With the development of science and technology, people have access to increasing numbers of channels from which to obtain information. The diversity of the channels has produced a large number of incomplete information sources—that is, a multi-source incomplete information system. Investigating some special properties of this system and fusing the information are the focus of the information technology field. In this section, we present a new fusion method for multi-source incomplete information systems and compare our fusion method with the mean value fusion method in a small experiment.
3.3. Multi-Source Incomplete Information Fusion
Because the information box in each table is not complete, we propose a new fusion method.
Definition 3. Let I be an incomplete information system and . , , we define the distance between any two objects in U with attribute a as follows. Definition 4. Given an incomplete information system , for any attribute , let denote the binary tolerance relation between objects that are possibly indiscernible in terms of a. is defined aswhere indicates the threshold associated with attribute a. The tolerance class of object x with reference to attribute a is denoted by . Definition 5. Given an incomplete information system , for any attribute subset , let denote the binary tolerance relation between objects that are possibly indiscernible in terms of B. is defined as The tolerance class of object x with respect to an attribute set B is denoted by .
In the literature [
39], Dai et al. proposed a new conditional entropy to evaluate the uncertainty in an incomplete decision system. Given an incomplete decision system
,
.
is a set of attributes, and
. The conditional entropy of
D with respect to
B is defined as
Because the conditional entropy is monotonous and because the attribute set B increases in importance as the conditional entropy decreases, we have the following definitions:
Definition 6. Let be s incomplete information systems and . , . The uncertainty of the information sources in D with respect to for attribute a is defined aswhere is the tolerance class of the information sources in D with respect to for attribute a. Because the conditional entropy of Dai [
39] is monotonous,
for attribute
a is also monotonous, and for attribute
a, the smaller the conditional entropy is, the more important the information source is. We have the following Definition 7:
Definition 7. Let be s incomplete information system. We define the incomplete information system, which is the most important for attribute a, as follows:where represents the information source, which is the most important for attribute a. Example 1. Let us consider a real medical examination issue at a hospital. When diagnosing leukemia, there are 10 patients, , to be considered. They undergo medical examinations at four hospitals, which test 6 indicators, , where – are, respectively, the “hemoglobin count,” “leukocyte count,” “blood fat,” “blood sugar,” “platelet count,” and “ level”. Table 1, Table 2, Table 3 and Table 4 are incomplete evaluation tables based on the medical examinations performed at the four hospitals; the symbol “∗” means that an expert cannot determine the level of a project. Suppose and , where , . Then, the conditional entropy of the information sources of D with respect to for attribute is as follows:
Because the conditional entropy can be used to evaluate the importance of information sources for attribute
a, we can determine the importance of all attributes for all information sources by using Definition 7 and
Table 5. The smaller the conditional entropy is, the more important the information sources are for attribute
a. Therefore,
is the most important for
and
,
is the most important for
and
, and
is the most important for
and
.
is not the most important for any attribute. A new information system,
is established by part of each table. Furthermore, we take
for the value of a property for
and
,
for the property’s value for
and
, and
for the property’s value for
and
. That is,
, where
represents the range of attribute
under
, and we obtain the new information system
after fusion. The new information system,
, after fusion is shown in
Table 6.
The fusion process is shown in
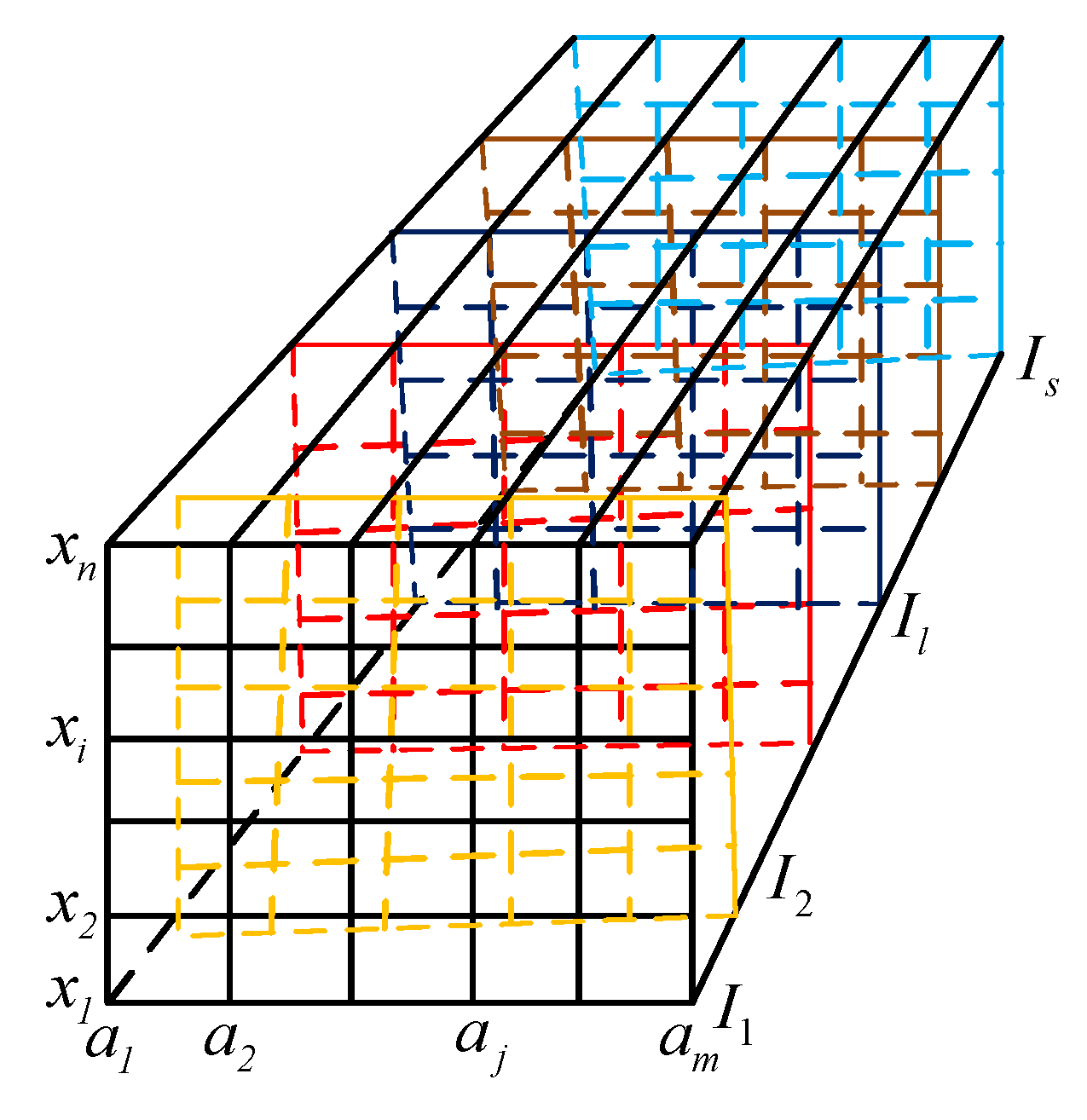
Figure 2. Suppose that there is a multi-source information system
that contains
s information systems and that there are
n objects and
m attributes in each information system
. We calculate the conditional entropy of each attribute by using Definition 6. Then, we determine the minimum of the conditional entropy for each attribute of the values using Definition 7. For example, we use different colors of rough lines to express the corresponding attributes to select a source. Then, the selected attribute values are integrated into a new information system.
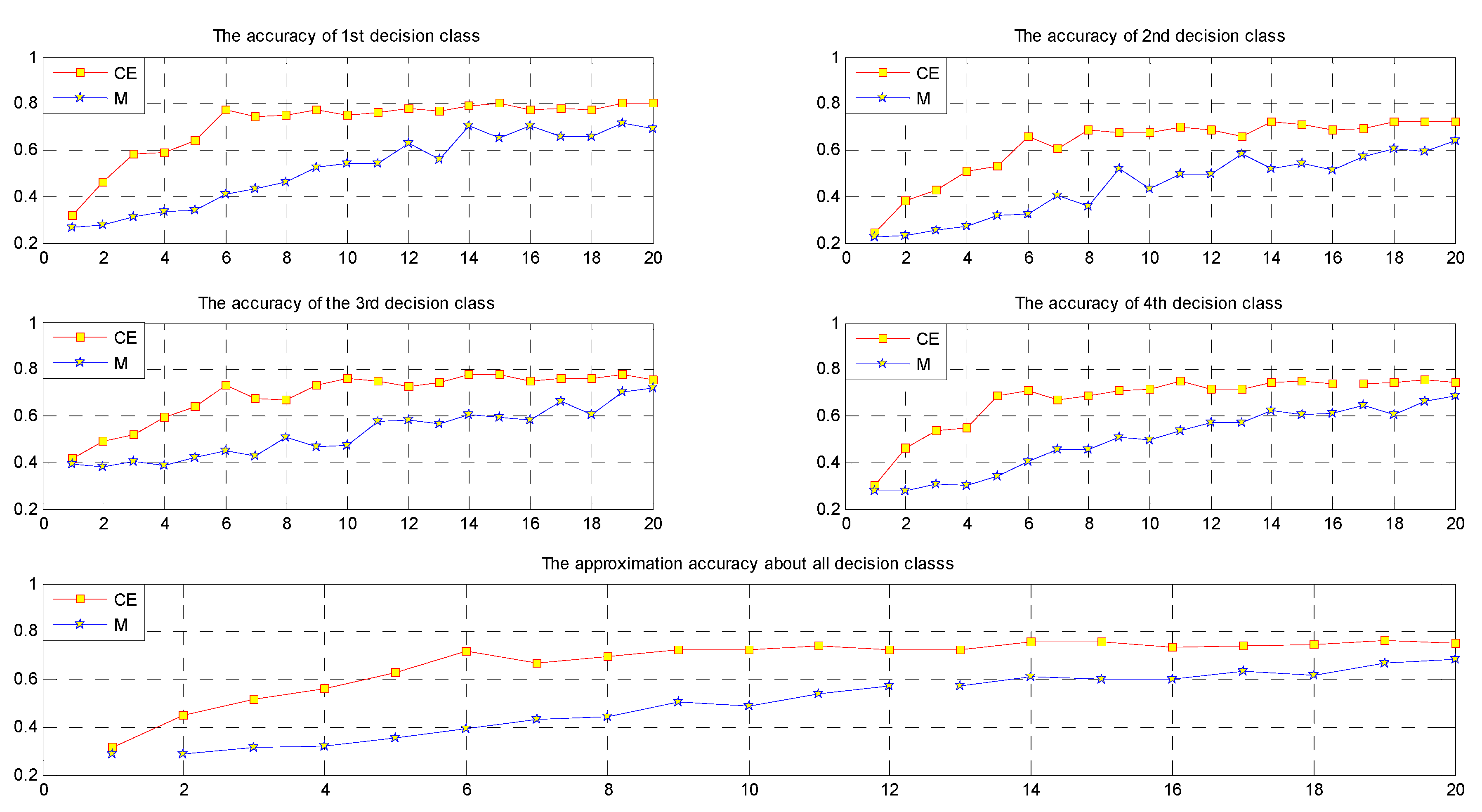
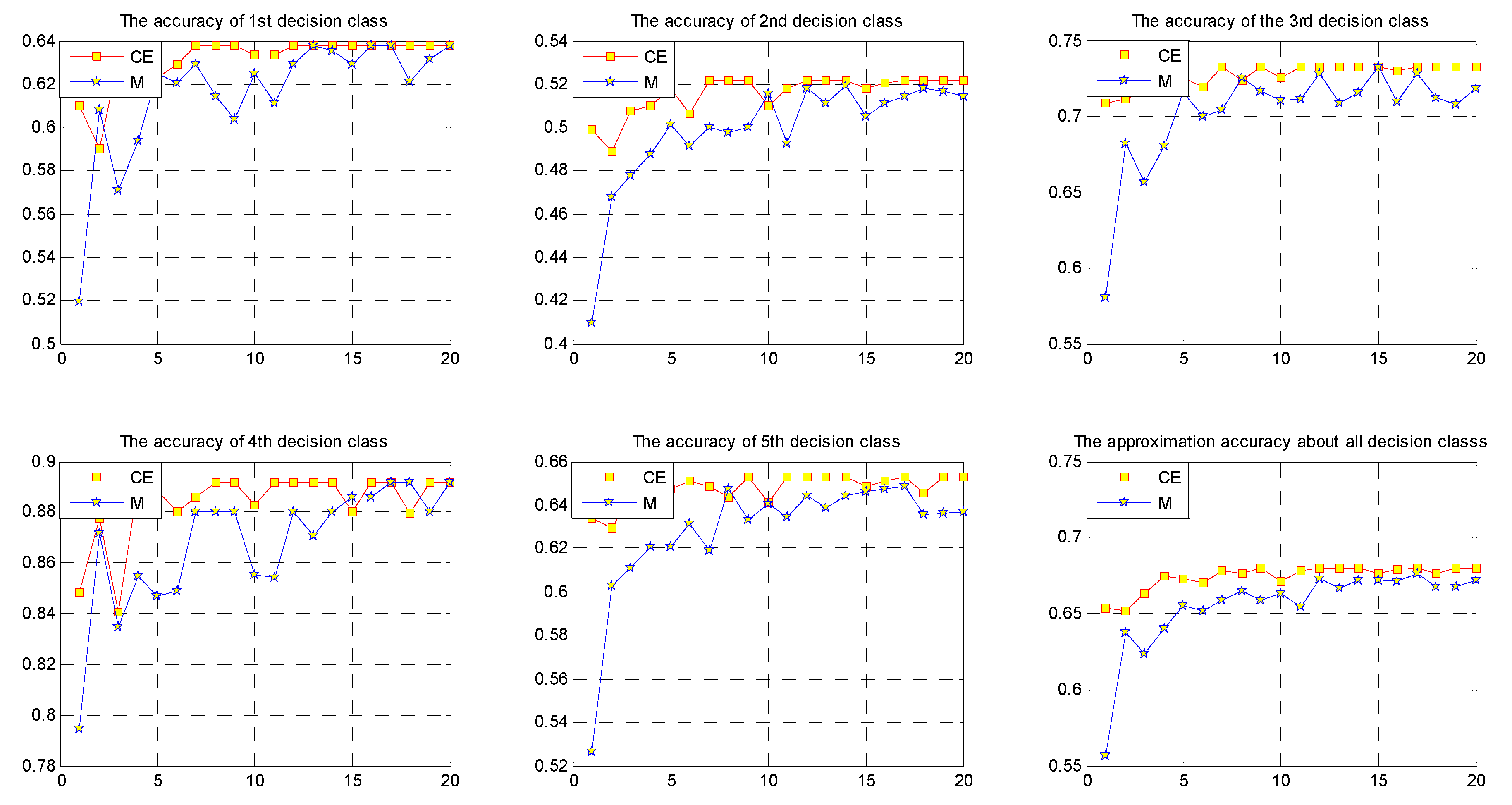
In practical applications, the mean value fusion method is one of the common fusion methods. We compare this type of method with conditional entropy fusion based on approximation accuracy. The results of two types of fusion method are presented in
Table 6 and
Table 7.
Using
Table 6 and
Table 7, we compute the approximation accuracy of the results of the two fusion methods and compare their approximation accuracy. Please see
Table 8.
By comparing the approximation accuracies, we see that multi-source fusion is better than mean value fusion. Therefore, we design a multi-source fusion algorithm (Algorithm 1) and analyze its computational complexity.
The given algorithm (Algorithm 1) is a new approach to multi-source information fusion. Its approximation accuracy is better than that of mean value fusion in the result of example
Section 3.3. First, we can calculate all the similarity classes
for any
for attribute
a. Then, the conditional entropy,
, is computed for information source
q and attribute
a. Finally, the minimum of the conditional entropy of the information source is selected for attribute
a, and the results are spliced into a new table. The computational complexity of Algorithm 1 is shown in
Table 9.
| Algorithm 1: An algorithm for multi-source fusion. |
![Entropy 19 00570 i001]() |
In steps 4 and 5 of Algorithm 1, we compute all for any for attribute a. Steps 6–14 calculate the conditional entropy for information source q and attribute a. Steps 17–26 are to find the minimum of the conditional entropy of the corresponding source for any . Finally, the results are returned.











{kind=link}
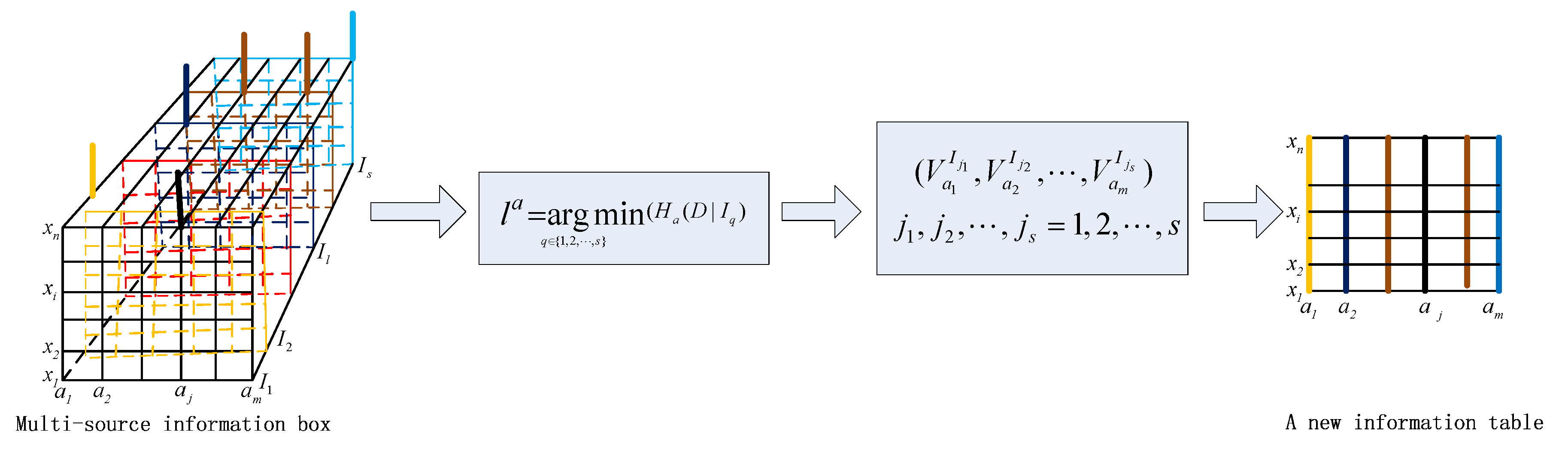{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}