A Geodesic-Based Riemannian Gradient Approach to Averaging on the Lorentz Group

{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Geometry of the Lorentz Group
3. Optimization on the Lorentz Group
3.1. Riemannian-Steepest-Descent Algorithm on the Lorentz Group
3.2. Extended Hamiltonian Algorithm on the Lorentz Group
4. Numerical Experiments
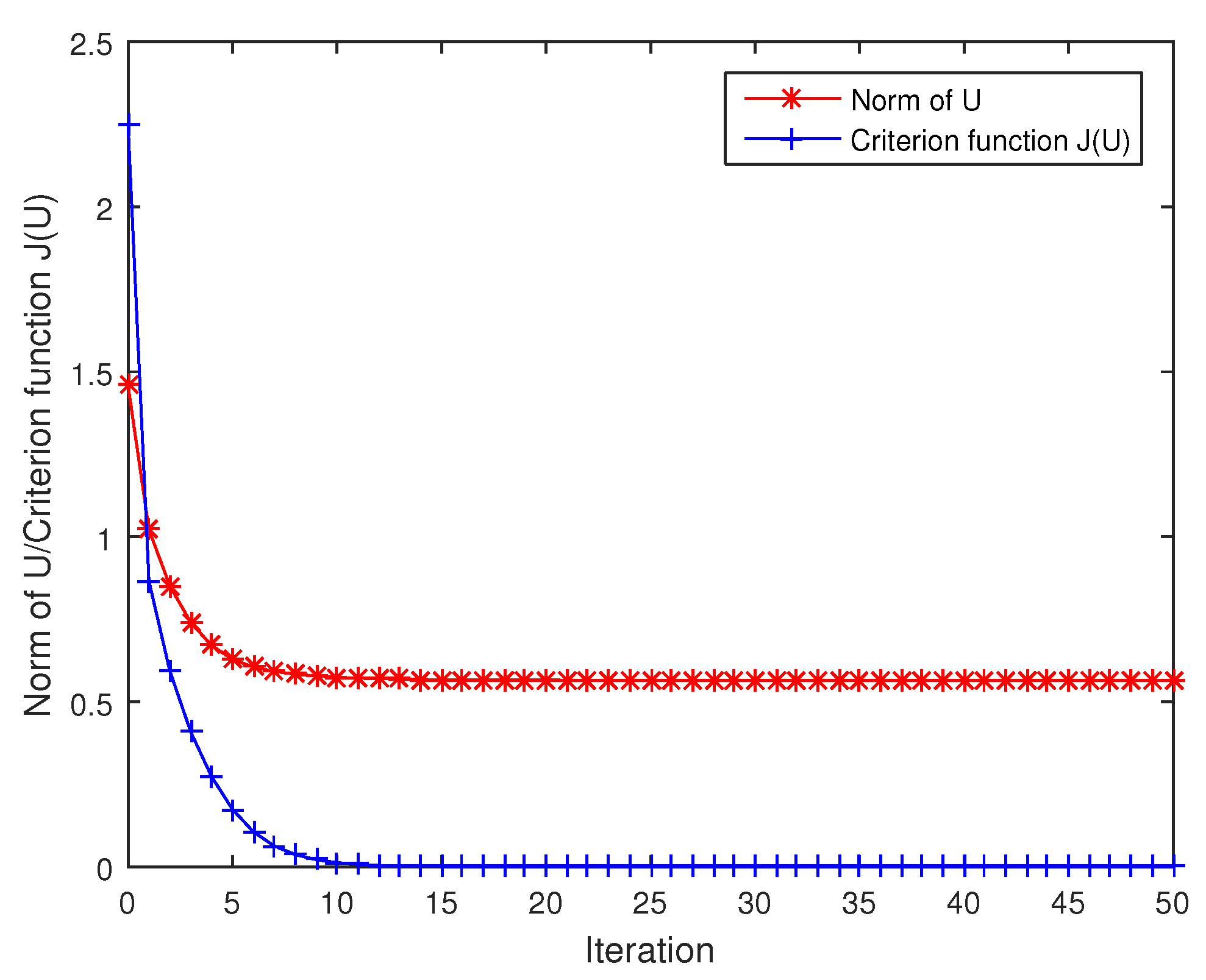
4.1. Numerical Experiments on Averaging Two Lorentz Matrices
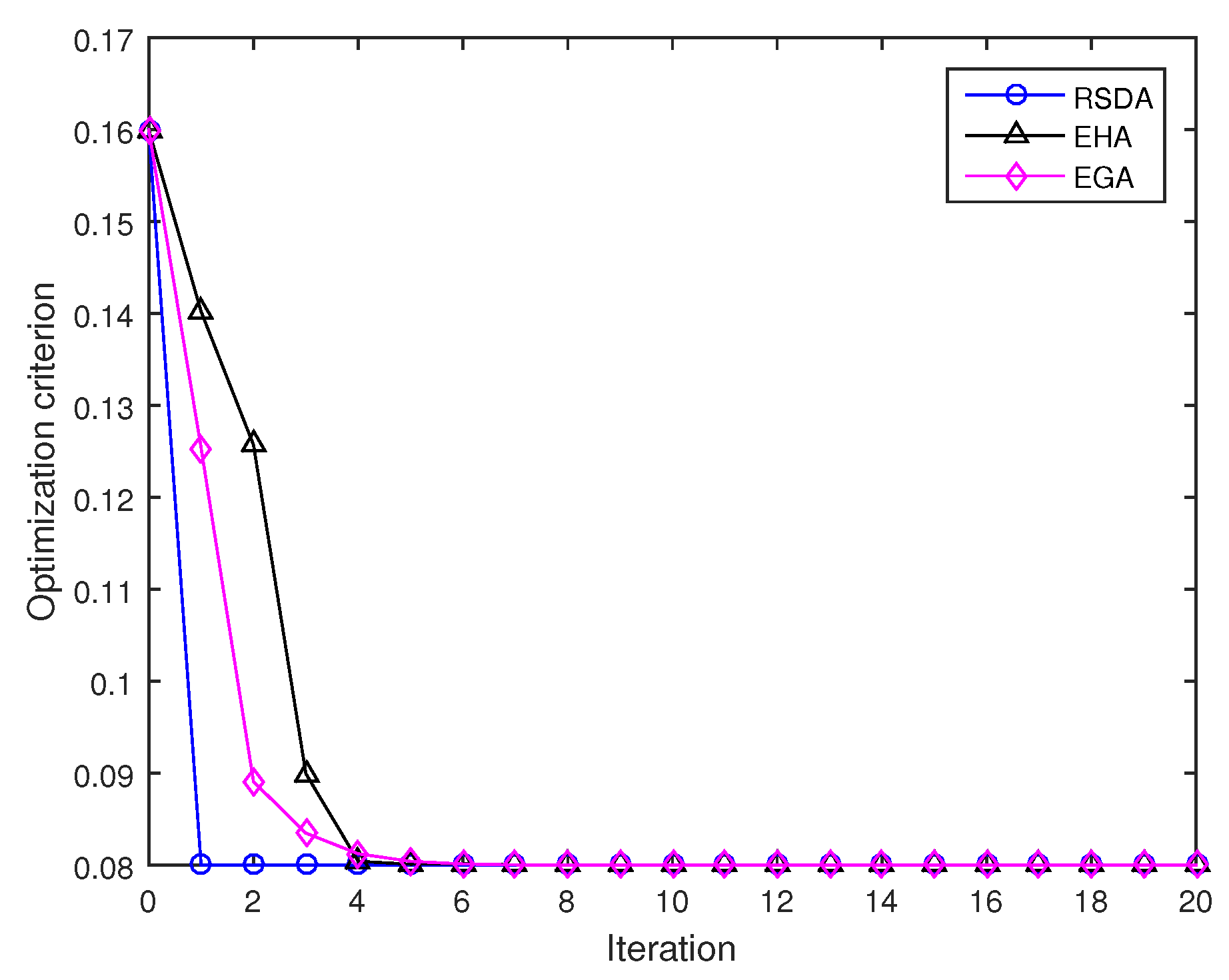
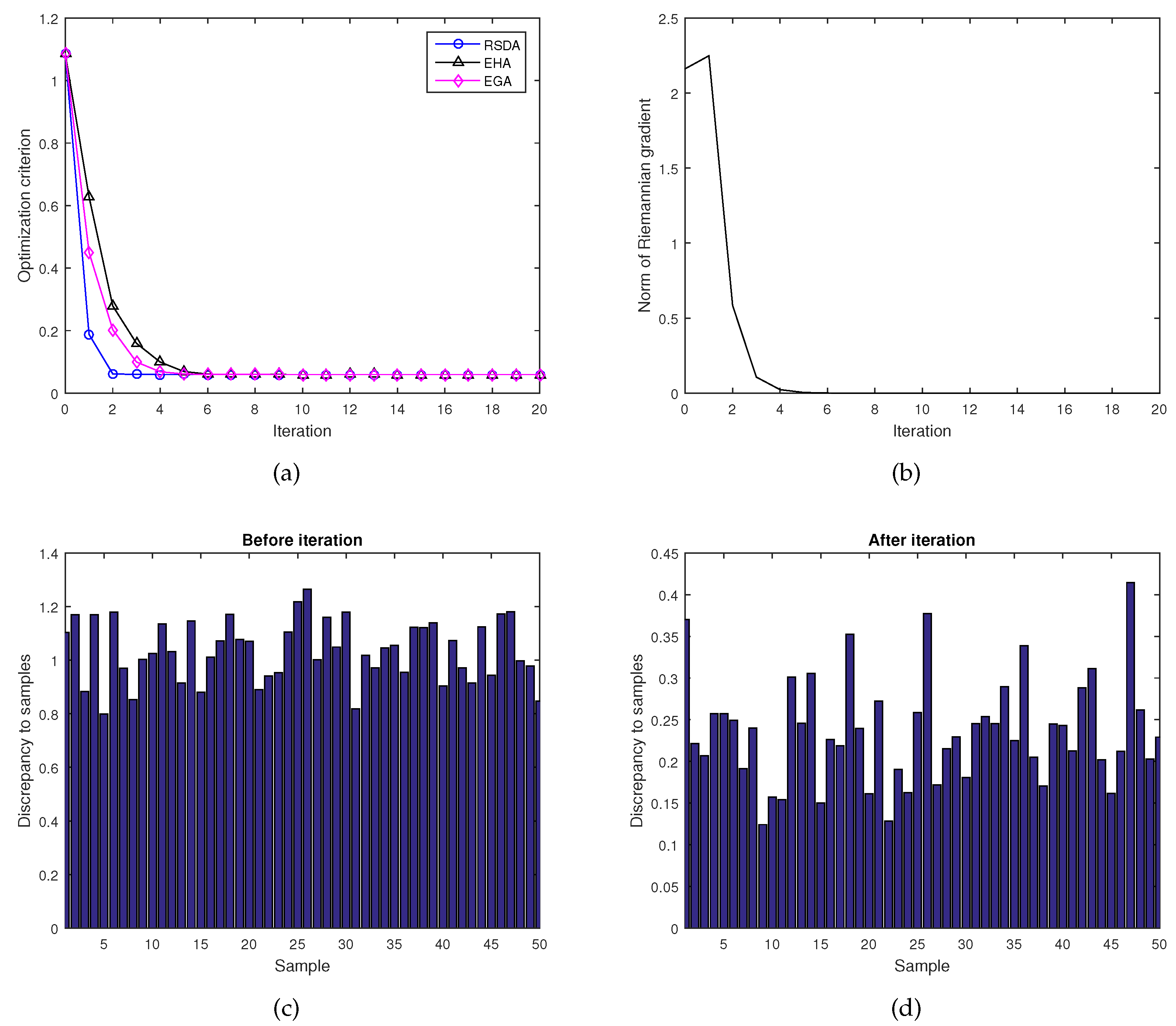
4.2. Numerical Experiments on Averaging Several Lorentz Matrices
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Harris, W.F. Paraxial ray tracing through noncoaxial astigmatic optical systems, and a 5 × 5 augmented system matrix. Optom. Vis. Sci. 1994, 71, 282–285. [Google Scholar] [CrossRef] [PubMed]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Multi-class brain computer interface classification by Riemannian geometry. IEEE Trans. Bio. Med. Eng. 2012, 59, 920–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moakher, M. Means and averaging in the group of rotations. SIAM J. Matrix Anal. A 2002, 24, 1–16. [Google Scholar] [CrossRef]
- Mello, P.A. Averages on the unitary group and applications to the problem of disordered conductors. J. Phys. A 1990, 23, 4061–4080. [Google Scholar] [CrossRef]
- Duan, X.M.; Sun, H.F.; Peng, L.Y. Riemannian means on special Euclidean group and unipotent matrices group. Sci. World J. 2013, 2013, 292787. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, R.; Vemuri, B.C. Recursive Fréchet mean computation on the Grassmannian and its applications to computer vision. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Fiori, S.; Kaneko, T.; Tanaka, T. Tangent-bundle maps on the Grassmann manifold: Application to empirical arithmetic averaging. IEEE Trans. Signal Process. 2015, 63, 155–168. [Google Scholar] [CrossRef]
- Kaneko, T.; Fiori, S.; Tanaka, T. Empirical arithmetic averaging over the compact Stiefel manifold. IEEE Trans. Signal Process. 2013, 61, 883–894. [Google Scholar] [CrossRef]
- Pölitz, C.; Duivesteijn, W.; Morik, K. Interpretable domain adaptation via optimization over the Stiefel manifold. Mach. Learn. 2016, 104, 315–336. [Google Scholar] [CrossRef]
- Fiori, S. Learning the Fréchet mean over the manifold of symmetric positive-definite matrices. Cogn. Comput. 2009, 1, 279–291. [Google Scholar] [CrossRef]
- Moakher, M. A differential geometric approach to the geometric mean of symmetric positive-definite matrices. SIAM J. Matrix Anal. A 2005, 26, 735–747. [Google Scholar] [CrossRef]
- Buchholz, S.; Sommer, G. On averaging in Clifford groups. In Computer Algebra and Geometric Algebra with Applications; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3519, pp. 229–238. [Google Scholar]
- Kawaguchi, H. Evaluation of the Lorentz group Lie algebra map using the Baker-Cambell-Hausdorff formula. IEEE Trans. Magn. 1999, 35, 1490–1493. [Google Scholar] [CrossRef]
- Heine, V. Group Theory in Quantum Mechanics; Dover: New York, NY, USA, 1993. [Google Scholar]
- Geyer, C.M. Catadioptric Projective Geometry: Theory and Applications. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2002. [Google Scholar]
- Fiori, S. Extended Hamiltonian learning on Riemannian manifolds: Theoretical aspects. IEEE Trans. Neural Netw. 2011, 22, 687–700. [Google Scholar] [CrossRef] [PubMed]
- Fiori, S. Extended Hamiltonian learning on Riemannian manifolds: Numerical aspects. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 7–21. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X. Matrix Analysis and Application; Springer: Beijing, China, 2004. [Google Scholar]
- Andruchow, E.; Larotonda, G.; Recht, L.; Varela, A. The left invariant metric in the general linear group. J. Geom. Phys. 2014, 86, 241–257. [Google Scholar] [CrossRef]
- Zacur, E.; Bossa, M.; Olmos, S. Multivariate tensor-based morphometry with a right-invariant Riemannian distance on GL+(n). J. Math. Imaging Vis. 2014, 50, 19–31. [Google Scholar] [CrossRef]
- Goldberg, K. The formal power series for log(exey). Duke Math. J. 1956, 23, 1–21. [Google Scholar] [CrossRef]
- Newman, M.; So, W.; Thompson, R.C. Convergence domains for the Campbell-Baker-Hausdorff formula. Linear Algebra Appl. 1989, 24, 30–310. [Google Scholar] [CrossRef]
- Thompson, R.C. Convergence proof for Goldberg’s expoential series. Linear Algebra Appl. 1989, 121, 3–7. [Google Scholar] [CrossRef]
- Karcher, H. Riemannian center of mass and mollifier smoothing. Commun. Pure Appl. Math. 1977, 30, 509–541. [Google Scholar] [CrossRef]
- Gabay, D. Minimizing a differentiable function over a differentiable manifold. J. Optim. Theory App. 1982, 37, 177–219. [Google Scholar] [CrossRef]
- Fiori, S. Solving minimal-distance problems over the manifold of real symplectic matrices. SIAM J. Matrix Anal. A 2011, 32, 938–968. [Google Scholar] [CrossRef]
- Fiori, S. A Riemannian steepest descent approach over the inhomogeneous symplectic group: Application to the averaging of linear optical systems. Appl. Math. Comput. 2016, 283, 251–264. [Google Scholar] [CrossRef]



© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Sun, H.; Li, D. A Geodesic-Based Riemannian Gradient Approach to Averaging on the Lorentz Group. Entropy 2017, 19, 698. https://doi.org/10.3390/e19120698
Wang J, Sun H, Li D. A Geodesic-Based Riemannian Gradient Approach to Averaging on the Lorentz Group. Entropy. 2017; 19(12):698. https://doi.org/10.3390/e19120698
Chicago/Turabian StyleWang, Jing, Huafei Sun, and Didong Li. 2017. "A Geodesic-Based Riemannian Gradient Approach to Averaging on the Lorentz Group" Entropy 19, no. 12: 698. https://doi.org/10.3390/e19120698
APA StyleWang, J., Sun, H., & Li, D. (2017). A Geodesic-Based Riemannian Gradient Approach to Averaging on the Lorentz Group. Entropy, 19(12), 698. https://doi.org/10.3390/e19120698