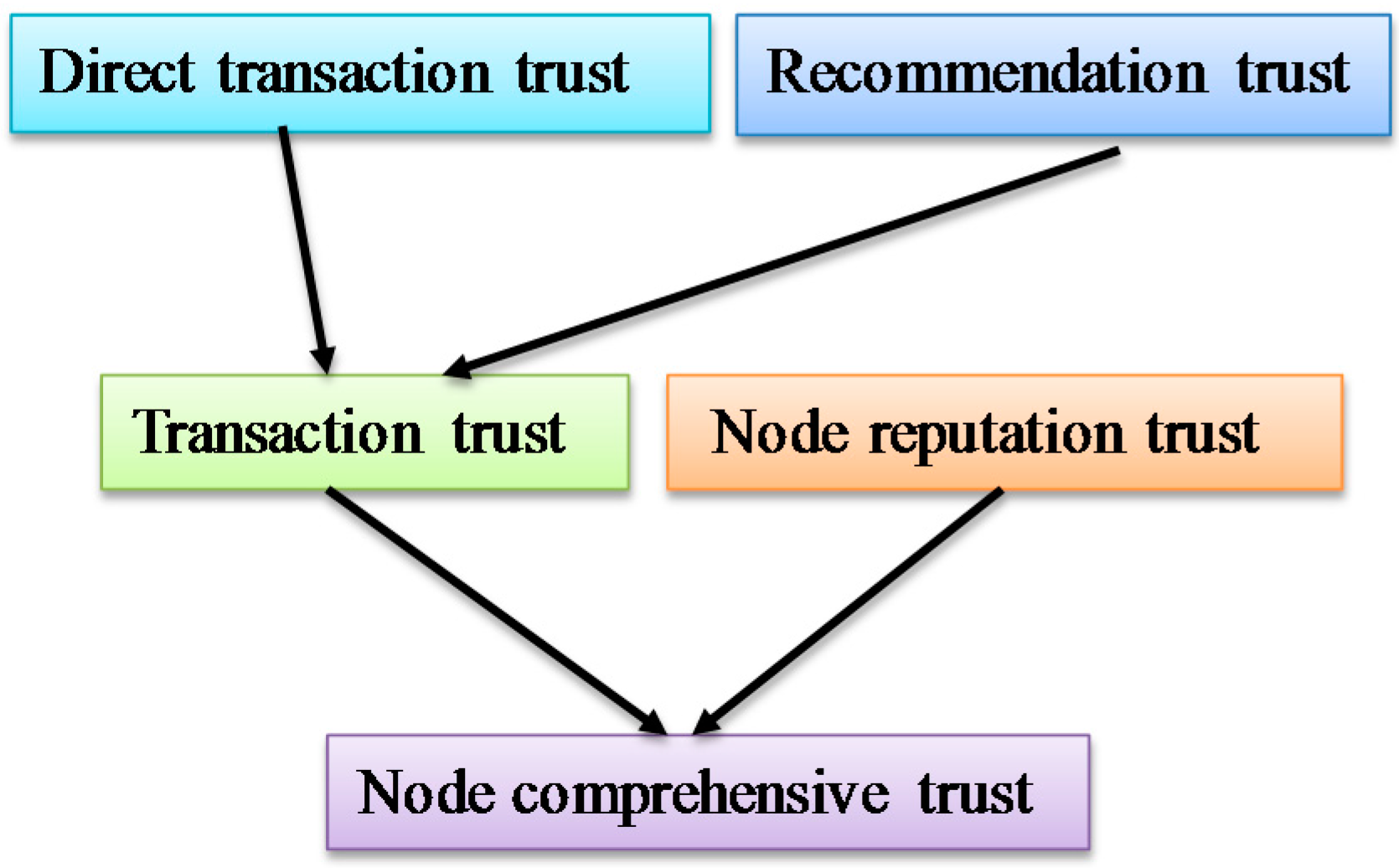
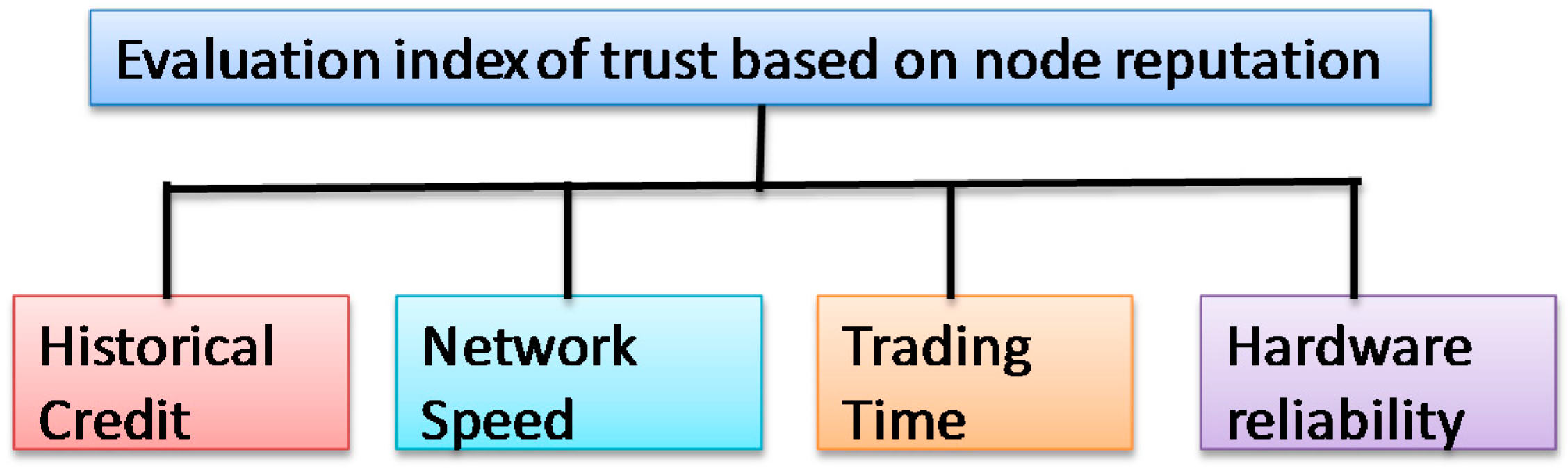
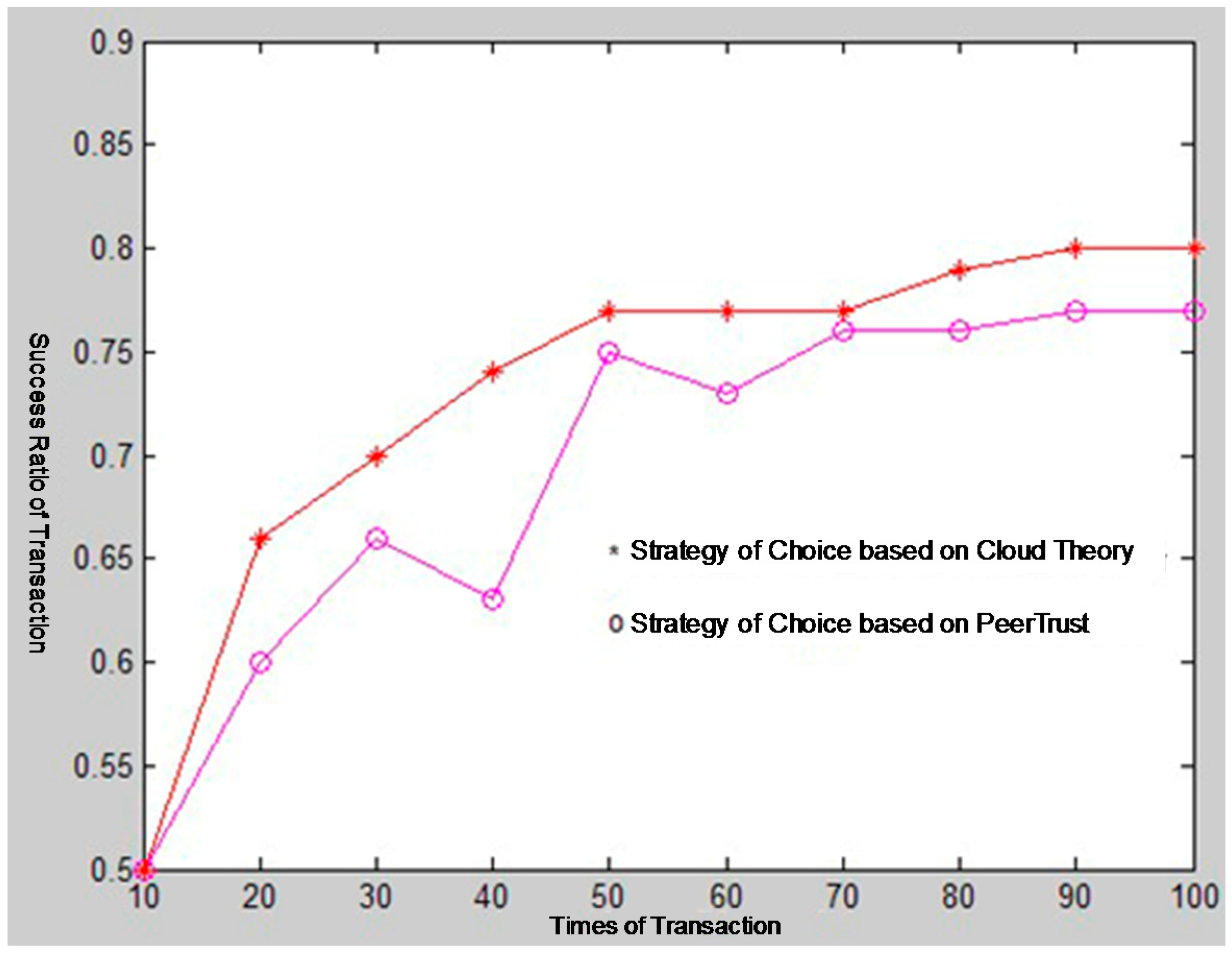
In the process of P2P network trust evaluation, it is also necessary to take the node’s historical trading experience into consideration after calculating the node’s reputation trust degree, which reflects the complete credible degree of a node. Obviously, the trading trust degree is a continuous accumulation process. Recording the feedback evaluation data of the trading nodes after each transaction and the node’s experience will become richer and richer as the number of transactions increases.
We then conduct a comprehensive analysis calculation by balancing weights between the direct transaction trust and recommendation trust. In the initial stage, when the node in the network wants to trade with strange nodes, the information of the strange nodes’ trust condition is largely collected from the recommendation of other entity that has traded with this node. After having several transactions with the node, when calculating the trading trust, both the direct trading historical experience with itself and other node’s recommendation are considered. When two nodes have a certain number of transactions, they establish mutual trust with each other. In this case, we can rely more on direct trading information when calculating the interact trust. The calculation formula for the trading trust degree is given as follows:
where
is the direct trading trust of node
p to node
q and
is the recommendation trust about node
q. The parameter
is called the balance weight, which reflects the experience value of node
p to
q. The greater its value is, the more experience node
p has, and thus the more sureness for the judgment of the trust condition of the node
q is.
is the time attenuation factor.
3.4.1. Computation of Direct Trading Trust
By querying the evaluation records of node
p to
q in the time window
, the formula of calculating direct trading trust is as follows:
where,
is called the direct trading trust degree, which is the feedback score of node
p to trade with node
q for several transactions in the time window
.
is the trading times of node
p to
q. In order to obtain more accurate results, we introduce the following three factors into Equation (10).
The first factor is the time attenuation factor . The trading feedback rating can better reflect the node’s recent behavior and trust condition if the time is closer. On the contrary, the trading feedback rating has a smaller impact on calculating the direct trading trust degree if the time is longer.
The second factor is the volume factor
. When the node’s turnover is larger, the feedback score can affect the direct trading trust degree more. The volume factor can effectively prevent some nodes from using the trust value accumulated by some small amounts in large transactions. In addition, the serious attitude of trading nodes to the large amount of transactions makes the evaluation results reflect the node’s behavior more accurately. The following formula is used to calculate the volume factor:
where
is the amount of the
ith transaction and
M is the control coefficient of the turnover factor, whose value is a positive number.
The third factor is the acceleration factor , where n is the number of failed transactions. The acceleration factor urges the trust value to drop rapidly when the transaction fails. In order to avoid the situation that nodes are punished because of one or two inadvertent errors, its value will instead increase rapidly when the number of failures increases.
At the moment
t, the assessment of node
p to node
q is
,
, whose value can be (1, 0.75, 0.5, 0.25 or 0).
t’ is the time of a transaction in time window
. The attenuation factor is
and
is the trading times of node
p with node
q. Then Equation (10) can be rewritten as Equation (12) after incorporating the above three factors, which provides a more comprehensive method to calculate the direct trading trust:
3.4.2. Computation of Recommendation Trust
In most existing social network trust evaluation models, the calculation of recommendation trust mainly takes the credibility of the recommended node into account. In this paper, we introduce the experience factor and time attenuation factor as well as the turnover factor into the calculation process. Assumes that node
q has direct transactions with
n other nodes in the time window
; node
q will save
n corresponding historical trading feedback evaluation records. The following is the formula of calculating recommendation degree in the traditional model:
Among them, the time attenuation factor is
. The parameter
t is the current time and
is the refresh time of the trust value after direct transactions among nodes.
is the recommendation degree of node
.
is the empirical value of node
relative to
, which can be computed as follows:
where
M and
N are positive numbers set by the actual conditions. The parameters
and
are the trading times and total turnover, respectively, between node
and node
in a certain time period.
In the above recommendation trust computing model, if the recommendation information has not been updated for a long time, its influence on the node’s trust degree calculation will diminish. This is why we introduce the time attenuation factor. Considering the total turnover, this prevents the nodes in the network from accumulating experience values too quickly by using a small amount with high faith transactions. The experience factor is also introduced in the model, because the experience of a node is richer, the recommended information it gives is closer to the reality, which is more trustworthy.
The reliability of the recommended node equals the recommendation degree, which is calculated as follows:
Among them, is the recommend similarity of node v and w, which is the similarity of their feedbacks to other nodes’ trust conditions. represents the trust value of node to node . The total amount of transactions between node and node in a time window is denoted as . The parameter is a set of nodes that have performed transactions with both node and . The nodes with high recommended credibility can be given a high weight for their recommendation information. By filtering the nodes whose feedback information has a large deviation from the trust evaluating standard, our model can also resist conspiracy attacks of malicious nodes.
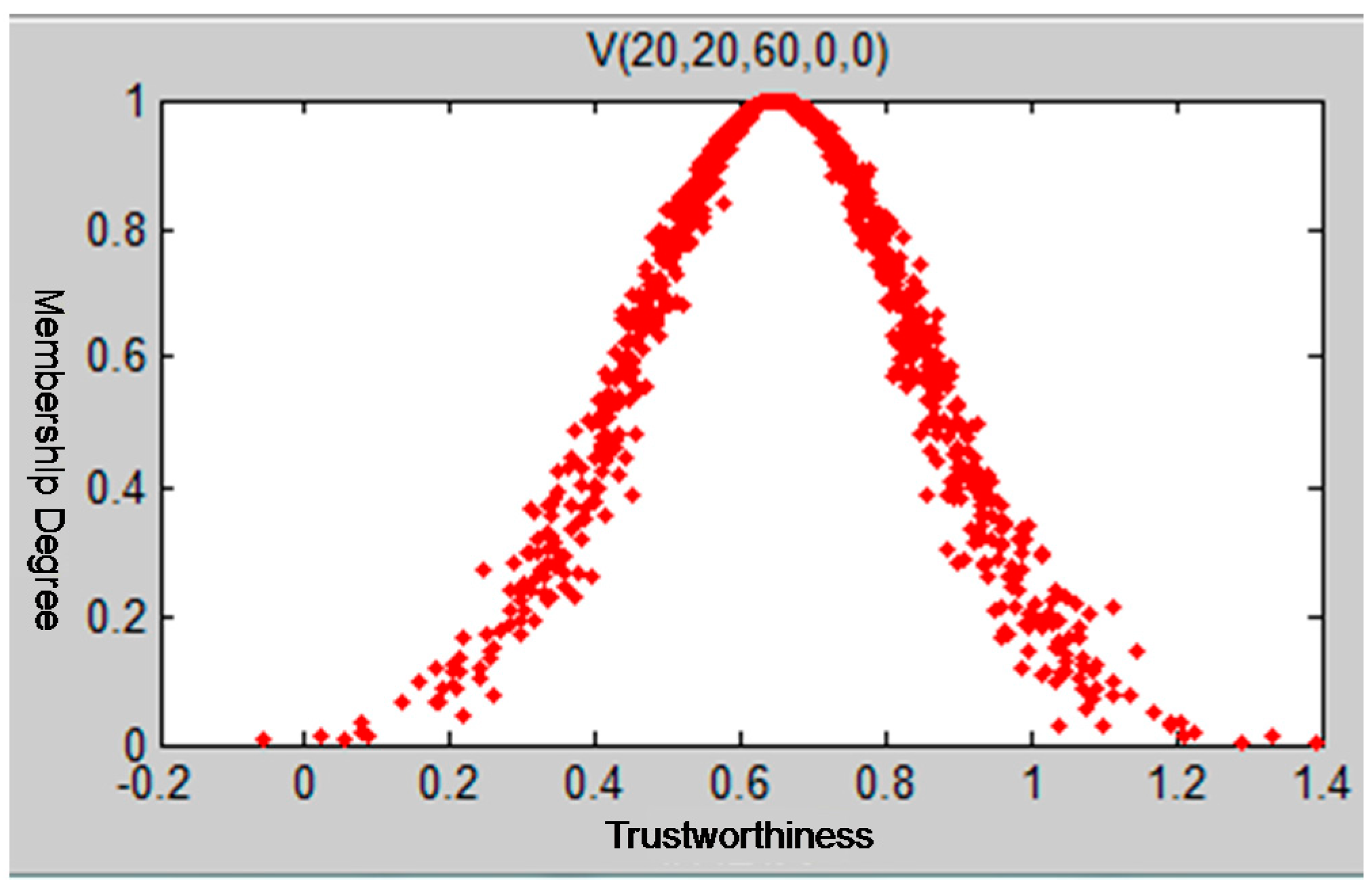
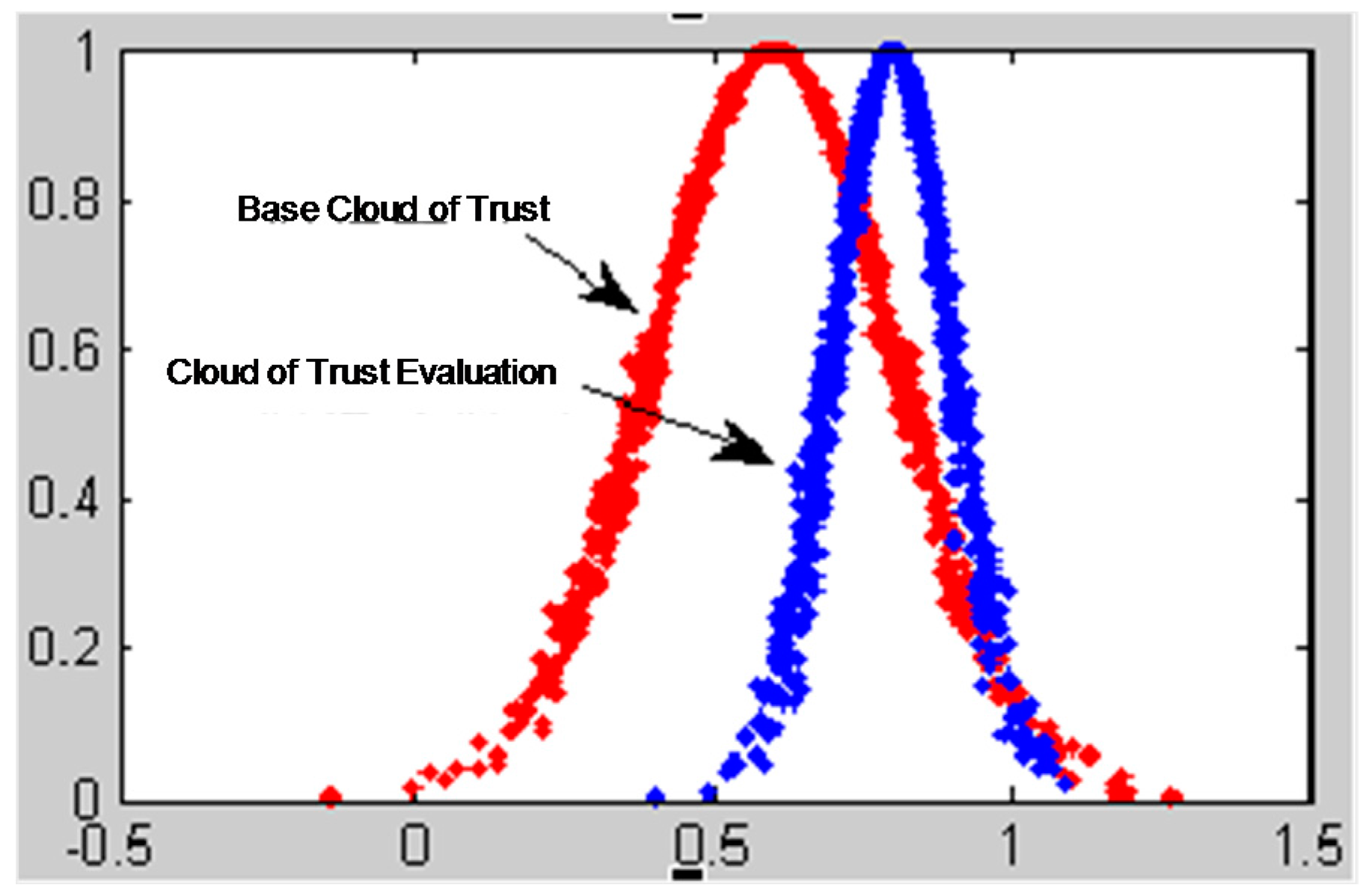
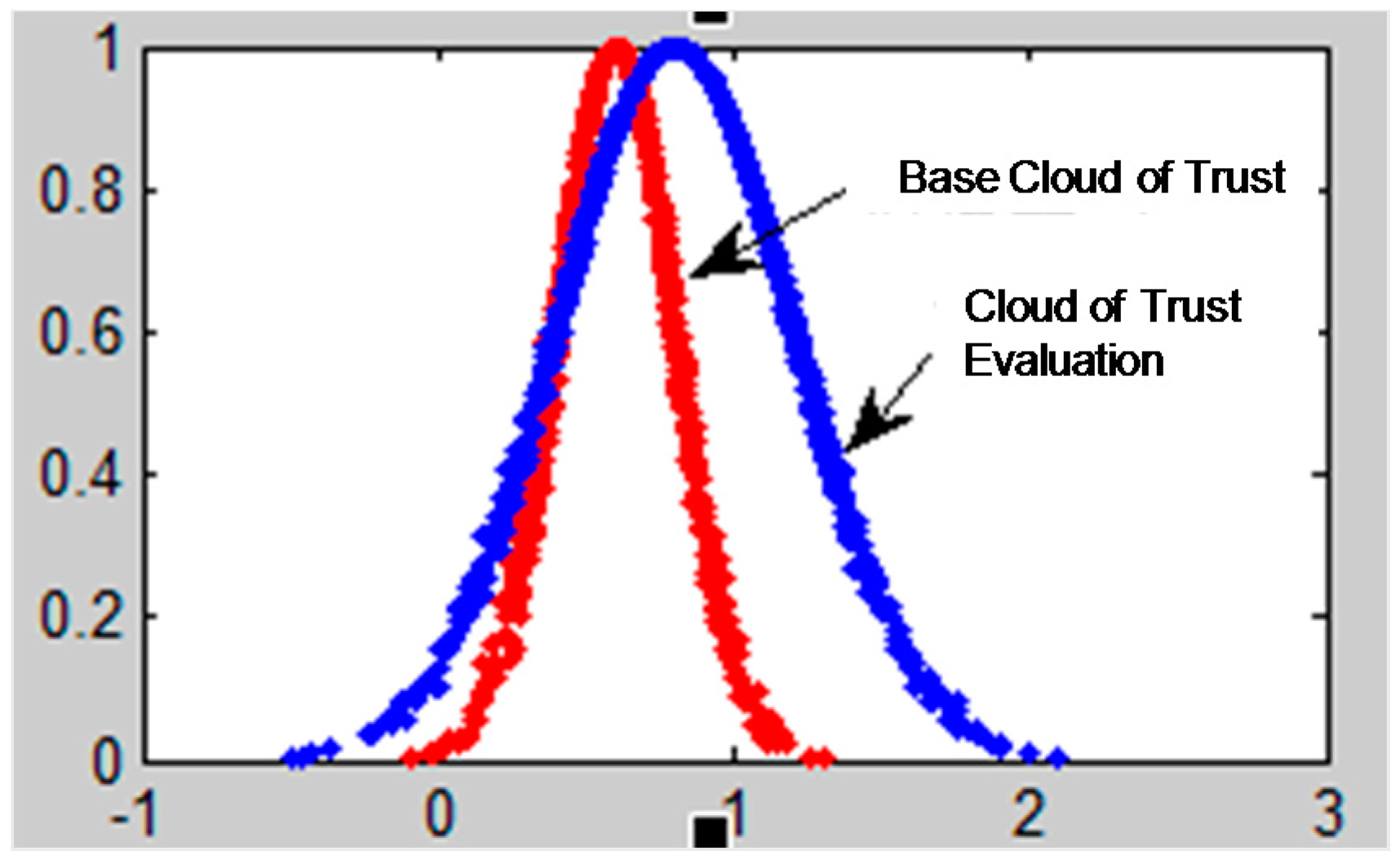
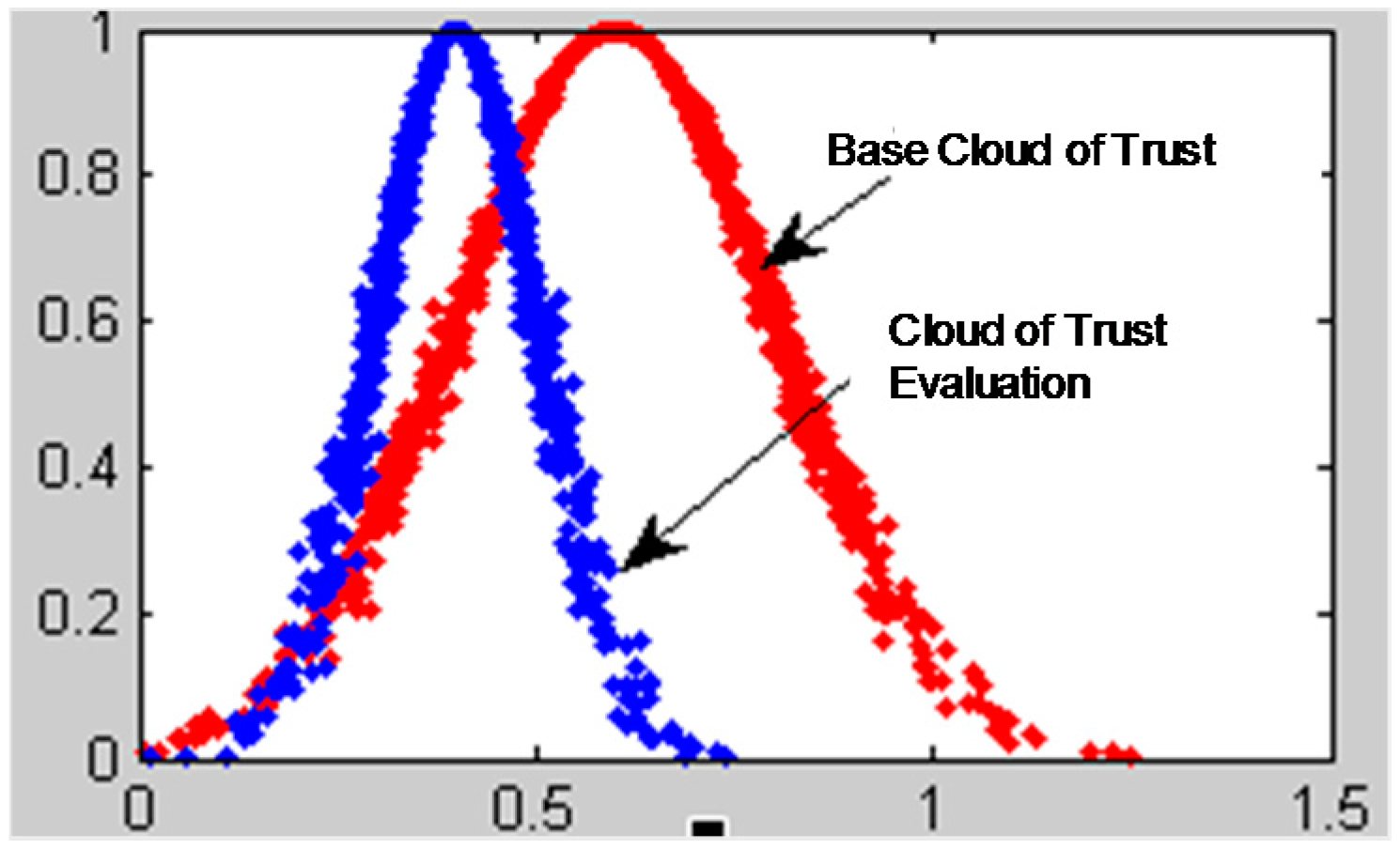
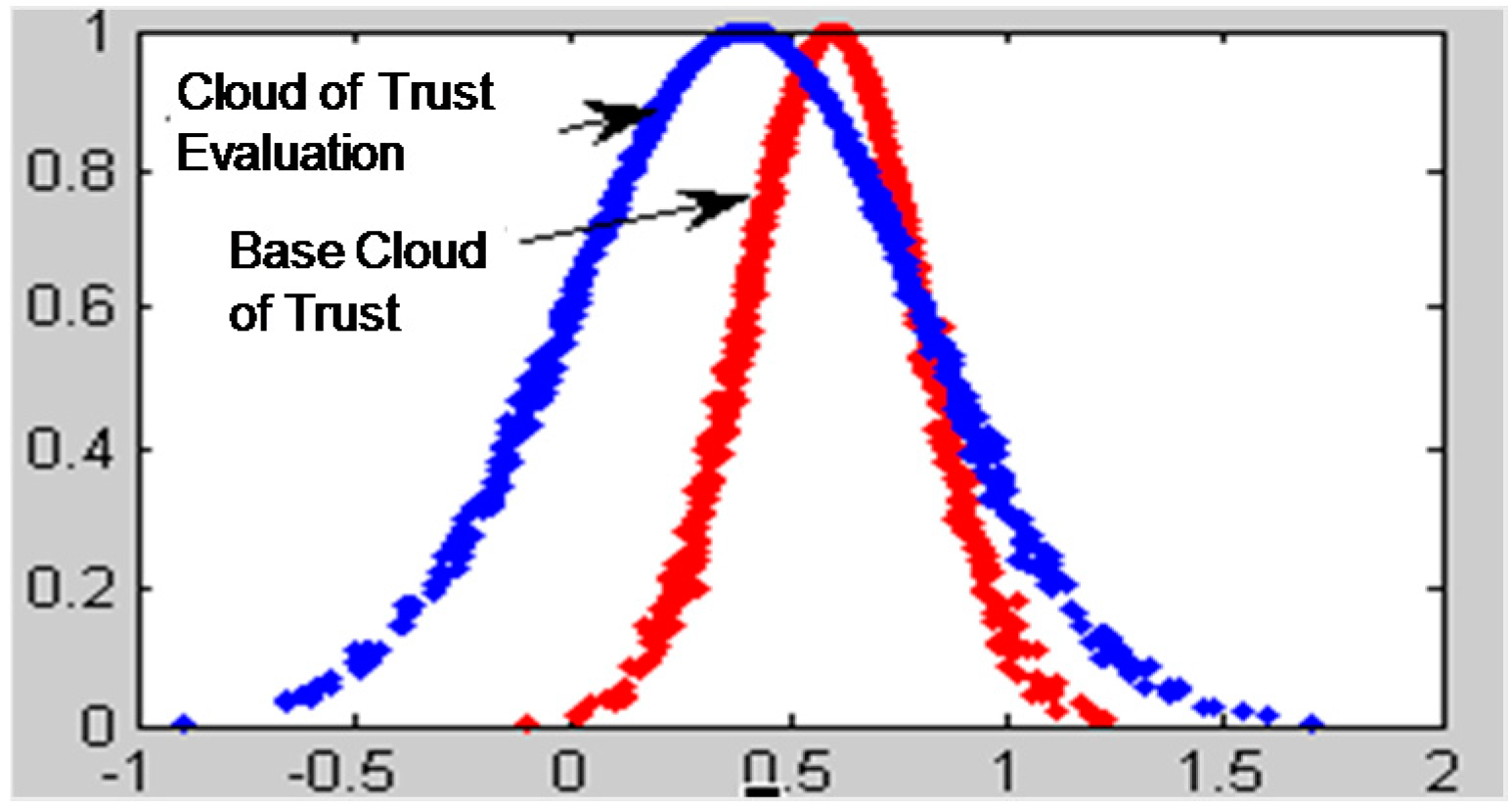
The traditional models of calculating recommendation degree only use the trust degree value to calculate the evaluated node’s trust conditions without taking the uncertainty of trust into consideration. From what has been introduced above, we know that the cloud model can reflect the trust condition of the evaluated nodes more comprehensively by using three digital characters. Integrating Ex, which expresses the node’s average trust value with the entropy En and the hyper entropy He, reflects the uncertainty of trust effectively.
We then introduce how to use the trust cloud to calculate the trust conditions of evaluated node . Let set to be the trust cloud of the evaluated node . We collect feedback records about trading conditions from other nodes in the time window . The node that has traded with node for i times is then denoted as . The parameter represents the recommending reliability of node and is the feedback rating of node to node for the transaction. Taking the records’ ratings as the sample values, the node’s recommending reliability is represented as the weights of sample numbers. The total number of samples is quite large. We then use the samples as an input and calculate the node trust cloud based on the following Algorithm 3.
| Algorithm 3: |
| Input: service node , evaluated node , total number of samples |
| Output: the evaluated node’s trust cloud . |
| (1) | , which sets parameters as zero. |
| (2) | Retrieve , which collects the rating record of node in the time window . |
| (3) | For to , we perform the following steps: Feedback source of which collects the nodes that give the rating records; Retrieve Feedback by , which collects the rating records of node to other trading nodes; Compute similarity by calculating the recommending reliability of node ; Calculate . |
| (4) | For to , perform , which takes the rating records value of as the sample input of the one-dimensional reverse cloud generator. |
| (5) | Output . |
In the calculation of the above node’s trust cloud, the value of total number of samples
should be as large as possible. It first ensures that the value
is positive in the algorithm, and then it can also reduce the errors that are generated by the reverse cloud generator algorithms. To get the trust cloud’s expectations by this algorithm, we use the following formula:
The characteristic parameter Ex of the trust cloud basically covers the trust information of the evaluated nodes. The uncertainty of trust is described by the other two characteristic parameters, entropy and hyper entropy. It is essential to build a more robust, accurate trust model to explore the node’s real trust behavior by fully mining the trust information contained in the three characteristic parameters of trust cloud.
When the total number of samples
is certain,
decides the discrete degree of trust. Therefore, we introduce the discrete factor
to measure and reflect the level of uncertainty of trust. We can use the three characteristic trust cloud parameters to distinguish a malicious recommended node from a goodwill recommended node. The analysis process is then as follows:
- (1)
The goodwill recommended node using characteristic parameter expectation value to measure the trust value of evaluated node is relatively accurate and the volatility of node’s behavior is low, so the discrete factor is small.
- (2)
The behavior of nodes that sometimes provide malicious information, and sometimes provide goodwill information is unstable with high volatility, so the discrete factor is large.
- (3)
The nodes that frequently provide malicious information, whose behavior and uncertainty factor is stable, will certainly generate a cloud expect value that becomes pretty low.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}