1. Introduction
The concept of the wiretap channel was first introduced by Wyner. In his celebrated paper [
1], Wyner considered a communication model, where the transmitter communicated with the legitimate receiver through a discrete memoryless channel (DMC). Meanwhile, there existed an eavesdropper observing the digital sequence from the receiver through a second DMC. The goal was to design a pair of an encoder and a decoder such that the receiver was able to recover the source message perfectly, while the eavesdropper was ignorant of the message. That communication model is actually a degraded discrete memoryless wiretap channel.
After that, the communication models of wiretap channels have been studied from various aspects. Csiszár and Körner [
2] considered a more general wiretap channel where the wiretap channel did not need to be a degraded version of the main channel, and common messages were also considered there. Other communication models of wiretap channels include wiretap channels with side information [
3,
4,
5,
6,
7,
8], compound wiretap channels [
9,
10,
11,
12] and arbitrarily-varying wiretap channels [
13].
Ozarow and Wyner studied another kind of wiretap channel called the wiretap channel II [
14]. The source message
W was encoded into digital bits
and transmitted to the legitimate receiver via a binary noiseless channel. An eavesdropper could observe arbitrary
digital bits from the receiver, where
is a constant real number not dependent on
N.
Some extensions of the wiretap channel have been studied in recent years.
Cai and Yeung extended the wiretap channel II into the network scenario [
15,
16]. In that network model, the source message of length
K was transmitted to the legitimate users through a network, and the eavesdropper was able to wiretap on at most
edges. Cai and Yeung suggested using a linear “secret-sharing” method to provide security in the network. Instead of sending
K message symbols, the source node sent
μ random symbols and
message symbols. Additionally, the code itself underwent a certain linear transformation. Cai and Yeung gave sufficient conditions for this transformation to guarantee security. They showed that as long as the field size is sufficiently large, a secure transformation existed. Some related work on wiretap networks was given in [
17,
18,
19,
20].
An extension of wiretap channel II was considered recently in [
21,
22]. The source message was encoded into the digital sequence
and transmitted to the legitimate receiver via a DMC. The eavesdropper could observe any
digital bits of
from the transmitter. A pair of inner-outer bounds was given in [
21], while the secrecy capacity with respect to the semantic secrecy criterion was established in [
22]. The coding scheme in [
21] was based on that developed by Ozarow and Wyner in [
14], while the scheme in [
22] was by Wyner’s soft covering lemma. He et al. considered another extension of wiretap channel II in [
23]. In that model, the eavesdropper observed arbitrary
digital bits of the main channel output
from the receiver. The capacity with respect to the strong secrecy criterion was established there. The proof of the coding theorem was based on Csiszár’s almost independent coloring scheme. Some other work on wiretap channel II can be found in [
24,
25,
26].
This paper considers a more general extension of wiretap channel II, where the eavesdropper observes arbitrary
μ digital bits from the transmitter via a second DMC. The capacity with respect to the weak secrecy criteria is established. The coding scheme is based on that developed by Ozarow and Wyner in [
14]. It is obvious that this communication model includes the general discrete memoryless wiretap channels, the wiretap channel II and the communication models discussed in [
21,
22,
23] as special cases. Nevertheless, we should notice that the secrecy criteria considered in [
22,
23] are strictly stronger than those considered in this paper; see
Figure 1.
The remainder of this paper is organized as follows. The formal statement and the main results are given in
Section 2. The secrecy capacity is formulated in Theorem 1, whose proof is discussed in
Section 4.
Section 5 provides a binary example of this model.
Section 6 gives a final conclusion of this paper.
2. Notation and Problem Statements
Throughout the paper, is the set of positive integers and for any . represents the collection of subsets of with size μ.
Random variables, sample values and alphabets (sets) are denoted by capital letters, lower case letters and calligraphic letters, respectively. A similar convention is applied to random vectors and their sample values. For example, represents a random N-vector (), and is a specific vector of in . is the N-th Cartesian power of .
Let ‘?’ be a “dummy” letter. For any index set
and finite alphabet
not containing the “dummy” letter ‘?’, denote:
For any given random vector
and index set
,
is a “projection” of onto with for , and otherwise.
is a subvector of .
The random vector takes the value from , while the random vector takes the value from .
Example 1. Supposing that , the index set and the random vector , we have and .
The communication model in this paper, which is shown in
Figure 2, is composed of an encoder, the main channel, the wiretap channel and a decoder. The definitions of these parts are from Definition 1 to Definition 4, respectively. The definition of achievability is in Definition 5.
Definition 1. (Encoder) The source message W is uniformly distributed on the message set . The (stochastic) encoder is specified by a matrix of conditional probability for the channel input and message .
Definition 2. (Main channel) The main channel is a DMC with finite input alphabet and finite output alphabet , where . The transition probability is . Let and denote the input and output of the main channel, respectively. It follows that for any and ,where: Definition 3. (Wiretap channel) The eavesdropper is able to observe arbitrary digital bits from the transmitter via another DMC, whose transition probability is denoted as with and . The alphabet does not contain the “dummy” letter ‘?’ either. The input and the output of the wiretap channel satisfy that:with: Supposing that the eavesdropper observes digital bits of the wiretap channel output whose indices lie in the observing index set , the subsequence obtained by the eavesdropper can then be denoted by . Therefore, the information on the source message (of each bit) exposed to the eavesdropper is denoted by: Remark 1. Clearly, for given wiretap channel output , one can easily determine which subsequence of is observed by the eavesdropper. More precisely, with .
Definition 4. (Decoder) The decoder is a mapping , with as the input and as the output. The average decoding error probability is defined as
Definition 5. (Achievability) A non-negative real number R is said to be achievable, if for any , there exists an integer , such that one can construct an code satisfying:and:where . The capacity, or the maximal achievable transmission rate, of the communication model is denoted by . Remark 2. Notice that the capacities defined in this paper are under the condition of negligible average decoding error probability, but one can construct the coding schemes for the negligible maximal decoding error probability through the standard techniques. See Appendix A for details. 4. Direct Part of Theorem 1
This section proves the direct part of Theorem 1. Let an arbitrary quadruple of random variables
be given, which satisfy that:
for
. The goal of this section is to establish that every real number
R satisfying
is achievable. In fact, it suffices to prove the achievability of every
R satisfying:
To show this, suppose that every transmission rate
R satisfying Equation (
5) is achievable. For any random variable
satisfying Equation (
4), the encoder could deliberately increase the noise of the communication system by inserting a virtual noisy channel
at the transmitting port of the system, such that:
This would create the virtual communication system depicted in
Figure 3, where the transition matrix of the main channel is:
and the transition matrix of the wiretap channel is:
It is clear that every real number is achievable for the virtual system and hence is achievable for the original system.
In the remainder of this section, it will be shown that every transmission rate
R satisfying Equation (
5) is achievable. To be precise, for any
ϵ and
τ satisfying
, we need to establish that there exists an
code, such that:
and:
when
N is sufficiently large.
The coding scheme is based on the scheme developed by Ozarow and Wyner [
14] for the classic wiretap channel II. In that channel model, for each wiretap channel output
, there exists a collection of codewords that are “consistent” with it, namely the codewords that could produce the wiretap channel output
for some observing index
. Ozarow and Wyner constructed a secure partition, such that the number of “consistent” codewords, for every wiretap channel output
, in each sub-code is less than a constant integer. However, it is not feasible to consider the “consistent” codewords in our model, where the wiretap channel may be noisy. Instead, we construct a secure partition such that the number of codewords, jointly typical with the wiretap channel output
, in each sub-code is less than a constant integer.
The proof is organized as follows. Firstly,
Section 4.1 gives some definitions on the typicality of
μ-subsequences and lists some basic results. Then, the construction of the encoder and decoder is introduced in
Section 4.2. The key point is to generate a “good” codebook with the desired partition to ensure secrecy. Thirdly, as the main part of the proof,
Section 4.3 shows the existence of a “good” codebook with the desired partition. For any
and
, the proof that the coding scheme in
Section 4.2 satisfies the requirements of the transmission rate, reliability and security, namely Formulas (
6) to (
8), is finally detailed in
Section 4.4.
4.1. Typicality
The definitions of letter typicality on a given index set follow from those briefly introduced in [
23]. We list them in this subsection for the sake of completeness.
Firstly, the original definitions of letter typicality are given as follows. Please refer to Chapter 1 in [
27] for more details.
For any
, the
δ-letter typical set
with respect to the probability distribution
on
is the set of
satisfying:
where
is the number of positions of
having the letter
.
Similarly, let
be the number of times that the pair
occurs in the sequence of pairs
. The jointly typical set
, with respect to the joint probability distribution
on
, is the set of sequence pairs
satisfying:
for all
For any given
, the conditionally typical set of
with respect to the joint mass function
is defined as:
The definitions on the typicality of μ-subsequences on index set and some basic results are given as follows.
Definition 6. Given a random variable X on , the letter typical set with respect to X on the index set is the set of such that , where is the μ-subvector of and is the probability mass function of the random variable X.
Example 2. Let X be a random variable on the binary set , such that . Set , and . Then:the sequence is out of while belongs to ;
the sequence belongs to while is out of ;
the sequence belongs to , and belongs to .
Remark 3. (Theorem 1.1 in [27]) Suppose that are N i.i.d. random variables with the same generic probability distribution as that of X. For any given and ,- 1.
if , then - 2.
,
where:and . Definition 7. Let be a pair of random variables with the joint probability mass function on . The jointly typical set with respect to on the index set is the set of satisfying , where and are the subvectors of and , respectively.
Definition 8. For any given with , the conditionally-typical set of on the index set is defined as: Remark 4. Let be a pair of random sequences with the conditional mass function:for and . Then, for any index set , and , it follows that: Corollary 4. For any and , it follows that .
Corollary 5. Let be N i.i.d. random variables with the same probability distribution as that of Y. For any and , it follows that: Remark 5. (Theorem 1.2 in [27]) Let be a pair of random sequences satisfying (9). For any index set , and , it is satisfied that:where:and . 4.2. Code Construction
Suppose that the triple of random variables is given and fixed.
Codeword generation: The random codebook
is an ordered set of
i.i.d. random vectors with mass function
, where:
for some
.
Codeword partition: Given a specific sample value
of
randomly-generated codewords, let
be a random variable uniformly distributed on
and
be the random sequence uniformly distributed on
. Set
, and partition
into:
subsets
with the same cardinality. Let
be the index of sub-code containing
, i.e.,
. We need to find a partition of the codebook
satisfying that:
where
is the output of the wiretap channel when taking
as the input, i.e.,
for
and
. If there is no such desired partition, declare an encoding error.
Remark 6. We call the codebook an ordered set because each codeword in the codebook is treated as unique, even if its value may be the same as the other codewords.
Encoder: Suppose that a desired partition on a specific codebook is given. When the source message W is to be transmitted, the encoder uniformly randomly chooses a codeword from the sub-code and transmits it to the main channel.
In this encoding scheme, each message is related to a unique sub-code, which is sometimes called a bin. Therefore, we would call this kind of coding scheme the random binning scheme.
Remark 7. For a given codebook and a desired partition applied to the encoder, let and be the input and output of the wiretap channel respectively, when the source message W is transmitted. It is clear that and share the same joint distribution.
Decoder: Supposing that the output of the main channel is . The decoder tries to find a unique sequence , such that and decodes as the estimation of the transmitted source message. If there is none or there is more than one satisfied , the encoder chooses a constant as .
4.3. Proof of the Existence of a “Good” Codebook with a Secure Partition
This subsection proves the existence of a class of “good” codebooks, on which there exist secure partitions, such that Equation (
12) holds, when
N is sufficiently large and
δ is sufficiently small. Moreover, those kinds of “good” codebooks can be randomly generated with probability
as
. The notation in
Section 4.2 will continue to be used in this subsection.
A formal definition of “good” codebooks is given by the following.
Definition 9. A codebook is called “good” if it is satisfied that:and:where:is the set of typical codewords on the index set ,is the set of codewords jointly typical with on the index set and: The main results of this subsection are summarized as the following three lemmas. Lemma 1 claims the existence of “good” codebooks; Lemma 2 constructs a special class of partitions on the “good” codebooks; and Lemma 3 proves that the partitions constructed by Lemma 2 are secure.
Lemma 1. Let be the random codebook generated by the scheme introduced in Section 4.2. If , the probability of being “good” is bounded by:where:and is given by Equation (
15).
Remark 8. It can be verified that as , if δ is sufficiently small. Therefore, one can obtain a “good” codebook with probability .
Lemma 2. For any given codebook satisfying Equation (14) with codewords, there exists a secure equipartition on it, such that:for all , and , if where: Lemma 3. For any and secure partition on a “good” codebook , it follows that:where:and: Remark 9. Formula (12) is finally established from the fact that the right-hand side of Equation (19) converges to zero as and . Proof of Lemma 3. By a way similar to establishing Equation (
22) in [
2], for every
, it follows that:
where the last equality follows because
forms a Markov chain. Therefore:
The terms in the rightmost side of Equation (
21) are bounded as follows.
Upper bound of
. On account of the fact that
is uniformly distributed on the “good” codebook
(cf. Equation (
13)), it follows that:
for every
. Combining Remark 5 yields:
for every
, where
is given by Equation (
20). Denote:
It follows that:
for every
. Moreover, on account of the property of (
18), we also have:
Therefore:
where (a) follows from Equation (
23) and the fact that
is binary and (b) follows from Equation (
22).
The value of
is upper bounded as:
where (a) follows the facts that
is binary and
when
and (b) follows from Equation (
22).
Recalling that when given
, the random vector
is uniformly distributed on
, we have:
Lower bound of
. For any
satisfying that
, we have:
where the function
represents the number of the letter
x appearing in the sequence
, and the inequality follows from the definition of
. Therefore,
By now, the terms in the rightmost side of Equation (
21) have been bounded as expected. Substituting Equations (
24) to (
27) into (
21) gives Equation (
19). The proof of Lemma 3 is completed. ☐
4.4. Proofs of Equations (6) to (8)
Remark 7 and Lemma 3 yield:
if the codebook is “good”, which implies Equation (
7). By the standard channel coding scheme (cf., for example, chapter 7.5 [
28]), using the random codebook-generating scheme in
Section 4.2, one can obtain a codebook satisfying Equation (
8) with probability
when
. Combining Lemma 1, it is established that one can get a codebook achieving both equations of (
7) and (
8) with probability
. Equation (
6) is obvious from the coding scheme. The proofs are completed.
5. Example
This section studies a concrete example of the communication model depicted in
Figure 2 and formulated in
Section 2, where the main channel is a discrete memoryless binary symmetrical channel (DM-MSC) with the crossover probability
, and the eavesdropper observes arbitrary
digital bits from the transmitter through a binary noiseless channel. This indicates that the transition matrices
and
(introduced in Definitions 2 and 3) satisfy that:
and:
where
x,
y and
z all take the value from the binary alphabet
.
This example is in fact a special case of the model considered in [
22]. Corollary 3 gives that the secrecy capacity of this example is:
where the auxiliary random variable
U is sufficient to be binary. However, the formula given in (
28) is inexplicit. In fact, it is an optimization problem. In this section, we will solve this optimization problem and find the exact random variable
U achieving the “max” function. The main result is given in Proposition 1, whose proof is based on Lemma 4.
Suppose that the random variables of
and
Y are all distributed on
, and they satisfy that:
for some
. Formula (
28) can then be rewritten as:
where:
and:
for
. Denoting:
and:
for
, the function
can then be further represented as:
To determine the value of , some properties of the function g are given in the following lemma.
Lemma 4. For any given , it follows that:- 1.
is symmetrical around .
- 2.
when , the function g is convex over , and is the unique minimal point.
- 3.
when , there exists a unique minimal point on the interval , and hence, is the unique minimal point over the interval ; moreover, is the unique maximal point over the interval , and the function is convex over the intervals of and .
The proof of Lemma 4 is given in
Appendix D.
Figure 4 shows some examples on the function
g, which cover both cases of
and
.
On account of Lemma 4, we conclude that:
Proposition 1. The secrecy capacity can be represented as:where is the unique minimal point of the function g over the interval . Moreover, is positive if and only if . Proof.
When
, the function
g is convex over the interval
. Therefore:
for all
,
and
. This indicates that
. It remains to determine the capacity for the case of
. The inference is divided into two parts. The first part shows that the inequalities
hold for all
,
and
satisfying
. The second part establishes Equation (
29).
The first part is proven by contradiction. Suppose that
. We can assume that
without loss of generality. In this case, it must follows that
or
since
is the convex combination of
and
. We further suppose that
. If it is also true that
, then it follows immediately that
on account of the fact that the function
g is convex over the interval
. On the other hand, if
, we let
satisfy that:
Then, it follows clearly that
, and hence:
where (a) follows because
is the minimal point of
g and
and (b) follows because
g is convex over the interval
. This contradicts the assumption that
.
To prove the second part, consider that when
, we have:
where the inequality holds because
is the maximal point over the interval
and
is the minimal point over the interval
. The formula above indicates that
. The equality holds if
,
and
; see
Figure 5.
The proof of Proposition 1 is completed. ☐
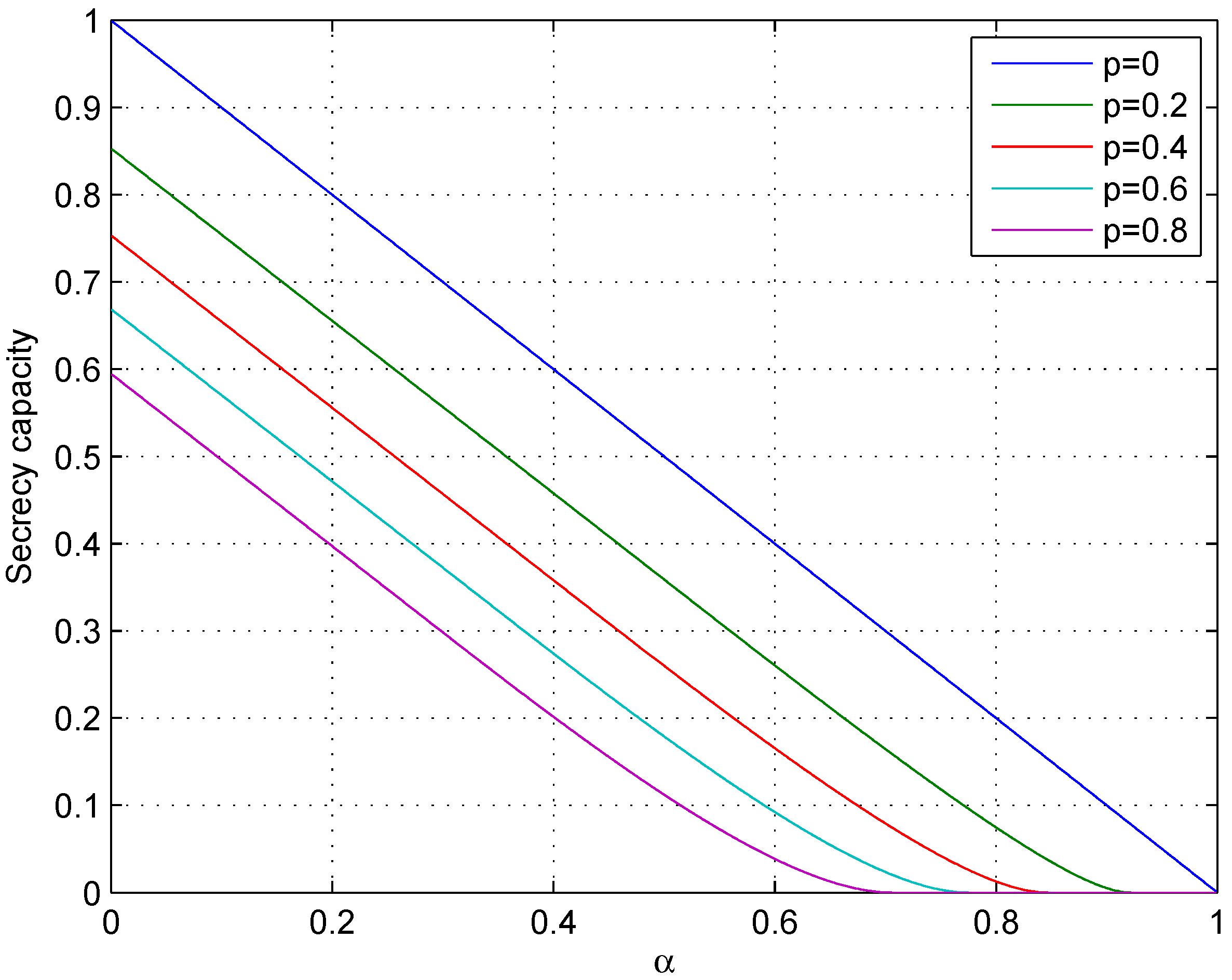
It is clear that when
, the communication model discussed in this section is specialized as wiretap channel II. In that case, the secrecy capacity is obviously a linear function of
α. However, when
, the linearity does not hold. Instead, the secrecy capacity is a convex function of
α. See
Figure 6.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





