1. Introduction
Semiparametric models, such as the partially linear model (PLM) and generalized PLM, play an important role in statistics, biostatistics, economics and engineering studies [
1,
2,
3,
4,
5]. For the response variable
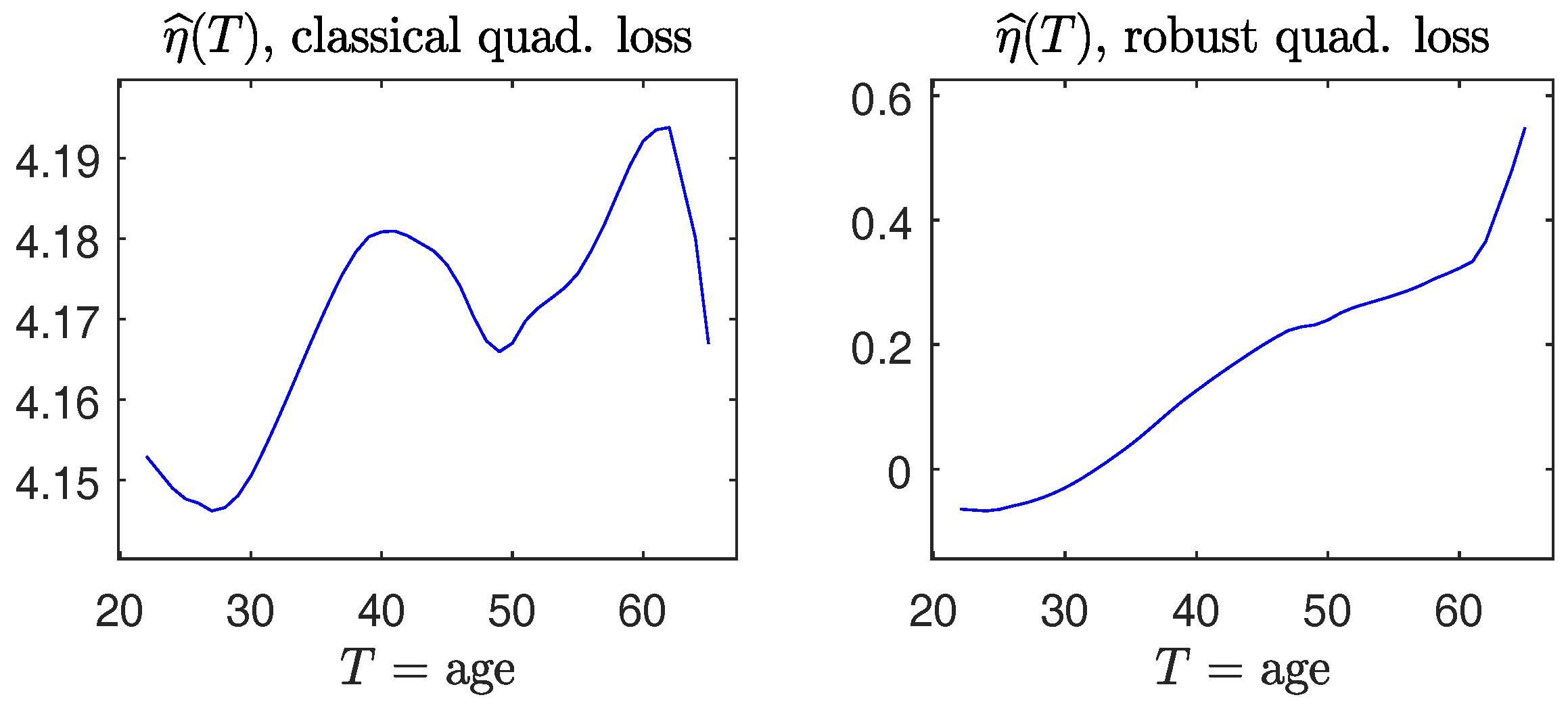
Y and covariates
, where
and
, the PLM, which is widely used for continuous responses
Y, describes the model structure according to:
where
is a vector of unknown parameters and
is an unknown smooth function; the generalized PLM, which is more suited to discrete responses
Y and extends the generalized linear model [
6], assumes:
where
F is a known link function. Typically, the parametric component
is of primary interest, while the nonparametric component
serves as a nuisance function. For illustration clarity, this paper focuses on
. An important application of PLM to brain fMRI data was given in [
7] for detecting activated brain voxels in response to external stimuli. There,
corresponds to the part of hemodynamic response values, which is the object of primary interest to neuroscientists;
is the slowly drifting baseline of time. Determining whether a voxel is activated or not can be formulated as testing for the linear form of hypotheses,
where
is a given
full row rank matrix and
is a known
vector.
Estimation of the parametric and nonparametric components of PLM and generalized PLM has received much attention in the literature. On the other hand, the existing work has some limitations: (i) The generalized PLM assumes that
follows the distribution in (3), so that the likelihood function is fully available. From the practical viewpoint, results from the generalized PLM are not applicable to situations where the distribution of
either departs from (3) or is incompletely known. (ii) Some commonly-used error measures, such as the quadratic loss in PLM for Gaussian-type responses (see for example [
7,
8]) and the (negative) likelihood function used in the generalized PLM, are not resistant to outliers. The work in [
9] studied robust inference based on the kernel regression method for the generalized PLM with a canonical link, based on either the (negative) likelihood or (negative) quasi-likelihood as the error measure, and illustrated numerical examples with the dimension
. However, the quasi-likelihood is not suitable for the exponential loss function (defined in
Section 2.1), commonly used in machine learning and data mining. (iii) The work in [
8] developed the inference of (
4) for PLM, via the classical quadratic loss as the error measure, and demonstrated that the asymptotic distributions of the likelihood ratio-type statistic and Wald statistic under the null of (
4) are both
. It remains unknown whether this conclusion holds when the tests are constructed based on robust estimators.
Without completely specifying the distribution of
, we assume:
with a known functional form of
. We refer to a model specified by (
2) and (
5) as the “general partially linear model” (GPLM). This paper aims to develop robust estimation of GPLM and robust inference of
, allowing the distribution of
to be partially specified. To introduce robust estimation, we adopt a broader class of robust error measures, called “robust-Bregman divergence (BD)” developed in [
10], for a GLM, in which BD includes the quadratic loss, the (negative) quasi-likelihood, the exponential loss and many other commonly-used error measures as special cases. We propose the “robust-BD estimators” for both the parametric and nonparametric components of the GPLM. Distinct from the explicit-form estimators for PLM using the classical quadratic loss (see [
8]), the “robust-BD estimators” for GPLM do not have closed-form expressions, which makes the theoretical derivation challenging. Moreover, the robust-BD estimators, as numerical solutions to non-linear optimization problems, pose key implementation challenges. Our major contributions are given below.
The robust fitting of the nonparametric component
is formulated using the local-polynomial regression technique [
11]. See
Section 2.3.
We develop a coordinate descent algorithm for the robust-BD estimator of
, which is computationally efficient particularly when the dimension
d is large. See
Section 3.
Theorems 1 and 2 demonstrate that under the GPLM, the consistency and asymptotic normality of the proposed robust-BD estimator for
are achieved. See
Section 4.
For robust inference of
, we propose a robust version of the Wald-type test statistic
, based on the robust-BD estimators, and justify its validity in Theorems 3–5. It is shown to be asymptotically
(central) under the null, thus distribution free, and
(noncentral) under the contiguous alternatives. Hence, this result, when applied to the exponential loss, as well as other loss functions in the wider class of BD, is practically feasible. See
Section 5.1.
For robust inference of
, we re-examine the likelihood ratio-type test statistic
, constructed by replacing the negative log-likelihood with the robust-BD. Our Theorem 6 reveals that the asymptotic null distribution of
is generally not
, but a linear combination of independent
variables, with weights relying on unknown quantities. Even in the particular case of using the classical-BD, the limit distribution is not invariant with re-scaling the generating function of the BD. Moreover, the limit null distribution of
(in either the non-robust or robust version) using the exponential loss, which does not belong to the (negative) quasi-likelihood, but falls in BD, is always a weighted
, thus limiting its use in practical applications. See
Section 5.2.
Simulation studies in
Section 6 demonstrate that the proposed class of robust-BD estimators and robust Wald-type test either compare well with or perform better than the classical non-robust counterparts: the former is less sensitive to outliers than the latter, and both perform comparably well for non-contaminated cases.
Section 7 illustrates some real data applications.
Section 8 ends the paper with brief discussions. Details of technical derivations are relegated to
Appendix A.
3. Two-Step Iterative Algorithm for Robust-BD Estimation
In a special case of using the classical quadratic loss combined with an identity link function, the robust-BD estimators for parametric and nonparametric components have explicit expressions,
where
,
,
, with
being an identity matrix,
,
the design matrix,
and:
When
, (
24) reduces to the “profile least-squares estimators” of [
8].
In other cases, robust-BD estimators from (
17) and (
23) do not have closed-form expressions and need to be solved numerically, which are computationally challenging and intensive. We now discuss a two-step robust proposal for iteratively estimating
and
. Let
and
denote the estimates in the
-th iteration, where
. The
k-th iteration consists of two steps below.
Step 1: Instead of solving (
23) directly, we propose to solve a surrogate optimization problem,
. This minimizer approximates
.
Step 2: Obtain
,
, where
is defined in (
17).
The algorithm terminates provided that is below some pre-specified threshold value, and all stabilize.
3.1. Step 1
For the above two-step algorithm, we first elaborate on the procedure of acquiring
in Step 1, by extending the coordinate descent (CD) iterative algorithm [
17] designed for penalized estimation to our current robust-BD estimation, which is computationally efficient. For any given value of
, by Taylor expansion, around some initial estimate
(for example,
), we obtain the weighted quadratic approximation,
where
is a constant not depending on
,
with
defined in (
10). Hence,
Thus it suffices to conduct minimization of
with respect to
, using a coordinate descent (CD) updating procedure. Suppose that the current estimate is
, with the current residual vector
, where
is the vector of pseudo responses. Adopting the Newton–Raphson algorithm, the estimate of the
j-th coordinate based on the previous estimate
is updated to:
As a result, the residuals due to such an update are updated to:
Cycling through , we obtain the estimate . Now, we set and . Iterate the process of weighted quadratic approximation followed by the CD updating, for a number of times, until the estimate stabilizes to the solution .
The validity of
in Step 1 converging to the true parameter
is justified as follows. (i) Standard results for
M-estimation [
16] indicate that the minimizer of
is consistent with
. (ii) According to our Theorem 1 (ii) in
Section 4.1,
for a compact set
, where
stands for convergence in probability. Using derivations similar to those of (A4) gives
for any compact set
. Thus, minimizing
is asymptotically equivalent to minimizing
. (iii) Similarly, provided that
is close to
, minimizing
is asymptotically equivalent to minimizing
. Assembling these three results with the definition of
yields:
3.2. Step 2
In Step 2, obtaining
for any given values of
and
t is equivalent to minimizing
in (
16). Notice that the dimension
of
is typically low, with degrees
or
being the most commonly used in practice. Hence, the minimizer of
can be obtained by directly applying the Newton–Raphson iteration: for
,
where
denotes the estimate in the
k-th iteration, and:
The iterations terminate until the estimate stabilizes.
Our numerical studies of the robust-BD estimation indicate that (i) the kernel regression method can be both faster and stabler than the local-linear method; (ii) to estimate the nonparametric component , the local-linear method outperforms the kernel method, especially at the edges of points ; (iii) for the performance of the robust estimation of , which is of major interest, there is a relatively negligible difference between choices of using the kernel and local-linear methods in estimating nonparametric components.
4. Asymptotic Property of the Robust-BD Estimators
This section investigates the asymptotic behavior of robust-BD estimators and , under regularity conditions. The consistency of to and uniform consistency of to are given in Theorem 1; the asymptotic normality of is obtained in Theorem 2. For the sake of exposition, the asymptotic results will be derived using local-linear estimation with degree . Analogous results can be obtained for local-polynomial methods with lengthier technical details and are omitted.
We assume that , and let be a compact set. For any continuous function , define and . For a matrix M, the smallest and largest eigenvalues are denoted by , and , respectively. Let be the matrix norm. Denote by convergence in probability and convergence in distribution.
4.1. Consistency
We first present Lemma 1, which states the uniform consistency of to the surrogate function . Theorem 1 gives the consistency of and .
Lemma 1 (For the non-parametric surrogate
)
. Let and be compact sets. Assume Condition and Condition in the Appendix. If , , , , then Theorem 1 (For and ). Assume conditions in Lemma 1.
- (i)
If there exists a compact set such that and Condition holds, then .
- (ii)
Moreover, if Condition holds, then .
4.2. Asymptotic Normality
The asymptotic normality of is provided in Theorem 2.
Theorem 2 (For the parametric part
βo)
. Assume Conditions A and Condition B in the Appendix. If , and , then:where:and:with: From Condition
, (
13) and (
14), we can show that if
for some constant
, then
. In that case,
, where:
Consider the conventional PLM in (
1), estimated using the classical quadratic loss, identity link and
. If
, then
, and thus, the result of Theorem 2 agrees with that in [
18].
Remark 2. Theorem 2 implies the root-n convergence rate of . This differs from , which converges at some rate incorporating both the sample size n and the bandwidth h, as seen in the proofs of Lemma 1 and Theorem 2.
5. Robust Inference for Based on BD
In many statistical applications, we will check whether or not a subset of explanatory variables used is statistically significant. Specific examples include:
These forms of linear hypotheses for
can be more generally formulated as: (
4).
5.1. Wald-Type Test
We propose a robust version of the Wald-type test statistic,
based on the robust-BD estimator
proposed in
Section 2.4, where
and
are estimates of
and
satisfying
. For example,
and:
fulfill the requirement, where:
Again, we can verify that if
for some constant
and
is obtained from kernel estimation method, then
, and hence,
, where:
Theorem 3 justifies that under the null, would for large n be distributed as , thus asymptotically distribution-free.
Theorem 3 (Wald-type test based on robust-BD under
H0)
. Assume conditions in Theorem 2,
and in (
28).
Then, under in (
4),
we have that: Theorem 4 indicates that
has a non-trivial local power detecting contiguous alternatives approaching the null at the rate
:
where
.
Theorem 4 (Wald-type test based on robust-BD under
H1n)
. Assume conditions in Theorem 2,
and in (
28).
Then, under in (
29),
,
where . To appreciate the discriminating power of in assessing the significance, the asymptotic power is analyzed. Theorem 5 manifests that under the fixed alternative , at the rate n. Thus, has the power approaching to one against fixed alternatives.
Theorem 5 (Wald-type test based on robust-BD under
H1)
. Assume conditions in Theorem 2,
and in (
28).
Then, under in (
4),
. For the conventional PLM in (
1) estimated using the non-robust quadratic loss, [
8] showed the asymptotic equivalence between the Wald-type test and likelihood ratio-type test. Our results in the next
Section 5.2 reveal that such equivalence is violated when estimators are obtained using the robust loss functions.
5.2. Likelihood Ratio-Type Test
This section explores the degree to which the likelihood ratio-type test is extended to the “robust-BD” for testing the null hypothesis in (
4) for the GPLM. The robust-BD test statistic is:
where
is the robust-BD estimator for
developed in
Section 2.4.
Theorem 6 indicates that the limit distribution of under is a linear combination of independent chi-squared variables, with weights relying on some unknown quantities, thus not distribution free.
Theorem 6 (Likelihood ratio-type test based on robust-BD under H0). Assume conditions in Theorem 2.
- (i)
Under in (
4),
we obtain:where and . - (ii)
Moreover, if , , and the generating q-function of BD satisfies:then under in (
4),
we have that .
Theorem 7 states that has non-trivial local power for identifying contiguous alternatives approaching the null at rate and that at the rate n under , thus having the power approaching to one against fixed alternatives.
Theorem 7 (Likelihood ratio-type test based on robust-BD under H1n and H1). Assume conditions in Theorem 2. Let and , .
- (i)
Under in (
29),
, where , and S is a matrix satisfying and . - (ii)
Under in (
4),
for a constant .
5.3. Comparison between and
In summary, the test
has some advantages over the test
. First, the asymptotic null distribution of
is distribution-free, whereas the asymptotic null distribution of
in general depends on unknown quantities. Second,
is invariant with re-scaling the generating
q-function of the BD, but
is not. Third, the computational expense of
is much more reduced than that of
, partly because the integration operations for
are involved in
, but not in
, and partly because
requires both unrestricted and restricted parameter estimates, while
is useful in cases where restricted parameter estimates are difficult to compute. Thus,
will be focused on in numerical studies of
Section 6.
6. Simulation Study
We conduct simulation evaluations of the performance of robust-BD estimation methods for general partially linear models. We use the Huber -function with . The weight functions are chosen to be , where , and denote the sample median and sample median absolute deviation of respectively, . As a comparison, the classical non-robust estimation counterparts correspond to using and . Throughout the numerical work, the Epanechnikov kernel function is used. All these choices (among many others) are for feasibility; the issues on the trade-off between robustness and efficiency are not pursued further in the paper.
The following setup is used in the simulation studies. The sample size is , and the number of replications is 500. (Incorporating a nonparametric component in the GPLM desires a larger n when the number of covariates increases for better numerical performance.) Local-linear robust-BD estimation is illustrated with the bandwidth parameter h to be of the interval length of the variable T. Results using other data-driven choices of h are similar and are omitted.
6.1. Bernoulli Responses
We generate observations
randomly from the model,
where
with
, and
is independent of
T. The link function is
, where
and
. Both the deviance and exponential loss functions are employed as the BD.
For each generated dataset from the true model, we create a contaminated dataset, where 10 data points
are contaminated as follows: they are replaced by
, where
,
,
with
.
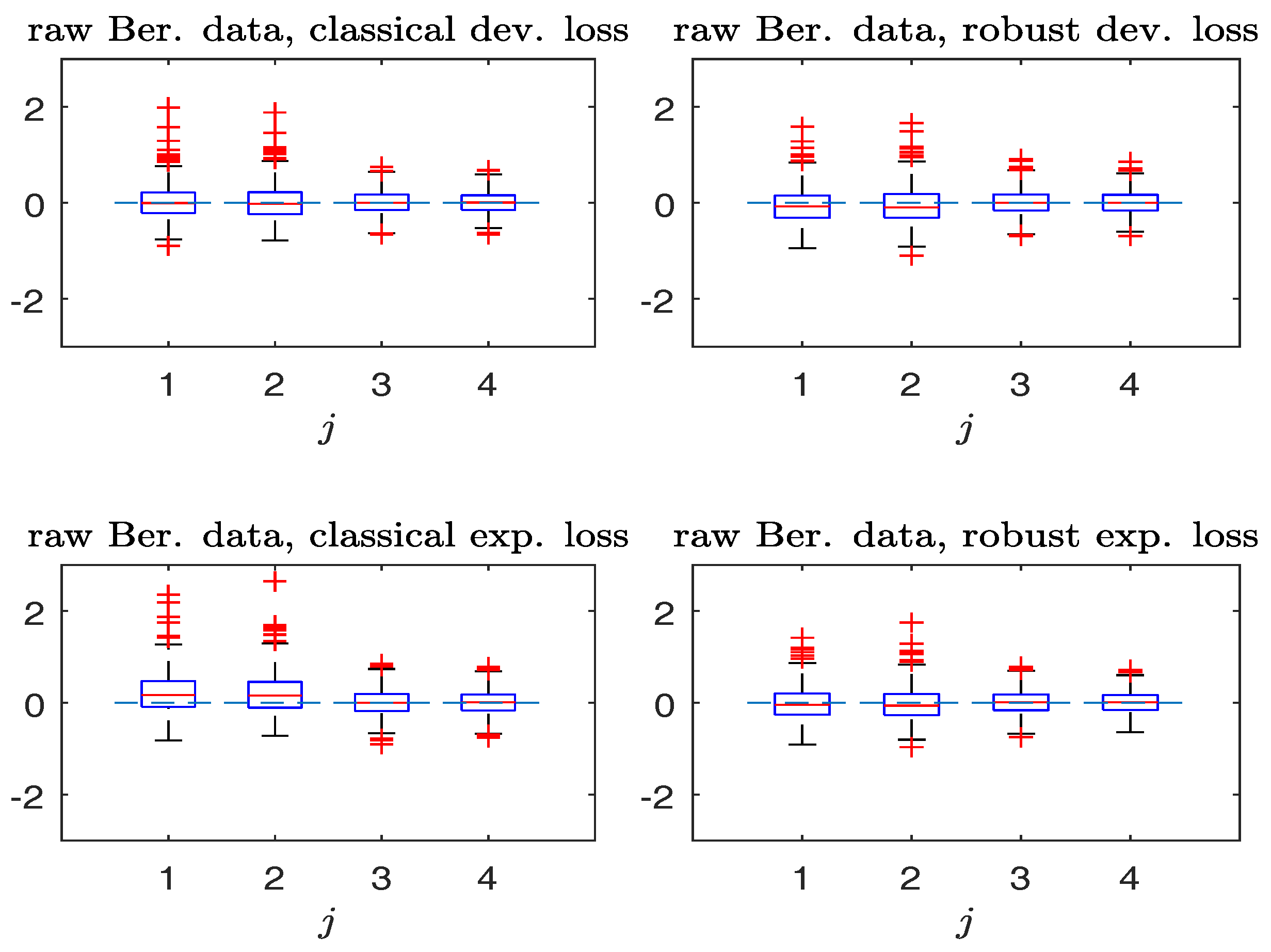
Figure 1 and
Figure 2 compare the boxplots of
,
, based on the non-robust and robust-BD estimates, where the deviance loss and exponential loss are used as the BD in the top and bottom panels respectively. As seen from
Figure 1 in the absence of contamination, both non-robust and robust methods perform comparably well. Besides, the bias in non-robust methods using the exponential loss (with
unbounded) is larger than that of the deviance loss (with
bounded). In the presence of contamination,
Figure 2 reveals that the robust method is more effective in decreasing the estimation bias without excessively increasing the estimation variance.
For each replication, we calculate
.
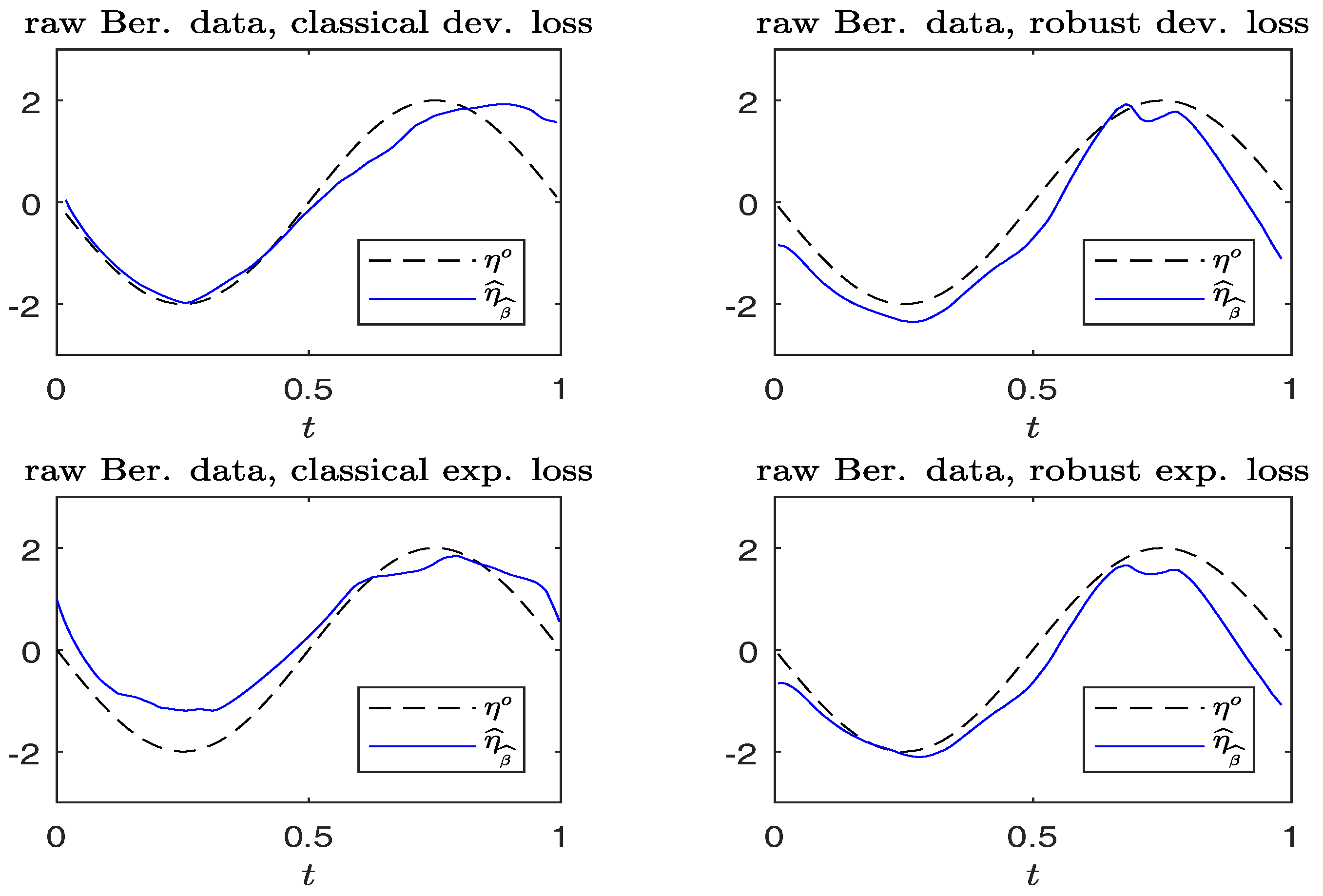
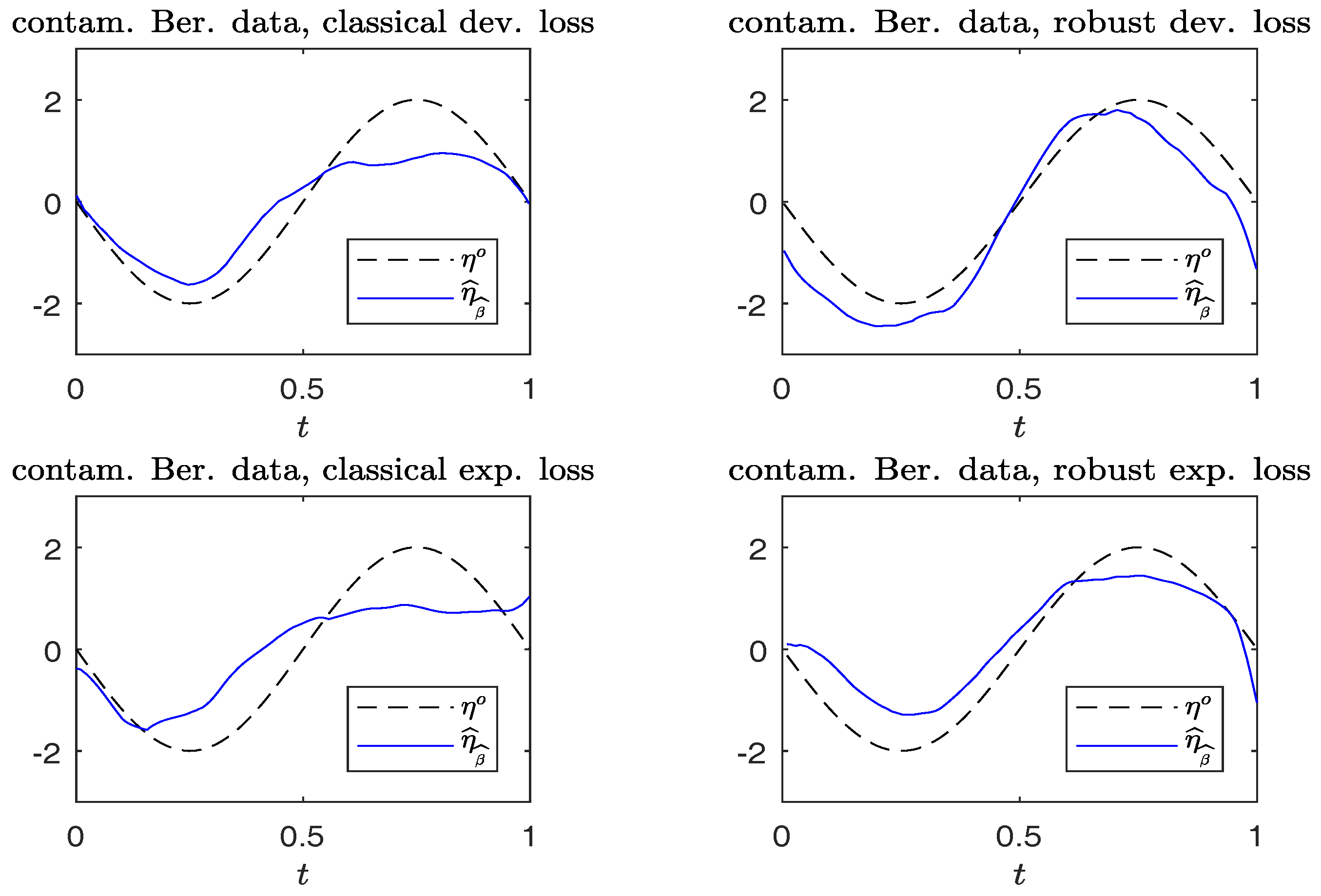
Figure 3 and
Figure 4 compare the plots of
from typical samples, using non-robust and robust-BD estimates, where the deviance loss and exponential loss are used as the BD in the top and bottom panels, respectively. There, the typical sample in each panel is selected in a way such that its MSE value corresponds to the 50-th percentile among the MSE-ranked values from 500 replications. These fitted curves reveal little difference between using the robust and non-robust methods, in the absence of contamination. For contaminated cases, robust estimates perform slightly better than non-robust estimates. Moreover, the boundary bias issue arising from the curve estimates at the edges using the local constant method can be ameliorated by using the local-linear method.
6.2. Gaussian Responses
We generate independent observations
from
satisfying:
where
,
with
,
denotes the CDF of the standard normal distribution. The link function is
, where
and
. The quadratic loss is utilized as the BD.
For each dataset simulated from the true model, a contaminated data-set is created, where 10 data points
are subject to contamination. They are replaced by
, where
,
,
with
.
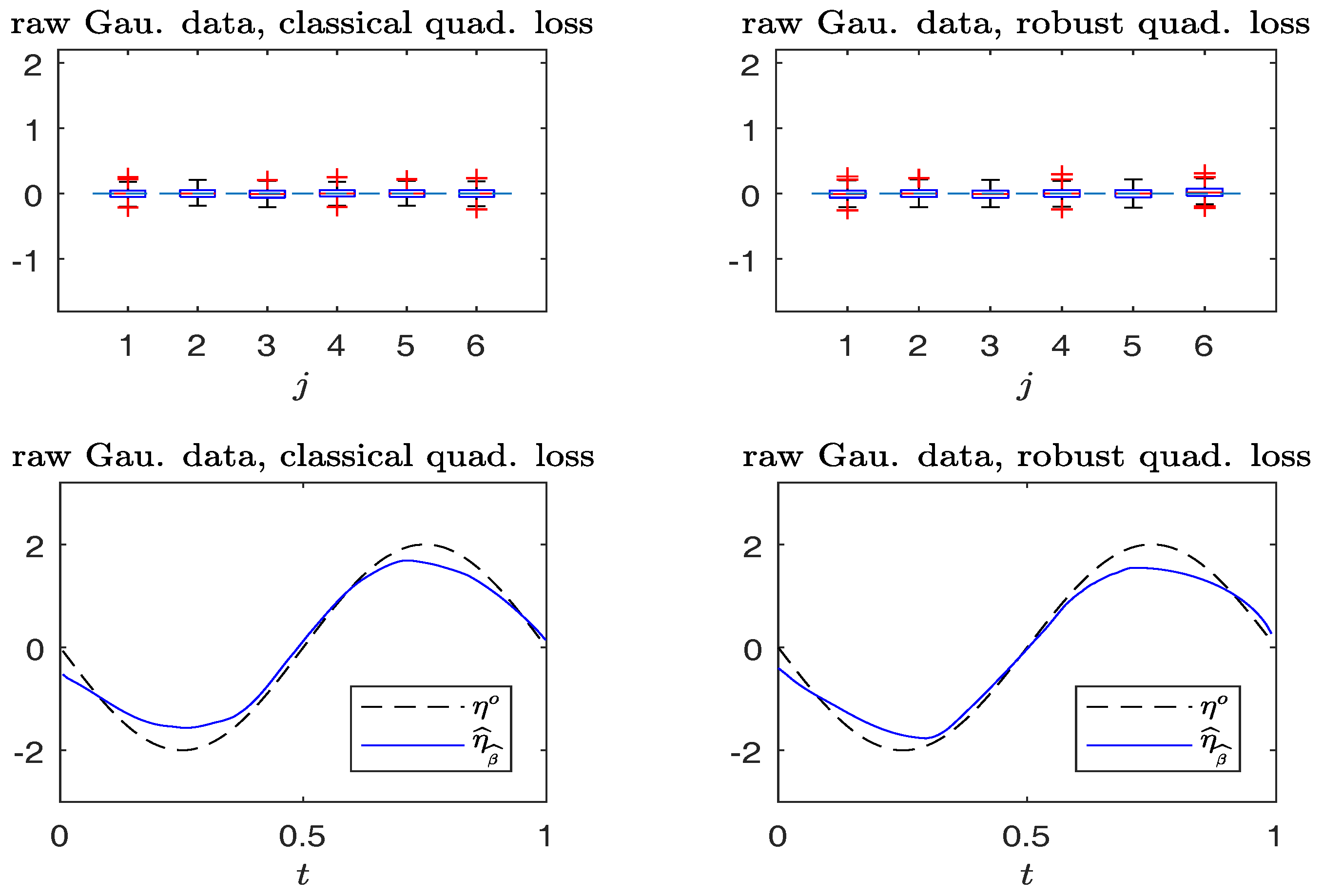
Figure 5 and
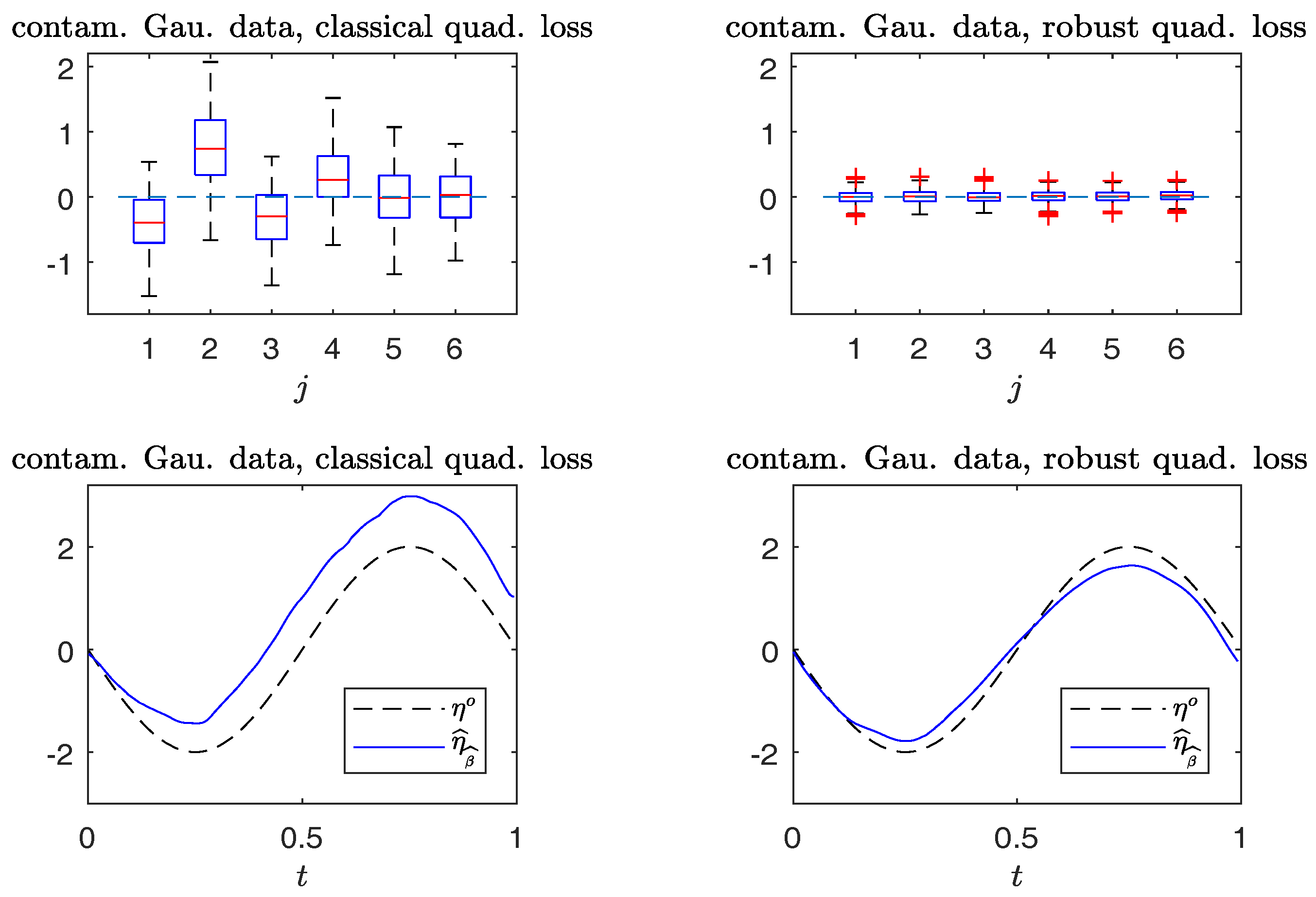
Figure 6 compare the boxplots of
,
, on the top panels, and plots of
from typical samples, on the bottom panels, using the non-robust and robust-BD estimates. The typical samples are selected similar to those in
Section 6.1. The simulation results in
Figure 5 indicate that the robust method performs, as well as the non-robust method for estimating both the parameter vector and non-parametric curve in non-contaminated cases.
Figure 6 reveals that the robust estimates are less sensitive to outliers than the non-robust counterparts. Indeed, the non-robust method yields a conceivable bias for parametric estimation, and non-parametric estimation is worse than that of the robust method.
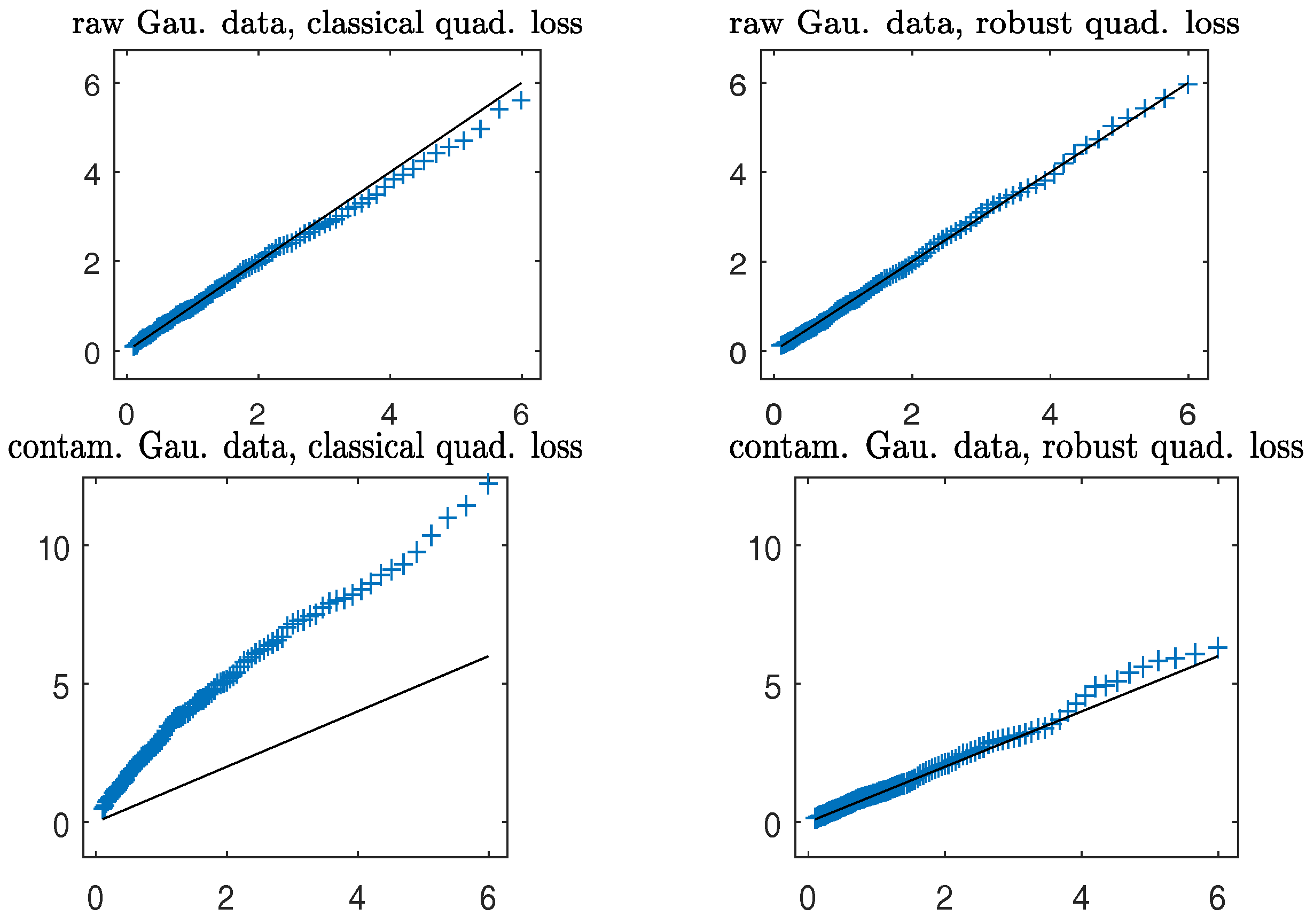
Figure 7 gives the QQ plots of the (first to 95-th) percentiles of the Wald-type statistic
versus those of the
distribution for testing the null hypothesis:
The plots depict that in both clean and contaminated cases, the robust (in right panels) closely follows the distribution, lending support to Theorem 3. On the other hand, the non-robust agrees well with the distribution in clean data; the presence of a small number of outlying data points severely distorts the sampling distribution of the non-robust (in the bottom left panel) from the distribution, yielding inaccurate levels of the test.
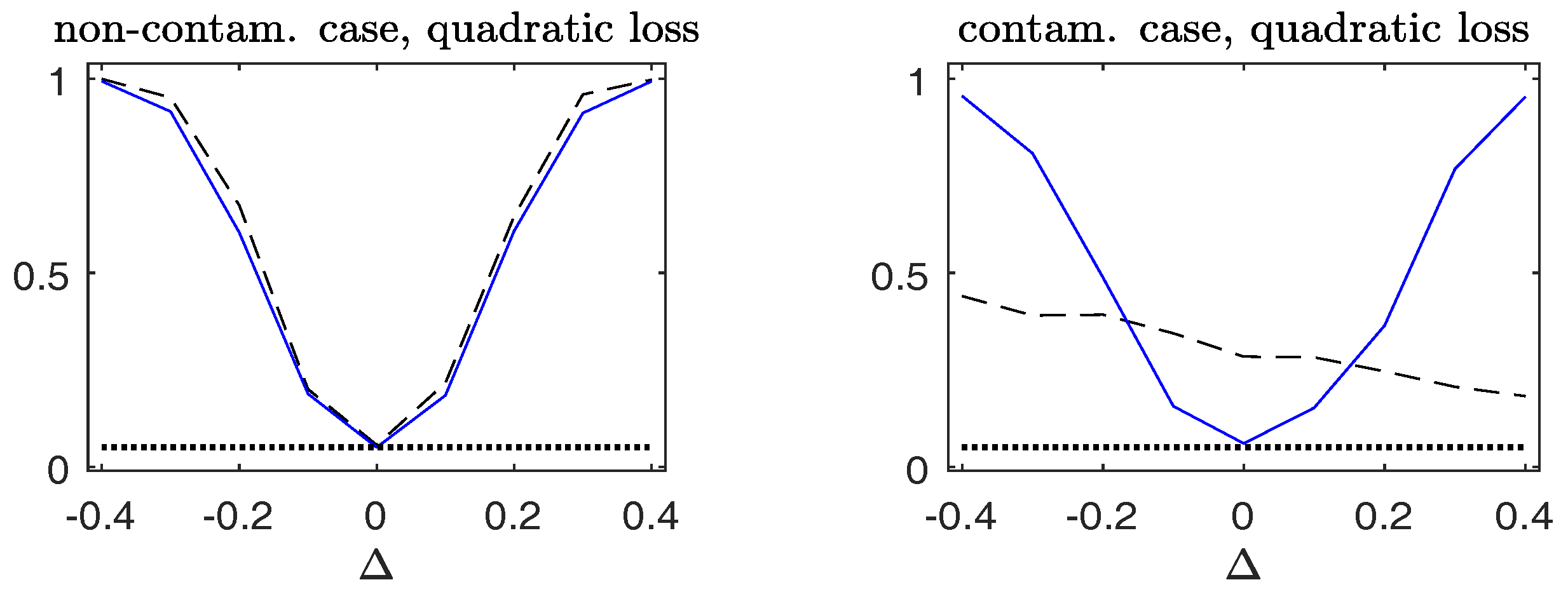
To assess the stability of the power of the Wald-type test for testing the hypothesis (
32), we evaluate the power in a sequence of alternatives with parameters
for each given
, where
.
Figure 8 plots the empirical rejection rates of the null model in the non-contaminated case and the contaminated case. The price to pay for the robust
is a little loss of power in the non-contaminated cases. However, under contamination, a very different behavior is observed. The observed power curve of the robust
is close to those attained in the non-contaminated case. On the contrary, the non-robust
is less informative, since its power curve is much lower than that of the robust
against the alternative hypotheses with
, but higher than the nominal level at the null hypothesis with
.
8. Discussion
Over the past two decades, nonparametric inference procedures for testing hypotheses concerning nonparametric regression functions have been developed extensively. See [
22,
23,
24,
25,
26] and the references therein. The work on the generalized likelihood ratio test [
24] offers light into nonparametric inference, based on function estimation under nonparametric models, using the quadratic loss function as the error measure. These works do not directly deal with the robust procedure. Exploring the inference on nonparametric functions, such as
in GPLM associated with a scalar variable
T and the additive structure
as in [
27] with a vector variable
, estimated via the “robust-BD” as the error measure, when there are possible outlying data points, will be the future work.
This paper utilizes the class BD of loss functions, the optimal choice of which depends on specific settings and criteria. For e.g., regression and classification will utilize different loss functions, and thus further study on optimality is desirable.
Some recent work on partially linear models in econometrics includes [
28,
29,
30]. There, the nonparametric function is approximated via linear expansions, with the number of coefficients diverging with
n. Developing inference procedures to be resistant to outliers could be of interest.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}