
Multi-Agent System Supporting Automated Large-Scale Photometric Computations


Abstract
:1. Introduction
2. State of the Art and Preliminaries
2.1. Lighting Design Overview
- A human has to be excluded from the design process. This is required because human activity is the bottleneck of the process.
- To enable the computer-aided, fully-automated data processing and design preparation, some formal representation of a problem has to be available.
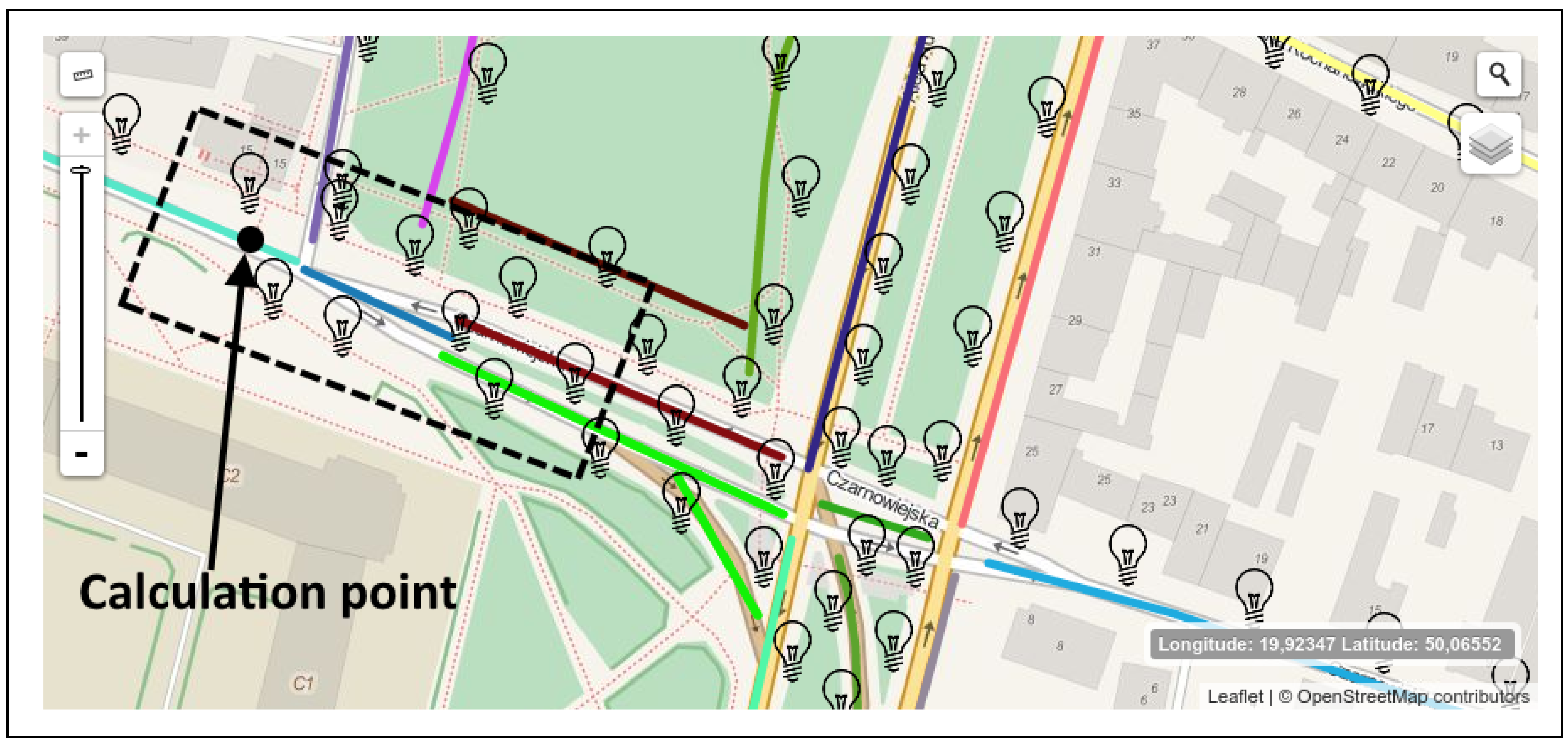
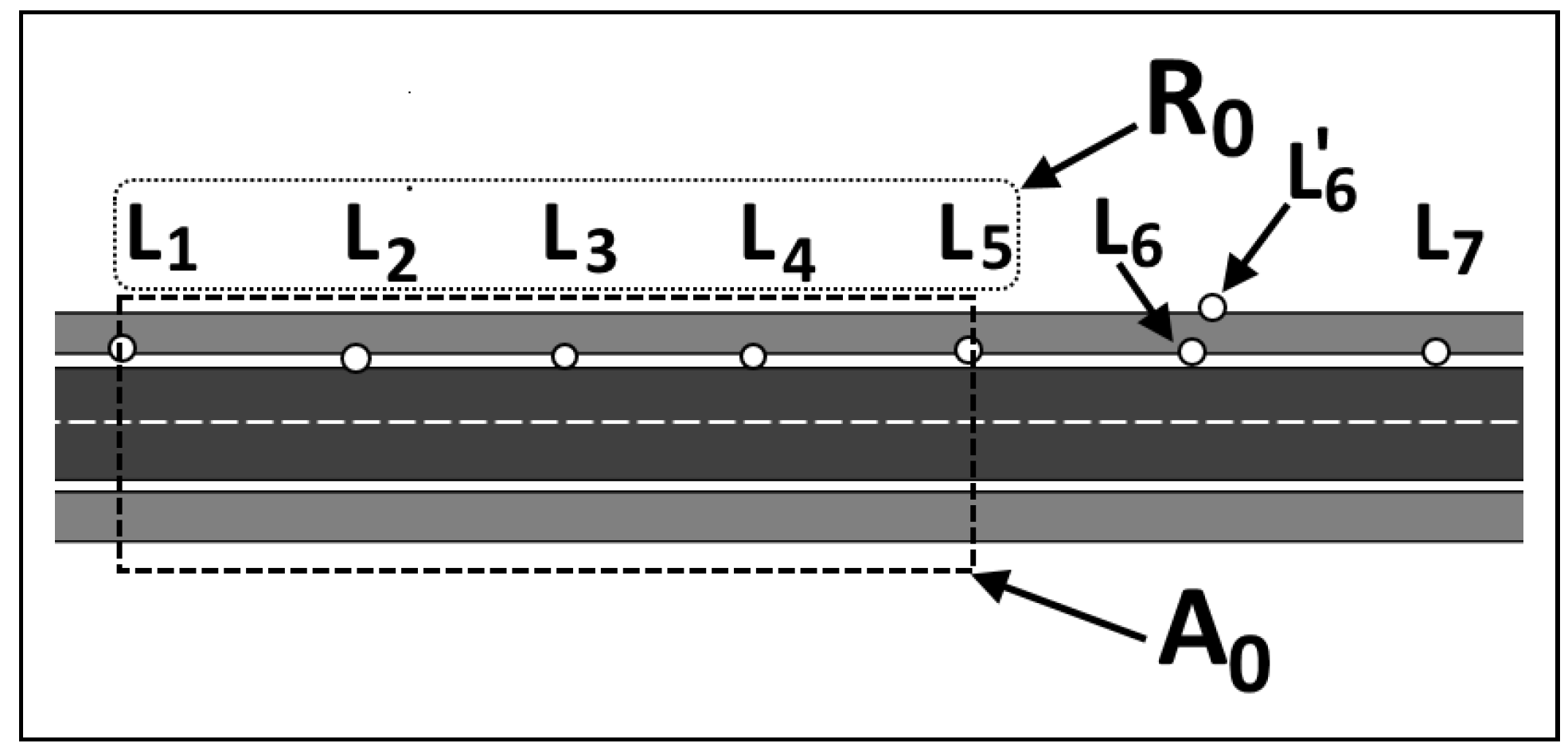
2.2. Calculation Process
3. Statistical Measure of a Solution Search Process
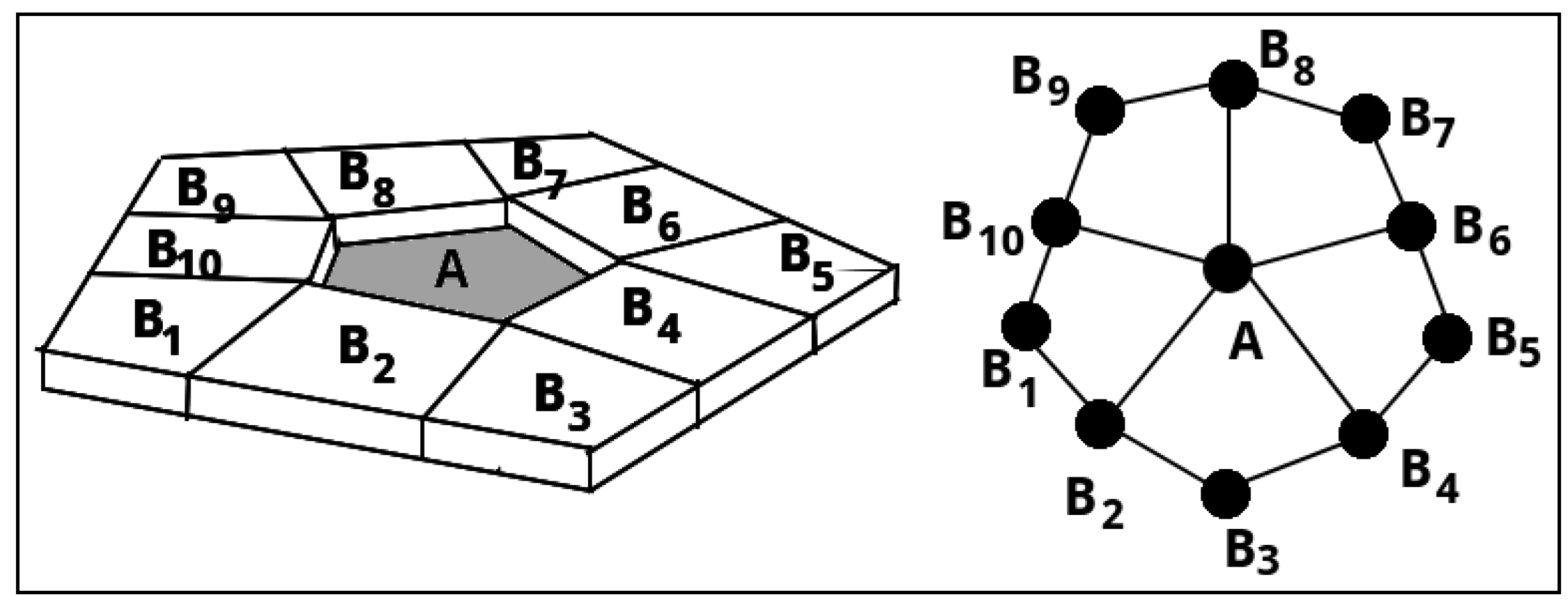
4. Graphs
4.1. S-hypergraph, A-hypergraph
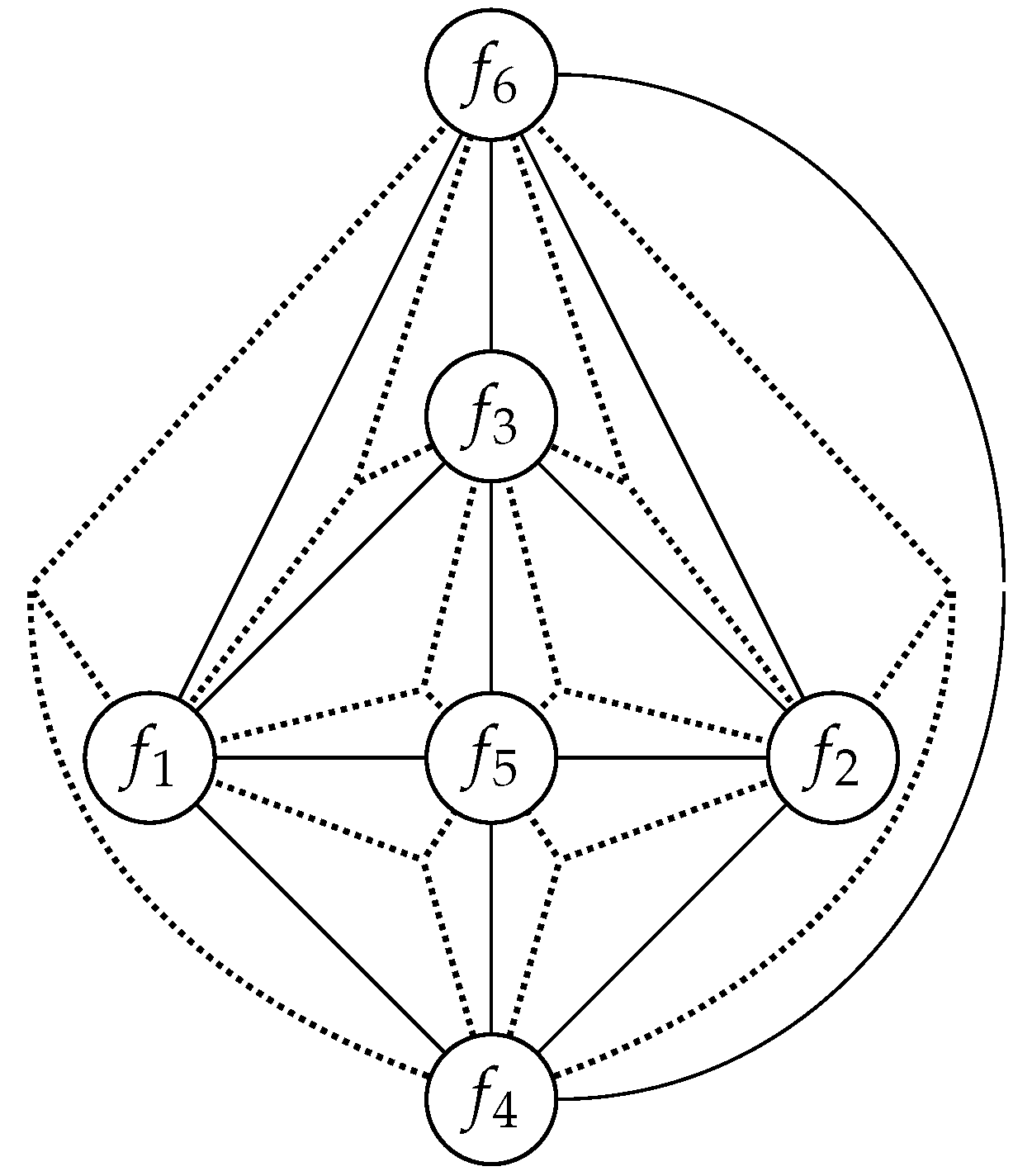
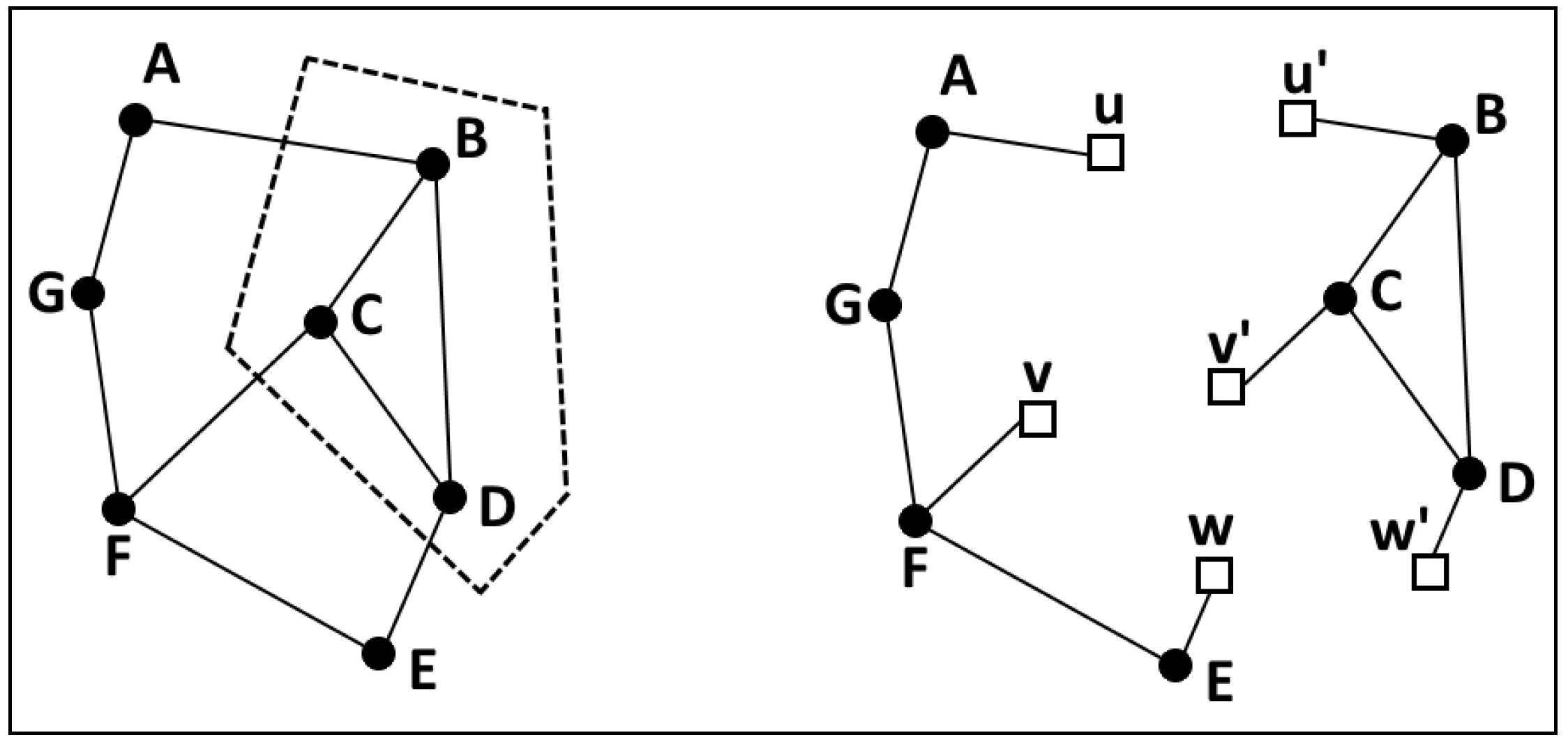
4.2. Slashed Graphs
- and , where is a set of core nodes, denotes a set of dummy nodes and ;
- where are mutually disjoint for ;
- , such that is the replica of v; ;
- is incident to at most one dummy node.
- (α denotes an isomorphic mapping between graphs), and are disjoint for .
- , a bijective mapping satisfying: , such that:
- (a)
- ;
- (b)
- is a replica of v;
- (i) for some i, such that ; or (ii) for some , such that e is a slashed edge associated with v and .
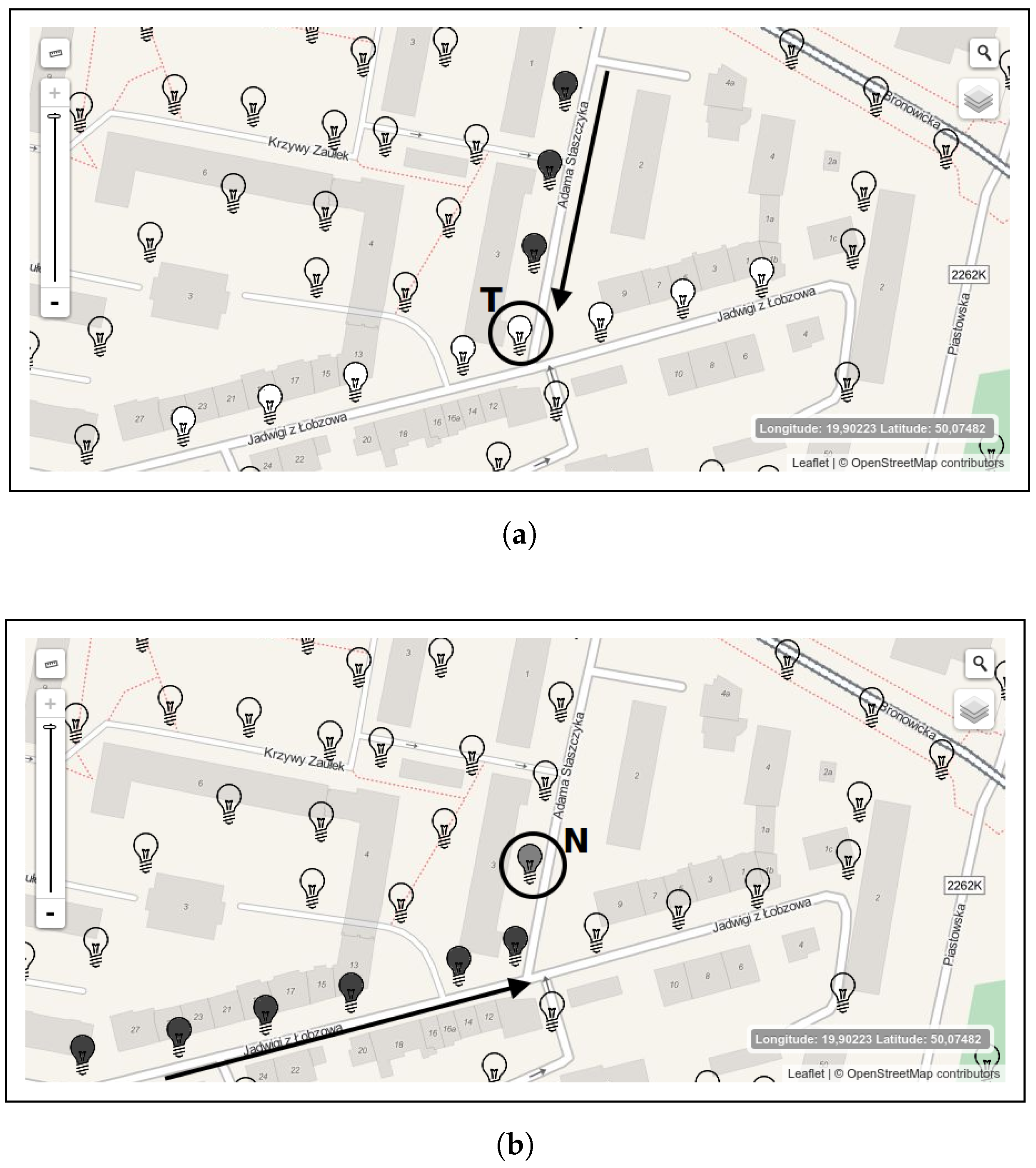
5. Agent System Perspective
- All non-tagged luminaires have been already processed. This happens when either a CA met a tagged luminaire or no other lamp to be processed is available in the relevant region.
- No solution can be found. Such a situation occurs when a problem of finding an optimal adjustment complying with a given lighting class cannot be found in the assumed search space. In this case, a CA reports a problem to an MA. Then, a master agent may restart calculations in a changed search space (e.g., with other fixture models or pole heights).
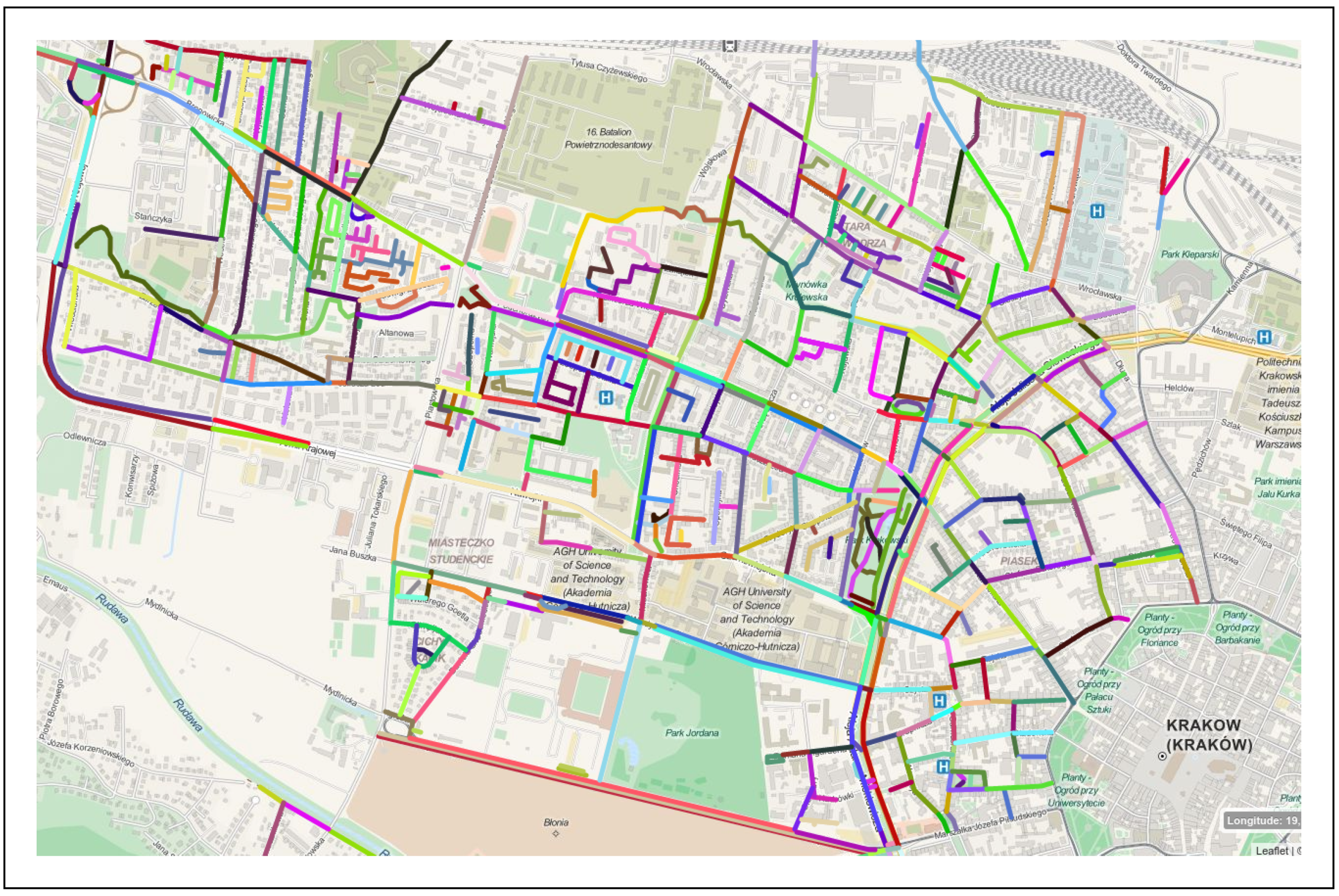
6. Results
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Outdoor Street Lighting. Available online: http://goo.gl/mfpGYT (accessed on 25 February 2016).
- Rabaza, O.; Peña-García, A.; Pérez-Ocón, F.; Gómez-Lorente, D. A simple method for designing efficient public lighting, based on new parameter relationships. Expert Syst. Appl. 2013, 40, 7305–7315. [Google Scholar] [CrossRef]
- Gómez-Lorente, D.; Rabaza, O.; Estrella, A.E.; Peña-García, A. A new methodology for calculating roadway lighting design based on a multi-objective evolutionary algorithm. Expert Syst. Appl. 2013, 40, 2156–2164. [Google Scholar] [CrossRef]
- Wojnicki, I.; Ernst, S.; Kotulski, L.; Sȩdziwy, A. Advanced street lighting control. Expert Syst. Appl. 2014, 41, 999–1005. [Google Scholar] [CrossRef]
- Salata, F.; Golasi, I.; Bovenzi, S.; Vollaro, E.D.L.; Pagliaro, F.; Cellucci, L.; Coppi, M.; Gugliermetti, F.; Vollaro, A.D.L. Energy Optimization of Road Tunnel Lighting Systems. Sustainability 2015, 7, 9664–9680. [Google Scholar] [CrossRef]
- Sȩdziwy, A. A New Approach to Street Lighting Design. LEUKOS 2015. [Google Scholar] [CrossRef]
- Sȩdziwy, A.; Kozień-Woźniak, M. Computational Support for Optimizing Street Lighting Design. In Complex Systems and Dependability; Springer: Berlin/Heidelberg, Germany, 2012; Volume 170, pp. 241–255. [Google Scholar]
- Temkin, O.N.; Zeigarnik, A.V.; Bonchev, D.B. Chemical Reaction Networks: A Graph-Theoretical Approach; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Ramadan, E.; Tarafdar, A.; Pothen, A. A hypergraph model for the yeast protein complex network. In Proceedings of the 18th International Parallel and Distributed Processing Symposium, Santa Fe, NM, USA, 26–30 April 2004.
- Pimm, S.L. Food webs. In Food Webs; Springer: Berlin/Heidelberg, Germany, 1982; pp. 1–11. [Google Scholar]
- Kotulski, L.; Sedziwy, A.; Strug, B. Heterogeneous graph grammars synchronization in CAD systems supported by hypergraph representations of buildings. Expert Syst. Appl. 2014, 41, 990–998. [Google Scholar] [CrossRef]
- Kotulski, L.; Sedziwy, A. Parallel Graph Transformations Supported by Replicated Complementary Graphs. In Adaptive and Natural Computing Algorithms; Dobnikar, A., Lotrič, U., Šter, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6594, pp. 254–264. [Google Scholar]
- DIALux. Available online: http://goo.gl/21XOBx (accessed on 25 February 2016).
- Road lighting—Part 3: Calculation of performance. Available online: https://www.fer.unizg.hr/download/repository/en13201-3.pdf (accessed on 25 February 2016).
- Road Lighting—Part 2: Performance Requirements. Available online: https://www.fer.unizg.hr/download/repository/en13201-2.pdf (accessed on 25 February 2016).
- Sedziwy, A.; Kotulski, L. A new approach to power consumption reduction of street lighting. In Proceedings of the International Conference on Smart Cities and Green ICT Systems (SMARTGREENS), Lisbon, Portugal, 22–25 May 2015; pp. 1–5.
- Handbook of Graph Grammars and Computing by Graph Transformations, Volume 1: Foundations; Rozenberg, G. (Ed.) World Scientific: Singapore, Singapore, 1997.
- Handbook of Graph Grammars and Computing by Graph Transformation, Volume 2: Applications, Languages and Tools; Ehrig, H.; Engels, G.; Kreowski, H.J.; Rozenberg, G. (Eds.) World Scientific: Singapore, Singapore, 1999.
- Kotulski, L.; Strug, B. Using Graph Transformations in Distributed Adaptive Design System. In Computer Vision and Graphics; Bolc, L., Kulikowski, J.L., Wojciechowski, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5337, pp. 477–486. [Google Scholar]
- Sȩdziwy, A. Effective Graph Representation for Agent-Based Distributed Computing. In Agent and Multi-Agent Systems. Technologies and Applications; Jezic, G., Ed.; Springer: Berlin Heidelberg, Germany, 2012; Volume 7327, pp. 638–647. [Google Scholar]
- Kotulski, L.; Sȩdziwy, A. GRADIS—The multiagent environment supported by graph transformations. Simul. Model. Pract. Theory 2010, 18, 1515–1525. [Google Scholar] [CrossRef]
- Sȩdziwy, A. Effective graph representation supporting multi-agent distributed computing. Int. J. Innov. Comput. Inf. Control 2014, 10, 101–113. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | (min. *) | (min.) | (min.) | (max. **) | (min.) |
|---|---|---|---|---|---|
| ME1 | 2.0 | 0.4 | 0.7 | 10 | 0.5 |
| ME2 | 1.5 | 0.4 | 0.7 | 10 | 0.5 |
| ME3a | 1.0 | 0.4 | 0.7 | 15 | 0.5 |
| ME3b | 1.0 | 0.4 | 0.6 | 15 | 0.5 |
| ME3c | 1.0 | 0.4 | 0.5 | 15 | 0.5 |
| ME4a | 0.75 | 0.4 | 0.6 | 15 | 0.5 |
| ME4b | 0.75 | 0.4 | 0.5 | 15 | 0.5 |
| ME5 | 0.5 | 0.35 | 0.4 | 15 | 0.5 |
| ME6 | 0.3 | 0.35 | 0.4 | 15 | n/a |
| Parameter | Range | Step | Number of Variants |
|---|---|---|---|
| Pole height | 6–12 m | 0.5 m | 13 |
| Arm length | 0–3 m | 0.5 m | 7 |
| Fixture inclination | 0–20 | 5 | 5 |
| Fixture dimming level | – | 76 | |
| Fixture model | n/a | n/a | 2000 |
| Attribute Name | Description |
|---|---|
| bounding_box | Array of 2D GIS coordinates |
| lighting_class | Lighting class (as in EN 13201:2) |
| surface | Reflective properties of the road surface |
| luminaires | Array of relevant luminaires (together with all applicable data) |
| Computing Method | Power Required (kW) | Power Savings * |
|---|---|---|
| No optimization, standard calculations | 275 | 0.0% |
| Optimized in standard calculations | 253 | 8% |
| Optimized in customized calculations | 234 | 15% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sȩdziwy, A.; Kotulski, L. Multi-Agent System Supporting Automated Large-Scale Photometric Computations. Entropy 2016, 18, 76. https://doi.org/10.3390/e18030076
Sȩdziwy A, Kotulski L. Multi-Agent System Supporting Automated Large-Scale Photometric Computations. Entropy. 2016; 18(3):76. https://doi.org/10.3390/e18030076
Chicago/Turabian StyleSȩdziwy, Adam, and Leszek Kotulski. 2016. "Multi-Agent System Supporting Automated Large-Scale Photometric Computations" Entropy 18, no. 3: 76. https://doi.org/10.3390/e18030076
APA StyleSȩdziwy, A., & Kotulski, L. (2016). Multi-Agent System Supporting Automated Large-Scale Photometric Computations. Entropy, 18(3), 76. https://doi.org/10.3390/e18030076