1. Introduction
According to price forecasts, producers and managers adjust current productions and operations, and governments make proper macro-economic policy to stabilize prices. A great number of studies shows that price forecasts of agricultural products are meaningful [
1,
2]. Nowadays, the price forecasts of agricultural products are mainly based on the point forecasts. However, interval forecasts can deliver more information than point forecasts. Point forecasting is widely used, can provide a single value of the variable in the future and cannot provide any information about the value of uncertainty. Uncertainty information is particularly important for decision makers with different risk preferences. The result of interval forecasts is an interval with a confidence level, which is more convenient for decision makers to formulate risk management strategies. Due to the importance of interval forecasts, in the monthly World Agricultural Supply and Demand Estimates (WASDE) of the United States Department of Agriculture (USDA), price forecasts are published in the form of intervals.
The more stable and simple the price system of agricultural products, the more favorable the price forecast. Entropy is a measure of the complexity of a system. Greater entropy means that the system is more complex, and then, the price forecast is prone to distortion. Su et al. [
3] verified that there is chaos in the price system by calculating the Kolmogorov entropy. Their price system has positive entropy; but the entropy is not big, and the system has weak chaos. How do we predict prices in such a system? When entropy is not big, can we obtain better forecasting results? In this paper, we illustrate that this price system can be forecasted, and we verify that the price interval forecast is feasible in the system with positive Kolmogorov entropy. Our paper illustrates that we can obtain the interval forecasts. In recent years, many scholars have carried out research work on entropy in the economic field. Bekiros et al. [
4] studied the dynamic causality between stock and commodity futures markets in the United States by using complex network theory. We utilize the extended matrix and the time varying network topology to reveal the correlation and the temporal dimension of the entropy relationship. Selvakumar [
5] proposed an enhanced cross-entropy (ECE) method to solve the dynamic economic dispatch (DED) problem with valve-point effects. Fan et al. [
6] used multi-scale entropy analysis; we investigate the complexity of the carbon market and the average return trend of daily price returns. Billio et al. [
7] analyzed the temporal evolution of systemic risk in Europe by using different entropy measures and constructed a new banking crisis early warning indicator. Ma and Si [
8] studied a continuous duopoly game model with a two-stage delay. They investigated the influence of delay parameters on the stability of the system.
In agricultural economics, Teigen and Bell [
9] established the confidence interval of the corn price by the approximate variance of the forecast. Prescott and Stengos [
10] applied the bootstrap method to construct the confidence interval of the dynamic metering model and forecasted the pork supply. Bessler and Kling [
11] affirmed the role of probability prediction and defined what is a “good” prediction. Sanders and Manfredo [
12], Isengildina-Massa et al. [
13] compared four methods, including the histogram method, the kernel density method, the parameter distribution estimation method and the quantile regression method. They evaluated the confidence intervals generated by these methods. The results showed that the kernel function method and the quantile regression method can get the best interval forecasts.
There are two main methods for interval forecasting. One is the prediction of the interval type data [
14]. The interval type data are composed of the minimum and maximum sequences. This method can be used in a case with comprehensive information. The disadvantage is that it cannot provide the confidence level of the interval. The other is constructing the confidence interval by the estimation of the errors of point forecasts. The advantage is that one can obtain confidence levels. In this paper, we will construct a forecast interval with some target confidence level based on the entropy theory and system complexity theory.
In practice, the prediction interval of the same target confidence is not unique, so which is the best interval? Decision makers often choose those results that meet their own needs, so we can directly build the “optimal” forecast intervals under their standard. In this paper, we will construct the model of the optimal forecast interval and transform this problem to an optimization problem. Since it is difficult to solve the analytic solution for a nonlinear optimization problem, we establish an algorithm to solve the numerical solution.
Nowadays, the optimal criterion of the interval mainly lies in the accumulation of the accuracies of point forecasts. The M index defined by Batu [
15] is an average of point forecast errors in the prediction interval. Demetresc [
16] used the cumulative accuracy of the point forecasts, which can obtain longer intervals and high reliability. However, for the economic data, this kind of forecast loses significance. The forecast interval not only delivers accuracy, but also delivers information. How does one evaluate the interval from both the accuracy and the informativeness, which seem to be contradictory aspects? Yaniv and Foster [
17] provided a formal model of the binary loss function, i.e., the trade-off model between accuracy and informativeness. They compared their model with many common models. The results showed that their model is more suitable to reflect individual preferences. In this paper, the optimal forecast interval model is established by using the trade-off model.
To obtain the confidence level, it is critical to correctly estimate the error distribution of the point forecasts. In general, the error distribution is supposed to be a normal distribution or a
distribution, etc. However, this method is subjective, and it is possible that the error distribution does not obey the assumed distribution. Gardner [
18] found that prediction intervals generated by the Chebyshev inequality are more accurate than those generated by the hypothesis of the normal distribution, which was opposed by Bowerman and Koehler [
19], Makridakis and Winkler [
20] and Allen and Morzuch [
21]. They thought the intervals generated by the Chebyshev inequality are too wide. Stoto [
22] and Cohen [
23] found that the forecast errors of population growth asymptotically obey the normal distribution. Shlyakhter et al. [
24], recommended the exponential distribution in the data of population and energy. Willia and Goodman [
25] first used the empirical method to estimate the distribution of historical errors of point forecasts without restrictions on the method of the point forecast. Chatfield [
26] pointed out that the empirical method is a good choice when the error distribution is uncertain. Taylor and Bunn [
27] first applied the quantile regression for the interval estimation. Hanse [
28] used semi-parametric estimation and the quantile method to construct the asymptotic forecast intervals. This method has strict requirements on time series. Demetrescu [
16] pointed out that quantile regressions are not so useful, since one does not know in advance which quantile is needed, and an iterative procedure would have obvious complexity. Jorgensen and Sjoberg [
29] used the nonparametric histogram method to find the points of the software development workload distribution. Yan et al. [
30], thought that the errors of point forecasts have great influence on the accuracy of uncertainty analysis. Ma et al. [
31] investigated existence and the local stable region of the Nash equilibrium point. Ma and Xie [
32] studied financial and economic system under the condition of three parameters’ change circumstances, Zhang and Ma [
33] and ou and Ma [
34] investigated a class of the nonlinear system modeling problem, with good research results. Martínez-Ballesteros et al. [
35] forecasted by means of association rules. Ren and Ma deepen and complete a kind of macroeconomics IS-LM model with fractional-order calculus theory, which is a good reflection on the memory characteristics of economic variables.
The novelty of this paper is in providing two methods. One is the stratified historical errors’ estimation, and the other is the optimal confidence interval model.
To improve the estimation accuracy, we try to stratify the historical error data according to the price and estimate the error distribution of each layer. In the estimation of the historical error distribution, all errors are often treated as obeying the same distribution. Considering the heteroscedasticity of prediction errors of different prices, it is too rough. The frequencies of different prices in history are different. Some extreme prices in history only appeared several times with the emergence of sharp fluctuations. The forecast errors of these prices are generally large, and the sample capacity of such errors is small. On the contrary, some prices appear very frequently with small fluctuations. The forecast errors of these prices are generally small, and the sample capacity of such errors is big. Therefore, we stratify the historical error data according to different prices and estimate the error distribution of each layer.
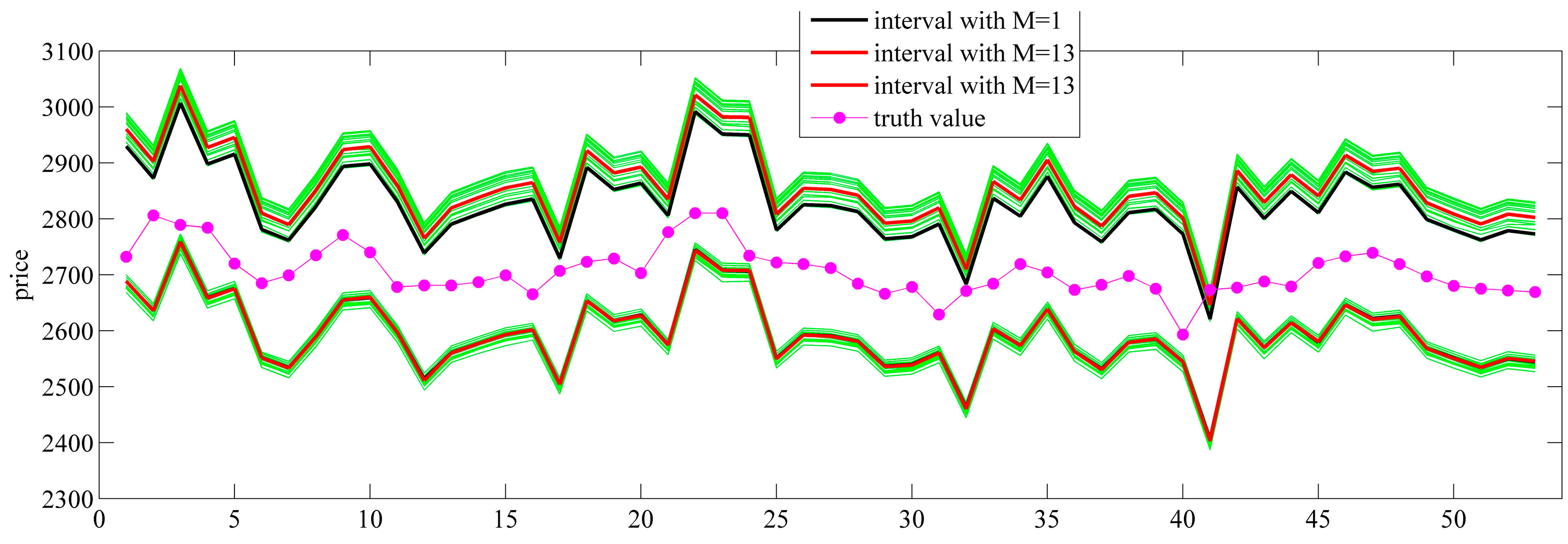
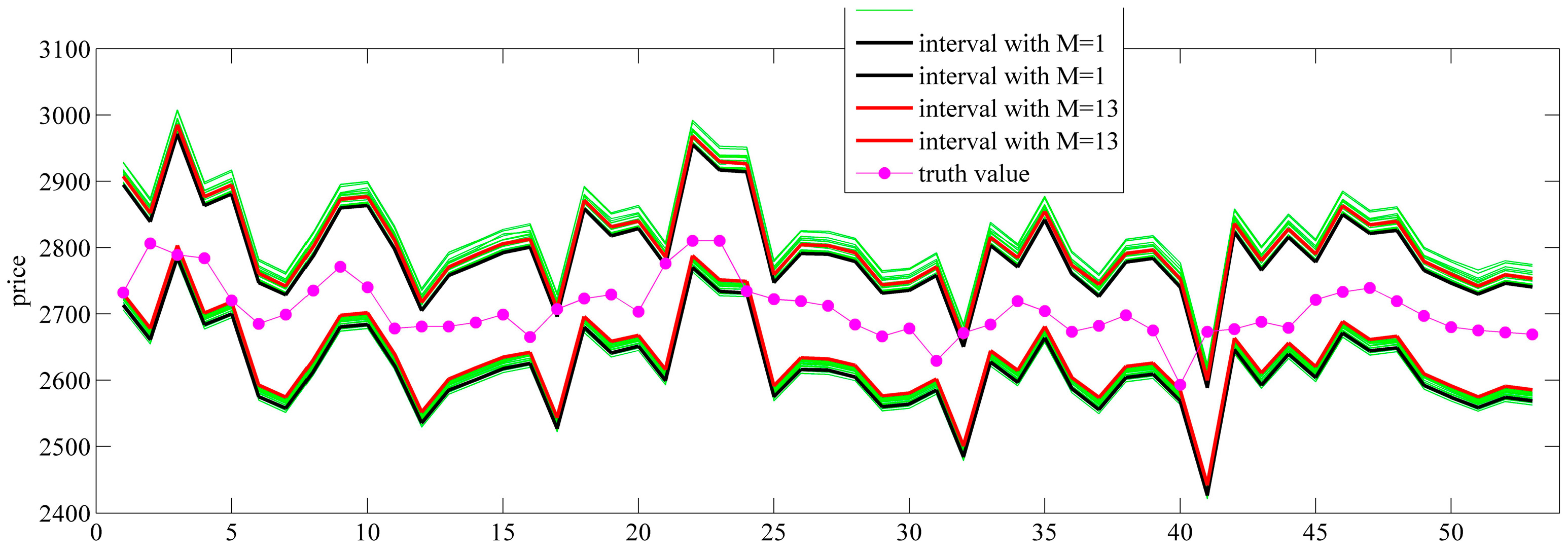
In this paper, we induce the model of the optimal confidence interval according to the accuracy and the informativeness trade-off model, provide a practical and efficient algorithm for the optimal confidence interval model based on the complexity of the forecasting system and estimate the error distributions according to the stratified prices. The kernel function method is used to estimate the error distribution. For different target confidence levels, simulation prediction is achieved for the continuous futures daily closing prices of soybean meal and non-GMO soybean. Unconditional coverage, independence and conditional coverage tests are used to evaluate the interval forecasts. Empirical analysis is divided into two subsections. In
Section 5.1, we apply the equal probability method, the shortest interval method and the optimal interval method to construct the prediction intervals, compare their loss functions and test whether the intervals generated by the optimal interval method are optimal. We add the various
SNR (Signal-Noise Ratio) noises to the historical error data and the prediction prices and test the robustness of the algorithm. In
Section 5.2, the prediction errors are divided into one to 20 layers according to the prices. The error distributions are estimated in different layers. The confidence intervals are constructed and evaluated, finding whether the error stratification method can improve the prediction accuracy. The evaluation indices are concluding from the loss function, interval endpoint, interval midpoint, interval length, coverage, unconditional coverage test statistic, independence test statistic and conditional coverage test statistic. The error data, including point forecast errors generated by the weighted local method and the RBF neural network method, are used to investigate whether the hierarchical estimation error method can improve the prediction accuracy for different point forecasts.
2. The Model and Algorithm of the Optimal Confidence Intervals
Denote by
the process to be forecast, and assume it has a continuous and strictly increasing cumulative distribution function. Suppose
is the conditional density of
on its past
, and
is the conditional cumulative distribution function of
. Clearly, the confidence interval
of
with confidence level
satisfies:
Yaniv and Foster [
17] established the accuracy-informativeness trade-off model:
where the first variable evaluates accuracy, the second variable evaluates informativeness,
is a truth value,
is the midpoint of prediction interval and
denotes the width of interval. Actually, the accuracy-informativeness trade-off model is a kind of loss function. Yaniv and Foster [
17] thought that, for a good interval, the lower the
score, the better. They gave a concrete expression of
:
where the coefficient
is a trade-off parameter that reflects the weights placed on the accuracy and informativeness of the estimates. Yaniv and Foster [
17] supposed that the value of
is taken from 0.6 to 1.2, close to one.
For a given confidence level
, we take the minimum
as the objective to solve the optimal confidence interval, which can be transformed to find the solution
of the nonlinear optimization problem under the condition
, where:
Denote by
the set of all possible values of
; the constraint conditions are:
Then, we can obtain the following simplified objective function.
Thus, we only need to find the solution that can minimize of (2) and that satisfies with . It is difficult to solve analytic solutions; however, for a strictly increasing and numerical , we can establish an algorithm to obtain numerical solutions. The steps are as follows.
Step 1. Take all and and find all satisfying , i.e., Since the value increases with the increase of for a fixed , the value of can be solved uniquely. Therefore, we point out that it is not necessary to take all of the values of .
Step 2. For each point obtained from the first step , calculate the midpoint .
Step 3. For every
, compute:
Step 4. Sort all of the ; find the smallest ; and record the corresponding
3. Estimate the Conditional Probability Distribution of Error
Denote by
the forecast of
and by
the error, i.e.,
If we take
as the optimal point forecast [
27], we can estimate
and obtain the distribution of
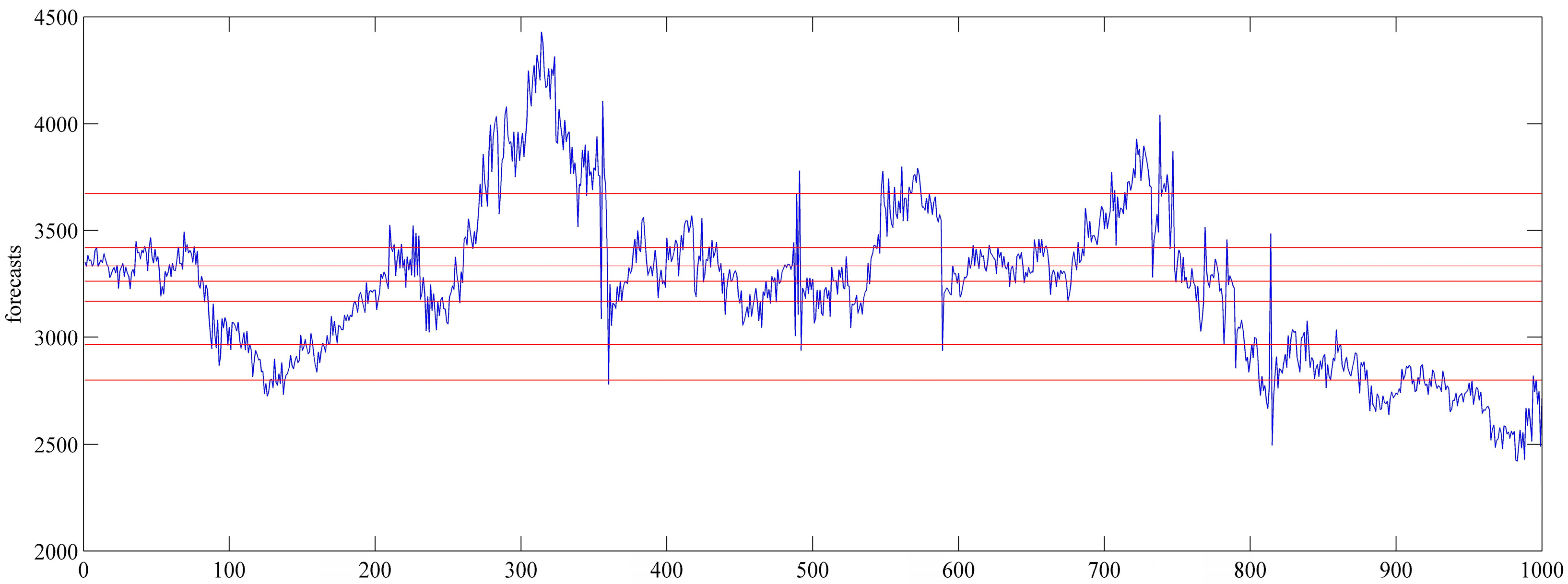
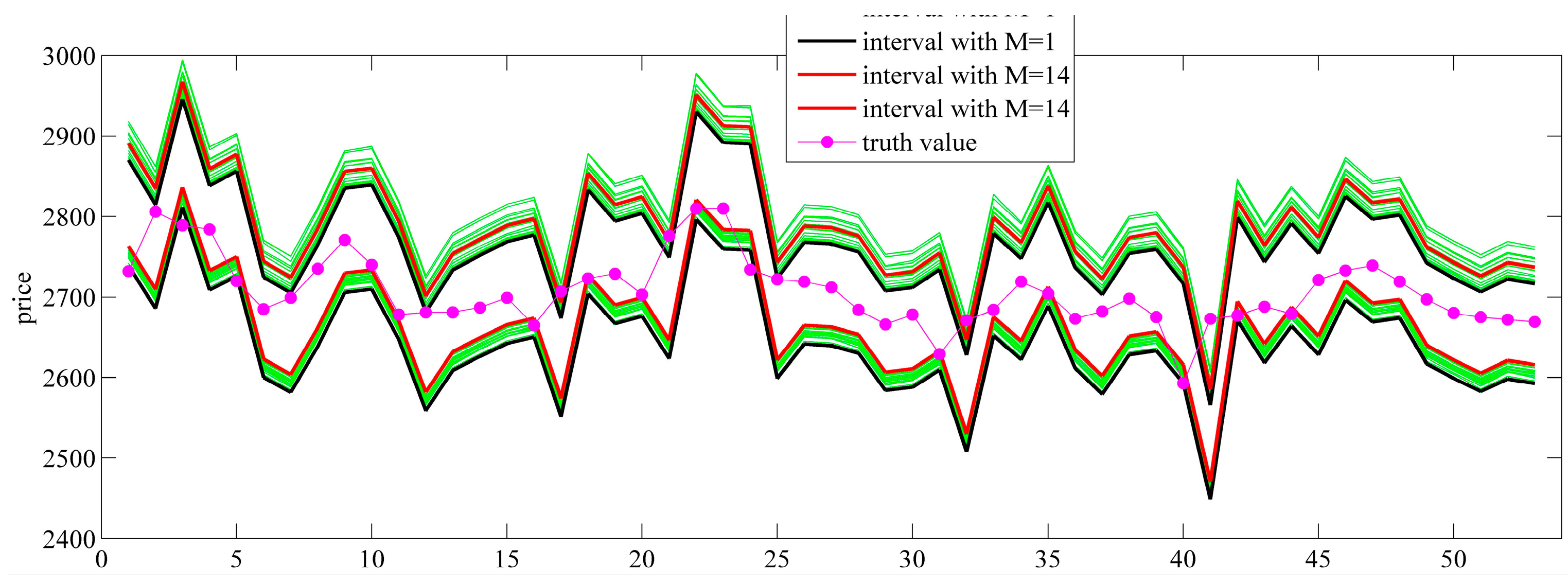
. In this paper, we apply the empirical method, which means that we can take all obtained point forecast errors as samples of the same probability distribution. We estimate the probability distribution by the kernel function method, for which we give the details below. However, it is rough to take all obtained errors as obeying one distribution. For one forecasting value, if we can collect all corresponding errors, the errors can be considered to obey one distribution. However, in general, the error sample size of one forecasting value is very small. In order to collect as many samples as possible, we can take the errors of one forecasting interval. Therefore, how to choose reasonable forecasting value intervals is very important.
We stratify the prediction error samples evenly according to the forecasting values. First, we divide the
N historical forecasting values
into
layers, i.e.,
M intervals, and record the upper limit and lower limit of every layer. The size of every layer is about
The size of every layer may not be the same, and a 10% difference is admissible. Second, put the errors of every layer forecasts into the error sample set of the layer. For example, when
,
, the division of the forecasts is shown in
Figure 1.
When
N is fixed, the bigger
is, the smaller
is; the smaller
is, the greater
is. When
is small, the size of the sample is small, and the estimating accuracy declines. When
is big, the size of the sample is big, which means the width between two adjacent red lines in
Figure 1 will be bigger. At this time, the forecasting values within the same layer have a big difference; taking the errors in this layer as obeying the same probability distribution is not reasonable. In short,
cannot be taken too big or too small. When
N is fixed, there is an optimal
to obtain the optimal estimated error distribution, which will be verified in
Section 5.
For fixed
N and
(
), we apply the kernel function method to estimate the error distribution. Assume that the size of each layer is
; the error sequence of the
layer is
. Then, the density estimation of the sequence at point
is
, where
is the normal kernel function:
is the bandwidth or smoothing parameter. In this paper, we apply the optimal bandwidth [
30]
, where
, and
represents the sample median.
4. Evaluation of the Prediction Interval
The accuracy of forecast intervals is traditionally examined in terms of coverage. However, only if test values are enough, the coverage can reflect the true confidence level. Bowman [
36] describes the use of smoothing techniques in statistics, including both density estimation and nonparametric regression. Christoffersen [
37] developed approaches to test the coverage and independence in terms of hypothesis tests. Since his methods do not make any assumption about the true distribution, they can be applied to all empirical confidence intervals. His methods include unconditional coverage, independence and conditional coverage tests.
Suppose that
is the confidence level, and test sample sequence is
. First, denote by
the indicator:
where
is an out-of-sample prediction interval, which denotes the prediction interval of
constructed by the
error;
and
are the lower limit and upper limit, respectively. Christoffersen [
37] proved that
obeys the binomial distribution
. When the capacity of test sample is finite, Christoffersen [
37] constructed a standard likelihood ratio test with the null hypothesis
and the alternative hypothesis
. The purpose is to examine, with condition
, whether
equals
significantly. If
is accepted, then the coverage of the test sample equals the target confidence level. Christoffersen [
37] established the following test statistic:
When the null hypothesis holds, and represent the chi-squared distribution which degree of freedom is 1, where , is the maximum likelihood estimation of , and and denote the number that “hit” zero and one, respectively.
Christoffersen [
37] thought that the unconditional test is insufficient when the dynamics are present in the higher order moments. In order to test the independence, he introduced a binary first-order Markov chain with transition probability matrix:
where
. If independence holds true, then
, where
. Therefore, under the null hypothesis of independence, (4) turns to:
We can estimate
by the test sample frequency, i.e.,
Additionally,
. The test statistic under the null hypothesis is:
where
,
.
The above tests for unconditional coverage and independence are now combined to form a complete test of conditional coverage:



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




