In this section, we propose three strategies for zero-error communication by mitigating the ambiguities resulting from the partial information about the true distribution.
3.1. Perfect Reconciliation
For the communication model described in
Section 2.1, a natural approach to tackle the partial information is by first sending the missing information to user 2 so that both sides know the source pairs that may be realized with positive probability with respect to the true distribution, which can then be utilized for communication. This setup consists of two stages. In the first stage, user 2 learns the support set of the true distribution
, or equally the bipartite graph
G corresponding to
, from user 1. We call this the reconciliation stage. After this stage, both parties use graph
G for zero-error interactive communication. We refer to this two-stage protocol as
perfect reconciliation in the sequel. The worst-case message length under this setup is referred to as
.
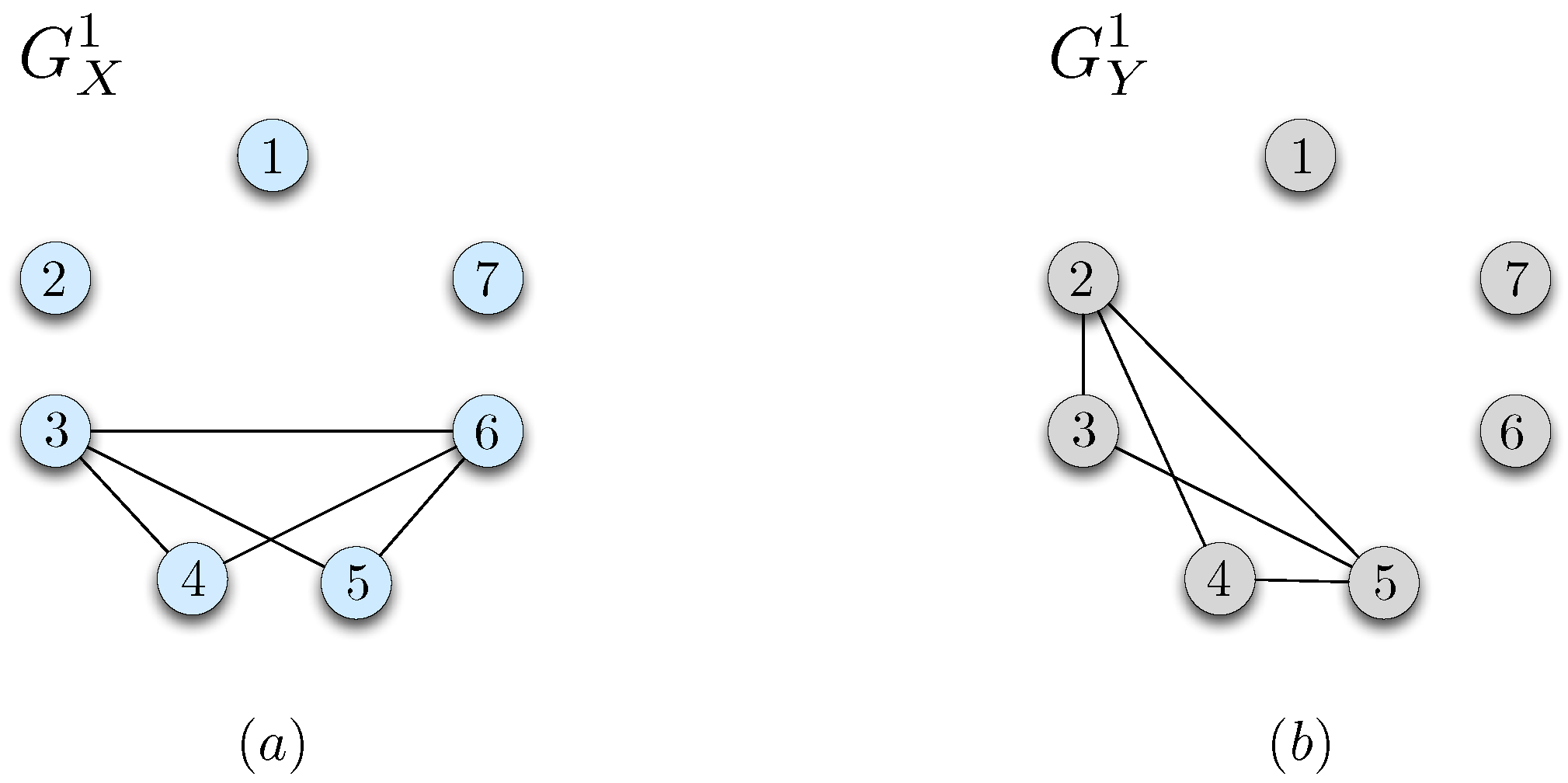
For the reconciliation stage, we first partition
into groups of distributions with distinct support sets, and denote by
the set of distinct bipartite graphs that correspond to the support sets of the distributions in
. This process is similar to the one described for
in
Section 2.1. Next, we find a lower bound for the minimum number of bits required for user 2 to learn the graph
G, i.e., all
pairs that may occur with positive probability under the true distribution
.
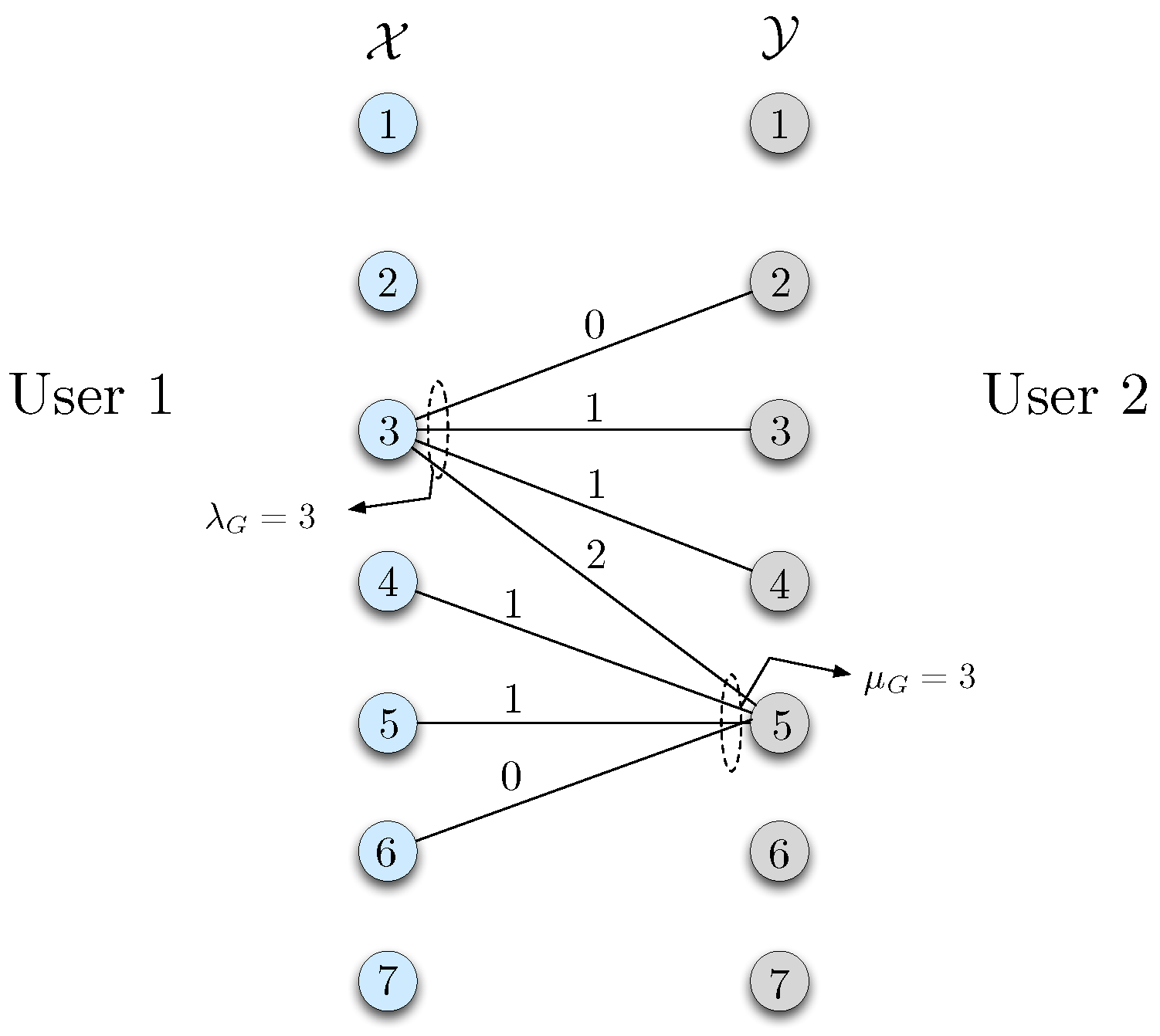
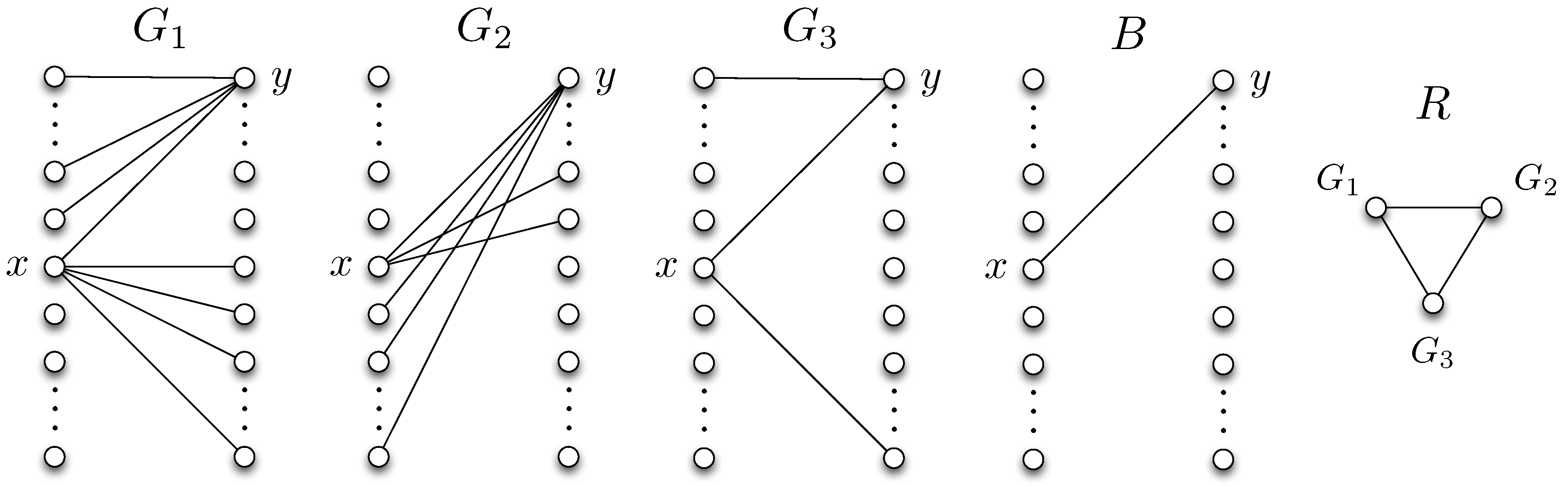
Definition 1. (Reconciliation graph) Define a characteristic graph , in which each vertex represents a graph . Recall that is a set of bipartite graphs as we define in Section 2.1. An edge is defined between vertices G and if and only if there exists a such that and . The minimum number of bits required for user 2 to perfectly learn G is then , where denotes the chromatic number of a graph. This can be observed by noting that in the reconciliation phase, any two nodes in the reconciliation graph with an edge in between has to be assigned to distinct bit streams, otherwise user 2 will not be able to distinguish them, which requires a minimum of number of bits to be transmitted from user 1 to user 2. It is useful to note that perfect reconciliation incurs a negligible cost for large blocklengths.
Proposition 2. Perfect reconciliation is an asymptotically optimal strategy.
Proof. Since the distributions and are fixed once chosen, reconciliation requires at most bits for any class of graphs . Therefore its contribution on the codeword length per symbol is , which vanishes as . Since the communication cost for not reconciling the graphs can never be lower than reconciling them, we can conclude that reconciling the graphs first, and then using the reconciled graphs for communication, cannot perform worse than not reconciling them. We note, however, that this statement may no longer hold if the joint distribution is arbitrarily varying over the course of n symbols, since correct recovery in this case may require the graphs to be repeatedly reconciled. ☐
In the following, we demonstrate a lower bound on the worst-case message length for this two-stage reconciliation-communication protocol.
Lemma 1. A lower bound on the worst-case message length for the two-stage reconciliation-communication protocol is, Proof. We prove Equation (
24) by obtaining a lower bound on the message length for the reconciliation and communication parts separately. The lower bound for the reconciliation part is determined by bounding the minimum number of bits to be transmitted from user 1 to user 2 using Definition 1. As a result, both sides learn the support set of the true distribution
. The lower bound in Equation (
24) then follows from
where Equation (
26) follows from the min-max inequality and Equation (
28) from Proposition 1. ☐
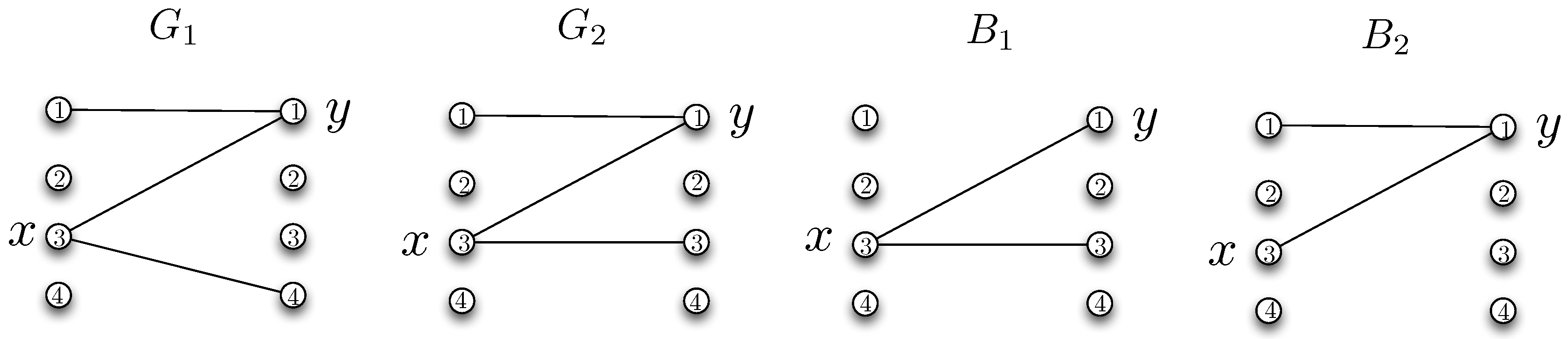
We next demonstrate an upper bound for the minimum worst-case message length. Consider the distribution and the corresponding bipartite graph . Let denote a characteristic graph for user 1 with a vertex set . Vertices of are the n-tuples . An edge exists between and whenever some exists such that , and . Similarly, define a characteristic graph for user 2 whose vertices are the n-tuples . An edge exists between and whenever some exists such that , , and .
The characteristic graphs defined above are useful in that any valid coloring over the characteristic graphs will enable the two parties to resolve the ambiguities in distinguishing the correct function values.
Figure 3 illustrates the characteristic graphs
and
, respectively, constructed by using
from Equation (
20) and
from Equation (
19) in the example discussed in
Section 2.2. In the following, we follow the notation
and
.
Theorem 1. The worst-case message length for the two-stage separate reconciliation and communication strategy satisfies Proof. Consider a minimum coloring for and using and colors. Note that and can be colored with at most and colors, respectively. Hence, users 1 and 2 can simultaneously send the index of the color assigned to their symbols by using at most and bits, respectively. Then, users can utilize the received color index and their own symbols for correct recovery of the function values. ☐
3.2. Protocols that Do Not Explicitly Start with a Reconciliation Procedure
Instead of the reconciliation-based strategy described in
Section 3.1, the two users may choose not to reconcile the distributions, but instead utilize a robust communication strategy that ensures zero-error communication under any distribution in set
. Specifically, they can agree on a worst-case communication strategy that always ensures zero-error communication for both users. In this section, we study two specific protocols that do not explicitly start with a reconciliation procedure. We denote the worst case message length in this setting as
.
As an example of such a robust communication strategy, consider a scenario in which user 1 enumerates each by using bits whereas user 2 enumerates each by using bits. Then, by using no more than bits in total, the two parties can communicate their observed symbols with zero-error under any true distribution, and evaluate . In that sense, this setup does not require any additional bits for learning about the distribution from the other side either perfectly or partially, but the message length for communicating the symbols is often higher. In the following, we derive an upper bound on the worst-case message length based on two achievable protocols that do not start with a reconciliation procedure.
The first achievable strategy we consider is based on graph coloring. Let be a characteristic graph for user 1 whose vertex set is . Define an edge between nodes and whenever there exists some such that and whereas . Similarly, define a characteristic graph for user 2 whose vertex set is . Define an edge between vertices and whenever there exists some such that and for some but . We note the difference between the conditions for constructing and in that the former is based on the union whereas the latter is based on the existence for some . This difference results from the fact that user 2 does not know the true distribution, hence needs to distinguish the possible symbols from a group of distributions, whereas user 1 has the true distribution, and can utilize it for eliminating the ambiguities for correct function recovery. We note however that both and depend on . Lastly, we let and denote the chromatic number of and , respectively.
Then, under any true distribution , the following communication protocol ensures zero error. Suppose user 1 observes and user 2 observes from some distribution . For each where , user 1 sends the color of by using no more than bits. After this step, user 2 can recover by using as follows. Given , user 2 considers the set of all such that for some . Note that within this set, each color represents a group of for which is equal. Therefore, under any true distribution , user 2 will be able to recover the correct value solely by using the received color along with . Similarly, for each , user 2 sends the color of by using no more than bits, after which user 1 recovers by using the received color and the true distribution . Since user 1 knows the true distribution, it can distinguish any function value correctly as long as no two are assigned to the same codeword for which such that and when .
We then have the following upper bound on the worst-case message length,
where user 1 sends
bits to user 2 whereas user 2 sends
bits to user 1. After this step, both users can recover the correct function values
for any source pair
under any
.
The second achievable strategy we consider is based on perfect hash functions. A function
is called a
perfect hash function for a set
if for all
such that
, one has
. Define a family of functions
such that
for all
. If
for some
, then, there exists a family of
functions such that for every
with
, there exists a function
that is injective (one-to-one) over
([
30], Section III.2.3). Perfect hash functions have been proved to be useful for constructing zero-error interactive communication protocols when the true distribution of the sources are known by both parties [
7]. In the following, we extend the interactive communication framework from [
7] to the setting when the true distribution is unknown by the communicating parties.
Initially, we construct a graph for user 2 with a vertex set . In that sense, each vertex of the graph is an n-tuple . Define an edge between vertices and if for some n-tuple that there exists some for which and for all . Define a minimum coloring of this graph and let denote the minimum number of required colors, i.e., the chromatic number of . In that sense, any valid coloring over this graph will enable user 1 to resolve the ambiguities in distinguishing the correct n-tuple observed by user 2, under any true distribution .
We next define the following ambiguity set for each
,
as the set of distinct
sequences that may occur with respect to the support set
under the given sequence
. We denote the size of the largest single-term ambiguity set as,
and note that
. Lastly, we define an ambiguity set for each
,
as the set of distinct function values that may appear for the given sequence
and with respect to the support set
. We denote the size of the largest single-term ambiguity set as
and note that
.
The interaction protocol is then given as follows. From Equation (
31), there exists a family
of
functions such that
for all
and for each
of size
, there exists an
that is injective over
. In that sense, the colors assigned to an ambiguity set
for some
will correspond to some
. Both users initially agree on such a family of functions
and a minimum coloring of graph
with
colors. Suppose user 1 observes
and user 2 observes
. User 1 finds a function
that is injective over the colors assigned to vertices
from Equation (
32) and sends its index to user 2 by using no more than
bits in total. After this step, user 2 evaluates the corresponding function for the assigned color of
and sends the evaluated value back to user 1 by using no more than
bits. After this step, user 1 will learn the color of
, from which it can recover
by using the observed
. This is due to the fact that from the definition of an ambiguity set
in Equation (
32), every
n-tuple
for a given
will receive a different color in the minimum coloring of the graph
. Since the selected perfect hash function is one-to-one over the colors assigned to
, it will allow user 1 to recover the color of
from the evaluated hash function value. In the last step, user 1 evaluates the function
, and sends it to user 2 by using no more than
bits. In doing so, she assigns a distinct index for each sequence of function values in the ambiguity set
from Equation (
34). User 2 can then recover the function
by using
and the received index. Overall, this protocol requires no more than
bits to be transmitted in total, therefore
where Equation (
42) follows from the fact that
, and Equation (
44) holds since
. This is due to the fact that any coloring over the
nth order strong product of
is also a valid coloring for
, since by construction of
, any edge that exists in
also exists in the
nth order strong product of
. Therefore, the chromatic number of
is no greater than the chromatic number of the
nth order product of
, which is no greater than
.
Combining the bounds obtained from the two protocols from Equations (
30) and (
45), we have the following upper bound on the worst-case message length.
Proposition 3. The worst-case message length for the two strategies that do not explicitly start with a reconciliation procedure can be upper bounded as, Proof. The result follows from combining the two interaction strategies in Equations (
30) and (
45). ☐
3.3. Partial Reconciliation
In order to understand the impact of
level of reconciliation on the worst-case message length, we consider a third scheme called
partial reconciliation, which allows user 2 to distinguish the true distribution up to a class of distributions, after which the two users use a robust worst-case communication protocol that allows for zero-error communication in the presence of any distribution within the class. In that sense, partial reconciliation allows some ambiguity in the reconciled set of distributions. Accordingly, the schemes considered in
Section 3.1 and
Section 3.2 are special cases of the partial reconciliation scheme. We denote
as the per-symbol worst-case message length for a finite block of
n source symbols under the partial reconciliation scheme. In the following, we demonstrate two protocols for interactive communication with partial reconciliation. The first protocol is based on coloring characteristic graphs, whereas the second protocol is based on perfect hash functions. We then derive an upper bound on the worst-case message length with partial reconciliation.
For the first partial reconciliation protocol, consider the set
of bipartite graphs
constructed by using the distributions
as described in
Section 2.1. Define a partition of the set
as
such that
and
for all
, where
is non-empty for
. Define
as the set of all such partitions of
.
Fix a partition . For each , define a graph for user 1 with the vertex set . Define an edge between nodes and if there exists some such that and whereas . Next, construct a graph for user 2 with the vertex set . Define an edge between nodes and if there exists some such that and for some but . Let and denote the chromatic number of and , respectively.
Then, under any true distribution
, the following communication protocol ensures zero error. The two users agree on a partition
before communication starts. Suppose users 1 and 2 observe
and
, respectively, under the true distribution
. Let
denote the bipartite graph corresponding to the distribution
. Initially, user 1 sends the index
i of the set
for which
, by using no more than
bits. After this step, user 1 sends the color of each symbol in
according to the minimum coloring of graph
by using no more than
bits in total. By using the sequence of colors received from user 1, user 2 can determine the correct function values
. In the last step, user 2 sends the color of each symbol in
according to graph
by using no more than
bits. After this step, user 1 can recover the function values
. Overall, this protocol requires no more than
bits to be transmitted. Since one can leverage any partition within
for constructing the communication protocol, we conclude that the worst-case message length for partial reconciliation is bounded above by,
For the second partial reconciliation protocol, we again leverage perfect hash functions from Equation (
31). As in the first protocol, we define a partition of the set
as
such that
and
for all
. We let
be the set of all such partitions of
.
We fix a partition of . For each , we define a graph with the vertex set . We define an edge between two vertices and if there exists some such that and for . We denote the chromatic number of by .
We define an ambiguity set for each
,
where the size of the largest single-term ambiguity set is given as,
and note that
. Next, we define an ambiguity set for each
,
and define the size of the largest single-term ambiguity set as,
where
. Given
, from Equation (
31), there exists a family
of
functions such that
for all
and for each
of size
, there exists an
injective over
. For each
, the two users agree on a family of functions
and a coloring of graph
with
colors. Suppose user 1 observes
and user 2 observes
. User 1 sends the index of the partition for p to user 2 by using no more than
bits. User 1 then finds a function
that is injective over the colors of the vertices
from Equation (
49) and sends its index to user 2 by using no more than
bits. User 2 then evaluates the corresponding function for the assigned color of
and sends it back to user 1 by using no more than
bits. After this step, user 1 learns the color of
, from which it recovers
by using the observed
. User 1 then evaluates the function
, and sends it to user 2 by using no more than
bits. In doing so, she assigns a distinct index for each sequence of function values in the ambiguity set
from Equation (
34). User 2 can then recover the function
by using
and the received index. Overall, this protocol requires no more than
bits to be transmitted in total, therefore
Combining the bounds obtained from the two protocols in Equations (
48) and (
57), we have the following upper bound on the worst-case message length with partial reconciliation,
At the outset, partial reconciliation characterizes the interplay between reconciliation and communication costs. In order to understand this inherent reconciliation-communication trade-off, we next identify the cases for which reconciling the missing information is better or worse than not reconciling them. To do so, we provide sufficient conditions under which reconciliation-based strategies can outperform the strategies that do not start with a reconciliation procedure, and vice versa, and show that either strategy can outperform the other. Finally, we demonstrate that partial reconciliation can strictly outperform both.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
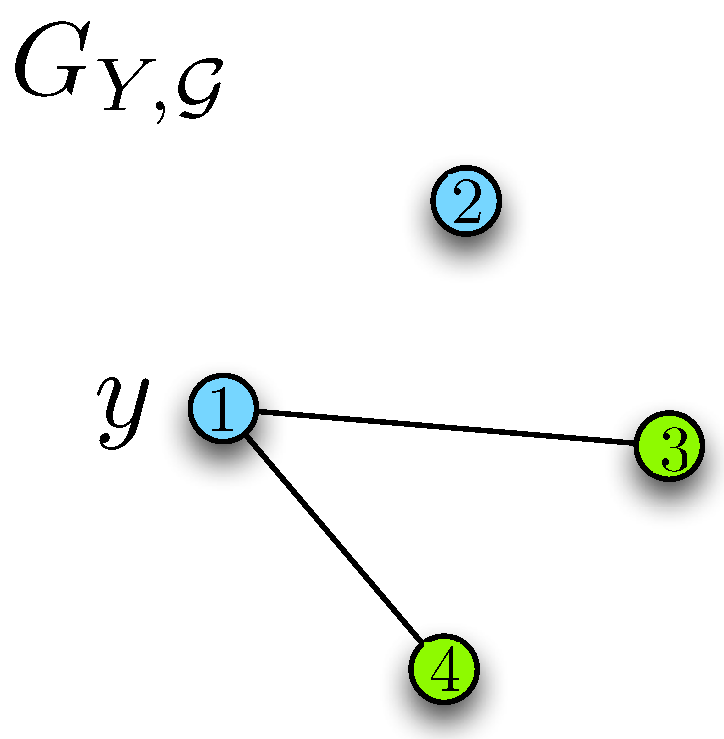{kind=link}
{kind=link}





