
Impact Location and Quantification on an Aluminum Sandwich Panel Using Principal Component Analysis and Linear Approximation with Maximum Entropy



Abstract
:1. Introduction
2. Impact Identification Methodology
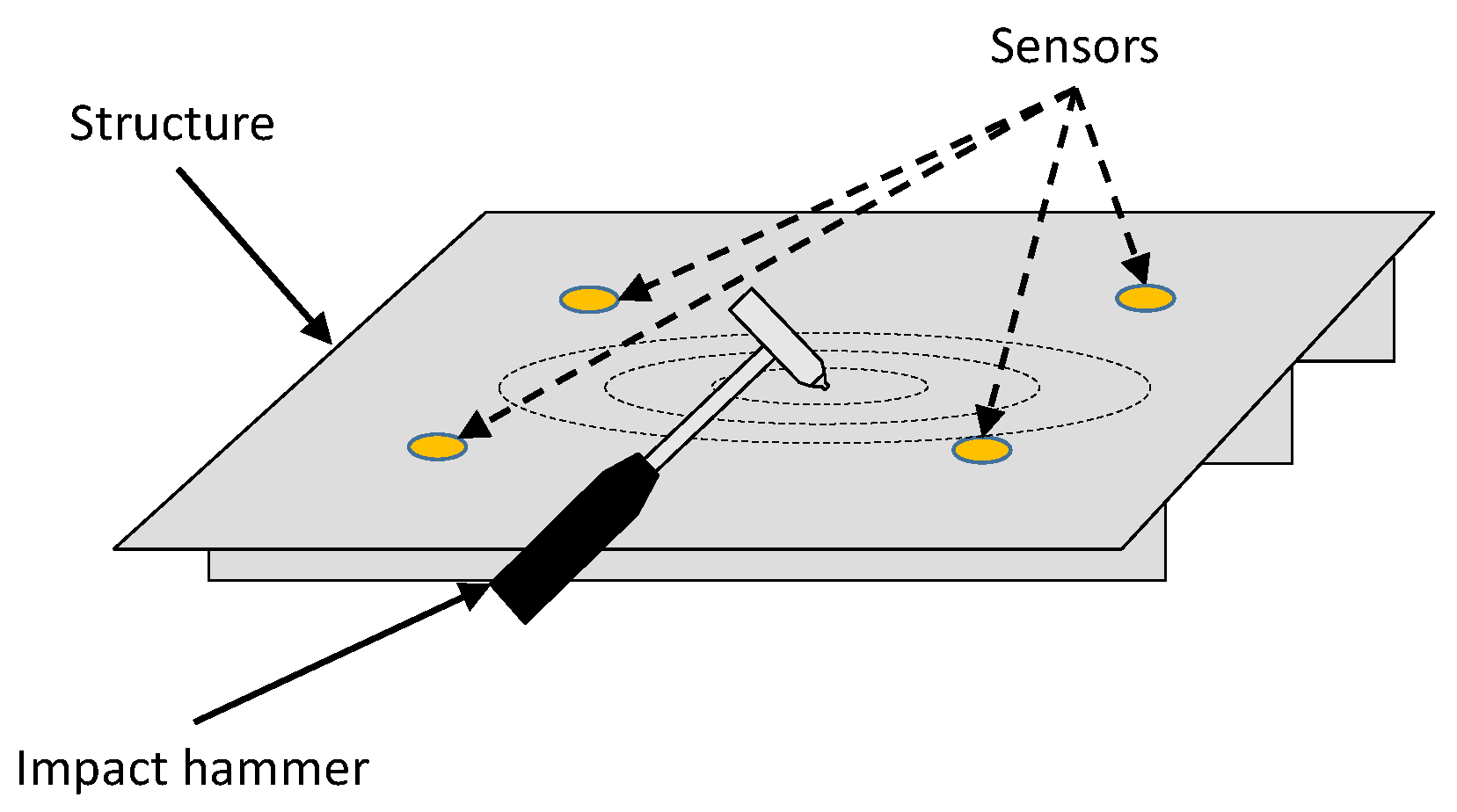
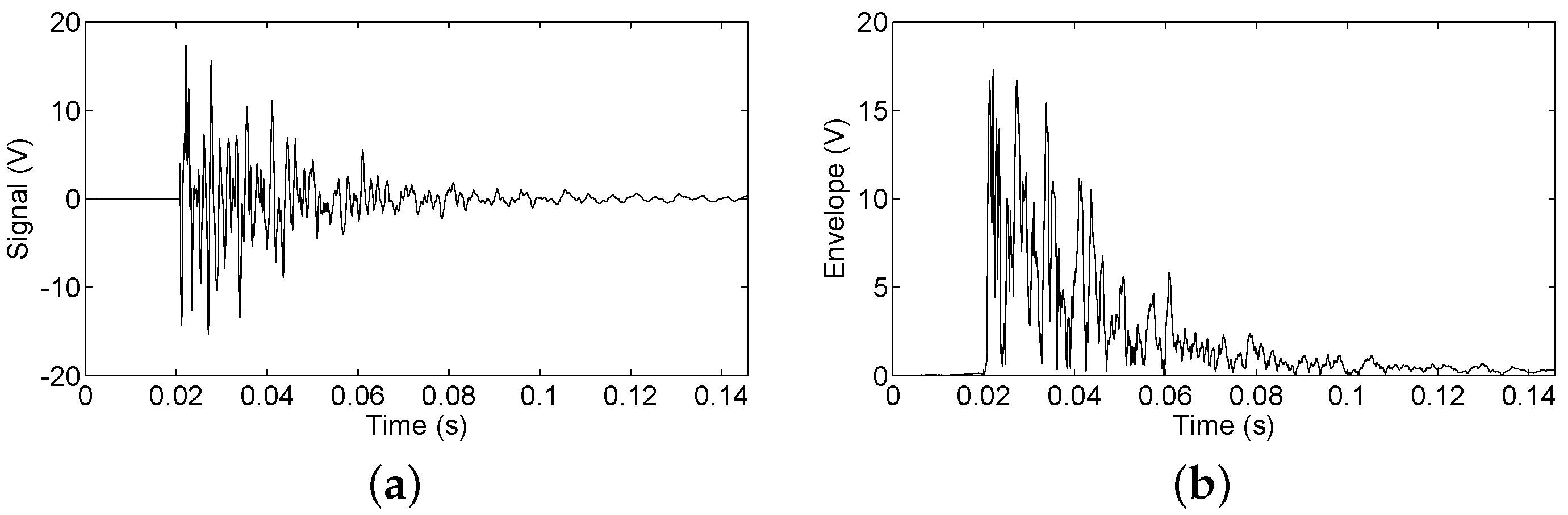
2.1. Data Acquisition
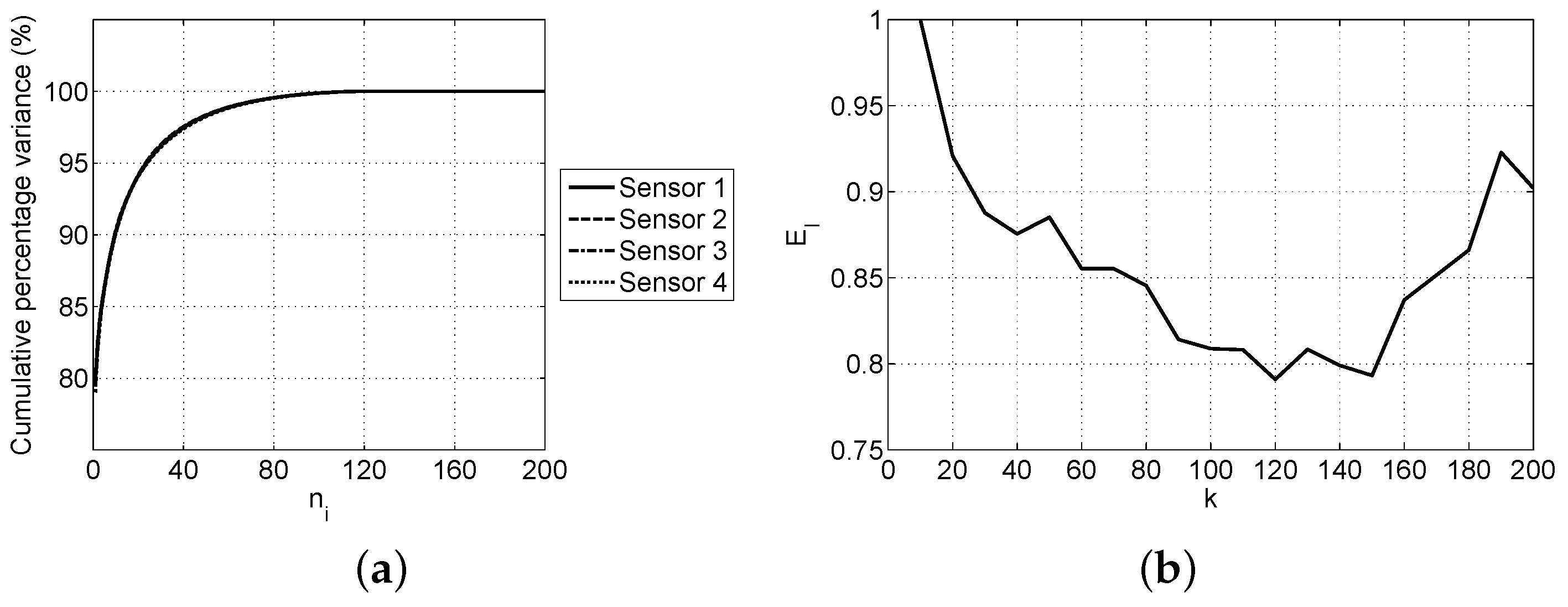
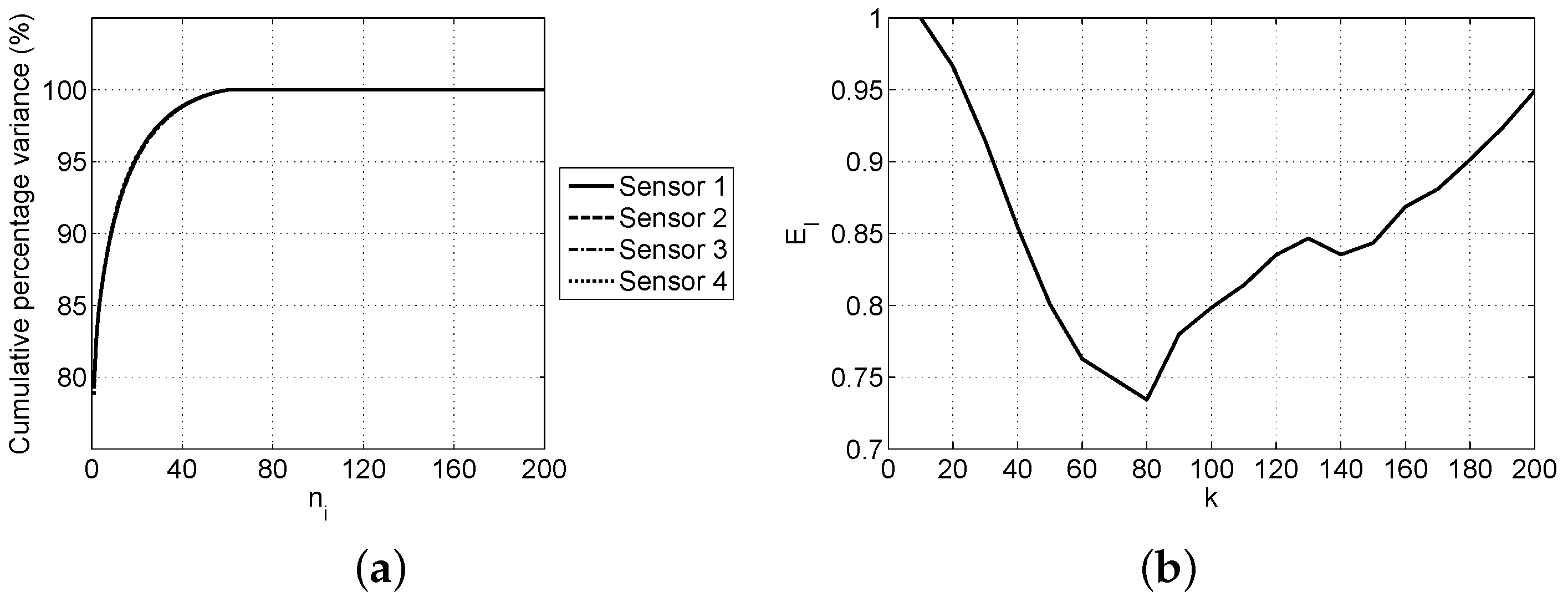
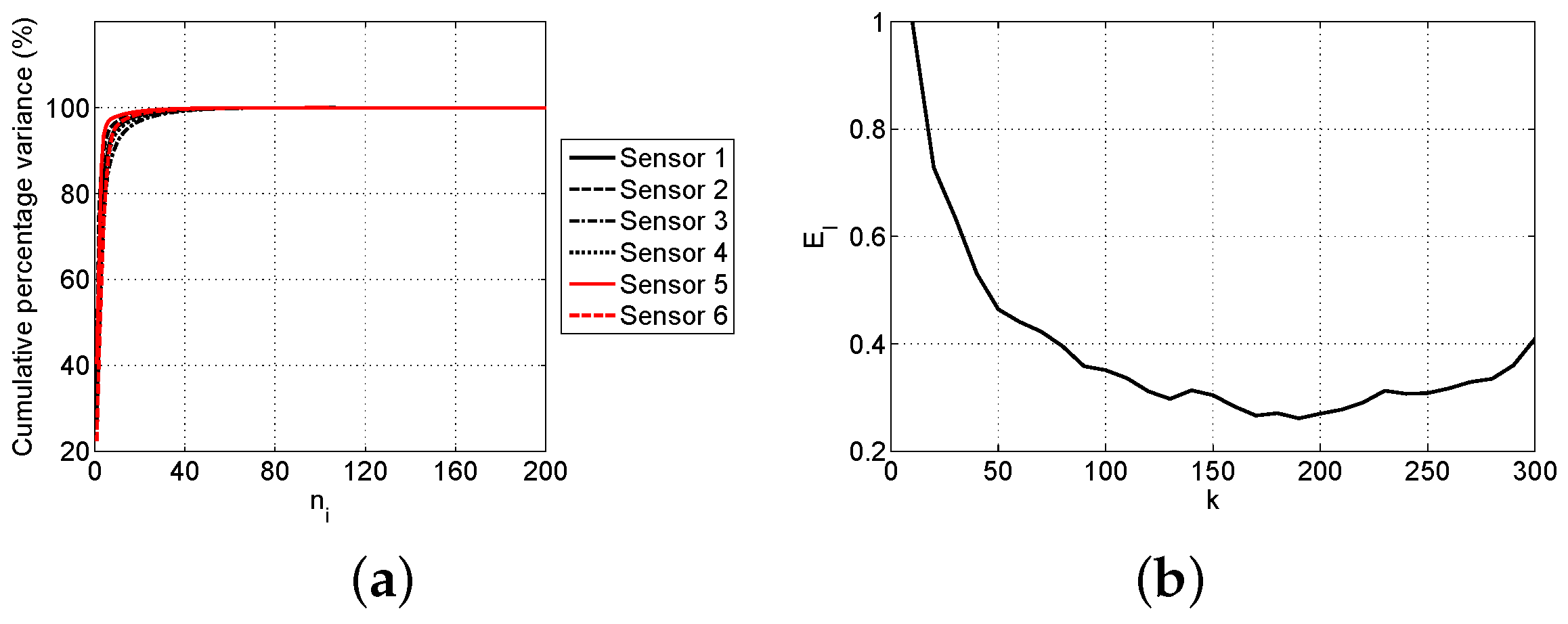
2.2. Principal Component Analysis
2.3. Linear Approximation with Maximum Entropy
2.4. Impact Identification
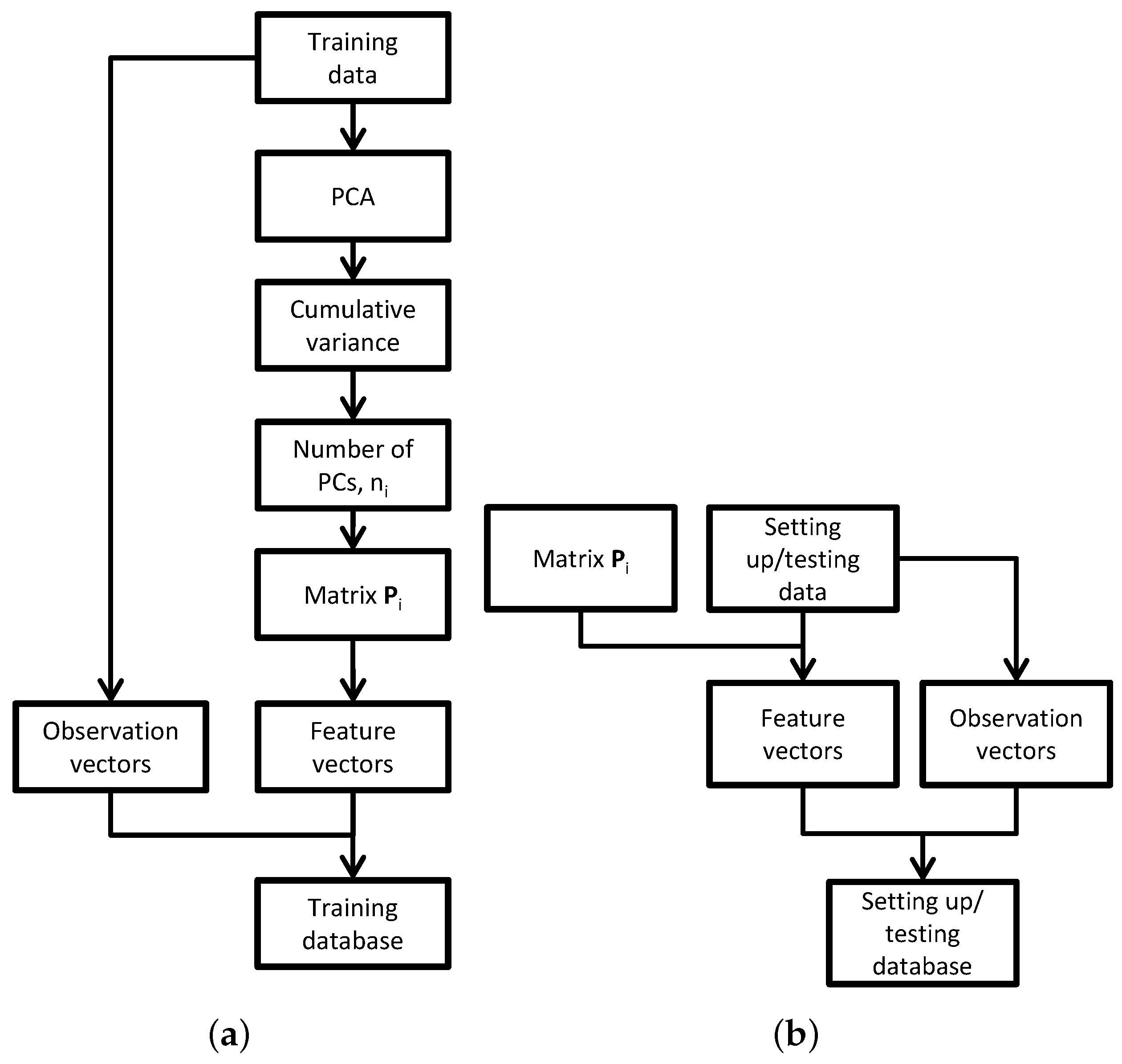
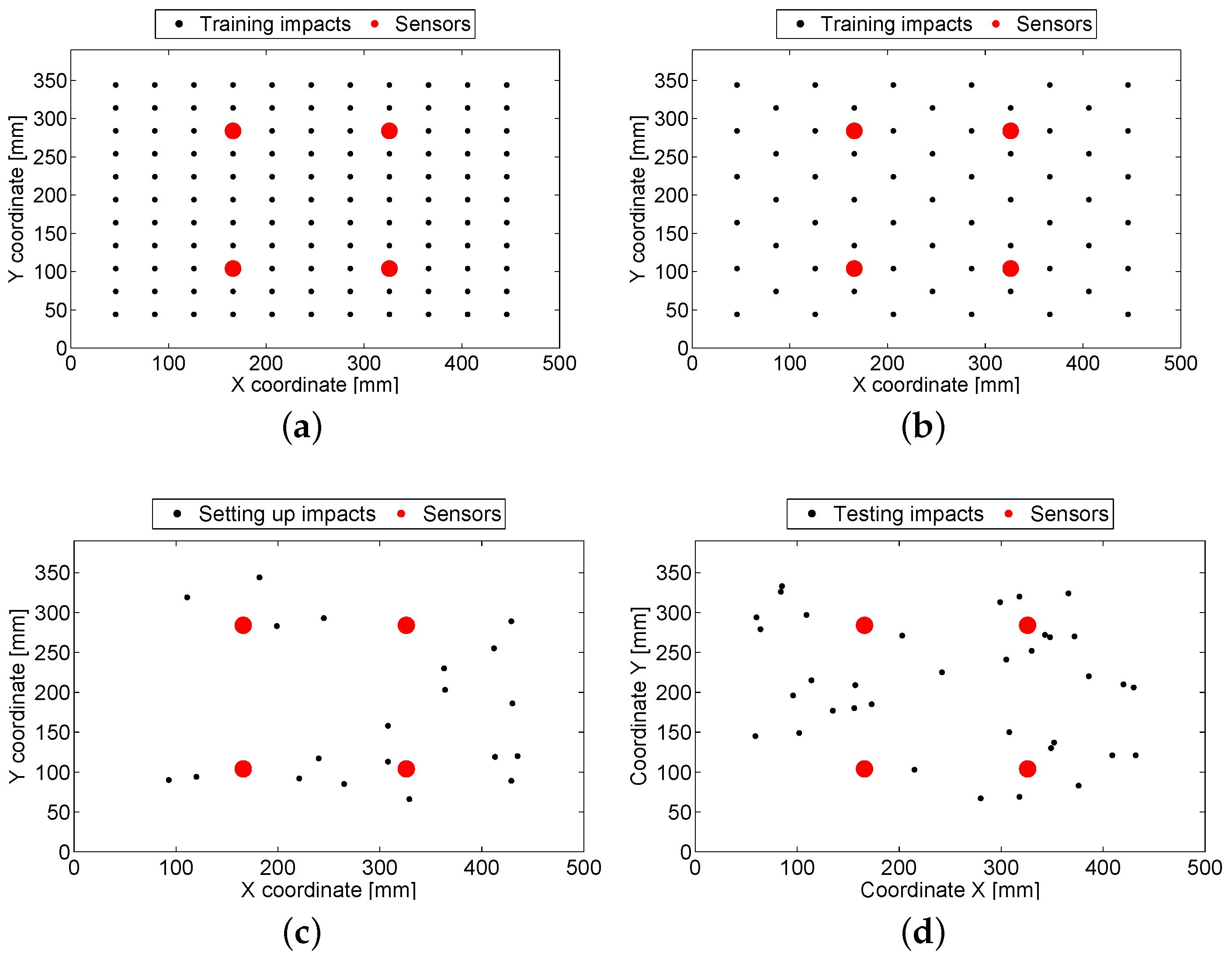
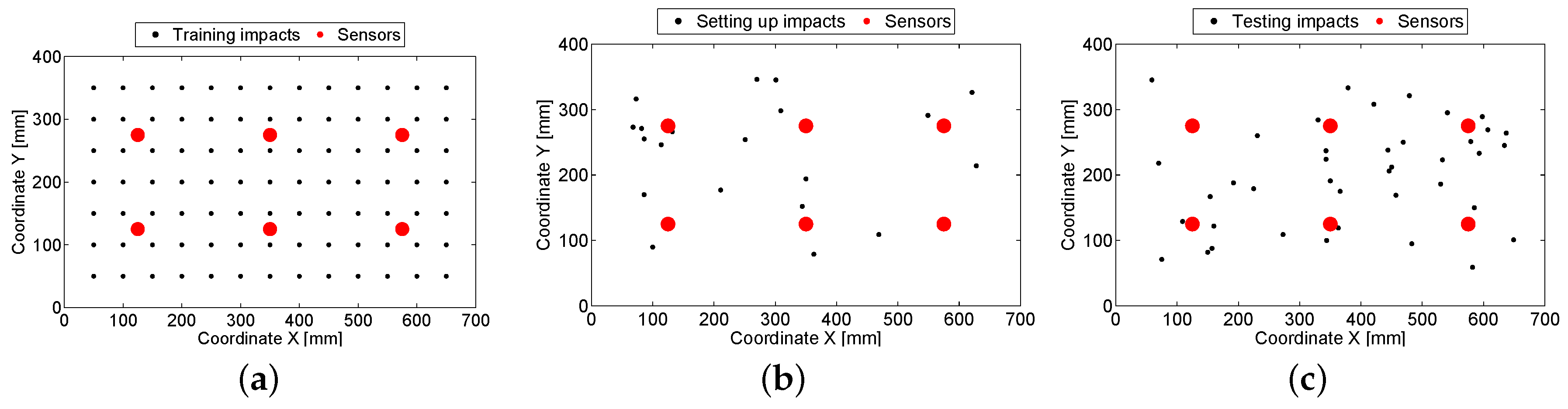
2.4.1. Building of the Databases
2.4.2. Selection of Parameters
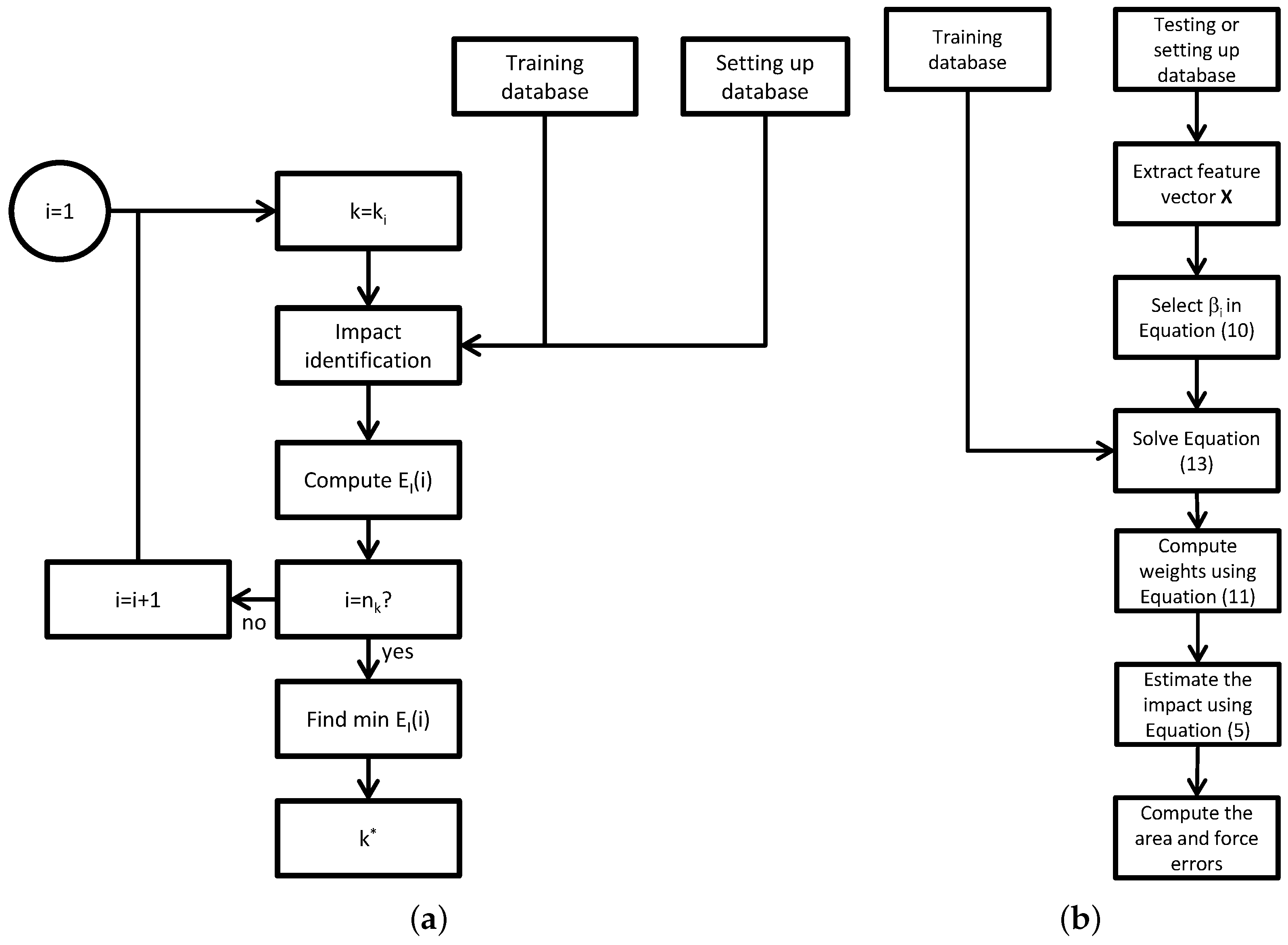
2.4.3. Evaluation of the Algorithm
- Extract a feature vector from the testing database.
- Select the parameter in the Equation (10), so that neighbors contribute to the solution.
- Solve the system of nonlinear equations presented in Equation (13).
- Compute the weight functions using Equation (11).
- Read the observation vectors in the database and estimate the experimental impact using Equation (5).
- Compute the area and force errors using Equations (16) and (17).
- Repeat steps 1 to 6 for all the feature vectors in the testing database.
3. Experimental Applications
3.1. Aluminum Plate
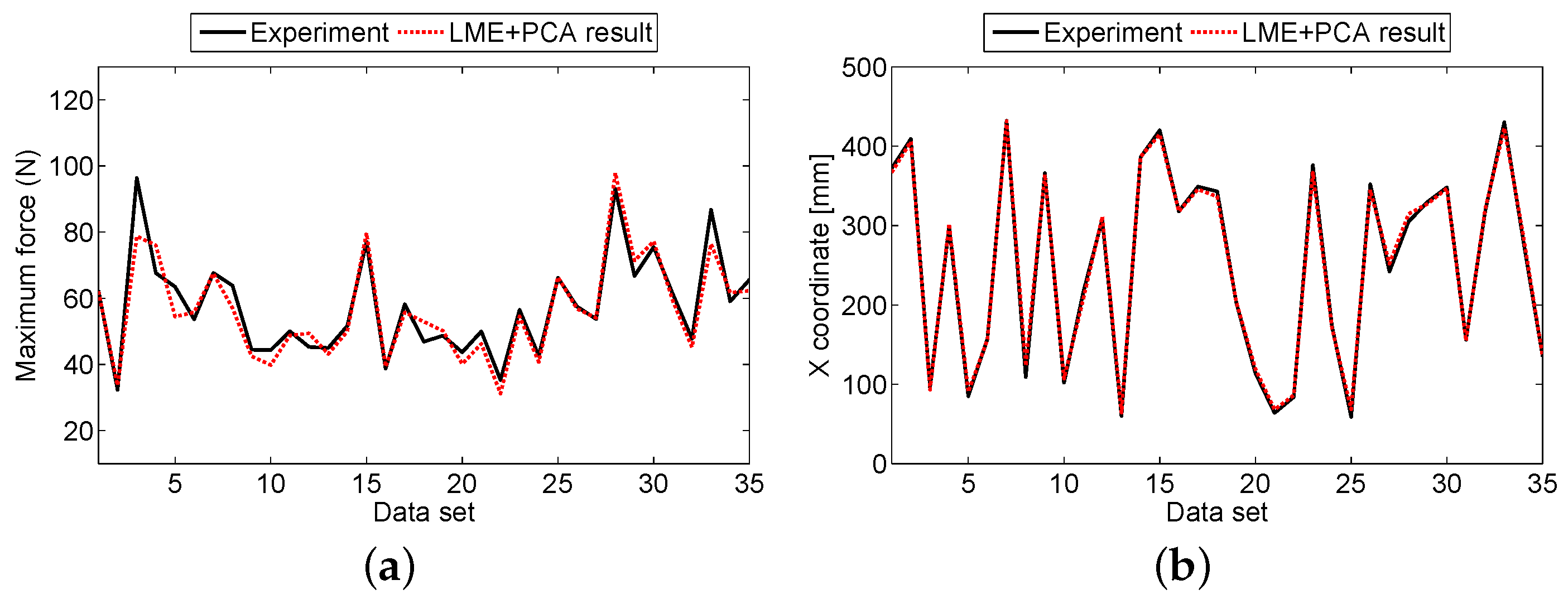
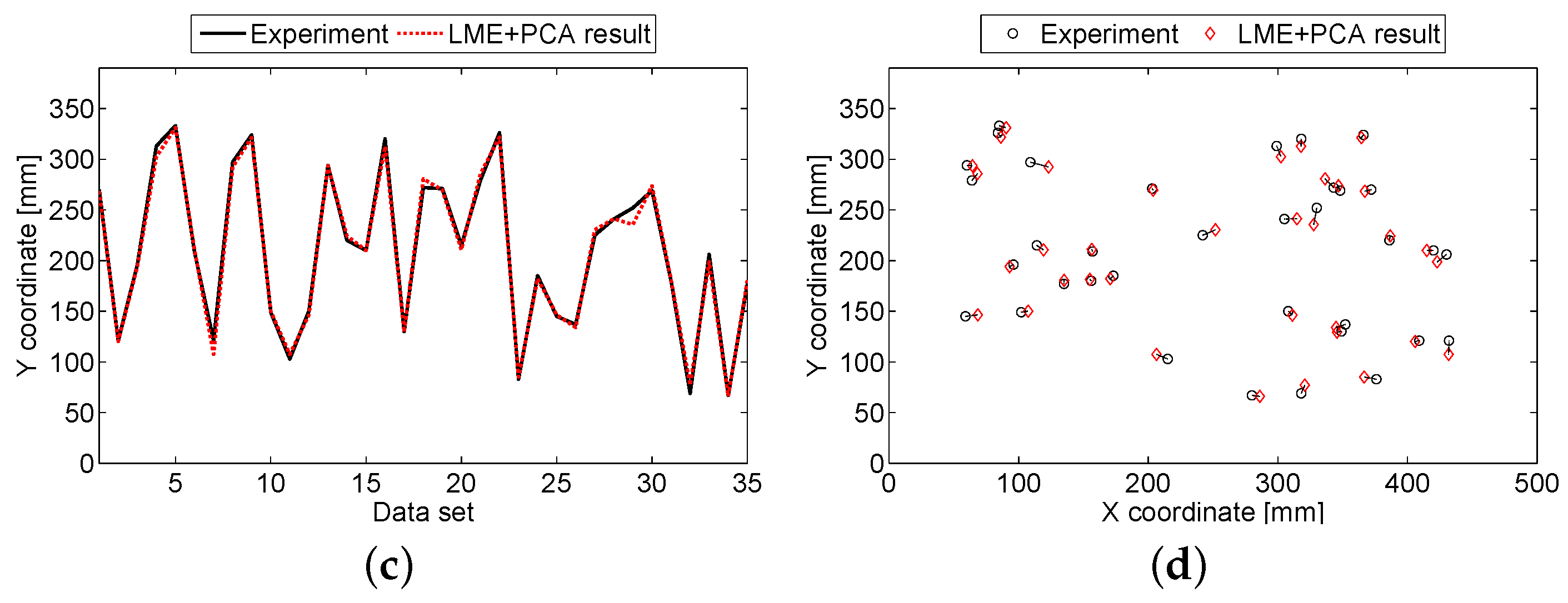
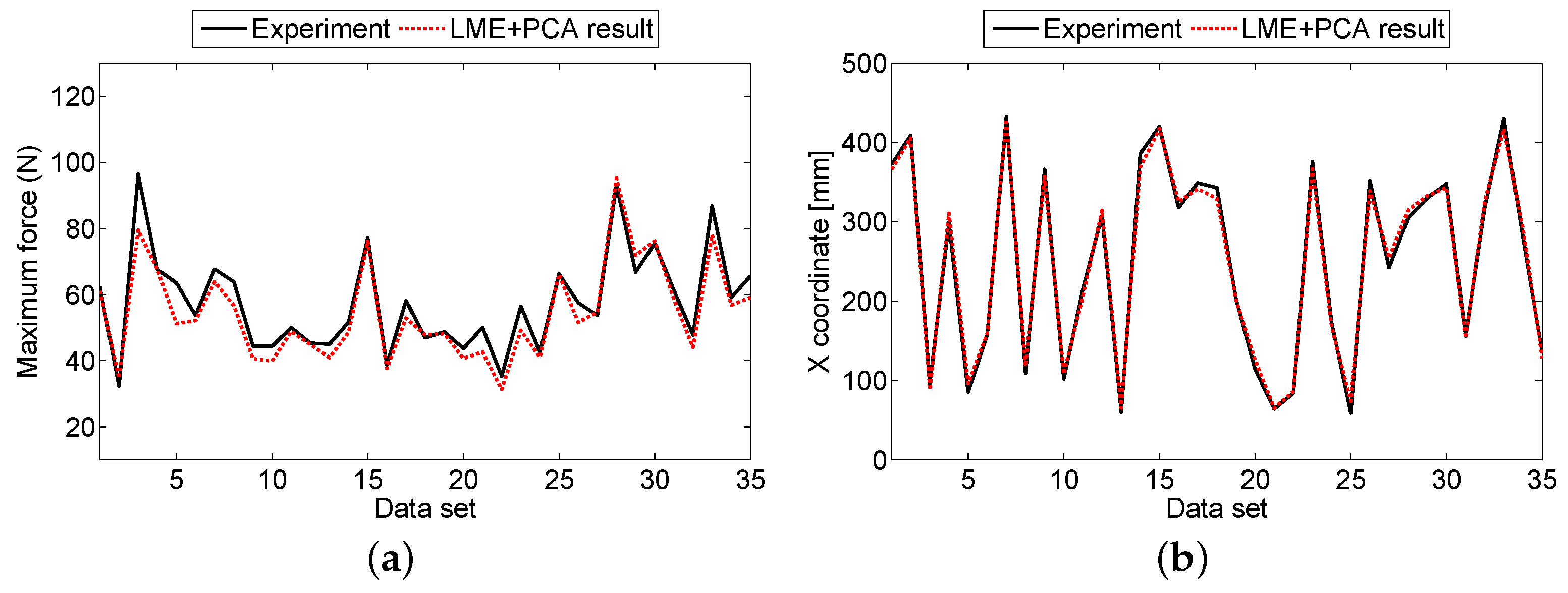
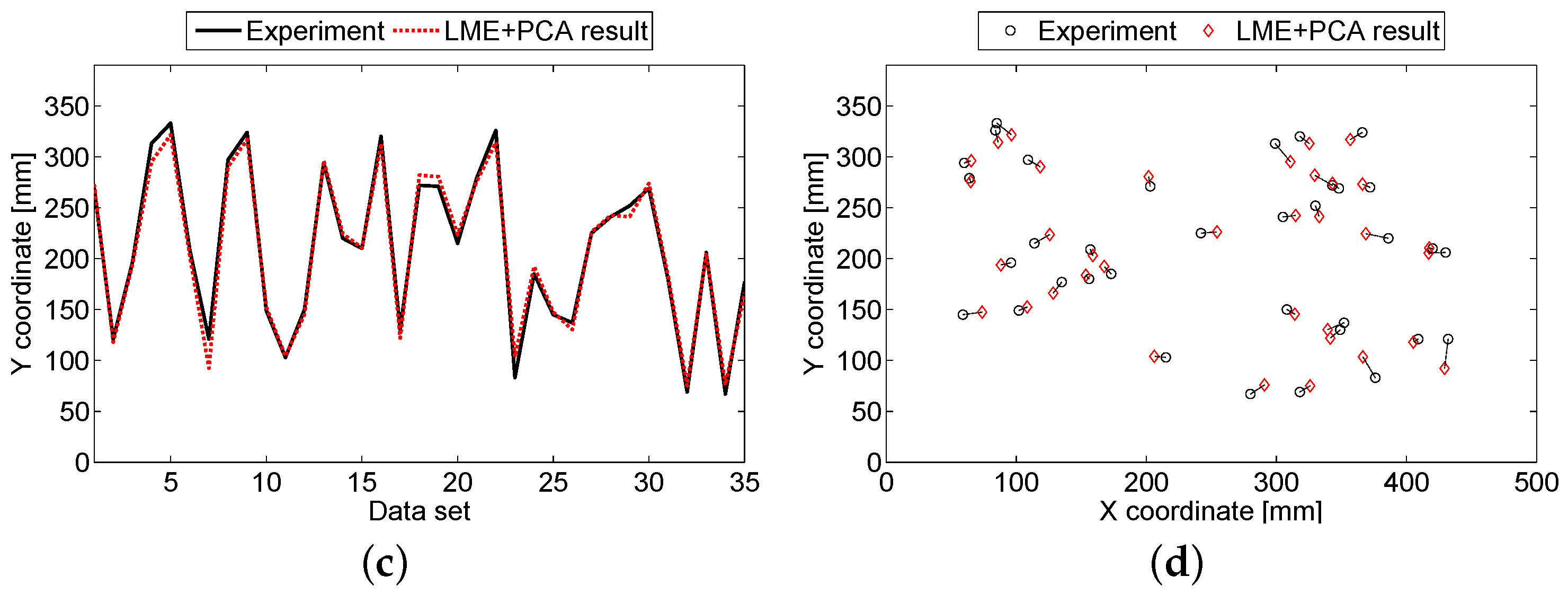
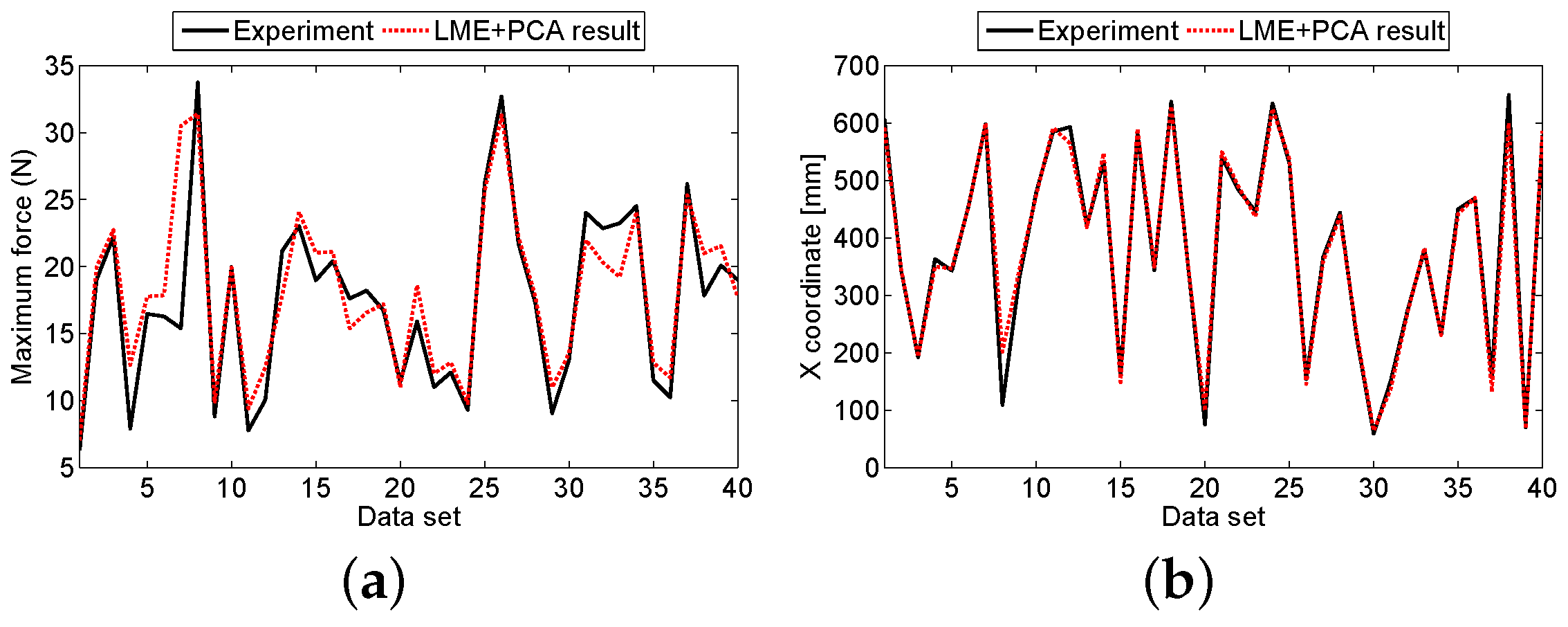
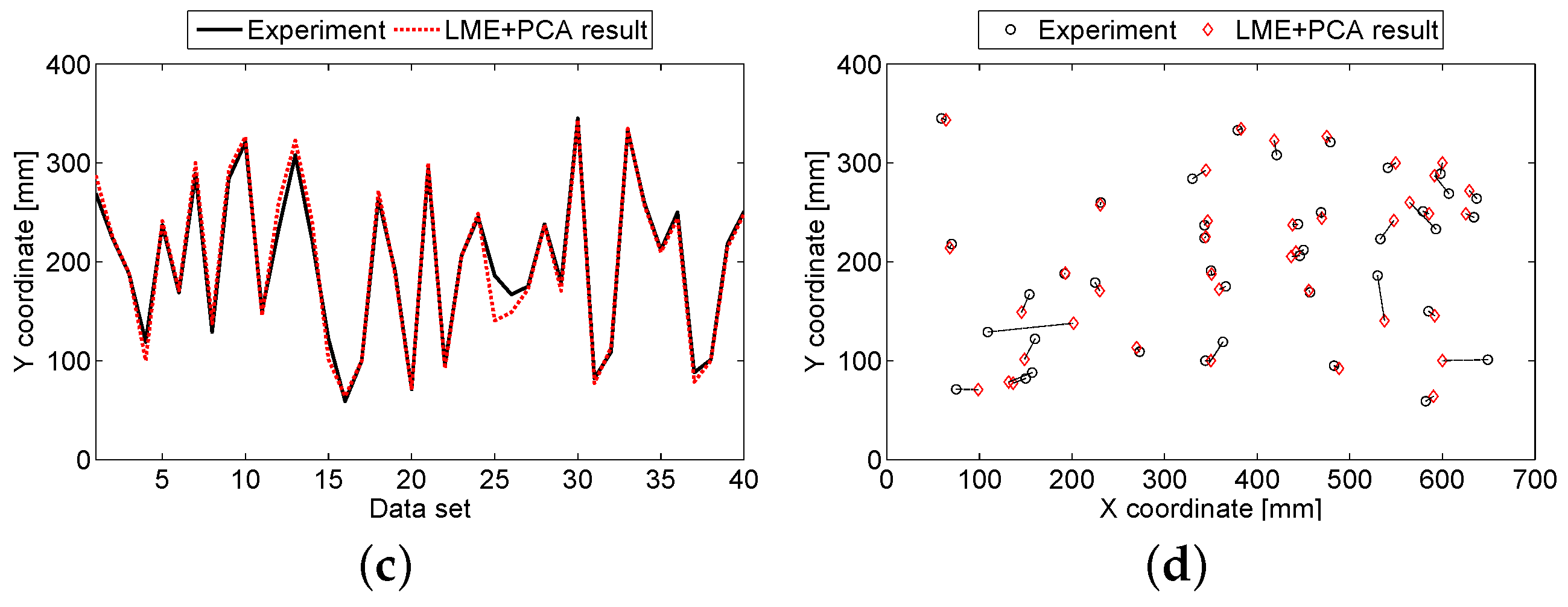
3.2. Aluminum Sandwich Panel
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vinson, J.R. Sandwich structures: Past, present, and future. In Sandwich Structures 7: Advancing with Sandwich Structures and Materials; Springer: New York, NY, USA, 2005. [Google Scholar]
- Seydel, R.; Chang, F.K. Impact identification of stiffened composite panels: I. System development. Smart Mater. Struct. 2001, 10, 354–369. [Google Scholar] [CrossRef]
- Seydel, R.; Chang, F.K. Impact identification of stiffened composite panels: II. Implementation studies. Smart Mater. Struct. 2001, 10, 370–379. [Google Scholar] [CrossRef]
- Worden, K.; Staszewski, W. Impact location and quantification on a composite panel using neural networks and a genetic algorithm. Strain 2000, 36, 61–68. [Google Scholar] [CrossRef]
- Staszewski, W.; Worden, K.; Wardle, R.; Tomlinson, G. Fail-Safe sensor distributions for impact detection in composite materials. Smart Mater. Struct. 2000, 9, 298–303. [Google Scholar] [CrossRef]
- Haywood, J.; Coverley, P.; Staszewski, W.; Worden, K. An automatic impact monitor for a composite panel employing smart sensor technology. Smart Mater. Struct. 2005, 14, 265–271. [Google Scholar] [CrossRef]
- LeClerc, J.; Worden, K.; Staszewski, W.; Haywood, J. Impact detection in an aircraft composite panel—A neural-network approach. J. Sound Vib. 2007, 299, 672–682. [Google Scholar] [CrossRef]
- Sharif-Khodaei, Z.; Ghajari, M.; Aliabadi, M. Determination of impact location on composite stiffened panels. Smart Mater. Struct. 2012, 21, 105026. [Google Scholar] [CrossRef]
- Gestel, T.V.; Suykens, J.; Baesens, B.; Viaene, S.; Vanthienen, J.; Dedene, G.; Moor, B.D.; Vandewalle, J. Benchmarking least squares support vector machine classifiers. Mach. Learn. 2004, 54, 5–32. [Google Scholar] [CrossRef]
- Xu, Q. Impact detection and location for a plate structure using least squares support vector machines. Struct. Health Monit. 2014, 31, 5–18. [Google Scholar] [CrossRef]
- Fu, H.; Xu, Q. Locating impact on structural plate using principal component analysis and support vector machines. Math. Probl. Eng. 2013, 2013, 352149. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar]
- Xu, Q. A Comparison study of extreme learning machine and least squares support vector machine for structural impact localization. Math. Probl. Eng. 2014, 2014, 906732. [Google Scholar] [CrossRef]
- Fu, H.; Vong, C.M.; Wong, P.K.; Yang, Z. Fast detection of impact location using kernel extreme learning machine. Neural Comput. Appl. 2016, 27, 121–130. [Google Scholar] [CrossRef]
- Ing, R.K.; Quieffin, N.; Catheline, S.; Fink, M. In solid localization of finger impacts using acoustic time-reversal process. Appl. Phys. Lett. 2005, 87, 204104. [Google Scholar] [CrossRef]
- Ribay, G.; Catheline, S.; Clorennec, D.; Ing, R.K.; Quieffin, N.; Fink, M. Acoustic impact localization in plates: Properties and stability to temperature variation. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2007, 54, 378–385. [Google Scholar] [CrossRef] [PubMed]
- Park, B.; Sohn, H.; Olson, S.E.; DeSimio, M.P.; Brown, K.S.; Derriso, M.M. Impact localization in complex structures using laser-based time reversal. Struct. Health Monit. 2012, 11, 577–588. [Google Scholar] [CrossRef]
- Ciampa, F.; Meo, M. Impact detection in anisotropic materials using a time reversal approach. Struct. Health Monit. 2012, 11, 43–49. [Google Scholar] [CrossRef]
- Meruane, V.; Ortiz-Bernardin, A. Structural damage assessment using linear approximation with maximum entropy and transmissibility data. Mech. Syst. Signal Process. 2015, 54, 210–223. [Google Scholar] [CrossRef]
- Meruane, V.; Fierro, V.D.; Ortiz-Bernardin, A. A Maximum Entropy Approach to Assess Debonding in Honeycomb Aluminum Plates. Entropy 2014, 16, 2869–2889. [Google Scholar] [CrossRef]
- Sanchez, N.; Meruane, V.; Ortiz-Bernardin, A. A novel impact identification algorithm based on a linear approximation with maximum entropy. Smart Mater. Struct. 2016, 25, 095050. [Google Scholar] [CrossRef]
- Ulrich, T. Envelope Calculation From the Hilbert Transform; Technical Report; Los Alamos National Laboratory: Los Alamos, NM, USA, 2006. [Google Scholar]
- Devroye, L.; Gyorfi, L.; Krzyzak, A.; Lugosi, G. On the strong universal consistency of nearest neighbor regression function estimates. Ann. Stat. 1994, 22, 1371–1385. [Google Scholar] [CrossRef]
- Rovatti, R.; Borgatti, M.; Guerrieri, R. A geometric approach to maximum-speed n-dimensional continuous linear interpolation in rectangular grids. IEEE Trans. Comput. 1998, 47, 894–899. [Google Scholar] [CrossRef]
- Jaynes, E. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Sukumar, N.; Wright, R. Overview and construction of meshfree basis functions: From moving least squares to entropy approximants. Int. J. Numer. Methods Eng. 2007, 70, 181–205. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Wiley: New York, NY, USA, 1959. [Google Scholar]
- Shore, J.; Johnson, R. Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy. IEEE Trans. Inf. Theory 1980, 26, 26–36. [Google Scholar] [CrossRef]
- Arroyo, M.; Ortiz, M. Local maximum-entropy approximation schemes: A seamless bridge between finite elements and meshfree methods. Int. J. Numer. Methods Eng. 2006, 65, 2167–2202. [Google Scholar] [CrossRef]
- Gupta, M.R.; Gray, R.M.; Olshen, R.A. Nonparametric supervised learning by linear interpolation with maximum entropy. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 766–781. [Google Scholar] [CrossRef] [PubMed]
- Meruane, V. Source Code for Impact Location and Quantification on an Aluminum Sandwich Panel Using PCA and LME. Available online: http://viviana.meruane.com/des_en.htm (accessed on 21 March 2017).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Piezoelectric Discs | |
| Model | 7BB-20-6L0 |
| Resonant frequency | 6 kHz |
| Disc size | 20 mm |
| Thickness | 0.42 mm |
| Impact Hammer | |
| Model | LC-01A |
| Sensitivity | 4 mV/N |
| Max. shock force | 2 kN |
| Tip material | Nylon |
| Force transducer | CL-YD-303 |
| Data Acquisition System | |
| Model | ECON MI-7016 |
| Resolution | 24 bit |
| Channels | 16 |
| Max. sampling rate | 96 kHz |
| Reference | Algorithm | Plate Size (mm) | Number of Sensors | Number of Training Impact Points | Area Error (%) | Force Error (%) |
|---|---|---|---|---|---|---|
| Xu [10] | LS-SVM | 490 × 390 | 4 | 63 | 1.06 | 51.2 |
| Fu and Xu [11] | PCA+SVM | 490 × 390 | 4 | 63 | 0.13 | - |
| Xu [13] | Kernel-ELM | 490 × 390 | 4 | 63 | 0.74 | - |
| Fu et al. [14] | PCA+Kernel-ELM | 490 × 390 | 4 | 63 | 0.24 | - |
| Current work | LME+PCA | 490 × 390 | 4 | 61 | 0.028 | 6.53 |
| Experimental Case | Identification Algorithm | |||
|---|---|---|---|---|
| LME | LME + PCA | |||
| Aluminum plate | Area Error (%) | 0.12 | 0.009 | |
| Force Error (%) | 7.18 | 5.84 | ||
| Sandwich panel | Area Error (%) | 0.15 | 0.031 | |
| Force Error (%) | 27.42 | 12.39 | ||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meruane, V.; Véliz, P.; López Droguett, E.; Ortiz-Bernardin, A. Impact Location and Quantification on an Aluminum Sandwich Panel Using Principal Component Analysis and Linear Approximation with Maximum Entropy. Entropy 2017, 19, 137. https://doi.org/10.3390/e19040137
Meruane V, Véliz P, López Droguett E, Ortiz-Bernardin A. Impact Location and Quantification on an Aluminum Sandwich Panel Using Principal Component Analysis and Linear Approximation with Maximum Entropy. Entropy. 2017; 19(4):137. https://doi.org/10.3390/e19040137
Chicago/Turabian StyleMeruane, Viviana, Pablo Véliz, Enrique López Droguett, and Alejandro Ortiz-Bernardin. 2017. "Impact Location and Quantification on an Aluminum Sandwich Panel Using Principal Component Analysis and Linear Approximation with Maximum Entropy" Entropy 19, no. 4: 137. https://doi.org/10.3390/e19040137
APA StyleMeruane, V., Véliz, P., López Droguett, E., & Ortiz-Bernardin, A. (2017). Impact Location and Quantification on an Aluminum Sandwich Panel Using Principal Component Analysis and Linear Approximation with Maximum Entropy. Entropy, 19(4), 137. https://doi.org/10.3390/e19040137