1. Introduction
Classic approaches of recurrent neural networks (RNNs), such as back-propagation through time [
1], have been considered difficult to handle. In particular learning in the recurrent layer is slow and problematic due to potential instabilities. About 15 years ago, reservoir computing [
2] was suggested as an alternative approach for RNNs. Here, it is not necessary to train connectivity in the recurrent layer. Instead, constant, usually random, connectivity weights are used in the recurrent layer. The supervised learning can be done by training the output layer using linear regression. Two types of reservoir computing are well established in the literature. The first is called liquid state machines (LSMs, [
3]), which are usually based on a network of spiking neurons. The second type is called an echo state nework (ESN, [
4]), which uses real valued neurons that initially use a sigmoid as a transfer function. Although a random recurrent connectivity pattern can be used, heuristically it has been found that typically the performance of the network depends strongly on the statistical features of this random connectivity (cf. for example [
5] for ESNs).
Thus, what is a good reservoir with regard to particular stationary input statistics? This has been a fundamental question for research in this field since the invention of reservoir computing. One fundamental idea is that a reservoir can only infer training output from this window of the input history of which traces still can be found inside the reservoir dynamics. However, if the necessary inference from time series in order to learn the training output is far in the past, it may happen that no traces of this input remain inside the reservoir. So, the answer seems to be that a good reservoir is a reservoir from whose states it is possible to reconstruct an input history with a time span that is as long as possible. More precisely, they should be reconstructed in a way that is sufficiently accurate in order to predict the training output. In other words, a good reservoir is a reservoir that has a good memory of the input history.
There have been efforts to quantify the quality of the memory of the reservoir. Most common is the
“memory capacity” (MC) according to Jaeger’s definition [
4]. However, MC has several drawbacks. For example, it is not directly compatible to a Shannon information based measure. Still, it illustrates that ESNs are relatively tightly restricted in the way that the upper limit of the MC is equal to the number of hidden layer neurons. So the capabilities of the network increase with the number of neurons.
One more important limiting factor with regard to the reservoir memory is the strength of the recurrent connectivity. According to the echo state condition, the nature of the reservoir requires that the maximum of its eigenvalues in modulus is smaller than 1, which is called the echo state property (ESP). This seems always to result in a exponential forgetting of previous states. Thus, forgetting is independent from the input statistics but instead has to be pre-determined and is due to the design of the reservoir dynamics.
In order to proceed, there are several important aspects. First, it is necessary to get rid of the intrinsic time scale of forgetting that is induced by
. More precisely, the remaining activity of inputs to the reservoir that date back earlier than
is a fraction smaller than
. Networks where the largest eigenvalue is larger than 1 cannot be used as reservoirs anymore, a point which is detailed below. One can try
and see if this improves the network performance and how this impacts the memory of the reservoir on earlier events. Steps toward this direction have been made by going near the “edge of chaos” [
5] or even further where the network may not be an echo state network for all possible input sequences but instead just around some permissible inputs [
6]. Presumably, these approaches still all forget exponentially fast.
Strictly, networks with
are not covered by the initial proof of Jaeger for the echo state condition. One important purpose of this paper is to close this gap and to complete Jaeger’s proof in this sense. The other purpose is to motivate the principles of [
7] in as simple as possible examples and thus to increase the resulting insight.
The intentions of the following sections of the paper are to motivate the concept of critical neural networks and explain how they are related to memory compression. These intentions comprise a relatively large part of the paper because it seems important to argue for the principle value of critical ESNs.
Section 2 introduces the concept of reservoir computing and also defines important variables for the following sections. An important feature is that Lyapunov coefficients are reviewed in order to suggest a clear definition for critical reservoirs that can be used analytically on candidate reservoirs.
Section 3 describes how critical one-neuron reservoirs can be designed and also introduces the concept of extending to large networks.
Section 4 explains why the critical ESNs are not covered by Jaeger’s proof. The actual proof for the echo state condition can be found in
Section 5. Certain aspects of the proof have been transferred to the appendix.
2. Motivation
The simplest way to train with data in a supervised learning paradigm is to interpolate data (cf. for example [
8]). Thus, for a time series of input data
that forms an input sequence
and a corresponding output data
one can choose a vector of non-linear, linearly independent functions
and a transfer matrix
. Then, one can define
can be calculated by linear regression, i.e.,
where the rectangular matrices
and
are composed from the data of the training set and
is the transpose of
A. Further, one can use a single transcendental function
such that
where
is a matrix in which each line consists of a unique vector and
is defined in the Matlab fashion; so the function is applied to each entry of the vector separately. Linear independence of the components of
can then be guaranteed if the column vectors of
are linearly independent. Practically, linear independence can be assumed if the entries of
are chosen randomly from a continuous set and
.
The disadvantage of the pure interpolation method with regard to time series is that the input history, that is , has no impact on training the current output . Thus, if a relation between previous inputs and current outputs exists, that relation cannot be learned.
Different from Equation (1), a reservoir in the sense of reservoir computing [
2,
9,
10] can be defined as
The recursive update function adds several new aspects to the interpolation that is outlined in Equation (1):
One important question is if the regression step in the previous section, and thus the interpolation, works at all for the recursive definition in Equation (
3). Jaeger showed ([
4], p. 43; [
11]) that the regression is applicable, i.e., the echo state property (ESP) is fulfilled, if and only if the network is uniformly state contracting. Uniformly state contraction is defined in the following.
Assume an infinite stimulus sequence
and two random initial internal states of the system
and
. To both initial states
and
the sequences
and
can be respectively assigned.
where
is another series and
shall be a distance measure using the square norm.
Then the system
is uniformly state contracting if it is independent from
and if for any initial state (
,
) and all real values
there exists a finite
for which
for all
.
Another way to look at the echo state condition is that the network
behaves in a time invariant manner, in the way that some finite subsequence in an input time series will roughly result always in the same outcome. In other words
independent of
,
and
and if
is sufficiently large.
Lyapunov analysis is a method to analyze predictability versus instability of a dynamical system (see [
12]). More precisely, it measures exponential stability.
In the context of non-autonomous systems, one may define the Lyapunov exponent as
Thus, if
then
approximates
b and thus measures the exponent of exponential decay. For power law decays, the Lyapunov exponent is always zero (For example, one may try
).
In order to define criticality, we use the following definition.
Definition 1. A reservoir that is uniformly state contracting shall be called critical if for at least one input sequence there is at least one Lyapunov exponent that is zero.
The echo state network (ESN) is an implementation of reservoir dynamics as outlined in Equation (
3). Like other reservoir computing approaches, the system is intended to resemble the dynamics of a biologically inspired recurrent neural network. The dynamics can be described for discrete time-steps
, with the following equations:
With regard to the transfer function
, it shall be assumed that it is continuous, differentiable, transcendental and monotonically increasing with the limit
, which is compatible with the requirement that
fulfills the Lipschitz continuity with
. Jaeger’s approach uses random matrices for
and
, learning is restricted to the output layer
. The learning (i.e., training
) can be performed by linear regression (cf. Equation (
1)).
The ESN fulfills the echo state condition (i.e., it is uniformly state contracting) if certain restrictions on the connectivity of the recurrent layer apply, for which one can name a necessary condition and a sufficient condition:
C1 A network has echo states only if
i.e., the absolute value of the biggest eigenvalue of
is below 1. The condition means that a network is
not and ESN if
.
C2 Jaeger named here initially
where
s is the vector of singular values of the matrix
. However, a closer sufficient condition has been found in [
13]. Thus, it is already sufficient to find a full rank matrix
D for which
The authors of [
14] found another formulation of the same constraint:
The network with internal weight matrix satisfies the echo state property for any input if W is diagonally Schur stable, i.e., there exists a diagonal such that is negative definite.Apart from the requirement that a reservoir has to be uniformly state contracting, the learning process itself is not of interest in the scope of this paper.
3. Critical Reservoirs with Regard to the Input Statistics
Various ideas on what types of reservoirs work better than others have been brought up. One can try to keep the memories of the input history in the network as long as possible. The principle idea is to tune the network’s recurrent connectivity to a level where the convergence for a subset of
with regard to Equation (
6) is
rather than
where
and
are system specific values, i.e., they depend on
.
A network according to Equation (
12) is still an ESN since it fullfils the ESP. Still, forgetting of initial states is not bound to a certain time scale. Remnants of information can —under certain circumstances— remain for virtually infinite long times within the network given that not too much unpredictable new input enters the network. Lyapunov analysis of a time series according to Equation (
12) would result in zero, and Lyapunov analysis of Equation (
13) yields a nonzero result.
In ESNs forgetting according to the power law of Equation (
12) for an input time series
is achievable if the following constraints are fulfilled:
The recurrent connectivity
, the input connectivity
of the ESN and the transfer function
have to be arranged in a way that if the ESN is fed with
one approximates
Thus, the aim of the training is
Since the ESN has to fulfil the Lipschitz continuity with
, the points where
have to be inflection points of the transfer function. In the following these inflection points shall be called epi-critical points (ECPs).
The recurrent connectivity of the network is to be designed in a way that the largest absolute eigenvalue and the largest singular value of
both are equal to one. This can be done by using normal matrices for
(see
Section 3.5).
3.1. Transfer Functions
The standard transfer function that is widely used in ESNs and other types of neural networks is the sigmoid function, i.e.,
The sigmoid transfer function has one ECP .
As a second possible transfer function, one may consider
Here, one has a infinite set of ECPs at
. It is important to have more than one ECP in the transfer functions because for a network with discrete values it appears necessary that each neuron has at least 2 possible states in order to have any inference from the past to the future. In the case of
, the only solution of Equation (
14) is
That type of trained network cannot infer information from the past to the present for the expected input, which significantly restricts its capabilities. One can see that from
The next iteration yields
which again, after training would require
Thus, the network can only anticipate the same input at all time steps.
In the case of Equation (
16), the maximal derivative
is 1 at
, where
n is an integer number (confer
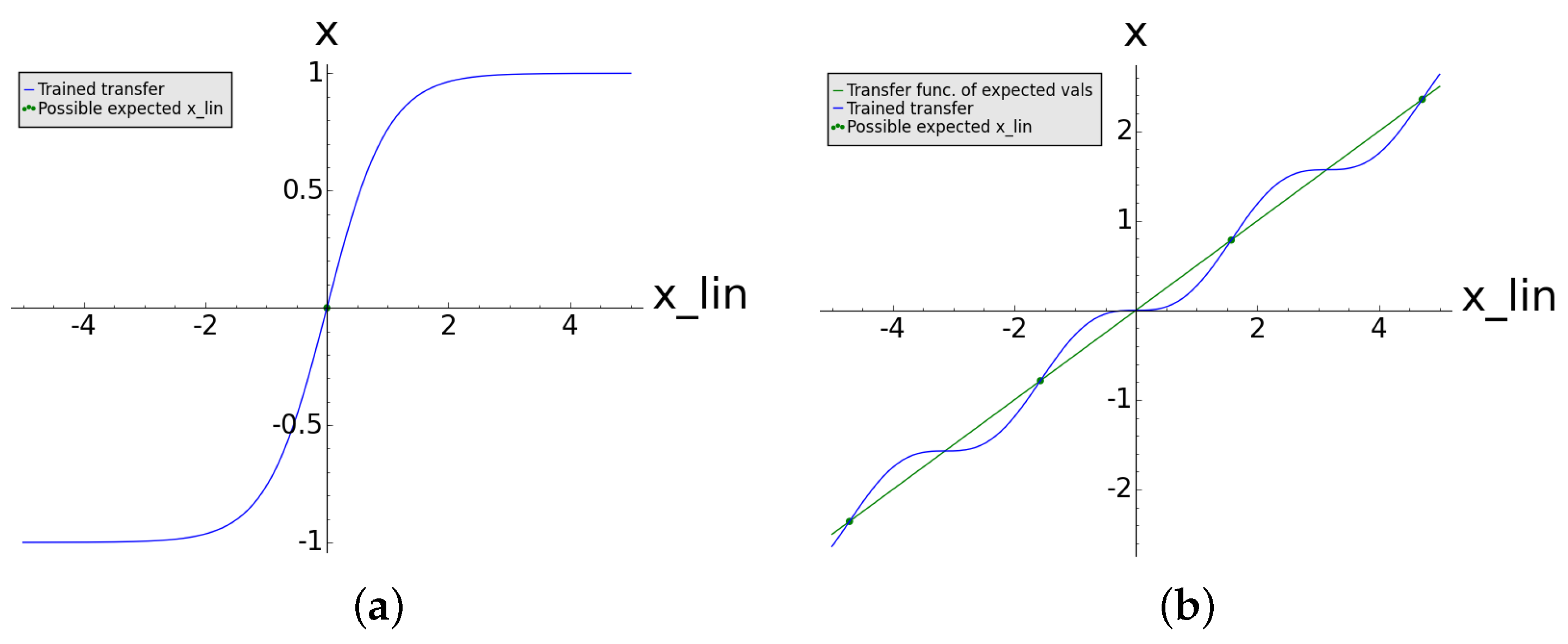
Figure 1). Here the main advantage is that there exists an infinite set of epi-critical points. However, all these points are positioned along the linear function
. This setting still significantly restricts the training of
. Here one can consider the polynomial with the lowest possible rank (cf. the green line in
Figure 1, left side) that interpolates between the epi-critical points (in the following called an epi-critical transfer function). In the case of Equation (
16) the epi-critical transfer function is the linear function
Thus, the effective dynamics of the trained reservoir on the expected input time series is -if this is possible- the dynamics of a linear network. This results in a very restricted set of trainable time series.
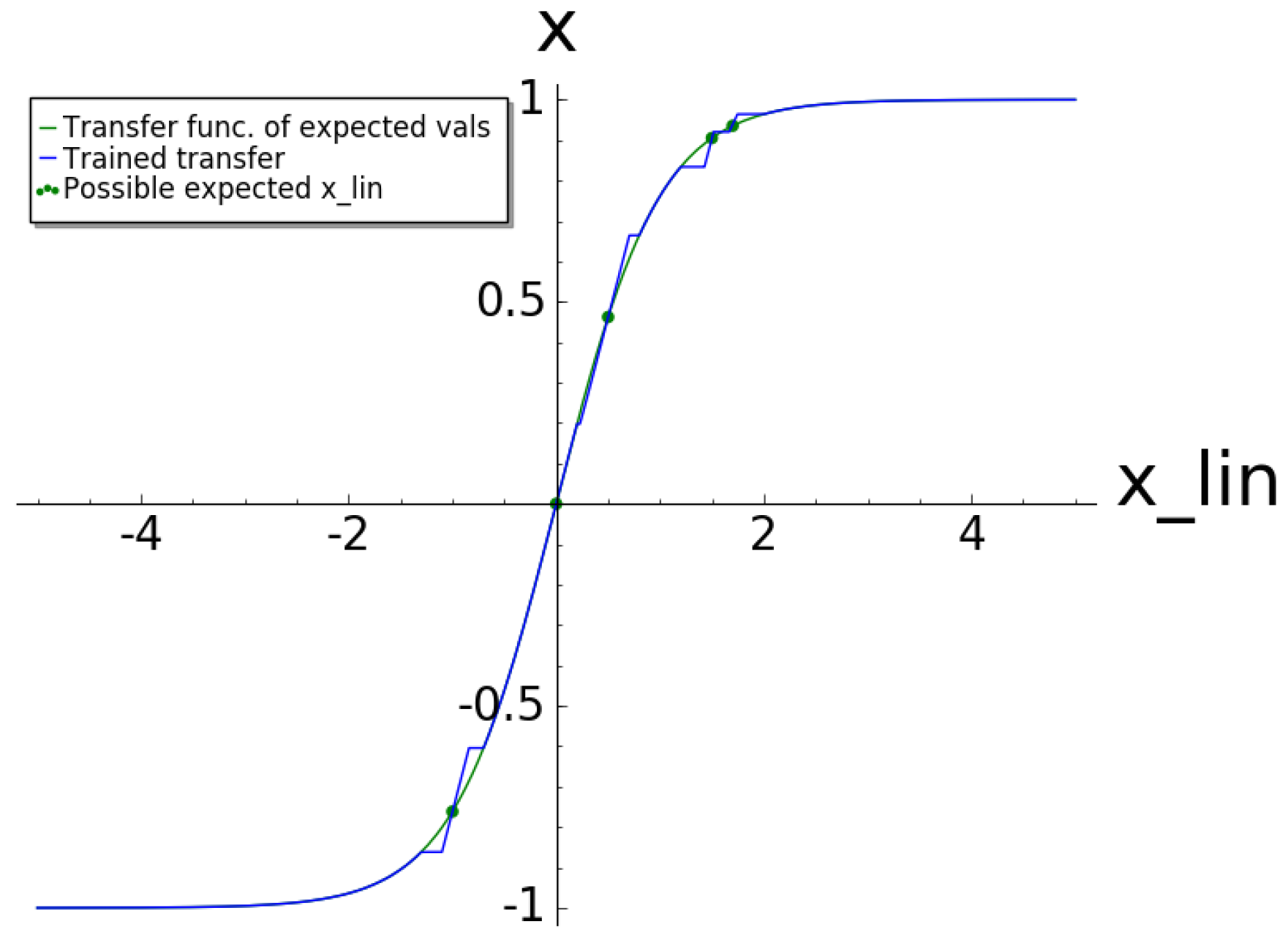
As an alternative, one could consider also a transcendental function for the interpolation between the points, such as depicted in
Figure 2. The true transfer function (blue line in
Figure 2) can be constructed in the following way. Around a set of defined epi-critical points
, define
θ as either
or
This is one conceptional suggestion for further investigations. The result is a transfer function with the epi-critical points and 0. The epi-critical transfer in this case is a function.
3.2. Examples Using a Single Neuron as a Reservoir
In this and the following sections, practical examples are brought up where a single neuron represents a reservoir. Single neuron reservoirs have been studied in other researches [
15,
16]. Here the intention is to illustrate the principle benefits and other features of critical ESNs.
First one can consider a neuron with
as a transfer function along with a single input unit
where in order to achieve a critical network
has to be equal to 1. i.e., the network exactly fulfills the boundary condition. From previous consideration one knows that
has the dynamics that results from
as an input. In this case the only fixed-point of the dynamics is
, which is also the epi-critical point if
.
Power law forgetting: Starting from the two initial values
and say
, one can see that the two networks converge in a power law manner to zero. On the other hand, for a linear network
with the same initial conditions the dynamics of the two networks never converge (independently of
). Instead, the difference between
and say
stays the same forever. Thus, the network behavior in the the case of
depends on the nature of the transfer function. For all other values of
b, both transfer functions result qualitatively in the same behavior in dependence on
b: either they diverge or they converge exponentially. Since
is also the border between convergence and divergence and thus the border between uniformly state contracting networks and not uniformly state contracting networks, the case of
is a critical point of the dynamical system, in a similar manner as a critical point at the transition from ordered dynamics to instability. In the following it is intended to extend rules for different transfer functions, where different transfer functions result in the critical point in uniformly state contracting networks and where this is not the case.
As a final preliminary remark, it has to be emphasized that a network being uniformly state contracting means that the states are contracting for any kind of input
. It does not mean that for any kind of input the contraction follows a power law. In fact, for all input settings
the contraction is exponential for the neuron of Equation (
17), even in the critical case (
).
3.3. Single Neuron Network Example with Alternating Input and Power Law Forgetting
As outlined above, for practical purposes the sigmoid function, i.e., , is not useful for critical networks because the only critical state occurs when total activity of such a network is null. In that case it is not possible to transfer information about the input history. The reason is illustrated in the following example, where instead of a sigmoid function other types of transfer functions are used.
So, the one-neuron network
with a constant
b, the transfer function of Equation (
16) and the expected alternating input
has an attractor state when also
is alternating with
independently from
b. Thus,
shall be interpreted as the expected input that directs the activity of the network exactly to where
and thus induces a critical dynamic
.
It is now interesting to investigate the convergence behavior for different values of
b considering differing starting values for internal states
and
.
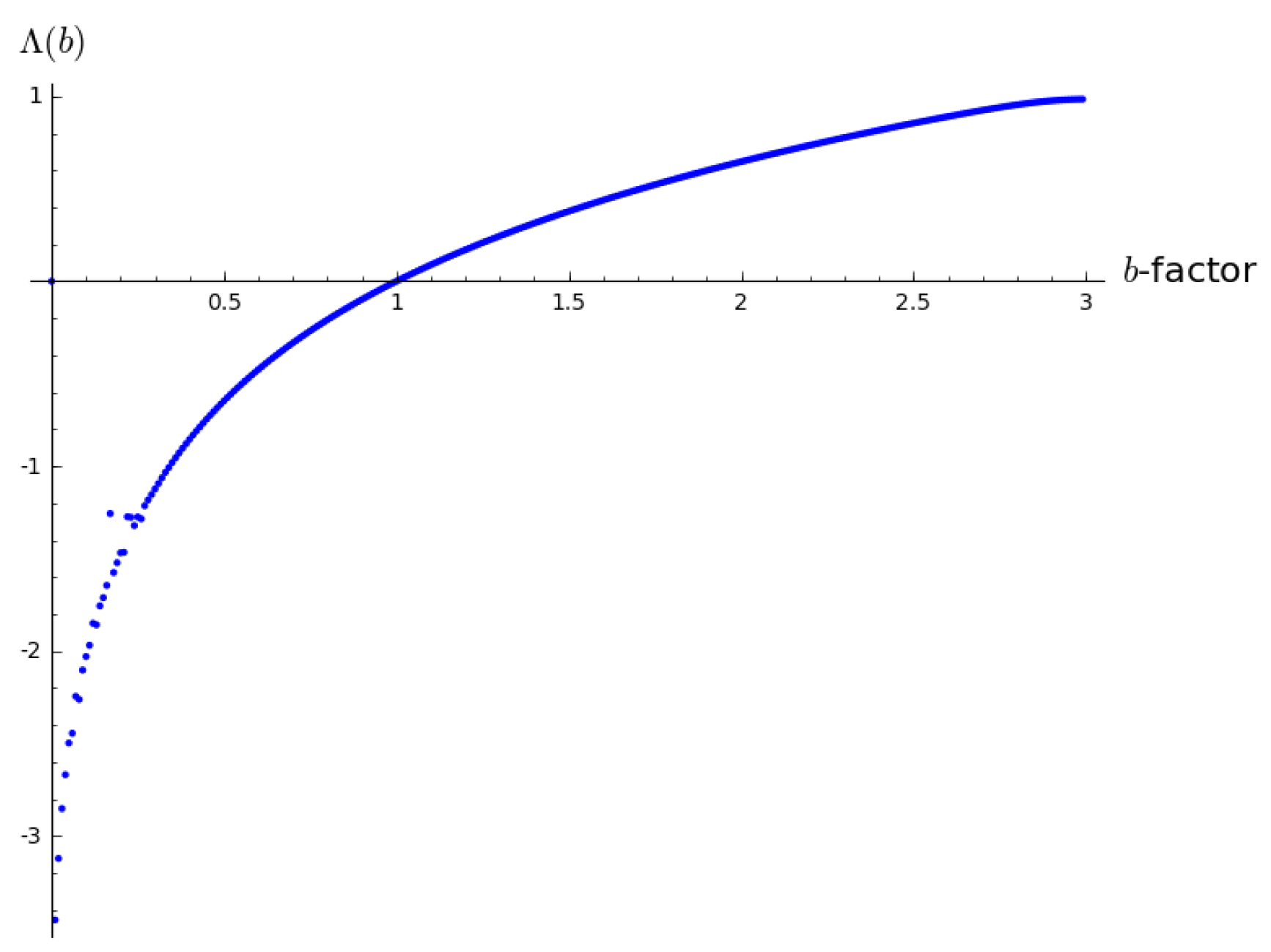
Figure 3 depicts the resulting different Lyapunov exponents for one-neuron networks with different values of
b. One can see that—not surprisingly—the Lyapunov exponent for
is zero. This is the critical point that marks the transition from order to instability in the system and at the same time the transition from ESP to non-ESP.
In the following the same network at
is investigated. Some unexpected input, i.e.,
, lets the network jump out of the attractor. If the input afterwards continues as expected, the network slowly returns to the attractor state in a power law fashion. Thus,
where
represents the undisturbed time series and
a is a constant value. Note that
contains all information of the network history and that the network was simulated using IEEE 754-2008 double precision variables, which have a memory size of 64 bits on Intel architecture computers. Although floating point variables are organized in a complicated way of three parts, the sign, exponent and mantissa, it is clear that the total reservoir capacity cannot exceed those 64 bits, which means in the limit a reservoir of one-neuron cannot remember more than 64 binary i.i.d. random numbers.
Thus, about 64 iterations after an unexpected input the difference between
and
should be annihilated. Thus, if both networks
and
receive the same unexpected input that is of the same magnitude, the difference between the
and
should reach virtually 0 within 64 iterations. The consideration can be tested by setting the input
where
is an i.i.d. random list of +1s and -1s, that produces a representative of
.
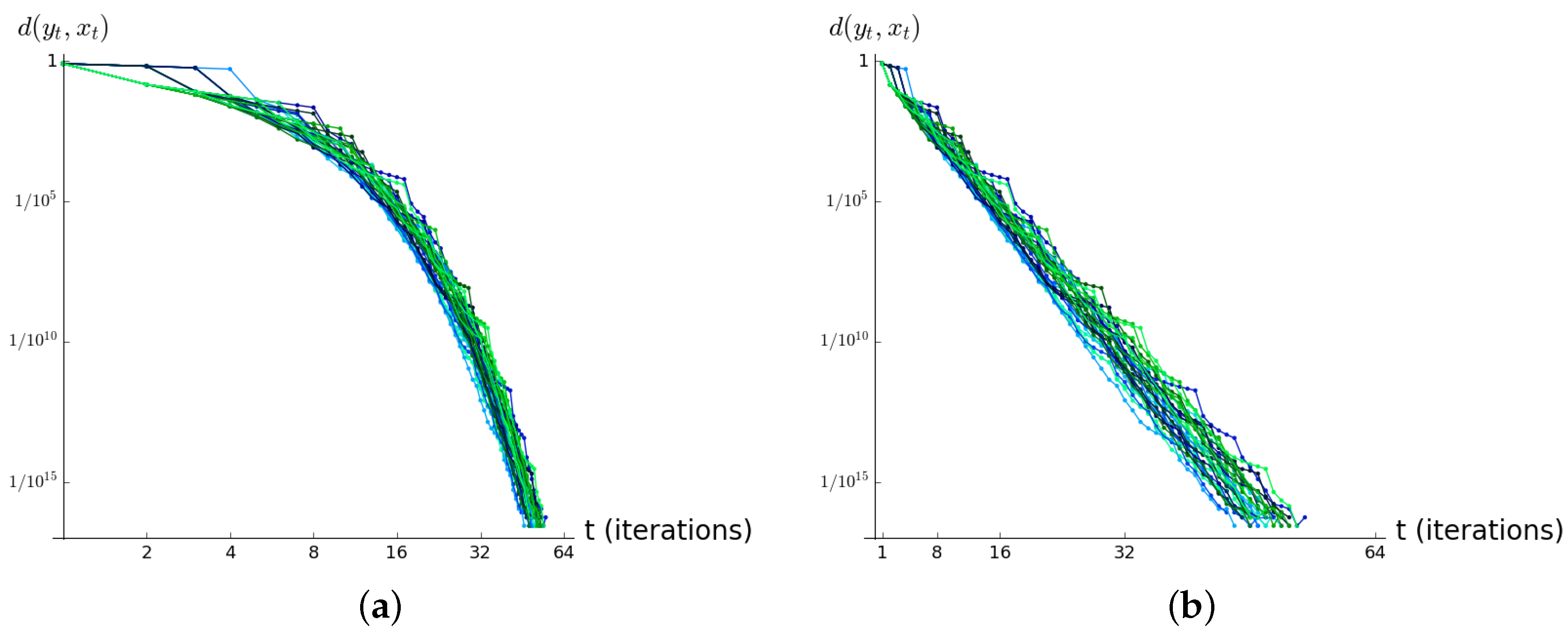
Figure 4 and
Figure 5 depict results from simulations, where after one iteration when two networks receive different inputs, both networks receive again the same input. Depicted is again the development of the difference between both networks
versus the number of iterations. The graphs appear in a double logarithmic fashion, so power law decays appear as straight lines. One can see that the networks that receive alternating, i.e., the expected input, pertains the difference for very long time spans (that exceed 64 iterations). On the other hand, if the network input for both networks is identical but i.i.d random and of the same order of magnitude as the expected input, the difference vanishes within 64 iterations.
The network distinguishes regular input from irregular input. Memories of irregular events pertain for a long time in the network provided that the following input is regular again. How a reservoir can be trained to anticipate certain input statistics has been discussed [
7]. Additional solutions to this problem are subject to further investigations.
3.4. Relation to “Near Edge of Chaos” Approaches
It is a common experience that—in spite of given theoretical limits for the ESPs—the recurrent connectivity can be significantly higher than
for many practical input statistics. Those over-tuned ESNs in many cases show a much better performance than those that actually obey Jaeger’s initial limit ESP. So, recently researchers came up with theoretical insights with regard to ESPs that are subject to a network and a particular input statistic [
6]. In the scope of this work, instead of defining the ESP for a network the ESP is always defined as related to a network and an input statistic. Also, similar efforts have been undertaken in the field of so-called liquid state machines [
17,
18].
One may assume that those approaches show similar properties as the one that has been presented here. However, for a good reason those approaches all are called
‘near edge of chaos’ approaches. In order to illustrate the problems that arise from those approaches, one may consider what happens if those overtuned ESNs are set exactly to the critical point. Here, just for the general understanding one may consider again a one-neuron network and a tanh as a transfer function, so
Note that the ESP limit outlined above requires that the recurrent connectivity should be
. An input time series than one can use is from the previous section
Slightly tedious but basically simple calculus results in a critical value of
for the input time series, where
. In this situation one can test for the convergence of two slightly different initial conditions and obtain a power law decay of the difference. However, setting up the amplitude of the input just a tiny bit higher is going to result in two diverging time series
and
. If the conditions of the ESN are chosen to be exactly at the critical point, it is possible that a untrained input sequence very close to the trained input sequence turns the ESN into a state where the ESP is not fulfilled anymore (for a related and more detailed discussion with a numerical analysis, confer [
19]).
For this reason all the networks have to be chosen at a significant margin away from the edge of instability. That is very different from the approach in the previous section where although the expected input sequence for the network is exactly at the critical point, all other input sequences result in a stable ESN in most cases with exponential forgetting.
3.5. How the One-Neuron Example Can Be Extended to Multi-Neuron Networks: Normal Matrices
A normal matrix
commutes with its own transpose, i.e.,
For a normal matrix
, it can easily be shown that
These matrices apply to the spectral theorem; the largest absolute eigenvalue is the same as the largest singular value, which makes a clear theoretical separation between networks that are uniformly state contracting and those that are not compatible to the echo state condition. Still, for normal matrices all previously known ES conditions do not determine to which of those two groups the critical point itself belongs.
Summarizing, all previous works result in theorems for an open set of conditions that are defined by the strict inequalities Equations (
9) and (
11). In the closest case, the case of normal matrices, when considering the singular condition
there is no statement of the above mentioned theorems if the network is uniformly state contracting.
Some simple, preliminary numerical tests reveal that in the case of networks that satisfy Equation (
21) the further development of the network strictly depends on the exact shape of transfer function.
4. Echo State Condition Limit with Weak Contraction
In the previous section, it has been shown how power law forgetting may occur in an ESN type neural network. These networks are all tuned to the point where . For this tuning it is still undetermined if the ESP is fulfilled or not even if normal matrices or one-neuron RNNs are used. The current section is dedicated to determining under which conditions Jaeger’s ESP can be extended to this boundary condition.
Jaeger’s sufficient echo state condition (see [
4], App. C, p. 41) has strictly been proven only for non-critical systems (largest singular value
) and with
as a transfer function. The original proof is based on the fact that
in combination with
is a contraction. In that case Jaeger shows an exponential convergence.
The core of all considerations of a sufficient condition is to give a close upper estimate of the distance between the next iterations of two different states
and
. The estimate is of the form
where the parameter
basically is quantified by the nature of the transfer function and the strength of the connectivity matrix. The estimate has to be good enough that the iterative application of
should result in a convergence to 0:
This is equivalent to investigating a series
with
and
which can prove that the requirement of uniformly state contraction (cf. Equation (
6)) is fulfilled. For example, consider the case of a reservoir with one-neuron as described in Equation (
17). Here the challenge is to find an estimator for
such that
where the chosen
still holds the limit in Equation (
22). For
, convergence can be proven easily:
Thus for
, one can easily define
. So
can be defined as
So Equation (
23) is fulfilled. The convergence is exponential. The arguments so far are analogous to the core of Jaeger’s proof for the sufficient echo state condition C2 that is restricted to one dimension.
For , this argument does not work anymore. Obviously, Jaeger’s proof is not valid under these circumstances. However, the initial theorem can be extended. As a pre-requisite, one can replace the constant with a function that depends on as an argument.
So one can try
where
and
have to be defined appropriately. This works for small values of
. However, it is necessary to name a limit for large
. Define
Three things have to be done to check this cover function:
First of all, one needs to find out if indeed the cover function
fulfills
In order to keep the proof compatible with the proof for multiple neurons for this work, one has to chose a slightly different application for
,
which serves the same purpose and is much more convenient for multiple neurons.
In
Appendix C one can find a recipe for this check.
Second, one has to look for the convergence of
when
. The analysis is done in
Appendix A.
Third, one needs to check
as long as
. Since the factor
is positive, smaller than one and constant, the convergence process is exponential, obviously.
Note that the next section’s usage of the cover function differs slightly even through it has the same form as Equation (
24).
5. Sufficient Condition for a Critical ESN
The content of this section is a replacement of the condition C2 where the validity of the ESP is inferred for .
Theorem 1. If hyperbolic tangent or the function of Equation (16) are used as transfer functions, the echo state condition (see Equation (6)) is fulfilled even if . Summary of the Proof. As an important precondition, the proof requires that both transfer functions fulfill
where
is defined for a network with
k hidden neurons as
Here, , are constant parameters that are determined by the transfer function and the metric norm ☐
In
Appendix C it is shown that indeed both transfer functions fulfil that requirement. It then remains to prove that in the slowest case we have a convergence in a process with 2 stages. In the first stage, if
there is a convergence that is faster or equal to an exponential decay. The second stage is a convergence process that is faster or equal to a power law decay.
Proof. Note with regard to the test function
:
In analogy to Jaeger, one can check now the contraction between the time step
t and
:
One can rewrite
where
. Next one can consider that one can decompose the recurrent matrix by using singular value decomposition (SVD) and obtain
. Note that both
and
are orthogonal matrices and that
is diagonal with positive values
on the main diagonal. We consider
Because
is an orthogonal matrix, the left side of the equation above is a rotation of the right side and the length
is the same as
. One can write
where the
are entries of the vector
. Since
and
is again a rotation matrix, one can write
where
is the
i-th component of the diagonal matrix
, i.e., the
i-th singular value.
In the following we define
and calculate
Merging Equations (
27) and (
29) results in the inequality
First, assuming
and since we know
, we get an exponential decay
This case is handled by Jaeger’s initial proof. With regard to an upper limit of the contraction speed (cf. Equation (
6)), one can find
If the largest singular value , then for some type of connectivities (i.e., normal matrices) the largest absolute eigenvalue is also larger than 1 due to the spectral theorem. In this case, the echo state condition is not always fulfilled, which has been shown also by Jaeger.
What remains is to check the critical case . Here again one can discuss two different situations (rather two separate phases of the convergence process) separately:
If
, we can write the update inequality of Equation (30) as:
Thus, for all
, the slowest decay process can be covered by
If
, then Equation (30) becomes:
One can replace
and again consider the sequence
which is discussed in
Appendix A. The result there is that the sequence converges faster than
Note that, although the Lyapunov exponent (cf. Equation (
7)) of
is zero, the sequence
converges in a power law fashion. Thus,
and thus ESP has been proven. ☐
Moreover, one can calculate the upper time limit
:
6. Summary, Discussion and Outlook
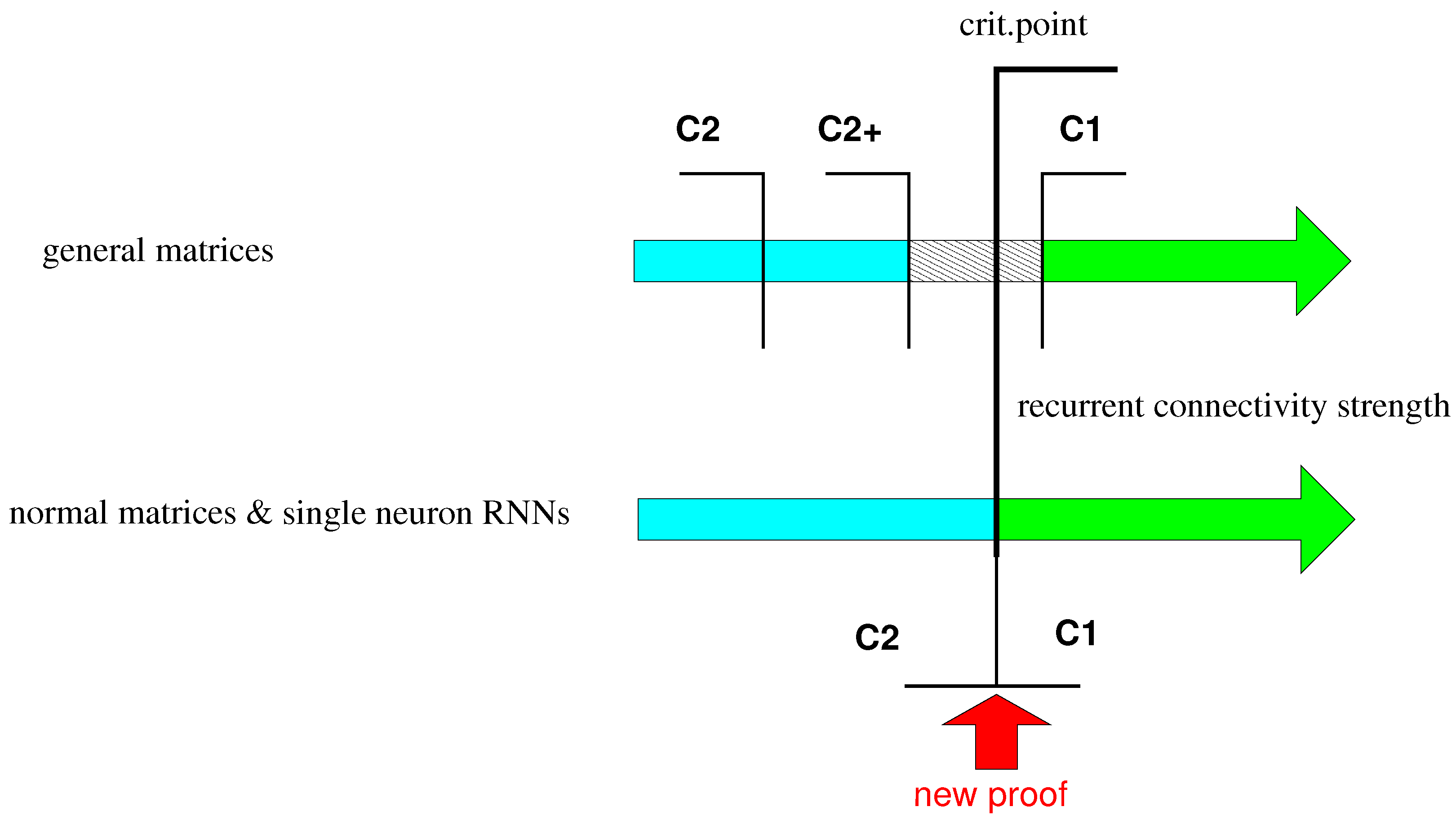
The background of this paper is to investigate the limit of recurrent connectivity in ESNs. The preliminary hypothesis towards the main work can be summarized in
Figure 6. Initially it is hard to quantify the transition point between uniformly state contracting and non-state contracting ESNs exactly. However, for normal matrices and one-neuron networks the gap between the sufficient condition and the necessary condition collapses in a way that there are two neighboring open sets. The first open set is known to have the ESP, and the other open set evidently does not have the ESP. What remains is the boundary set. The boundary set is interesting to analyze because it can easily be shown that here power law forgetting can occur.
The proof of
Section 4 shows a network is an ESN even if the largest eigenvalue of the recurrent connectivity matrix is equal to 1 and if the transfer function is either Equation (
15) or (
16). The proof is also extensible to other transfer functions. On the other hand it is obvious that some transfer functions result in networks that are not ESNs. For example a linear transfer function (
) is
not state contracting.
Even if the network is state contracting, it is not necessarily exponentially uniformly state contracting. Its rate of convergence might follow a power law in the slowest case. Several examples for power law forgetting have been shown in the present work. More examples of preliminary learning have been outlined in [
7]. One important target of the present research is to allow for a kind of memory compression in the reservoir by letting only the unpredicted input enter the reservoir.
One ultimate target of the present work is to find a way to organize reservoirs as recurrent filters with a memory compression feature. In order to bring concepts of data compression into the field of reservoir computing and in order to project as much as possible of the input history to the limit size reservoir, principles of memory compression have to be transferred into reservoir computing. However, the reservoir computing techniques that are analogous to classic memory compression have not been identified so far.
Another topic that needs further investigation is entropy in time series. Power law forgetting is only possible if the time series that relates to the criticality is either of a finite entropy, i.e., from a certain point in time all following entries of the time series can be predicted from the previous entries, or if the network simply ignores certain aspects of the incoming time series.
There also potential analogies in biology. Several measurements of memory decay in humans exist that reveal that there the forgetting follows a power law at least for a large fraction of the investigated examples [
20,
21].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





