3.1. Attack Scenario
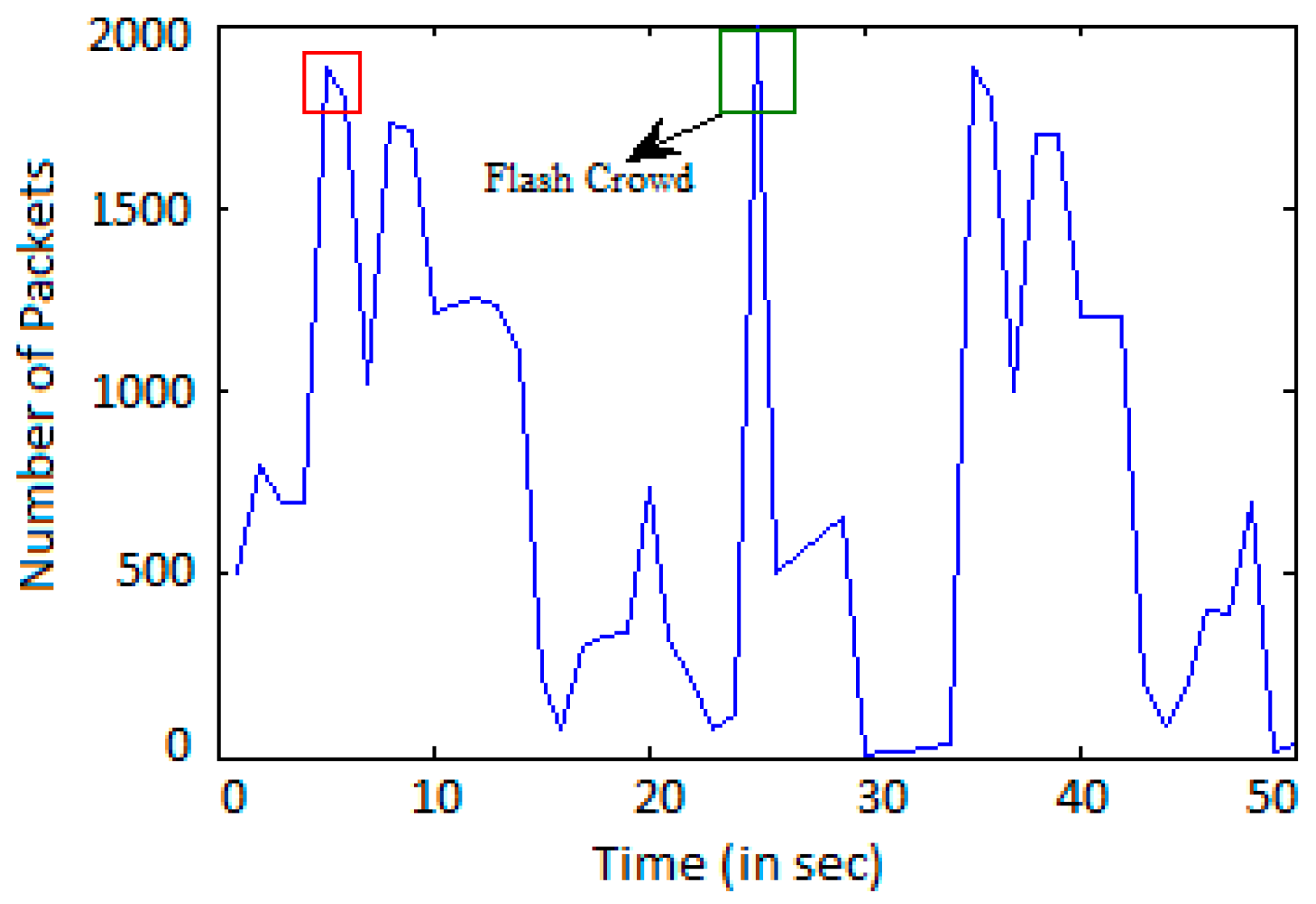
A layer seven DDoS attack on a web server is carried out by multiple abnormal clients sending massive HTTP GET requests to the web server. There are some cases when multiple normal clients transmit a huge HTTP GET request, but this could not be treated as DDoS attack. The difference between the above two cases is that in the second case, there is no particular order of the flow. There can be a high value and low value of the flow count at different instants of time. A normal client or human client accessing the web server in a random fashion results in the number of HTTP GET request counts being random. However, in the case of an attack, the clients are equipped with the automated program and, therefore, transmit an HTTP GET request in a particular fashion to overwhelm the web server.
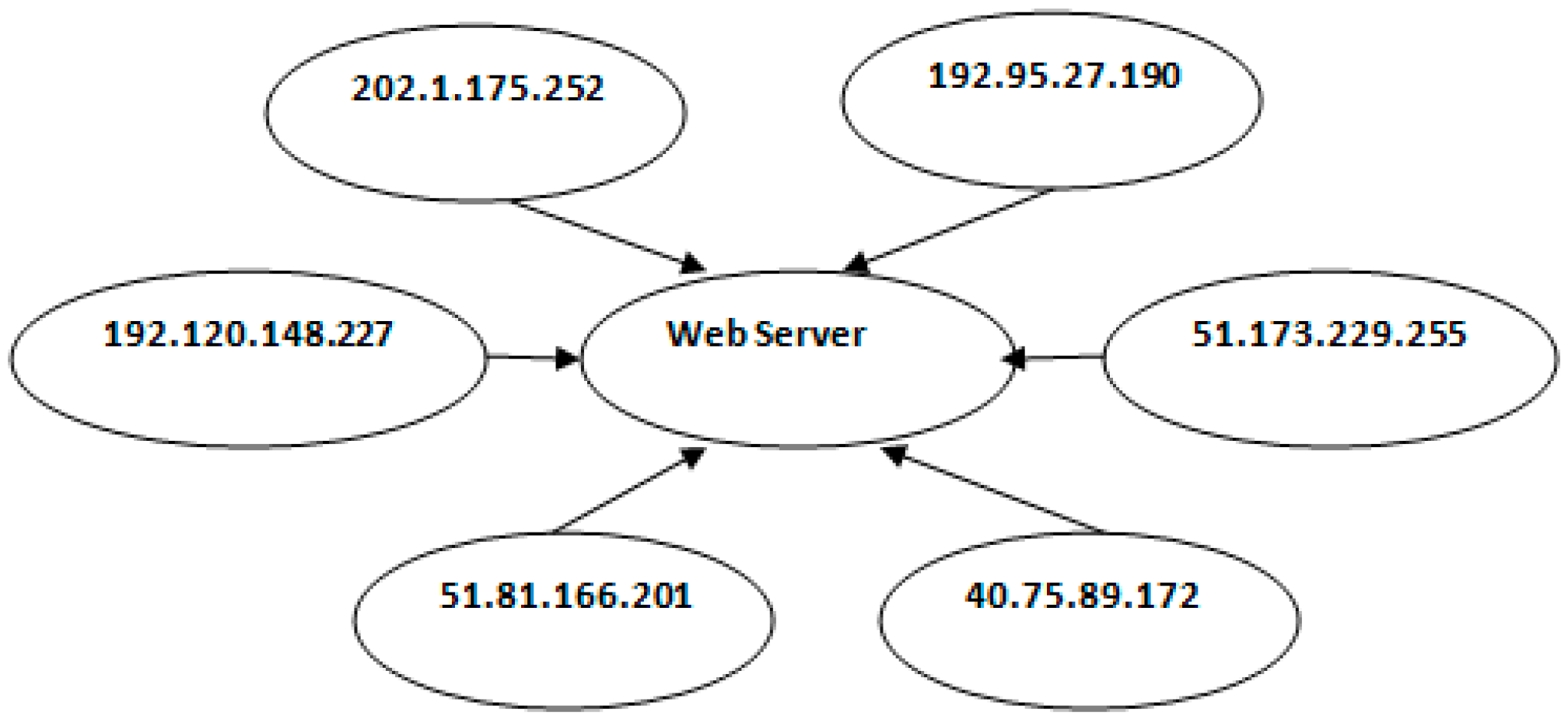
Figure 1 provides a typical DDoS attack scenario.
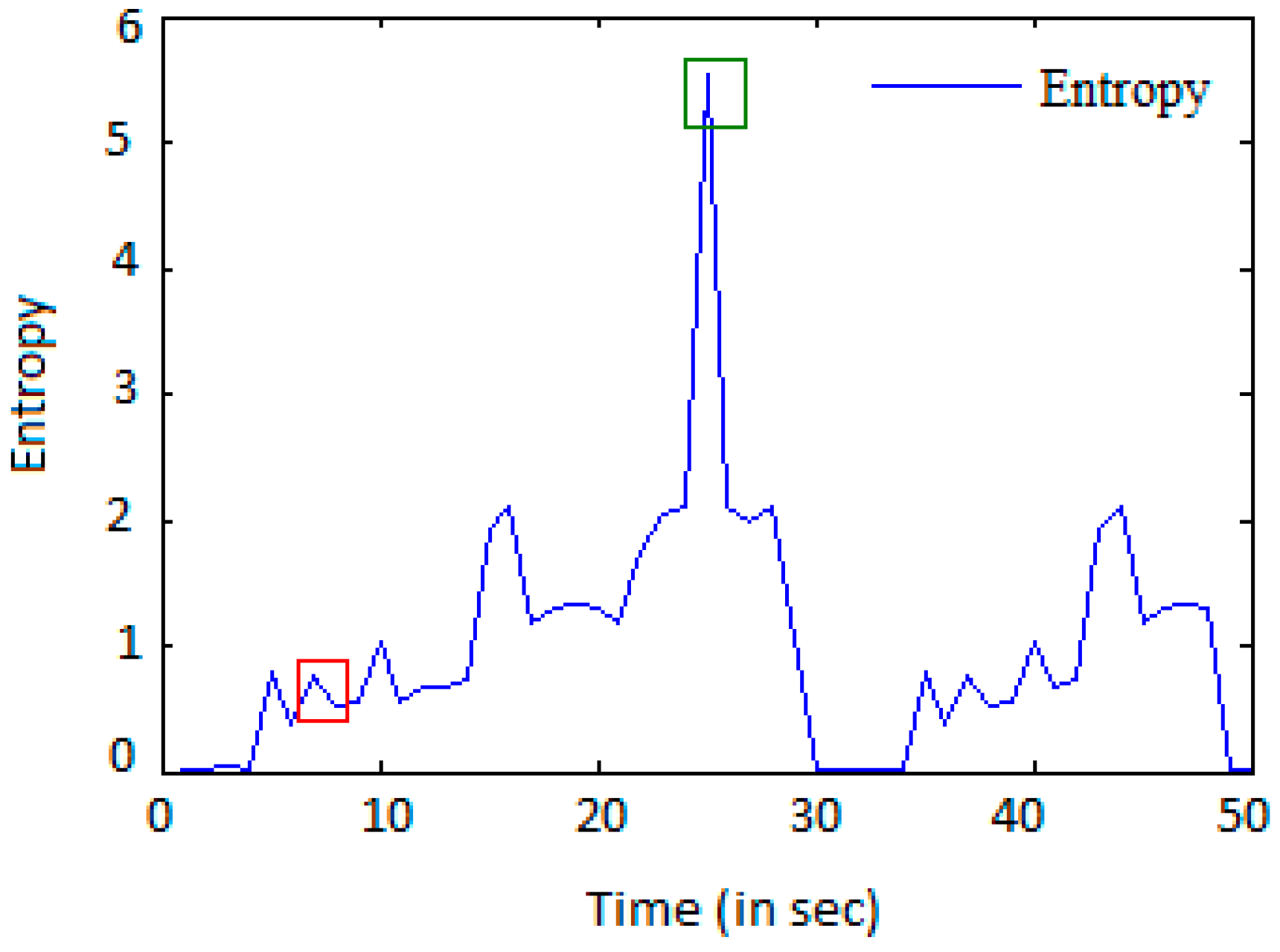
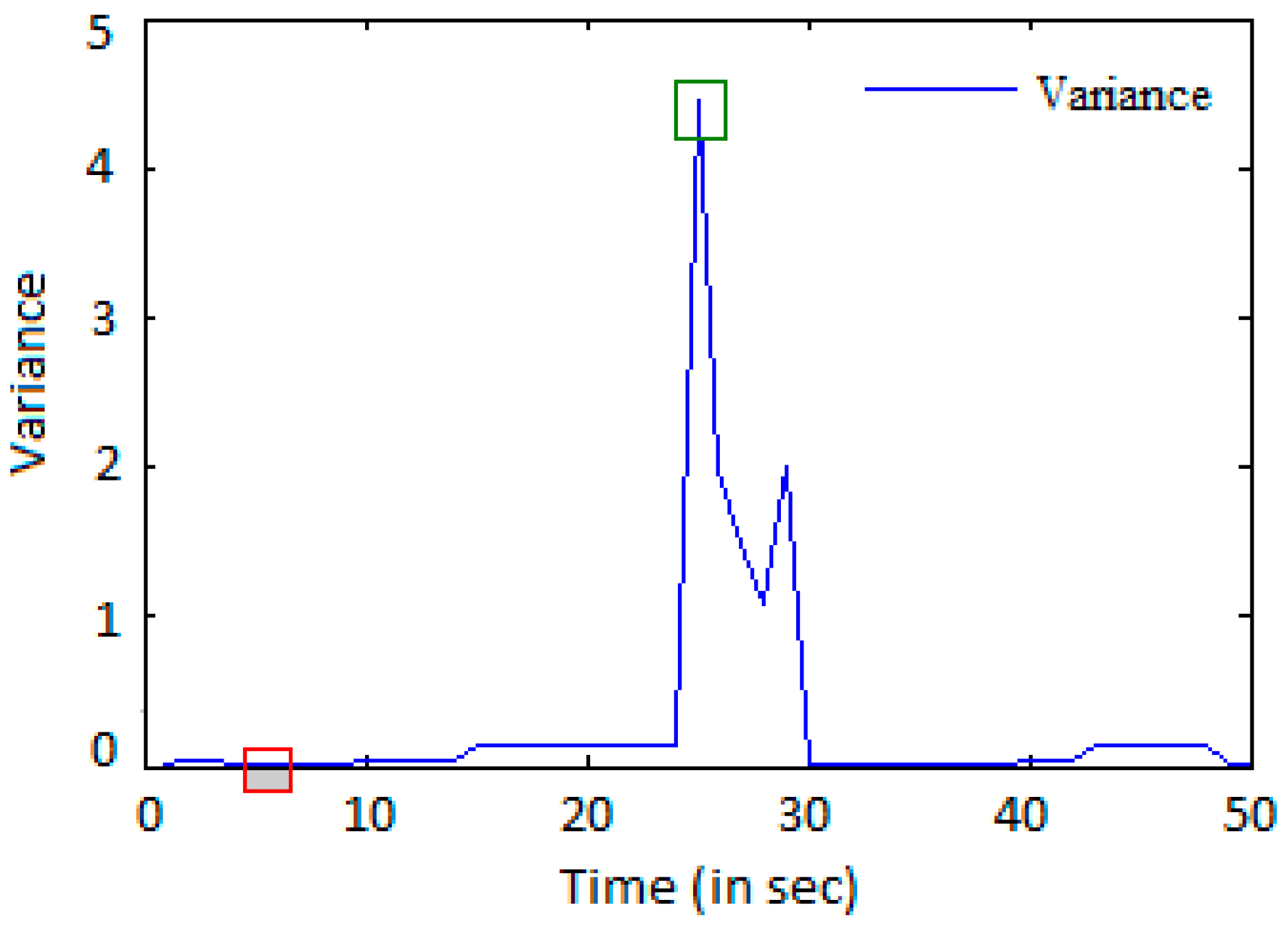
To overwhelm the web server, the attacker sends a large number of requests. In this work, the randomness of the flow is shown by computation of entropy. A smaller value of entropy will demonstrate that the flow is in order, otherwise the flow is out of order. In the case of an attack, the mean entropy value will be small when compared with a normal scenario.
In the paper, we consider the IP addresses 51.81.166.201 and 192.95.27.190 in
Figure 1 as normal clients, while the rest are attacking clients. In
Figure 1, we show only six IP addresses for easier and faster analyzing of the attack and normal scenario. The total number of clients considered for accessing the web server is 357. Each attack client is installed with an automated program to send a massive HTTP GET request. The details of experimental setup are described in
Section 4. We consider and analyze the HTTP GET request, the entropy, and the variance for each IP address during a period of time.
3.3. Multilayer Perceptron with Genetic Algorithm Learning
In the paper, for classifying the attacker from the normal clients based on the parameters discussed above, we consider multilayer perceptron (MLP) with genetic algorithm (GA) learning [
23] as the classification model. We use GA to train the MLP neural network instead of the traditional gradient descent used in back-propagation (BP) and find the correct weights of the network. The steps are shown as follows:
● Step 1: Neural Network Model
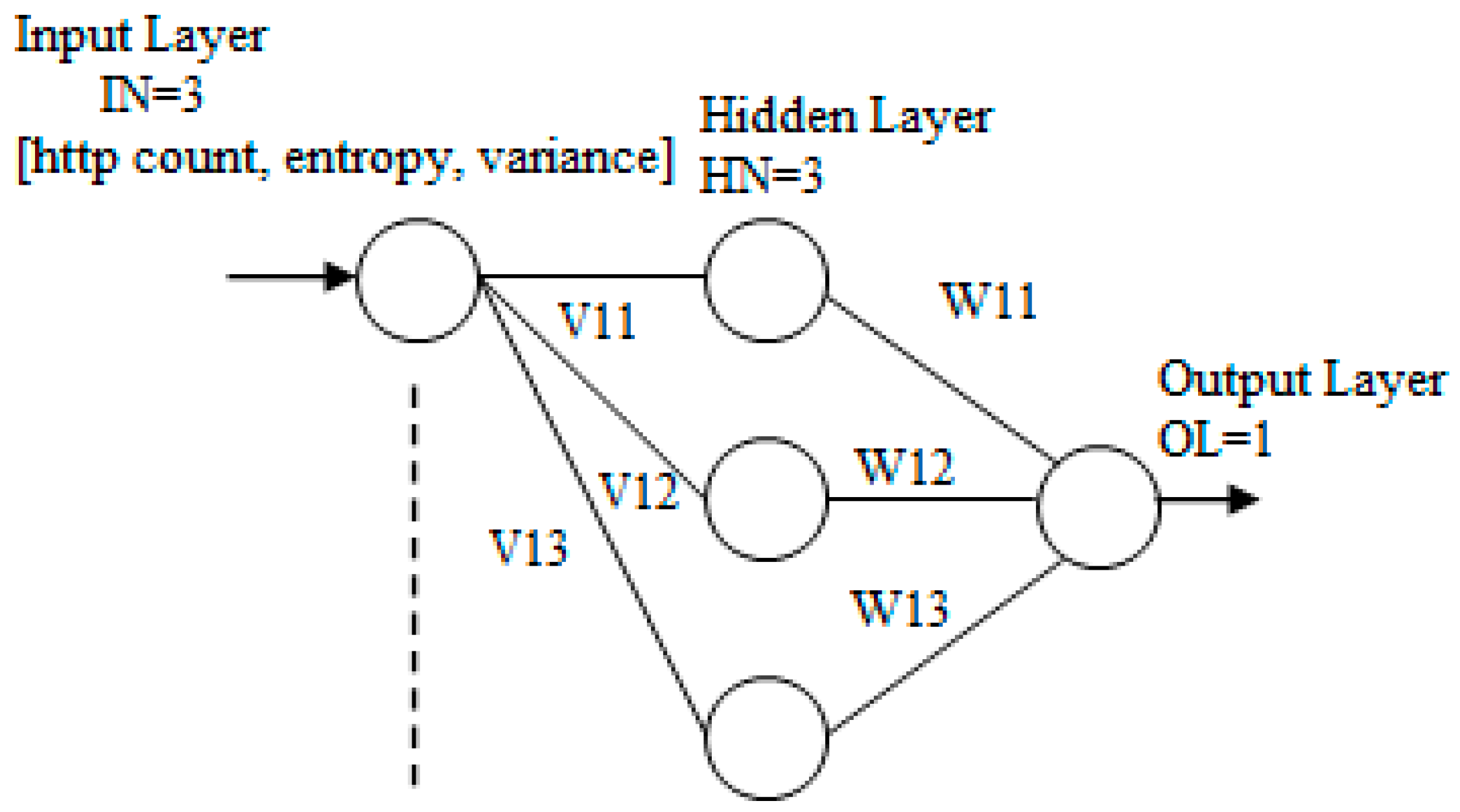
The neural network that we used is the MLP. The structure of the neural network is given in
Figure 2. The network contains three layers: input layer, one hidden layer, and output layer. The layers are connected by synaptic weights.
In our application, the size of each input pattern is 3. The number of hidden neurons is 3. The number of output neurons is 1. The input layer consists of the combination of HTTP count, entropy, and variance, which is an attribute of the input neuron layer. The number of total weights, TW, will be given by Equation (3)
where IN is the size of input pattern, HN is the number of hidden neurons, and ON is the number of output neurons. In our paper, the total number of weights, TW, given in Equation (3) is 12.
● Step 2: Weights initialization
To find the correct weights of the connection of the layers of the MLP, we use GA. In the beginning, the GA randomly creates a population of complete strings called solutions or individuals. All the weights of the connection of MLP layers can be represented by each solution/individual of the GA population. The solution will be a bit string of 0 s and 1 s.
The genelength, GL, will be given by the Equation (4)
where B = number of bits per weight. We represent each weight using 16 bits binary number, i.e., B = 16, then genelength, GL, from Equation (4) is 192. So, the genotype of our solution/individual is a 192 bit binary string.
● Step 3: Reconstruction of the phenotype from the genotype
After generating the solutions, we need to calculate the fitness value of each solution using a fitness equation. To calculate the fitness, we need to find the phenotype of each 16 bit substring, which represents each individual weight. The phenotype,
of each substring is a numeric value which is the actual value of each weight and is given by Equation (5).
where, b
ik is the
k-th bit of the
i-th weight. The phenotype is again modified to put the weight value in some convenience range, and is given by Equation (6):
where
is the
i-th weight present in the string/solution, A is the scaling factor, and B is the shifting factor.
In this paper, we take the weight value from [−10,10], so we make A = 20 and B = −10 in Equation (6).
In this way, we get the weights, , which is the weight from the i-th input to the j-th hidden neuron and the weights, , which is the weight from the j-th hidden neuron to the k-th output neuron.
● Step 4: Output of the hidden layer and the output layer
Now the weights obtained will combine with the input and obtain from each layer. We get a training example
x from the training set, and then calculate the outputs of the hidden neurons:
Using Equations (6) and (7) we calculate , which is the output of the j-th hidden neuron.
● Step 5: Calculate the output of the output neurons
The output of the output neurons can be calculated by:
where
is the output of the
k-th output neuron. The function sigmoid ( ) is a unipolar sigmoid function given by:
These two operations of finding the output are performed for all the input patterns. Then we update the Error, E, with Equation (12) using Equations (9) and (10):
where
is the desired output. This process is performed until all the training samples have been used.
● Step 6: Calculate the fitness of the string/solution
The fitness of the string/solution can be calculated with the fitness definition using Equation (13).
where N is the number of patterns/training examples. The above processes are repeated from step 2 onward for all the strings/solutions of the population. In this paper, the generated fitness value is given in
Table 7. To reduce the size of the table, we have taken the iterations that have different fitness values and omitted the any values that have same fitness value.
● Step 7: Selection
We find the string with the highest fitness value using Equation (13). If this highest fitness value is greater than the desired fitness value (=0.99 in our application), then the operation stops. The weights representing this string with the highest fitness value will be used for the testing/real operation phase.
Table 7 shows the current fitness values at the given iterations and compares them with the original fitness values.
● Step 8: Reproduction
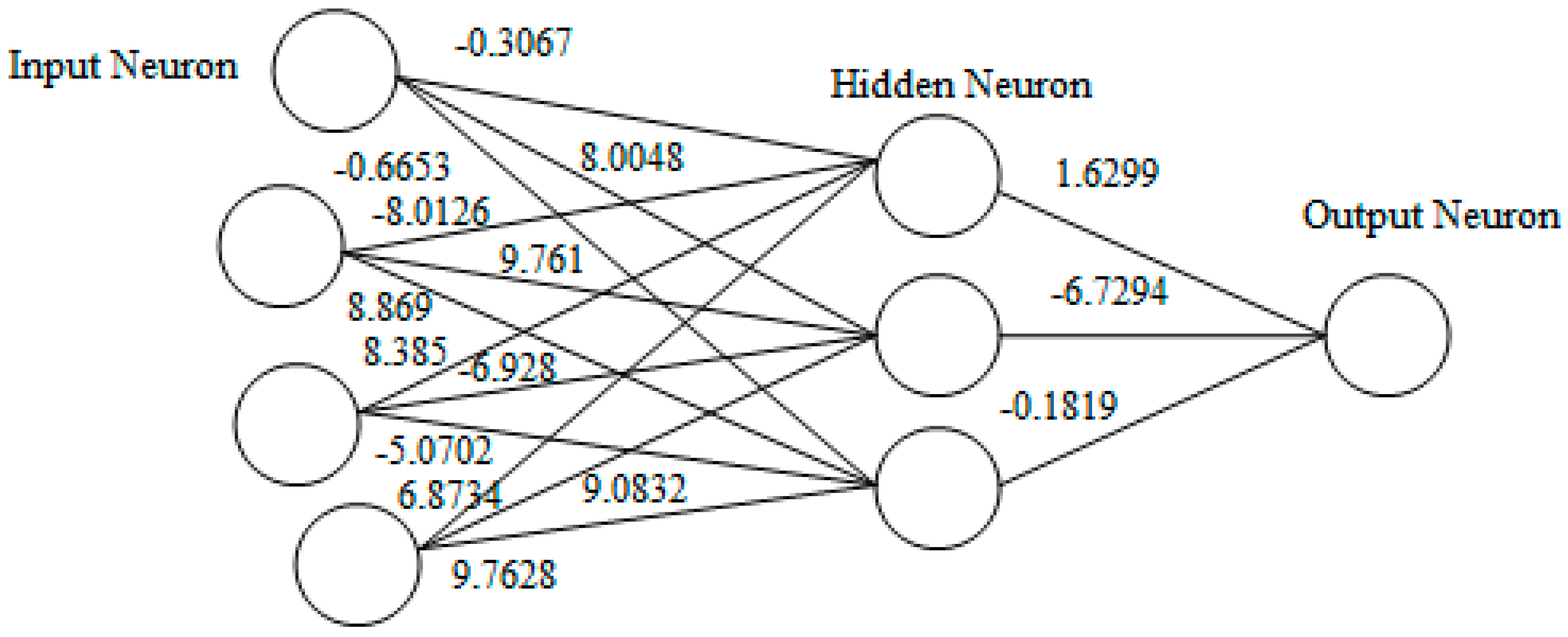
The population is modified using operators, namely, crossover and mutation. The above processes from step 3 onward are repeated for many generations until we get a string/solution whose fitness value is greater than or equal to the desired fitness. The weights with the highest fitness values are selected. Herein, we obtained the fitness value at the 231th iteration with the value 0.998628. The inputs to the MLP are the training populations obtained after GA optimization. The targeted outputs are the two classes, viz. attack represented by 1 and normal represented by 0. In this work, we obtained the weights of the hidden neurons and the output neurons as shown in
Figure 3.
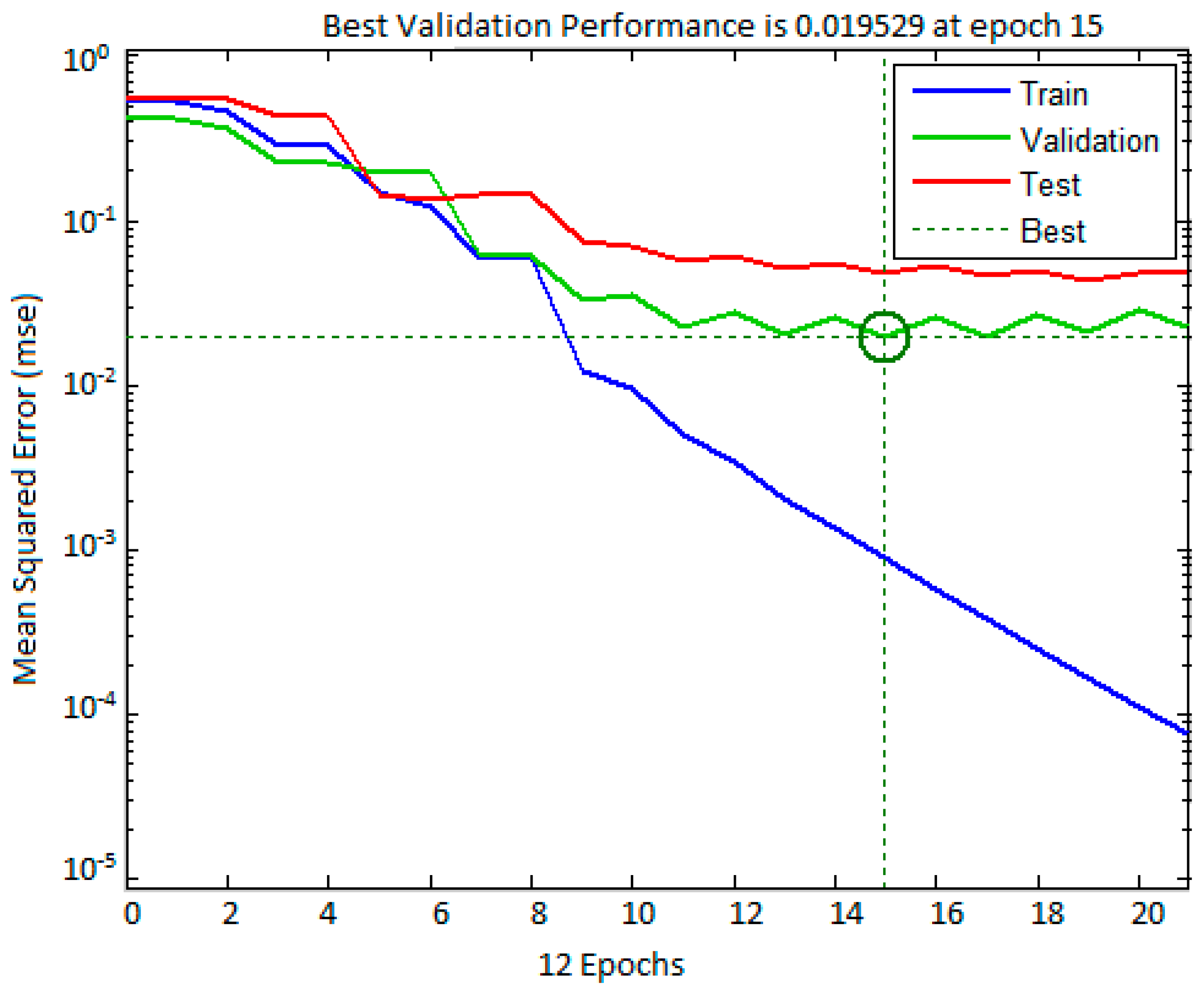
The best validation performance graph for training the input dataset is given in
Figure 4. The X-axis represents the number of epoch and Y-axis represents the mean square error (mse). The best validation performance is 0.019529 at epoch 15. In
Figure 4, the validation process, training process, and test error (represented by green, blue, and red lines, respectively) decrease with the increase in period of time or volume of training.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}