1. Introduction
Filtering problems arise in various applications such as signal processing, automatic control and financial time series. The goal of nonlinear filtering is to estimate the state of a nonlinear dynamic process based on noisy observation. In the last several decades, the Kalman filter has become a standard method for linear dynamic systems subject to linear measurements, which can provide a perfect analytical solution in the optimal operation. However, it is not suitable for the nonlinear cases of filtering problems. Along with the spirit of Kalman filter, the approximation methods have been proposed for the nonlinear filtering, such as the Extended Kalman filter (EKF) [
1], Unscented Kalman filter (UKF) [
2], Gauss–Hermite Kalman filter (GHKF) [
3], and Cubature Kalman filter (CKF) [
4]. All these methods can be induced by the Bayesian approach with different approximations [
5] for nonlinear cases. Apart from the aforementioned methods, the sequential Monte Carlo technique approximating for the Bayesian probability density functions (PDFs) is another feasible approach, for instance, the particle filtering (PF) [
6] which uses the particle representations of probability distributions. Within the Bayesian framework, the nonlinear filtering can be converted to Bayesian filtering, and the procedure of filtering consists of two steps: state propagation and measurement update. Correspondingly, the state propagation provides the prior information for the state, and the measurement update integrates the prior information and the conditional measurement to obtain the posterior PDF of the state. In particular, the nonlinear and non-Gaussian conditions will make the measurement update more difficult and the solution of posterior PDFs intractable.
Because Bayesian posterior PDF plays a key role in nonlinear filtering, the study of Bayesian posterior PDF has attracted increasing attentions over the past few decades. Conventionally, the linear minimum mean square error (LMMSE) estimator and maximum a posteriori (MAP) estimator have played major roles in estimating posterior PDF. For the LMMSE estimator, it approximates the posterior mean and covariance matrix by its estimator and its mean square error matrix, respectively. Usually, the EKF, UKF and CKF can be derived from the LMMSE estimator. Besides, an adaptable recursive method named recursive update filter (RUF) has been derived based on the principle of LMMSE [
7,
8], which overcomes some of the limitations of the EKF. Being different from the LMMSE, the MAP estimator has estimated the posterior mean and obtained the covariance matrix by linearizing the measurement function around the MAP estimator. The well-known iterated EKF (IEKF), which is induced by using the Gauss–Newton optimization [
9] or Levenberg–Marquardt (LM) [
10] method, can be interpreted as a MAP estimator. With the variational approach employing for MAP optimization, the variational Kalman filter (VKF) [
11] has been proposed. By using the Newton–Raphson iterative optimization steps to yield an approximate MAP estimation, the generalized iterated Kalman filter (GIKF) [
12] algorithm has been presented to handle the nonlinear stochastic discrete-time system with state-dependent multiplicative estimation. Generally speaking, the MAP estimator methods need the iterative procedures to obtain the final estimation, and these iterative methods for nonlinear filtering have better performance. As the IEKF outperforms EKF and UKF, as shown by Lefebvre [
13], the Iterated UKF (IUKF) [
14] performs better than the UKF in the estimation of state and the corresponding covariance matrix.
Recently, Morelande [
15] has adopted the Kullback–Leibler (KL) divergence as the metric to analyze the difference between the true joint posterior PDFs of the state conditional on the measurement and the approximation posterior PDFs. Actually, this metric can be used to derive new algorithms. The iterated posterior linearization filter (IPLF) [
16] can be seen as an approximate recursive KL divergence minimization procedure. The adaptive unscented Gaussian likelihood approximation filter (AUGLAF) [
17] selects the best approximation to the posterior PDFs based on the KL divergence. The KL partitioned update Kalman filter (KLPUKF) [
18] uses KL divergence to measure the nonlinearity of the measurement. In essence, the KL divergence, also known as relative entropy, is a quantity in information theory. This optimization criterion of information theory has already been applied in signal processing. By utilizing the information theoretic quantities to capture the higher-order statistics, we can obtain the significant performance improvement. Meanwhile, another optimization criterion in information theoretic learning (ITL), i.e., maximum correntropy criterion (MCC), has been introduced for the filtering problems. With this criterion involving in the existing filtering framework, some new Kalman-type filters have been proposed, such as maximum correntropy Kalman filter (MCKF) [
19], maximum correntropy unscented Kalman filter (MCUKF) [
20], robust information filter based on maximum correntropy criterion [
21].
Enlightened by the information theoretic quantities applied in nonlinear filtering, we consider the nonlinear filtering from the information geometric viewpoint. Information geometry, which was originally proposed by Amari [
22], has become a new mathematical tool for the study on manifold of probability distributions. The combination of information theory and differential geometry opens a new perspective to study the geometric structure of information theory and provides a new way to deal with the existing statistical problems. In this paper, we will study the nonlinear filtering by using information geometric method. By using the joint PDFs of the measurement and the state to construct the statistical manifold, the nonlinear characteristics can be represented as the geometric quantities, such as metric tensor, and the filtering problems are converted to the optimization problems on the statistical manifold. In this way, the nonlinear filtering can be progressed by the information geometric optimization method, and it will induce an iterative procedure for estimation. The natural gradient descent [
23] method is used to seek the optimal estimation across the statistical manifold, and the distance defined on the statistical manifold is utilized to design as the stopping criterion to achieve the goal of filtering.
The paper is organized as follows. Firstly, we give a brief description for Bayesian filtering and information geometry in
Section 2 and
Section 3, respectively. Then, the adaptive natural gradient descent method on the statistical manifold is presented to derive the new nonlinear filtering algorithm in
Section 4. Further discussion about our proposed method will be given in
Section 5, and the numerical simulations are implemented to demonstrate the performance in
Section 6. Finally, conclusions are made in
Section 7.
4. Natural Gradient Descent Filtering
For the Bayesian filtering, the posterior distribution plays the key role in the procedure. However, the close-form of posterior PDFs is intractable because of the Bayesian integral. Usually, the optimization technique has been used to obtain the approximation formulation. In this section, we consider this problem from the information geometric perspective, and derive a new filtering method by using information geometric optimization technique.
In the Bayesian filtering, the state propagation (Equation (
1)) can provide the prior information of state before the measurement update. The prior PDF is Gaussian density when the state transition function is linear. While the state function is nonlinear, the prior PDF is non-Gaussian. Here, we focus on the measurement update step, and make an effort to use information geometric optimization for the posterior PDF. Similar to the usual Gaussian filtering, the Gaussian density is used to approximate the non-Gaussian density in the step of state propagation [
16], which has the formulation as
where
and
denote the mean and covariance matrix of the prior PDF after state propagation. It means that the
k-time state
based on the
-time measurement
. With the
k-time measurement likelihood function, i.e., the conditional probability density of the measurement
given
is
We can obtain the Bayesian posterior probability density by substituting Equations (
28) and (
29) into Equation (2). The numerical optimization is used to obtain the approximative solution for Bayesian integral. Similar to MAP, the optimization is reformulated as
where
denotes the negative logarithm likelihood function of posterior distribution, which neglects the terms independent of the
.
Consider the statistical manifold
constructed by the joint probability density
, the natural logarithm maps the statistical manifold to
as
. Given a point
, the Fisher metric tensor of
at
can be calculated as
where
denotes the first order partial derivative of
with respect to
, and
represents the error of the measurement prediction with the state estimation
.
From Equation (
31), we can note that the Fisher metric tensor consists of two parts: the measurement information and the prior information of the state. It also means that the curvature of the statistical manifold is affected by the measurement data and the prior information. It is evident that the effect of nonlinear measurement is reflected by the first terms of the Fisher metric tensor. Equation (
31) establishes the relationship between the nonlinear measurement and the metric tensor.
Since the joint PDFs construct the statistical manifold, the minimization of is converted to the optimization on the statistical manifold for the best estimation. This optimization on statistical manifold considers the measurement and state in a unified approach, and the natural gradient descent method can be used to seek the optimal estimation on the manifold along geodesic lines.
By computing the first order partial derivative of
, we can obtain the gradient
where
and
denote the individual error of the measurement prediction and the state estimation.
Since
is a symmetric positive-definite diagonal matrix,
is positive semi-definite. Note that
is positive, so
is nonsingular. Thus, the natural gradient of the statistical manifold is defined as
With the natural gradient descent on the statistical manifold, we can update the state estimation
and the covariance matrix is approximated by the inverse of the Fisher metric tensor
where
is the Jacobian matrix of measurement function
.
Usually, one step cannot achieve the best estimation, so more steps must be utilized to achieve the final estimation. The states are updated iteratively in state space, while the corresponding posterior probabilities are moving across the statistical manifold.
To sum it up, we can construct an iterative estimation of state through the natural gradient descent method
which corresponds to the moving from
to
on statistical manifold. In Equation (
36),
, and
is the prior information of state provided by the state propagation. Meanwhile, the error covariance matrix associated with
is approximated by the inverse of Fisher metric tensor
Therefore, we can obtain the iterative posterior mean and covariance matrix as . When the stopping criteria are satisfied, the iterative procedure will be terminated, and the filtered state will be achieve.
4.1. Adaptive Step-Size
In this iterative procedure, there are some parameters that must be taken into account. One of them is the step-size parameter, which describes the update step-size in each iterated step. It can be a fixed value through the whole iterative procedure. As an alternative, the step-size is initialized and adjusted in each iteration. There are many strategies to adjust the value of step-size in order to achieve the sufficient decrease during the iterative procedure. In our proposed method, the value of step-size can be obtained by an exact line search [
34]
where
denotes the natural gradient. In each iteration, the searching direction described by the natural gradient is fixed, and we just need to select the parameter
. Usually, the candidates of
can be generated randomly.
4.2. Stopping Criterion
In the iterative procedure, the number of steps can be fixed as a constant. However, it has not considered the convergence and may lead to additional computational burden. Alternatively, the number of steps is acquired according to certain stopping criterion of the iterative procedure. As in the conventional IEKF, the stopping criterion is that the distance of the state estimates between two successive iterations is smaller than a given constant
, that is,
While the distance
is defined in Euclidean space, the counterpart in Riemannian manifold is
We can use this distance to measure the convergence on the statistical manifold. Owing to the equivalence between manifold distance and KL divergence, we also can utilize the KL divergence to measure the convergence. Here, we adopt the KL divergence (Equation (
14)) instead of the distance in stopping criterion, i.e.,
Furthermore, it also describe the divergence between two probability densities of successive iterations. When the convergence is achieved, the divergence level is very low.
6. Simulation
In this section, we compare the classical filtering methods including EKF, IEKF and RUF with our method NGDF in the application of passive target tracking [
14,
36]. The EKF has just one step in the update procedure, and the IEKF is an iterative filtering method derived by the Netwon method. The RUF [
7,
8] is an another iterative filtering method derived by the LMMSE, not the MAP, and it has the fixed number of steps.
For the system setting, the state at time instant k is consisting of position vector and velocity vector , while the measurement at same instant is consisting of bearing , bearing rate , and Doppler rate .
The state equation is linear and represented as
where
where
is a
identity matrix, ⊗ is the Kronecker product,
is the sampling time, and
is zero-mean process noise with covariance matrix
.
The measurement equation is
where
,
denotes the wavelength of received signal, and
are mutually independent zero-mean Gaussian distributed noises with covariance matrix
. Here, we treat
as the coordinate of target, and
as the measurement, which are different from the notations in the above sections.
In this simulation, we consider 200 time steps for tracking, and
,
,
. The prior PDF at time 0 is
, where
, and
where
,
,
, and
.
We carry out the numerical experiment considering two aspects: the first is different initialization parameters in filtering method for the same track, while the second is different tracks with different noise level. The normalization root mean square error (RMSE) of position and velocity are utilized to illustrate the performance of tracking. They are defined as follows
where
denotes the true state, and
is estimation state. For the filtering methods, we set
in the stopping criterion (
41) for our proposed method, while
in (
39) for the IEKF. In the iterative methods (IEKF, RUF and NGDF), the max number of iterative steps is
.
Firstly, we set the measurement noise variances as
,
and
, and select a track as
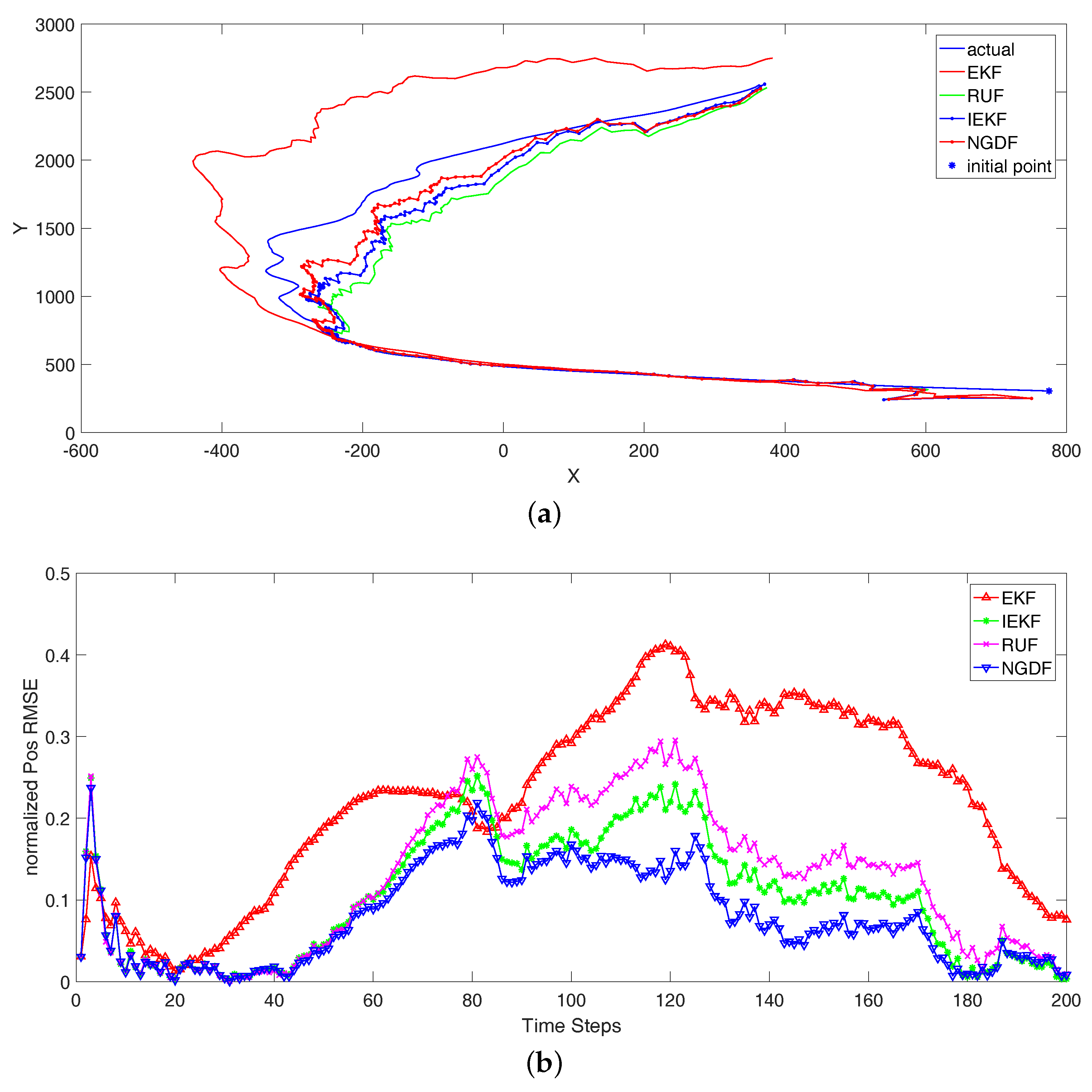
Figure 1a. We carry out 100 Monte Carlo runs for filtering, and average over different realizations to obtain the tracking and normalized position RMSE. In each Monte Carlo runs, the initial filtered state at time 0 is generated random according to the prior PDF. Usually, they are different. After filtering, the results are shown in
Figure 1. In this figure, we can note that the different initial state has influenced the first few steps, and will perform well in the follow steps. In addition, the changeable trajectory can lead to the performance of tracking degradation. In this comparing experiment, we can know that the filtered track by our filtering method is closer to the true track than the other methods, and the normalized position RMSE of our method is lower than the others. Comparing the iterative filtering methods with EKF, the iterative methods have better performance. This is because that the iterative methods have utilized the more iterative steps to hold the nonlinear measurement function, and they are more accurate than the nonlinear processing in EKF methods.
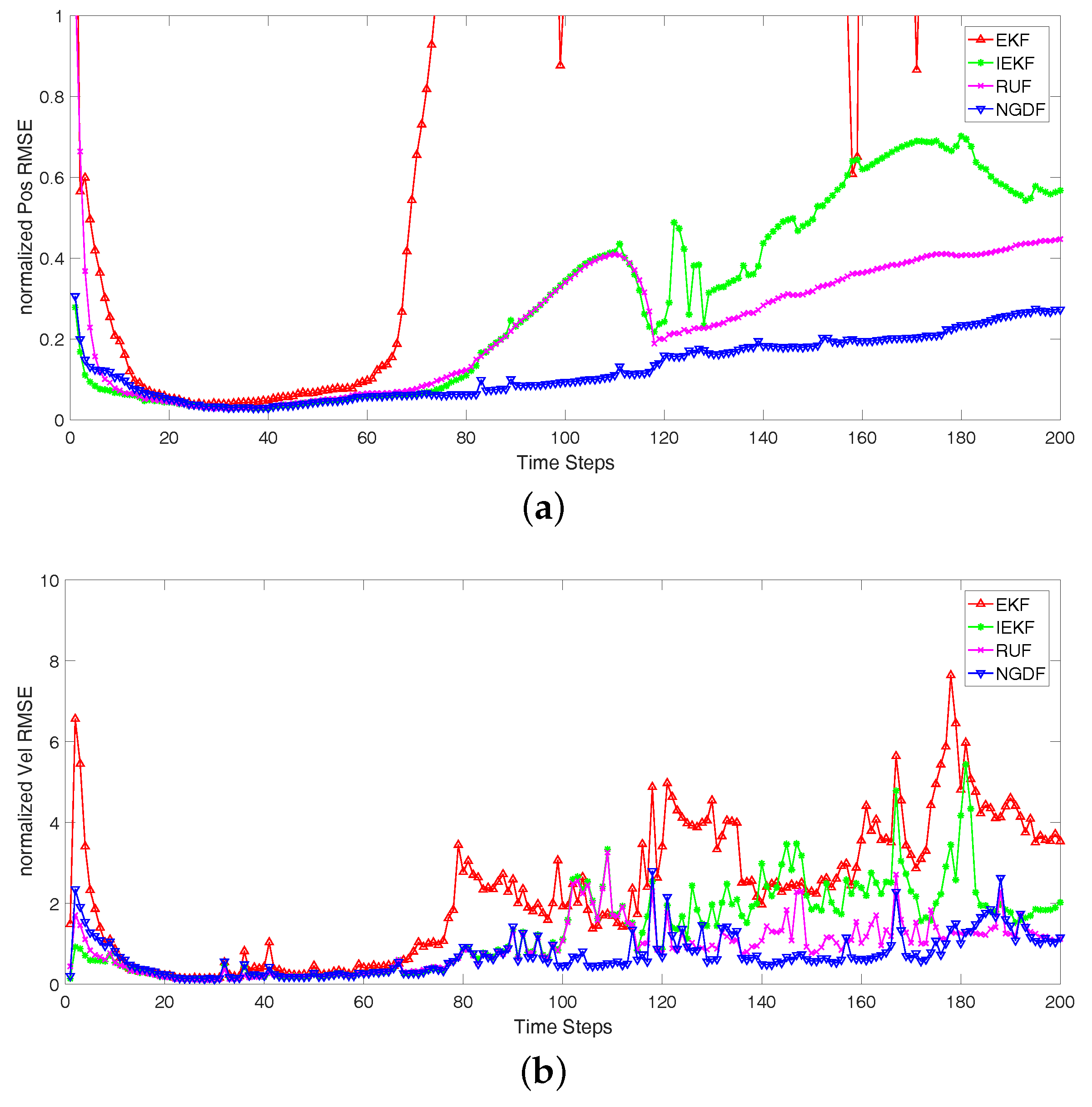
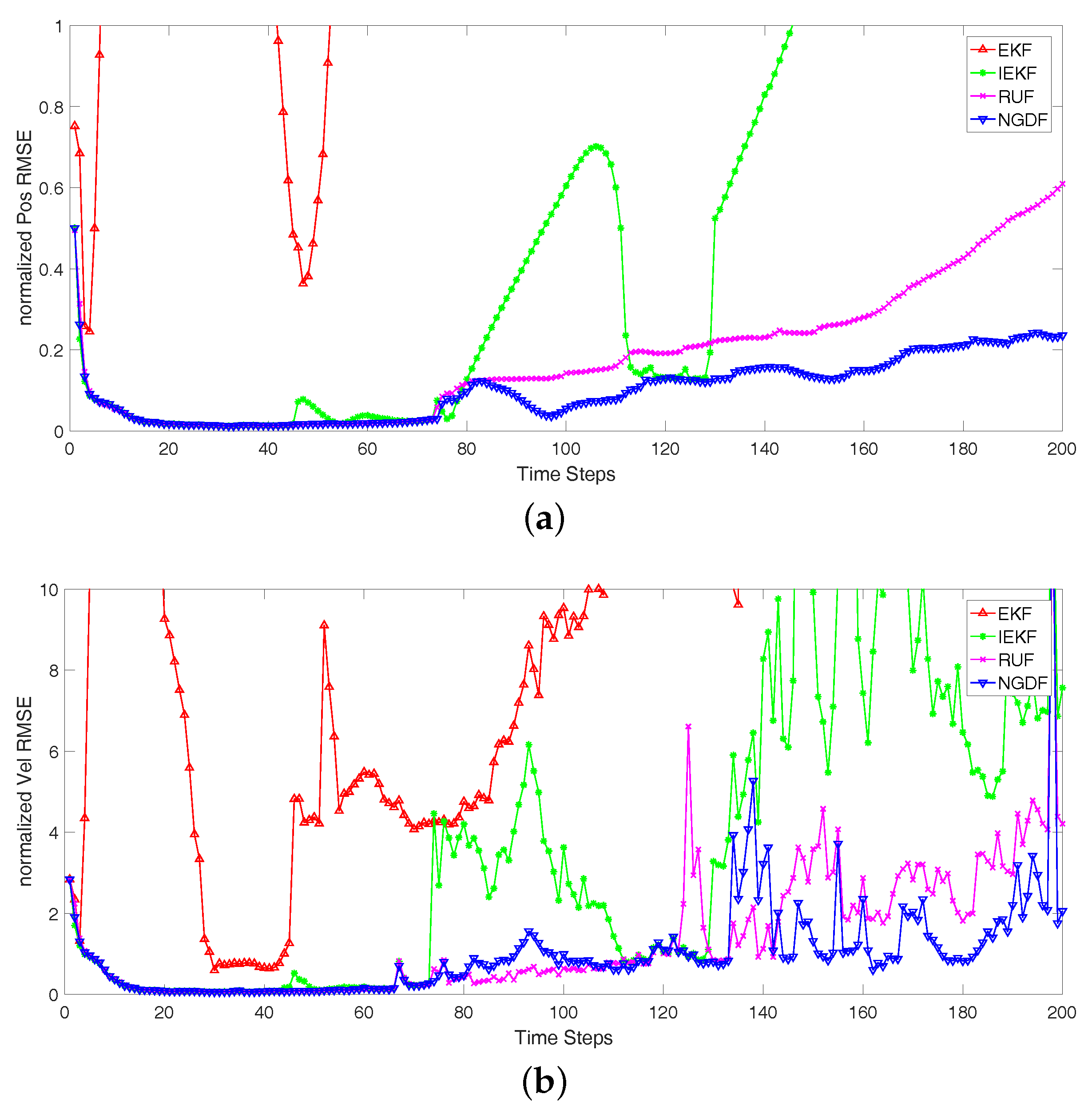
Secondly, we consider different tracks with different noise level. We carry out 100 Monte Carlo runs for the tracks, and take the average over different realizations of the tracks and the corresponding filtered states. The initial true state is random generated according to the prior PDF of state. Because the random initial state is used in each track and the state noise is imposed on state at each time step, the tracks will be different for the Monte Carlo runs. In the Bayesian filtering framework, we focus on the measurement update, and the different measurement noise is considered in this paper. We analyze the three scenarios that differ in the measurement noise variances:
Scenario 1: , and ;
Scenario 2: , and ;
Scenario 3: , and .
The normalized RMSEs of position and velocity are shown in
Figure 2,
Figure 3 and
Figure 4, and the number of iterative steps is shown in
Figure 5. The results in
Figure 2,
Figure 3 and
Figure 4 show that the iterative methods perform better than the EKF, and our proposed method NGDF outperforms other two iterative methods IEKF and RUF in the estimations of position and velocity. Our method has the stable performance that the normalized position RMSEs keep a lower level. The EKF method has the bad performance that it diverges at some times. Comparing with the estimation of velocity, the performance of four filtering methods fluctuate greatly. These are limited by the measurement of radar system. The position measurement can be obtained directly, while the velocity measurement is obtained indirectly that also need the position measurement. The error of position measurement and estimation also influence the velocity estimation. In this case, our method has small fluctuation comparing with the other methods. From
Figure 2,
Figure 3 and
Figure 4, the EKF fluctuates greatly. It means that the EKF method diverges in many cases, and it is not suitable for this tracking problems with the nonlinear measurement. Meanwhile, the IEKF has some jump points. This is because the iterative estimation has not converged, but the stopping criterion is satisfied. Besides, we can note the performance of the RUF method. It has a stable performance second only to our method. However, it has far more computational burden than our method and the EKF and IEKF method shown in
Figure 5.
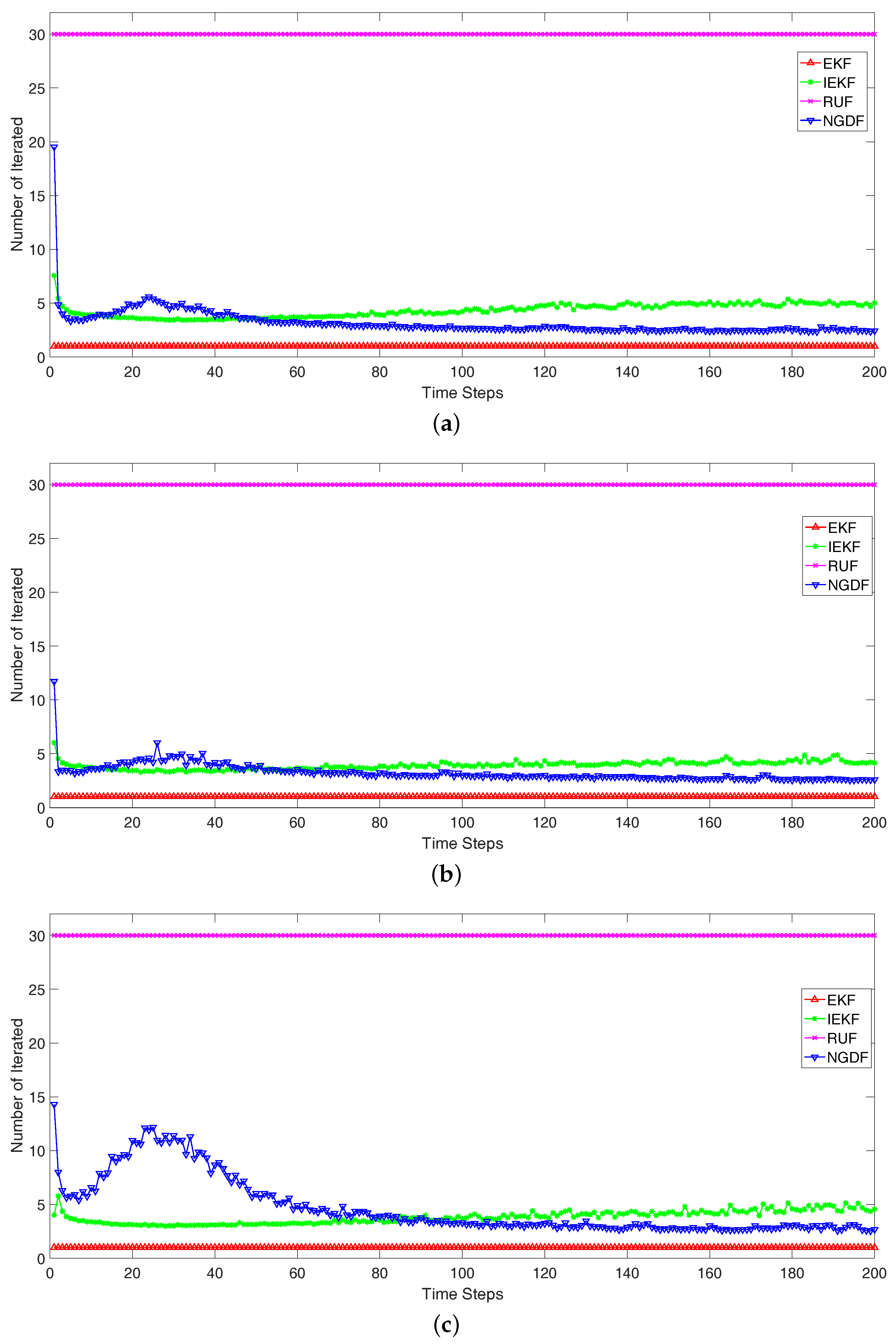
To measure the computational burden, we compare the number of iteration intuitively. The average number of iteration in each time step is shown in
Figure 5. In the simulation, the EKF uses one step to obtain the filtered state in each time step, i.e., the iteration number is
. The RUF is an iterative method, which has fixed iteration number as
. For these three scenarios, the iteration number of the IEKF is about
, while the iteration number of NGDF is roughly less than
in
Figure 5a,b. In
Figure 5c, the number of iteration of NGDF is more than IEKF before the time steps 80, but lower in the succedent time steps. These results can reflect the computational burden. In each time step, the computational burden of RUF is 30 times than the EKF, while the IEKF is about 5 times and NGDF is less 4 times. Comparing the IEKF and NGDF method, the step-size of NGDF is adaptive, which leads to the less steps and more robust estimation. While the IEKF uses the full step-size, which may fluctuate or delay the stopping time. Besides, we compare the execution times in milliseconds for the Scenario 1. The four methods are implemented with the Matlab on a Intel Core i7 laptop. The average of the execution times based on the 100 monte carlo runs are: EKF (11.5 s), IEKF (38.4 s), NGDF (26.4 s) and RUF (187.6 s). In addition, it should be noted that these times are computed for the whole filtering procedure which achieve filtering from the beginning of time steps to the end. We can conclude that the lowest computational burden is achieved by our proposed method.
In this simulation, we also note that the performance may be become bad after a certain tracking steps. This is because that the resolution limit of radar system measurement. The resolution limit of measurement will influence the accuracy of the measurement, thus make some effect on the estimation state. This is why that the tracking of radar system has a tracking time interval. Exceeding the time interval, the tracking performance is unavailable. In addition, the level of noise has influenced the track and estimation. The lower level of state noise may make the track tend to be fixed, while the lower level of measurement noise may make the measurement is more available. They can make the estimation more accurate, but there have no significant and determination relationship between noise level and filtering. This is because the nonlinear function between state and measurement. Usually for the filtering problems, we have made some simplification and considered some case to compare the filtering methods.
To sum up, in this simulation, our method is the filtering method with highest performance than the other methods. It has a stable performance, and the increase in performance of our method does not imply a much higher computational burden compared to other iterative methods.
7. Conclusions
In this paper, we have derived a novel filtering method by utilizing the information geometric approach. The filtering problem has been converted to an optimization on the statistical manifold constructed by the joint PDFs of Bayesian filtering, and the adaptive natural gradient descent method is used to search the optimal estimation. In the filtering procedure, curvature characteristic brought about by the nonlinearity of the observation operator is considered carefully by the Fisher metric tensor. For the Bayesian filtering, the Fisher metric tensor consists of measurement likelihood and prior information of state. For the linear case, the metric is constant, while variable in the nonlinear case. Then, the adaptive natural gradient descent technique is used to derive the iterative filtering, and the KL divergence is employed in the stopping criterion. Furthermore, the conventional Kalman filter, EKF and IEKF are the special formulations of our proposed method under certain conditions. With adaptive step-size and KL divergence stopping criterion, the proposed method has made some improvement over EKF, IEKF and RUF.
For the Bayesian nonlinear filtering, the posterior density may be non-Gaussian. There are two reasons bringing about the non-Gaussian cases. The first reason is that non-Gaussian observation densities make the posterior density non-Gaussian. An optimal filter has been proposed to address this problem [
37]. It can modify the Kalman filter to handle the non-Gaussian observation density. The second reason is that nonlinear measurement makes the Gaussian densities become non-Gaussian. The Monte Carlo method can be used to solve this problem with large computational burden.
In the derivation of our method, we can note that the information geometric optimization for filtering can be extended to some non-Gaussian case, such as the exponential density. When the density has the analytic form, the metric can be computed, and the information geometric optimization can be used to derive the filtering method. Besides, we can use the fact that the non-Gaussian density can be approximated by the sum of some Gaussian densities to convert the non-Gaussian density into the Gaussian density, then the proposed method in this paper can be utilized in each Gaussian density component. In future work, we will continue to combine the information geometric optimization with non-Gaussian filtering, and provide some approaches for addressing the problems of non-Gaussian density in the filtering.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




