that the correct lag is in 1 and 2, respectively; (b) that the data generating process has memory respecting the true lag, as each true lag is less relevant that the preceding one; and (c) this occurs for all sample sizes. Interestingly, observation (b) sharply contrast with classical techniques that do not gather this salient empirical fact. For models MA(1) and MA(2), our statistic also performs as expected for identifying the model: the true lag is detected, the memoryless basic property is clearly observed for all lags, and therefore cannot be confused with an AR(p) model. The results for mixed models are also of interest. Regarding the ARMA(1,1), the statistic reaches its maximum at the correct lag, namely, 1, and then decays exponentially to zero; given the MA structure at lag 1, statistic’s decay from its value at lag 1 and 2 is more prominent than in the case of an AR(1). This can also be devised for ARMA(1,2) model: the two relevant lags are clearly detected, namely, 1 and 2; the statistic does not decay very fast at lag 2 given its MA(2) structure, but it reappears for p > 2. Finally, in the MA(2;4) model, we have considered a moving average linear process with different weights in the two relevant lags, so we expect and observe that the proposed statistic firstly estimates the correct lag and then determines its relevance. To complete the analysis, the results are compared for two non linear models previously studied (DGP 2 and DGP 3), which are nonlinear counterparts of AR and MA models. It can be observed that the exponential decaying behavior is much faster in the nonlinear case than in the linear case, for the autoregressive models. For the moving average models, the values of the statistic, while being statistically significant, are lower than in the linear MA counterpart.
We now illustrate how our tools can be used for helping in the modelling process of real data. To this end we have considered a well-known empirical time series, namely, the returns obtained from closing values of the daily New York Stock Exchange (NYSE) index from 2000 to 2008 (
Figure 2).
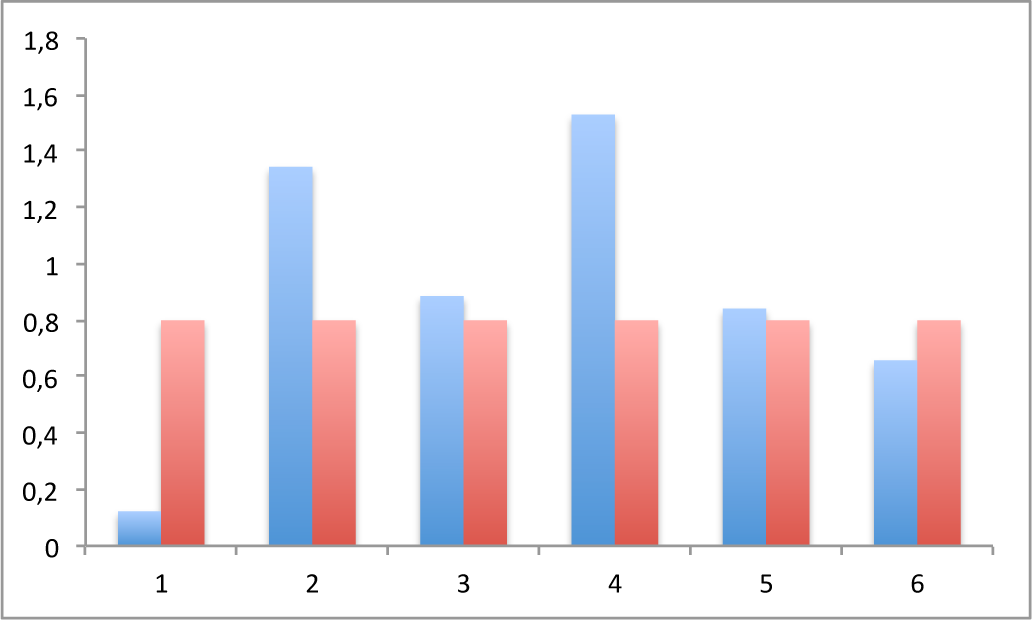
Given the series of returns, our proposal consists of using the tools previously presented. To this end we compute
for several lags for the selected time series. The results are given in
Figure 3. According to the results, our statistical procedure identifies lags 2 and 4, so the modeler is recommended to use these two lags. As regarding the identification of the underlying model, in view of the
Figure 3 when compared with
Figure 2, it does not seem that the model is of an autoregressive linear nature, and seem to be closer to a moving average process where lags 2 and 4 will play a relevant role.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}