1. Introduction
The development of the wind energy is very rapid with growing concerns about the energy and environmental problems nowadays. The global cumulative installed capacity reached 432,419 MW at a compound growth rate of 17% per year [
1]. Wind farms mainly use the large capacity variable speed constant frequency (VSCF) doubly-fed wind turbines (DFWT) as the main models [
2]. Its structure mainly includes the rotor, shaft, gearbox, the doubly-fed induction generator (DFIG), the converter, etc. Because of the long transfer chain of DFWT and the installation in the cabin at high altitude of tens of meters, or even hundreds of meters, precise alignment is rather difficult; on the other hand, due to the fluctuation of wind speed, start-stop of the units frequently happened. As time goes on, there will be a shift or deformation in some components, causing the misalignment between the generator and the gearbox [
3]. When misalignment happens, gearbox high-speed shaft and generator bearings will produce heavy dynamic load, which will not only increase axial and radial vibration, but also cause the bearing oil leakage, high temperature of bearing and attachment bolts and fastening bolts loosening. The accumulation of eccentric error even causes damage to bearings of the high-speed end and generator. Because misalignment is an important cause of early failure of large DFWT and may cause damage to two core parts including the gearbox and generator, it is necessary to study the misalignment fault diagnosis methods to ensure longstanding and stable running of the DFWT.
At present, there are many methods used in the wind turbines fault diagnosis. For example, the back propagation (BP) neural network based on the fruit flies algorithm optimization was used by Qi Liwan in fault diagnosis for the wind turbine gearbox [
4]; a fault diagnosis method based on learning vector quantization (LVQ) neural network was proposed by Ding at al. [
5]; the fuzzy clustering analysis method was applied to the wind motor gearbox fault by Li [
6]; the fault classification method based on the ART2 neural network and C-average clustering algorithm of wind turbine gearbox was used by Li et al. [
7]; an expert system model for the fault diagnosis of a wind turbine cabin was established by Zhang [
8]; a classification method based on support vector machine (SVM) was proposed by Liu et al. to classify the operating mode of wind turbines [
9]; a wind turbine main shaft bearing fault diagnosis based on SVM was studied by Huang [
10]; machine learning and data mining techniques organized in the framework of a general scheme that achieves fault diagnosis of wind turbines were studied by Precup et al. [
11]; a hybrid dynamic classifier for drift-like fault diagnosis was applied to wind turbine converters by Toubakh [
12]; a mixed Bayesian/Set-membership approach was used by Rosa et al. to solve the problem of fault detection and isolation of wind turbines [
13]; the interval nonlinear parameter-varying (NLPV) parity equations were used by Blesa et al. to solve the problem of fault diagnosis of a wind farm [
14]; and the interval observer approach and virtual actuators/sensors were applied by Blesa et al. in literature [
15], where the problem of Fault Detection and Isolation (FDI) and Fault Tolerant Control (FTC) of wind turbines were addressed. Compared with other intelligent algorithms, SVM has many advantages in learning ability, generalization performance, small sample processing capacity and the nonlinear processing capacity. Therefore, in this paper, SVM is used in the misalignment fault diagnosis.
There are three types of misalignment: parallel misalignment, angle misalignment and the comprehensive misalignment [
16]. Due to the short running time of large DFWT in China, the data of misalignment available for diagnostic studies are lacking. Thus, a 3D model was established by Solidworks (Solidworks 2014, version SP0) for a 1.5 MW wind turbine in this paper, and the model is then imported into Adams (Adams 2013, version 2013.1), where the normal working and the misalignment of the system are simulated. The vibration signals (angular acceleration) of the gearbox high-speed shaft are obtained for analysis. The methods for extracting fault features from vibration signals mainly include traditional and modern signal processing methods [
17]. The traditional signal processing methods include time domain analysis and frequency domain analysis. Signal stability hypothesis is the basis of the traditional time domain or frequency domain analysis. However, the vibration signals of DFWT usually have the characteristics of being nonlinear and non-stationary. Therefore, the modern signal processing methods should be used to analyze them. Many scholars have done a lot of work in this area. For example, wavelet decomposition was used by Zhang o process the vibration signals of gearbox in DFWT [
18]; while wavelet packet was used by Wang [
19], a method of multi resolution empirical mode decomposition (EMD) combined with the average in frequency domain was proposed by Ju et al. to extract gear fault frequency [
20]; EMD and the envelope spectrum of the intrinsic mode function (IMF) was used by Zheng et al. to identify the fault types of rolling bearing [
21] and so on. The advantages and shortcomings of modern signal processing methods now commonly used are summarized in
Table 1.
Among these commonly used processing techniques summarized in
Table 1, EMD proposed by Hibert–Huang is a signal processing technique to decompose a data set into several IMFs by a sifting process, reducing the coupling between the signal characteristic information. Using the EMD method, the feature information of the original data can be grasped accurately and effectively, which is conducive to mining deep feature [
35]. However, there will be divergent phenomenon at both ends of the date when using the EMD method, which may result in the entire data sequence gradually being contaminated and the decomposition effect becoming severely distorted [
36,
37,
38,
39]. To solve this, a mirror extension algorithm is used to improve the EMD in this paper. After the vibration signals of DFWT processed by the IEMD, the energy entropy of the IMF are calculated and taken as the inputs of SVM. Meanwhile, PSO is used to optimize the parameters of SVM to get better classification performance. The results show that the proposed method can effectively identify the different misalignment types.
2. The Related Theories
2.1. The Improved EMD
The basic idea of EMD is to decompose a complex non-stationary signal into a finite number of IMF, and the IMF must satisfy the following:
The amount of extreme values and passing zeros of the function must be equal to or differ by one at most;
The average value of the upper envelope formed by the local maximum points and the lower envelope formed by the local minimum points of the function is zero.
The specific steps of decomposing the original signal
by EMD are as follows:
- (1)
Find out all the maximum points and the minimum points of the original signal firstly. Then, fit the upper envelope
and the lower envelope
by the cubic spline interpolation. The average value
can be obtained. Assume:
- (2)
Judge whether meets the two conditions of IMF. If it is satisfied, then is the first IMF component; if not, then take as a new . Repeat step (1) until meets the two requirements.
- (3)
After the first IMF component
is decomposed from the original signal
, separate
from
to get the rest
:
Take as the original data and repeat steps (1), (2) and (3). The second IMF component of the original signal can be then obtained. Repeat n times, and , ,…, can be obtained. The process will last until the remainder becomes a monotonic function.
Finally,
can be expressed as follows:
The IMF components contain different frequency band elements of the original signal , while the remaining part represents the central tendency of .
According to the maximum values and minimum values provided by the original signal, cubic spline interpolation is performed to obtain the upper and lower envelope in the EMD processing. However, the two end points of the signal may not be extreme value points, which will produce the fitting error. The error will gradually spread to the inside signal with the decomposition process, causing the waveform of IMF component to become seriously distorted. This is called the end effects of the EMD. In order to maintain the authenticity of the data, the mirror extending method is used to improve the EMD in this paper.
The mirror extending method is based on the characteristics of mirror symmetry mapping. To minimize the side effect, the mirror is placed in the position that ensures that the signal has symmetrical extreme values. The specific steps are:
- (1)
To draw the curves at both ends and mark the corresponding extreme values (the maximum and minimum);
- (2)
To decide the position of the mirror according to the distribution characteristics of the curves, and make the signal in the mirror and the original signal connected end-to-end to form a closed loop;
- (3)
To get the new signal with the length of two times the original data.
By extension, the upper and lower envelope obtained by fitting are completely determined by the internal data, and the end effects are solved in essence.
2.2. The Principles of SVM
SVM was proposed by Vapnik in 1995, which takes the training error as the constraint condition of the optimization problem and minimizes the confidence range as the objective of optimization. SVM is a kind of learning method based on structuring risk minimization principle, with better promotion ability than other traditional methods [
40]. Since the solving process of SVM is finally transformed into a quadratic programming resolving, its solution is the only optimal one. SVM shows many unique advantages in solving nonlinear and high-dimensional pattern recognition problems [
41,
42,
43]. The principle of SVM can be briefly described as giving training samples
,
, …,
, where
,
, and
is the number of training samples. They can be separated by a hyper plane, and the hyper plane can be expressed as follows:
where
and
, respectively, represent the normal vector and the constant term. When
and
are the best, it means the optimal hyper plane has been found, which makes the distance between the positive and negative samples the largest.
For linearly inseparable problems, the samples can be mapped to the hyper plane by the kernel function
to realize linear separability. Its objective function is as follows:
where
is the Lagrange operator;
is the punishment factor, and its basic function is to control the penalty of the wrong samples;
is the kernel function, and its basic function is to transform the vectors of low-dimensional to the inner product in the high-dimensional.
The kernel functions used in SVM are mainly linear kernel function, polynomial kernel function, radial basis kernel function and sigmoid kernel function. For the selection of kernel function, there is no definite criterion. Many studies and experiments show that the radial basis function (RBF) is a better choice when there is not enough prior knowledge [
44]. In this paper, the RBF is used as the kernel function. The function is as follows:
where
is the kernel parameter.
After determining the type of kernel function, the penalty parameter and the RBF parameter should be decided. Parameter determines the training error and the generalization ability of the classifier; parameter affects the distribution form of the samples in the feature space. The selection of them is very important for the performance of the classifier. The traditional grid search is a way to find the optimal parameters, but the search result may not be necessarily good. Thus, in this paper, PSO is used to select the parameters of and to improve the classification performance.
2.3. Particle Swarm Optimization
PSO is a kind of swarm intelligence optimization algorithm besides the ant colony algorithm and the fish swarm algorithm, which was first proposed by Kennedy and Eberhart in 1995. PSO is used to initialize a group of particles in the solution space, and each particle represents a potential optimal solution to the optimization problem. The characteristics of the particles are represented by three indexes of position, velocity and fitness value. Fitness value can be calculated by the fitness function, and the size of the value represents the goodness and badness of the particle. The particles’ location are updated by tracking the individual extreme value and the population extreme value when they move in the solution space. The fitness value of each particle is calculated when it updates its location. The principle can be briefly described as follows.
Supposing in a
-dimensional search space, there is a population
, consisting of
particles. The
i-th particle is represented as a
D-dimensional vector of
, which represents the position of the
i-th particle in the
D-dimensional search space, and it also represents a potential solution to the problem. According to the objective function, the fitness value of each particle's position
can be calculated. If the velocity of the
i-th particle is
, the individual extremum is
, the population extremum is
, and then the velocity and position of the particle are updated according to the following equations:
where
;
;
is the number of iterations;
and
are learning factors, which are non negative constants, making the particles learn from their own or other better particles to achieve the purpose of being close to the better position of itself or the whole group;
and
are random numbers distributed in [0, 1] to maintain the diversity of group. In order to prevent the blind search of particles, it is generally recommended to limit the position and velocity to a certain range of
and
.
3. Acquisition of Samples for Diagnosis
A 1.5 MW wind turbine system in a certain factory is studied in this paper. Gearbox, coupling, generator, etc., are modeling and assembling by SolidWorks firstly. Secondly, the models are saved in SolidWorks as Parasolid(.x_t) format. Then, they are imported into Adams. According to the actual status of the wind turbine system, material definition, motion constraints, drive and contact force for components and parts are added. In this paper, four states of normal working condition, parallel misalignment, angle misalignment and the comprehensive misalignment are studied, respectively. The models have been verified before the vibration signals are extracted from the gearbox high-speed shaft.
3.1. Verification of the Models
3.1.1. Normal Working State
At normal working state, the model is verified by the speed of the gearbox, generator shaft and the meshing frequency. The comparison of theoretical results and simulation results are listed in
Table 2.
It can be seen the relative error is very small by comparing the theoretical results with the simulation results in
Table 2. This demonstrates that the model of normal working state is correct.
3.1.2. At Fault Conditions
The shaft radial force and axial force are used to test the validity of the failure models. In theory [
45], the characteristics of misalignment can be summarized in
Table 3.
The actual outputs of the failure models would be described below:
Parallel Misalignment
In Adams, the local coordinate system (Marker) can be created in the left half coupling mass center. In addition, the rotation axis of the revolute joint relative to the ground is arranged on a
z-axis of the Marker global coordinate system. Then, the Marker global coordinate system is translated a certain distance along the
y-axis to make the mechanism rotate. The deviation between the center of mass and the center of rotation can lead to the eccentric mass excitation to the mechanism; thus, the parallel misalignment of the rotor shaft of the generator in this distance can be simulated. Some results of the parallel misalignment are shown in
Table 4.
From
Table 4, it can be found that the fundamental frequency and the frequency-doubled of the radial force and axial force are obvious when parallel misalignment exists. With the increment of parallel misalignment, the amplitude increment of the fundamental frequency and frequency-doubled of the radial force is far bigger than axial force, that is, the radial vibration is the main. This is in accordance with the theoretical analysis shown in
Table 3.
Angle Misalignment
The local coordinate system (marker) rotates a certain angle around the
y-axis, and the
z-axis of the local coordinate system is set up as the orientation of revolution joint, and then the corresponding angle misalignment can be simulated. Some results of the angle misalignment are shown in
Table 5.
From
Table 5, it can be found the fundamental frequency of radial force and axial force are obvious when angle misalignment exists. With the increment of angle misalignment, the fundamental frequency amplitude is also increasing, but priority is given to the axial vibration. This accords with the theoretical analysis shown in
Table 3.
Comprehensive Misalignment
Adding the parallel misalignment and angle misalignment in the local coordinate system (maker) of the left half coupling at the same time, comprehensive misalignment can be simulated. Some results of the comprehensive misalignment are shown in
Table 6.
From
Table 6, it can be seen that the radial vibration and axial vibration are obvious at the same time, as well as the fundamental frequency and the frequency doubling when the comprehensive misalignment happens. The simulation results verify the theoretical conclusion very well.
Through validation, it can be concluded the simulation results accord with theoretical conclusions. This is effectively guaranteeing the validity of the extraction of vibration signals.
3.2. Acquisition of the Vibration Signals of the Gearbox High-Speed Shaft
In this paper, the vibration signals (angular acceleration) of the gearbox high-speed shaft are obtained for analysis.
According to the requirements of the selected unit, the allowance range of the parallel misalignment is 0–0.15 mm. The allowance range of the angle misalignment is 0°–0.05°. In these ranges, the wind turbine system runs normally. In this paper, the range of parallel misalignment simulated is 1–10 mm. The range of angle misalignment that simulated is 0.10°–10°. The samples used are simulated by the method described above from four cases of normal working conditions, parallel misalignment, angle misalignment and the comprehensive misalignment. Each kind of sample is 68, with a total of 272 samples.
4. Extracting IEMD Energy Entropy from the Vibration Signals
Entropy is a measure of the uncertainty degree of the information, including energy entropy, singular entropy, and the approximate entropy (they are generally referred to as the information entropy). Energy entropy has a very good effect on the extraction of non-stationary and nonlinear complex signal statistical characteristics [
46]. Its definition is as follows:
Assuming
where
,
is the amplitude of each discrete point.
Then, the energy entropy is the following:
When misalignment occurs in DFWT, the frequency of the vibration signal will change, and so will the energy distribution. Therefore, the energy entropy can be used to reflect the characteristics of vibration signals. In this paper, vibration signals are analyzed by the IEMD first, and then the energy entropy of the IMF components are calculated. Different numbers of the IMF may be obtained from different vibration signals, and the correlation coefficient method is used to determine the number of IMF components to be put into the SVM. The correlation coefficient method is to determine the correlation coefficient between the IMF information and the original signal [
47]. Assuming that a non-stationary signal
can be decomposed into a finite mutually uncorrelated component
, that is:
the correlation coefficient of each component and the original signal is calculated as:
and the larger the value of correlation coefficient, the greater the relevance, and vice versa.
For example, after processing the vibration signal, which is shown in
Figure 1 by IEMD, the correlation coefficients of all IMF components are calculated as shown in
Table 7.
The contribution rate of the first eight IMF components in 13 IMFs reaches 92.23%. Thus, it can be concluded that the first eight IMFs contain the main information of the signals. Through a lot of experiments, it is known that the correlation between the first several IMF components and the original signal are relatively big. The contribution rates of the first eight IMFs are over 90%. Therefore, they are used to calculate the energy entropy to characterize the different states in this paper. The partial data of the first eight IEMD energy entropies of the vibration signals are shown in
Table 8.
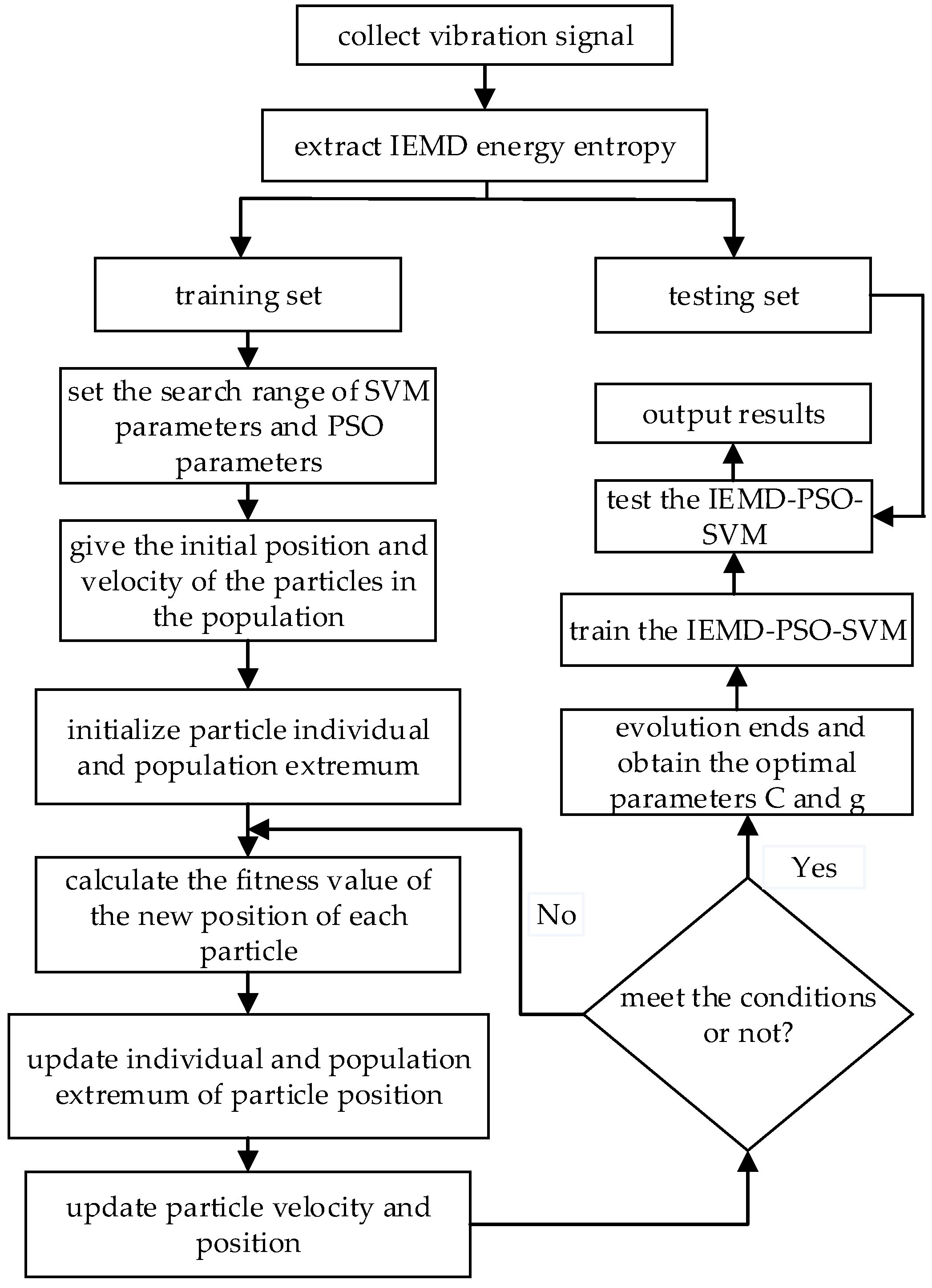
5. Fault Diagnosis Based on IEMD Energy Entropy and PSO-SVM
After extracting the IEMD energy entropy of the vibration signals, the samples were divided into two equal groups, one was the training set, containing 45 × 4 samples, and the other was the testing set, containing 23 × 4 samples. The training samples were used to obtain the optimized SVM classifier (3
-fold cross validation). The PSO algorithm was used to optimize the penalty parameter
and kernel parameter
of SVM, and the whole fault diagnosis processing can be referred to as IEMD-PSO-SVM; the specific implementation is shown in
Figure 2.
Learning factors
and
control the degree of interaction between the individual experience and the population experience, which reflects the information exchange between the groups. The appropriate choice of
and
can not only speed up the search but also avoid the whole population plunging into the local optimum. Learning factors generally take a fixed constant value [
48], according to experience. In this paper, let
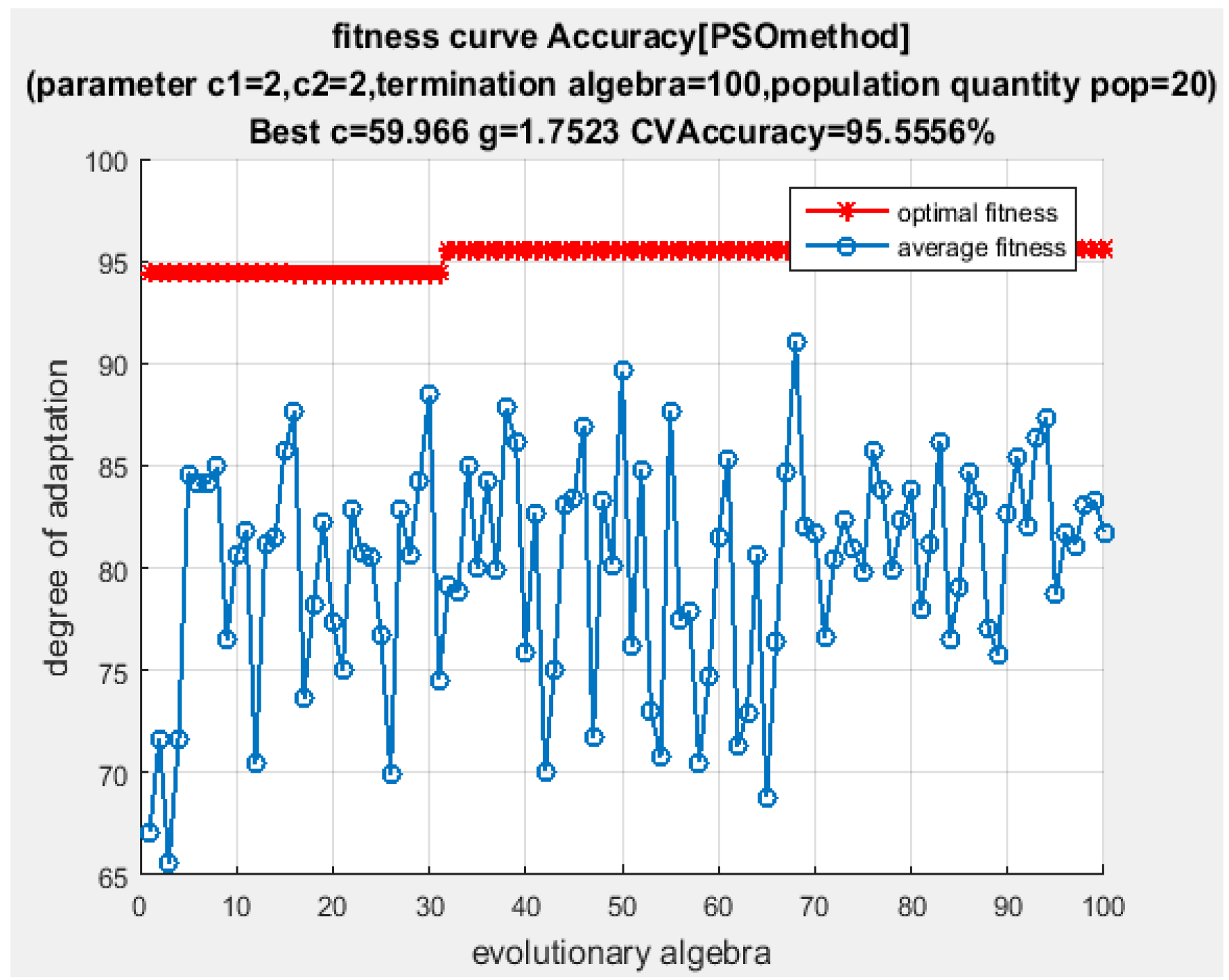
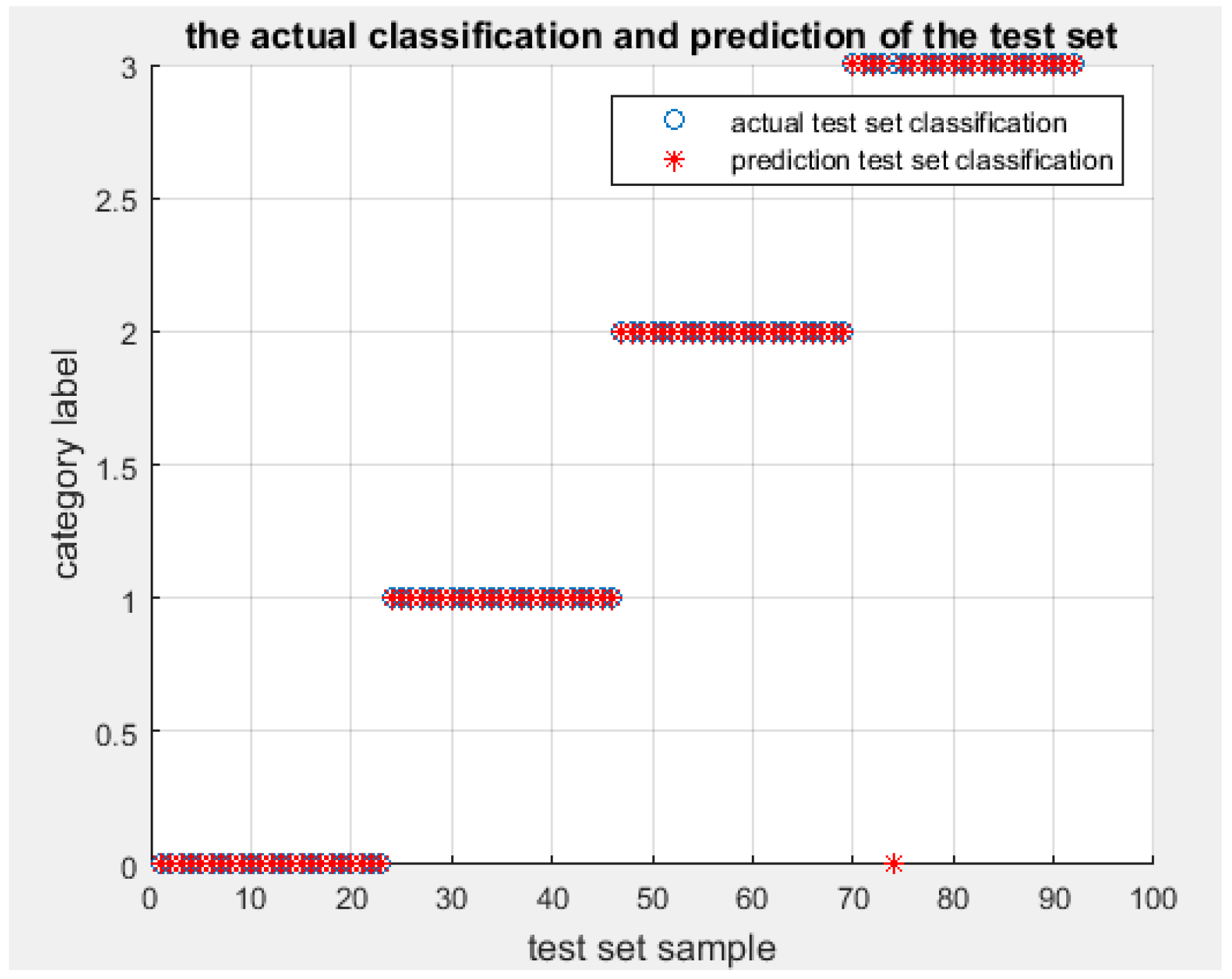
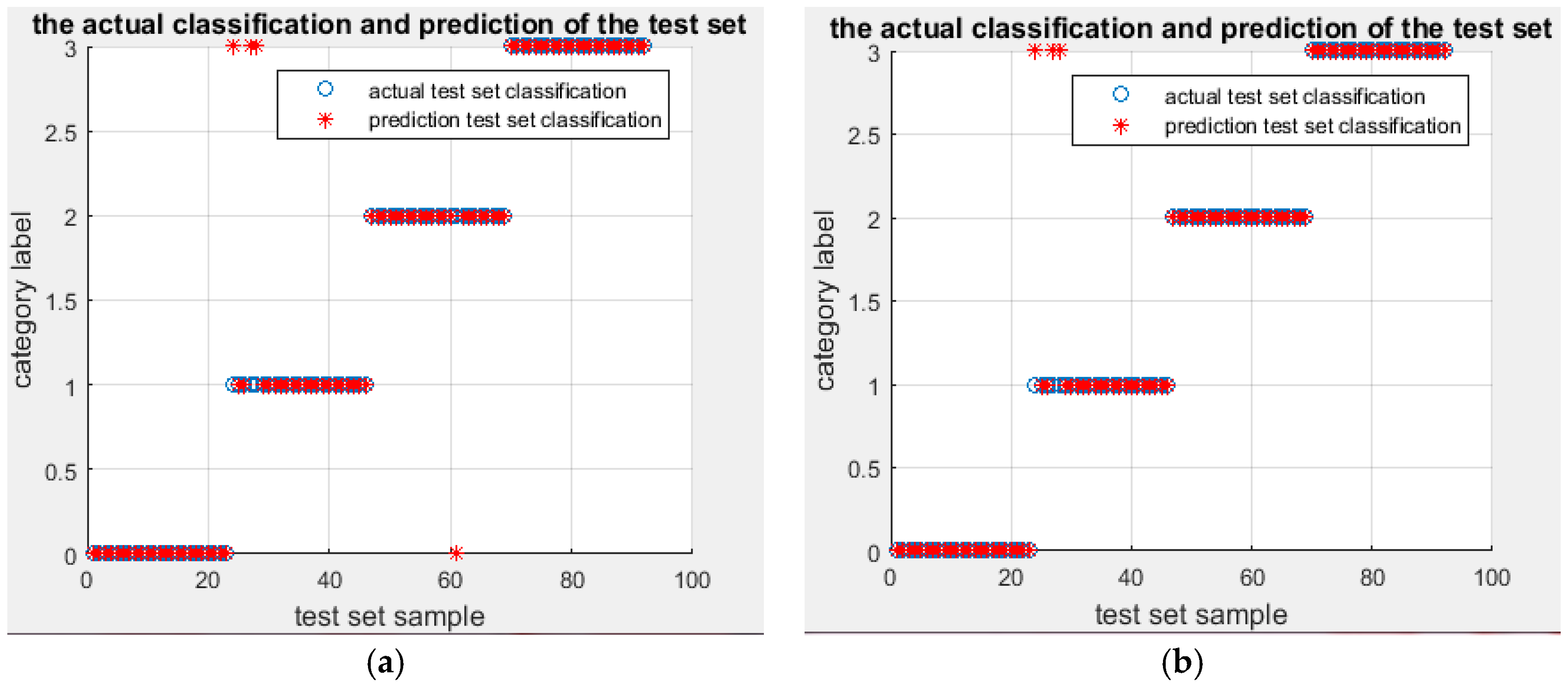
. The classification results of DFWT using IEMD-PSO-SVM are shown in
Figure 3 and
Figure 4.
From
Figure 3 and
Figure 4, it can be seen that the testing accuracy of the SVM optimized by PSO is 95.5556%, and the optimal parameters are:
and
. Only one sample is misclassified. The training accuracy at this time reaches 100% and the testing accuracy at this time also reaches 98.913%, with the correct rate of fault classification being very high. In order to illustrate the superiority of the proposed algorithm, the same energy entropy of the same vibration signals are classified by GridSearch-SVM (the parameters of SVM are optimized by GridSearch) and genetic algorithm (GA)-SVM (the parameters of SVM are optimized by Genetic Algorithm), and the recognition results are shown in
Figure 5.
It can be seen that four samples are misclassified by the IEMD-GA-SVM model, while three samples are misclassified by IEMD-GridSearch-SVM. The testing accuracies are, respectively, 95.6522% and 96.7391%.
In a similar way, the energy entropy calculated after the same vibration signals being decomposed by EMD can be put into the PSO-SVM, GridSearch-SVM and GA-SVM, and the classification results are shown in
Figure 6 and
Table 9.
It can be seen that the promotion ability of EMD-GA-SVM, EMD-GridSearch-SVM and EMD-PSO-SVM was not high. Furthermore, the corresponding recognition accuracy decomposed by EMD was much lower than that by IEMD. The promotion ability of IEMD-GA-SVM and IEMD-GridSearch-SVM was less than that of IEMD-PSO-SVM. Thus, on the whole, the IEMD-PSO-SVM algorithm is better in diagnostic performance.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}